接上节课,智能筛选新闻、生成海报并推送到企业微信。
思路和效果
将新闻按照主题关联度来排,取关联度高的前十条新闻,用它们的标题作为生图的关键词,然后将图片发到企微。步骤大致如下:
- DeepSeek:文本处理
- Gemini:图像生成
- 企业微信:消息推送
效果图:

目的达到了,但是图片内容效果不尽人意,因为我用的是nano banana2.5,不是pro,运行稳定且有需求的话可以用最新滴nano banana pro(也是最贵滴)。
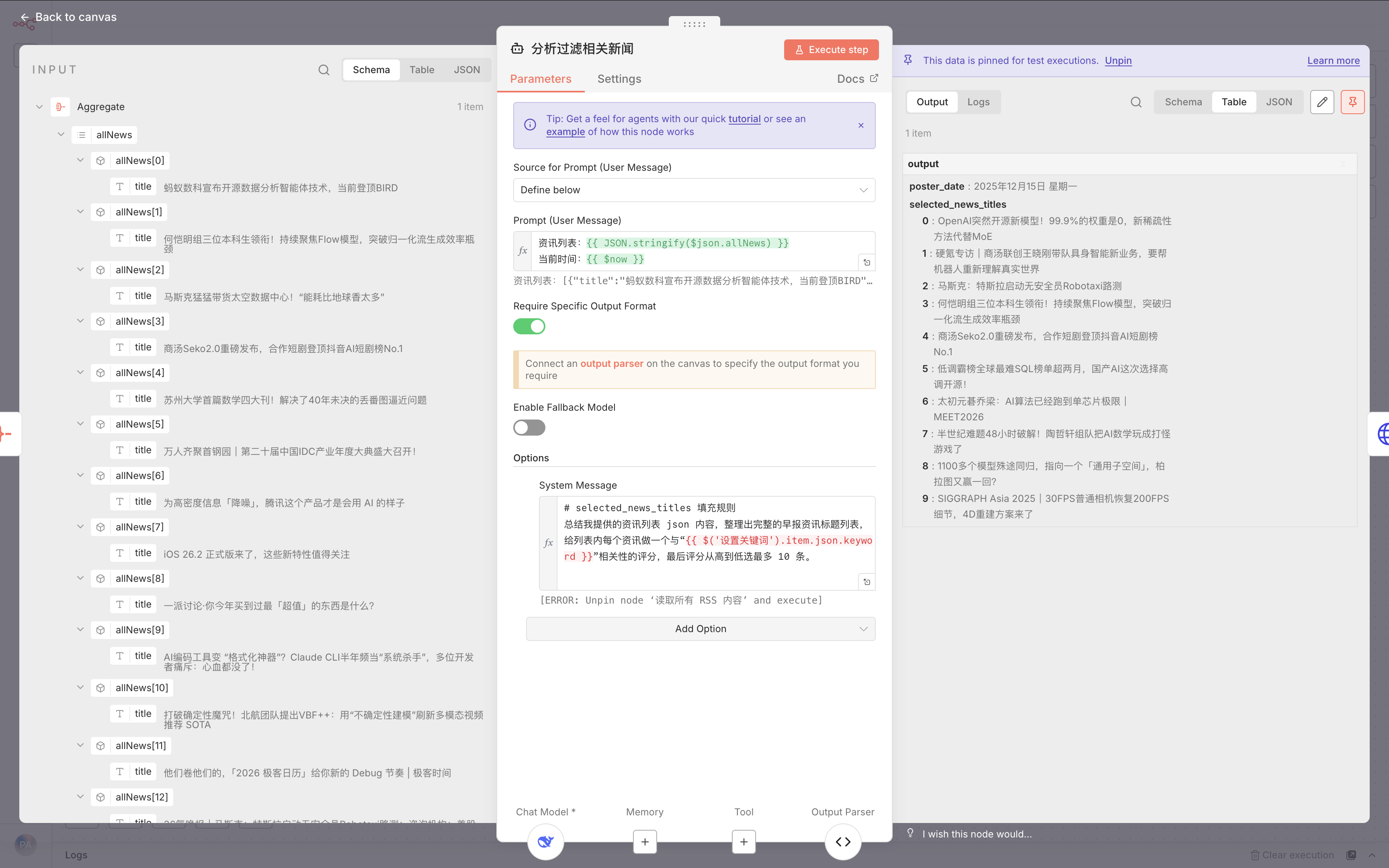
一、核心节点:AI智能筛选新闻
