视频压缩是数字视频技术的核心组成部分,其主要目标是在保持可接受的视觉质量的前提下,大幅减少视频数据量。未压缩的视频数据量巨大,难以存储和传输。视频压缩算法通过识别并消除视频数据中的冗余信息 来实现这一目标。这些冗余主要分为三类:空间冗余 (帧内冗余)、时间冗余 (帧间冗余)和视觉冗余(心理视觉冗余)。
时间冗余与帧间压缩
1. 时间冗余 (Temporal Redundancy)
时间冗余指的是视频序列中连续帧之间内容的高度相似性。在一个典型的视频序列中,背景通常保持静止或变化缓慢,运动的物体在连续的两帧之间也只发生了很小的位移。例如,在一个人物访谈视频中,除了人物的嘴部和面部有微小变化外,大部分画面(如背景、人物躯干)在很长一段时间内都是相同的。
这种相似性意味着如果完整地存储每一帧,就会存储大量的重复信息。消除这种跨帧的重复信息,就是消除时间冗余。
2. 帧间压缩 (Inter-frame Compression)
帧间压缩是一种利用时间冗余来压缩视频数据的方法。其核心思想是:不对视频序列中的所有帧都进行独立编码,而是只编码当前帧与参考帧之间的"差异"或"变化"。
这种方法比独立编码每一帧(帧内压缩/空间压缩)的效率高得多,尤其适用于运动量较小或静止场景较多的视频。帧间压缩的技术基础是运动估计 和运动补偿。
帧间压缩的关键技术:运动估计与运动补偿
帧间压缩的核心在于找到当前帧(待编码帧)中的内容在已编码的参考帧(可以是前面的帧,也可以是后面的帧)中的对应位置,然后只编码两者的差异。
1. 运动估计 (Motion Estimation, ME)
目标: 确定当前帧中的图像块是如何从参考帧中的对应块"移动"过来的。
基本过程:
-
分块 (Macroblocking): 当前帧被划分为一系列小的、固定大小的块(如16 * 16像素或8 * 8像素的宏块/编码单元)。
-
块匹配 (Block Matching): 对于当前帧的每一个块(目标块),编码器会在参考帧中的一个搜索窗口内寻找最相似的块。
-
相似性判据: 寻找"最相似"通常是通过计算两个块之间的差异来实现,常用的度量标准包括:
- 平均绝对差 (Sum of Absolute Differences, SAD): 计算对应像素点绝对差值的和。
- 均方差 (Mean Squared Error, MSE): 计算对应像素点差值的平方的平均值。
-
运动矢量 (Motion Vector, MV): 一旦找到最匹配的块,当前块与参考块之间的相对位移就被记录下来,这个位移量就是运动矢量。运动矢量是一个二维向量
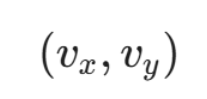
,它指示了参考帧中匹配块的位置。
意义: 运动估计是计算密集型操作,但它找到了块在时间上的相关性,是时间冗余消除的第一步。
2. 运动补偿 (Motion Compensation, MC)
目标: 利用运动矢量从参考帧中重建(预测)出当前帧的块,并计算残差。
基本过程:
-
预测块生成: 编码器使用运动矢量将参考帧中的匹配块"移动"到当前块的位置,从而生成一个预测块。
-
残差计算: 将当前帧的实际块与生成的预测块进行逐像素相减,得到残差块(或称为预测误差)。
-
编码残差: 只需要对这个残差块进行编码和传输。如果预测准确,残差块的大部分数值将接近于零,经过变换(如DCT)和量化后,可以极大地压缩数据量。

意义: 运动补偿通过从参考帧中"借用"信息,将编码原始块的问题转化为了编码运动矢量 和残差的问题,从而实现了对时间冗余的消除。
帧的类型与GOP结构
为了实现高效的帧间压缩,视频编码标准定义了不同类型的帧,它们以特定的序列组织起来,形成一个图像组 (Group of Pictures, GOP)。
1. 帧的类型 (Frame Types)
- I 帧 (Intra-coded Frame / Key Frame):
- 特点: 独立编码,不参考任何其他帧 。它仅利用空间冗余消除技术进行压缩,类似于一张JPEG图像。
- 作用: 作为GOP的起点,为后续的P帧和B帧提供解码的参考基础。如果解码器从视频流中间开始解码,它必须从最近的I帧开始。I帧的压缩率最低,数据量最大。
- P 帧 (Predicted Frame):
- 特点: 单向预测编码。它通过运动补偿 ,仅参考前面的一个I帧或P帧进行预测和编码。
- 作用: 消除时间冗余,压缩率比I帧高。它也可以作为后续P帧或B帧的参考。
