一、数据聚合
1.1 聚合的分类
聚合可以实现对文档数据的统计、分析、运算(MySQL中的聚合函数有avg,max,min,sum,一般还要结合group by 分组使用)。常见的有三类:
(1)桶(Bucket)聚合 :用来对文档做分组。
TermAggregation:按文档字段值(该字段不能分词,不能是text)分组
Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
(2)度量(Metric)聚合 :用以计算一些值,比如最大值、最小值、平均值
Avg:求平均值
Max:求最大值
Min:求最小值
Stats:同时求max、min、avg、sum等。
(3)管道(pipeline)聚合:其它聚合的结果为基础做聚合
1.2 DSL实现
还是博文springcloud篇7中添加的hotel索引:
bash
# 酒店的mapping
PUT /hotel
{
"mappings":{
"properties":{
"id":{
"type":"keyword"
},
"name":{
"type":"text",
"analyzer":"ik_max_word",
"copy_to":"all"
},
"address":{
"type":"keyword",
"index":false
},
"price":{
"type":"integer"
},
"score":{
"type":"integer"
},
"brand":{
"type":"keyword",
"copy_to":"all"
},
"city":{
"type":"keyword"
},
"starName":{
"type":"keyword"
},
"business":{
"type":"keyword",
"copy_to":"all"
},
"location":{
"type":"geo_point"
},
"pic":{
"type":"keyword",
"index":false
},
"all":{
"type":"text",
"analyzer":"ik_max_word"
}
}
}
}1.2.1 实现Bucket聚合
例子:统计所有数据中的酒店品牌有几种,此时可以根据酒店品牌的名称做聚合。


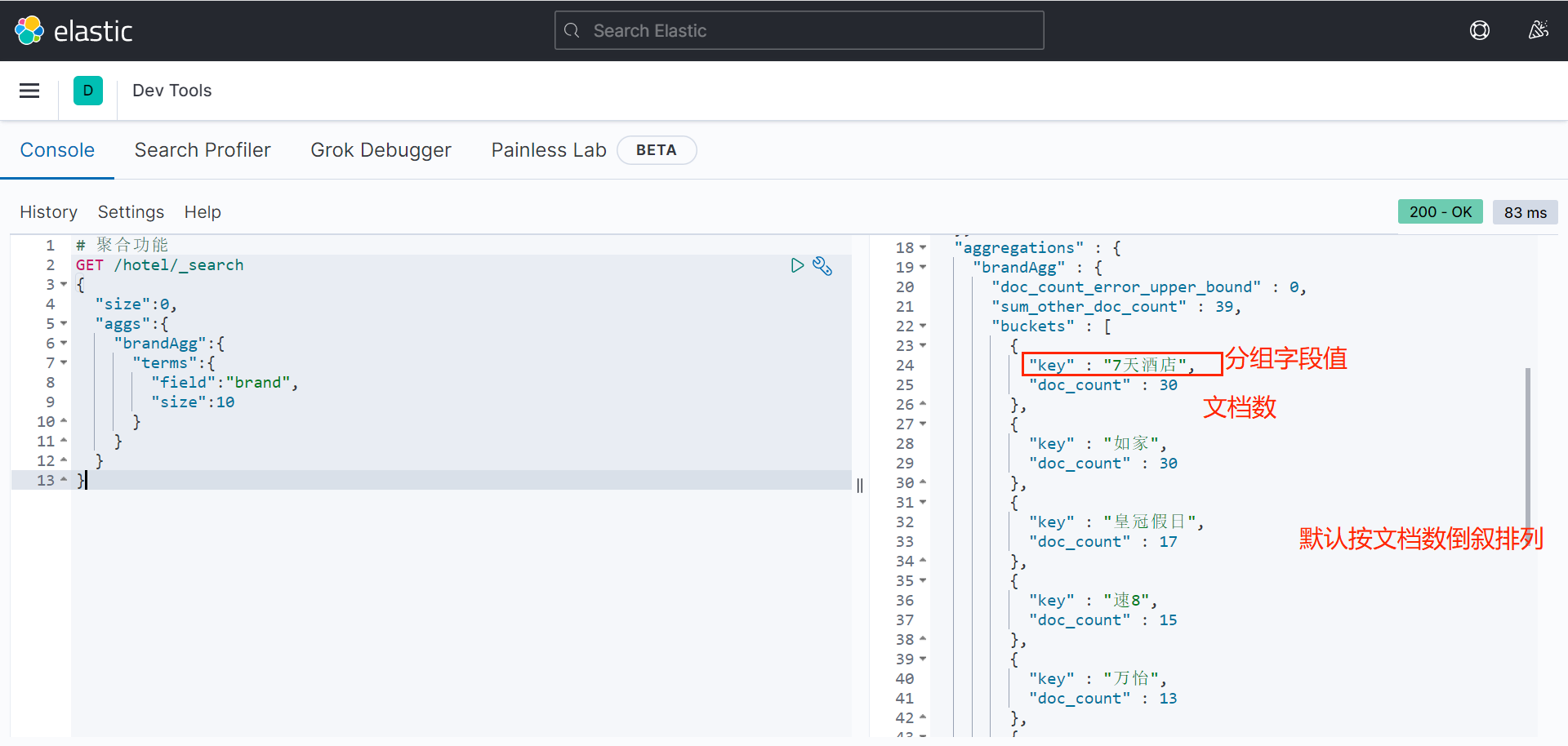
bash
# 聚合功能
GET /hotel/_search
{
"size":0,
"aggs":{
"brandAgg":{
"terms":{
"field":"brand",
"size":10
}
}
}
}补充1.Bucket聚合-聚合结果排序
默认情况下,Bucket聚合会统计Bucket内的文档数量,记为_count,并且按照_count降序排序。
可以修改结果排序方式:

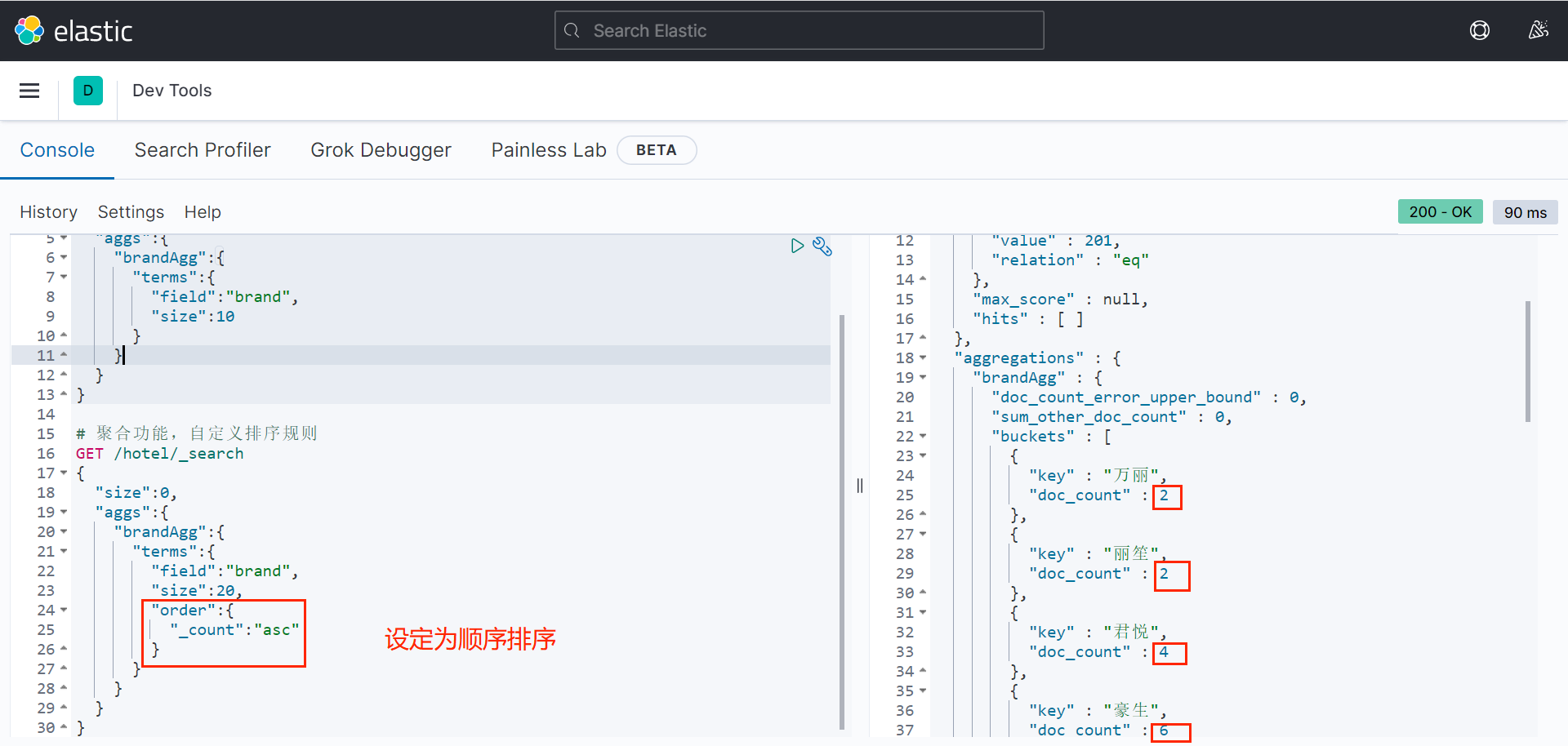
bash
# 聚合功能,自定义排序规则
GET /hotel/_search
{
"size":0,
"aggs":{
"brandAgg":{
"terms":{
"field":"brand",
"size":20,
"order":{
"_count":"asc"
}
}
}
}
}补充2.Bucket聚合-限定聚合范围
默认情况下,Bucket聚合是对索引库的所有文档做聚合,可以限定要聚合的文档范围,只要添加query条件即可。
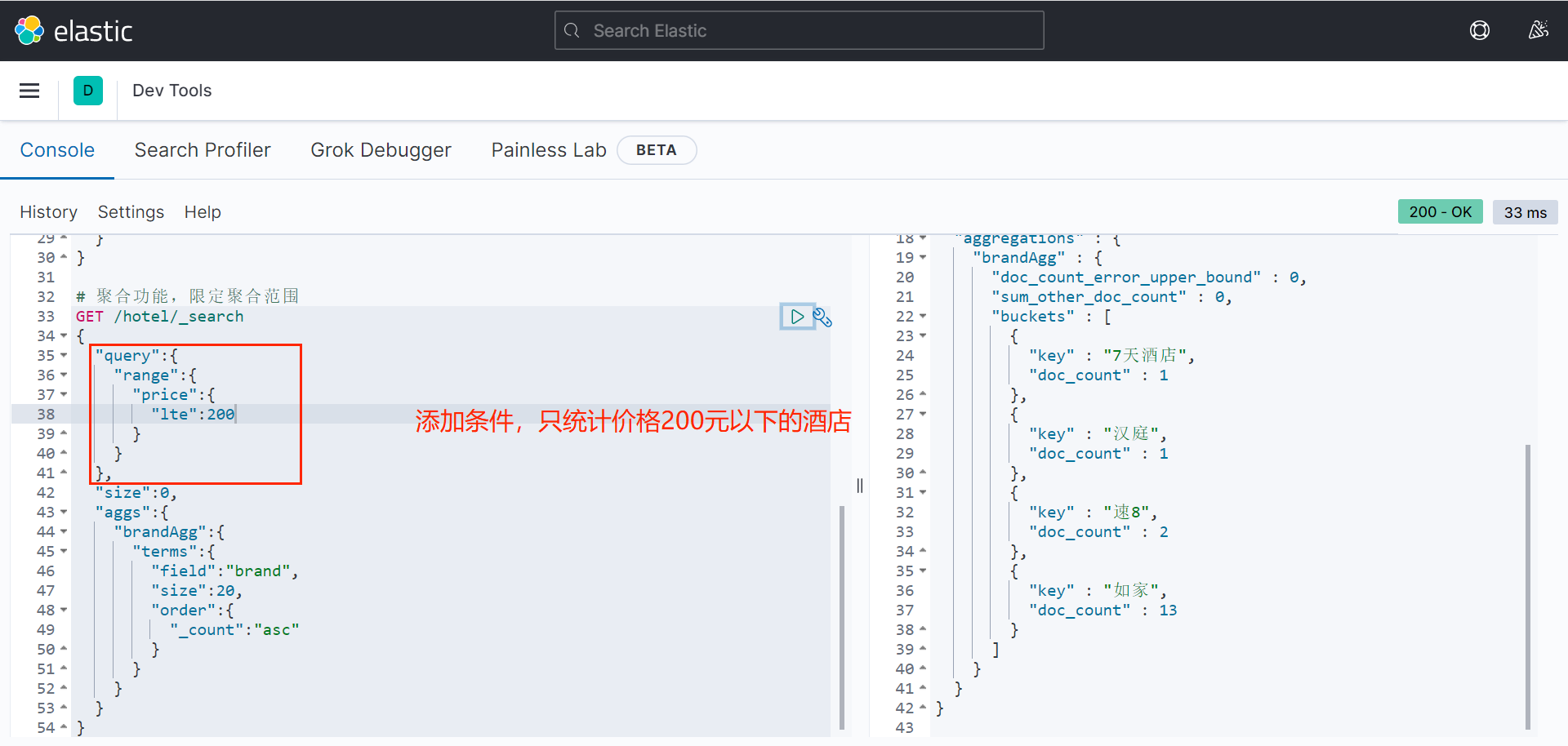
bash
# 聚合功能,限定聚合范围
GET /hotel/_search
{
"query":{
"range":{
"price":{
"lte":200
}
}
},
"size":0,