这个节点是大模型做裁判的关键环节。它拿到所有新闻标题后,要选出最相关的10条。
1. 筛选逻辑拆解
系统指令很明确:
- 给每个标题打相关性分数(与"AI/人工智能/机器人/科技"相关程度)
- 按分数从高到低排序
- 取前10名
这样避免了随机选择,确保选出的都是干货。
2. 输出格式强制约束
大模型必须输出固定格式:
{
"selected_news_titles": ["标题1", "标题2"],
"poster_date": "2025年12月15日 星期一"
}小技巧:这种严格格式约束,让后续节点可以直接使用数据,不用再解析。
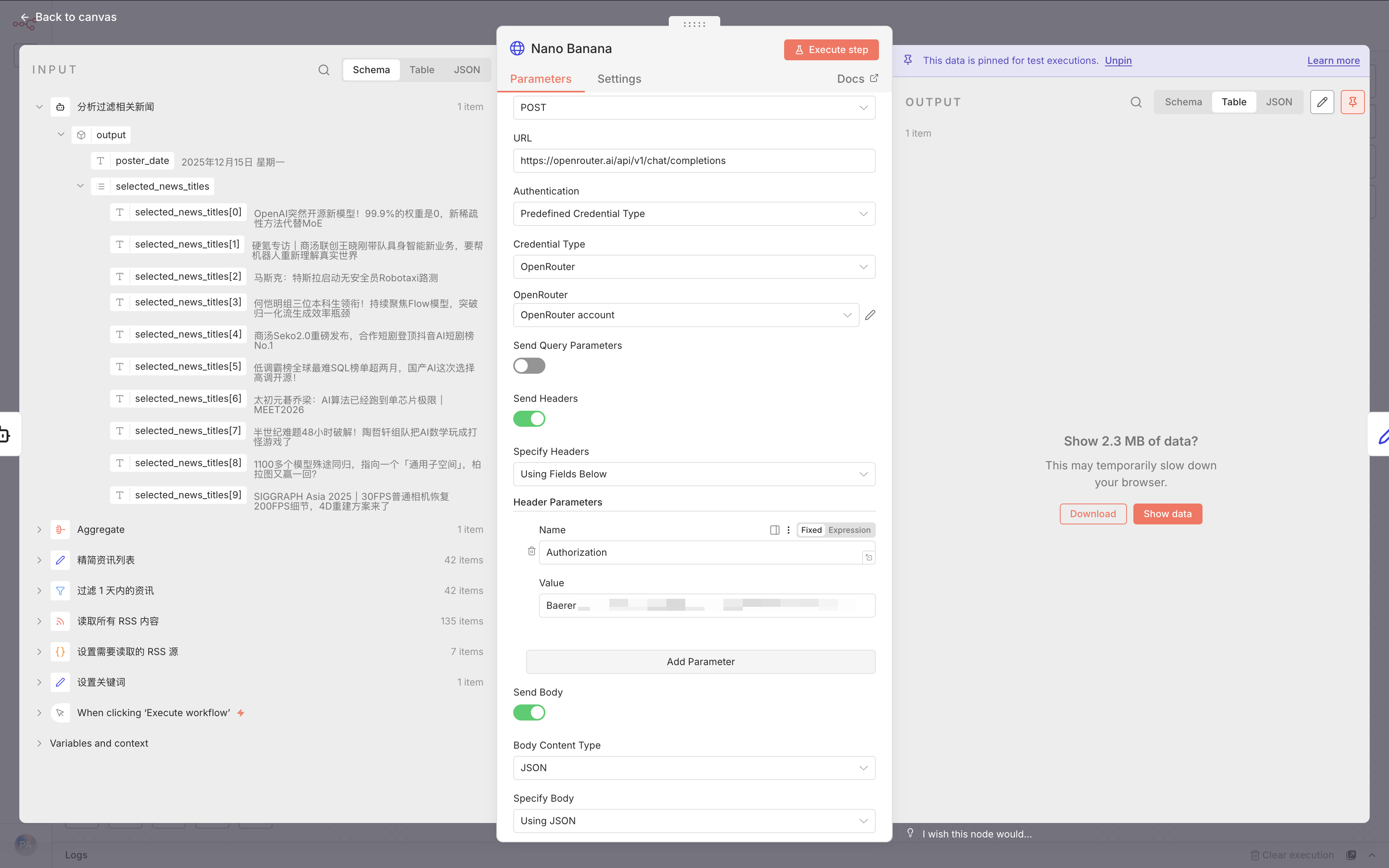
二、海报生成:让AI当美编
选好新闻后,需要"配图"。这里调用Gemini-2.0生成海报。
提示词设计精髓
这个提示词写得很有水平:
- 尺寸要求:4k竖版(9:16),适合手机查看
- 布局要求:Bento Grid(便当盒式分区)
- 风格要求:手绘风+简洁图标
- 关键约束:严禁内容重复!
为什么用OpenRouter?
- 它是"模型聚合平台",能访问多种图像模型
- 根据需求用不同版本的大模型

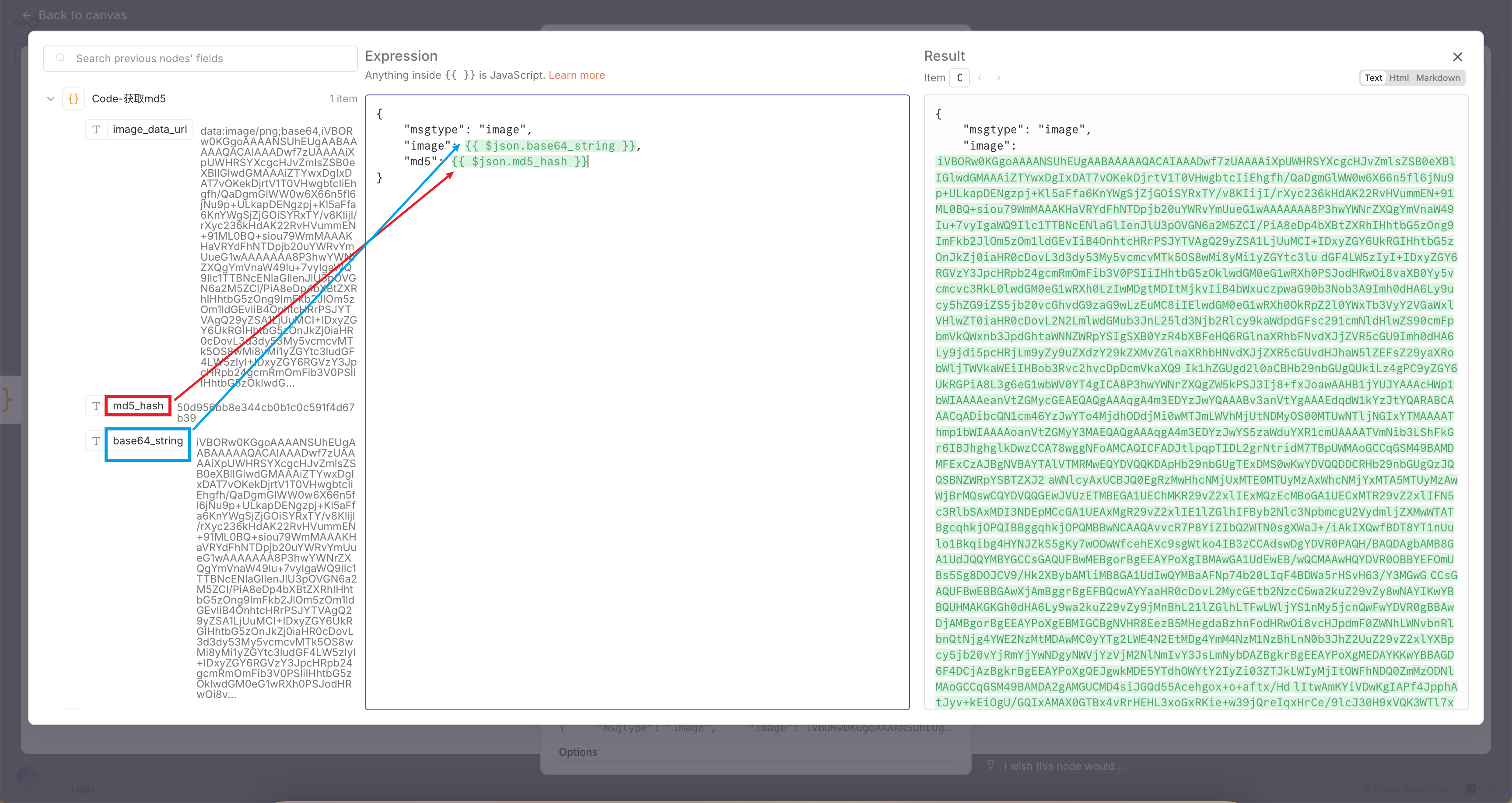
