基于视觉的抓取算法的目的:给定一个包含物体的场景、一个机械手模型,算法以该场景的视觉信息为输入,计算出一个最优的抓取位姿,使机械手在该位姿下可以稳定地抓取物体。
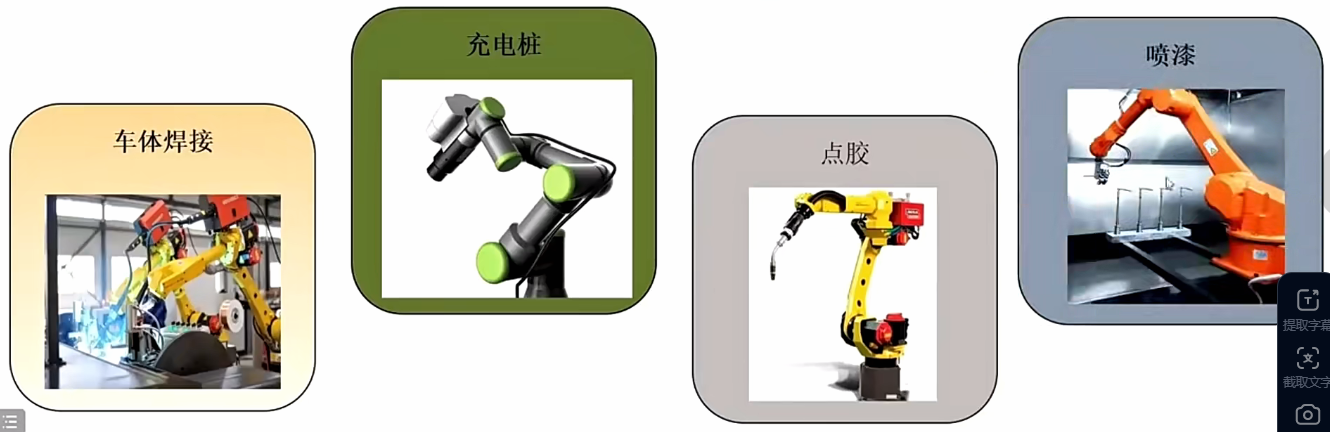
机械臂抓取常见场景:
物流拆垛:把一堆重物叠起来的堆给拆出来,分成一件一件物品
物品分拣:把一堆东西按类分好
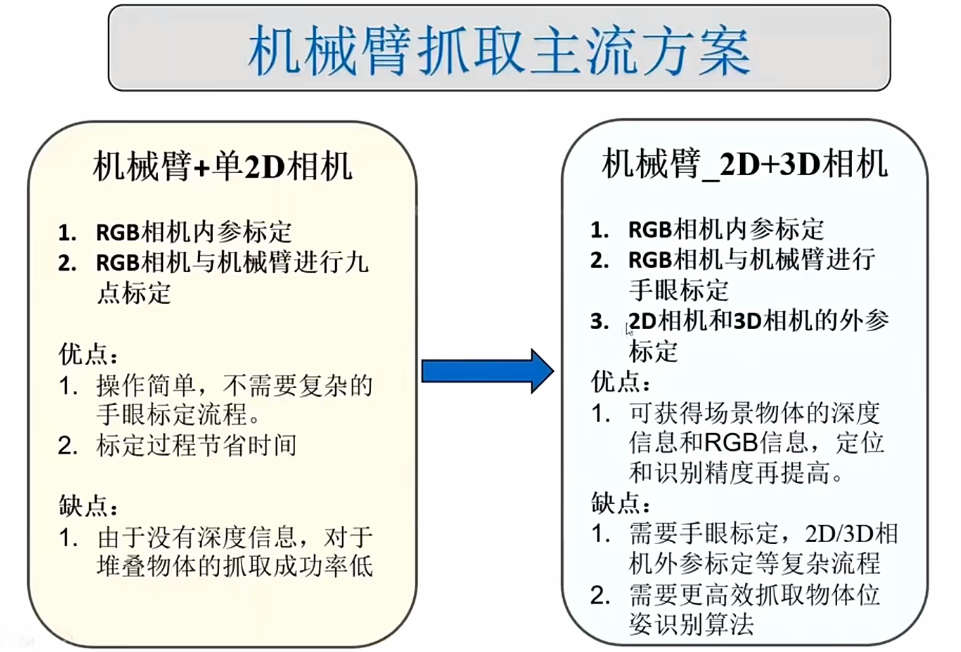
常见主流抓取方案:
抓取任务的分类:
物体:模型未知、模型已知
场景:bin-picking、操作物体、hand-over
机械手模型:二指、多指、吸盘
视觉信息:彩色图像、深度图像、点云
抓取位姿(二指机械手):平面抓取位姿、6DOF抓取位姿
平面抓取的特点:
使机械抓手在x和y轴的转角设置为已知的定值(其实就是设置为初始值),即roll和pitch为定值
那么剩下的就是获取抓取点的x,y值以及沿着z轴方向的值这样就是完整的抓取位姿也是神经网络实际输出的值