"aggs":{
"brandAgg":{
"terms":{
"field":"brand",
"size":20,
"order":{
"_count":"asc"
}
}
}
}
}1.2.2 实现Metric聚合
需与bucket聚合结合使用。
例子,获取每个品牌的用户评分的min、max、avg等值。

从上图中可以看出,聚合可以嵌套,brandAgg聚合内部嵌套了一个score_stats聚合。
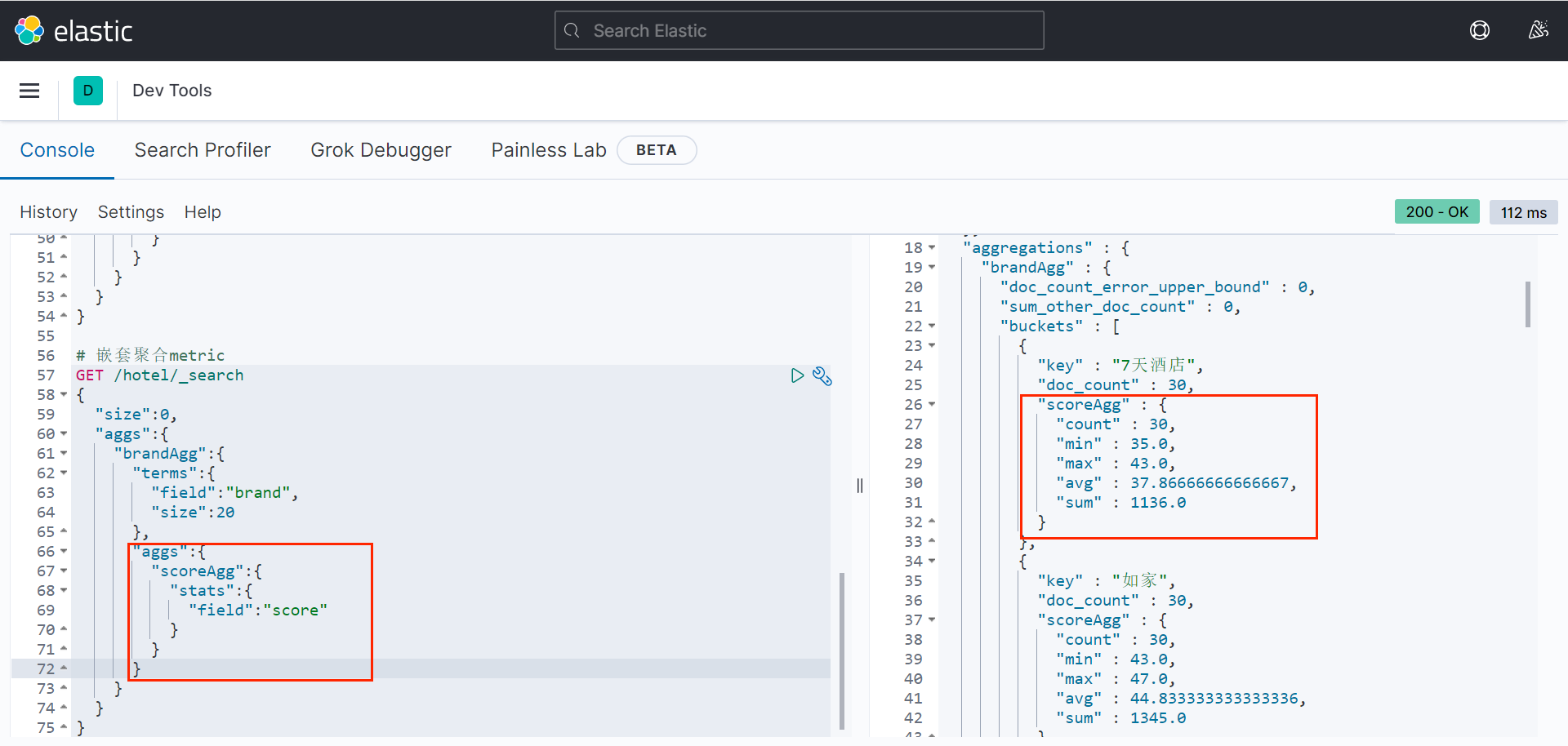
bash
# 嵌套聚合metric
GET /hotel/_search
{
"size":0,
"aggs":{
"brandAgg":{
"terms":{
"field":"brand",
"size":20
},
"aggs":{
"scoreAgg":{
"stats":{
"field":"score"
}
}
}
}
}
}再根据聚合的计算结果排序:
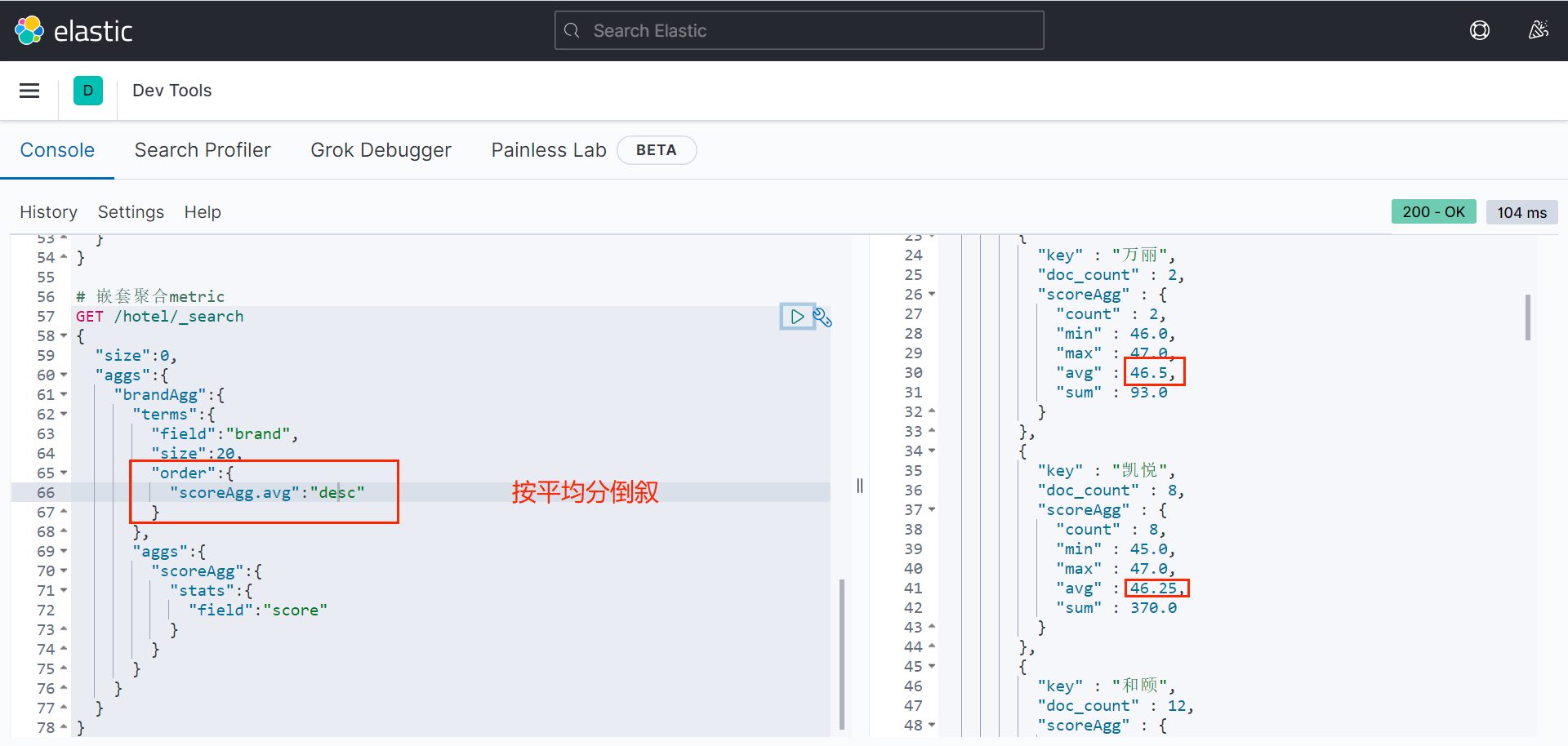
bash
# 嵌套聚合metric
GET /hotel/_search
{
"size":0,
"aggs":{
"brandAgg":{
"terms":{
"field":"brand",
"size":20,
"order":{
"scoreAgg.avg":"desc"
}
},
"aggs":{
"scoreAgg":{
"stats":{
"field":"score"
}
}
}
}
}
}1.3 RestAPI实现聚合
获取查询结果:
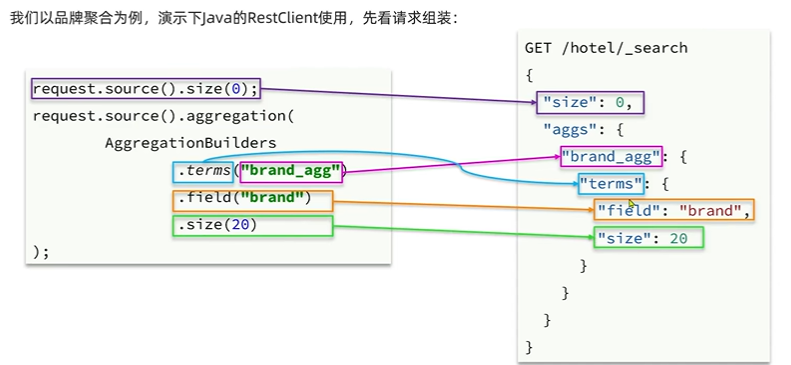
聚合结果解析:
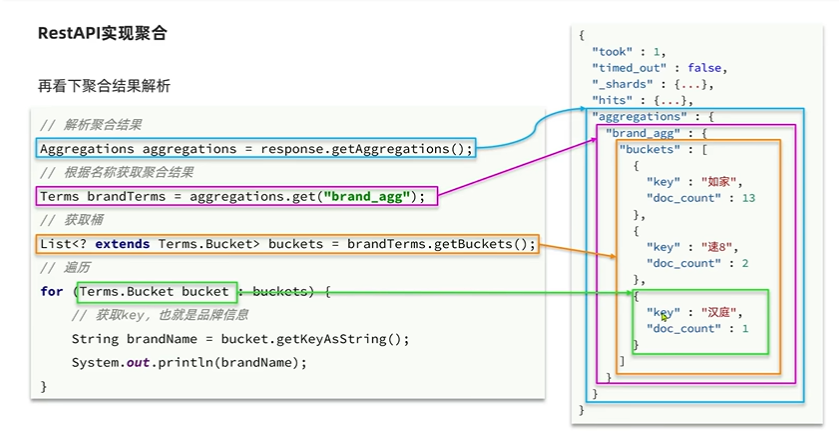
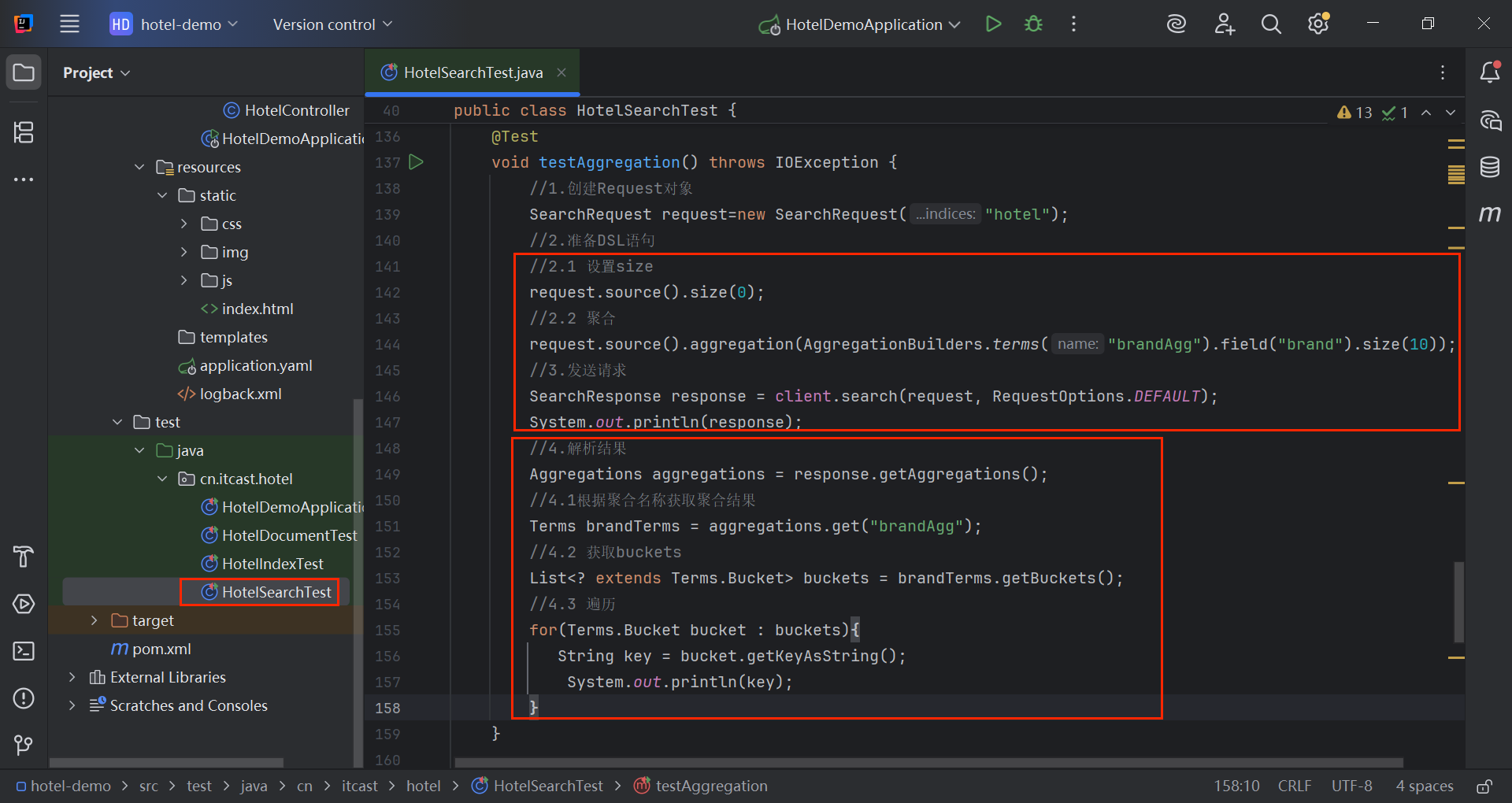
java
@Test
void testAggregation() throws IOException {
//1.创建Request对象
SearchRequest request=new SearchRequest("hotel");
//2.准备DSL语句
//2.1 设置size
request.source().size(0);
//2.2 聚合
request.source().aggregation(AggregationBuilders.terms("brandAgg").field("brand").size(10));
//3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
System.out.println(response);
//4.解析结果
Aggregations aggregations = response.getAggregations();
//4.1根据聚合名称获取聚合结果
Terms brandTerms = aggregations.get("brandAgg");
//4.2 获取buckets
List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();
//4.3 遍历
for(Terms.Bucket bucket : buckets){
String key = bucket.getKeyAsString();
System.out.println(key);
}
}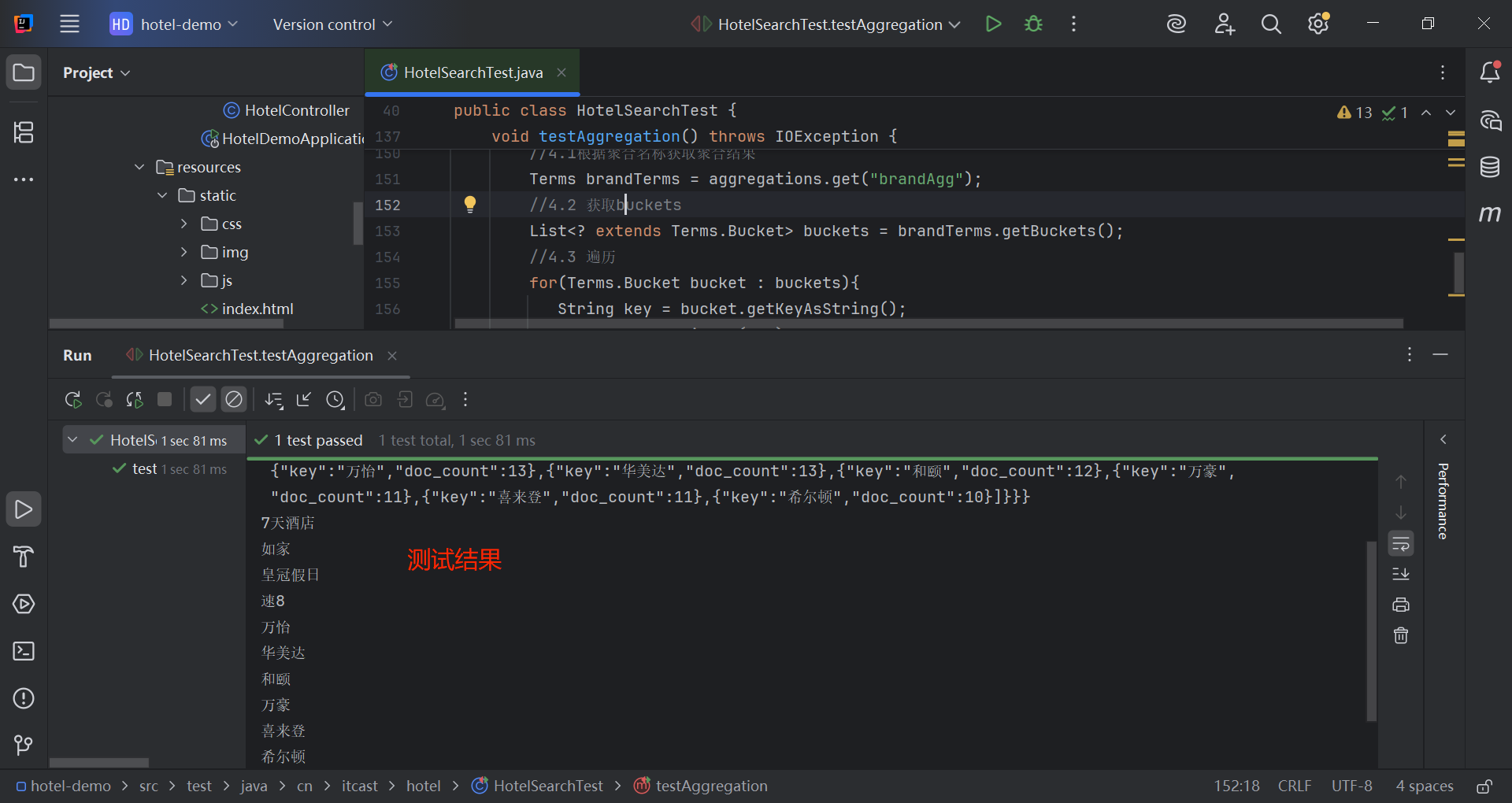
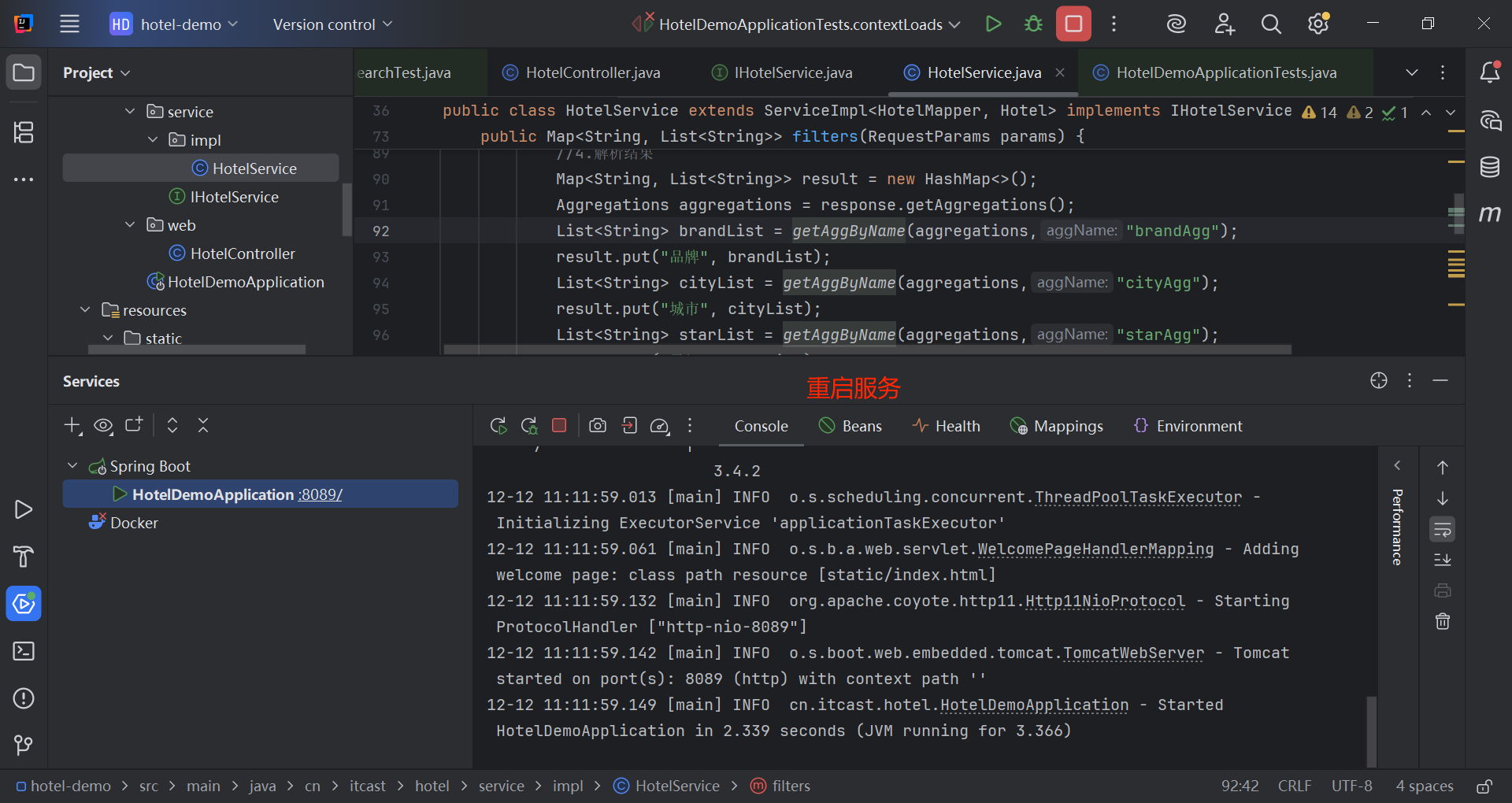
1.4 多条件聚合
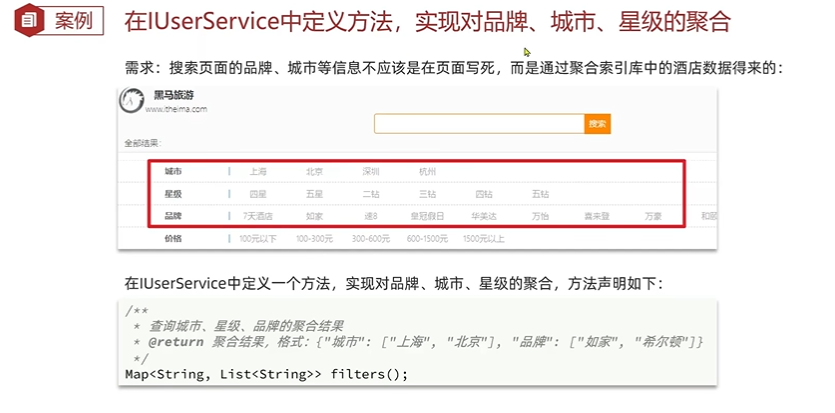
