目录
[1.1 国内](#1.1 国内)
[1.1.1 秘塔搜索API](#1.1.1 秘塔搜索API)
[1、API Server](#1、API Server)
[2、MCP Servers](#2、MCP Servers)
[1.1.2 腾讯云联网搜索API](#1.1.2 腾讯云联网搜索API)
[1.1.3 博查Web Search API](#1.1.3 博查Web Search API)
[1、Web search API](#1、Web search API)
[2、AI Search API](#2、AI Search API)
[3、Agent Search API](#3、Agent Search API)
[4、Semantic Reranker API](#4、Semantic Reranker API)
[1.1.4 数眼智能搜索API](#1.1.4 数眼智能搜索API)
[1.1.5 智谱AI Web Search Pro](#1.1.5 智谱AI Web Search Pro)
[【API Server】](#【API Server】)
[【MCP Server】](#【MCP Server】)
[1.2 国外](#1.2 国外)
[1.2.1 Tavily](#1.2.1 Tavily)
[3、Tavily MCP Server](#3、Tavily MCP Server)
[2、Exa MCP](#2、Exa MCP)
[方式一:远程Exa MCP(推荐)](#方式一:远程Exa MCP(推荐))
[方式二:配置 Claude 桌面](#方式二:配置 Claude 桌面)
[5、实战应用一:测试调用Exa MCP](#5、实战应用一:测试调用Exa MCP)
[6、实战应用二:UI对话(Exa MCP)](#6、实战应用二:UI对话(Exa MCP))
[1.3 主流联网搜索API对比](#1.3 主流联网搜索API对比)

前言
-
追求快速验证想法 :如果目标是用DeepSeek快速做一个能联网的Demo或内部工具,首选腾讯云平台。它能让你在几分钟内就搭出一个联网应用,免去了自己组合、调试API的麻烦。
-
需要高灵活性与全球信息 :如果你的应用场景多样,或需要全球、多语言信息,应该选择通用网页搜索API 。可以从微软的Bing Web Search API或国内的**博查API(侧重中文)**入手,它们都有相对完善的文档和开发者计划。
-
构建复杂AI助手 :如果目标是开发需要深度思考、自主规划查询步骤的AI智能体,那么Tavily或**Exa.ai**这类AI优化API是更专业的选择。
注:部分通用搜索API(如SerpApi、Serply、Zenserp等)会提供免费额度,适合前期测试。
一、搜索引擎选择
1.1 国内
国内有不少适配中文场景、兼顾合规性与易用性的联网搜索API,适配个人开发、企业项目等不同需求,以下几款口碑和实用性拉满,具体信息如下:
1.1.1 秘塔搜索API
有100K的免费token可以,调用简单,可作为快速开发验证使用;
官网地址: 秘塔AI API Key 密钥:深度解析与应用指南 - 幂简集成
查看APIkey:幂简集成
集成了3种场景的APIkey,每个场景配置了3个接口。
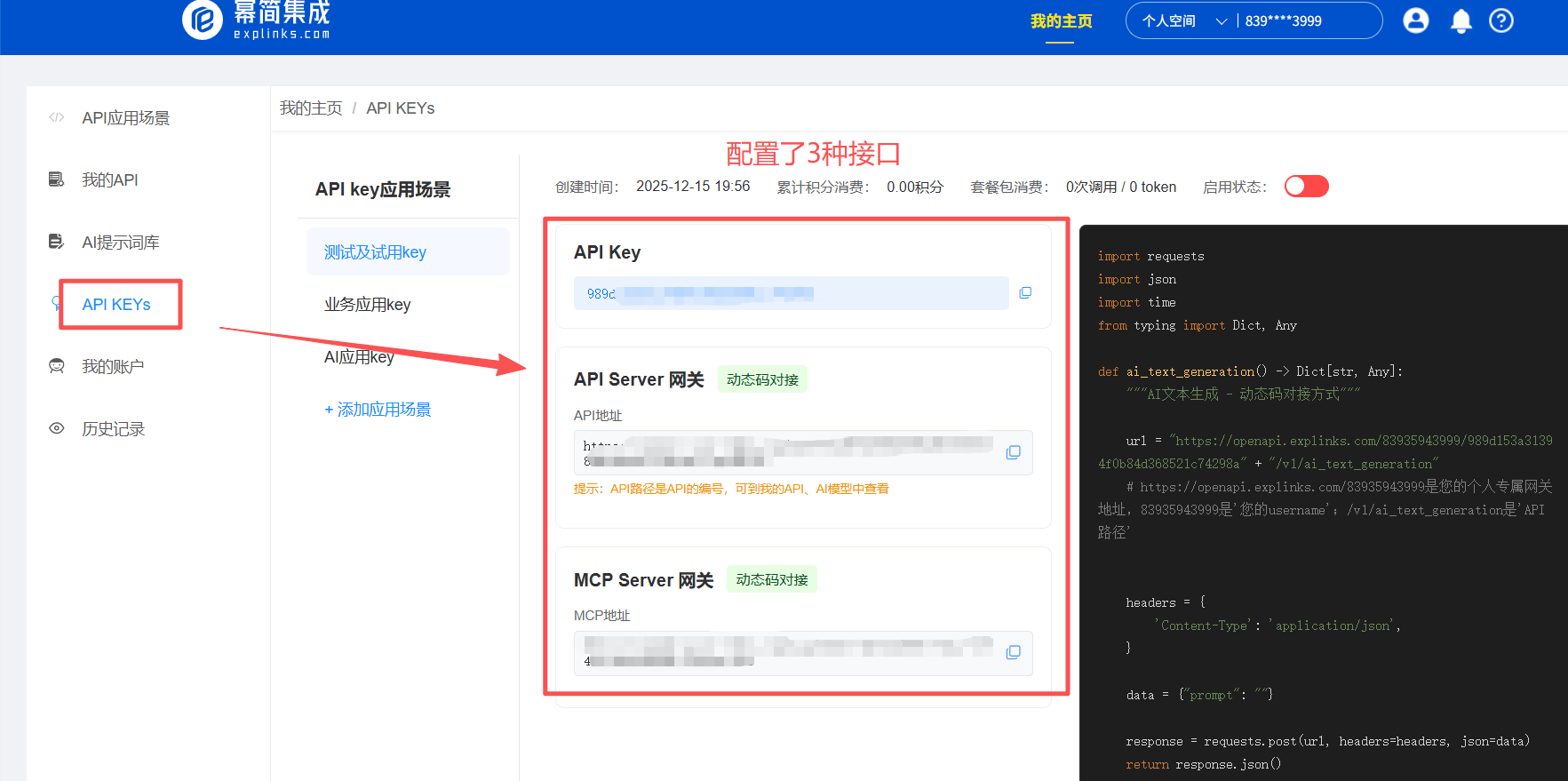
对个人和中小团队很友好,登录metaso.cn就能领API Key和5000点免费额度,测试阶段0.03元就能请求一次。支持网页、图片、播客等多模态内容检索,还有网页全文获取(自动清洗广告,返回Markdown格式正文)、AI总结问答等功能,适配知识库构建、LLM工作流接入等场景,还提供Python/Node.js示例代码快速对接。
1、API Server
python
import requests
import json
import time
from typing import Dict, Any
def ai_text_generation() -> Dict[str, Any]:
"""AI文本生成 - 动态码对接方式"""
url = "https://openapi.explinks.com/83935943999/989d153a31394f0b84d368521c74298a" + "/v1/ai_text_generation"
# https://openapi.explinks.com/83935943999是您的个人专属网关地址,83935943999是'您的username';/v1/ai_text_generation是'API路径'
headers = {
'Content-Type': 'application/json',
}
data = {"prompt": ""}
response = requests.post(url, headers=headers, json=data)
return response.json()2、MCP Servers
python
from openai import OpenAI
client = OpenAI()
resp = client.responses.create(
model="gpt-4.1",
tools=[
{
"type": "mcp",
"server_label": "explinks-server",
"server_url": "https://openmcp.explinks.com/mcp/83935943999/989d153a31394f0b84d368521c74298a/sse",
"require_approval": "never",
},
],
input="Hello Explinks!",
)1.1.2 腾讯云联网搜索API
源自搜狗搜索,依托腾讯分布式计算,响应最快达300ms。覆盖搜狗百科、腾讯新闻等优质资源,支持指定网址、时间范围检索,分标准版(46元/千次)和尊享版(80元/千次),尊享版可返回50条结果还能指定垂域搜索,已应用在腾讯元宝、QQ浏览器等产品,适合企业级稳定需求。
官网地址: 访问管理 - 控制台
按次计费
【如何调用】
【python示例】
python# -*- coding: utf8 -*- # Copyright (c) 2017-2025 Tencent. All Rights Reserved. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. import json from tencentcloud.common.exception.tencent_cloud_sdk_exception import TencentCloudSDKException from tencentcloud.common.abstract_client import AbstractClient from tencentcloud.wsa.v20250508 import models class WsaClient(AbstractClient): _apiVersion = '2025-05-08' _endpoint = 'wsa.tencentcloudapi.com' _service = 'wsa' def SearchPro(self, request): r"""联网搜索API,以JSON形式向客户提供搜索结果数据,包含标题、摘要、内容来源url等信息 :param request: Request instance