Pandas是Python第三方库,提供高性能易用数据类型和分析工具
import pandas as pd
Pandas库的Series类型
Series类型由一组数据及与之相关的数据索引组成

python
import pandas as pd
a = pd.Series([9,8,7,6])
print(a)
#执行结果
0 9
1 8
2 7
3 6
dtype: int64
#int64:Numpy中的数据类型 结果中第一列:自动索引
python
import pandas as pd
a = pd.Series([9,8,7,6],index=['a','b','c','d']) #index参数,可以自定义索引,可以省略
print(a)
#执行结果
a 9
b 8
c 7
d 6
dtype: int64Series类型创建
Series类型可以由如下类型创建:
- Python列表
- 标量值
- Python字典
- ndarray
- 其他函数
1、从标量值创建
python
import pandas as pd
s = pd.Series(25,index=['a','b','c']) #index参数不能省略
print(s)
#执行结果
a 25
b 25
c 25
dtype: int642、从字典类型创建
python
import pandas as pd
s = pd.Series({'a':9,'b':8,'c':7})
print(s)
#执行结果
a 9
b 8
c 7
dtype: int64
#重新调整创建语句,index从字典中进行选择
s = pd.Series({'a':9,'b':8,'c':7},index=['c','a','b','d'])
#执行结果
c 7.0
a 9.0
b 8.0
d NaN
dtype: float643、从ndarray类型创建
python
import pandas as pd
import numpy as np
n = pd.Series(np.arange(5))
print(n)
#执行结果
0 0
1 1
2 2
3 3
4 4
dtype: int64
#重新调整创建语句
n = pd.Series(np.arange(5),index=np.arange(9,4,-1))
#执行结果
9 0
8 1
7 2
6 3
5 4
dtype: int64Series类型的基本操作
Series类型包括index和values两部分。Series类型的操作类似ndarray类型和Python字典类型。
python
import pandas as pd
n = pd.Series([9,8,7,6],index=['a','b','c','d'])
print(n)
print(n.index)
print(n.values)
print(n['b'])
print(n[1])
print(n[['c','b','a']])
print(n[['a','b',0]]) #此行代码会报错
#执行结果
a 9
b 8
c 7
d 6
dtype: int64
Index(['a', 'b', 'c', 'd'], dtype='object')
[9 8 7 6]
8
8
c 7
b 8
a 9
dtype: int64
#总结
# .index 获得索引 .values 获得数据
#自动索引和自定义索引并存
#两套索引并存,但不能混用Series类型的操作类似ndarray类型:
- 索引方法相同,采用\[\]
- NumPy中运算和操作可用于Series类型
- 可以通过自定义索引的列表进行切片
- 可以通过自动索引进行切片,如果存在自定义索引,则一同被切片
python
import pandas as pd
import numpy as np
n = pd.Series([9,8,7,6],index=['a','b','c','d'])
print(n)
print(n[:3])
print(n[n>n.median()])
print(np.exp(n))
#执行结果
a 9
b 8
c 7
d 6
dtype: int64
a 9
b 8
c 7
dtype: int64
a 9
b 8
dtype: int64
a 8103.083928
b 2980.957987
c 1096.633158
d 403.428793
dtype: float64Series类型的操作类似Python字典类型:
- 通过自定义索引访问
- 保留字in操作
- 使用.get()方法
python
import pandas as pd
n = pd.Series([9,8,7,6],index=['a','b','c','d'])
print(n['b'])
print('c' in n)
print(0 in n)
print(n.get('f',100))
#执行结果
8
True
False
100Series类型对齐操作
Series+Series
python
import pandas as pd
a = pd.Series([1,2,3],index=['c','d','e'])
b = pd.Series([9,8,7,6],['a','b','c','d'])
print(a+b)
#执行结果
a NaN
b NaN
c 8.0
d 8.0
e NaN
dtype: float64Series类型在运算中会自动对齐不同索引的数据
Series类型的name属性
Series对象和索引都可以有一个名字,存储在属性.name中
python
import pandas as pd
b = pd.Series([9,8,7,6],['a','b','c','d'])