如上图所示,前端页面的筛选条件(城市、星级、品牌和价格)的选项并不是前端写死的,而是要通过后台搜索聚合结果得到。
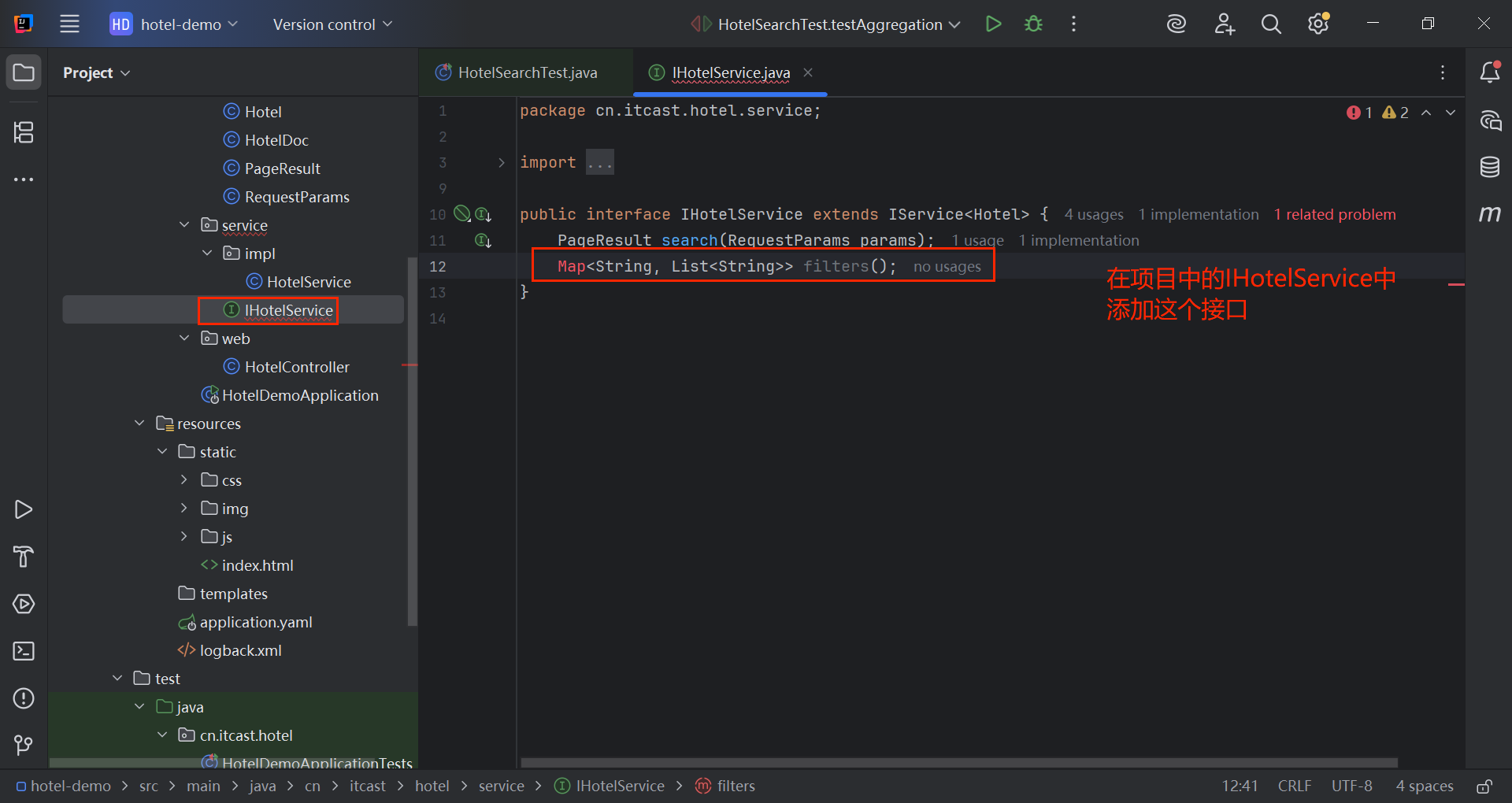
java
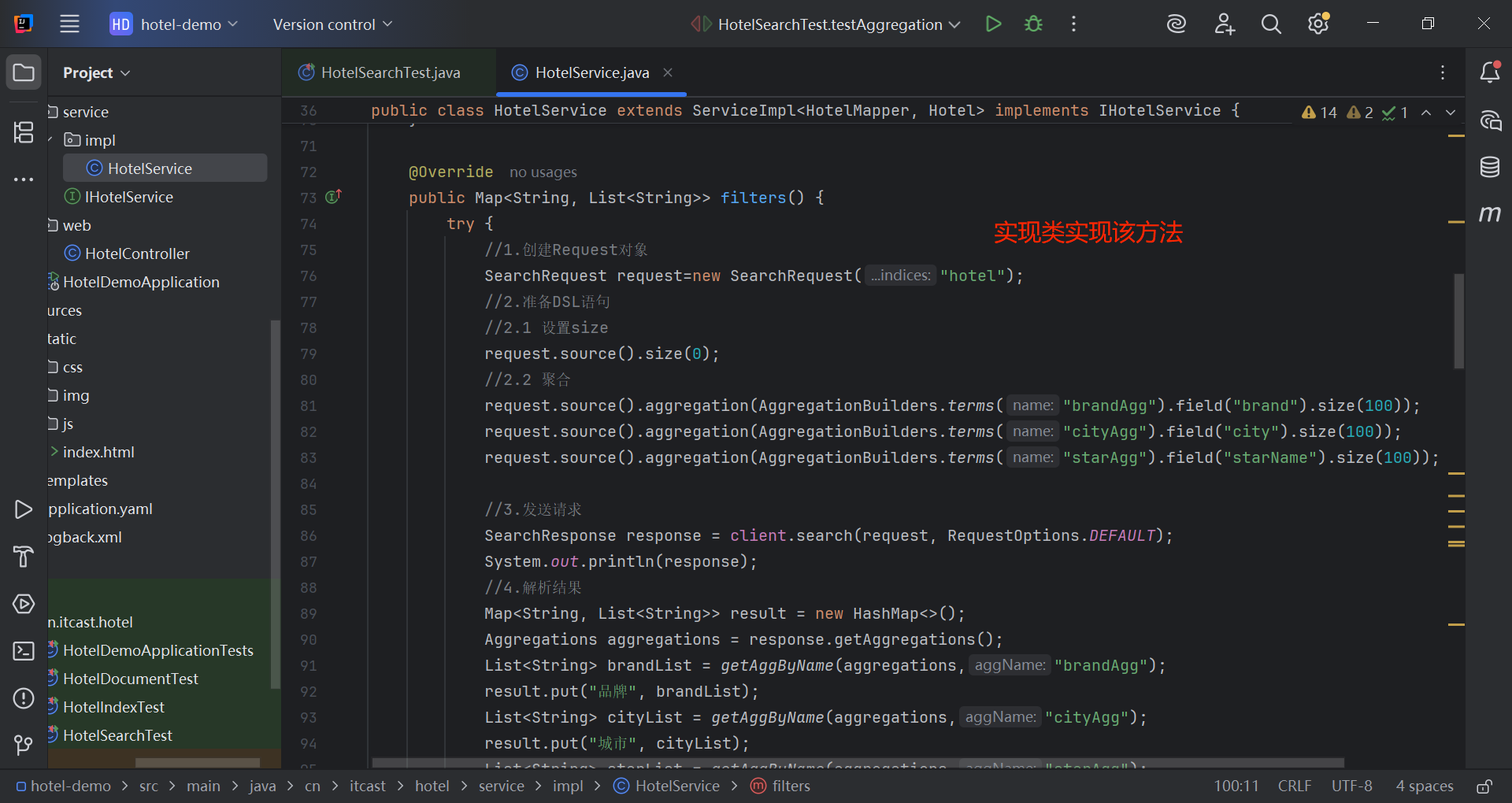
public interface IHotelService extends IService<Hotel> {
PageResult search(RequestParams params);
Map<String, List<String>> filters();
}
java
@Override
public Map<String, List<String>> filters() {
try {
//1.创建Request对象
SearchRequest request=new SearchRequest("hotel");
//2.准备DSL语句
//2.1 设置size
request.source().size(0);
//2.2 聚合
request.source().aggregation(AggregationBuilders.terms("brandAgg").field("brand").size(100));
request.source().aggregation(AggregationBuilders.terms("cityAgg").field("city").size(100));
request.source().aggregation(AggregationBuilders.terms("starAgg").field("starName").size(100));
//3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.解析结果
Map<String, List<String>> result = new HashMap<>();
Aggregations aggregations = response.getAggregations();
List<String> brandList = getAggByName(aggregations,"brandAgg");
result.put("品牌", brandList);
List<String> cityList = getAggByName(aggregations,"cityAgg");
result.put("城市", cityList);
List<String> starList = getAggByName(aggregations,"starAgg");
result.put("星级", starList);
return result;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private static List<String> getAggByName(Aggregations aggregations,String aggName) {
//4.1根据聚合名称获取聚合结果
Terms brandTerms = aggregations.get(aggName);
//4.2 获取buckets
List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();
//4.3 遍历
List<String> brandList = new ArrayList<>();
for(Terms.Bucket bucket : buckets){
String key = bucket.getKeyAsString();
