文章目录
- 前言
- 掌握Java网页抓取:技术与示例
- Java网页抓取库概述
-
- Jsoup
- HtmlUnit
- Selenium
- [Apache HttpClient/HttpComponents](#Apache HttpClient/HttpComponents)
- Playwright
- 分步指南:使用Java进行基本网页抓取
- 处理动态内容
- 分页和网页爬取
- 并行化和高效抓取
- 为什么代理在网页抓取中很重要
- 在Java网页抓取中使用代理
-
- [Selenium WebDriver与代理](#Selenium WebDriver与代理)
- [Playwright for Java与代理](#Playwright for Java与代理)
- 反抓取措施及应对方法
- 存储和处理抓取的数据
- 故障排除和调试
- Java网页抓取的最佳实践
- 高级技巧和资源
- 总结
- 常见问题解答
-
- 网页抓取合法吗,道德考虑是什么?
- 我需要什么Java版本进行网页抓取项目?
- [我应该使用哪个库: Jsoup、HtmlUnit、Selenium还是HttpClient?](#我应该使用哪个库: Jsoup、HtmlUnit、Selenium还是HttpClient?)
- 我可以抓取使用JavaScript或动态加载内容的网站吗?
- 如何避免在抓取时被阻止?
- 存储抓取数据的最佳方式是什么?
- 当抓取器停止工作时如何调试?
前言
掌握Java网页抓取:技术与示例
网页抓取是自动化页面请求、解析HTML并从公共网站提取结构化数据的过程。虽然Python经常受到所有关注,但Java是专业网页抓取的有力竞争者,因为它可靠、快速,并且为规模而构建。其成熟的生态系统包括Jsoup、Selenium、Playwright和HttpClient等库,为您提供大规模网页抓取项目所需的控制和性能。
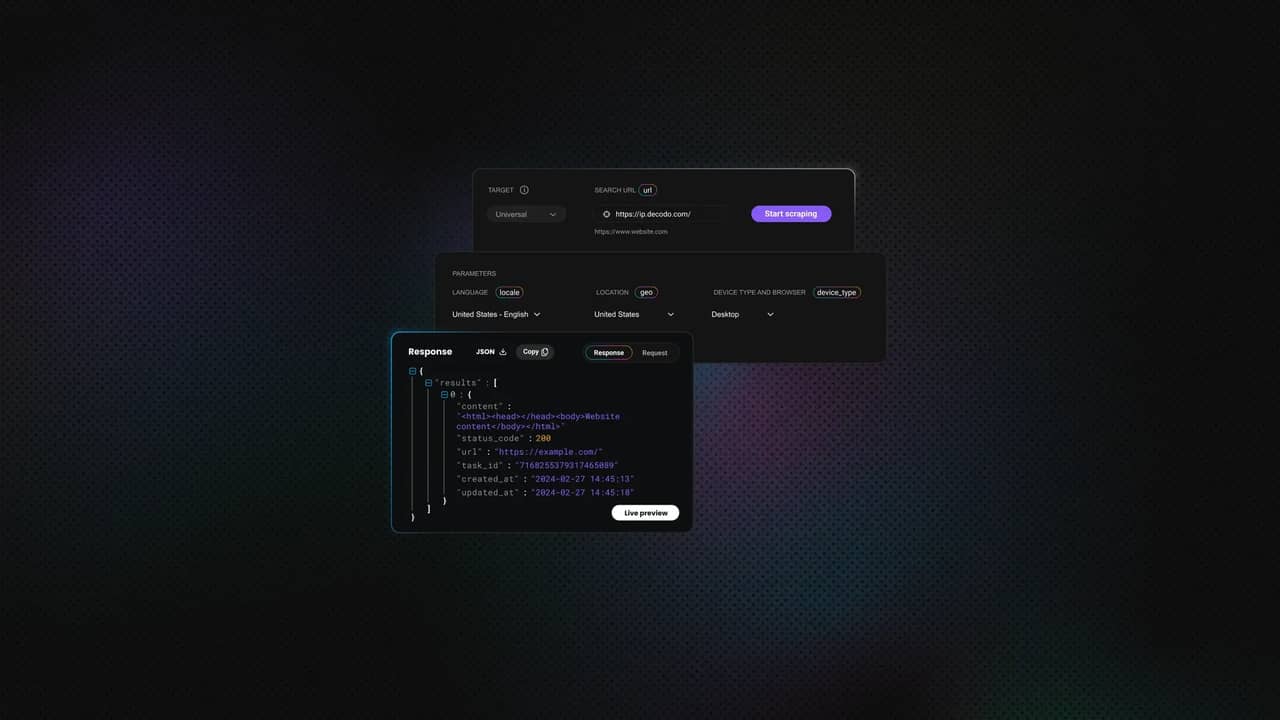
Java抓取的先决条件
在创建简单的Java网页抓取器之前,确保您的设置已准备就绪:
- 使用当前的Java LTS版本 -- 下载并安装Java 17、21或更新版本
- 使用IDE ,如IntelliJ IDEA(社区版免费)-- 它简化了开发并与构建工具集成
- 使用自动化构建工具 ,如Maven来管理Jsoup或Selenium等依赖项。使用安装指南在系统上获取Maven
- 理解HTML基础,这样您就可以定位要抓取的元素
- 理解CSS选择器和XPath -- 对于定位页面上的特定元素至关重要
有关更深入的设置说明和本博客文章中讨论的一些Java脚本,请访问此GitHub仓库。
Java网页抓取库概述
Java为您提供了多种从网络抓取数据的方法,正确的工具取决于您处理的内容类型。一些页面提供静态HTML,而其他页面依赖JavaScript动态加载数据。让我们简要了解何时使用每个库。
在尝试本指南中的任何示例之前,请确保设置了依赖项。您不需要手动下载这些库。如果您使用Maven,只需将依赖项块添加到pom.xml,Maven就会从Maven中央仓库为您将所有内容拉入项目。Gradle的工作方式相同。声明依赖项后,您的IDE会自动处理导入,下面的代码片段无需额外配置即可编译。此设置还使您可以轻松更新版本或在API更改时检查官方文档。
Jsoup
Jsoup轻量级,几乎像浏览器一样读取HTML。您只需几行代码就可以获取页面,然后使用熟悉的CSS选择器提取您需要的内容。
当目标页面在初始HTML响应中呈现所有数据时使用Jsoup。另一方面,它无法抓取严重依赖JavaScript生成内容的动态创建页面。
HtmlUnit
HtmlUnit是一个用Java编写的无头浏览器,可以模拟用户交互,如点击。它比Jsoup慢,但可以处理动态JavaScript内容,而无需运行完整的浏览器窗口。
它对于测试和简单的抓取任务很方便,在这些任务中您需要等待JavaScript运行。
Selenium
如果您需要对动态网站有更多控制,Selenium是下一步。它通过WebDriver控制真实浏览器(Chrome、Firefox或Edge)。这允许您抓取仅在类似用户的操作后出现的内容。您可以单击按钮、登录或滚动无限页面。
权衡是速度。Selenium功能强大,但资源密集。
Apache HttpClient/HttpComponents
对于专注于HTTP性能的项目,您可能更喜欢Apache HttpClient(HttpComponents)。这是一个用于发送请求、管理头、处理cookie和控制会话的工具。
在生产级系统中,开发人员通常将HttpClient与Jsoup配对,以便在获取和解析之间进行清晰的分离。
