Kafka改为system模式
要将 Kafka(KRaft 模式)以 systemd 服务(system 模式) 方式运行,可以创建一个 systemd unit 文件,实现开机自启、日志管理、自动重启等功能。以下是详细步骤:
前提条件
- 已完成 Kafka 的 KRaft 模式初始化(包括生成 UUID、格式化存储目录)
- 已配置好
config/kraft/server.properties - 如需 SASL 认证,JAAS 配置文件已就绪
- 使用非 root 用户运行 Kafka(推荐新建专用用户,如
kafka)
一、创建专用用户
bash
# 创建Kafka用户与密码
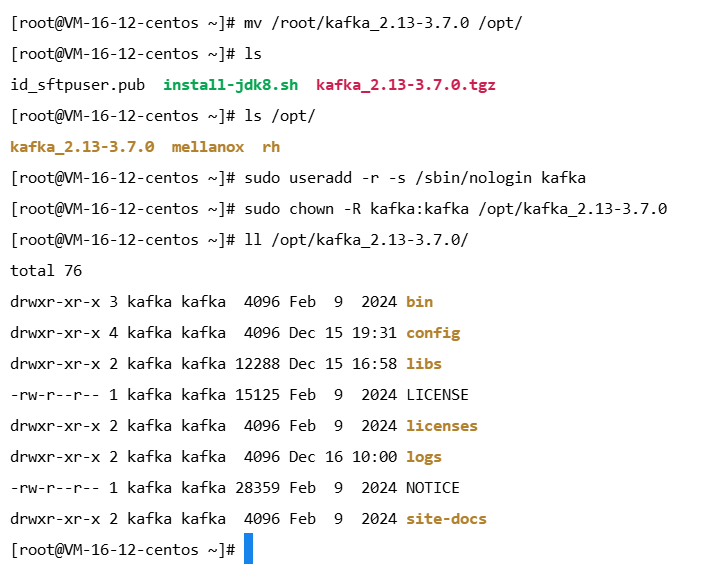
sudo useradd -r -s /sbin/nologin kafka
# 将Kafka的目录移至非root目录下
mv /root/kafka_2.13-3.7.0 /opt/
# 将kafka用户此文件的权限
sudo chown -R kafka:kafka /opt/kafka_2.13-3.7.0将
/opt/kafka_2.13-3.7.0替换为你的实际 Kafka 安装路径,例如/opt/kafka
二、创建 systemd 服务文件
bash
sudo vi /etc/systemd/system/kafka.service内容如下(根据是否启用 SASL 调整):
情况 A:未启用 SASL(纯 PLAINTEXT)
ini
[Unit]
Description=Apache Kafka Server (KRaft mode)
After=network.target
[Service]
Type=simple
User=kafka
Group=kafka
WorkingDirectory=/opt/kafka_2.13-3.7.0
ExecStart=/opt/kafka_2.13-3.7.0/bin/kafka-server-start.sh /opt/kafka_2.13-3.7.0/config/kraft/server.properties
Restart=on-failure
RestartSec=10
StandardOutput=journal
StandardError=journal
SyslogIdentifier=kafka
[Install]
WantedBy=multi-user.target情况 B:启用了 SASL/PLAIN 认证
ini
[Unit]
Description=Apache Kafka Server (KRaft + SASL/PLAIN)
After=network.target
[Service]
Type=simple
User=kafka
Group=kafka
WorkingDirectory=/opt/kafka_2.13-3.7.0
Environment="KAFKA_OPTS=-Djava.security.auth.login.config=/etc/kafka/security/kafka_server_jaas.conf"
ExecStart=/opt/kafka_2.13-3.7.0/bin/kafka-server-start.sh /etc/kafka/server.properties
Restart=on-failure
RestartSec=5
StandardOutput=journal
StandardError=journal
SyslogIdentifier=kafka
[Install]
WantedBy=multi-user.target注意:
- 所有路径请替换为你实际的 Kafka 安装路径(建议统一放在
/opt/kafka)- 确保
kafka_server_jaas.conf文件权限安全:chmod 600 config/security/kafka_server_jaas.conf,且属主为kafka
三、重载 systemd 并启用服务
bash