brandList.add(key);
}
return brandList;
}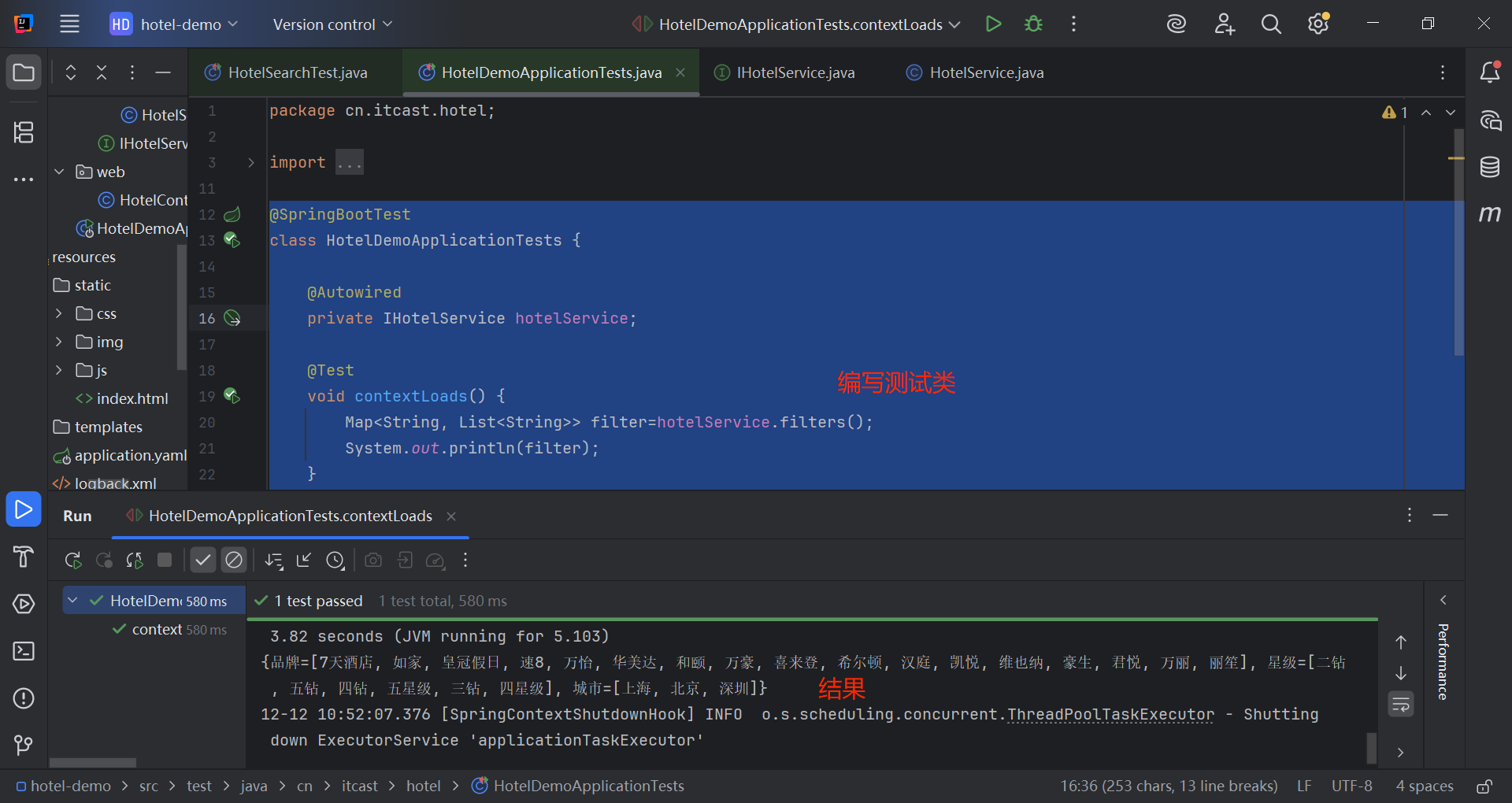
java
@SpringBootTest
class HotelDemoApplicationTests {
@Autowired
private IHotelService hotelService;
@Test
void contextLoads() {
Map<String, List<String>> filter=hotelService.filters();
System.out.println(filter);
}
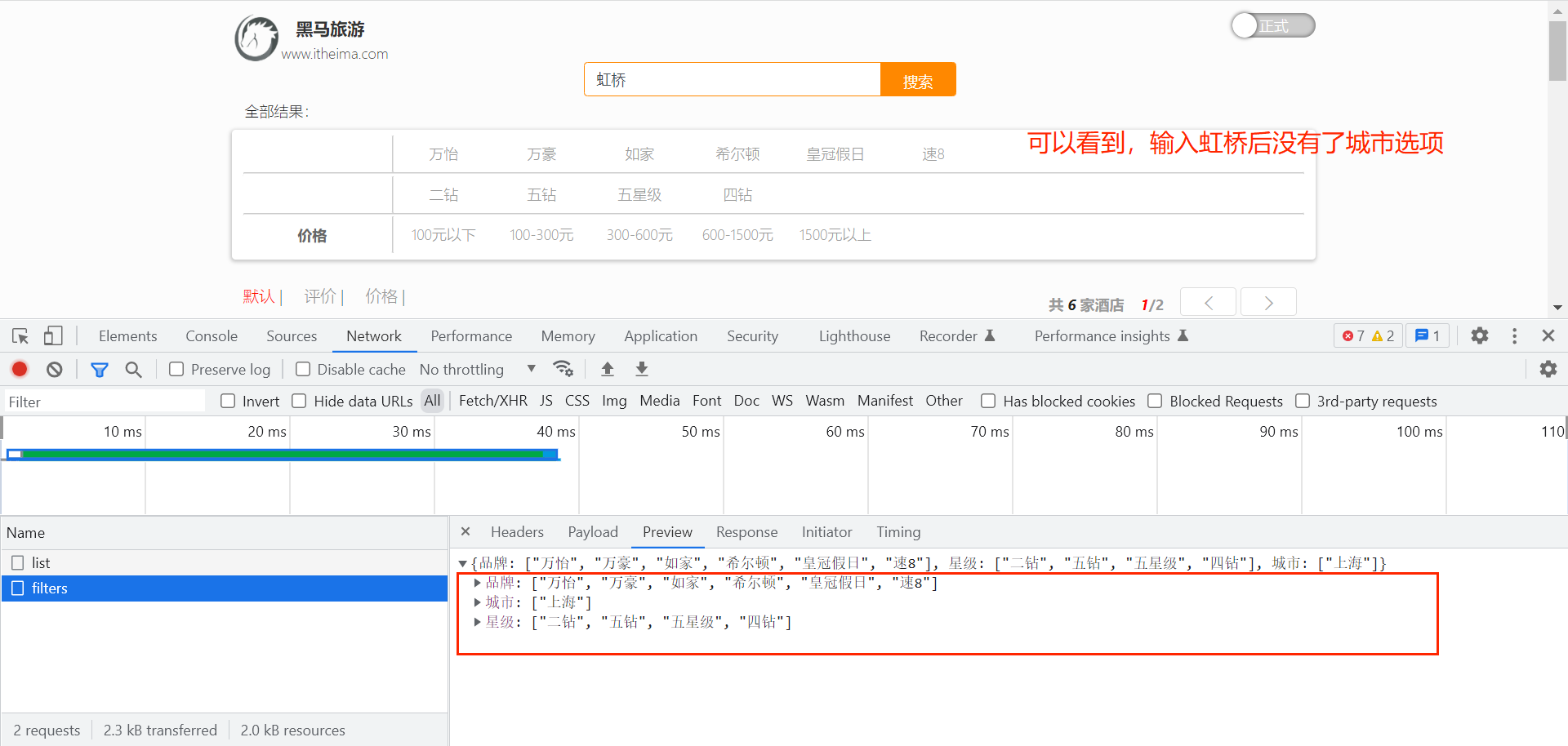
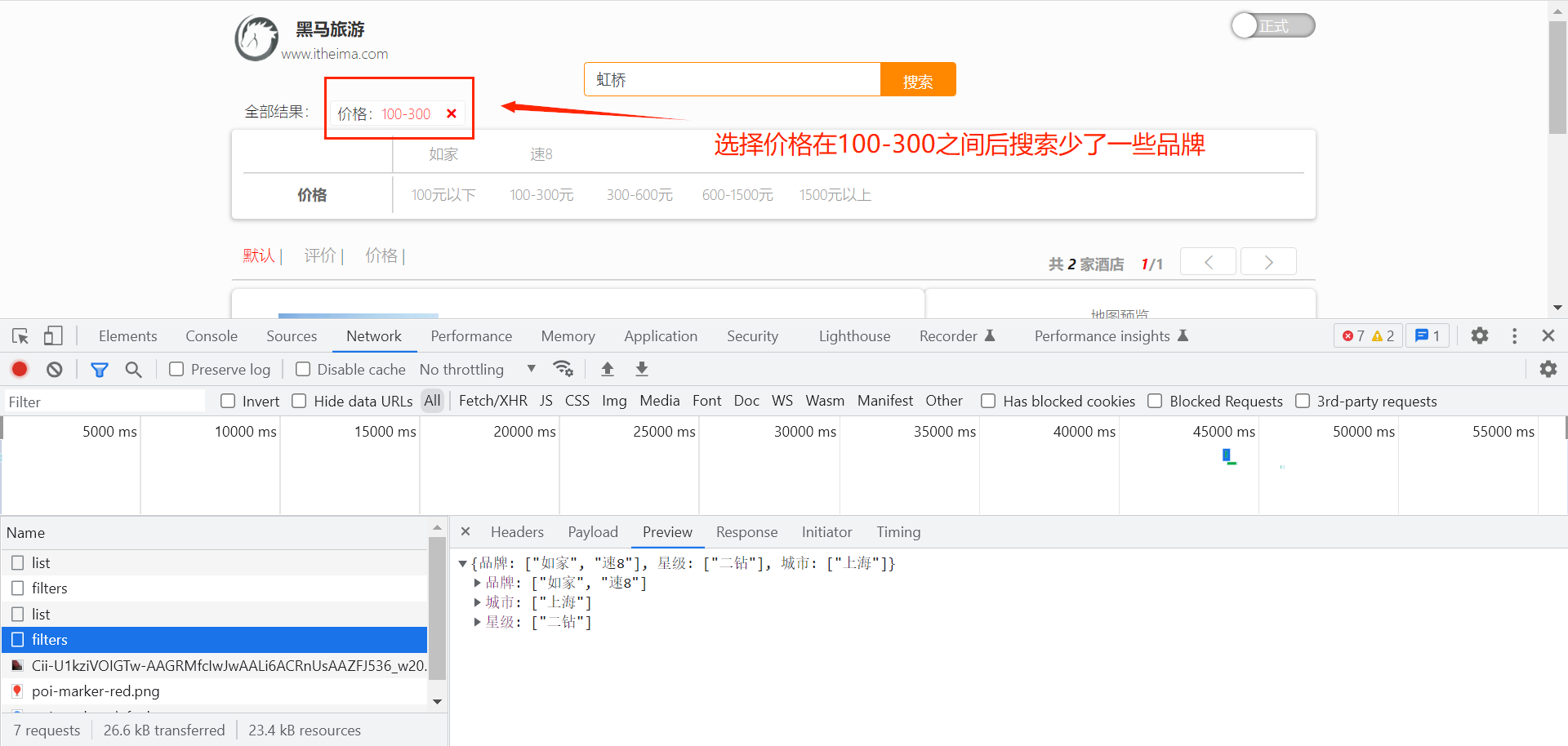
}1.5 带过滤条件的聚合
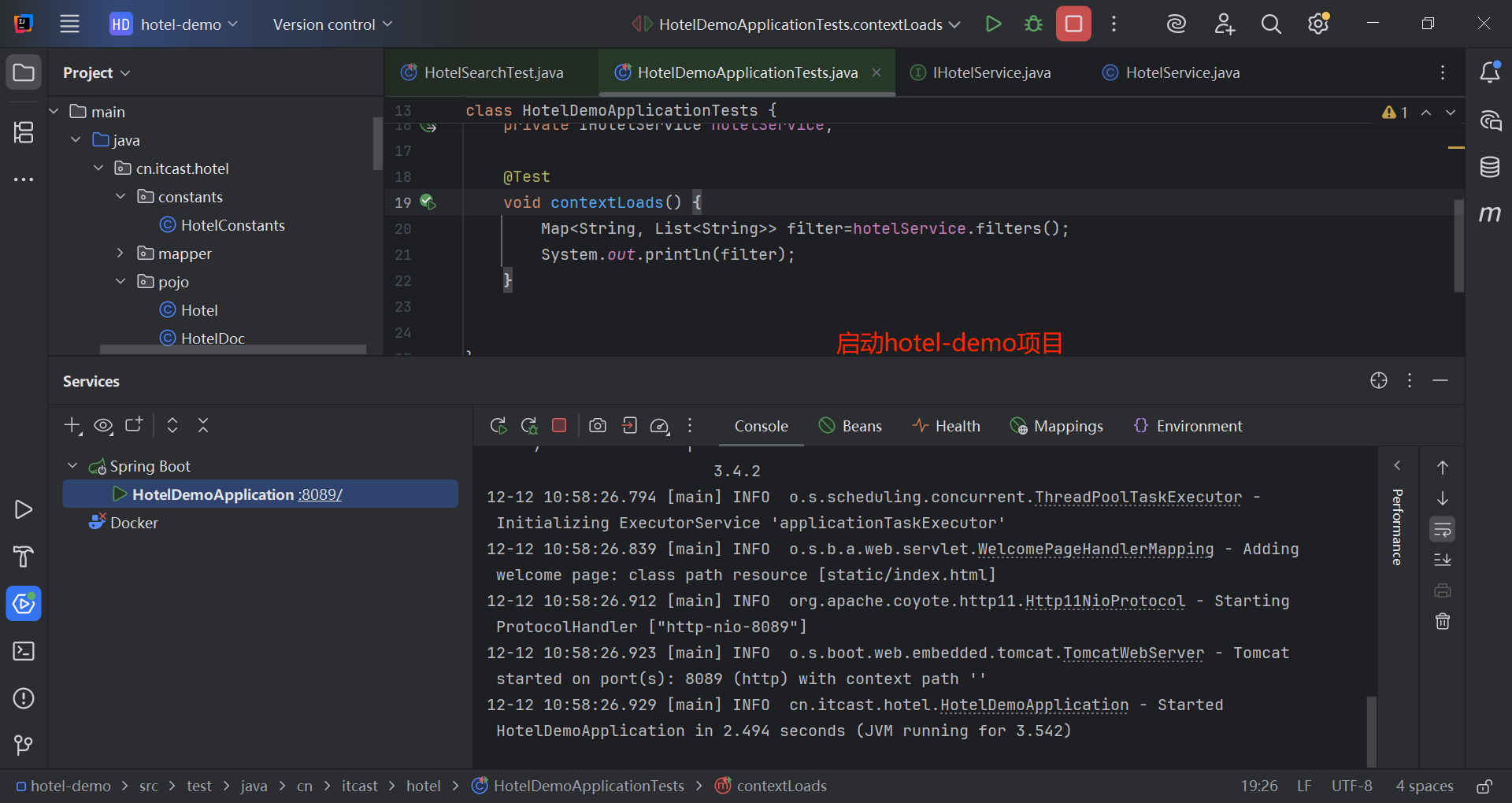
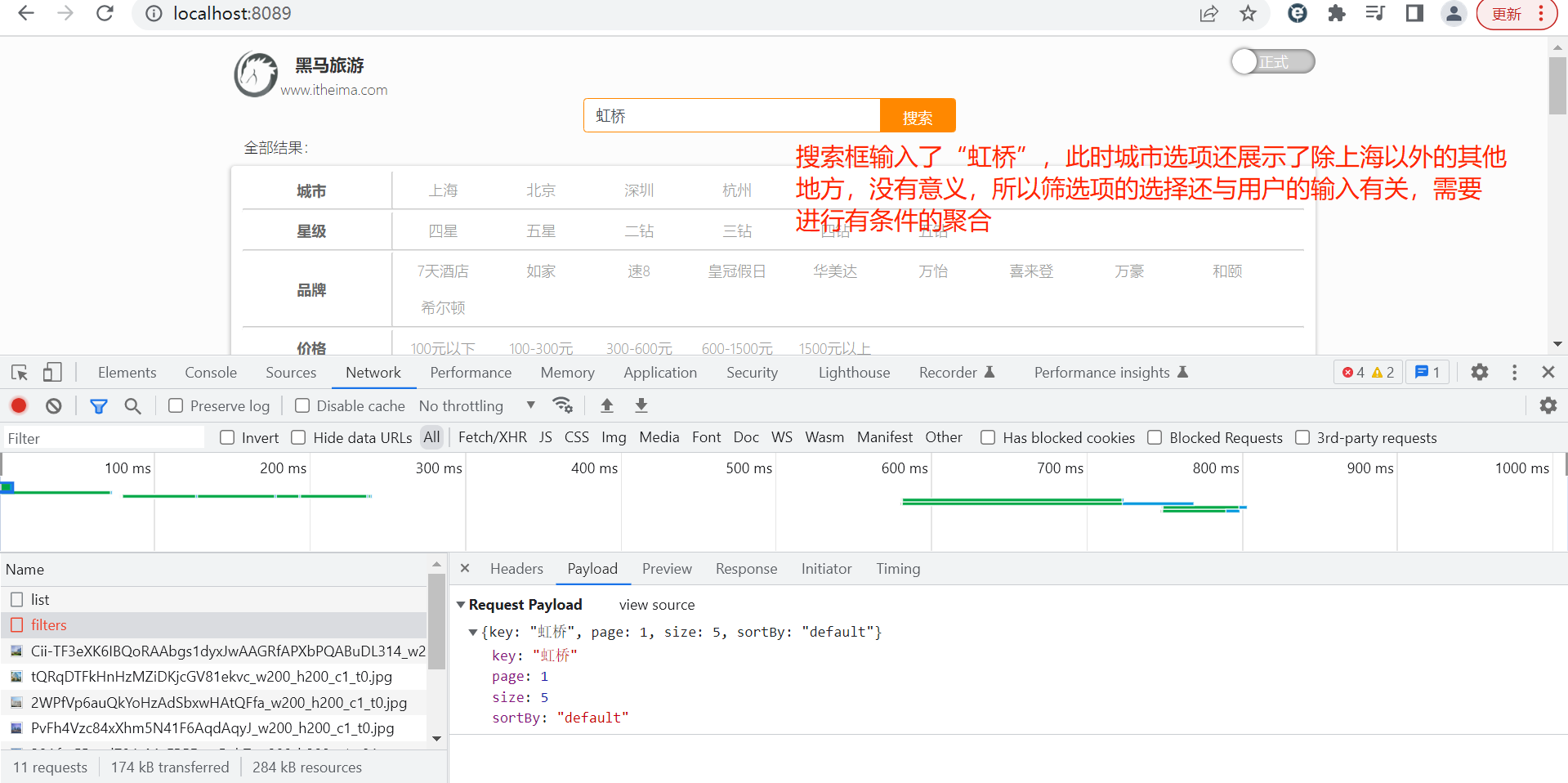
注意:因为筛选项的聚合结果与用户输入有关,所以接口的入参与用户搜索的接口的入参一致。
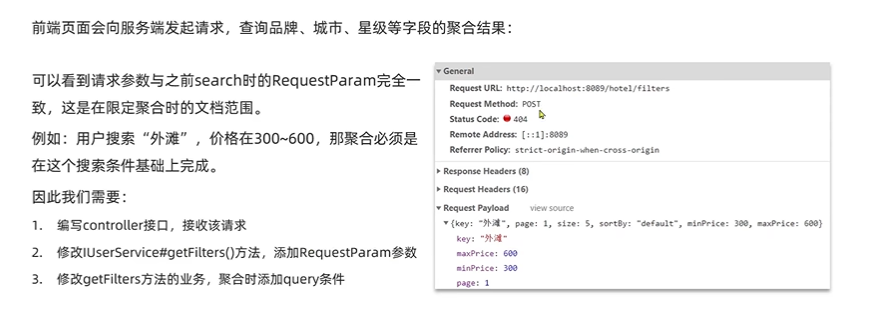
代码修改如下:
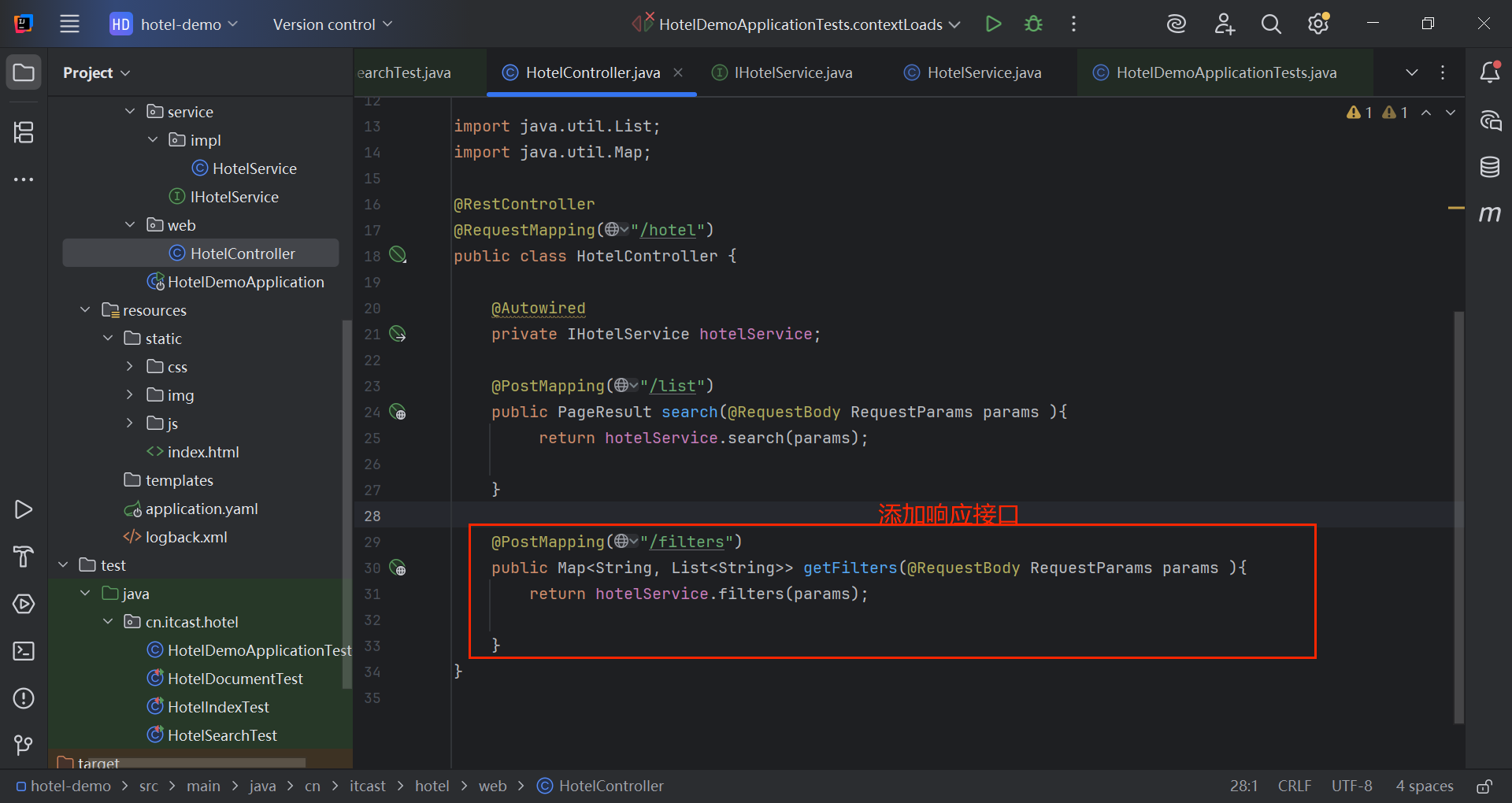
java
@PostMapping("/filters")
public Map<String, List<String>> getFilters(@RequestBody RequestParams params ){
return hotelService.filters(params);
}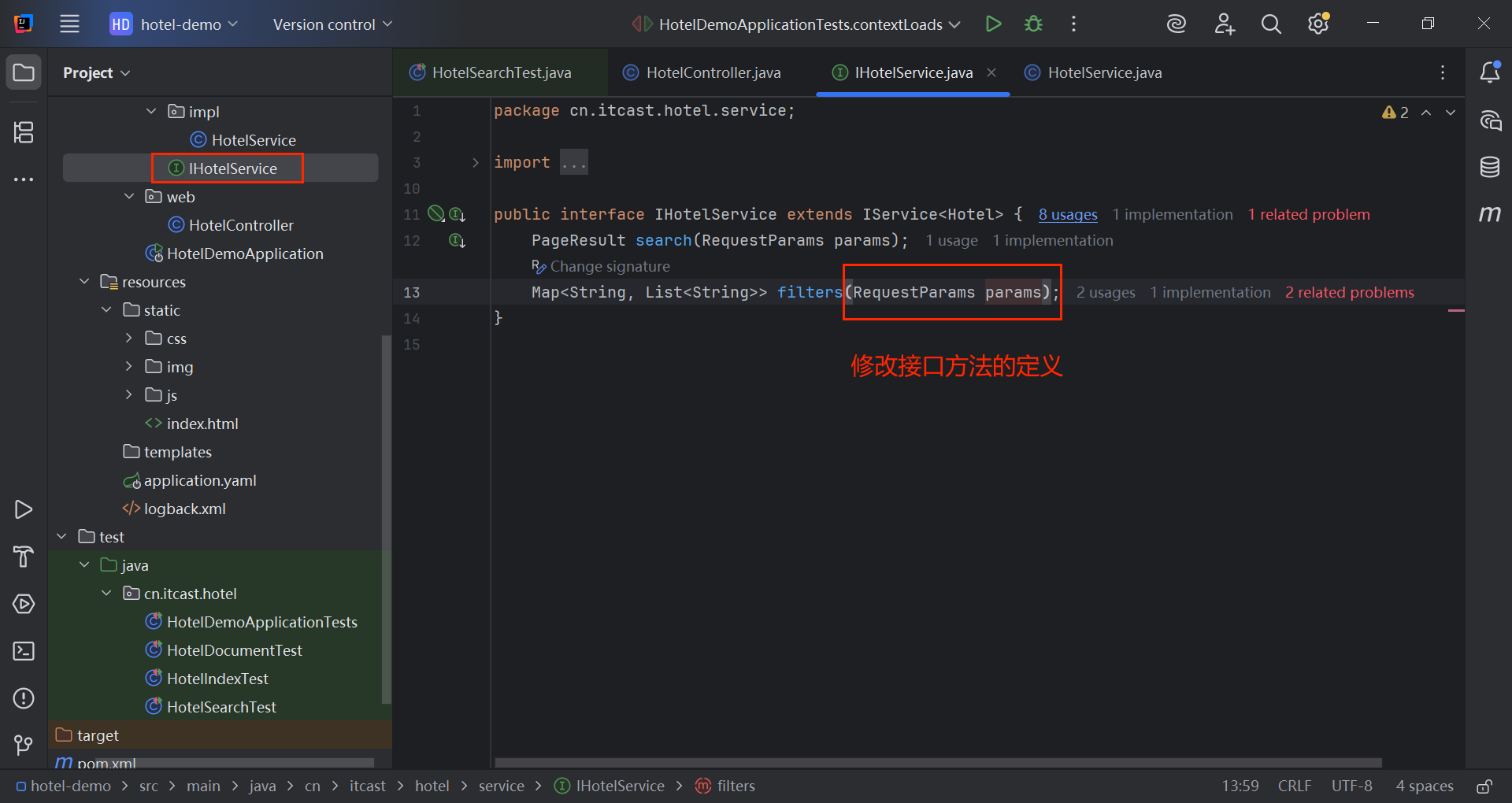
java
public interface IHotelService extends IService<Hotel> {
PageResult search(RequestParams params);
Map<String, List<String>> filters(RequestParams params);
}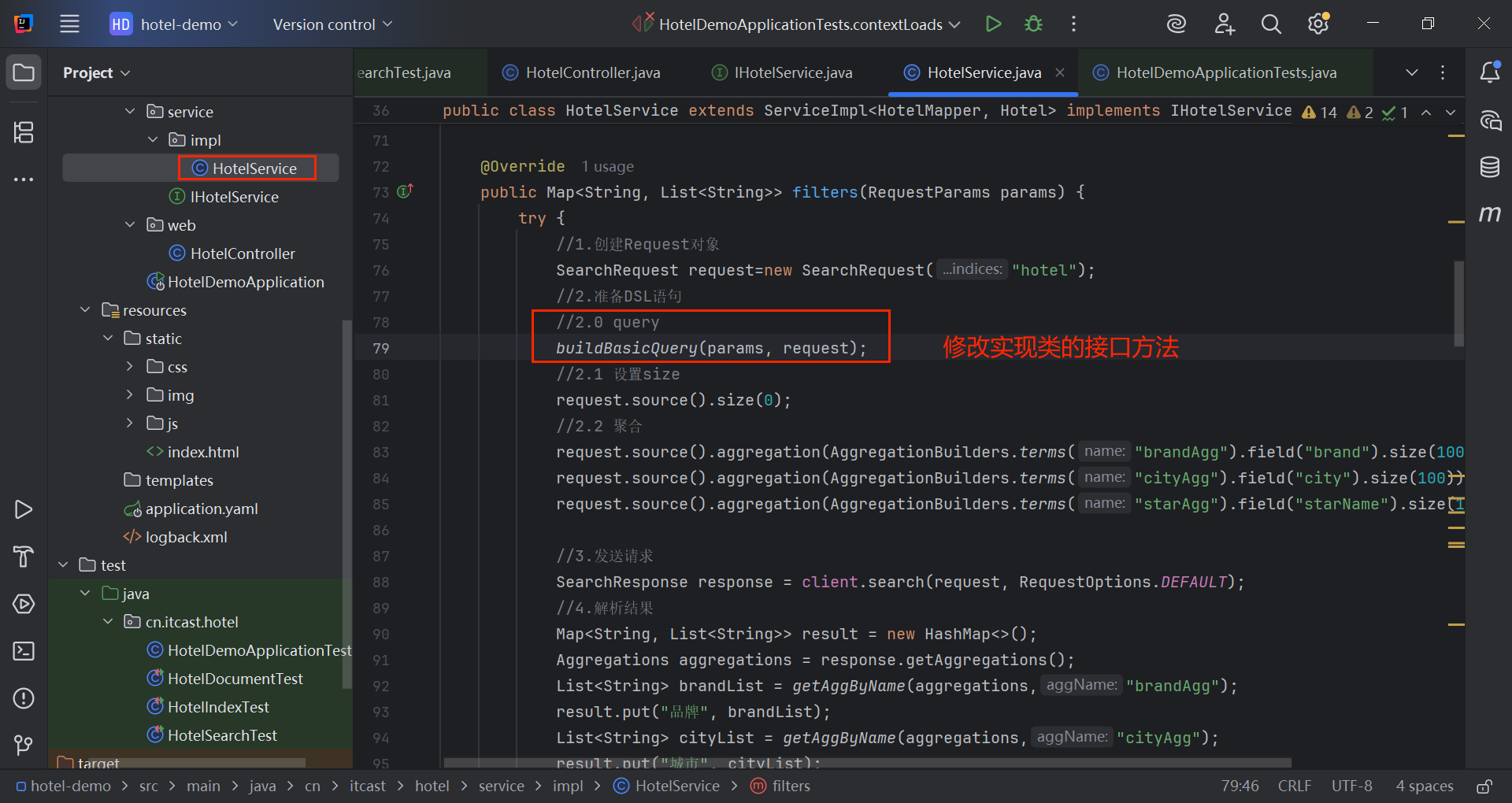
java
@Override
public Map<String, List<String>> filters(RequestParams params) {
try {
//1.创建Request对象
SearchRequest request=new SearchRequest("hotel");
//2.准备DSL语句
//2.0 query
buildBasicQuery(params, request);
//2.1 设置size
request.source().size(0);
//2.2 聚合
request.source().aggregation(AggregationBuilders.terms("brandAgg").field("brand").size(100));
request.source().aggregation(AggregationBuilders.terms("cityAgg").field("city").size(100));
request.source().aggregation(AggregationBuilders.terms("starAgg").field("starName").size(100));
//3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.解析结果