Playwright
Playwright for Java带来了高级API,用于比Selenium在某些情况下更快、更可靠地抓取JavaScript密集型网站。Microsoft维护它,它正在成为自动化和抓取的有力竞争者。
分步指南:使用Java进行基本网页抓取
让我们逐步构建一个简单的Java网页抓取器,并解释每个步骤,以便您可以直接将其放入项目中。
我们假设您已经满足所有先决条件,并使用Maven作为构建工具在IntelliJ IDEA中创建了Java项目。
添加依赖项
在开始构建抓取器之前,添加您将使用的库。对于解析HTML,您将使用Jsoup。对于导出结果到JSON,您将使用Gson。对于导出到CSV,您将使用OpenCSV。将以下内容添加到您的pom.xml文件:
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>decodo-web-scraper</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>21</maven.compiler.source>
<maven.compiler.target>21</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- Jsoup用于解析 -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.21.2</version>
</dependency>
<!-- Gson用于JSON导出 -->
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.13.2</version>
</dependency>
<!-- OpenCSV用于CSV导出(可选) -->
<dependency>
<groupId>com.opencsv</groupId>
<artifactId>opencsv</artifactId>
<version>5.7.1</version>
</dependency>
<!-- Playwright用于带代理的浏览器自动化 -->
<dependency>
<groupId>com.microsoft.playwright</groupId>
<artifactId>playwright</artifactId>
<version>1.45.0</version>
</dependency>
<!-- Selenium用于带代理的浏览器自动化 -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>4.25.0</version>
</dependency>
</dependencies>
</project>获取页面
您将从一个带有引用的简单占位符网站获取数据: https://quotes.toscrape.com。
首先,创建一个具有合理连接超时的可重用客户端。接下来,构建一个GET请求,该请求针对您想要抓取的网站,设置清晰的User-Agent(以及您需要的任何其他头),并定义请求方法。最后,发送请求并将响应主体捕获为字符串。该HTML落在您将在下一步解析的html变量中。
java
import java.net.http.*;
import java.net.*;
import java.time.Duration;
// 创建HTTP客户端
HttpClient client = HttpClient.newBuilder()
.connectTimeout(Duration.ofSeconds(10))
.build();
// 构建针对您想要抓取的网站的GET请求
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://quotes.toscrape.com/"))
.header("User-Agent", "Java/HttpClient")
.GET()
.build();
// 发送请求并将响应主体捕获为字符串
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
String html = response.body();使用Jsoup解析结果
在浏览器中检查页面。每个引用都位于一个类为quote的div中,内部有两个span: span.text保存引用文本,span.author保存作者。
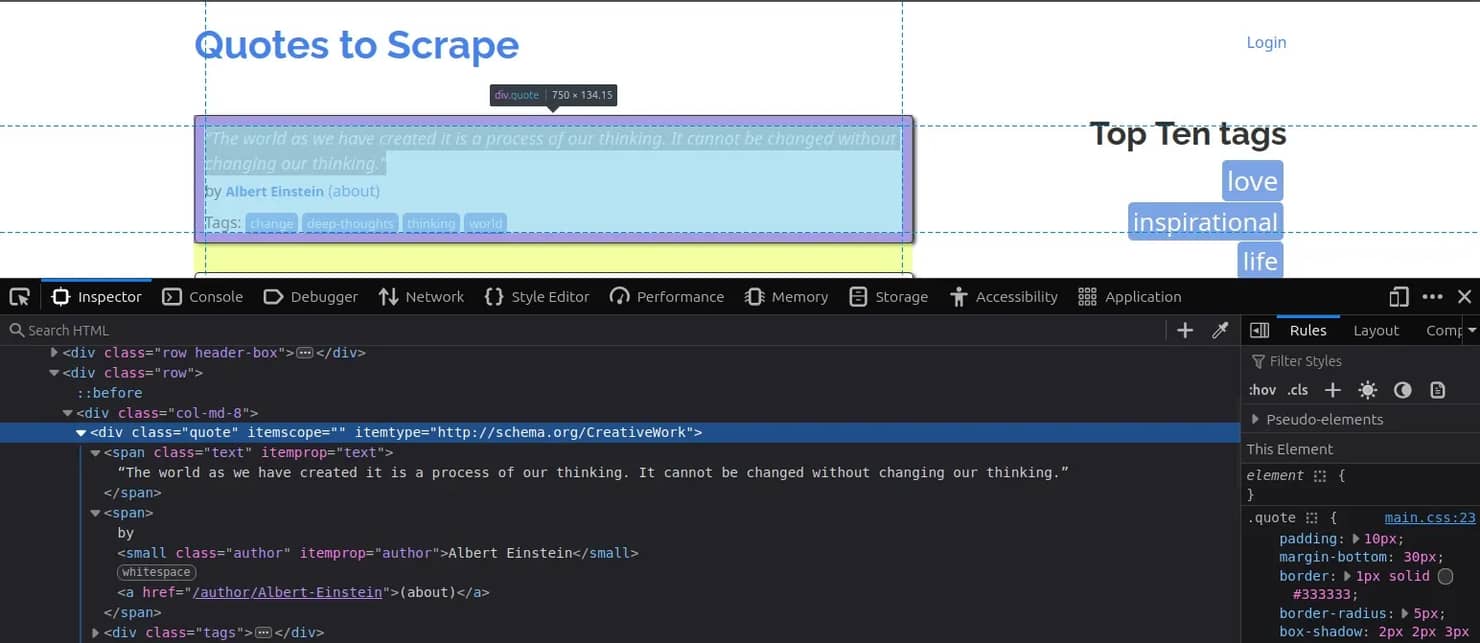