for SearchPro. :type request: :class:`tencentcloud.wsa.v20250508.models.SearchProRequest` :rtype: :class:`tencentcloud.wsa.v20250508.models.SearchProResponse` """ try: params = request._serialize() headers = request.headers body = self.call("SearchPro", params, headers=headers) response = json.loads(body) model = models.SearchProResponse() model._deserialize(response["Response"]) return model except Exception as e: if isinstance(e, TencentCloudSDKException): raise else: raise TencentCloudSDKException(type(e).__name__, str(e))

1.1.3 博查Web Search API
国内备案产品,数据不出海符合合规要求,微信扫码登录open.bochaai.com就能创建API Key。提供Web、AI、Agent、三款搜索API,支持设置搜索时间范围和长文本摘要输出,适配AI应用和RAG开发,还给出了Python、curl等调用示例代码,采用阶梯收费,充值越多可用次数和并发量越高。
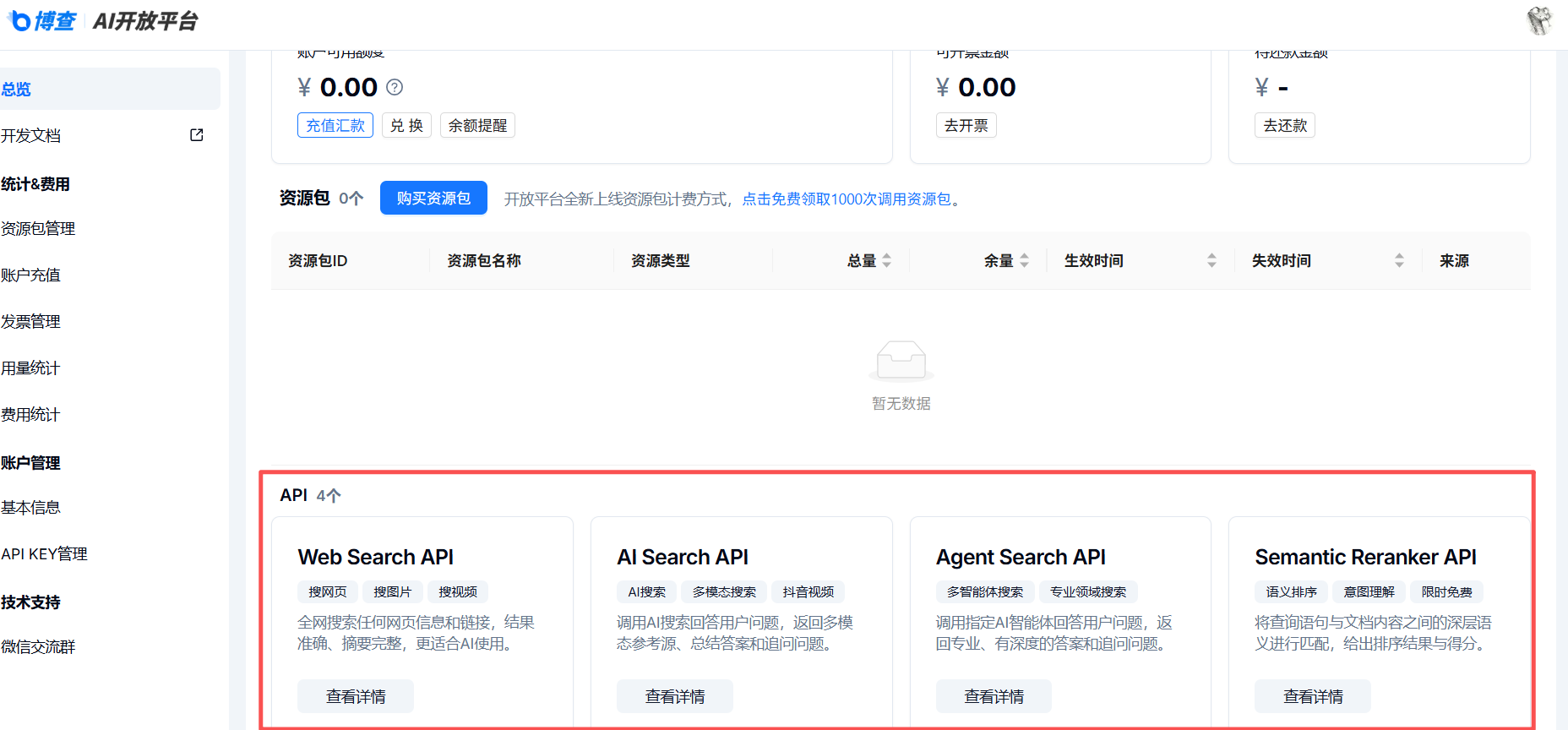
【API接口介绍】
说明:以下内容取自官网文档内容(更新时间:2025年11月15日)
阅读地址: 什么是给AI用的搜索引擎? - 飞书云文档
博查专门设计了一个给人工智能用的搜索引擎,为人工智能产业提供世界知识搜索服务,一句话说就是:"全球通。比如,在人工智能对话、人工智能搜索、人工智能智能体等人工智能应用的开发过程中,均需要引入搜索用人工智能引擎"'接口来提供实时信息,增强检索并且降低大模型的幻觉。国内目前只有博查提供专为人工智能使用的搜索服务。
博查提供3种搜索应用程序,通过完整搜索引擎与多种合作内容源,提供世界知识搜索服务。内容包含网页链接和超长文本摘要,更适合人工智能使用且符合国内规范。
1、Web search API
-- 为你的AI应用提供联网搜索能力,从全网搜索网页、视频、图片等;
▲从全网搜索任何网页信息和网页链接,结果准确、摘要完整,更适合AI使用。
▲可配置搜索时间范围、是否显示摘要,支持按分页获取更多结果。
搜索结果:
包括网页、图片、视频,Response格式兼容Bing Search API。
- 网页包括name、url、snippet、summary、siteName、siteIcon、datePublished等信息
图片包括 contentUrl、hostPageUrl、width、height等信息
视频搜索目前在WebSearch中暂未开放
pythonAPI接口 接口域名:https://api.bocha.cn/ EndPoint:https://api.bocha.cn/v1/web-search2、AI Search API
-- 为你的AI应用提供多模态参考源、总结答案和追问问题,在全网搜索的基础上,提供抖音视频、头条新闻、西瓜视频、微博、百科等内容源,并且提供AI总结的答案与追问问题;
▲调用AI搜索回答用户问题,返回网页、图片、多模态参考源(模态卡)、总结答案和追问问题。
▲搜索全网信息,同时根据搜索词自动获取垂域结构化数据,可开启大模型实时生成答案和追问问题,支持流式输出,每次搜索返回的参考网页最多支持50条(count50)。
搜索结果:
网页:返回最多50条网页信息,含摘要。
图片:网页中附带的图片。
模态卡:例如天气、百科、医疗、万年历、火车、星座属相、贵金属、汇率、油价、手机、股票、汽车等。
pythonAPI接口 接口域名:https://api.bocha.cn EndPoint:https://api.bocha.cn/v1/ai-search3、Agent Search API
-- 为你的AI应用提供专业领域参考源、有深度的答案和追问问题。
▲调用指定AI智能体回答用户问题,返回专业、有深度的答案和追问问题。
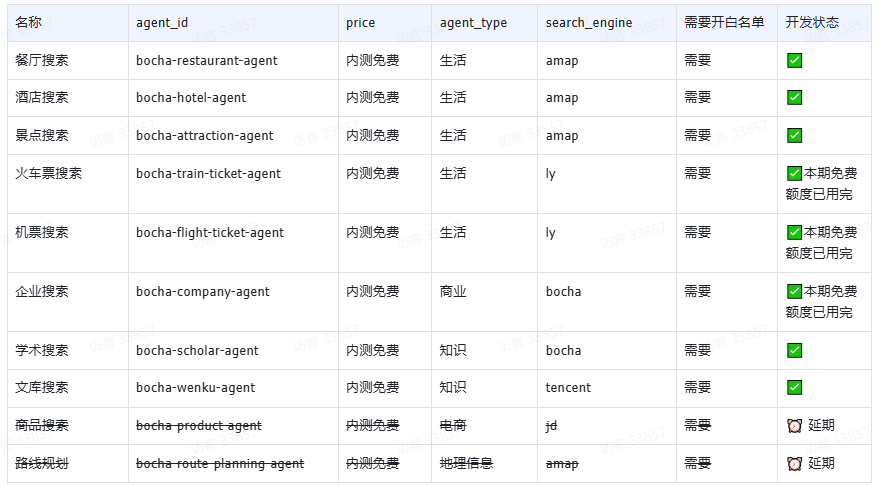
智能体列表:
请求示例
pythonAPI接口 接口域名:https://api.bocha.cn EndPoint:https://api.bocha.cn/v1/agent-search4、Semantic Reranker API
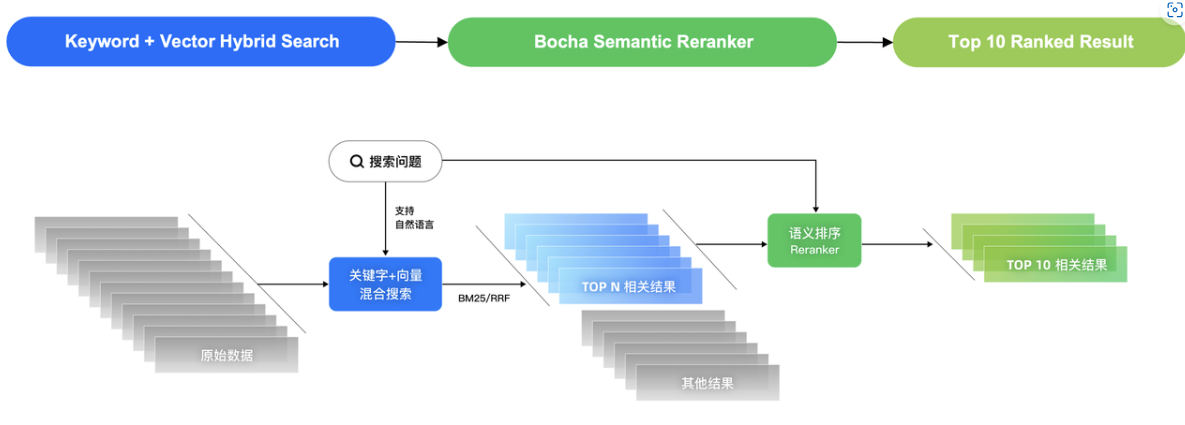
Bocha Semantic Reranker是一种基于文本语义的排序模型(Rerank Model),它的主要用途是提升搜索结果的质量。在搜索推荐系统中,Bocha Semantic Reranker可以基于关键字搜索、向量搜索和混合搜索的初步排序结果的质量进行优化。具体来说,在初始的BM25排序或RRF排序之后,Bocha Semantic Reranker会从top-N候选结果中,利用语义信息对文档进行二次排序。这一过程中,模型会根据查询语句与文档内容之间的深层语义匹配情况,给出每个文档的排序结果和得分,从而改善用户的搜索体验。由于这种方法是对初步排序结果进行二次优化,因此被称为"Reranker"。
评分原理
博查语义排序模型的评分过程是基于查询语句(用户的输入问题)以及与之匹配的文档内容(通常是最高512个tokens的文本)进行的。评分的过程如下:
评估语义相关性:模型会评估查询语句与每个文档的语义相关性,判断文档是否能够有效回答用户的查询或与查询意图高度匹配。
分配Rerank Score:根据语义相关性,模型为每个文档分配一个rerankScore,分数的范围从0到1。分数越高,表示文档与查询的语义相关性越强,越符合用户需求。通常,分数接近1表示高度相关,分数接近0表示不相关或低相关。
|-----------|---------------------------------------|
| Score | Meaning |
| 0.75~1 | 该文档高度相关并完全回答了问题,尽管可能包含与问题无关的额外文本。 |
| 0.5~0.75 | 该文档与问题是相关的,但缺乏使其完整的细节。 |
| 0.2~0.5 | 该文档与问题有一定的相关性;它部分回答了问题,或者只解决了问题的某些方面。 |
| 0.1~0.2 | 该文档与问题相关,但仅回答了一小部分。 |
| 0~0.1 | 该文档与问题无关紧要。 |排序效果
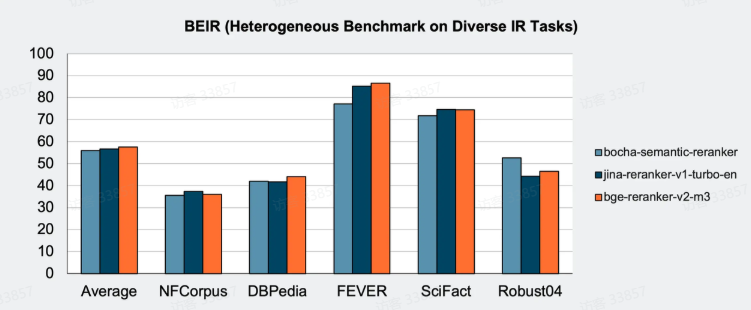
以 80M 参数实现接近于世界一线 280M、560M参数模型的排序效果,推理速度更快、成本更低。
由于模型版本会持续迭代及更新,官方API使用的reranker模型版本参与测评版本并不完全相同。API中使用的模型效果更好。
pythonAPI接口 接口域名:https://api.bocha.cn EndPoint:https://api.bocha.cn/v1/rerank

1.1.4 数眼智能搜索API
官网地址: 数眼智能-基于AI的企业级数据解决方案提供商---超越代码新视界!