Map<String, List<String>> result = new HashMap<>();
Aggregations aggregations = response.getAggregations();
List<String> brandList = getAggByName(aggregations,"brandAgg");
result.put("品牌", brandList);
List<String> cityList = getAggByName(aggregations,"cityAgg");
result.put("城市", cityList);
List<String> starList = getAggByName(aggregations,"starAgg");
result.put("星级", starList);
return result;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private static List<String> getAggByName(Aggregations aggregations,String aggName) {
//4.1根据聚合名称获取聚合结果
Terms brandTerms = aggregations.get(aggName);
//4.2 获取buckets
List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();
//4.3 遍历
List<String> brandList = new ArrayList<>();
for(Terms.Bucket bucket : buckets){
String key = bucket.getKeyAsString();
brandList.add(key);
}
return brandList;
}
private static void buildBasicQuery(RequestParams params, SearchRequest request) {
//1.准备DSL语句
//1.1 query
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
//关键字搜索
String key = params.getKey();
if(key == null || "".equals(key)){
boolQuery.must(QueryBuilders.matchAllQuery());
}else{
boolQuery.must(QueryBuilders.matchQuery("all",key));
}
//城市条件
if(params.getCity() !=null && !"".equals(params.getCity())){
boolQuery.filter(QueryBuilders.termQuery("city", params.getCity()));
}
//品牌条件
if(params.getBrand() !=null && !"".equals(params.getBrand())){
boolQuery.filter(QueryBuilders.termQuery("brand", params.getBrand()));
}
//星级条件
if(params.getStarName() !=null && !"".equals(params.getStarName())){
boolQuery.filter(QueryBuilders.termQuery("brand", params.getStarName()));
}
//价格条件