基于该结构,代码将获取的HTML解析为Jsoup Document,使用CSS选择器.quote选择所有引用块,然后对于每一个,读取.text和.author元素:
java
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
// 将获取的HTML解析为Jsoup Document
Document doc = Jsoup.parse(html, "https://quotes.toscrape.com");
// 使用CSS选择器选择所有引用块
Elements quotes = doc.select(".quote");
// 对于每个引用,读取.text和.author元素
for (Element quote : quotes) {
System.out.println("*** 引用:");
System.out.println(quote.selectFirst(".text").text());
System.out.println("- 作者: " + quote.selectFirst(".author").text());
}为了保持示例透明,此代码将引用和作者打印到标准输出,以便您可以验证选择器并准确查看程序正在提取的内容。
在下一节中,您将学习如何正确执行此操作,定义一个带有text和author字段的Quote类,并在遍历页面时构建Quote对象列表。
提取字段并映射到对象
创建一个小的Quote类来保存您抓取的两个字段(quoteText和quoteAuthor),包含通常的构造函数、getter和setter:
java
public class Quote {
private String quoteText;
private String quoteAuthor;
// 构造函数、getter、setter
}然后,不是在循环内打印,您将为每个匹配的元素实例化一个Quote并将其添加到List:
java
import java.util.ArrayList;
import java.util.List;
// ...
// 将获取的HTML解析为Jsoup Document
Document doc = Jsoup.parse(html, "https://quotes.toscrape.com");
// 使用CSS选择器选择所有引用块
Elements quotes = doc.select(".quote");
// 收集解析的引用
List<Quote> allQuotes = new ArrayList<>();
// 对于每个引用,读取.text和.author元素
for (Element quote : quotes) {
String quoteText = quote.selectFirst(".text").text();
String quoteAuthor = quote.selectFirst(".author").text();
// 将当前引用添加到所有引用列表
allQuotes.add(new Quote(quoteText, quoteAuthor));
}这为您提供了一个可以测试并稍后在管道中导出到JSON或XML的集合。
导出到JSON
以下是如何使用Gson将收集的List导出到JSON。此版本漂亮打印输出并将其写入quotes.json:
java
import com.google.gson.Gson;
import com.google.gson.GsonBuilder;
import java.nio.file.Files;
import java.nio.file.Path;
// ... 在您构建了List<Quote> allQuotes之后
Gson gson = new GsonBuilder()
.setPrettyPrinting()
.create();
String json = gson.toJson(allQuotes);
Files.writeString(Path.of("quotes.json"), json);
System.out.println("将 " + allQuotes.size() + " 条引用写入quotes.json");这将使用您抓取的数据写入一个新的quotes.json文件,以JSON结构存储。您还将看到一条控制台消息,确认导出成功并显示保存了多少项。
导出到CSV
以下是如何使用OpenCSV将List导出到CSV。这将写入标题行,然后每个引用一行:
java
import com.opencsv.CSVWriter;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.charset.StandardCharsets;