控制台: 总览 - 控制台
中文场景适配性强,主打"搜索+解析"一体化,支持JS动态渲染网页解析,还能做物体识别等视觉类搜索。结果经过合规校验,减少数据清洗成本,同时提供多行业定制化数据集,很适合舆情监控、RAG检索增强等企业级中文动态网页相关场景。
【核心接入代码】
使用 Python 内置urllib库(无需额外安装),直接复制即可运行:
pythonimport urllib.parse import urllib.request import json def shuyan_search(query, api_key): # 1. 构造请求参数 base_url = "http://shuyantech.com/api/qa" params = { "q": query, # 搜索问句(支持知识类、搜索类等问题) "apikey": api_key # 你的API密钥 } url = f"{base_url}?{urllib.parse.urlencode(params)}" # 2. 发送请求(内置库无需安装) try: response = urllib.request.urlopen(url, timeout=10) # 3. 解析响应 if response.getcode() == 200: result = json.loads(response.read().decode("utf-8")) if result["status"] == "ok": return { "answer": result["ret"]["answer"], # 核心答案 "related": result["ret"].get("others", []) # 相关补充信息 } else: return f"接口返回错误:{result['msg']}" else: return f"HTTP错误,状态码:{response.getcode()}" except Exception as e: return f"请求失败:{str(e)}" # 4. 测试调用 if __name__ == "__main__": API_KEY = "你的密钥" # 替换为实际密钥 TEST_QUERY = "TI9在哪里举办" # 搜索类问题示例 result = shuyan_search(TEST_QUERY, API_KEY) print("搜索结果:", result["answer"]) print("相关信息:", result["related"])
【测试验证】
替换密钥:将代码中API_KEY替换为你的实际密钥
运行代码:直接执行 Python 脚本,无需安装任何库
预期输出(以 TI9 问题为例):
搜索结果: 中国上海
相关信息: [("落户魔都!Valve宣布TI9将在中国上海举办...",), ...]若返回ok则接入成功,若提示fail检查密钥有效性或参数格式
【大模型集成思路】
将 API 结果喂给大模型,实现联网增强:
python# 以伪代码示例集成逻辑 def llm_with_search(llm, query, api_key): # 1. 判断是否需要联网(大模型生成搜索信号则触发) need_search = llm.generate(f"是否需要搜索回答:{query}") if need_search: # 2. 调用数眼搜索API search_result = shuyan_search(query, api_key) # 3. 构造增强prompt prompt = f"基于以下搜索结果回答:{search_result['answer']}\n问题:{query}" # 4. 大模型生成最终答案 return llm.generate(prompt) return llm.generate(query)
1.1.5 智谱AI Web Search Pro
官方文档: 联网搜索 - 智谱AI开放文档
在意图识别上表现突出,支持流式输出搜索结果,能和大模型高效融合,缓解大模型"幻觉问题"。目前有限时免费政策,性价比很高,适合需要与大模型搭配实现精准实时检索的开发场景。
【安装依赖】
python# 安装最新版本 pip install zai-sdk # 或指定版本 pip install zai-sdk==0.1.0
【API Server】
pythonfrom zai import ZhipuAiClient client = ZhipuAiClient(api_key="your-api-key") response = client.web_search.web_search( search_engine="search_pro", search_query="搜索2025年4月的财经新闻", count=15, # 返回结果的条数,范围1-50,默认10 search_domain_filter="www.sohu.com", # 只访问指定域名的内容 search_recency_filter="noLimit", # 搜索指定日期范围内的内容 content_size="high" # 控制网页摘要的字数,默认medium ) print(response)
【MCP Server】
访问官方MCP文档了解更多关于该协议的信息。
配置 MCP 服务器
{ "mcpServers": { "zhipu-web-search-sse": { "url": "https://open.bigmodel.cn/api/mcp-broker/proxy/web-search/mcp?Authorization=Your Zhipu API Key" } } }对话示例:
pythonfrom zai import ZhipuAiClient client = ZhipuAiClient(api_key="your-api-key") # 定义工具参数 tools = [{ "type": "web_search", "web_search": { "enable": "True", "search_engine": "search_pro", "search_result": "True", "search_prompt": "你是一位财经分析师。请用简洁的语言总结网络搜索{search_result}中的关键信息,按重要性排序并引用来源日期。今天的日期是2025年4月11日。", "count": "5", "search_domain_filter": "www.sohu.com", "search_recency_filter": "noLimit", "content_size": "high" } }] # 定义用户消息 messages = [{ "role": "user", "content": "2025年4月的重要财经事件、政策变化和市场数据" }] # 调用API获取响应 response = client.chat.completions.create( model="glm-4-air", # 模型标识符 messages=messages, # 用户消息 tools=tools # 工具参数 ) # 打印响应结果 print(response)
1.2 国外
1.2.1 Tavily
官网地址: Tavily API Platform
【特色】
- 快速结果:Tavily 的 API 提供快速响应,是实时聊天体验的关键。
- 智能参数选择:利用 LangChain 集成,基于对话上下文动态选择 API 参数。专门为智能系统设计。你只需要一个自然语言输入,不需要为我们的API配置结构化JSON。
- 内容摘要:Tavily 提供现场搜索结果的简洁摘要,最适合在低延迟、多回合应用中保持小上下文大小。
- 来源归属:所有搜索、提取和爬取结果均包含URL,便于引用的实现,提高回答的透明度和可信度。
【可用工具】
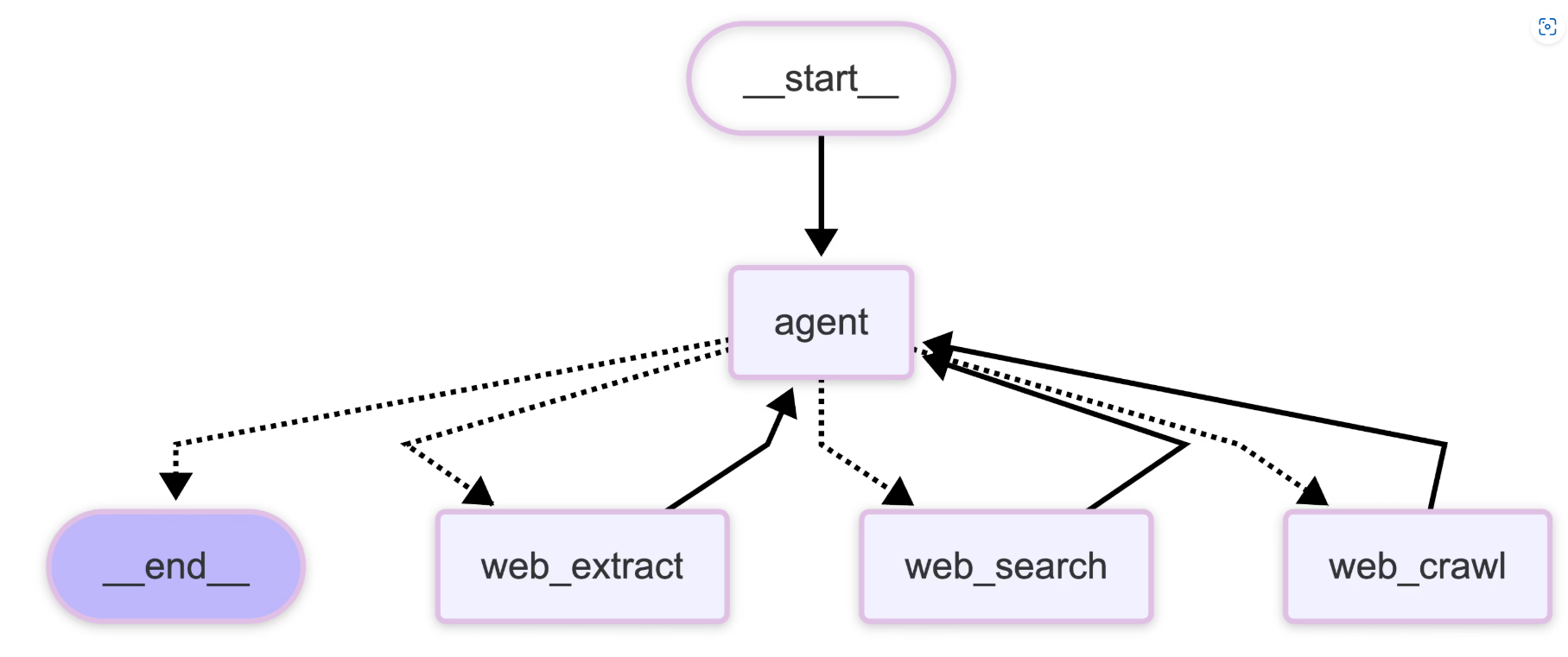
工具 功能 Tavily Search 为 AI 优化的实时网络搜索,支持 basic/advanced 搜索深度、主题过滤、域名控制等 Tavily Extract 从指定 URL 提取网页内容,支持批量提取(最多 20 个 URL) Tavily Crawl 智能网站爬取,可并行探索数百条路径,内置内容提取 Tavily Map 网站结构发现和映射,生成全面的站点地图 Tavily Research 综合研究 API,进行多次搜索并生成详细研究报告 在 LangChain/LangGraph 中使用:
pythonfrom langchain_tavily import TavilySearch, TavilyExtract, TavilyCrawl search = TavilySearch(max_results=5) extract = TavilyExtract() crawl = TavilyCrawl()处理流程:
详情说明:聊天 - 塔维利·多克斯
1、安装依赖
#python直接调用
pip install tavily-python
#langgraph和langchain安装这个
pip install -U langchain-tavily
#lamaindex安装这个
pip install llama-index-tools-tavily-research llama-index llama-hub tavily-python2、API调用示例
▲python直接调用
pythonfrom tavily import TavilyClient tavily_client = TavilyClient(api_key="tvly-YOUR_API_KEY") #替换tvly的API_key response = tavily_client.search("Who is Leo Messi?") print(response)▲langchain框架调用