平面抓取模型(抓取标签):
描述二指机械手在平面抓取时的状态,也是神经网络实际输出的值。
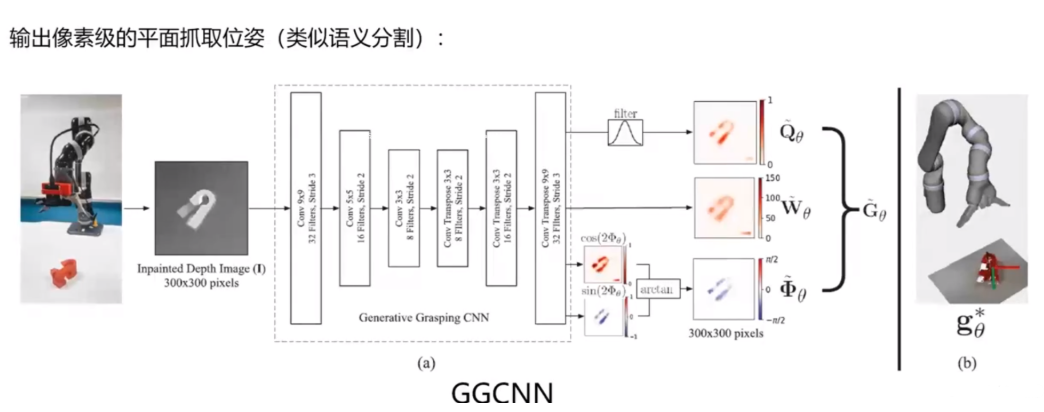
常见的二指机械手平面抓取模型如下:
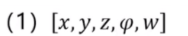
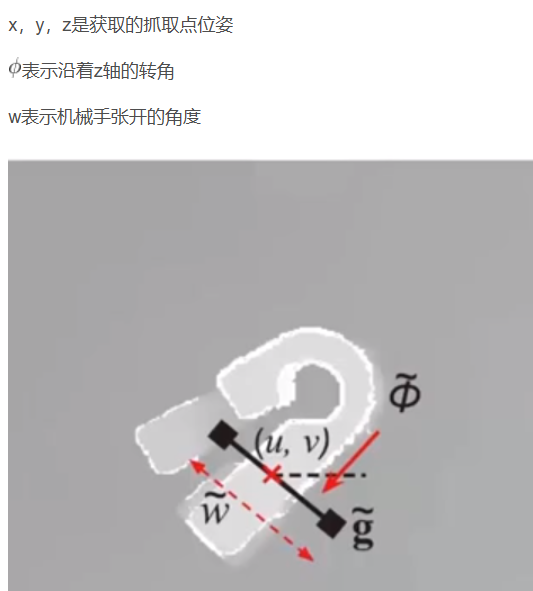
上图就是一个抓取位姿图
ggcnn的输入实际上就是一张深度图,然后输出抓取位姿图
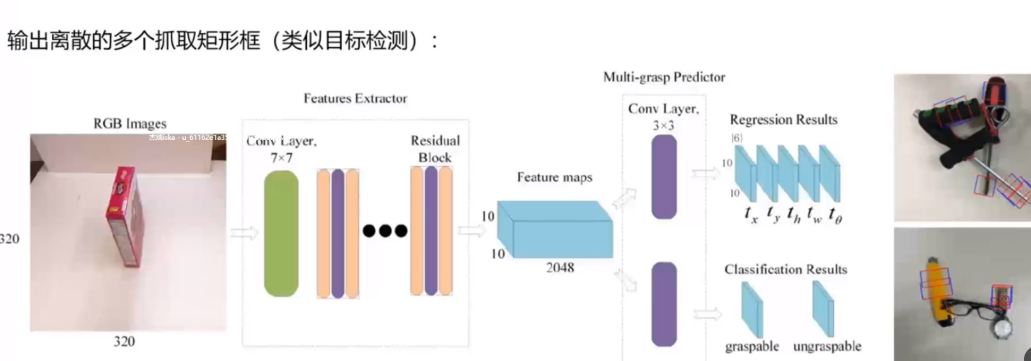
常见的平面抓取检测流程包括两种:
端到端

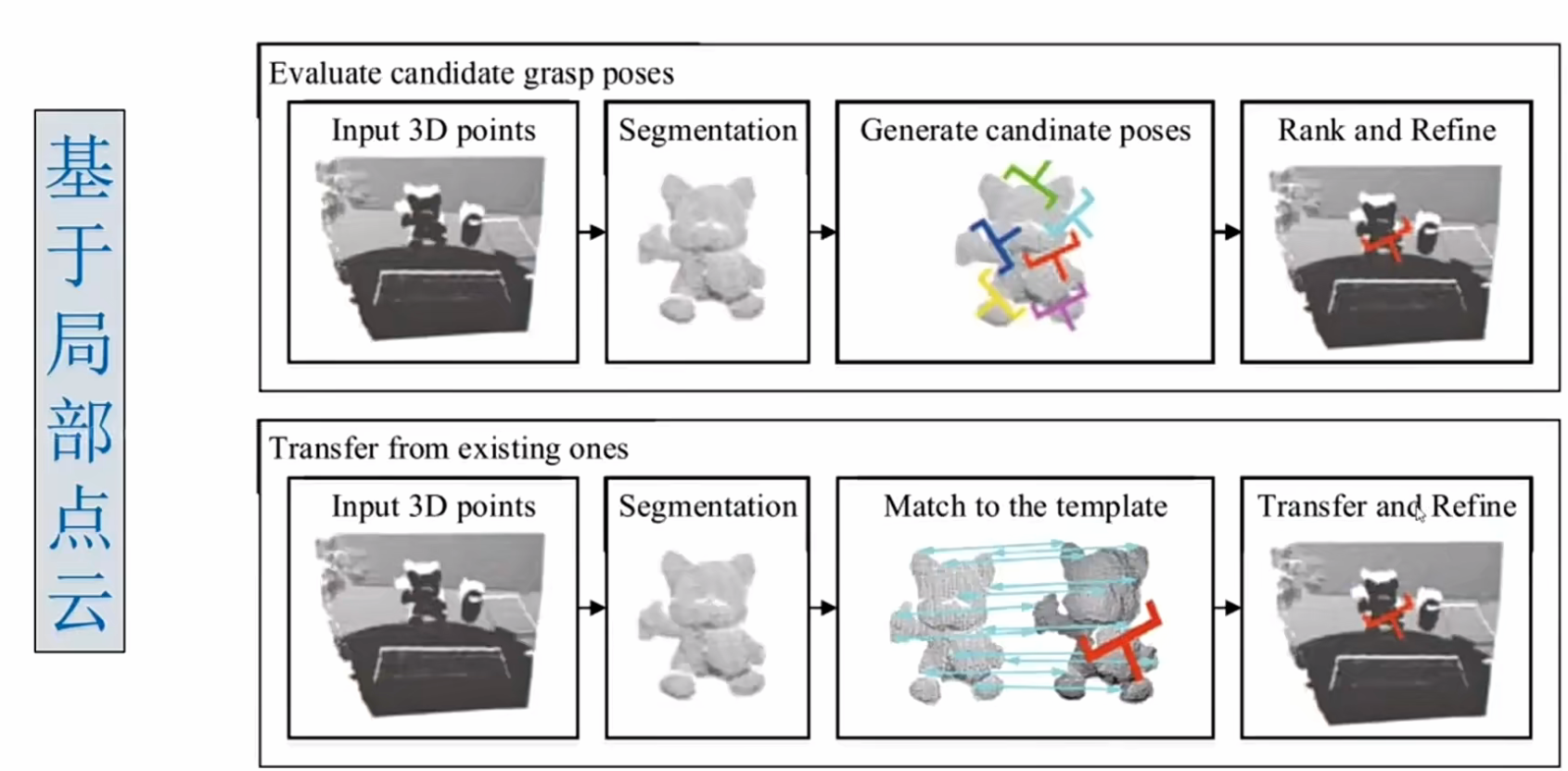
先采样后评估
- 第一步:输入信息 :给机械臂的 "眼睛"(摄像头)输入 RGBD 图像(既包含物体的颜色信息,也包含物体的深度信息 ------ 能知道物体离摄像头多远)。