import java.io.Writer;
// ... 在您构建了List<Quote> allQuotes之后
Path out = Path.of("quotes.csv");
try (Writer w = Files.newBufferedWriter(out, StandardCharsets.UTF_8);
CSVWriter csv = new CSVWriter(w)) {
// 标题
csv.writeNext(new String[] { "quoteText", "quoteAuthor" });
// 行
for (Quote q : allQuotes) {
csv.writeNext(new String[] { q.getQuoteText(), q.getQuoteAuthor() });
}
}
System.out.println("将 " + allQuotes.size() + " 条引用写入quotes.csv");这将写入一个包含CSV结构中抓取引用的quotes.csv文件。您还将看到一条显示保存了多少项的控制台消息。
处理动态内容
当网站上的数据仅在JavaScript运行后加载时,您不能只使用HttpClient和Jsoup来抓取内容。您最终会得到空部分或缺失值,因为您获得的HTML不是用户在浏览器中看到的内容。
动态页面使用JavaScript异步请求数据,通常通过XHR或fetch()调用。要处理这个问题,Java中有两个主要策略: 像浏览器一样呈现页面或拦截底层网络请求。
对于完整渲染,使用Selenium。它控制真实浏览器并等待页面完全加载后再抓取。这是一个最小示例:
java
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
public class DynamicExample {
public static void main(String[] args) {
WebDriver driver = new ChromeDriver();
driver.get("https://example.com/quotes");
// 示例: 在数据出现之前点击按钮
WebElement button = driver.findElement(By.cssSelector(".load-more"));
button.click();
// 等待新元素加载(演示用简单睡眠)
try { Thread.sleep(2000); } catch (InterruptedException ignored) {}
System.out.println(driver.getPageSource());
driver.quit();
}
}对于生产使用,将睡眠调用替换为WebDriverWait或显式等待,以确保元素正确加载:
java
new WebDriverWait(driver, Duration.ofSeconds(5))
.until(ExpectedConditions.elementToBeClickable(By.cssSelector(".load-more")));如果您更愿意保持完全无头,HtmlUnit会模拟浏览器行为而不启动真实浏览器。它更轻、更快,尽管对现代JavaScript框架的准确性较低。
在某些情况下,您根本不需要浏览器。打开浏览器的DevTools并检查Network标签。您可能会发现网站从公共JSON端点获取数据。如果是这种情况,您可以直接使用HttpClient访问该端点,完全绕过渲染。这是一种优雅的方式,可以更快地抓取,同时使用更少的资源。
分页和网页爬取
分页是网站如何将大型数据集分布在多个页面上。大多数网站通过下一页按钮或可预测的URL结构实现分页,如?page=2或/page/3。
您可以通过浏览网站并观察URL栏来确认这一点。一旦您发现模式,就可以自动化它。在"Quotes to Scrape"网站的情况下,它使用page/3结构。
以下是使用Jsoup爬取多个页面直到没有更多结果出现的简单示例:
java
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class MainPagination {
public static void main(String[] args) throws Exception {
int page = 1;
boolean hasNext = true;
while (hasNext) {
String url = "https://quotes.toscrape.com/page/" + page;