python# !pip install -qU langchain langchain-openai langchain-tavily from langchain.agents import create_agent from langchain_openai import ChatOpenAI from langchain_tavily import TavilySearch # Initialize the Tavily Search tool tavily_search = TavilySearch(max_results=5, topic="general") # Initialize the agent with the search tool agent = create_agent( model=ChatOpenAI(model="gpt-5"), tools=[tavily_search], system_prompt="You are a helpful research assistant. Use web search to find accurate, up-to-date information." ) # Use the agent response = agent.invoke({ "messages": [{"role": "user", "content": "What is the most popular sport in the world? Include only Wikipedia sources."}] })▲langgraph框架调用
pythonfrom langchain_tavily import TavilySearch, TavilyExtract, TavilyCrawl from langgraph.prebuilt import create_react_agent from langgraph.checkpoint.memory import MemorySaver from langchain_openai import ChatOpenAI import os # 设置 API 密钥 os.environ["TAVILY_API_KEY"] = "your-tavily-api-key" os.environ["OPENAI_API_KEY"] = "your-openai-api-key" # 初始化 LLM llm = ChatOpenAI(model="gpt-4.1-nano") # 初始化 Tavily 工具 search = TavilySearch(max_results=10, topic="general") extract = TavilyExtract(extract_depth="advanced") crawl = TavilyCrawl() # 定义系统提示 PROMPT = "你是一个有帮助的研究助手。使用 Tavily 搜索来查找准确的最新信息。" # 使用 MemorySaver 保持对话历史 checkpointer = MemorySaver() # 构建 ReAct 代理 agent = create_react_agent( prompt=PROMPT, model=llm, tools=[search, extract, crawl], checkpointer=checkpointer, ) # 运行对话 config = {"configurable": {"thread_id": "conversation-1"}} # 第一轮对话 response1 = agent.invoke( {"messages": [{"role": "user", "content": "2025年AI代理有什么新趋势?"}]}, config=config ) print(response1["messages"][-1].content) # 第二轮对话(保持上下文) response2 = agent.invoke( {"messages": [{"role": "user", "content": "能详细说说第一个趋势吗?"}]}, config=config ) print(response2["messages"][-1].content)▲llamaIndex框架调用
pythonfrom llama_index.tools.tavily_research.base import TavilyToolSpec from llama_index.agent.openai import OpenAIAgent tavily_tool = TavilyToolSpec( api_key='tvly-YOUR_API_KEY', ) agent = OpenAIAgent.from_tools(tavily_tool.to_tool_list()) agent.chat('What happened in the latest Burning Man festival?')
3、Tavily MCP Server
▲远程连接mcp服务
利用 Tavily MCP 最简单的方法是使用远程 URL。这提供了无缝的体验,无需本地安装或配置。只需使用远程 MCP 服务器的 URL 与您的 Tavily API 密钥一起使用:
dark-plushttps://mcp.tavily.com/mcp/?tavilyApiKey=<your-api-key>获取您的 Tavily API 密钥tavily.com.
▲mcp服务配置:server_concig.py
python{ "mcpServers": { "tavily-remote-mcp": { "command": "npx -y mcp-remote https://mcp.tavily.com/mcp/?tavilyApiKey=<your-api-key>", "env": {} } } }
▲使用示例
1、塔维利搜索示例
①一般网络搜索:
python你能搜索一下量子计算的最新发展吗?②新闻搜索:
python搜索过去7天内关于AI初创企业的新闻文章。③领域特定搜索:
python在nature.com和sciencedirect.com上搜索气候变化研究2、塔维利提取物示例
摘录文章内容:
python从本文中提取主要内容: https://example.com/article3、综合用法
python搜索过去7天内关于AI初创企业的新闻文章,并从每篇文章中提取主要内容以生成详细报告。
1.2.2 Exa.ai
Exa.ai 工具集更适合信息获取型任务(搜索、抓取、企业/人物调研),而非复杂计算、逻辑推理或创造性生成类任务。
优势: 适合需要多步分析、深度汇总的任务;适合针对企业、人物、职业背景等特定信息的查询;
劣势: 联网检索能力一般。如果是想要实时检索,这个实时能力不是很好,只能实现简单搜索。
官网地址: Exa | Web Search API, AI Search Engine, & Website Crawler
查看APIkey
【适用场景】
根据提供的工具列表,Exa.ai 提供的工具主要适用于以下三类场景:
实时网页信息检索与抓取
适合快速获取公开的网页信息、新闻、文章等,例如:
web_search_exa:适合一般性问题、事实查证。
crawling_exa:针对指定 URL 获取详细内容。
特定领域或平台的专业搜索
适合针对企业、人物、职业背景等特定信息的查询,例如:
company_research_exa:公司概况、业务总结。linkedin_search_exa:职场、人物背景信息。
复杂任务的研究支持
适合需要多步分析、深度汇总的任务,例如:
deep_researcher_start:启动深度研究任务(如行业分析、竞品调研)。
deep_researcher_check:查询长任务的结果。此外还包含一个面向开发场景的工具:
get_code_context_exa:适合检索代码片段、文档或技术解决方案。
1、快速构建API调用示例
①创建一个 .env 文件
在项目根创建一个调用的文件,添加以下一行。.env
python
EXA_API_KEY=your api key without quotes②安装 Python SDK
用 PIP 安装 Python SDK。如果你想把 API 密钥存档,务必安装 dotenv 库。.env
python
pip install exa-py
pip install openai
pip install python-dotenv③创建执行文件
安装好SDK后,创建一个python文件(exa.py),并添加下面的代码。
python
from exa_py import Exa
from dotenv import load_dotenv
import os
# Use .env to store your API key or paste it directly into the code
load_dotenv()
exa = Exa(os.getenv('EXA_API_KEY'))
result = exa.search_and_contents(
"An article about the state of AGI",
type="auto",
text=True,
)
print(result)2、Exa MCP
官网文档: Exa MCP - Exa
①mcp工具服务配置
使用基于HTTP的配置格式:
python
{
"mcpServers": {
"exa": {
"type": "http",
"url": "https://mcp.exa.ai/mcp",
"headers": {}
}
}
}Exa MCP 服务器使像 Claude 这样的 AI 助手能够通过 Exa Search API 进行实时网页搜索,从而访问互联网上的最新信息。它是开源的,可以看看GitHub.