if(params.getMinPrice() !=null && !"".equals(params.getMinPrice()) &&
params.getMaxPrice() !=null && !"".equals(params.getMaxPrice())){
boolQuery.filter(QueryBuilders.rangeQuery("price").gte(params.getMinPrice()).lte(params.getMaxPrice()));
}
//2.算分控制
FunctionScoreQueryBuilder functionScoreQuery=
QueryBuilders.functionScoreQuery(
boolQuery,//原始查询,相关性算分的查询
new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{//function score数组
new FunctionScoreQueryBuilder.FilterFunctionBuilder(//其中的一个function score元素
QueryBuilders.termQuery("isAD",true),
ScoreFunctionBuilders.weightFactorFunction(10)
)
});
request.source().query(functionScoreQuery);
}
二、自动补全
2.1 拼音分词器
要实现根据字母做补全,就必须对文档按照拼音分词 。在GitHub上有elasticsearch的拼音分词器插件,地址:https://github.com/medcl/elasticsearch-analysis-pinyin

找到学习资料中已解压的拼音分词器,将解压的ik文件夹里的东西上传到查询到的插件目录/var/lib/docker/volumes/es-plugins/_data。直接上传可能打不开这个目录,可以先上传到一个目录再用mv指令。


bash
mv xx /var/lib/docker/volumes/es-plugins/_data
docker restart es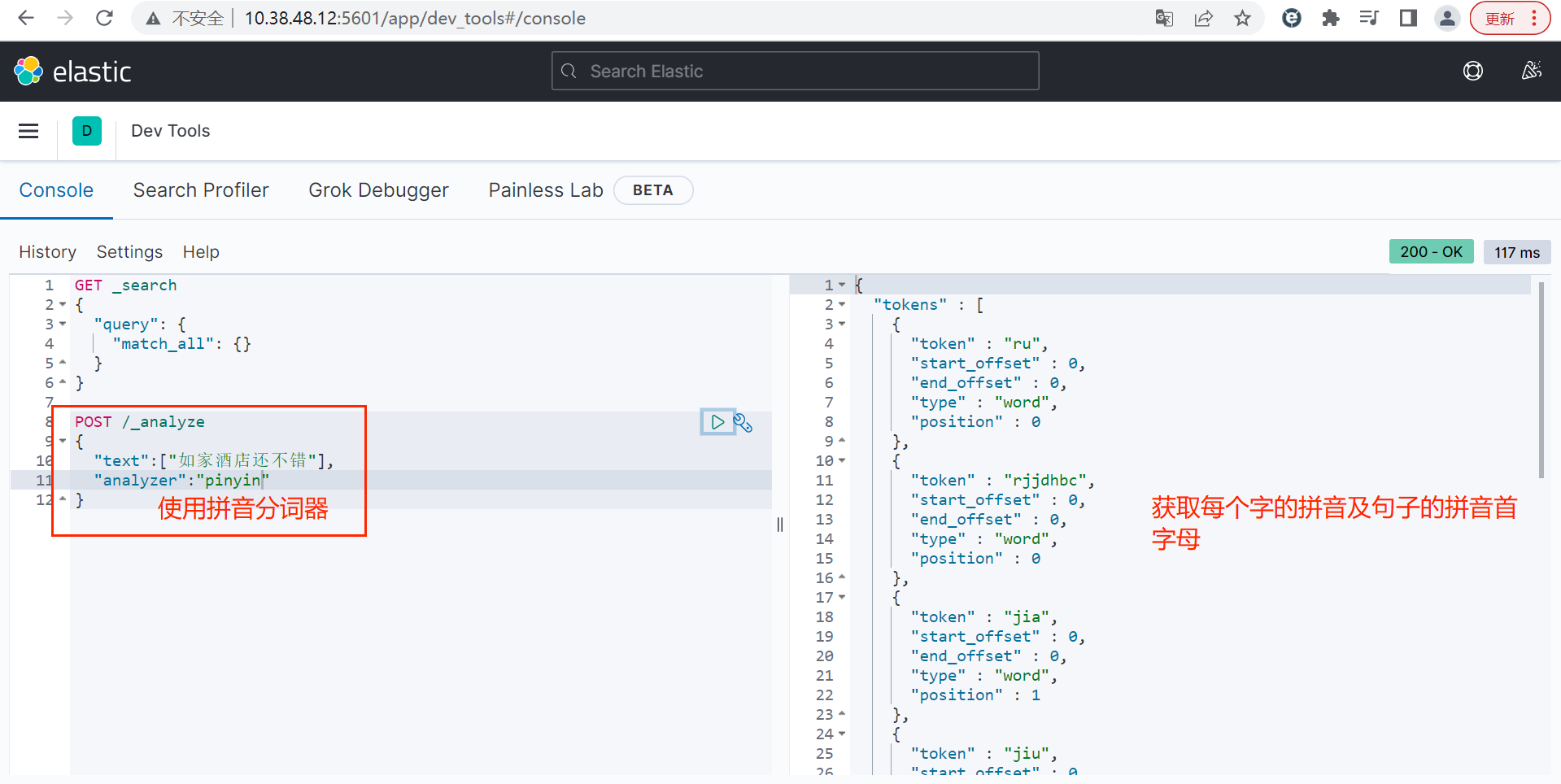
2.2 自动补全查询
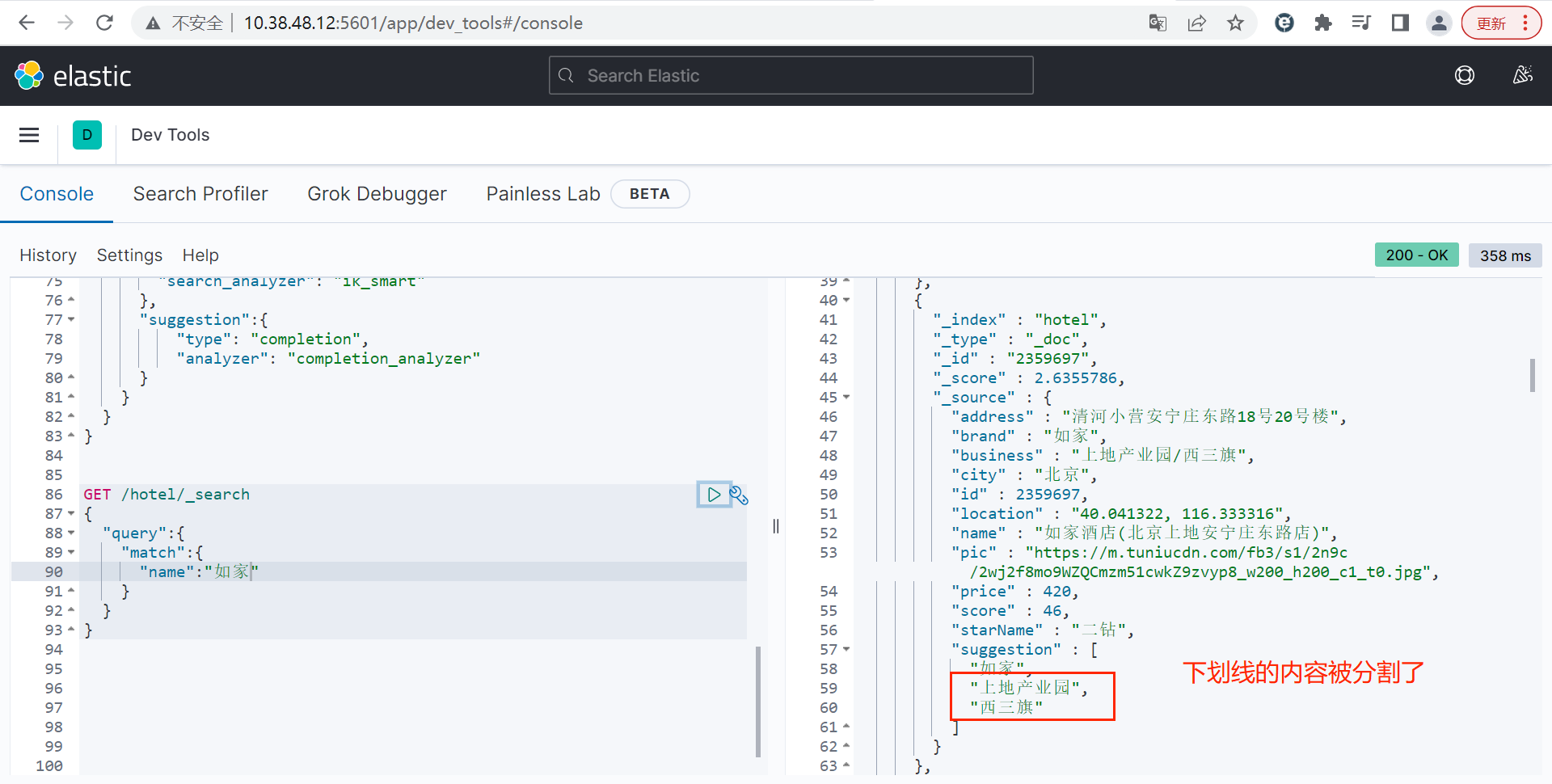
注意:2.1中的拼音分词器的结果只保留了每个字的拼音及句子首字母拼音组合的结果,但是没有保留中文分词,所以还需要对拼音分词器进行改进。
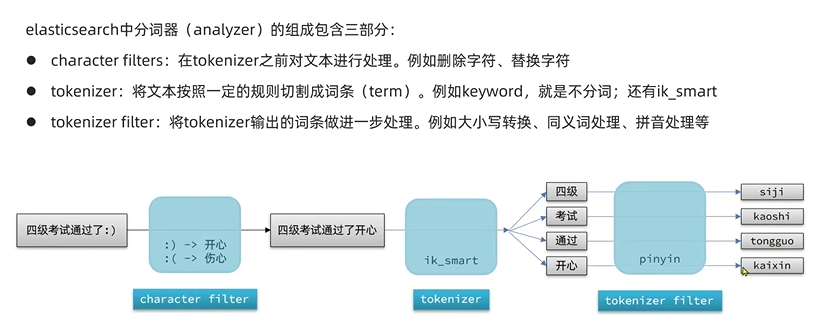
可以在创建索引库时,通过setting来配置自定义的analyzer(分词器):

这里没有定义character filter分词器(分词器的三部分不一定都要有)。
回到之前的拼音分词器结果,可以看到只有单个字的拼音,而没有单个词的拼音,可以在定义分词器的时候修改:
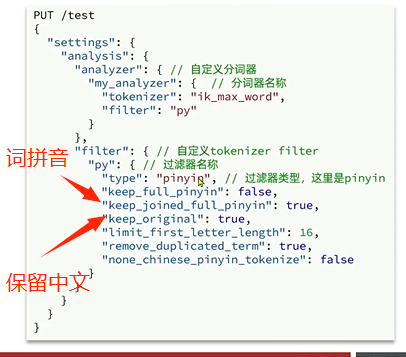
bash
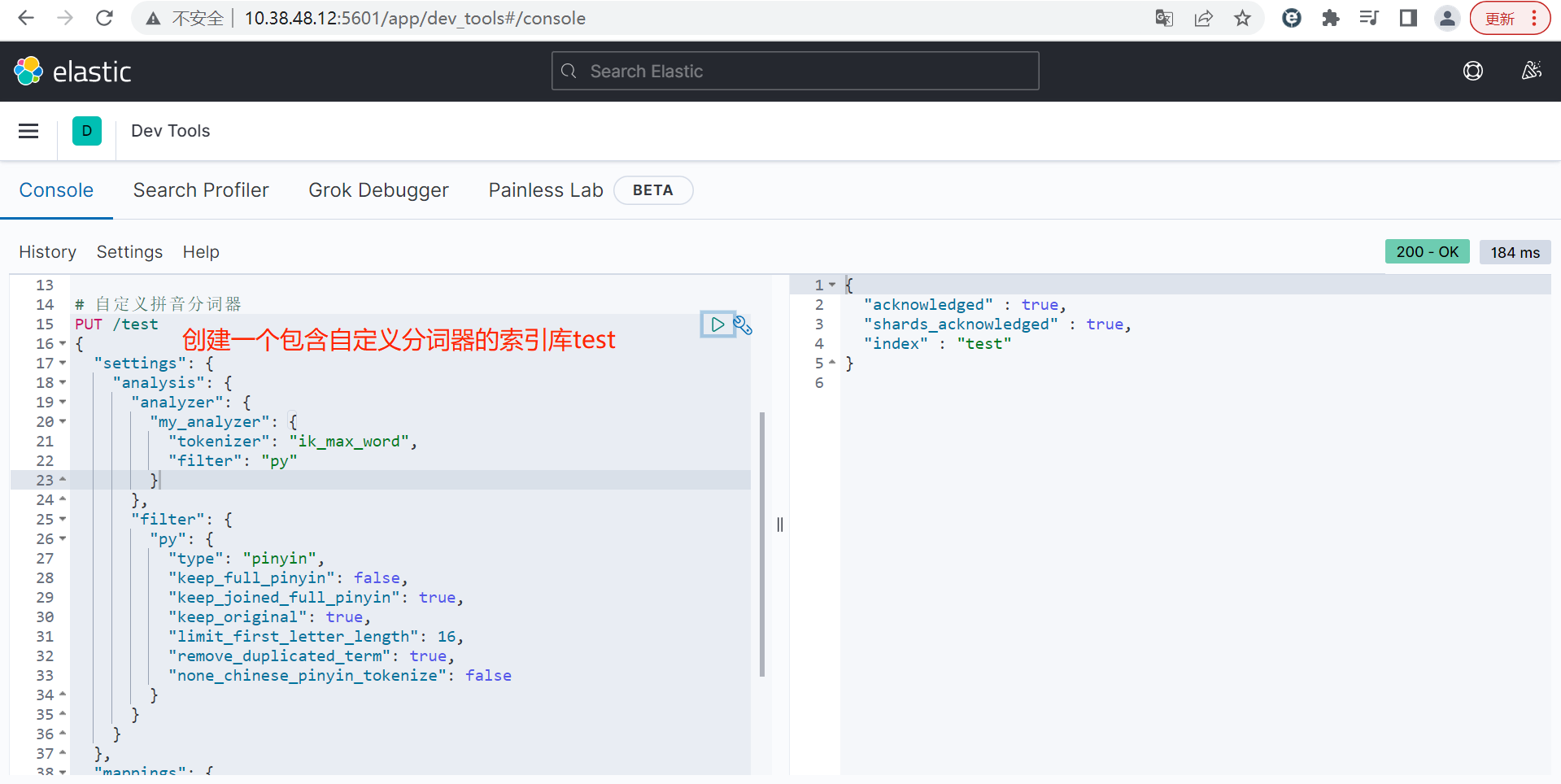
// 自定义拼音分词器
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
}
}
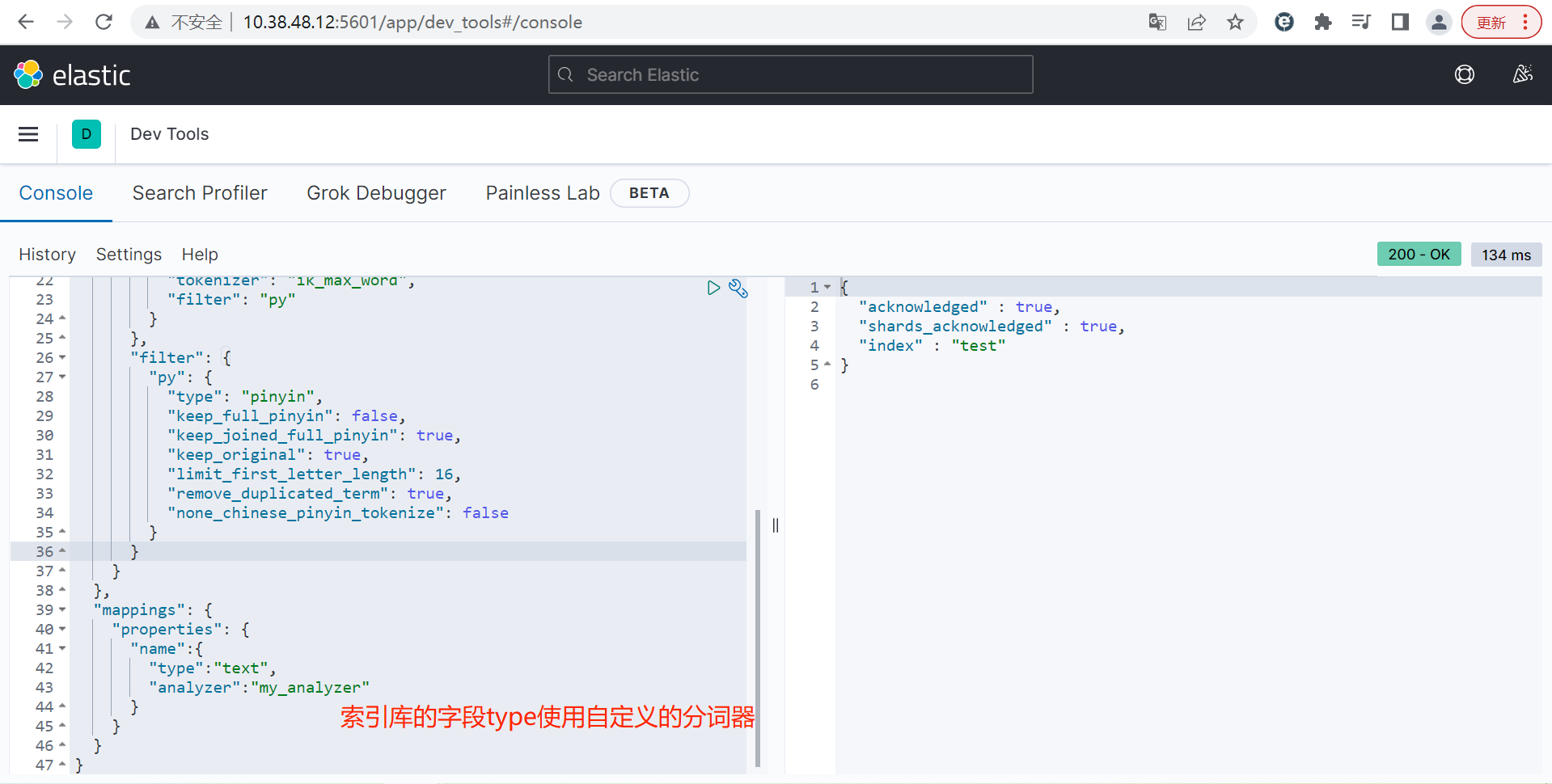
bash
# 自定义拼音分词器
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name":{
"type":"text",
"analyzer":"my_analyzer"
}
}
}
}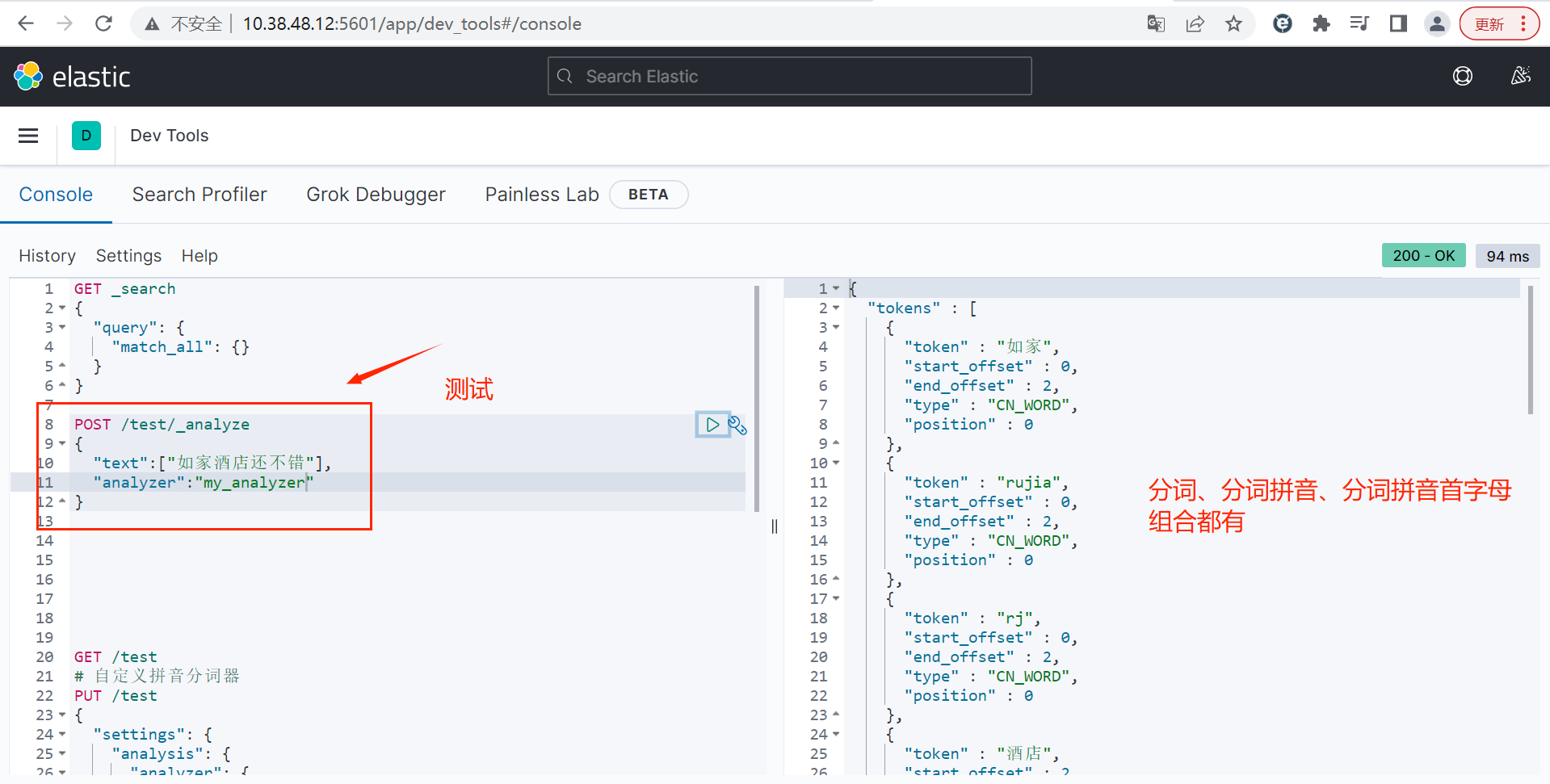