Document doc = Jsoup.connect(url)
.userAgent("Mozilla/5.0 (compatible; JavaScraper/1.0)")
.timeout(10000)
.get();
Elements quotes = doc.select(".quote");
if (quotes.isEmpty()) break; // 没有更多产品时停止
// 打印页码和抓取的引用数量
System.out.println("页面 " + page + ": " + quotes.size() + " 项");
// 在这里提取和存储数据
page++;
// 小延迟有助于避免达到速率限制
Thread.sleep(1500);
}
}
}这种方法适用于静态或可预测的URL。对于动态分页,如无限滚动或加载更多按钮,您需要Selenium或Playwright来点击并等待新内容,如上一节所示。
注意: 构建抓取器时,避免重复数据。保留一个简单的内存中Set来存储已访问的URL或产品ID。如果您的爬虫扩展,将该检查移至数据库或键值存储(如Redis)。重复会浪费带宽和存储。
并行化和高效抓取
一个接一个地获取页面对于测试来说很好,但是当您处理数百或数千个URL时,您会希望并行化您的请求。Java为此提供了出色的工具!
ExecutorService是Java的内置线程池管理器。它允许您并行运行多个抓取任务,每个任务获取和解析单独的页面。固定大小的线程池(比如5或10个线程)平衡速度和系统稳定性。这是一个基本示例:
java
import java.net.http.*;
import java.net.*;
import java.util.*;
import java.util.concurrent.*;
public class ParallelScraper {
public static void main(String[] args) throws Exception {
List<String> urls = List.of(
"https://quotes.toscrape.com/page/1",
"https://quotes.toscrape.com/page/2",
"https://quotes.toscrape.com/page/3"
);
HttpClient client = HttpClient.newHttpClient();
ExecutorService executor = Executors.newFixedThreadPool(5);
for (String url : urls) {
executor.submit(() -> {
try {
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(url))
.header("User-Agent", "JavaScraper/1.0")
.GET()
.build();
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
System.out.println(url + " - " + response.statusCode());
} catch (Exception e) {
System.err.println("获取 " + url + " 时出错: " + e.getMessage());
}
});
}
executor.shutdown();
executor.awaitTermination(1, TimeUnit.MINUTES);
}
}仅此模式就可以大大缩短您的抓取时间。但您不必止步于此。
从Java 19开始,虚拟线程(Project Loom的一部分)使并发更加轻量。每个任务几乎像协程一样运行,这允许您生成数千个线程而不会达到内存限制。官方JEP 425文档解释了虚拟线程如何简化像抓取这样的I/O密集型工作负载。
为什么代理在网页抓取中很重要
代理帮助您的抓取器表现得像正常用户,而不是单一的可重复模式。它们在多个IP上分散您的流量,降低任何一个端点的压力,并减少临时阻止的机会。
它们还解锁区域内容差异,这在定价、产品可用性和排名数据中很常见。
如果您的工作流程依赖于多步骤流程(过滤、分页、添加参数),会话粘性代理为您提供稳定的行为。通过每个会话背后一致的IP,您的抓取器避免了断开的序列和不匹配的结果。
Decodo提供115M+动态住宅代理,成功率99.86%,平均响应时间低于0.6秒,并提供3天免费试用。以下是入门方法:
- 在Decodo仪表板上创建帐户
- 在左侧面板上,选择住宅代理
- 选择订阅、按需付费计划或申请3天免费试用
- 在代理设置标签中,配置您的位置和会话偏好