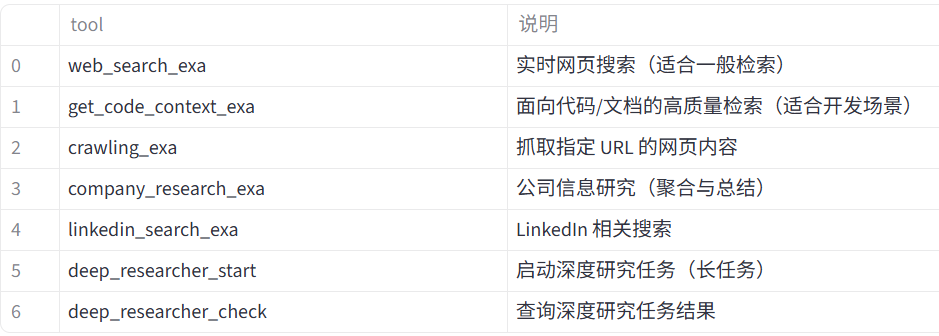
3、可用工具
注: 默认情况下,只有和是启用的。您可以使用该参数启用更多工具(见下方示例)。web_search_exa``get_code_context_exa``tools
Exa MCP 包含多个专门的搜索工具:
| 工具 | 描述 |
|---|---|
get_code_context_exa |
**新增功能!**搜索并获取开源库、GitHub仓库和编程框架中的相关代码片段、示例和文档。非常适合查找最新的代码文档、实现示例、API使用模式和真实代码库的最佳实践 |
web_search_exa |
执行实时网页搜索,优化结果并提取内容 |
deep_researcher_start |
创建一个针对复杂问题的智能人工智能研究者。AI会在网上搜索,阅读大量资料,并深入思考你的问题,从而生成详细的研究报告 |
deep_researcher_check |
检查你的研究是否准备好并获得结果。在开始研究任务后使用它,确认是否完成,并获得你的全面报告 |
company_research |
全面的公司调研工具,可爬取公司网站以收集企业详细信息 |
crawling |
从特定网址提取内容,适合阅读文章、PDF或任何网页,只要你有准确的URL。 |
linkedin_search |
在LinkedIn上搜索使用Exa AI的公司和个人。只需在查询中包含公司名称、个人姓名或特定的LinkedIn网址即可 |
4、如何调用工具
方式一:远程Exa MCP(推荐)
这种连接方式比较便捷,直接通过变换url上变动即可实现工具调用
▲Exa MCP服务连接
使用以下URL直接连接到Exa托管的MCP服务器:
pythonhttps://mcp.exa.ai/mcp▲Exa MCP服务连接并调用工具
可以使用参数启用特定工具(如果是多个,则使用逗号分隔的列表):
tools这里配置了网页搜索和编码两个工具
pythonhttps://mcp.exa.ai/mcp?tools=web_search_exa,get_code_context_exa或者启用所有工具:
pythonhttps://mcp.exa.ai/mcp?tools=web_search_exa,get_code_context_exa,crawling_exa,company_research_exa,linkedin_search_exa,deep_researcher_start,deep_researcher_check▲配置exa api密钥
pythonhttps://mcp.exa.ai/mcp?exaApiKey=YOUREXAKEY
方式二:配置 Claude 桌面
要配置 Claude Desktop 以使用 Exa MCP:
在 Claude 桌面中启用开发者模式
- Open Claude Desktop
- 点击左上角菜单
- 启用开发者模式
打开配置文件
- 启用开发者模式后,进入设置
- 进入开发者选项
- 点击"编辑配置"打开配置文件
或者,你也可以直接打开:macOS:
code ~/Library/Application\ Support/Claude/claude_desktop_config.jsonWindows:
code %APPDATA%\Claude\claude_desktop_config.json添加Exa MCP配置在你的配置中添加以下内容:
启用工具示例:
▲仅启用代码搜索(建议开发者使用)
python{ "mcpServers": { "exa": { "command": "npx", "args": [ "-y", "exa-mcp-server", "tools=get_code_context_exa" ], "env": { "EXA_API_KEY": "your-api-key-here" } } } }▲启用代码搜索和网页搜索
python{ "mcpServers": { "exa": { "command": "npx", "args": [ "-y", "exa-mcp-server", "tools=get_code_context_exa,web_search_exa" ], "env": { "EXA_API_KEY": "your-api-key-here" } } } }▲启用所有工具
python{ "mcpServers": { "exa": { "command": "npx", "args": [ "-y", "exa-mcp-server", "tools=web_search_exa,get_code_context_exa,crawling_exa,company_research_exa,linkedin_search_exa,deep_researcher_start,deep_researcher_check" ], "env": { "EXA_API_KEY": "your-api-key-here" } } } }
5、实战应用一:测试调用Exa MCP
安装依赖:
pythonpip install exa-py pip install openai pip install python-dotenv pip install mcp
①配置exa MCP服务:servers_config.json
这里配置了两个工具:web_search_exa,get_code_context_exa
python
{
"mcpServers": {
"exa": {
"type": "http",
"url": "https://mcp.exa.ai/mcp?tools=web_search_exa,get_code_context_exa&exaApiKey=YOUR_EXA_API_KEY",
"transport": "streamable_http",
"headers": {}
}
}
}②API配置:.env
填写自己的APIkey
python
EXA_API_KEY=d9c61**********③运行脚本
示例1:exa_mcp_multiturn_demo.py
python
import asyncio
import json
import os
from pathlib import Path
from typing import Any, Dict, Optional, Tuple
try:
from dotenv import load_dotenv
except ModuleNotFoundError as e:
raise SystemExit(
"缺少依赖 python-dotenv。请先在当前 conda 环境执行:\n"
"python -m pip install python-dotenv\n"
) from e
try:
from mcp import ClientSession
from mcp.client.streamable_http import streamablehttp_client
except ModuleNotFoundError as e:
raise SystemExit(
"缺少依赖 mcp(MCP Python SDK)。请先在当前 conda 环境执行:\n"
"python -m pip install mcp\n"
) from e
BASE_DIR = Path(__file__).resolve().parent
def _safe_json_dumps(obj: Any) -> str:
return json.dumps(obj, ensure_ascii=False, indent=2, default=str)
def _mask_exa_key(value: str) -> str:
if not value:
return value
if len(value) <= 8:
return "****"
return value[:4] + "****" + value[-4:]
def _extract_text_from_mcp_result(result: Any) -> str:
if result is None:
return ""
if isinstance(result, str):
return result
content = getattr(result, "content", None)
if isinstance(content, list):
texts = []
for item in content:
t = getattr(item, "text", None)
if isinstance(t, str):
texts.append(t)
continue
if isinstance(item, dict) and isinstance(item.get("text"), str):
texts.append(item["text"])
if texts:
return "\n".join(texts)
try:
return _safe_json_dumps(result)
except Exception:
return str(result)
def _try_parse_json(text: str) -> Optional[Any]:
if not text:
return None
try:
return json.loads(text)
except Exception:
return None
def _pick_first_url(parsed: Any) -> Optional[str]:
if isinstance(parsed, dict):
if isinstance(parsed.get("url"), str):
return parsed["url"]
results = parsed.get("results")
if isinstance(results, list) and results:
first = results[0]
if isinstance(first, dict) and isinstance(first.get("url"), str):
return first["url"]
if isinstance(parsed, list) and parsed:
first = parsed[0]
if isinstance(first, dict) and isinstance(first.get("url"), str):
return first["url"]
return None
def load_mcp_server_config() -> Tuple[str, Dict[str, Any]]:
with open(BASE_DIR / "servers_config.json", "r", encoding="utf-8") as f:
cfg = json.load(f)
mcp_servers = cfg.get("mcpServers") or {}
exa_cfg = mcp_servers.get("exa") or {}
url = exa_cfg.get("url")
if not isinstance(url, str) or not url.strip():
raise ValueError("servers_config.json 中未找到 mcpServers.exa.url")
return url.strip(), exa_cfg
def build_exa_mcp_url(base_url: str) -> str:
load_dotenv(dotenv_path=BASE_DIR / ".env")
exa_key = os.getenv("EXA_API_KEY", "").strip()
if "exaApiKey=" in base_url:
if exa_key and "YOUR_EXA_API_KEY" in base_url:
return base_url.replace("YOUR_EXA_API_KEY", exa_key)
return base_url
if not exa_key:
raise ValueError(
"未检测到 EXA_API_KEY。请在当前目录 .env 中设置 EXA_API_KEY=...,或在 servers_config.json 的 url 里加上 exaApiKey=..."
)
join_char = "&" if "?" in base_url else "?"
return f"{base_url}{join_char}exaApiKey={exa_key}"
def _print_title(title: str) -> None:
print("\n" + "=" * 70)
print(title)
print("=" * 70)
def _print_kv(title: str, value: str) -> None:
print(f"\n[{title}]")
print(value)
def _parse_tools_list(tools_response: Any) -> Dict[str, Dict[str, Any]]:
tools_by_name: Dict[str, Dict[str, Any]] = {}
for item in tools_response:
if isinstance(item, tuple) and len(item) == 2 and item[0] == "tools":
for tool in item[1]:
name = getattr(tool, "name", None)
if not isinstance(name, str):
continue
tools_by_name[name] = {
"description": getattr(tool, "description", ""),
"inputSchema": getattr(tool, "inputSchema", {}) or {},
}
return tools_by_name
def _select_tool(tools_by_name: Dict[str, Dict[str, Any]], candidates: Tuple[str, ...]) -> Optional[str]:
for c in candidates:
if c in tools_by_name:
return c
return None
def _build_tool_args(schema: Dict[str, Any], base_args: Dict[str, Any]) -> Dict[str, Any]:
props = schema.get("properties") if isinstance(schema, dict) else None
props = props if isinstance(props, dict) else {}
args: Dict[str, Any] = {}
for k, v in base_args.items():
if k in props:
args[k] = v
required = schema.get("required") if isinstance(schema, dict) else None
required = required if isinstance(required, list) else []
missing = [k for k in required if k not in args]
if missing:
raise ValueError(f"工具参数缺失 required 字段: {missing}. 你传入的参数: {list(base_args.keys())}")
return args
async def run_demo() -> None:
base_url, _ = load_mcp_server_config()
url = build_exa_mcp_url(base_url)
load_dotenv(dotenv_path=BASE_DIR / ".env")
exa_key = os.getenv("EXA_API_KEY", "").strip()
_print_title("Exa MCP 多轮对话示例(脚本演示版)")
_print_kv("MCP URL(已隐藏 key)", url.replace(exa_key, _mask_exa_key(exa_key)) if exa_key else url)
async with streamablehttp_client(url=url) as (read_stream, write_stream, _get_session_id):
async with ClientSession(read_stream, write_stream) as session:
capabilities = await session.initialize()
_print_kv("Server capabilities", _safe_json_dumps(getattr(capabilities, "capabilities", capabilities)))
tools_response = await session.list_tools()
tools_by_name = _parse_tools_list(tools_response)
_print_kv("可用工具列表", "\n".join(sorted(tools_by_name.keys())) or "(empty)")
search_tool = _select_tool(tools_by_name, ("web_search_exa", "deep_search_exa", "web_search"))
crawl_tool = _select_tool(tools_by_name, ("crawling_exa", "crawling"))
if not search_tool:
raise RuntimeError("没有找到可用的搜索工具(web_search_exa / deep_search_exa / web_search)")