- 第二步:采样候选抓取姿势:在这张 RGBD 图像里,先 "试选" 很多个可能的 "抓取位姿"(比如 "抓物体的左上角""抓物体的中间",每个位姿还包含抓的角度),同时提取每个候选位姿对应的局部图像块(只看这个抓取姿势对应的小区域图像)。
- 第三步:用神经网络评估 "好不好抓":把每个候选的抓取姿势对应的图像块,都放进一个叫 "Grasp Quality CNN" 的神经网络里,让网络输出这个姿势 "能成功抓住的概率(置信度)"。
- 第四步:选最好的姿势去抓:从所有候选里,挑出 "置信度最高(最可能抓成功)" 的那个姿势,让机械臂实际去抓取。
- 特点 :因为要评估很多个候选姿势,所以这个方法的速度比较慢。
6自由度抓取方案:

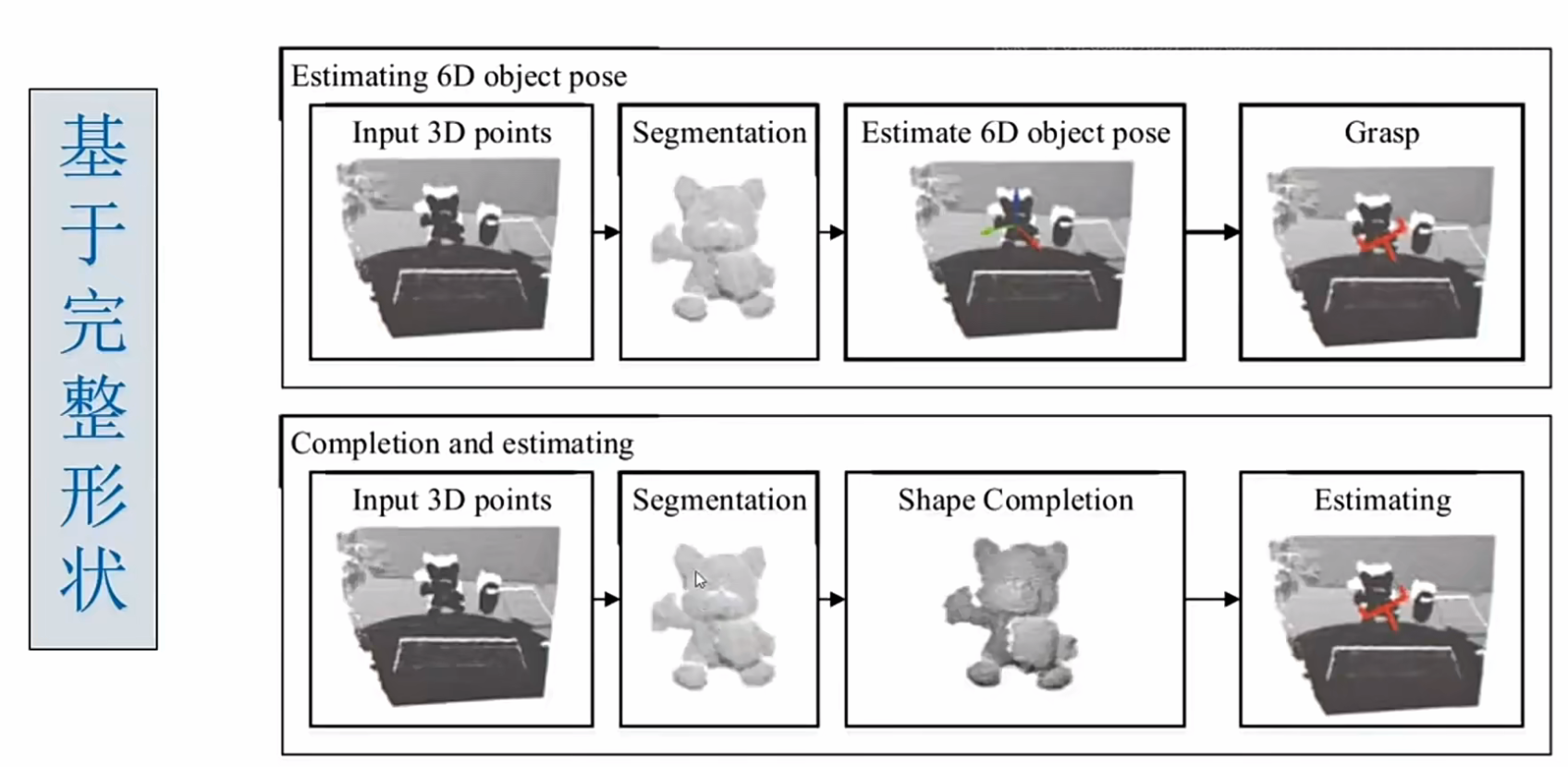
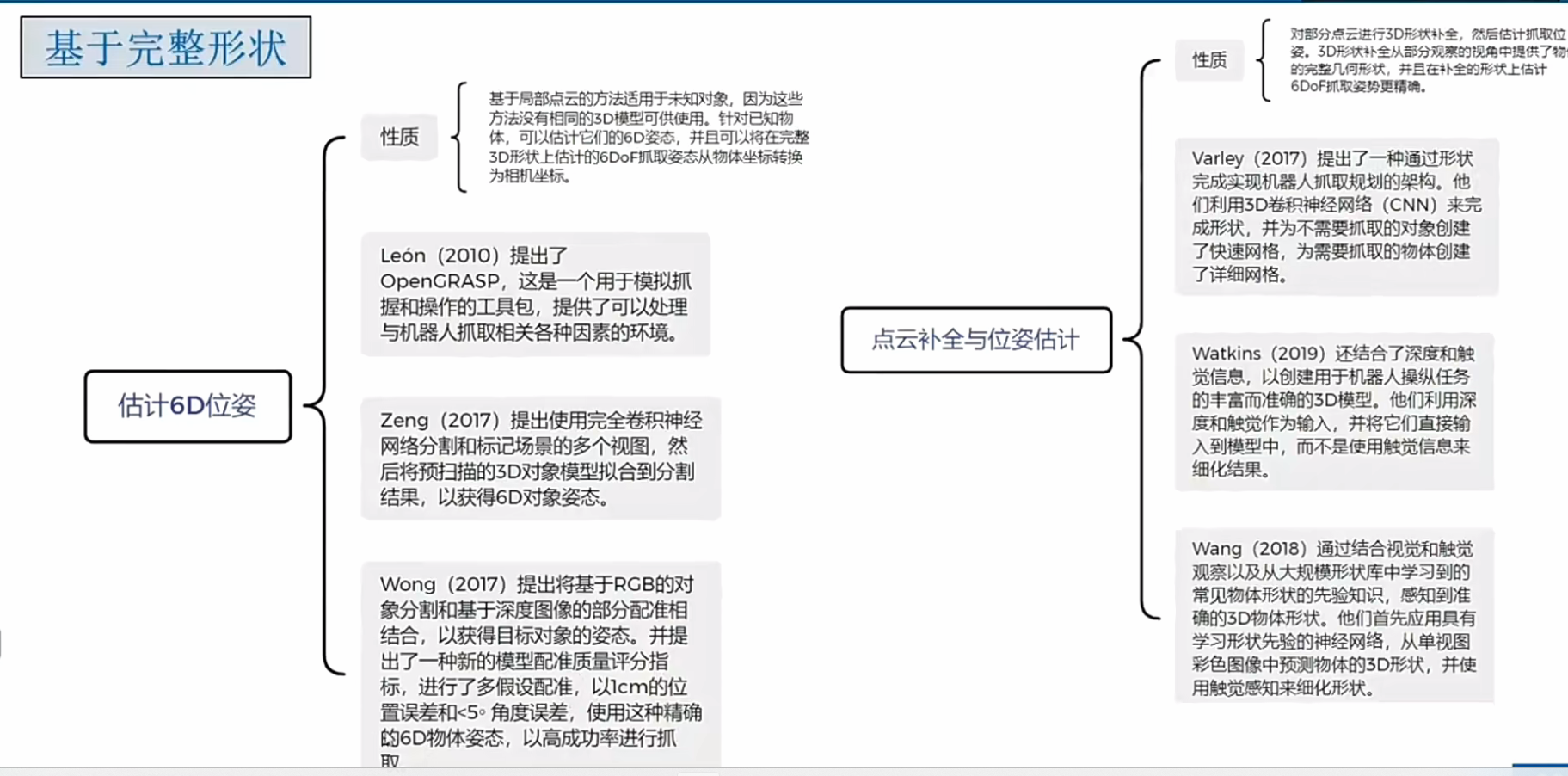
6DOF抓取估计(目前面临的挑战)

机器人抓取遇到的困难:
3D相机硬件测距原理介绍
点光源结构光3D相机测距 Z:
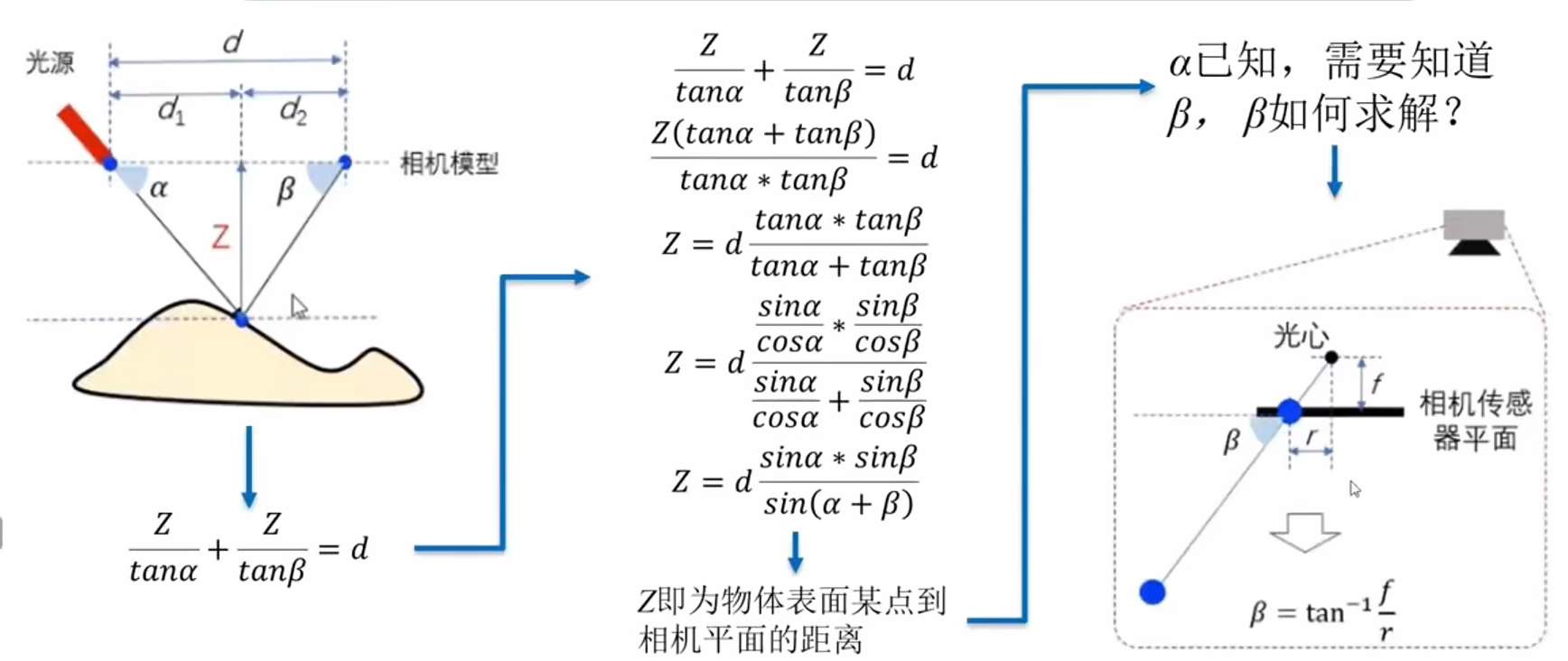
线光源结构光3D相机测距 Z:

面光源结构光3D相机测距 Z: 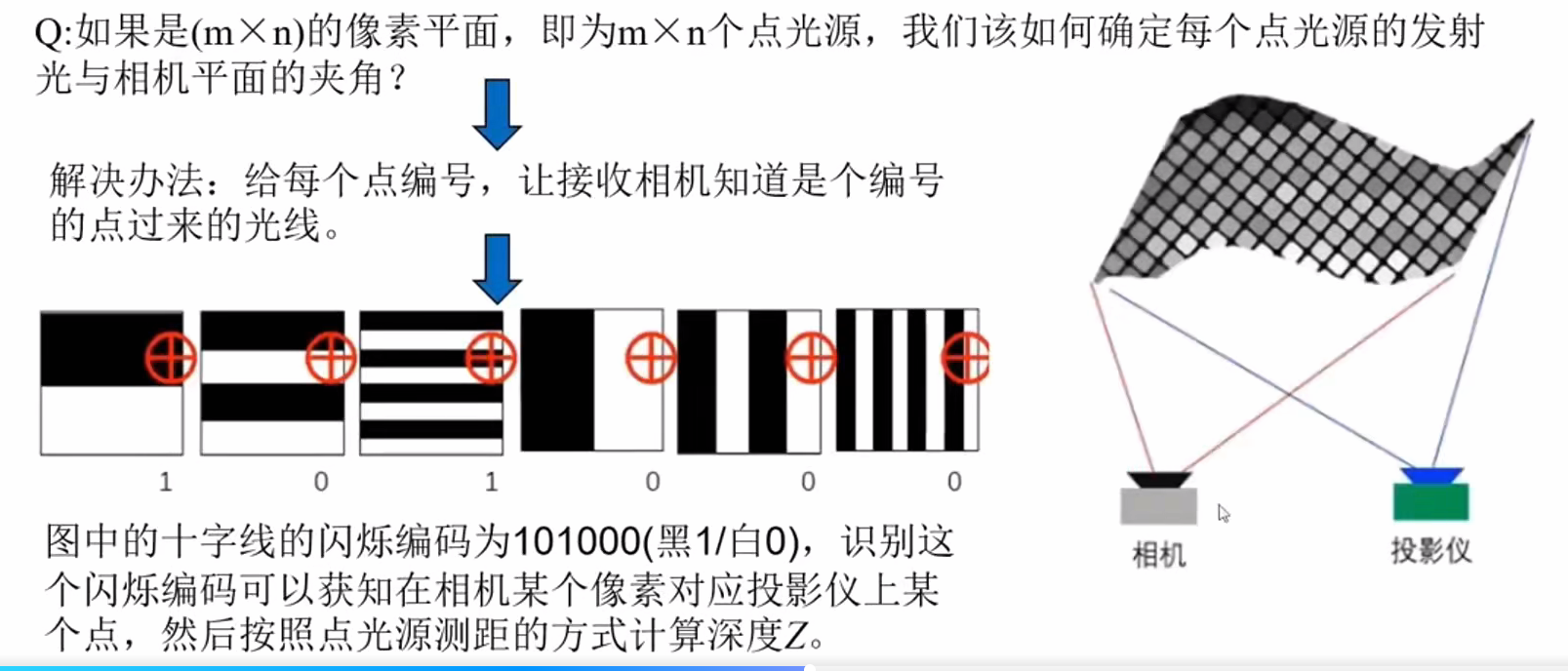
抓取的数据集:




(4)仿真图片+解析计算标注(Dex-net2.0数据集)
步骤 1:搭建 "虚拟实验室"(用 PyBullet 仿真环境)
先打开 PyBullet 这个软件 ------ 它是一个 "虚拟的物理世界",能模拟真实的物体、相机、力学规律。
步骤 2:摆物体 + 拍 "带深度的照片"
-
在这个虚拟世界里,随机摆放单个物体(Dex-net2.0 是 "单物体场景",所以每次只放一个物体,比如杯子、积木);
-
用虚拟的 "深度相机"(仿真真实的 RGBD 相机)给这个物体拍照片 ------ 拍出来的是RGBD 图像:既有物体的颜色(RGB),也有每个像素对应的 "物体离相机的距离(深度,D)",能体现物体的立体形状。
步骤 3:用 "力封闭原则" 选 "能抓稳的姿势"