- 复制您的代理凭据以集成到抓取脚本中
在Java网页抓取中使用代理
随着Java抓取器的增长,您最终会达到一个点,流量模式开始比您编写的代码更重要。从单个IP发送每个请求适用于小型测试,但它很快成为大规模的瓶颈。代理通过不同的IP路由您的流量来解决这个问题,使您的抓取器更稳定。
Java在其标准HTTP(S)堆栈和更高级别的库中干净地集成代理。您不必重写抓取器来使用它们。您只需定义一次代理,让HTTP客户端或浏览器自动化库处理其余部分。
Selenium WebDriver与代理
Selenium允许您通过代理路由整个浏览器会话,这对于依赖JavaScript或类似用户交互的页面很有帮助。不要忘记用您自己的身份验证凭据替换占位符值:
java
package org.example;
import org.openqa.selenium.Proxy;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
public class SeleniumProxyTest {
public static void main(String[] args) {
// 使用username:password@host:port的代理
String proxyUser = "YOUR_PROXY_USERNAME";
String proxyPass = "YOUR_PROXY_PASSWORD";
String proxyHost = "gate.decodo.com";
int proxyPort = 7000;
String proxyWithAuth = proxyUser + ":" + proxyPass + "@" + proxyHost + ":" + proxyPort;
Proxy seleniumProxy = new Proxy();
seleniumProxy.setProxyType(Proxy.ProxyType.MANUAL);
seleniumProxy.setHttpProxy(proxyWithAuth);
seleniumProxy.setSslProxy(proxyWithAuth);
ChromeOptions options = new ChromeOptions();
options.setProxy(seleniumProxy);
// 可选 -- 避免一些SSL/代理问题
options.addArguments("--ignore-certificate-errors");
WebDriver driver = new ChromeDriver(options);
try {
driver.get("https://quotes.toscrape.com");
System.out.println(driver.getPageSource());
} finally {
driver.quit();
}
}
}浏览器通过代理加载网站,打印的HTML与从代理角度看到的页面匹配。
Playwright for Java与代理
Playwright在浏览器启动时公开代理路由。在占位符值处插入您的代理用户名和密码:
java
package org.example;
import com.microsoft.playwright.*;
import com.microsoft.playwright.options.Proxy;
public class PlaywrightTest {
public static void main(String[] args) {
Proxy proxy = new Proxy("http://gate.decodo.com:7000")
.setUsername("YOUR_PROXY_USERNAME")
.setPassword("YOUR_PROXY_PASSWORD");
try (Playwright playwright = Playwright.create()) {
Browser browser = playwright.chromium().launch(
new BrowserType.LaunchOptions()
.setHeadless(true)
.setProxy(proxy)
);
Page page = browser.newPage();
page.navigate("https://quotes.toscrape.com");
System.out.println(page.content());
browser.close();
}
}
}这将整个浏览器会话通过代理路由。控制台中打印的HTML反映了从该代理位置呈现的内容。