bash
POST /test/_analyze
{
"text":["如家酒店还不错"],
"analyzer":"my_analyzer"
}在举一个查询的例子:
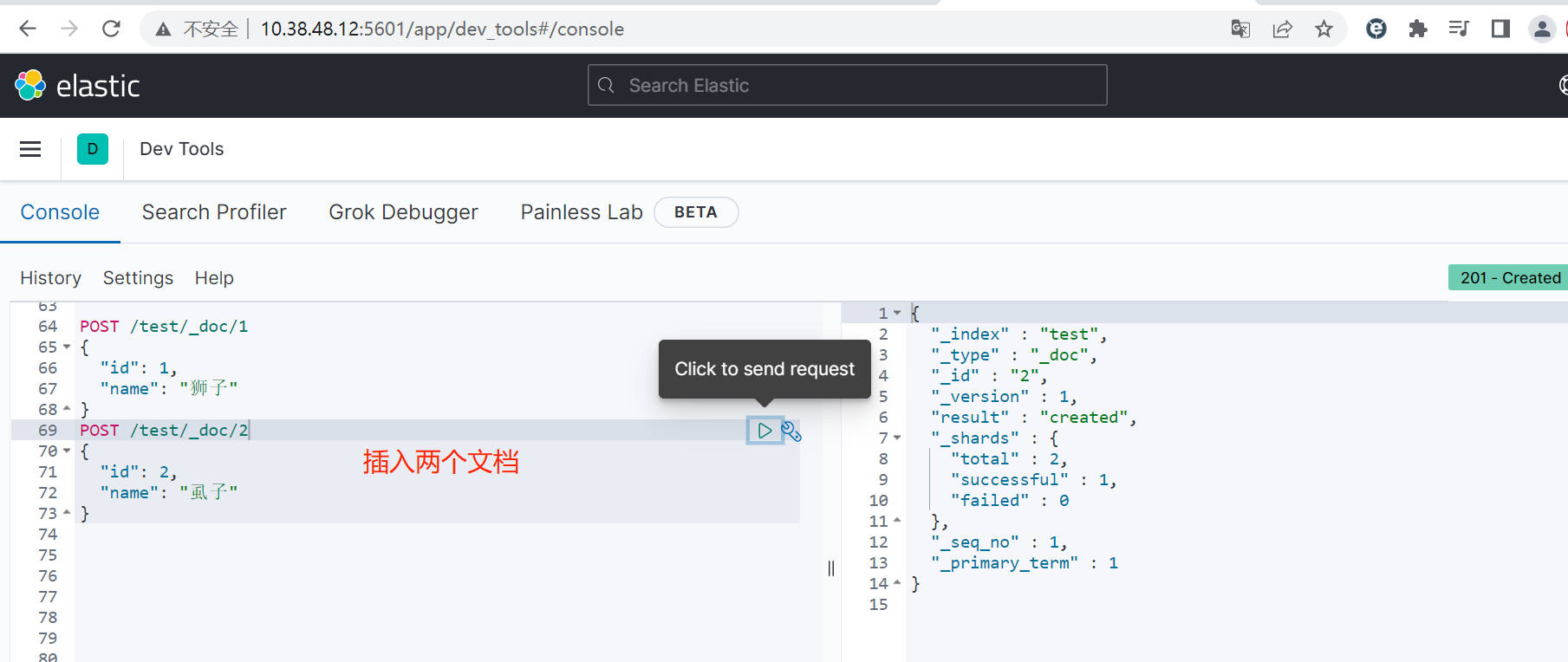
bash
POST /test/_doc/1
{
"id": 1,
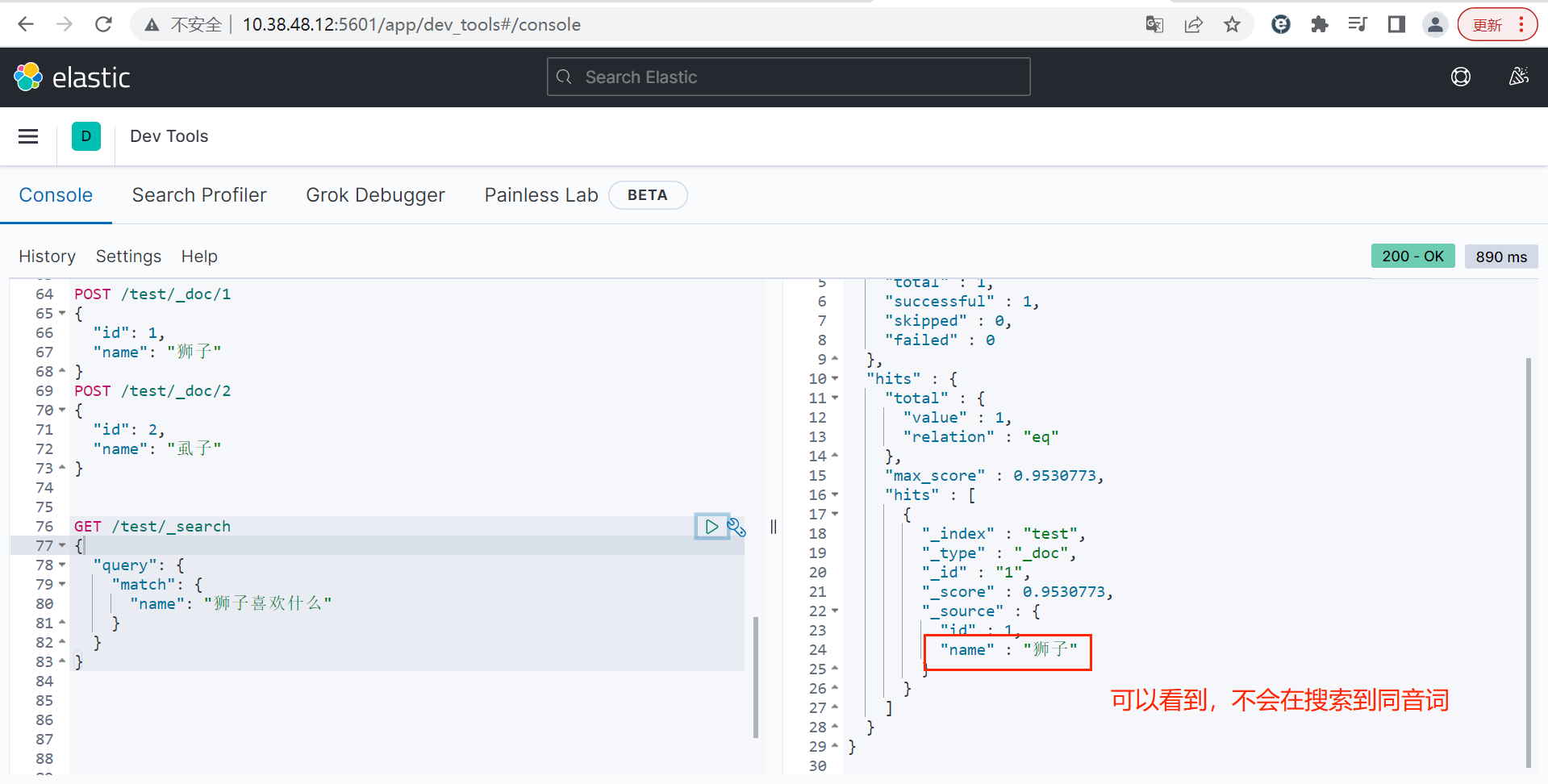
"name": "狮子"
}
POST /test/_doc/2
{
"id": 2,
"name": "虱子"
}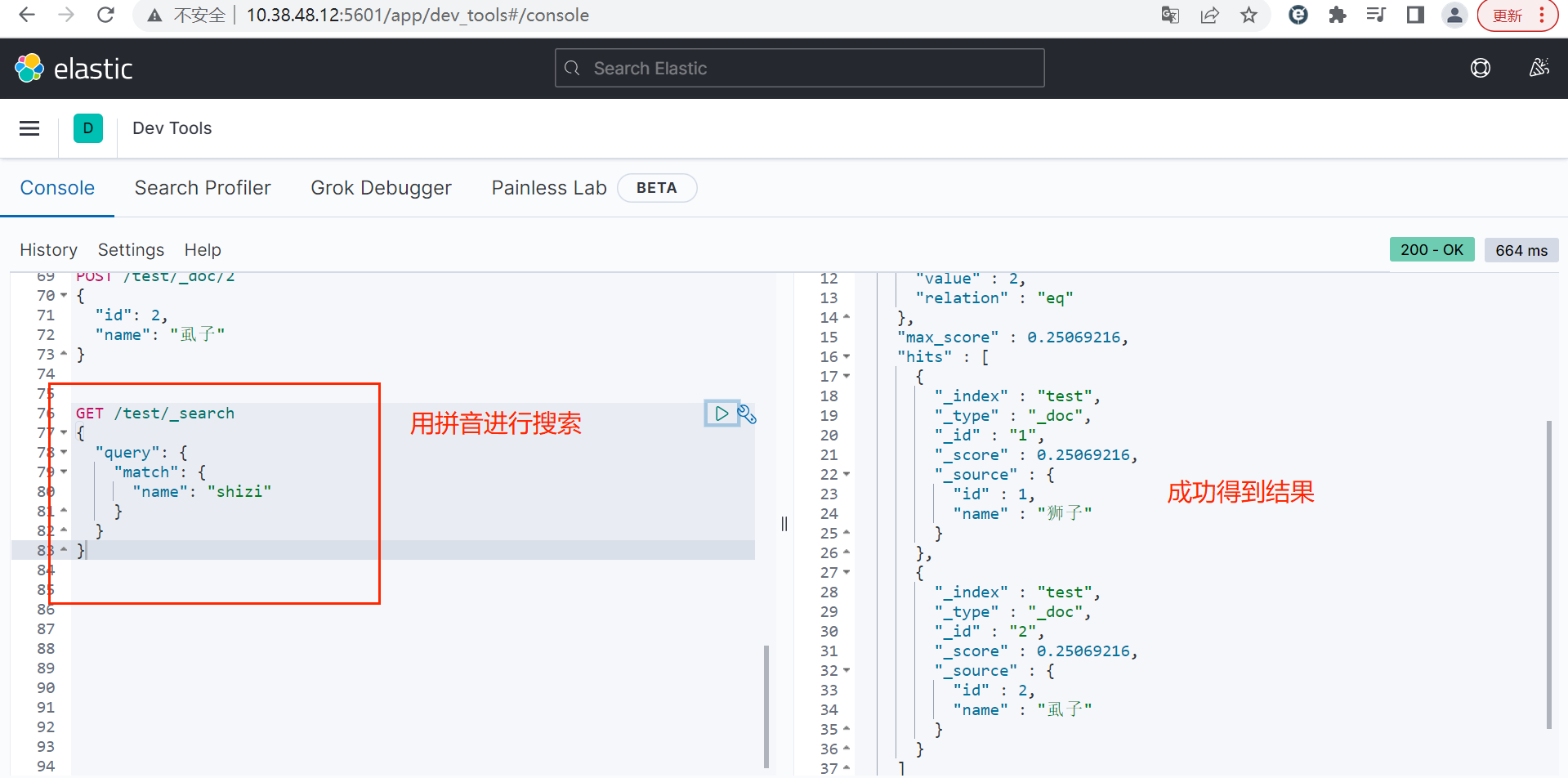
bash
GET /test/_search
{
"query": {
"match": {
"name": "shizi"
}
}
}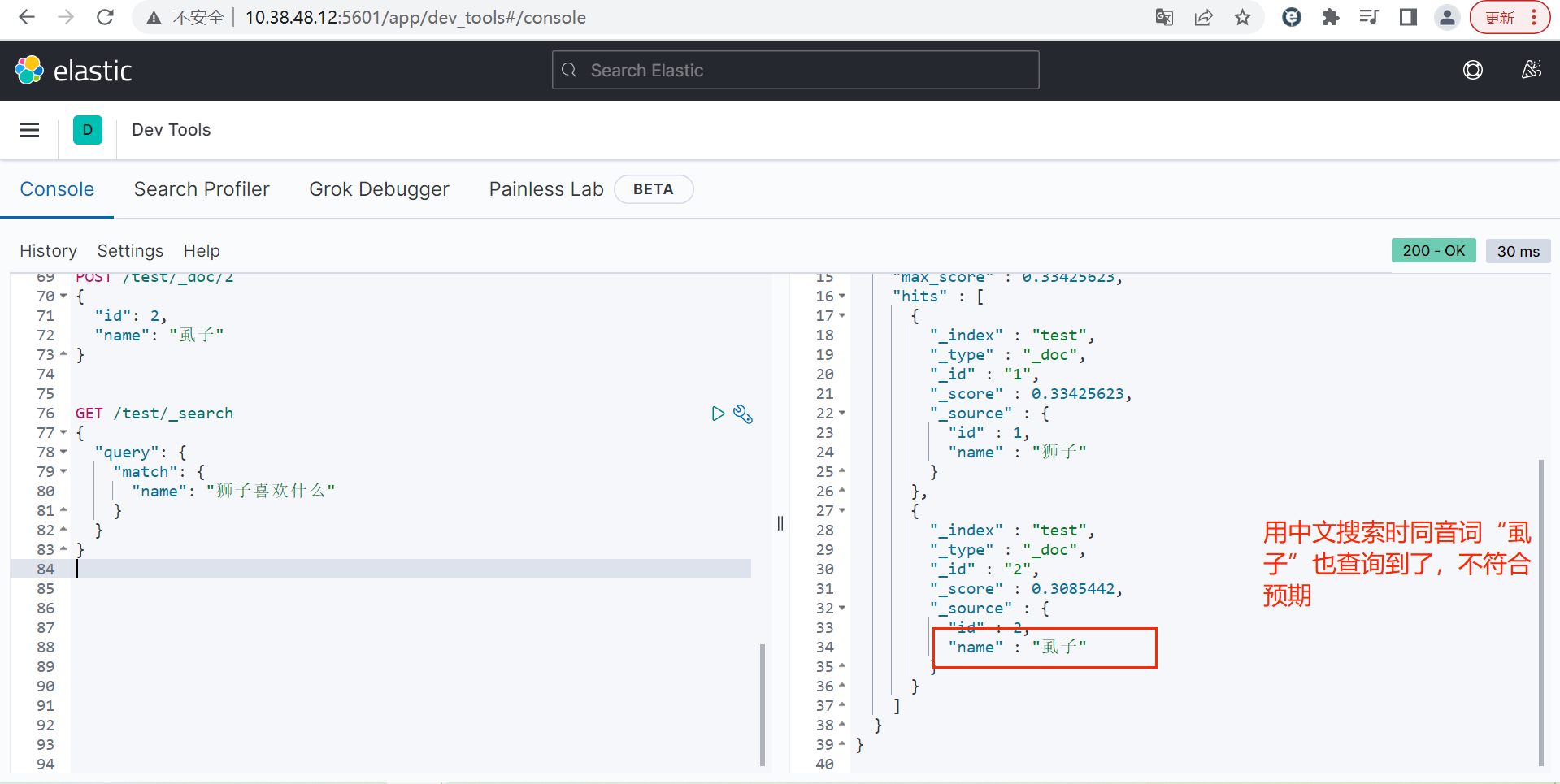
bash
GET /test/_search
{
"query": {
"match": {
"name": "狮子喜欢什么"
}
}
}注意:
拼音分词器适合在创建倒排索引的时候使用,但不能在搜索的时候使用。
因此,字段在创建倒排索引时应该用my_analyzer分词器;字段在搜索时应该使用ik_smart分词器。

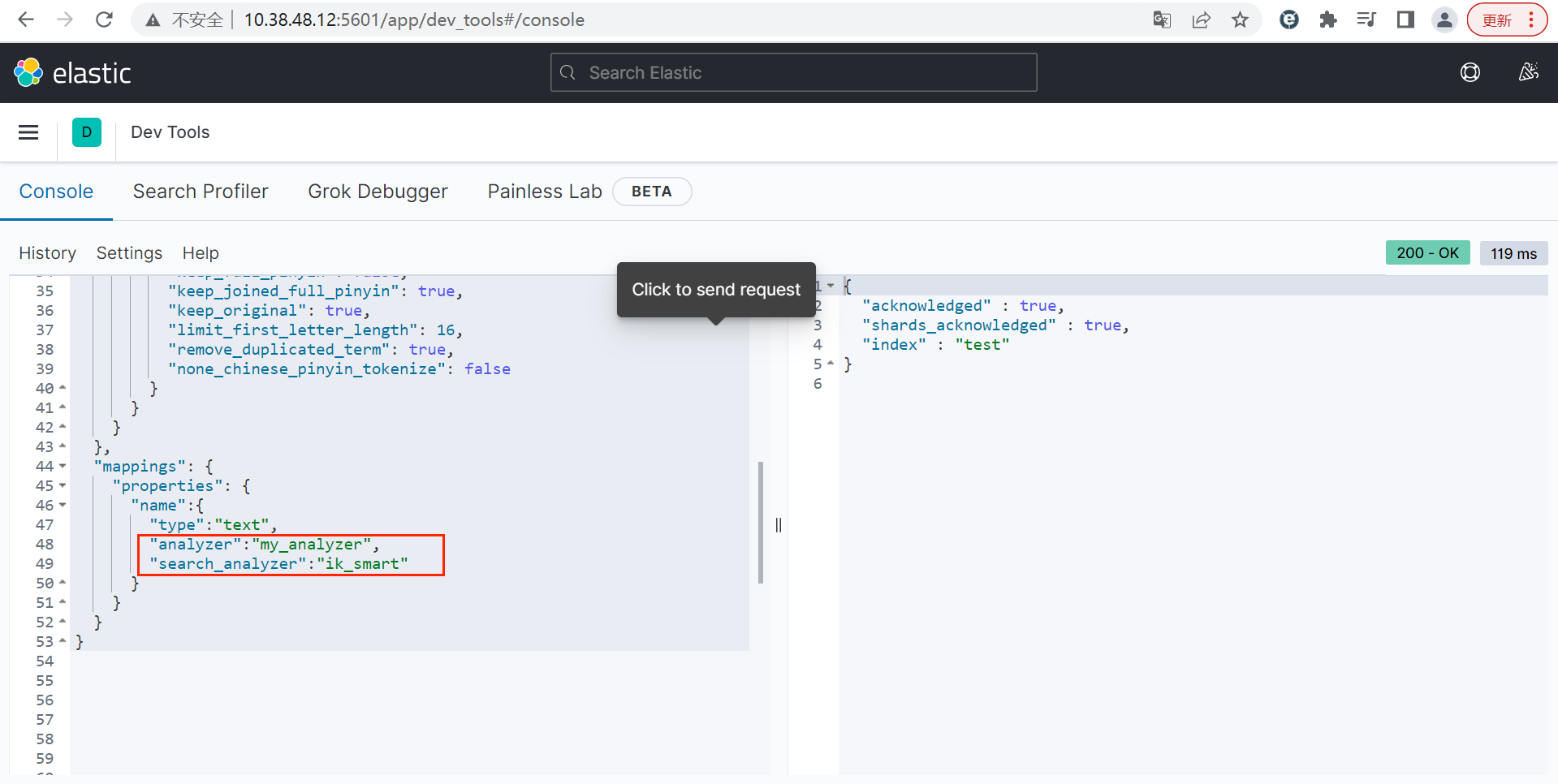
bash
# 自定义拼音分词器
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name":{
"type":"text",
"analyzer":"my_analyzer",
"search_analyzer":"ik_smart"
}
}
}
}
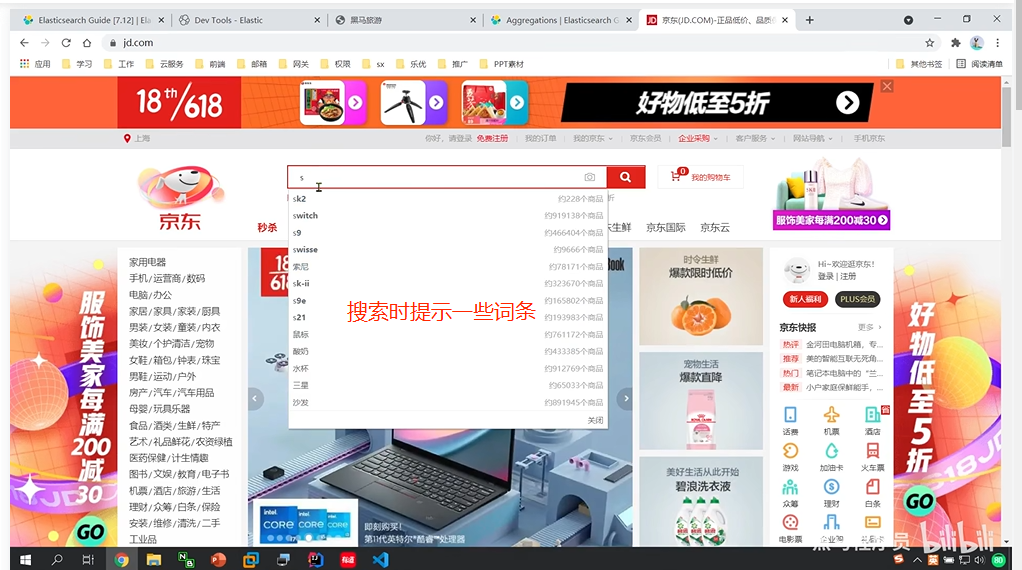
2.3 completion suggester查询
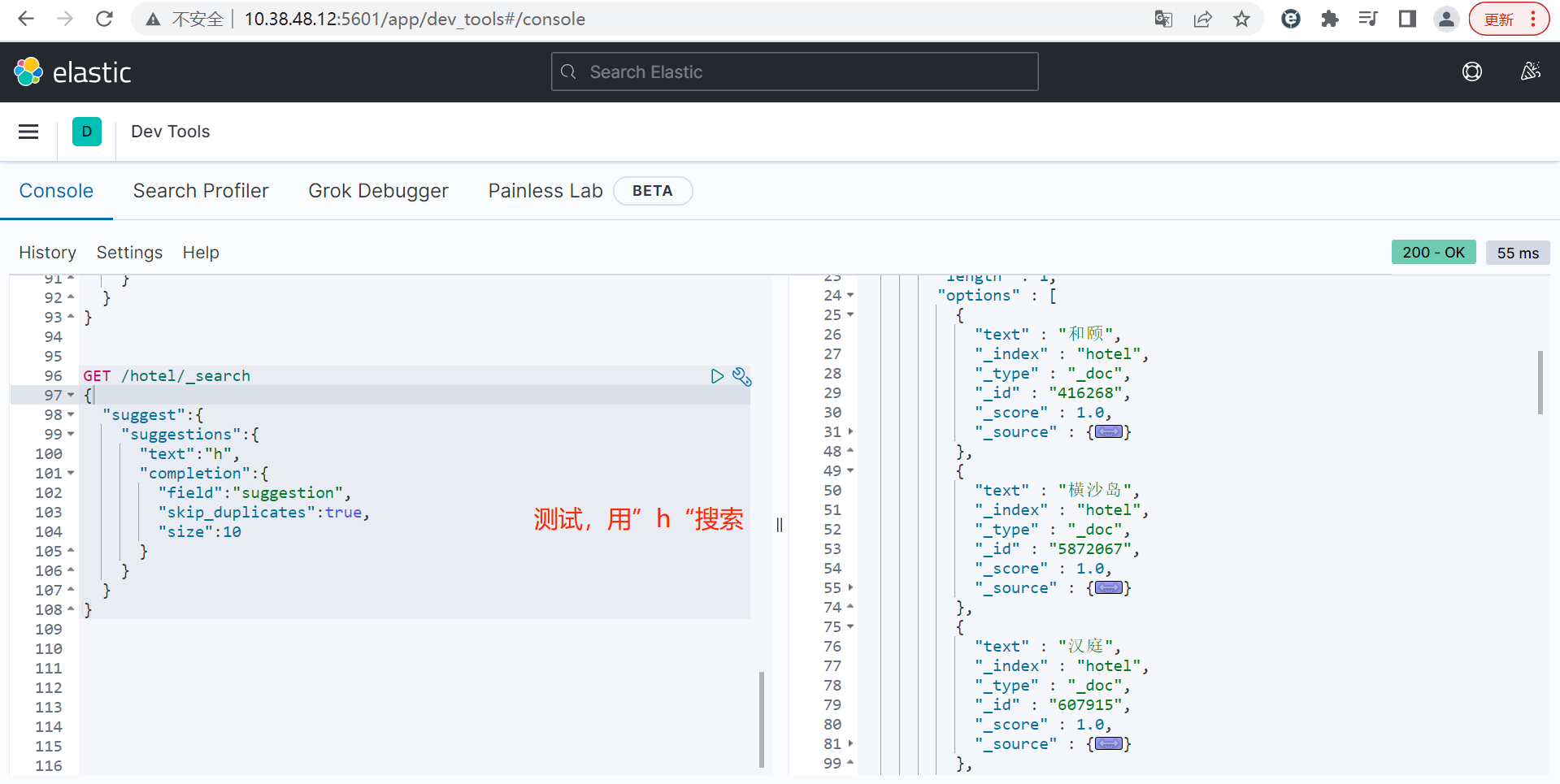
elasticsearch提供了Completion Suggester查询来实现自动补全功能。这个查询会匹配以用户输入内容开头的词条并返回。
为了提高补全查询的效率,对于文档中字段的类型有一些约束:
(1)参与补全查询的字段必须是completion类型。

(2)字段的内容一般是用来补全的多个词条形成的数组。

查询语法如下:

一个例子如下:
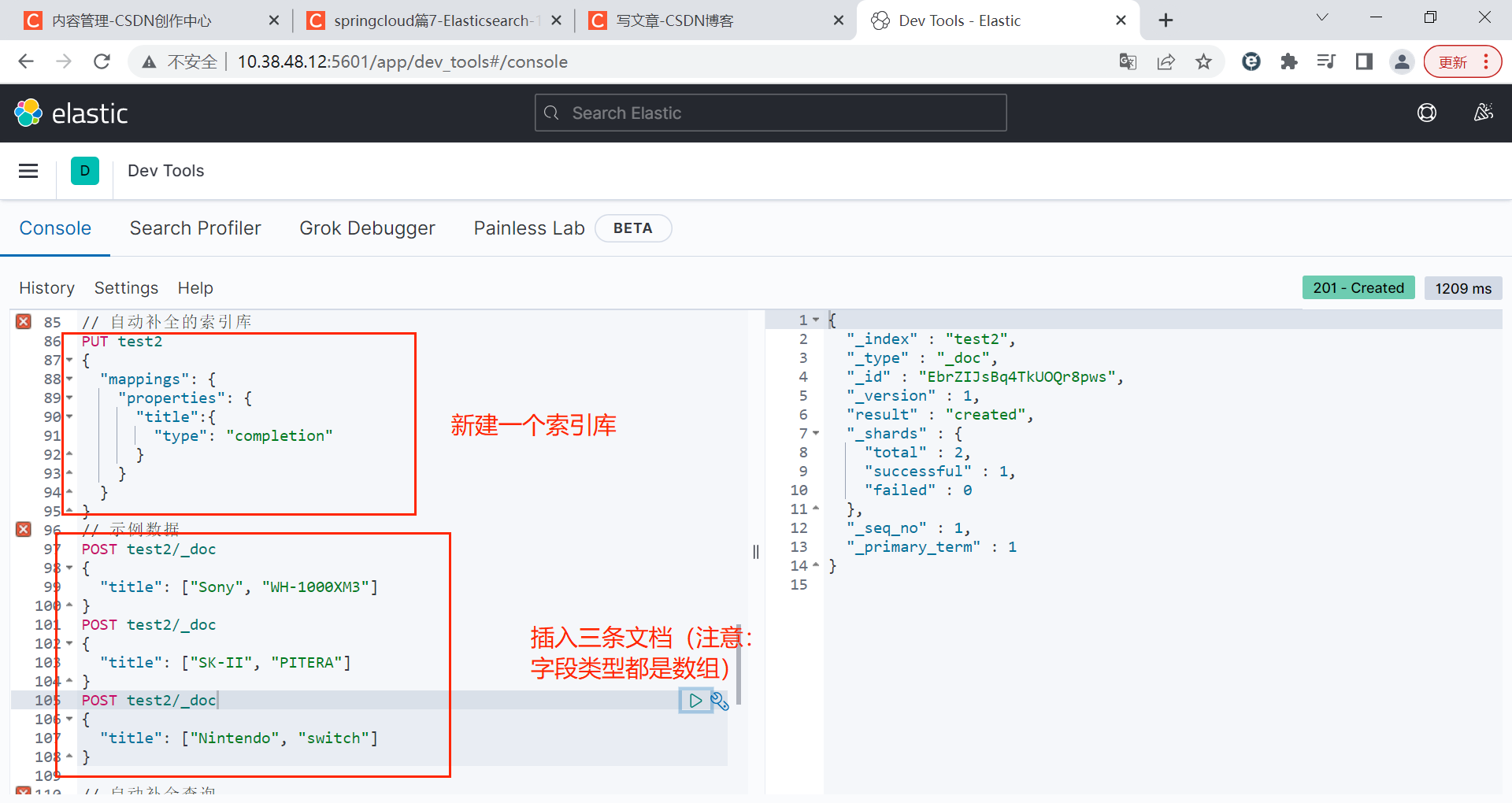
bash
// 自动补全的索引库
PUT test2
{
"mappings": {
"properties": {
"title":{
"type": "completion"
}
}
}
}
// 示例数据
POST test2/_doc
{
"title": ["Sony", "WH-1000XM3"]
}
POST test2/_doc
{
"title": ["SK-II", "PITERA"]
}
POST test2/_doc
{
"title": ["Nintendo", "switch"]
}
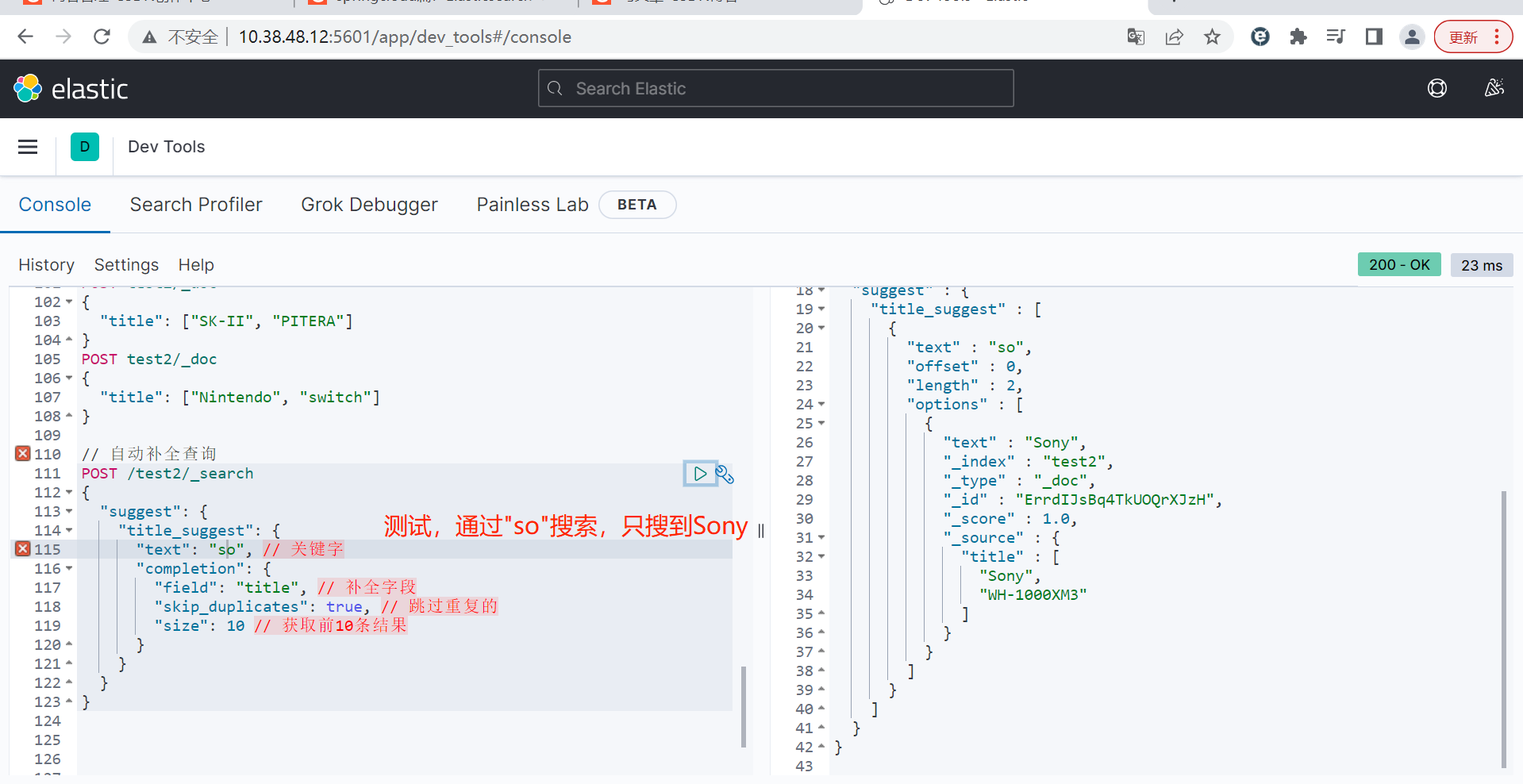
bash
// 自动补全查询
POST /test2/_search
{
"suggest": {
"title_suggest": {
"text": "s", // 关键字
"completion": {
"field": "title", // 补全字段
"skip_duplicates": true, // 跳过重复的
"size": 10 // 获取前10条结果
}
}
}
}
2.4 实战-酒店数据自动补全

2.4.0 数据库改造