print(b.name)
b.name = 'Series对象'
b.index.name = '索引列'
print(b)
#执行结果
None
索引列
a 9
b 8
c 7
d 6
Name: Series对象, dtype: int64Series类型的修改
Series对象可以随时修改并即刻生效
python
import pandas as pd
b = pd.Series([9,8,7,6],['a','b','c','d'])
b['a'] = 15
b.name = "Series"
print(b)
b.name = "New Series"
b[['b','c']] = 20
print(b)
#执行结果
a 15
b 8
c 7
d 6
Name: Series, dtype: int64
a 15
b 20
c 20
d 6
Name: New Series, dtype: int64Series类型:
Series是一维带"标签"数组
index_0-->data_a
Series基本操作类似ndarray和字典,根据索引对齐
Pandas库的DataFrame类型
DataFrame类型由共用相同索引的一组列组成


DataFrame是一个表格型的数据类型,每列值类型可以不同
DataFrame既有行索引、也有列索引
DataFrame常用于表达二维数据,但可以表达多维数据
DataFrame类型创建
DataFrame类型可以由如下类型创建:
- 二维ndarray对象
- 由一维ndarray、列表、字典、元组或Series构成的字典
- Series类型
- 其他的DataFrame类型
1、从二维ndarray对象创建
python
import pandas as pd
import numpy as np
d = pd.DataFrame(np.arange(10).reshape(2,5))
print(d)
#执行结果
0 1 2 3 4 #这一行是自动列索引
0 0 1 2 3 4
1 5 6 7 8 9
#
这
一
列
是
自
动
行
索
引 2、从一维ndarray对象字典创建
python
import pandas as pd
dt = {'one':pd.Series([1,2,3],['a','b','c']),
'two':pd.Series([9,8,7,6],['a','b','c','d'])}
d = pd.DataFrame(dt)
print(d)
s = pd.DataFrame(dt,index=['b','c','d'],columns=['two','three'])
print(s)
#执行结果
one two
a 1.0 9
b 2.0 8
c 3.0 7
d NaN 6
two three
b 8 NaN
c 7 NaN
d 6 NaN #数据根据行列索引自动补齐3、从列表类型的字典创建
python
import pandas as pd
dl = {'one':[1,2,3,4],'two':[9,8,7,6]}
d = pd.DataFrame(dl,index=['a','b','c','d'])
print(d)
#执行结果
one two
a 1 9
b 2 8
c 3 7
d 4 6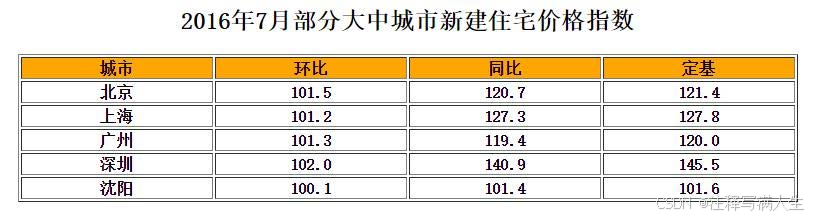
创建上述表格的数据
python
import pandas as pd
dl = {'城市':['北京','上海','广州','深圳','沈阳'],
'环比':[101.5,101.2,101.3,102.0,100.1],
'同比':[120.7,127.3,119.4,140.9,101.4],
'定基':[121.4,127.8,120.0,145.5,101.6]}
d = pd.DataFrame(dl,index=['c1','c2','c3','c4','c5'])
print(d)
print(d.index)
print(d.columns)
print(d.values)
print(d['同比'])
#print(d.ix['c2']) ix在新版本的pandas里已备废弃,开始用loc、iloc
print(d.loc["c2"])
print(d['同比']['c2'])
#执行结果
城市 环比 同比 定基
c1 北京 101.5 120.7 121.4
c2 上海 101.2 127.3 127.8
c3 广州 101.3 119.4 120.0
c4 深圳 102.0 140.9 145.5
c5 沈阳 100.1 101.4 101.6
Index(['c1', 'c2', 'c3', 'c4', 'c5'], dtype='object')
Index(['城市', '环比', '同比', '定基'], dtype='object')
[['北京' 101.5 120.7 121.4]
['上海' 101.2 127.3 127.8]
['广州' 101.3 119.4 120.0]
['深圳' 102.0 140.9 145.5]
['沈阳' 100.1 101.4 101.6]]
c1 120.7
c2 127.3
c3 119.4
c4 140.9
c5 101.4
Name: 同比, dtype: float64
城市 上海
环比 101.2
同比 127.3
定基 127.8
Name: c2, dtype: object
127.3DataFrame是二维带"标签"数组

DataFrame基本操作类似Series,依据行列索引
数据类型操作
如何改变Series和DataFrame对象?