"力封闭原则" 是个简单的物理规则:选的抓取姿势,得能让夹爪把物体 "夹稳、不会掉"(比如抓杯子的把手,比抓光滑的杯壁更稳)。
在这个虚拟物体的 3D 模型上,用这个原则 "试" 很多个抓取位姿(比如抓物体的不同位置、不同角度),把这些 "能抓稳" 的姿势都记下来。
步骤 4:把 "抓姿" 转成标签,和照片对应上
把刚才选好的 "能抓稳的抓取位姿",对应到刚才拍的 RGBD 图像里,生成抓取标签------Dex-net2.0 里的标签格式是[x,y,z,φ,w]:
-
x,y,z:抓取位置(物体上哪个点); -
φ,w:抓取角度(夹爪要转多少度)。
最后:批量生成,得到 Dex-net2.0 数据集
重复上面 4 步,批量在 PyBullet 里摆不同物体、拍图、选抓姿、生成标签,最后攒出了 **670 万个 "RGBD 图像块 + 抓取标签"** 的数据集 ------ 这些数据都是虚拟环境里造的,不用手动标注,效率很高。
简单总结:Dex-net2.0 是在 "电脑虚拟世界" 里,自动摆物体、拍带深度的照片、选能抓稳的姿势、生成标签,最后攒出来的 "机械臂抓东西的练习数据"~
(5)真实图片+解析计算标注
步骤 1:先在 "虚拟环境" 给单个物体选 "能抓稳的姿势"
先打开仿真软件(比如 PyBullet),把每个物体的 3D 模型放进去,用 "力封闭原则"(之前说的 "能夹稳不掉" 的物理规则),给每个单独的物体选很多个 "靠谱的抓取位姿"(记下来这些抓姿,叫 "物体级抓姿")。
步骤 2:拍 "真实的多物体场景照片"
在现实世界里,把多个真实物体堆在一起(比如桌上放杯子、工具、玩具,对应图里的 "多物体桌面"),用真实的 RGBD 相机(能拍颜色 + 深度的摄像头),给这些 "杂乱堆着的物体" 拍照片 ------ 这些是真实的 RGBD 图像(不是仿真图)。
步骤 3:把 "虚拟抓姿" 使用到 "真实场景" 里
真实场景里物体可能并非是在平面,有可能倾斜,有可能有六个自由度。虚拟里的单个平面物体的抓姿怎么能用到真实场景里物体身上呢?