反抓取措施及应对方法
当您的抓取器扩展时,您可能会遇到试图阻止您的网站防御机制。将它们视为您可能做错事的信号。从最轻的修复开始,仅在需要时升级。
轮换User-Agent并设置真实的头
许多基本过滤器取决于相同的头。轮换一小批现代User-Agent,并添加Accept-Language、Referer和Accept来模拟真实流量。保持池短和合理,随机字符串看起来是假的。
管理cookie和会话
一些网站期望有状态客户端。跨请求持久化cookie并重用同一客户端,以便您的会话看起来一致。当您看到突然重定向到登录或同意页面时添加退避。
尊重robots.txt和网站条款
让robots.txt和速率限制规则指导您。仅爬取您需要的路径,在可能的情况下缓存响应,并限制每个主机的并发性。以稳定的速度发送请求。目标是每个站点每秒1-3个请求,添加小的随机延迟(大约500-1500毫秒),并密切关注错误率。
使用明确的升级路径处理CAPTCHA
403响应代码或标题为"Just a moment..."的页面激增通常表示机器人检查。
首先,放慢速度并改善头的真实性。如果挑战持续存在,切换到真实浏览器(Selenium或Playwright for Java)并使用显式等待。只有在那之后才考虑第三方CAPTCHA解决服务。
使用代理和IP轮换
当阻止是基于IP的或跨区域扩展时轮换IP。将轮换与会话粘性配对以保持购物车、过滤器或分页稳定。但是,如果您的行为或指纹看起来是自动化的,仅靠代理轮换无济于事。
存储和处理抓取的数据
真正的网页抓取价值来自于您如何存储和处理结果:
- 保存到文件. 对于小型作业,为表格评论写入CSV,当记录变化或将馈送API/NoSQL时写入JSON
- 规模增长时使用数据库 . 如果您的架构清晰,移至MySQL/PostgreSQL。当结构变化或搜索很重要时选择MongoDB/Elasticsearch。使用JDBC批量插入,并设计唯一键,以便更新插入避免重复
- 清理和规范化. 修剪空白,标准化单位和货币,并在存储前验证必填字段。删除明显损坏的行
- 处理和分析. 从Java Streams开始进行快速聚合。对于较大的管道,安排批处理作业,并在数量激增时考虑Spark或Kafka Streams
故障排除和调试
即使是最干净的抓取器最终也会崩溃,网站更改布局、添加新的反机器人机制或限制请求。以下是常见问题领域和如何克服它们的实用技巧。
检查HTTP响应
在假设解析代码错误之前检查您的抓取器收到的响应。如果您突然获得空数据,记录HTTP状态码和响应主体的前几百个字符:
- 403或429. 您可能被阻止或速率限制。尝试添加头、轮换IP或添加延迟
- 301或302. 网站添加了重定向。检查登录页面或新URL
- 200但内容为空. 页面可能是动态呈现的。使用Selenium或Playwright
记录重要事件
为关键事件添加结构化日志 -- 请求URL、响应时间和解析的项目数量。使用轻量级日志库,如SLF4J与Logback。避免记录完整的HTML,除非调试特定问题(它可能会减慢您的抓取器并使日志混乱)。
检查选择器和页面结构
当解析突然失败时,验证页面的HTML结构是否没有更改。在浏览器中加载目标页面,右键单击检查,并确认您的CSS选择器或XPath表达式仍然匹配。
模拟真实浏览器
如果您一直收到空白或部分页面,网站可能需要JavaScript渲染。在无头浏览器中运行相同的URL以确认:
java
WebDriver driver = new ChromeDriver();
driver.get("https://example.com/");
System.out.println(driver.getPageSource());
driver.quit();如果Selenium返回完整的HTML而Jsoup没有,问题不是您的代码,而是渲染方法。
处理异常
意外错误不应该使您的抓取器崩溃。将解析逻辑和网络调用包装在try/catch块中,并使用上下文记录失败:
java
try {
scrapePage(url);
} catch (IOException e) {
logger.warn("获取 {} 时出现网络问题", url, e);
} catch (Exception e) {
logger.error("{} 处出现意外错误", url, e);
}您可以使用指数退避重试失败的请求,或存储它们以供以后重新处理。
设置警报和健康检查
对于生产抓取器,添加基本警报系统:
- 跟踪成功率和平均抓取时间
- 如果提取的项目数量急剧下降,发送通知
- 保留历史日志以识别何时以及为什么某事开始失败
Java网页抓取的最佳实践
专业抓取意味着构建尊重网络同时保持可靠的系统。以下是进行网页抓取时要记住的一些事项。