增加或重排:重新索引、删除:drop
重新索引
.reindex()能够改变或重排Series和DataFrame索引
python
import pandas as pd
dl = {'城市':['北京','上海','广州','深圳','沈阳'],
'环比':[101.5,101.2,101.3,102.0,100.1],
'同比':[120.7,127.3,119.4,140.9,101.4],
'定基':[121.4,127.8,120.0,145.5,101.6]}
d = pd.DataFrame(dl,index=['c1','c2','c3','c4','c5'])
print(d)
d = d.reindex(index=['c5','c4','c3','c2','c1'])
print(d)
d = d.reindex(columns=['城市','同比','环比','定基'])
print(d)
#执行结果
城市 环比 同比 定基
c1 北京 101.5 120.7 121.4
c2 上海 101.2 127.3 127.8
c3 广州 101.3 119.4 120.0
c4 深圳 102.0 140.9 145.5
c5 沈阳 100.1 101.4 101.6
城市 环比 同比 定基
c5 沈阳 100.1 101.4 101.6
c4 深圳 102.0 140.9 145.5
c3 广州 101.3 119.4 120.0
c2 上海 101.2 127.3 127.8
c1 北京 101.5 120.7 121.4
城市 同比 环比 定基
c5 沈阳 101.4 100.1 101.6
c4 深圳 140.9 102.0 145.5
c3 广州 119.4 101.3 120.0
c2 上海 127.3 101.2 127.8
c1 北京 120.7 101.5 121.4.reindex(index=None, columns=None, ...)的参数
| 参数 | 说明 |
|---|---|
| index,columns | 新的行列自定义索引 |
| fill_value | 重新索引中,用于填充缺失位置的值 |
| method | 填充方法, ffill当前值向前填充,bfill向后填充 |
| limit | 最大填充量 |
| copy | 默认True,生成新的对象,False时,新旧相等不复制 |
python
import pandas as pd
dl = {'城市':['北京','上海','广州','深圳','沈阳'],
'环比':[101.5,101.2,101.3,102.0,100.1],
'同比':[120.7,127.3,119.4,140.9,101.4],
'定基':[121.4,127.8,120.0,145.5,101.6]}
d = pd.DataFrame(dl,index=['c1','c2','c3','c4','c5'])
d = d.reindex(index=['c5','c4','c3','c2','c1'])
print(d)
d = d.reindex(columns=['城市','同比','环比','定基'])
print(d)
newc = d.columns.insert(4,'新增')
newd = d.reindex(columns=newc,fill_value=200)
print(newd)
print(d.index)
print(d.columns)
#执行结果
城市 环比 同比 定基
c5 沈阳 100.1 101.4 101.6
c4 深圳 102.0 140.9 145.5
c3 广州 101.3 119.4 120.0
c2 上海 101.2 127.3 127.8
c1 北京 101.5 120.7 121.4
城市 同比 环比 定基
c5 沈阳 101.4 100.1 101.6
c4 深圳 140.9 102.0 145.5
c3 广州 119.4 101.3 120.0
c2 上海 127.3 101.2 127.8
c1 北京 120.7 101.5 121.4
城市 同比 环比 定基 新增
c5 沈阳 101.4 100.1 101.6 200
c4 深圳 140.9 102.0 145.5 200
c3 广州 119.4 101.3 120.0 200
c2 上海 127.3 101.2 127.8 200
c1 北京 120.7 101.5 121.4 200
Index(['c5', 'c4', 'c3', 'c2', 'c1'], dtype='object')
Index(['城市', '同比', '环比', '定基'], dtype='object')
#Series和DataFrame的索引是Index类型,Index对象是不可修改类型索引类型的常用方法
| 方法 | 说明 |
|---|---|
| .append(idx) | 连接另一个Index对象,产生新的Index对象 |
| .diff(idx) | 计算差集,产生新的Index对象 |
| .intersection(idx) | 计算交集 |
| .union(idx) | 计算并集 |
| .delete(loc) | 删除loc位置处的元素 |
| .insert(loc,e) | 在loc位置增加一个元素e |