# 重载配置
sudo systemctl daemon-reload
# 启动 Kafka
sudo systemctl start kafka
# 设置开机自启
sudo systemctl enable kafka
# 查看状态
sudo systemctl status kafka
# 查看日志
sudo journalctl -u kafka -f这里停掉之前的Kafka服务,再启动会报错
Dec 16 11:02:15 VM-16-12-centos kafka[28282]: [2025-12-16 11:02:15,524] ERROR Encountered fatal fault: caught exception (org.apache.kafka.server.fault.ProcessTerminatingFaultHandler)
Dec 16 11:02:15 VM-16-12-centos kafka[28282]: java.io.IOException: Could not read file /tmp/kraft-combined-logs/__cluster_metadata-0/00000000000000114142-0000000005.checkpoint
Dec 16 11:02:15 VM-16-12-centos kafka[28282]: at kafka.log.LogLoader.$anonfun$removeTempFilesAndCollectSwapFiles$2(LogLoader.scala:225)
Dec 16 11:02:15 VM-16-12-centos kafka[28282]: at scala.collection.ArrayOps$WithFilter.foreach(ArrayOps.scala:73)问题:
Kafka 试图从 /tmp/kraft-combined-logs/ 加载元数据,但其中的 checkpoint 文件损坏或无法读取。
默认的数据目录/tmp 是临时目录,系统可能随时清理(尤其重启后)所以这里要做日志文件与数据文件的分离
四、日志文件与数据文件的分离(如果没出问题就选做)
1. 停止服务并清理临时数据
sudo systemctl stop kafka
sudo rm -rf /tmp/kraft-combined-logs /tmp/kafka-logs这会清空所有数据(因之前存在损坏),但这是修复的前提。
2. 创建持久化目录并授权
# 创建用户(如果尚未创建)
sudo useradd -r -s /sbin/nologin kafka
# 创建数据目录
sudo mkdir -p /var/lib/kafka/data
# 创建应用日志目录
sudo mkdir -p /var/log/kafka
# 授权给 kafka 用户
sudo chown -R kafka:kafka /var/lib/kafka /var/log/kafka
sudo chmod 750 /var/lib/kafka/data
sudo chmod 750 /var/log/kafka3. 迁移并修正配置文件
1. 移动关键配置文件到 /etc/kafka/
sudo mkdir -p /etc/kafka/security
sudo cp /opt/kafka_2.13-3.7.0/config/kraft/server.properties /etc/kafka/
sudo cp /opt/kafka_2.13-3.7.0/config/security/kafka_server_jaas.conf /etc/kafka/security/
sudo chown -R kafka:kafka /etc/kafka
sudo chmod 600 /etc/kafka/security/kafka_server_jaas.conf2. 编辑 /etc/kafka/server.properties
vi /etc/kafka/server.properties内容如下:
# KRaft 模式
process.roles=broker,controller
node.id=1
controller.quorum.voters=1@localhost:9093
# Listener 配置(根据你的网络调整 advertised.listeners)
listeners=SASL_PLAINTEXT://:9092,CONTROLLER://:9093
advertised.listeners=SASL_PLAINTEXT://<你的服务器内网IP>:9092
inter.broker.listener.name=SASL_PLAINTEXT
controller.listener.names=CONTROLLER
# 核心:数据目录(不再是 /tmp!)
log.dirs=/var/lib/kafka/data
# SASL 认证
sasl.enabled.mechanisms=PLAIN
sasl.mechanism.inter.broker.protocol=PLAIN替换
<你的服务器内网IP>为实际 IP(如10.0.16.12),不要用localhost(除非仅本机访问)如果是跟着前一篇博客搭建的话,可以只修改
log.dirs=/var/lib/kafka/data
4. 重新格式化存储(关键)
sudo -u kafka /opt/kafka_2.13-3.7.0/bin/kafka-storage.sh format \
-t $(sudo -u kafka /opt/kafka_2.13-3.7.0/bin/kafka-storage.sh random-uuid) \
-c /etc/kafka/server.properties成功输出:
Formatting /var/lib/kafka/data with metadata.version 3.7-IV4.5. 更新 systemd 服务文件
编辑 /etc/systemd/system/kafka.service:
vi /etc/systemd/system/kafka.service内容如下:
[Unit]
Description=Apache Kafka Server (KRaft + SASL/PLAIN)
After=network.target
[Service]
Type=simple
User=kafka
Group=kafka
Environment="KAFKA_OPTS=-Djava.security.auth.login.config=/etc/kafka/security/kafka_server_jaas.conf -Dkafka.logs.dir=/var/log/kafka"
ExecStart=/opt/kafka_2.13-3.7.0/bin/kafka-server-start.sh /etc/kafka/server.properties
Restart=on-failure
RestartSec=10
StandardOutput=journal
StandardError=journal
[Install]
WantedBy=multi-user.target重载配置:
sudo systemctl daemon-reload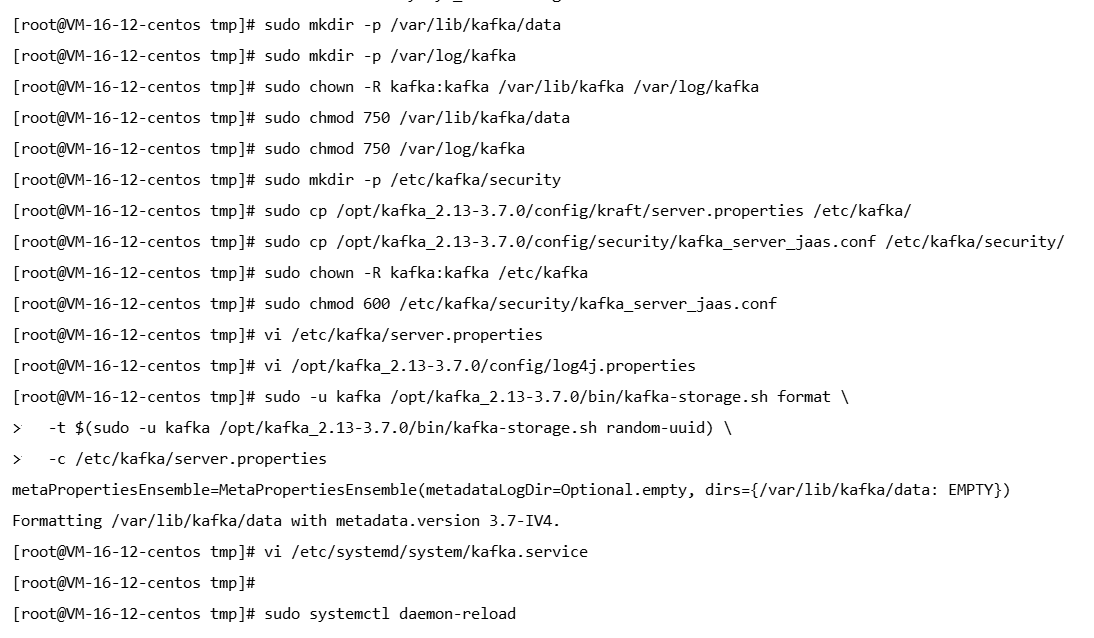
6. 启动并验证
# 启动
sudo systemctl start kafka
# 检查状态
sudo systemctl status kafka
# 查看实时日志
sudo journalctl -u kafka -f --since "1 min ago"
# 验证数据目录是否生成
ls -l /var/lib/kafka/data/
# 应包含 meta.properties 和 __cluster_metadata-0/
# 验证应用日志
tail -f /var/log/kafka/server.log成功标志:
[KafkaRaftServer nodeId=1] Kafka Server started (kafka.server.KafkaRaftServer)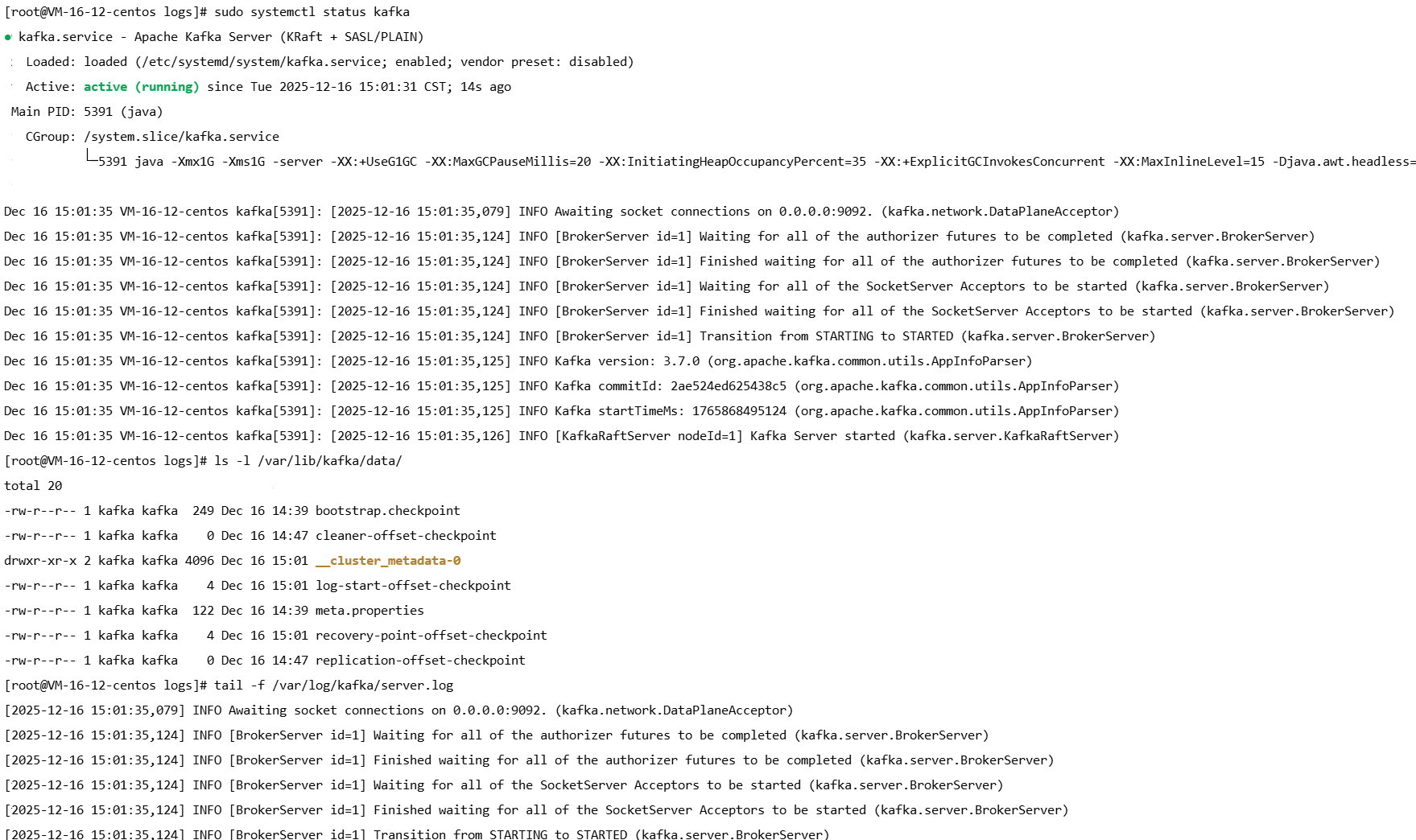
总结
| 项目 | 路径 | 说明 |
|---|---|---|
| Kafka 数据(Topic + 元数据) | /var/lib/kafka/data |
由 log.dirs 指定,必须持久化 |
| Kafka 应用日志(server.log) | /var/log/kafka/ |
由 log4j.properties 控制 |
| 配置文件 | /etc/kafka/ |
符合 Linux 规范,便于管理 |
| 安装包 | /opt/kafka_2.13-3.7.0/ |
只读,不存运行时数据 |
完全分离:数据、日志、配置、程序四者独立,安全、可维护、可备份。
建议(生产环境)
- 磁盘挂载 :将
/var/lib/kafka挂载到独立高性能磁盘(如 SSD) - 日志轮转 :配置
logrotate管理/var/log/kafka/*.log - 监控 :监控
/var/lib/kafka/data磁盘使用率 - 备份 :定期快照
/var/lib/kafka/data
五、验证服务是否正常
bash
# 创建测试 topic
/opt/kafka_2.13-3.7.0/bin/kafka-topics.sh --create --topic test-systemd \
--bootstrap-server localhost:9092 --partitions 1 --replication-factor 1
# 列出 topics
/opt/kafka_2.13-3.7.0/bin/kafka-topics.sh --list --bootstrap-server localhost:9092若启用 SASL,需在客户端命令中添加认证参数(或使用配置文件),没有启用则可以直接使用上面的验证命令。
1.客户端创建
1.1. 确认服务端 SASL 用户名和密码
(前面已创建,略过)
| 用户名(username) | 密码(password) | 用途建议 |
|---|---|---|
admin |
StrongPassword123! |
管理员(全权限) |
producer |
StrongPassword456! |
仅用于生产消息 |
consumer |
StrongPassword789! |
仅用于消费消息 |
1.2. 创建客户端 JAAS 配置文件
sudo mkdir -p /etc/kafka/security
sudo vi /etc/kafka/security/kafka_admin_client_jaas.conf这里设置管理员用户的客户端,内容如下:
KafkaClient {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="admin"
password="StrongPassword123!";
};1.3. 设置权限(仅 kafka 用户可读)
sudo chown kafka:kafka /etc/kafka/security/kafka_admin_client_jaas.conf
sudo chmod 600 /etc/kafka/security/kafka_admin_client_jaas.conf1.4. 创建客户端配置文件
sudo vi /etc/kafka/client.properties内容如下:
security.protocol=SASL_PLAINTEXT
sasl.mechanism=PLAIN
2.客户端使用
使用认证信息执行命令(通过环境变量指定 JAAS)
# 切换到 kafka 用户(避免权限问题)
sudo -u kafka bash
# 执行命令(注意路径)
# 创建测试 topic
KAFKA_OPTS="-Djava.security.auth.login.config=/etc/kafka/security/kafka_admin_client_jaas.conf" \
/opt/kafka_2.13-3.7.0/bin/kafka-topics.sh \
--bootstrap-server localhost:9092 \
--command-config /etc/kafka/client.properties \
--create --topic test-systemd --partitions 1 --replication-factor 1
# 列出 topics
KAFKA_OPTS="-Djava.security.auth.login.config=/etc/kafka/security/kafka_admin_client_jaas.conf" \
/opt/kafka_2.13-3.7.0/bin/kafka-topics.sh \
--command-config /etc/kafka/client.properties \
--list --bootstrap-server localhost:9092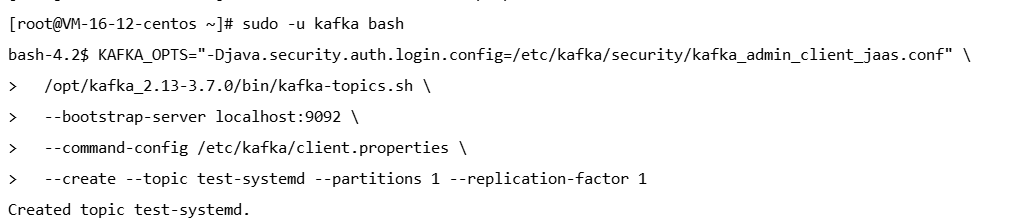

六、安全建议(生产环境)
- 不要使用 root 运行 Kafka
- 限制
advertised.listeners为内网 IP 或通过反向代理暴露 - SASL/PLAIN 仅用于内网;公网必须配合 SSL(SASL_SSL)
- 防火墙限制 9092 端口仅允许可信 IP 访问
- 定期备份元数据(KRaft 的 snapshot 和 log 目录)
至此,Kafka 已成功转为 systemd 管理的服务模式,具备自动启动、崩溃恢复、集中日志等能力,适合生产部署。