保持在道德界限内
仅抓取对普通用户清晰可见的公开数据,并始终检查网站的robots.txt以获取有关不抓取内容的指导。如果您的目标有官方公共API,请尝试一下。此外,避免绕过登录、付费墙或任何其他访问控制机制。
最小化服务器负载并成为负责任的抓取器
不要用请求淹没网站:
- 每个主机保持每秒1-3个请求的稳定速度
- 添加小的随机延迟,并使用持久HttpClient重用连接以保持高效而不会压垮服务器
- 在可能的情况下缓存结果,智能重试,并使用包含联系方式的描述性User-Agent标识您的抓取器
考虑长期性,而非数量
您的目标应该是随着时间收集一致、高质量的数据。这样,您将获得更少的阻止、更干净的数据以及可以安全扩展的更强大的基础设施。
高级技巧和资源
一旦您的抓取器稳定,您就可以开始优化性能和灵活性。这些是专业数据团队用来保持管道高效和弹性的相同策略。
使用无头浏览器
当页面严重依赖JavaScript时,使用Selenium或Playwright for Java来渲染和提取数据。两者都可以在无头模式下运行,这意味着浏览器在没有可见窗口的情况下运行(对于自动化更快、更高效)。
Playwright的异步API和内置等待机制通常使其对于大规模项目更流畅。
请参阅Playwright for Java文档和Selenium WebDriver指南以进行设置和性能调整。
集成第三方API或服务
对于大量或复杂的抓取,处理IP轮换、CAPTCHA解决和JavaScript渲染的API可以为您节省大量工程时间。它们简化了扩展,您调用单个端点并获得清理、结构化的数据。这种方法让您的团队专注于业务逻辑而不是基础设施。
使用Decodo的网页抓取API,您无需担心代理集成、JavaScript渲染或速率限制。它允许您指定目标URL并以HTML、JSON、CSV或Markdown等格式返回数据。
进一步阅读
为您的主要工具添加书签官方文档:
- Jsoup文档 -- 解析和选择器
- Java HttpClient API文档 -- 高级网络选项
- Gson文档 -- JSON序列化
- OpenCSV文档 -- CSV导出
要获得更深入的见解,请探索开源抓取器的GitHub仓库,或加入开发者论坛,如Stack Overflow和Reddit的r/webscraping。您看到的现实世界示例越多,您对什么在生产中扩展以及什么会崩溃的感觉就越好。
总结
使用Java,您现在拥有了完整的抓取工具包: 用于获取的HttpClient,用于解析的Jsoup,用于动态页面的Selenium和Playwright,以及用于清理导出的Gson/OpenCSV。这种组合涵盖静态网站、复杂交互、代理和结构化数据输出。
接下来是完善。您可以使用并行抓取进行扩展,添加分页,跨类似网站重用提取器,或自动化计划运行。根据每个项目定制这些构建块是将基本抓取器转变为快速、可靠的Java管道的关键。
常见问题解答
网页抓取合法吗,道德考虑是什么?
网页抓取的合法性通常取决于您收集的数据以及如何使用它。始终坚持公开信息,尊重robots.txt,并避免对网站施加不必要的负载。
我需要什么Java版本进行网页抓取项目?
坚持使用Java长期支持(LTS)版本。它们稳定、受到广泛支持,并与大多数现代库兼容。
我应该使用哪个库: Jsoup、HtmlUnit、Selenium还是HttpClient?
- 对于静态HTML页面,使用Jsoup -- 它快速而简单
- 对于依赖JavaScript的页面,使用Selenium、Playwright或HtmlUnit -- 它们可以渲染和抓取动态内容
- 如果您只需要发送HTTP请求并处理响应,HttpClient是轻量级的,非常适合
我可以抓取使用JavaScript或动态加载内容的网站吗?
是的,您可以。静态抓取器无法捕获该数据,但像Selenium或Playwright for Java这样的工具可以。它们模拟真实浏览器,执行JavaScript,并让您提取传统解析器遗漏的内容。
如何避免在抓取时被阻止?
保持合理的请求速率,轮换User-Agent头,如果您发出大量请求,请使用代理池。在请求之间添加随机延迟也有帮助。对于高频作业,考虑使用托管的网页抓取API -- 它自动处理IP轮换和会话管理。
存储抓取数据的最佳方式是什么?
对于小型数据集,写入CSV或JSON文件。对于较大的项目,使用JDBC将结果存储在数据库中,以便轻松查询和分析。
当抓取器停止工作时如何调试?
首先检查响应代码 -- 403或429通常意味着您的抓取器被阻止或速率限制。记录您的请求、头和响应以发现更改的内容。使用浏览器开发工具检查页面结构还可以揭示网站布局或脚本是否已更新。