三、数据处理:Base64提取与校验
AI返回的是数据URL,我们需要:
-
提取纯Base64字符串
-
计算MD5值(企业微信API要求)
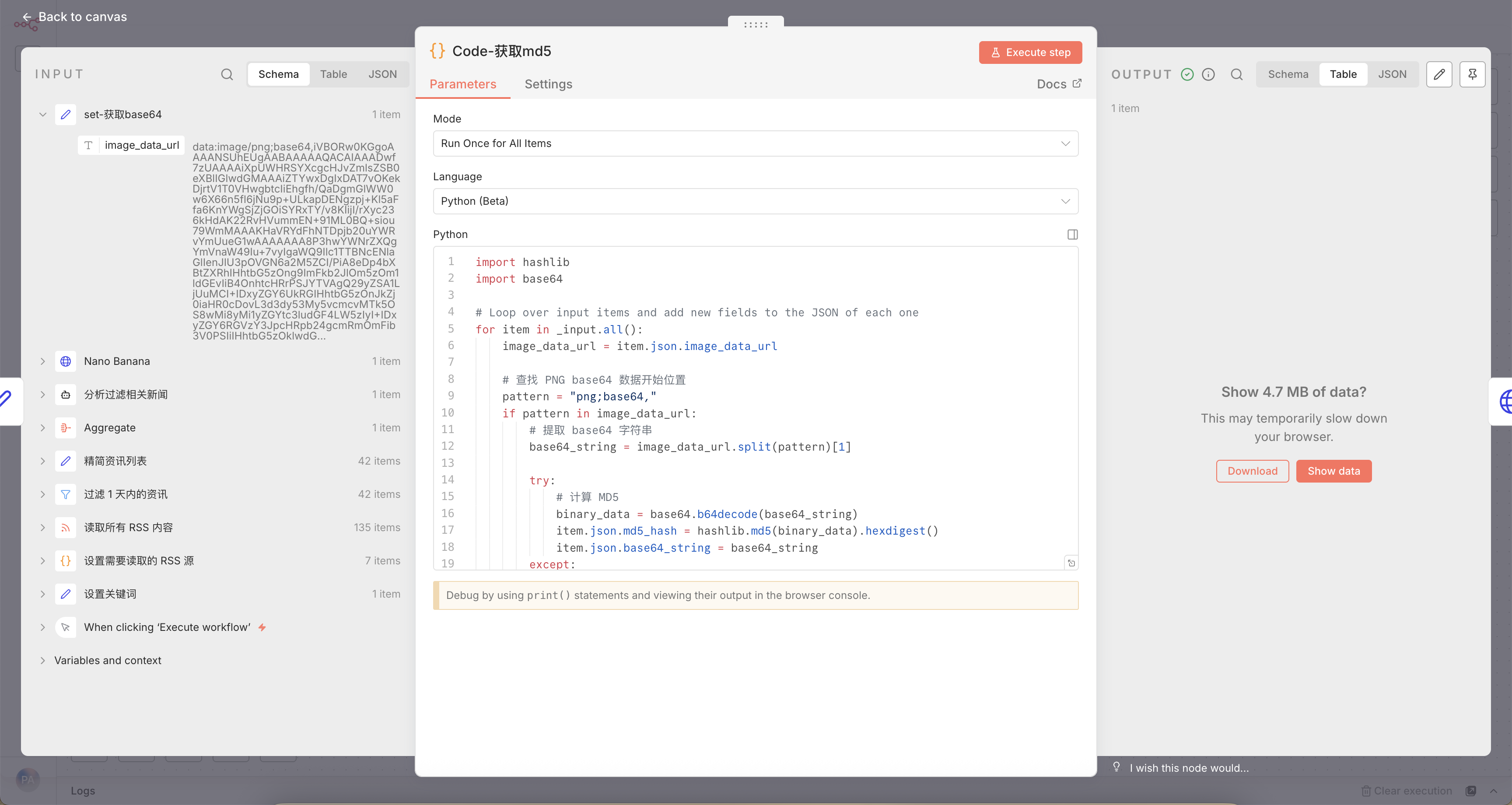
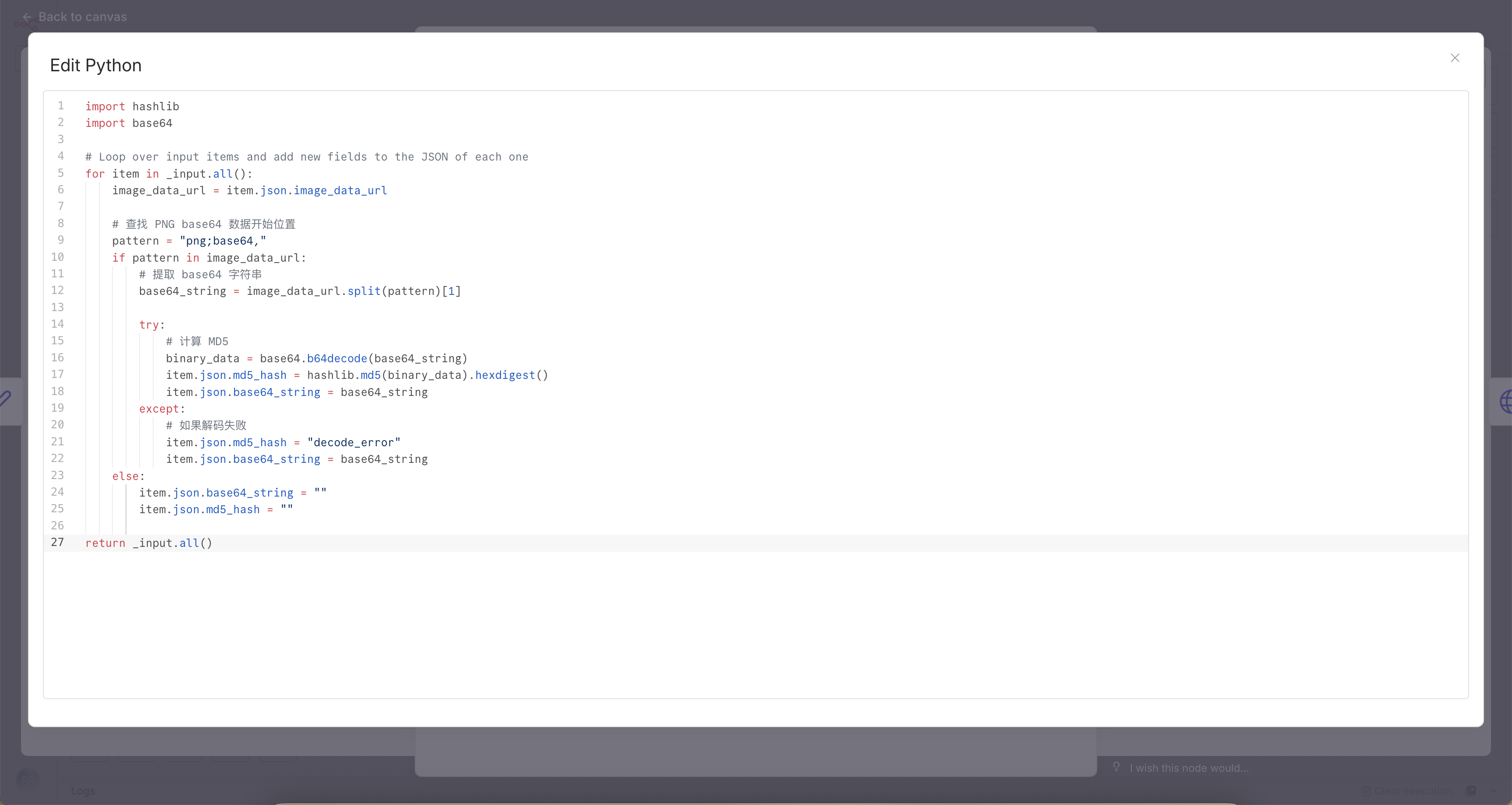
代码节点核心逻辑:
# 找到"png;base64,"后面的部分
base64_string = image_data_url.split("png;base64,")[1]