_print_title("第 1 轮:用户提问 -> Assistant 调用搜索工具")
user_1 = "帮我搜一下:Model Context Protocol (MCP) 的最佳实践/教程,优先官方文档或高质量文章。"
_print_kv("User", user_1)
search_schema = tools_by_name[search_tool]["inputSchema"]
base_search_args = {
"query": user_1,
"num_results": 5,
"numResults": 5,
}
search_args = _build_tool_args(search_schema, base_search_args)
_print_kv("Tool Call", _safe_json_dumps({"tool": search_tool, "arguments": search_args}))
search_result = await session.call_tool(search_tool, search_args)
search_text = _extract_text_from_mcp_result(search_result)
parsed = _try_parse_json(search_text)
first_url = _pick_first_url(parsed)
_print_kv("Tool Raw Result(截断)", (search_text[:1200] + "...") if len(search_text) > 1200 else search_text)
_print_kv(
"Assistant(示例回复)",
"我已经完成检索,并拿到了候选文章列表。下一轮你可以指定其中一篇文章,我再抓取全文并提炼要点。",
)
_print_title("第 2 轮:用户追问 -> Assistant(可选)调用抓取工具")
user_2 = "从上面的结果里选一篇最权威的,抓取内容并用 3 条要点总结。"
_print_kv("User", user_2)
if not crawl_tool:
_print_kv(
"提示",
"当前 Exa MCP 未启用抓取工具(crawling_exa / crawling)。\n"
"你可以把 servers_config.json 的 url 改成:\n"
"https://mcp.exa.ai/mcp?tools=web_search_exa,crawling_exa&exaApiKey=YOUR_EXA_API_KEY\n"
"然后重新运行脚本。",
)
return
if not first_url:
_print_kv("提示", "未能从搜索结果中解析出 URL(可能是返回格式不同)。你可以直接在结果里复制 URL 再做抓取。")
return
crawl_schema = tools_by_name[crawl_tool]["inputSchema"]
base_crawl_args = {
"url": first_url,
"urls": [first_url],
}
crawl_args = _build_tool_args(crawl_schema, base_crawl_args)
_print_kv("Tool Call", _safe_json_dumps({"tool": crawl_tool, "arguments": crawl_args}))
crawl_result = await session.call_tool(crawl_tool, crawl_args)
crawl_text = _extract_text_from_mcp_result(crawl_result)
_print_kv("Tool Raw Result(截断)", (crawl_text[:1200] + "...") if len(crawl_text) > 1200 else crawl_text)
_print_kv(
"Assistant(示例回复)",
"我已抓取该页面内容。这里给一个演示式总结结构:\n"
"1) 解释 MCP 的核心概念与角色(Client/Server/Tools/Resources)。\n"
"2) 给出工具设计最佳实践:输入 schema 清晰、幂等、可重试、错误可解释。\n"
"3) 给出工程化建议:鉴权、超时/限流、日志与可观测性、版本兼容策略。\n\n"
f"参考链接:{first_url}",
)
if __name__ == "__main__":
asyncio.run(run_demo())运行结果:
python
======================================================================
Exa MCP 多轮对话示例(脚本演示版)
======================================================================
[MCP URL(已隐藏 key)]
https://mcp.exa.ai/mcp?tools=web_search_exa,get_code_context_exa&exaApiKey=d9c6****17b9
[Server capabilities]
"experimental=None logging=None prompts=PromptsCapability(listChanged=True) resources=ResourcesCapability(subscribe=None, listChanged=True) tools=ToolsCapability(listChanged=True) completions=CompletionsCapability() tasks=None"
[可用工具列表]
get_code_context_exa
web_search_exa
======================================================================
第 1 轮:用户提问 -> Assistant 调用搜索工具
======================================================================
[User]
帮我搜一下:Model Context Protocol (MCP) 的最佳实践/教程,优先官方文档或高质量文章。
[Tool Call]
{
"tool": "web_search_exa",
"arguments": {
"query": "帮我搜一下:Model Context Protocol (MCP) 的最佳实践/教程,优先官方文档或高质量文
章。",
"numResults": 5
}
}
[Tool Raw Result(截断)]
Title: MCP中文文档
Published Date: 2024-12-12T02:45:10.000Z
URL: https://modelcontextprotocol.info/zh-cn/docs
Text: MCP中文文档 --Model Context Protocol (MCP)
CTRL K
* [MCP中文文档](https://modelcontextprotocol.info/zh-cn/docs/)
* [快速入门](#快速入门)
* [核心概念](#核心概念)
* [为什么选择 MCP?](#为什么选择-mcp)
* [MCP协议:AI时代的上下文集成革命](https://modelcontextprotocol.info/zh-cn/docs/introduction/)* [MCP 学习路径:从零基础到精通](https://modelcontextprotocol.info/zh-cn/docs/learning-path/)
* [快速入门](https://modelcontextprotocol.info/zh-cn/docs/quickstart/)
* [指南](https://modelcontextprotocol.info/zh-cn/docs/quickstart/guide/)
* [服务器开发](https://modelcontextprotocol.info/zh-cn/docs/quickstart/server/)
* [客户端开发](https://modelcontextprotocol.info/zh-cn/docs/quickstart/client/)
* [用户端](https://modelcontextprotocol.info/zh-cn/docs/quickstart/user/)
* [快速入门](https://modelcontextprotocol.info/zh-cn/docs/quickstart/quickstart/)
* [核心概念](https://modelcontextprotocol.info/zh-cn/docs/concepts/)
* [采样](https://modelcontextprotocol.info/zh-cn/docs/concepts/sampling/)
* [传输](https://modelcontextprotocol.info/zh-cn/docs/concepts/transports/)
* [根目录](https://modelcontextprotocol.info/zh-cn/docs/concepts/roots/)
* [工具](https://modelcontextprotocol.info/z...
[Assistant(示例回复)]
我已经完成检索,并拿到了候选文章列表。下一轮你可以指定其中一篇文章,我再抓取全文并提炼要点。
======================================================================
第 2 轮:用户追问 -> Assistant(可选)调用抓取工具
======================================================================
[User]
从上面的结果里选一篇最权威的,抓取内容并用 3 条要点总结。
[提示]
当前 Exa MCP 未启用抓取工具(crawling_exa / crawling)。
你可以把 servers_config.json 的 url 改成:
https://mcp.exa.ai/mcp?tools=web_search_exa,crawling_exa&exaApiKey=YOUR_EXA_API_KEY
然后重新运行脚本。6、实战应用二:UI对话( Exa MCP**)**
安装依赖:
pythonpip install exa-py pip install openai pip install python-dotenv pip install mcp pip install streamlit
示例二:streamlit_deepseek_exa_chat.py
加了ui界面,实现多轮对话。但可以发现exa对国内的一些实时
新闻类搜索不太敏感
①配置文件: .env
python
EXA_API_KEY=d9c6191*******
DEEPSEEK_API_KEY=sk-d980d57********
DEEPSEEK_BASE_URL=https://api.deepseek.com
DEEPSEEK_MODEL=deepseek-chat②说明文档: ui_doc.py
python
import json
from pathlib import Path
from typing import Any, Dict, List, Optional
from urllib.parse import parse_qs, urlparse
import streamlit as st
def _safe_json(obj: Any) -> str:
return json.dumps(obj, ensure_ascii=False, indent=2, default=str)
def load_servers_config(base_dir: Path) -> Dict[str, Any]:
with open(base_dir / "servers_config.json", "r", encoding="utf-8") as f:
return json.load(f)
def get_exa_server_url(servers_cfg: Dict[str, Any]) -> str:
mcp_servers = servers_cfg.get("mcpServers") or {}
exa_cfg = mcp_servers.get("exa") or {}
url = exa_cfg.get("url")
if not isinstance(url, str) or not url.strip():
raise ValueError("servers_config.json 中未找到 mcpServers.exa.url")
return url.strip()
def parse_tools_from_exa_url(url: str) -> List[str]:
qs = parse_qs(urlparse(url).query)
tools_val = qs.get("tools")
if not tools_val:
return []
tools_raw = tools_val[0]
if not isinstance(tools_raw, str):
return []
return [t.strip() for t in tools_raw.split(",") if t.strip()]
def render_docs(base_dir: Path, app_filename: str = "streamlit_deepseek_exa_chat.py") -> None:
st.title("说明文档")
try:
servers_cfg = load_servers_config(base_dir)
exa_url = get_exa_server_url(servers_cfg)
enabled_tools = parse_tools_from_exa_url(exa_url)
except Exception as e:
st.error(f"读取 servers_config.json 失败:{e}")
return
st.subheader("1. 这个 UI 做什么")
st.markdown(
"""
本应用提供两个能力:
- DeepSeek 多轮对话(右侧聊天区)
- 可选:通过 Exa MCP 先联网检索,再把检索结果作为上下文喂给 DeepSeek(提高时效性与可引用性)
"""
)
st.subheader("2. 一键启动")
st.markdown("在 `client_web` 环境中执行:")
st.code(f"streamlit run {app_filename}")
st.subheader("3. 必要配置(.env)")
st.markdown("建议把 Key 放在 `exa_ai/.env`:")
st.code(
"\n".join(
[
"EXA_API_KEY=...",
"DEEPSEEK_API_KEY=...",
"DEEPSEEK_BASE_URL=https://api.deepseek.com",
"DEEPSEEK_MODEL=deepseek-chat",
]
)
)
st.subheader("4. Exa MCP 工具启用情况(来自 servers_config.json)")
st.markdown("当前 `mcpServers.exa.url`:")
st.code(exa_url)
if enabled_tools:
st.markdown("当前启用的 tools:")
st.code("\n".join(enabled_tools))
else:
st.warning("当前 URL 未解析到 tools 参数(tools=...)。")
st.subheader("5. 各工具用途速查")
tool_desc: Dict[str, str] = {
"web_search_exa": "实时网页搜索(适合一般检索)",
"get_code_context_exa": "面向代码/文档的高质量检索(适合开发场景)",
"crawling_exa": "抓取指定 URL 的网页内容",
"company_research_exa": "公司信息研究(聚合与总结)",
"linkedin_search_exa": "LinkedIn 相关搜索",
"deep_researcher_start": "启动深度研究任务(长任务)",
"deep_researcher_check": "查询深度研究任务结果",
"deep_search_exa": "更深层的搜索与摘要(如果启用)",
}
if enabled_tools:
rows = []
for t in enabled_tools:
rows.append({"tool": t, "说明": tool_desc.get(t, "(未内置说明)")})
st.table(rows)
else:
st.info("未检测到 tools= 参数,无法展示启用列表。")
st.subheader("6. 常见问题")
st.markdown(
"""
- 为什么联网搜索失败?
- 请确认已安装 `mcp`,并且 `EXA_API_KEY` 正确
- 如提示未启用 `web_search_exa`,请确认 `servers_config.json` 的 URL 里包含 `tools=web_search_exa`
- 为什么 DeepSeek 调用失败(401/403)?
- 基本都是 `DEEPSEEK_API_KEY` 不正确或余额/权限不足
- `DEEPSEEK_BASE_URL` 默认为 `https://api.deepseek.com`
- 为什么"深度研究"没跑起来?