python
import pandas as pd
dl = {'城市':['北京','上海','广州','深圳','沈阳'],
'环比':[101.5,101.2,101.3,102.0,100.1],
'同比':[120.7,127.3,119.4,140.9,101.4],
'定基':[121.4,127.8,120.0,145.5,101.6]}
d = pd.DataFrame(dl,index=['c1','c2','c3','c4','c5'])
nc = d.columns.delete(2)
ni = d.index.insert(5,'c0')
nd = d.reindex(index=ni,columns=nc).ffill()
print(nd)
#执行结果
城市 环比 定基
c1 北京 101.5 121.4
c2 上海 101.2 127.8
c3 广州 101.3 120.0
c4 深圳 102.0 145.5
c5 沈阳 100.1 101.6
c0 沈阳 100.1 101.6删除指定索引对象
python
import pandas as pd
dl = {'城市':['北京','上海','广州','深圳','沈阳'],
'环比':[101.5,101.2,101.3,102.0,100.1],
'同比':[120.7,127.3,119.4,140.9,101.4],
'定基':[121.4,127.8,120.0,145.5,101.6]}
d = pd.DataFrame(dl,index=['c1','c2','c3','c4','c5'])
print(d)
a = d.drop('c5')
print(a)
b = d.drop('同比',axis = 1)
print(b)
#执行结果
城市 环比 同比 定基
c1 北京 101.5 120.7 121.4
c2 上海 101.2 127.3 127.8
c3 广州 101.3 119.4 120.0
c4 深圳 102.0 140.9 145.5
c5 沈阳 100.1 101.4 101.6
城市 环比 同比 定基
c1 北京 101.5 120.7 121.4
c2 上海 101.2 127.3 127.8
c3 广州 101.3 119.4 120.0
c4 深圳 102.0 140.9 145.5
城市 环比 定基
c1 北京 101.5 121.4
c2 上海 101.2 127.8
c3 广州 101.3 120.0
c4 深圳 102.0 145.5
c5 沈阳 100.1 101.6Pandas库的数据类型运算
算术运算法则
算术运算根据行列索引,补齐后运算,运算默认产生浮点数
补齐时缺项填充NaN (空值)
二维和一维、一维和零维间为广播运算
采用+ ‐ * /符号进行的二元运算产生新的对象
python
import pandas as pd
import numpy as np
a = pd.DataFrame(np.arange(12).reshape(3,4))
print(a)
b = pd.DataFrame(np.arange(20).reshape(4,5))
print(b)
print(a+b)
print(a*b)
#执行结果
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
0 1 2 3 4
0 0 1 2 3 4
1 5 6 7 8 9
2 10 11 12 13 14
3 15 16 17 18 19
0 1 2 3 4
0 0.0 2.0 4.0 6.0 NaN
1 9.0 11.0 13.0 15.0 NaN
2 18.0 20.0 22.0 24.0 NaN
3 NaN NaN NaN NaN NaN
0 1 2 3 4
0 0.0 1.0 4.0 9.0 NaN
1 20.0 30.0 42.0 56.0 NaN
2 80.0 99.0 120.0 143.0 NaN
3 NaN NaN NaN NaN NaN方法形式的运算
| 方法 | 说明 |
|---|---|
| .add(d, **argws) | 类型间加法运算,可选参数 |
| .sub(d, **argws) | 类型间减法运算,可选参数 |
| .mul(d, **argws) | 类型间乘法运算,可选参数 |
| .div(d, **argws) | 类型间除法运算,可选参数 |
python
import pandas as pd
import numpy as np
a = pd.DataFrame(np.arange(12).reshape(3,4))
print(a)
b = pd.DataFrame(np.arange(20).reshape(4,5))
print(b)
print(b.add(a,fill_value=100))
print(b.mul(a,fill_value=0))
#fill_value参数替代NaN,替代后参与运算
c = pd.DataFrame(np.arange(20).reshape(4,5))
print(c)
d = pd.Series(np.arange(4))
print(c - 10)
print(c - d)
#不同维度间为广播运算,一维Series默认在轴1参与运算