# 计算MD5(用于校验)
md5_hash = hashlib.md5(base64.b64decode(base64_string)).hexdigest()四、最终推送:企业微信机器人
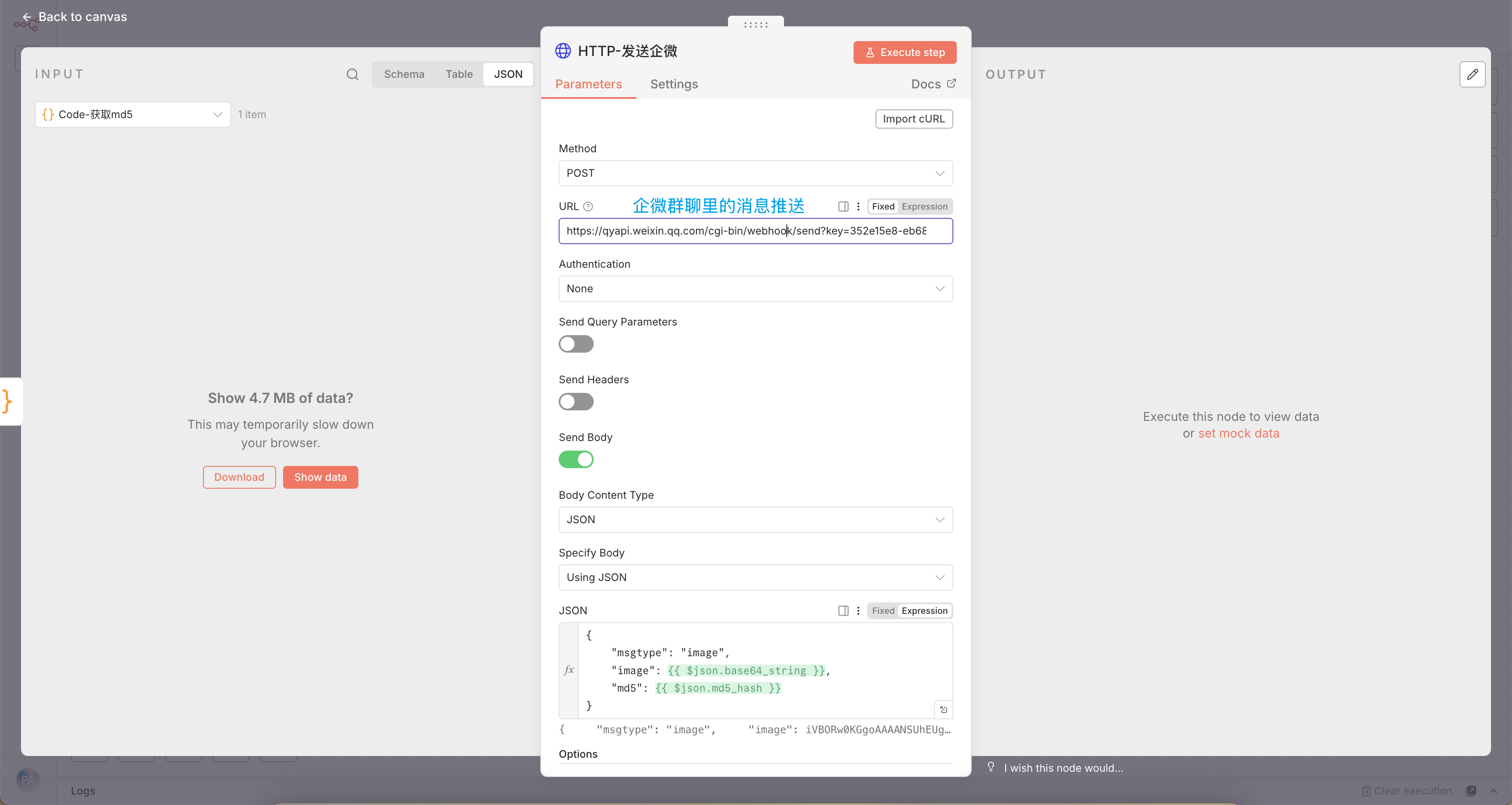
配置很简单:
{
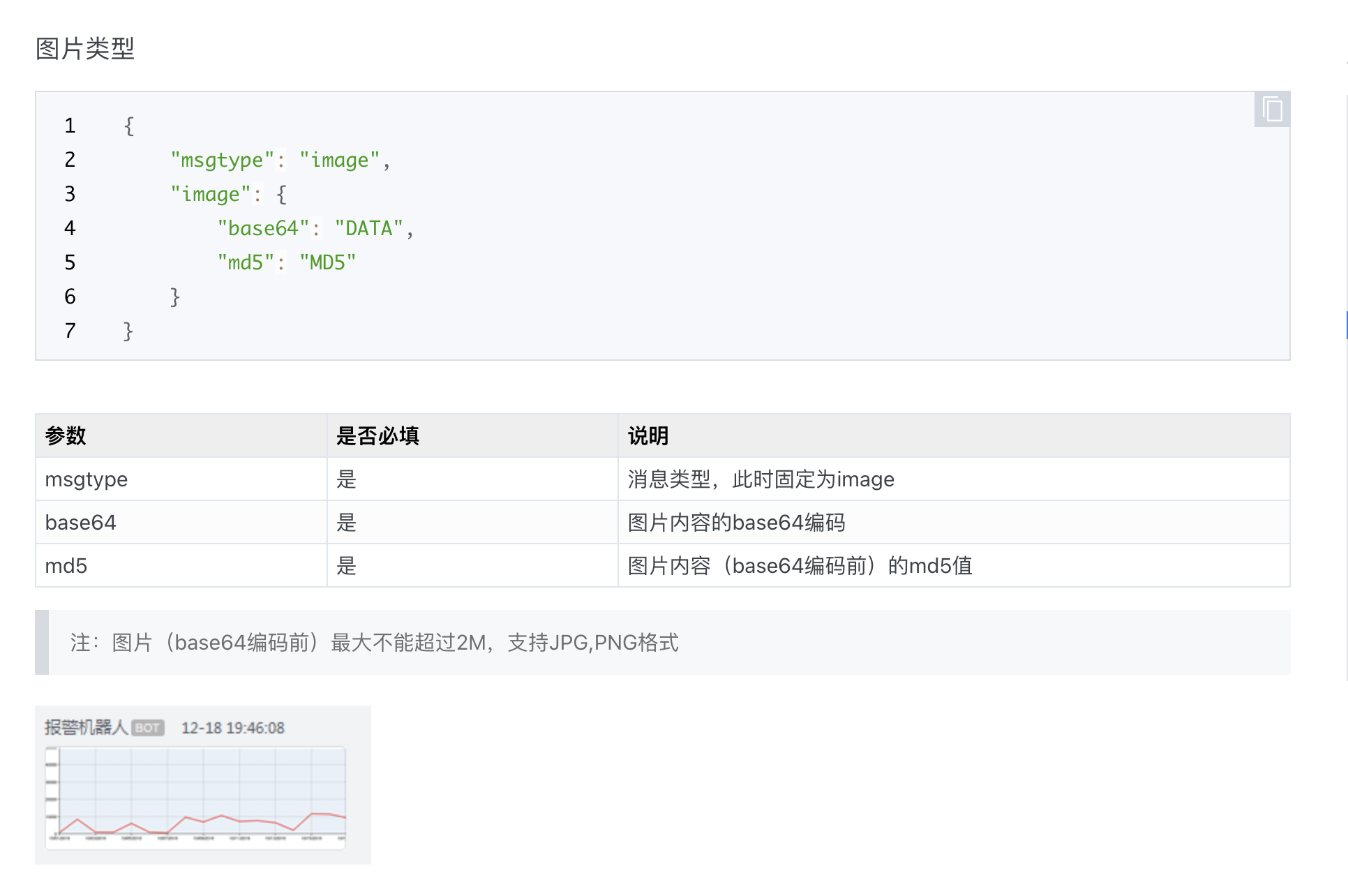
"msgtype": "image",
"image": {
"base64": "{{base64_string}}",
"md5": "{{md5_hash}}"
}
}Webhook密钥从企业微信群机器人设置获取。
五、小记
这节我还学习了base64和md5,她俩都是企微接收图片时要求必填的参数。