- 深度研究通常是异步长任务:先 `deep_researcher_start`,之后多次 `deep_researcher_check`
"""
)
with st.expander("servers_config.json 原始内容", expanded=False):
st.code(_safe_json(servers_cfg), language="json")③ui对话脚本: streamlit_deepseek_exa_chat.py
运行命令:
streamlit run streamlit_deepseek_exa_chat.py
python
import asyncio
import json
import os
import threading
from pathlib import Path
from typing import Any, Dict, List, Optional, Tuple
import streamlit as st
from dotenv import load_dotenv
import ui_docs
try:
from openai import OpenAI
except ModuleNotFoundError as e:
raise SystemExit("缺少依赖 openai,请先安装:python -m pip install openai") from e
try:
from mcp import ClientSession
from mcp.client.streamable_http import streamablehttp_client
except ModuleNotFoundError:
ClientSession = None
streamablehttp_client = None
BASE_DIR = Path(__file__).resolve().parent
def _run_coro(coro):
try:
asyncio.get_running_loop()
except RuntimeError:
return asyncio.run(coro)
out: Dict[str, Any] = {}
def _worker():
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
try:
out["result"] = loop.run_until_complete(coro)
finally:
loop.close()
t = threading.Thread(target=_worker, daemon=True)
t.start()
t.join()
return out.get("result")
def _safe_json(obj: Any) -> str:
return json.dumps(obj, ensure_ascii=False, indent=2, default=str)
def _load_mcp_server_config() -> Tuple[str, Dict[str, Any]]:
with open(BASE_DIR / "servers_config.json", "r", encoding="utf-8") as f:
cfg = json.load(f)
mcp_servers = cfg.get("mcpServers") or {}
exa_cfg = mcp_servers.get("exa") or {}
url = exa_cfg.get("url")
if not isinstance(url, str) or not url.strip():
raise ValueError("servers_config.json 中未找到 mcpServers.exa.url")
return url.strip(), exa_cfg
def _build_exa_mcp_url(base_url: str) -> str:
load_dotenv(dotenv_path=BASE_DIR / ".env")
exa_key = os.getenv("EXA_API_KEY", "").strip()
if "exaApiKey=" in base_url:
if exa_key and "YOUR_EXA_API_KEY" in base_url:
return base_url.replace("YOUR_EXA_API_KEY", exa_key)
return base_url
if not exa_key:
raise ValueError("未检测到 EXA_API_KEY。请在 exa_ai/.env 中设置 EXA_API_KEY=...")
join_char = "&" if "?" in base_url else "?"
return f"{base_url}{join_char}exaApiKey={exa_key}"
def _extract_text_from_mcp_result(result: Any) -> str:
if result is None:
return ""
if isinstance(result, str):
return result
content = getattr(result, "content", None)
if isinstance(content, list):
texts: List[str] = []
for item in content:
t = getattr(item, "text", None)
if isinstance(t, str):
texts.append(t)
continue
if isinstance(item, dict) and isinstance(item.get("text"), str):
texts.append(item["text"])
if texts:
return "\n".join(texts)
try:
return _safe_json(result)
except Exception:
return str(result)
def _parse_search_results(raw_text: str) -> List[Dict[str, str]]:
try:
data = json.loads(raw_text)
except Exception:
return []
if isinstance(data, dict) and isinstance(data.get("results"), list):
results = data.get("results")
elif isinstance(data, list):
results = data
else:
results = []
cleaned: List[Dict[str, str]] = []
for r in results[:8]:
if not isinstance(r, dict):
continue
title = r.get("title") if isinstance(r.get("title"), str) else ""
url = r.get("url") if isinstance(r.get("url"), str) else ""
snippet = r.get("summary") if isinstance(r.get("summary"), str) else ""
if not snippet and isinstance(r.get("text"), str):
snippet = r.get("text")
cleaned.append({"title": title, "url": url, "snippet": snippet})
return cleaned
async def _exa_search_async(query: str, num_results: int) -> Tuple[List[Dict[str, str]], str]:
if ClientSession is None or streamablehttp_client is None:
raise RuntimeError("缺少依赖 mcp。请先安装:python -m pip install mcp")
base_url, _ = _load_mcp_server_config()
url = _build_exa_mcp_url(base_url)
async with streamablehttp_client(url=url) as (read_stream, write_stream, _):
async with ClientSession(read_stream, write_stream) as session:
await session.initialize()
tools = await session.list_tools()
tool_names: List[str] = []
for item in tools:
if isinstance(item, tuple) and len(item) == 2 and item[0] == "tools":
tool_names.extend([t.name for t in item[1] if hasattr(t, "name")])
if "web_search_exa" not in tool_names:
raise RuntimeError(f"Exa MCP 未启用 web_search_exa。当前 tools: {tool_names}")
result = await session.call_tool("web_search_exa", {"query": query, "num_results": num_results})
raw = _extract_text_from_mcp_result(result)
return _parse_search_results(raw), raw
def exa_search(query: str, num_results: int) -> Tuple[List[Dict[str, str]], str]:
return _run_coro(_exa_search_async(query, num_results))
def build_search_context(results: List[Dict[str, str]]) -> str:
if not results:
return "Web search results: (empty)"
lines = ["Web search results (from Exa MCP):"]
for i, r in enumerate(results, start=1):
title = r.get("title", "")
url = r.get("url", "")
snippet = (r.get("snippet", "") or "").strip()
if len(snippet) > 280:
snippet = snippet[:280] + "..."
lines.append(f"{i}. {title}\nURL: {url}\nSnippet: {snippet}")
return "\n\n".join(lines)
def deepseek_chat(messages: List[Dict[str, str]], api_key: str, base_url: str, model: str, temperature: float) -> str:
client = OpenAI(api_key=api_key, base_url=base_url)
resp = client.chat.completions.create(
model=model,
messages=messages,
temperature=temperature,
)
return resp.choices[0].message.content or ""
def _mcp_tools_to_openai_tools(tools_response: Any) -> List[Dict[str, Any]]:
out: List[Dict[str, Any]] = []
for item in tools_response:
if isinstance(item, tuple) and len(item) == 2 and item[0] == "tools":
for tool in item[1]:
name = getattr(tool, "name", None)
if not isinstance(name, str) or not name.strip():
continue
out.append(
{
"type": "function",
"function": {
"name": name,
"description": getattr(tool, "description", "") or "",
"parameters": getattr(tool, "inputSchema", {}) or {},
},
}
)
return out
async def _deepseek_agent_with_mcp_async(
user_visible_messages: List[Dict[str, str]],
api_key: str,
base_url: str,
model: str,
temperature: float,
max_tool_iterations: int,
) -> Tuple[str, List[Dict[str, Any]]]:
if ClientSession is None or streamablehttp_client is None:
raise RuntimeError("缺少依赖 mcp。请先安装:python -m pip install mcp")
mcp_base_url, _ = _load_mcp_server_config()
mcp_url = _build_exa_mcp_url(mcp_base_url)
client = OpenAI(api_key=api_key, base_url=base_url)
system_prompt = (
"你是一个严谨的中文助手。你具备一组可调用的工具(tools)。\n"
"当问题需要最新信息/网页内容/公司信息/LinkedIn/代码上下文时,优先调用合适的工具。\n"
"回答时尽量给出来源 URL(如果工具返回了 URL)。\n"
"如果不需要工具,直接回答。\n"
"深度研究是长任务:通常先调用 deep_researcher_start,再根据返回信息多次调用 deep_researcher_check。\n"
)
messages: List[Dict[str, Any]] = [{"role": "system", "content": system_prompt}]
for m in user_visible_messages:
if m.get("role") in ("user", "assistant") and isinstance(m.get("content"), str):
messages.append({"role": m["role"], "content": m["content"]})
tool_trace: List[Dict[str, Any]] = []
async with streamablehttp_client(url=mcp_url) as (read_stream, write_stream, _):
async with ClientSession(read_stream, write_stream) as session:
await session.initialize()
mcp_tools = await session.list_tools()
openai_tools = _mcp_tools_to_openai_tools(mcp_tools)
iteration = 0
while iteration < max_tool_iterations:
resp = client.chat.completions.create(
model=model,
messages=messages,
tools=openai_tools,
tool_choice="auto",
temperature=temperature,
)
msg = resp.choices[0].message
tool_calls = getattr(msg, "tool_calls", None)
content = getattr(msg, "content", None)
if tool_calls:
messages.append(
{
"role": "assistant",
"content": content or "",
"tool_calls": [
{
"id": tc.id,
"type": "function",
"function": {
"name": tc.function.name,
"arguments": tc.function.arguments,
},
}
for tc in tool_calls
],
}
)
for tc in tool_calls:
name = tc.function.name
args_text = tc.function.arguments or "{}"
try:
args = json.loads(args_text)
except Exception:
args = {}
result = await session.call_tool(name, args)
result_text = _extract_text_from_mcp_result(result)
tool_trace.append(
{
"tool": name,
"arguments": args,
"result_preview": (result_text[:1200] + "...") if len(result_text) > 1200 else result_text,
}
)
messages.append(
{
"role": "tool",
"tool_call_id": tc.id,
"content": result_text,
}
)
iteration += 1
continue
messages.append({"role": "assistant", "content": content or ""})
return content or "", tool_trace
return "", tool_trace
def deepseek_agent_with_mcp(
user_visible_messages: List[Dict[str, str]],
api_key: str,
base_url: str,
model: str,
temperature: float,
max_tool_iterations: int,
) -> Tuple[str, List[Dict[str, Any]]]:
return _run_coro(
_deepseek_agent_with_mcp_async(
user_visible_messages=user_visible_messages,
api_key=api_key,
base_url=base_url,
model=model,
temperature=temperature,
max_tool_iterations=max_tool_iterations,
)
)
def init_state() -> None:
if "messages" not in st.session_state:
st.session_state.messages = []
if "last_search" not in st.session_state:
st.session_state.last_search = None
if "last_tool_trace" not in st.session_state:
st.session_state.last_tool_trace = None
def main() -> None:
load_dotenv(dotenv_path=BASE_DIR / ".env")
st.set_page_config(page_title="DeepSeek + Exa MCP Chat", layout="wide")
init_state()
with st.sidebar:
mode = st.radio("页面", options=["对话", "说明文档"], index=0)
if mode == "说明文档":
ui_docs.render_docs(BASE_DIR)
return
st.title("DeepSeek 对话(可选 Exa 联网搜索)")
with st.sidebar:
st.subheader("DeepSeek 配置")
api_key_default = os.getenv("DEEPSEEK_API_KEY", "")
base_url_default = os.getenv("DEEPSEEK_BASE_URL", "https://api.deepseek.com")
model_default = os.getenv("DEEPSEEK_MODEL", "deepseek-chat")
api_key = st.text_input("DEEPSEEK_API_KEY", value=api_key_default, type="password")
base_url = st.text_input("DEEPSEEK_BASE_URL", value=base_url_default)
model = st.text_input("DEEPSEEK_MODEL", value=model_default)
temperature = st.slider("temperature", min_value=0.0, max_value=1.5, value=0.7, step=0.1)
st.divider()
st.subheader("工具调用(Exa MCP)")
enable_tools = st.checkbox("启用自动工具选择(DeepSeek 决策)", value=True)
max_tool_iterations = st.slider("最多工具调用轮数", min_value=1, max_value=10, value=5, step=1)
if st.button("清空对话"):
st.session_state.messages = []
st.session_state.last_search = None
st.session_state.last_tool_trace = None
st.rerun()
for msg in st.session_state.messages:
with st.chat_message(msg["role"]):
st.markdown(msg["content"])
prompt = st.chat_input("输入你的问题...")
if not prompt:
return
if not api_key:
st.error("请先在左侧填写 DEEPSEEK_API_KEY(或写入 exa_ai/.env)")
return
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
st.session_state.last_search = None
st.session_state.last_tool_trace = None
with st.chat_message("assistant"):
with st.spinner("DeepSeek 思考中..."):
try:
if enable_tools:
answer, tool_trace = deepseek_agent_with_mcp(
user_visible_messages=st.session_state.messages,
api_key=api_key,
base_url=base_url,
model=model,
temperature=temperature,
max_tool_iterations=max_tool_iterations,
)
st.session_state.last_tool_trace = tool_trace
else:
system_prompt = (
"你是一个严谨的中文助手。\n"
"- 不确定就明确说明\n"
)
deepseek_messages: List[Dict[str, str]] = [{"role": "system", "content": system_prompt}]
for m in st.session_state.messages:
if m["role"] in ("user", "assistant"):
deepseek_messages.append(m)
answer = deepseek_chat(
messages=deepseek_messages,
api_key=api_key,
base_url=base_url,
model=model,
temperature=temperature,
)
except Exception as e:
st.error(f"调用 DeepSeek 失败:{e}")
return
st.markdown(answer)
if enable_tools and st.session_state.last_tool_trace:
with st.expander("本轮工具调用 Trace", expanded=False):
st.code(_safe_json(st.session_state.last_tool_trace), language="json")
st.session_state.messages.append({"role": "assistant", "content": answer})
if __name__ == "__main__":
main()7、测试问题
以下几个问题主要是测试各个工具的效果
1.