print(c.sub(d,axis=0))
#使用运算方法可以令一维Series参与轴0运算
#执行结果
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
0 1 2 3 4
0 0 1 2 3 4
1 5 6 7 8 9
2 10 11 12 13 14
3 15 16 17 18 19
0 1 2 3 4
0 0.0 2.0 4.0 6.0 104.0
1 9.0 11.0 13.0 15.0 109.0
2 18.0 20.0 22.0 24.0 114.0
3 115.0 116.0 117.0 118.0 119.0
0 1 2 3 4
0 0.0 1.0 4.0 9.0 0.0
1 20.0 30.0 42.0 56.0 0.0
2 80.0 99.0 120.0 143.0 0.0
3 0.0 0.0 0.0 0.0 0.0
0 1 2 3 4
0 0 1 2 3 4
1 5 6 7 8 9
2 10 11 12 13 14
3 15 16 17 18 19
0 1 2 3 4
0 -10 -9 -8 -7 -6
1 -5 -4 -3 -2 -1
2 0 1 2 3 4
3 5 6 7 8 9
0 1 2 3 4
0 0.0 0.0 0.0 0.0 NaN
1 5.0 5.0 5.0 5.0 NaN
2 10.0 10.0 10.0 10.0 NaN
3 15.0 15.0 15.0 15.0 NaN
0 1 2 3 4
0 0 1 2 3 4
1 4 5 6 7 8
2 8 9 10 11 12
3 12 13 14 15 16比较运算法则
比较运算只能比较相同索引的元素,不进行补齐
二维和一维、一维和零维间为广播运算
采用> < >= <= == !=等符号进行的二元运算产生布尔对象
python
import pandas as pd
import numpy as np
a = pd.DataFrame(np.arange(12).reshape(3,4))
print(a)
b = pd.DataFrame(np.arange(12,0,-1).reshape(3,4))
print(b)
print(a > b)
print(a == b)
#同维度运算,尺寸一致
c = pd.DataFrame(np.arange(12).reshape(3,4))
print(c)
d = pd.Series(np.arange(4))
print(d)
print(c > d)
print(d > 0)
#不同维度,广播运算,默认在1轴
#执行结果
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
0 1 2 3
0 12 11 10 9
1 8 7 6 5
2 4 3 2 1
0 1 2 3
0 False False False False
1 False False False True
2 True True True True
0 1 2 3
0 False False False False
1 False False True False
2 False False False False
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
0 0
1 1
2 2
3 3
dtype: int64
0 1 2 3
0 False False False False
1 True True True True
2 True True True True
0 False
1 True
2 True
3 True
dtype: boolPandas数据特征分析
数据排序
.sort_index()方法在指定轴上根据索引进行排序,默认升序
.sort_index(axis=0, ascending=True)
python
import pandas as pd
import numpy as np
a = pd.DataFrame(np.arange(20).reshape(4,5),index=['c','a','d','b'])
print(a)
print(a.sort_index())
b = a.sort_index(axis=1,ascending=False)
print(b)
print(b.sort_index())
#执行结果
0 1 2 3 4
c 0 1 2 3 4
a 5 6 7 8 9
d 10 11 12 13 14
b 15 16 17 18 19
0 1 2 3 4
a 5 6 7 8 9
b 15 16 17 18 19
c 0 1 2 3 4
d 10 11 12 13 14
4 3 2 1 0
c 4 3 2 1 0
a 9 8 7 6 5
d 14 13 12 11 10
b 19 18 17 16 15
4 3 2 1 0
a 9 8 7 6 5
b 19 18 17 16 15
c 4 3 2 1 0
d 14 13 12 11 10.sort_values()方法在指定轴上根据数值进行排序,默认升序
Series.sort_values(axis=0, ascending=True)
DataFrame.sort_values(by, axis=0, ascending=True)