第一步:虚拟里的抓姿,是 "跟着物体自己走的"
在虚拟环境中,我们给单个物体(比如杯子)选抓姿时,不是以 "虚拟世界的地面 / 相机" 为参考,而是以 "物体自身的坐标系" 为参考的。
比如虚拟里的杯子,我们定义它的 "自身坐标系":以杯底中心为原点,杯身竖直方向为 Z 轴,把手方向为 X 轴。此时选的 "抓把手" 的抓姿,是 **"相对于杯子自身坐标系的坐标和角度"**(比如 "在自身坐标系的 X=0.1、Y=0、Z=0.2 位置,角度为 0°")。
第二步:真实场景中,先找到 "物体自身坐标系的位置和角度"
真实场景里的物体(比如倾斜的杯子),我们会用算法算出它的6DOF 位姿------ 这其实就是 "物体自身坐标系,在真实世界里的位置和角度":
- 平移(3 个自由度):物体自身坐标系的原点,在真实世界里的位置(比如 "离相机 1 米,在相机右方 0.2 米");
- 旋转(3 个自由度):物体自身坐标系的三个轴,在真实世界里的倾斜角度(比如 "杯身歪了 30°,把手朝左偏了 15°")。
第三步:把 "虚拟抓姿" 转换成 "真实场景的抓姿"
有了真实物体的 6DOF 位姿,我们可以用坐标变换矩阵(由平移和旋转计算出来),把 "虚拟里物体自身坐标系下的抓姿",转换成 "真实世界坐标系下的抓姿"。
比如:
- 虚拟里的抓姿是 "杯子自身坐标系的(0.1,0,0.2),角度 0°";
- 真实杯子的 6DOF 位姿告诉我们:它的自身坐标系 "歪了 30°、平移到了真实世界的(2,1,0.5)位置";
- 通过变换矩阵计算后,虚拟抓姿就会变成 "真实世界里的(2.08,1.05,0.52)位置,角度 30°"------ 刚好对应真实倾斜杯子的把手位置。
总结
虚拟抓姿不是 "固定的平面姿势",而是 **"绑定在物体自身上的'相对姿势'"**;真实物体不管怎么倾斜、有多少自由度,只要能算出它的 6DOF 位姿(找到它的自身坐标系),就能通过 "坐标变换" 把虚拟抓姿适配到真实物体的任意状态上。
步骤 4:生成标签,攒成数据集
把每个真实 RGBD 图像里,每个物体对应的 "套过来的抓姿",标注成两种格式:
-
6DOF 位姿:记录 "抓这个物体的 3 个位置 + 3 个旋转角度"(精准的空间抓姿);
-
平面抓取矩形框:在 2D 照片里,画个矩形框标出 "抓的区域"。
经典平面抓取算法
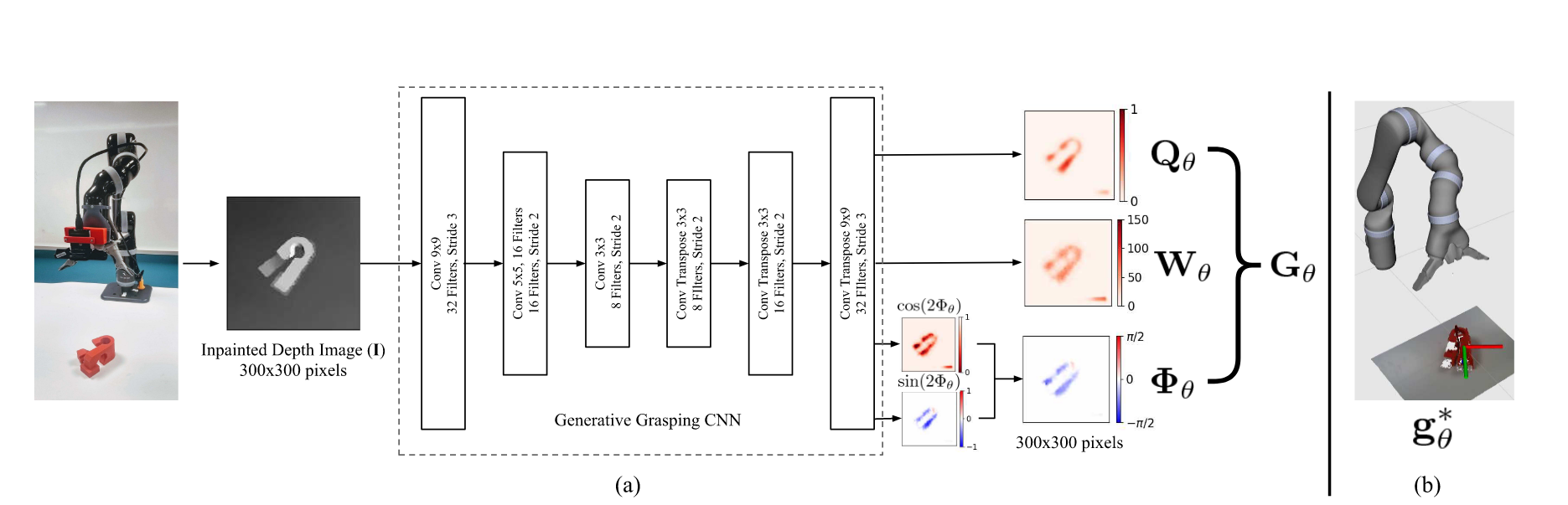
ggcnn:
ggcnn这是一种端到端的方法来进行抓取 以深度图作为输入 输出一种像素级的抓取位姿。
举个直观的例子:假设输入的深度图是一张 "桌上杯子" 的图,GGCNN 会告诉我们:
-
杯子把手区域的某个像素(比如第 80 行、150 列):"以这个像素为中心,夹爪转 20°、张开 3 厘米,抓成功的概率是 95%";
-
杯子杯壁的某个像素(比如第 60 行、120 列):"以这个像素为中心,夹爪转 0°、张开 4 厘米,抓成功的概率是 40%"。
ggcnn的网络结构:
DEX-Ne t2.0:
Dex-Net是先采样后评估的方法
这个方法精度很高,但是速度慢,并且只限于平面抓取
DEX-Net 2.0 是针对单物体场景的深度学习抓取方法,核心是通过 "仿真数据训练 + 抓取质量预测",让机械臂快速判断 "哪个姿势能稳抓物体",是早期将 "物理抓取规则" 与深度学习结合的经典方案之一。
DEX-Ne t2.0核心流程
整个抓取过程分 3 步,和你之前了解的 "先采样后评估" 策略完全对应:
- 输入物体数据:获取单物体的 RGBD 图像(颜色 + 深度),并转换成物体的 3D 点云(体现立体形状);
- 采样候选抓姿:基于物体的 3D 模型,用 "力封闭原则"(物理上能夹稳物体的规则),采样出多个候选抓取位姿(每个位姿包含 "抓哪里(x,y,z)、抓的角度(φ,w)");
- 神经网络评估质量:把每个候选抓姿对应的局部点云 / 图像块,输入到训练好的 CNN(卷积神经网络)中,网络输出这个抓姿的 "成功概率(质量分数)";
- 执行最优抓取:选质量分数最高的候选抓姿,让机械臂执行抓取。
核心数据集(DEX-Net 2.0 Dataset)
- 用 PyBullet 仿真环境批量生成:包含 670 万个 "抓取位姿标签 + 对应图像块",全部是单物体场景;
- 标签格式:
[x,y,z,φ,w](x/y/z 是抓取位置,φ/w 是抓取角度); - 数据特点:每个抓姿都满足 "力封闭"(物理上能抓稳),为神经网络提供了 "什么是好抓姿" 的监督信号。
手眼标定----求解相机内参
内参是相机 "自带的'成像规则'",负责把 "3D 空间里的物体" 转换成 "相机拍出来的 2D 像素",是机械臂 "通过相机'看'到物体后,算出物体真实位置" 的关键前提。
一、相机内参的核心定义
相机内参是相机自身的固定参数(出厂后基本不变,除非相机硬件改动),机械臂的相机(比如 RGBD 相机或者深度相机)要 "看懂" 物体的位置,得先把 "相机看到的 3D 世界" 转成 "照片里的 2D 像素"------ 内参就是这个转换的 "数学工具"
二、内参的原理:从 "3D 空间" 到 "2D 像素" 的转换
1. 先明确两个坐标系
- 相机坐标系(3D):以相机光心为原点,镜头朝向为 Z 轴(物体离相机越远,Z 越大),水平向右是 X 轴,竖直向下是 Y 轴(单位是米 / 毫米,是真实的 3D 空间)。
- 像素坐标系(2D):相机拍出来的照片,以照片左上角为原点,水平向右是 u 轴,竖直向下是 v 轴(单位是 "像素",比如 (200,150) 代表第 200 列、第 150 行的像素)。
2. 内参矩阵:实现 3D→2D 的转换
内参用一个 3×3 的矩阵表示,结构是:
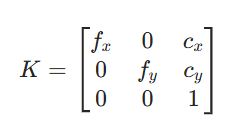
每个参数的意思:
-
(f_x、f_y) :"焦距的像素表示"------fx与fy的像素值(比如 fx=500 像素)表征着相机的焦距(比如 35mm)
就像你用手机拍杯子时:fx 决定了 "杯子在屏幕左右方向上的放大程度";fy 决定了 "杯子在屏幕上下方向上的放大程度"。
-
(c_x、c_y):"图像主点的像素坐标"------ 相机光轴(镜头中心的射线)在照片里对应的像素点(理想情况下是照片的中心,比如 1280×720 的照片,cx≈640,cy≈360)。
3. 转换公式(核心逻辑)
如果相机坐标系里有一个物体点,坐标是(X_c, Y_c, Z_c)(Zc 是物体离相机的距离,即深度),那么它在照片里对应的像素坐标(u, v),就是通过内参矩阵计算的:

三、内参在机械臂中的核心应用:"看得到"→"抓得到"
机械臂要抓物体,必须把 "相机照片里的像素点" 转换成 "机械臂能理解的真实空间位置"------ 内参是这个过程的第一步,流程是:
步骤 1:用内参,把 "像素 + 深度" 转成 "相机坐标系的 3D 坐标"
RGBD 相机能同时拍到 "像素(u,v)" 和 "深度(Zc,即物体离相机的距离)",结合内参,就能反推出物体在相机坐标系里的 3D 坐标(X_c, Y_c, Z_c):
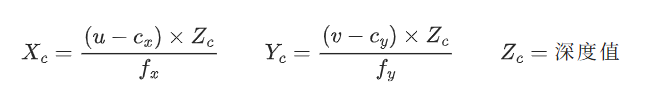
举个例子:
- 相机内参:fx=500,fy=500,cx=640,cy=360;(出厂后就固定了)
- 照片里物体的像素(坐标)是 (740, 410),深度是 0.5 米(Zc=0.5);
- 计算得:Xc=(740-640)×0.5/500=0.1 米,Yc=(410-360)×0.5/500=0.05 米;
- 所以物体在相机坐标系里的位置是 (0.1, 0.05, 0.5) 米。
步骤 2:结合外参,转成 "机械臂坐标系的坐标"
有了相机坐标系的 3D 坐标,再通过相机外参(表征相机和机械臂的相对位置,表征相机坐标系与机械臂基座坐标系的转换关系),就能把坐标转换成 "机械臂坐标系下的位置"------ 机械臂就知道 "要移动到哪个点去抓物体" 了。
四、关键补充:内参必须 "标定"
(1)相机的内参虽然是固定的,但实际出厂时会有误差,所以必须先用棋盘格标定(比如 OpenCV 的标定工具),得到准确的 fx、fy、cx、cy,否则转换出来的坐标会不准,导致机械臂 "抓不准"。
(2)光心:
-
相机镜头不是一片玻璃,而是好几片镜片叠在一起的(就像一组放大镜组合);
-
所有光线穿过这组镜片后,会 "仿佛" 从一个共同的中心点穿过 ------ 这个 "虚拟的、让光线集中通过的中心点",就是光心;
-
它的位置确实在镜头的中心区域(物理上靠近镜头的几何中心),所以你平时想 "镜头中间那个点",就等于想 "光心",完全没问题。
项目实战:
环境搭建:阅读reandme

如何解决环境搭建遇到的问题:百度,ai,csdn,github中的issue
数据集:
