本地数据共享(LDS)是一种极低延迟、用于临时数据的RAM暂存器,其有效带宽至少比直接、无缓存的全局内存高出一个数量级。它允许工作组内的工作项之间共享数据,并用于保存像素着色器参数插值所需的参数。与只读缓存不同,LDS允许对内存空间进行高速的"写入后读取"复用(聚集/读取/加载和分散/写入/存储操作)。
10.1 概述
下图展示了LDS集成到AMD GPU内存(使用OpenCL)的概念框架。
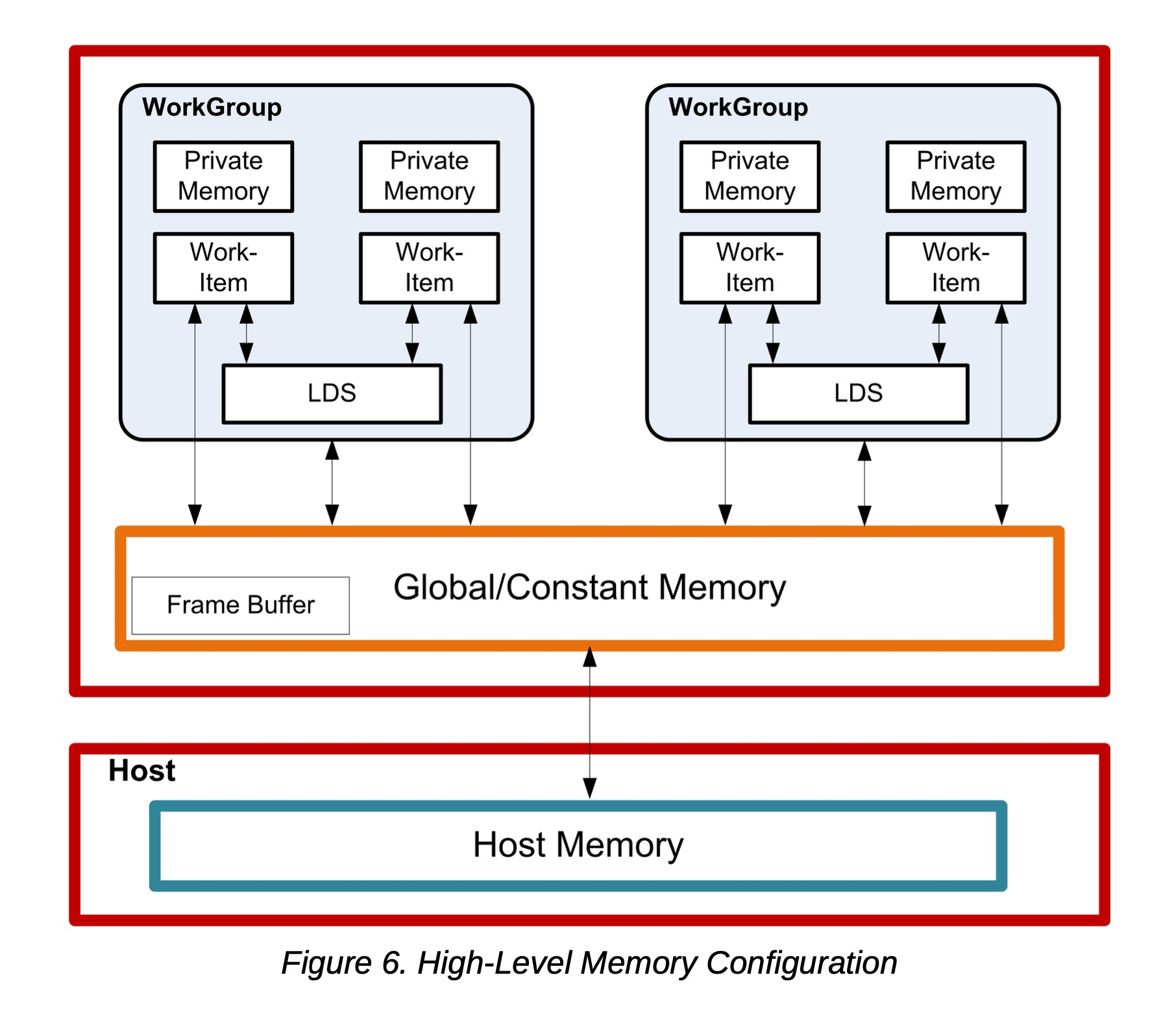
(图6:高级内存配置)
LDS物理上位于芯片上,紧邻算术逻辑单元(ALU),其速度大约比全局内存快一个数量级(假设没有存储体冲突)。
每个计算单元拥有64 kB内存,分为32个库,每库512个双字。每个存储体是一个256x32的双端口RAM(每个时钟周期可1读1写)。双字按顺序放入各个存储体,但所有存储体可以同时执行存储或加载操作。一个工作组最多可以请求64 kB内存。跨波前的读取操作以瀑布式分四个周期调度。
LDS内存的高带宽不仅得益于其靠近ALU,还因为能同时访问其多个存储体。因此,有可能并发执行32条写入或读取指令,每条指令名义上为32位;扩展指令(如read2/write2)每条可为64位。然而,如果同一时间对同一存储体进行多次访问尝试,就会发生存储体冲突。在这种情况下,对于索引和原子操作,硬件会将这些对同一存储体的并发访问尝试转为串行访问,以防止冲突。这会降低LDS的有效带宽。因此,为了获得最大吞吐量(最佳效率),避免存储体冲突至关重要。了解请求调度和地址映射是实现这一目标的关键。
10.2 内存层次结构中的数据流
下图是内存结构内数据流的概念图。
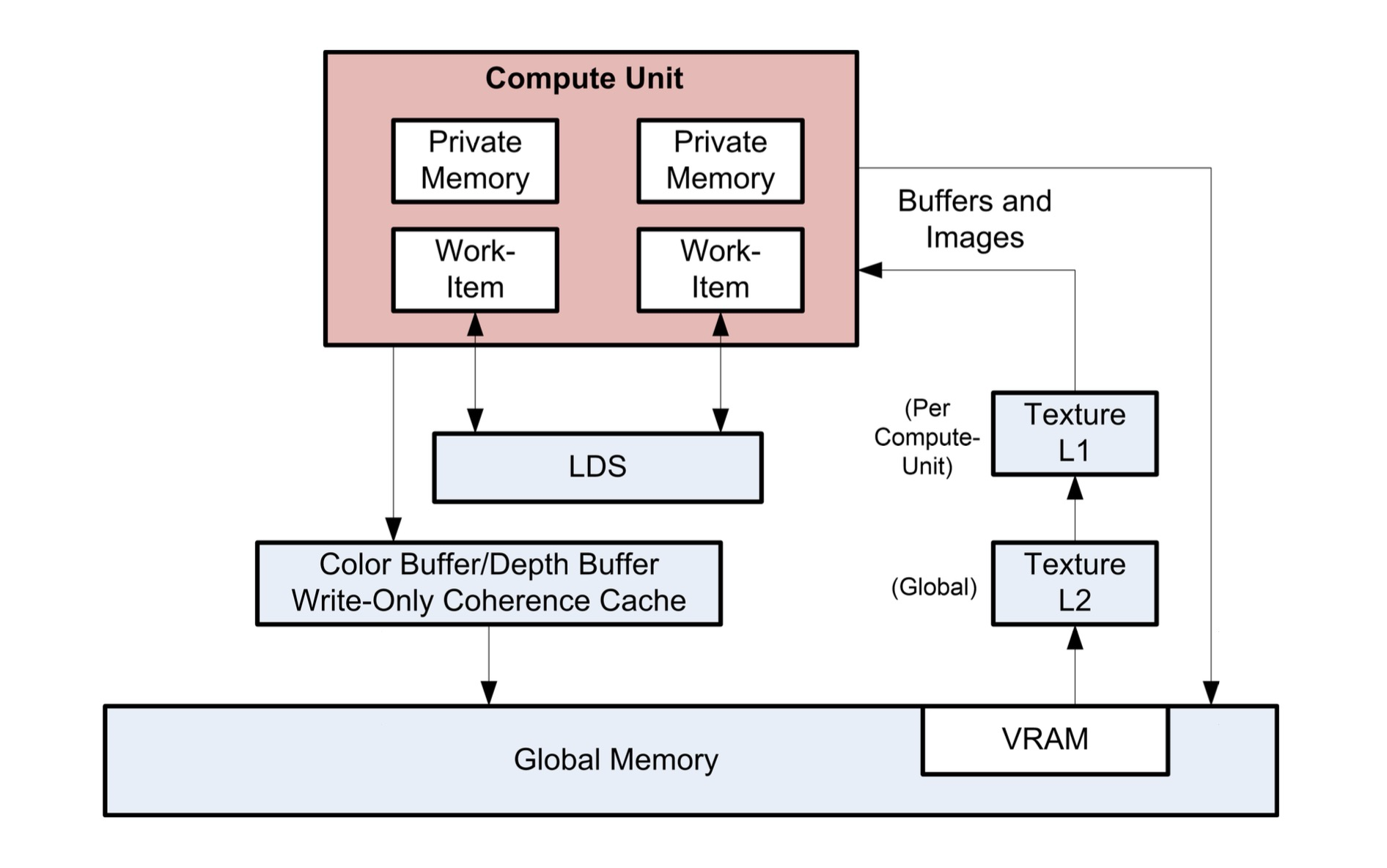
要将数据从全局内存加载到LDS,需要从全局内存读取数据并放入工作项的寄存器;然后,执行一次到LDS的存储操作。类似地,要将数据存储到全局内存,需要从LDS读取数据放入工作项寄存器,然后再放入全局内存。为了有效利用LDS,算法必须在全局内存和LDS之间传输的数据上执行多次操作。也可以绕过VGPR,直接从内存缓冲区将数据加载到LDS。
LDS原子操作在LDS硬件中执行。(因此,尽管这些操作不直接使用ALU,但执行此功能会带来LDS延迟。)
10.3 LDS访问
LDS通过以下三种方式之一进行访问:
-
直接读取
-
参数读取
-
索引或原子操作
以下小节描述了这些方法。
10.3.1 LDS直接读取
直接读取仅在LDS中可用,GDS中不可用。
LDS直接读取发生在向量ALU(VALU)指令中,允许LDS提供一个双字值,该值广播到波前中的所有线程,并用作ALU操作的SRC0输入。VALU指令通过在SRC0字段使用LDS_DIRECT来指示输入由LDS提供。
要从LDS读取的数据的LDS地址和数据类型来自M0寄存器:
LDS_addr = M0[15:0] (byte address and must be Dword aligned)
DataType = M0[18:16]
0 unsigned byte
1 unsigned short
2 Dword
3 unused
4 signed byte
5 signed short10.3.2 LDS参数读取
参数读取仅在LDS中可用,GDS中不可用。
像素着色器使用LDS读取顶点参数值;然后像素着色器对其进行插值以找到每个像素的参数值。当使用以下操作码时,会发生LDS参数读取:
-
V_INTERP_P1_F32D = P10 * S + P0 参数插值,第一步。 -
V_INTERP_P2_F32D = P20 * S + D 参数插值,第二步。 -
V_INTERP_MOV_F32D = {P10,P20,P0}S 参数加载。
典型的参数插值操作涉及读取三个参数:P0、P10和P20,并使用两个重心坐标I和J来确定最终的每像素值:
Final value = P0 + P10 * I + P20 * J参数插值指令指示参数属性编号(0到32)和分量编号(0=x, 1=y, 2=z, 3=w)。

参数插值和参数移动指令在使用M0寄存器之前必须初始化它。lds_param_offset[15:0] 是从分配给此波前的LDS存储空间起始处到该波前参数在LDS内存中开始位置的地址偏移量。new_prim_mask 是一个15位掩码,每个四边形对应一位;该掩码中的"1"表示此四边形开始一个新的图元,"0"表示它使用与前一四边形相同的图元。掩码是15位而非16位,因为波前中的第一个四边形总是开始一个新图元,因此不包含在掩码中。
10.3.3 数据共享的索引和原子访问
LDS和GDS都可以执行索引和原子数据共享操作。为简洁起见,下文使用"LDS",除非特别说明,否则也适用于GDS。
索引和原子操作通过VGPR向LDS提供每个工作项的唯一地址,并将每个工作项的唯一数据提供给VGPR或从VGPR返回。由于LDS内部的分库结构,操作最快可在两个周期内完成,最多可能需要64个周期,具体取决于存储体冲突(映射到同一内存存储体的地址)的数量。
索引操作是简单的LDS加载和存储操作,从VGPR读取数据或将数据返回到VGPR。
原子操作是算术操作,将VGPR的数据与LDS中的数据结合,并将结果写回LDS。原子操作可以选择将LDS的"操作前"值返回到VGPR。
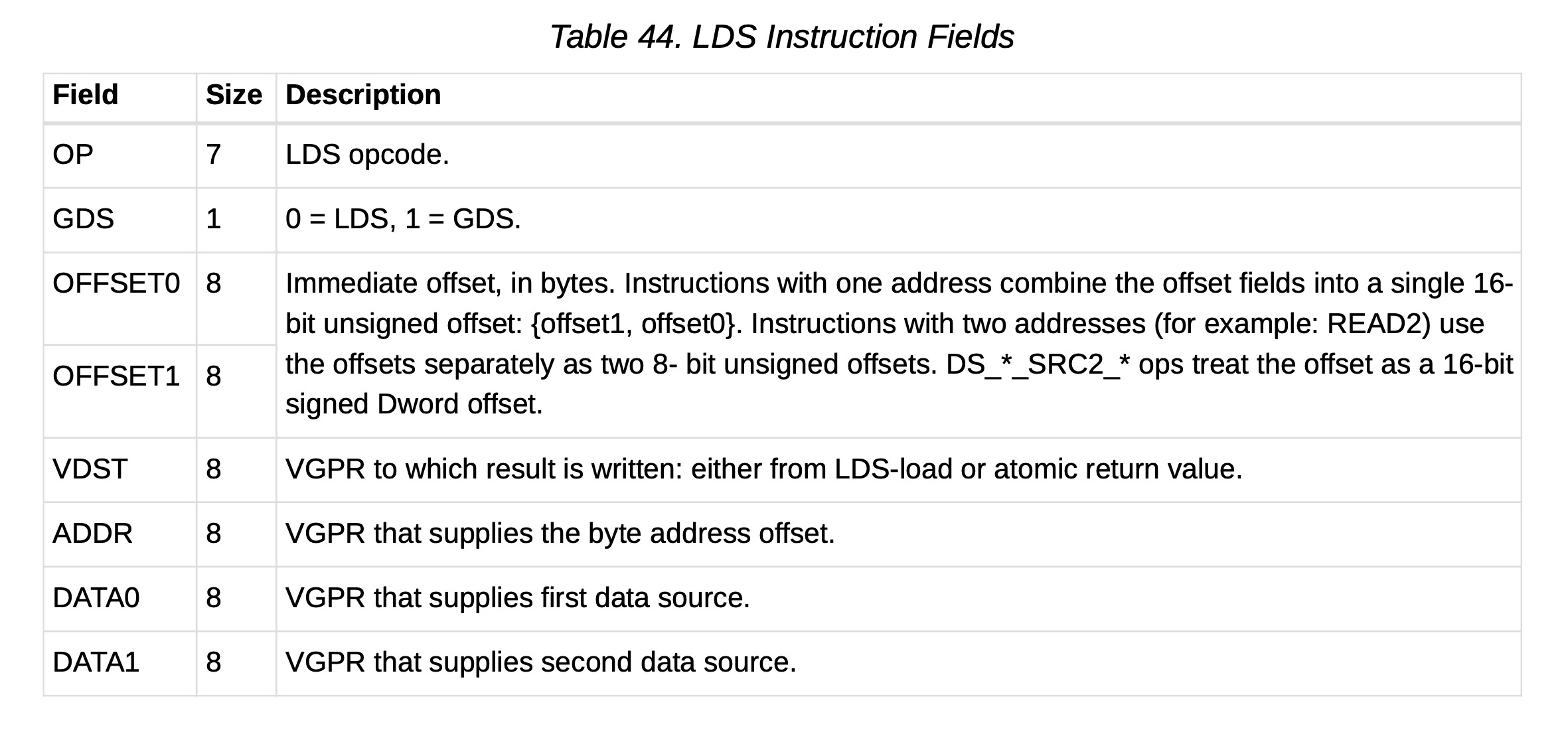
下表列出并简要描述了LDS指令字段。
(表44:LDS指令字段)
所有LDS操作都需要在使用前初始化M0。M0包含一个大小值,可用于将访问限制在分配的LDS范围的子集内。如果不需要限制,则将M0设置为0xFFFFFFFF。
(表45:LDS索引加载/存储)

单地址指令
LDS_Addr = LDS_BASE + VGPR[ADDR] + {InstrOffset1,InstrOffset0}双地址指令
LDS_Addr0 = LDS_BASE + VGPR[ADDR] + InstrOffset0*ADJ +
LDS_Addr1 = LDS_BASE + VGPR[ADDR] + InstrOffset1*ADJ
Where ADJ = 4 for 8, 16 and 32-bit data types; and ADJ = 8 for 64-bit.其中,对于8、16和32位数据类型,ADJ = 4;对于64位数据类型,ADJ = 8。
注意,LDS_ADDR1仅用于READ2*、WRITE2*和WREXCHG2*。
M0[15:0] 提供了此次访问的字节大小。发送到LDS的大小是 MIN(M0, LDS_SIZE),其中LDS_SIZE是着色器处理器插值器(SPI)在波前创建时分配的LDS空间量。
地址来自VGPR,ADDR和InstrOffset都是字节地址。
在 wavefront 创建时,LDS_BASE被分配给此波前或工作组拥有的物理LDS区域。
通过将两个偏移量设置为相同的值来指定单个地址。这会导致只发生一次读取或写入,并且仅使用第一个DATA0。
SRC2操作
ds_<op>_src2_<type> 操作码是不同的。这些操作数对LDS内存中的两个操作数执行原子操作:一个被视为数据,另一个是第二个源操作数和最终目的地。这些操作的寻址可以根据offset17的最高有效位(MSB)以两种不同的模式运行:
如果为0,则数据项的偏移量由偏移字段作为有符号双字偏移量导出:
LDS_Addr0 = LDS_BASE + VGPR(ADDR) + SIGNEXTEND(InstrOffset1[6:0],InstrOffset0))<<2 // data
term
LDS_Addr1 = LDS_BASE + VGPR(ADDR) // second source and final destination
address如果该位为1,则数据项的偏移量变为每个线程的偏移量,并且是一个从VGPR为索引读取的MSB导出的有符号双字偏移量。寻址变为:
LDS_Addr0 = LDS_BASE + VGPR(ADDR)[16:0] + SIGNEXTEND(VGPR(ADDR)[31:17])<<2 // data term
LDS_Addr1 = LDS_BASE + VGPR(ADDR)[16:0] // second source and final destination addressLDS原子操作
DS_<atomicOp> OP, GDS=0, OFFSET0, OFFSET1, VDST, ADDR, Data0, Data1
数据大小在atomicOp中编码:字节、字、双字或双精度。
LDS_Addr0 = LDS_BASE + VGPR[ADDR] + {InstrOffset1,InstrOffset0} ADDR是一个双字地址。对于双精度数据,VGPR 0、1和dst是双GPR。VGPR数据源只能是VGPR或常数值,不能是SGPR。