by : axis轴上的某个索引或索引列表
python
import pandas as pd
import numpy as np
a = pd.DataFrame(np.arange(20).reshape(4,5),index=['c','a','d','b'])
print(a)
b = a.sort_values(2,ascending=False)
print(b)
b = a.sort_values('a',axis=1,ascending=False)
print(b)
#执行结果
0 1 2 3 4
c 0 1 2 3 4
a 5 6 7 8 9
d 10 11 12 13 14
b 15 16 17 18 19
0 1 2 3 4
b 15 16 17 18 19
d 10 11 12 13 14
a 5 6 7 8 9
c 0 1 2 3 4
4 3 2 1 0
c 4 3 2 1 0
a 9 8 7 6 5
d 14 13 12 11 10
b 19 18 17 16 15
python
import pandas as pd
import numpy as np
a = pd.DataFrame(np.arange(12).reshape(3,4),index=['a','b','c'])
print(a)
b = pd.DataFrame(np.arange(20).reshape(4,5),index=['c','a','d','b'])
print(b)
c = a+b
print(c.sort_values(2,ascending=False))
print(c.sort_values(2,ascending=True))
#执行结果
0 1 2 3
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
0 1 2 3 4
c 0 1 2 3 4
a 5 6 7 8 9
d 10 11 12 13 14
b 15 16 17 18 19
0 1 2 3 4
b 19.0 21.0 23.0 25.0 NaN
c 8.0 10.0 12.0 14.0 NaN
a 5.0 7.0 9.0 11.0 NaN
d NaN NaN NaN NaN NaN
0 1 2 3 4
a 5.0 7.0 9.0 11.0 NaN
c 8.0 10.0 12.0 14.0 NaN
b 19.0 21.0 23.0 25.0 NaN
d NaN NaN NaN NaN NaN
#NaN统一放到排序末尾基本的统计分析函数
使用与Series和DataFrame类型
| 方法 | 说明 |
|---|---|
| .sum() | 计算数据的总和,按0轴计算,下同 |
| .count() | 非NaN值的数量 |
| .mean() .median() | 计算数据的算术平均值、算术中位数 |
| .var() .std() | 计算数据的方差、标准差 |
| .min() .max() | 计算数据的最小值、最大值 |
| .argmin() .argmax() | 计算数据最大值、最小值所在位置的索引位置(自动索引) |
| .idxmin() .idxmax() | 计算数据最大值、最小值所在位置的索引(自定义索引) |
| .describe() | 针对0轴(各列)的统计汇总 |
python
import pandas as pd
import numpy as np
a = pd.Series([9,8,7,6],index=['a','b','c','d'])
print(a)
print(a.describe())
print(type(a.describe()))
print(a.describe()['count'])
print(a.describe()['max'])
b = pd.DataFrame(np.arange(20).reshape(4,5),index=['c','a','d','b'])
print(b)
print(b.describe())
print(type(b.describe()))
print(b.describe().loc['count'])
print(b.describe()[2])
#执行结果
a 9
b 8
c 7
d 6
dtype: int64
count 4.000000
mean 7.500000
std 1.290994
min 6.000000
25% 6.750000
50% 7.500000
75% 8.250000
max 9.000000
dtype: float64
<class 'pandas.core.series.Series'>
4.0
9.0
0 1 2 3 4
c 0 1 2 3 4
a 5 6 7 8 9
d 10 11 12 13 14
b 15 16 17 18 19
0 1 2 3 4
count 4.000000 4.000000 4.000000 4.000000 4.000000
mean 7.500000 8.500000 9.500000 10.500000 11.500000
std 6.454972 6.454972 6.454972 6.454972 6.454972
min 0.000000 1.000000 2.000000 3.000000 4.000000