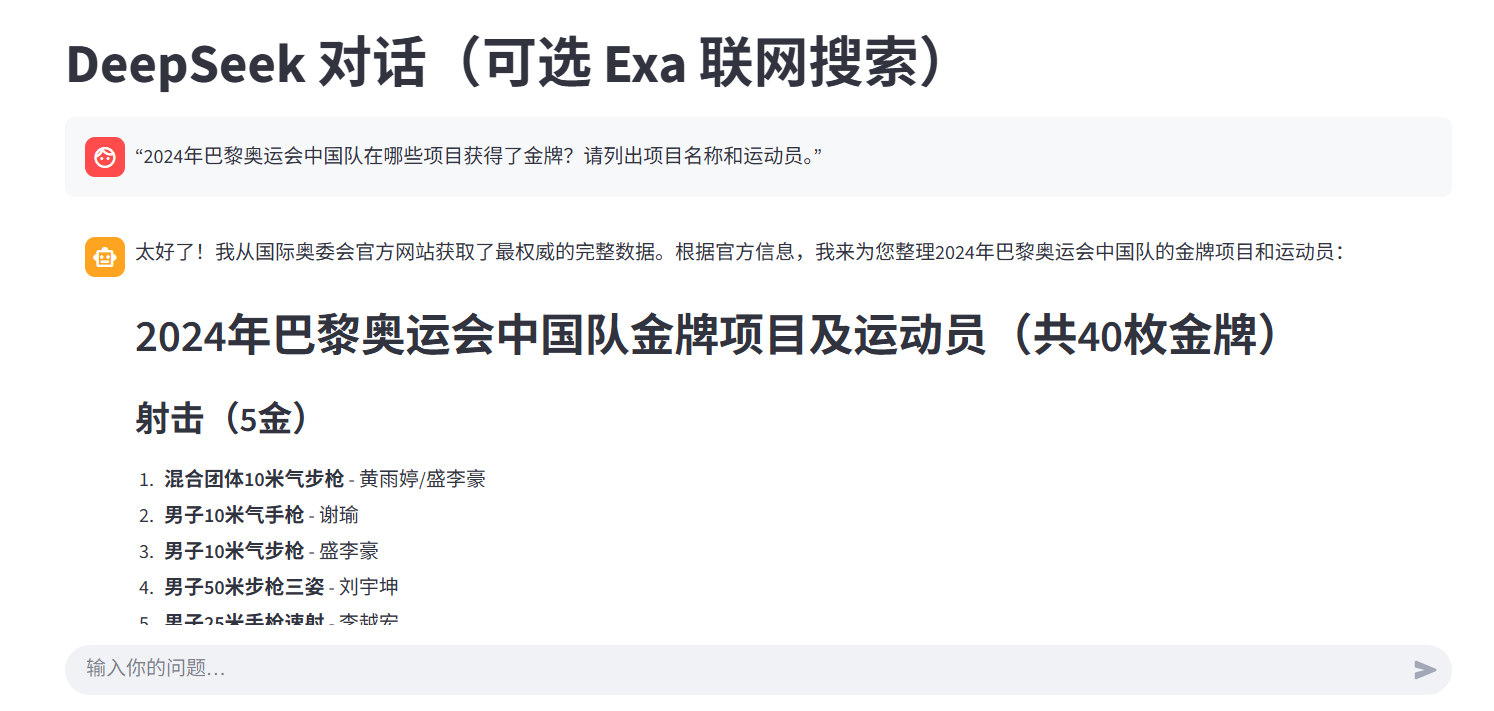
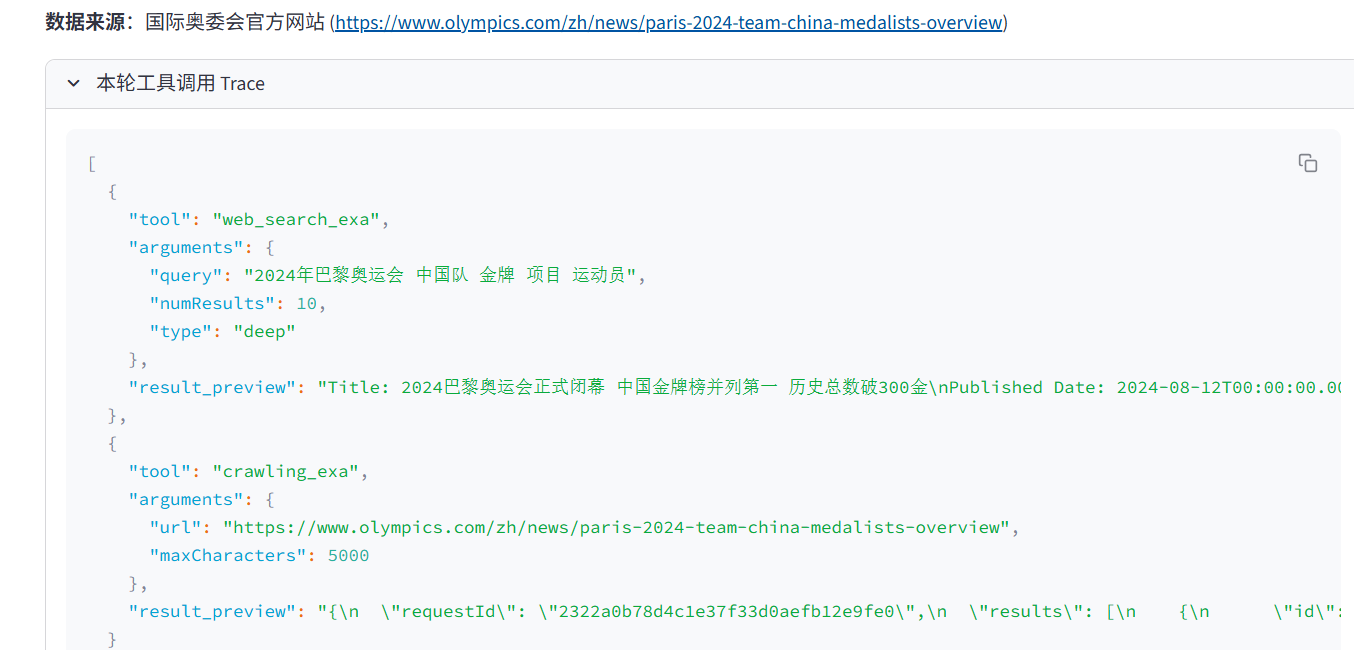
web_search_exa- 适合一般性、实时性事实查询测试问题:
"2024年巴黎奥运会中国队在哪些项目获得了金牌?请列出项目名称和运动员。"这个测试的是它对近期新闻和体育赛事结果的综合检索与概括能力。
2.
get_code_context_exa- 适合代码/文档检索测试问题:
"如何在Python的Pandas库中,将两个DataFrame按照某一列进行合并?请给出代码示例和主要参数说明。"这个测试的是它能否准确检索并结构化呈现编程文档或常用代码片段。
3.
crawling_exa- 适合抓取特定URL内容并总结测试问题:
"请抓取并总结OpenAI官网 (https://openai.com) 首页上关于其最新模型(如GPT-4o)的主要功能介绍。"这个测试的是它能否准确获取指定页面内容,并进行关键信息提取。
4.
company_research_exa- 适合公司信息聚合测试问题:
"请为我总结电动汽车公司'Rivian'(里维安)目前的主要产品、市场定位和最新的财务表现。"这个测试的是它能否从多个来源整合公司业务、产品和财务等关键信息。
5.
linkedin_search_exa- 适合职场/人物背景查询测试问题:
"在LinkedIn上,特斯拉(Tesla Inc.)的现任首席财务官(CFO)是谁?请提供其职业背景概要。"这个测试的是它能否检索到准确的职业信息和公开的履历。
6.
deep_researcher_start+deep_researcher_check- 适合深度、长周期研究测试问题(可启动一个深度任务):
"请深度分析'人工智能在气候变化预测中的应用'这一主题,包括主要技术、研究机构、当前挑战和未来趋势。请生成一份结构化报告。"启动任务后,可用
deep_researcher_check查询进度和结果。这个测试的是它处理复杂、多维度问题的研究能力。
1.3 主流联网搜索API对比
| API/平台名称 | 核心特点 | 适合场景 | 备注 |
|---|---|---|---|
| 腾讯云平台 (搜狗搜索) | 与DeepSeek模型深度集成,国内合规稳定,一键配置联网。 | 希望快速构建 包含DeepSeek模型的AI应用,主要面向中文互联网和国内市场的开发者。 | 属于平台服务,非通用API。优势在于开箱即用和DeepSeek模型的生态整合。 |
| 通用网页搜索API (如Bing/Google/博查) | 通过官方或第三方API调用,通用性强,全球或中文索引全,自由度最高。 | 需要接入各种应用场景,对搜索结果有定制化需求(如多语言、特定区域)。 | 需处理API密钥、调用频率、费用及可能的网络问题。第三方服务商如SerpApi可简化Google搜索获取。 |
| AI优化搜索API (如Tavily/Exa.ai) | 专门为LLM和RAG优化,提供答案生成、结果结构化、多轮搜索。 | 构建AI Agent、智能助手或复杂RAG系统 ,追求答案质量而非原始链接列表。 | 抽象程度更高,更注重理解用户意图和结果的可读性。 |