- B 帧 (Bi-predictive Frame):
- 特点: 双向预测编码。它可以通过运动补偿 ,同时参考前面 的一个/多个已编码帧和后面的一个/多个已编码帧进行预测和编码。
- 作用: 提供最高的压缩效率。由于它利用了过去和未来的信息,可以更好地处理遮挡、物体进入/离开画面等情况。B帧不能作为其他帧的参考帧(在H.264/H.265中,它可以作为参考,但通常不被用作GOP中的主要参考)。
2. 图像组 (Group of Pictures, GOP) 结构
GOP是视频流中的一个基本独立单元,通常以一个I帧开始,后面跟着一系列P帧和B帧,直到下一个I帧开始。
-
GOP 长度 (GOP Size): 两个连续I帧之间的帧数。GOP长度越长,I帧出现的频率越低,压缩率通常越高,但解码错误传播的风险也越大(如果一个I帧丢失,直到下一个I帧出现的所有P/B帧都无法正确解码)。
-
GOP 结构举例: 一个常见的GOP结构可能是 N=12, M=3:
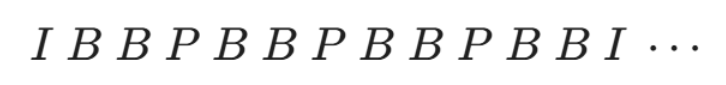
其中 N 是I帧到I帧的距离(GOP长度),M 是P帧到P帧的距离(或者说B帧的数量)。
运动估计/补偿的进阶优化
为了进一步提高压缩效率和鲁棒性,现代编码器在运动估计和补偿方面引入了诸多优化:
1. 亚像素运动估计 (Sub-pixel Motion Estimation)
传统的运动矢量只能指向整数像素位置。但物体的实际运动往往不是整数像素级的。
- 优化: 编码器允许运动矢量指向半像素 、四分之一像素 ,甚至八分之一像素位置(例如H.264/H.265使用四分之一像素精度)。
- 实现: 通过对参考帧的像素值进行插值来创建亚像素的参考点。
- 优势: 可以获得更精确的预测块,从而使残差更小,压缩率更高。
2. 变换编码与量化 (Transform Coding and Quantization)
在运动补偿之后,得到的残差块需要进行进一步的压缩:
- 变换编码: 对残差块应用离散余弦变换 (DCT) 或其整数近似版本(如H.264/H.265中)。这会将时域(或空间域)的信号转换为频域系数,将能量集中在少数低频系数上。
- 量化: 对变换后的系数进行有损量化 ,即将系数值除以量化步长并取整。这一步骤是视频压缩中有损压缩的主要来源,它通过丢弃人眼不敏感的高频信息,大幅减少了所需的数据量。
3. 各种预测模式 (Various Prediction Modes)
现代编码器提供了更灵活的预测模式,不再局限于单一大小的宏块:
- 可变块大小 (Variable Block Size, VBS): 允许编码器根据画面内容,将宏块分割成更小的块(如16 * 8, 8 * 16, 8 * 8, 4 * 4等)进行运动估计。这使得运动复杂的区域可以采用更小的块进行精确预测。
- 加权预测 (Weighted Prediction): 用于处理光照变化或渐隐/渐现的场景。预测块不是简单地从参考块复制,而是进行加权平均或亮度/对比度调整。
- 跳过模式 (Skip Mode): 如果一个宏块的残差非常小,编码器可以直接跳过残差的编码,只传输一个简单的"跳过"标志。这在静止或匀速运动的区域非常高效。
帧间冗余消除的优势与挑战
优势:
- 极高的压缩率: 相比于只使用帧内压缩(如MJPEG),帧间压缩能够将视频文件大小再压缩一个数量级以上,是实现高清/超高清视频高效传输和存储的基石。
- 适应性强: 运动估计和补偿机制能够动态适应视频中不同程度的运动和变化。
挑战:
- 编码/解码复杂度高: 运动估计是计算密集型任务,需要大量的处理能力。B帧的引入需要对帧进行重新排序(乱序解码/显示),增加了编解码的复杂度、内存需求和延迟(或称为端到端时延)。
- 错误传播: 帧间预测的依赖性导致一个帧的解码错误会沿着GOP向后传播,影响后续所有依赖于该错误帧的P帧和B帧。
- 随机访问性差: 要从视频流的任意位置开始解码,必须找到最近的I帧。如果GOP很长,随机访问的响应时间就会变慢。
总结
视频压缩中的帧间/时间冗余消除 是数字视频技术最重要的发明之一。它主要通过帧间预测技术实现,核心在于:
- 将视频序列划分为I、P、B三类帧,通过GOP结构组织。
- 对P帧和B帧,利用运动估计 确定当前帧块在参考帧中的位置,生成运动矢量。
- 通过运动补偿 ,使用运动矢量从参考帧中生成预测块 ,并计算残差。
- 最终编码并传输的数据是I帧的完整(空间压缩后的)数据 、P/B帧的运动矢量 和残差。