25% 3.750000 4.750000 5.750000 6.750000 7.750000
50% 7.500000 8.500000 9.500000 10.500000 11.500000
75% 11.250000 12.250000 13.250000 14.250000 15.250000
max 15.000000 16.000000 17.000000 18.000000 19.000000
<class 'pandas.core.frame.DataFrame'>
0 4.0
1 4.0
2 4.0
3 4.0
4 4.0
Name: count, dtype: float64
count 4.000000
mean 9.500000
std 6.454972
min 2.000000
25% 5.750000
50% 9.500000
75% 13.250000
max 17.000000
Name: 2, dtype: float64累计统计分析函数
适用于Series和DataFrame类型,累计计算
| 方法 | 说明 |
|---|---|
| .cumsum() | 依次给出前1、2、...、n个数的和 |
| .cumprod() | 依次给出前1、2、...、n个数的积 |
| .cummax() | 依次给出前1、2、...、n个数的最大值 |
| .cummin() | 依次给出前1、2、...、n个数的最小值 |
python
import pandas as pd
import numpy as np
b = pd.DataFrame(np.arange(20).reshape(4,5),index=['c','a','d','b'])
print(b)
print(b.cumsum())
print(b.cumprod())
print(b.cummin())
print(b.cummax())
#执行结果
0 1 2 3 4
c 0 1 2 3 4
a 5 6 7 8 9
d 10 11 12 13 14
b 15 16 17 18 19
0 1 2 3 4
c 0 1 2 3 4
a 5 7 9 11 13
d 15 18 21 24 27
b 30 34 38 42 46
0 1 2 3 4
c 0 1 2 3 4
a 0 6 14 24 36
d 0 66 168 312 504
b 0 1056 2856 5616 9576
0 1 2 3 4
c 0 1 2 3 4
a 0 1 2 3 4
d 0 1 2 3 4
b 0 1 2 3 4
0 1 2 3 4
c 0 1 2 3 4
a 5 6 7 8 9
d 10 11 12 13 14
b 15 16 17 18 19| 方法 | 说明 |
|---|---|
| .rolling(w).sum() | 依次计算相邻w个元素的和 |
| .rolling(w).mean() | 依次计算相邻w个元素的算术平均值 |
| .rolling(w).var() | 依次计算相邻w个元素的方差 |
| .rolling(w).std() | 依次计算相邻w个元素的标准差 |
| .rolling(w).min .max() | 依次计算相邻w个元素的最小值和最大值 |
python
import pandas as pd
import numpy as np
b = pd.DataFrame(np.arange(20).reshape(4,5),index=['c','a','d','b'])
print(b)
print(b.rolling(2).sum())
print(b.rolling(3).sum())
#执行结果
0 1 2 3 4
c 0 1 2 3 4
a 5 6 7 8 9
d 10 11 12 13 14
b 15 16 17 18 19
0 1 2 3 4
c NaN NaN NaN NaN NaN
a 5.0 7.0 9.0 11.0 13.0
d 15.0 17.0 19.0 21.0 23.0
b 25.0 27.0 29.0 31.0 33.0
0 1 2 3 4
c NaN NaN NaN NaN NaN
a NaN NaN NaN NaN NaN
d 15.0 18.0 21.0 24.0 27.0
b 30.0 33.0 36.0 39.0 42.0数据的相关性分析
相关分析
两个事物,表示为X 和 Y,如何判断它们之间的存在相关性?
- X增大,Y增大,两个变量正相关
- X增大,Y减小,两个变量负相关
- X增大,Y无视,两个变量不相关
协方差
两个事物,表示为X 和 Y,如何判断它们之间的存在相关性?
Cov(x,y)=∑i=1n(xi−xˉ)∗(yi−yˉ)n−1Cov(x,y)=\frac{\sum_{i=1}^{n}({x_i-\bar{x})}*({y_i-\bar{y})}}{n-1}Cov(x,y)=n−1∑i=1n(xi−xˉ)∗(yi−yˉ)
- 协方差>0, X 和 Y正相关
- 协方差<0, X 和 Y负相关
- 协方差=0, X 和 Y独立无关
| 方法 | 说明 |
|---|---|
| .cov() | 计算协方差矩阵 |
| .corr() | 计算相关系数矩阵, Pearson、Spearman、Kendall等系数 |