base64是什么?
我跟龙哥一起探讨,发现它跟ASCII 的联系非常深,ASCII如下(截图不完整):
我的理解是:ASCII里记录着里面有128个字符表(0-127),每格表代表不同的含义,包括古早常用的有特殊含义字母组合(0-31),计算符号和数字(32-64),大小写字母以及后面又加了些符号等等。而Base64是取里面的64个字符,大小写字母和数字,还差几个我不知道是什么,问了ds,她解释说:
- ASCII 定义了一个包含 128个 字符的标准集(包括控制字符和可打印字符)。
- Base64 从这个可打印字符部分中,精心挑选了 64个 最安全、最通用、最不可能被系统误解 的字符,组成了自己的"密码本":
-
- 大写字母 A-Z (26个)
- 小写字母 a-z (26个)
- 数字 0-9 (10个)
- 符号 + (1个)
- 符号 / (1个)
- 总计:26 + 26 + 10 + 1 + 1 = 64个字符
这就是它名字 Base64 的由来------基于这64个字符的编码系统。
ds还举了例子,我觉得说的挺清楚的:

md5是什么呢?

我的理解是:MD5就像现在网购要求的开箱视频 (AI生成的不算),目的是验证买家 收到的货物的跟卖家 发过来的货物是否货不对板,防止了买家无凭证,也防止卖家的货在中途被掉包等。企微要求必填md5,就是验证我们在群聊收到消息推送发的图片(买家 )与我们的工作流发给企微webhook的图片(卖家)是否一致,因为中间可能存在恶意广告给卖家图片调包的现象。ds说我的理解100%正确!

我看nano生图只有base64没有生成md5,所以我让ds帮我在代码里添加了md5的获取方式。本来用的是js,但是因为不熟悉,且python自带库,方便些,所以用了python代码。话说n8n的python代码标注的是Beta

,居然还是公测版,我们python如此的"不稳定"吗哈哈。