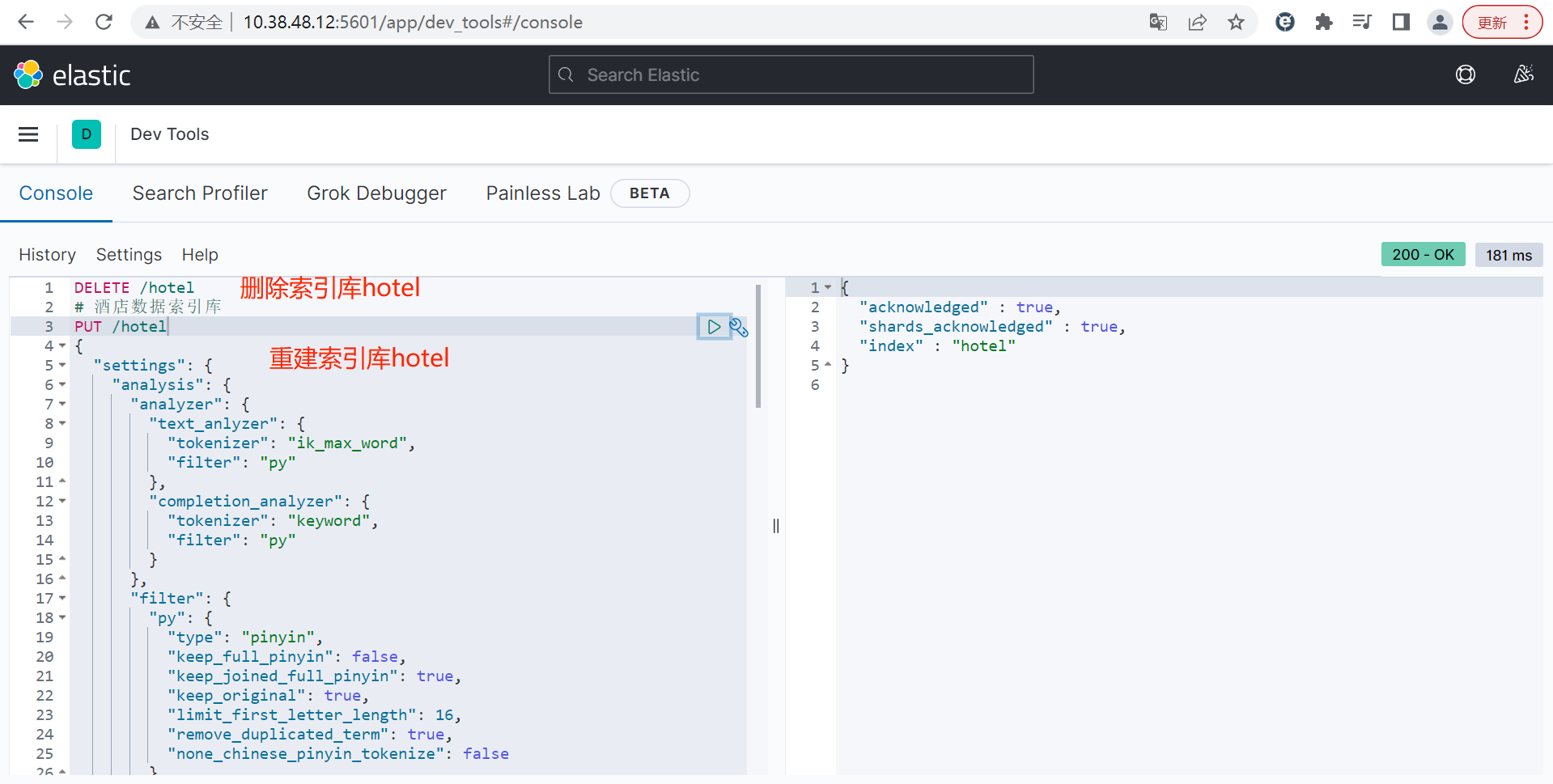
bash
DELETE /hotel
# 酒店数据索引库
PUT /hotel
{
"settings": {
"analysis": {
"analyzer": {
"text_anlyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
},
"completion_analyzer": {
"tokenizer": "keyword",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart",
"copy_to": "all"
},
"address":{
"type": "keyword",
"index": false
},
"price":{
"type": "integer"
},
"score":{
"type": "integer"
},
"brand":{
"type": "keyword",
"copy_to": "all"
},
"city":{
"type": "keyword"
},
"starName":{
"type": "keyword"
},
"business":{
"type": "keyword",
"copy_to": "all"
},
"location":{
"type": "geo_point"
},
"pic":{
"type": "keyword",
"index": false
},
"all":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart"
},
"suggestion":{
"type": "completion",
"analyzer": "completion_analyzer"
}
}
}
}注意,hotel索引添加了一个字段suggestion。
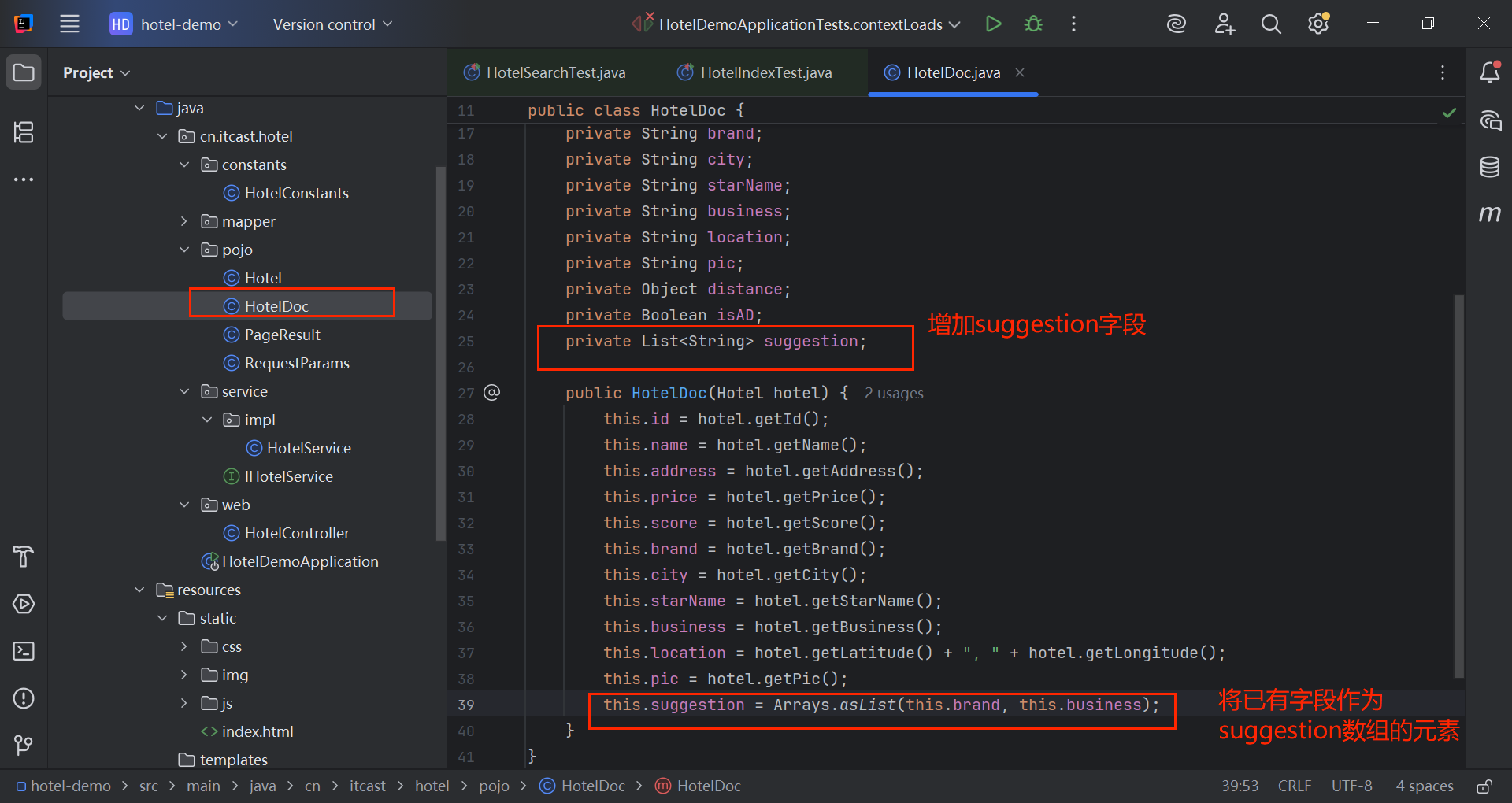
java
@Data
@NoArgsConstructor
public class HotelDoc {
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String location;
private String pic;
private Object distance;
private Boolean isAD;
private List<String> suggestion;
public HotelDoc(Hotel hotel) {
this.id = hotel.getId();
this.name = hotel.getName();
this.address = hotel.getAddress();
this.price = hotel.getPrice();
this.score = hotel.getScore();
this.brand = hotel.getBrand();
this.city = hotel.getCity();
this.starName = hotel.getStarName();
this.business = hotel.getBusiness();
this.location = hotel.getLatitude() + ", " + hotel.getLongitude();
this.pic = hotel.getPic();
this.suggestion = Arrays.asList(this.brand, this.business);
}
}
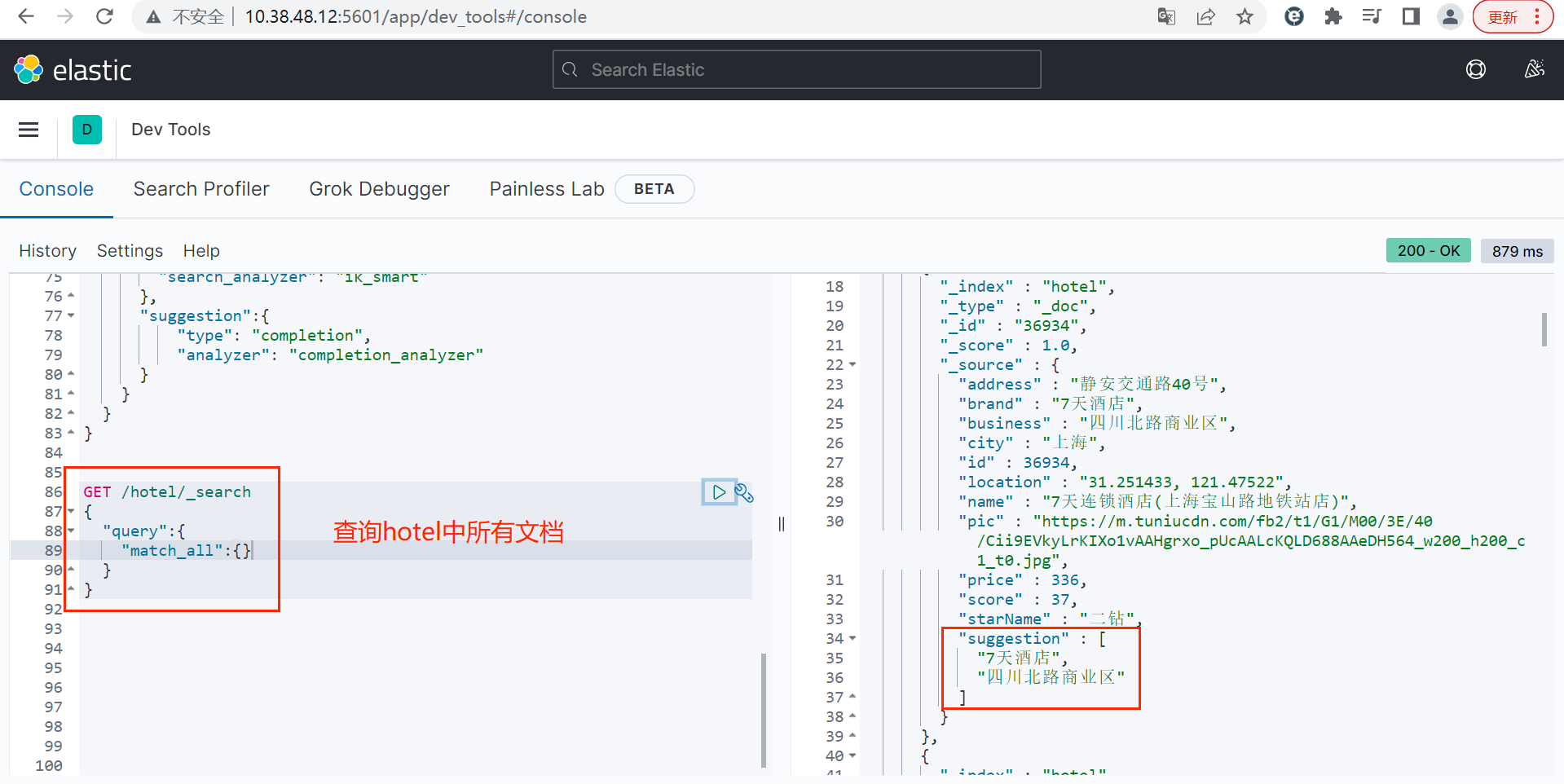
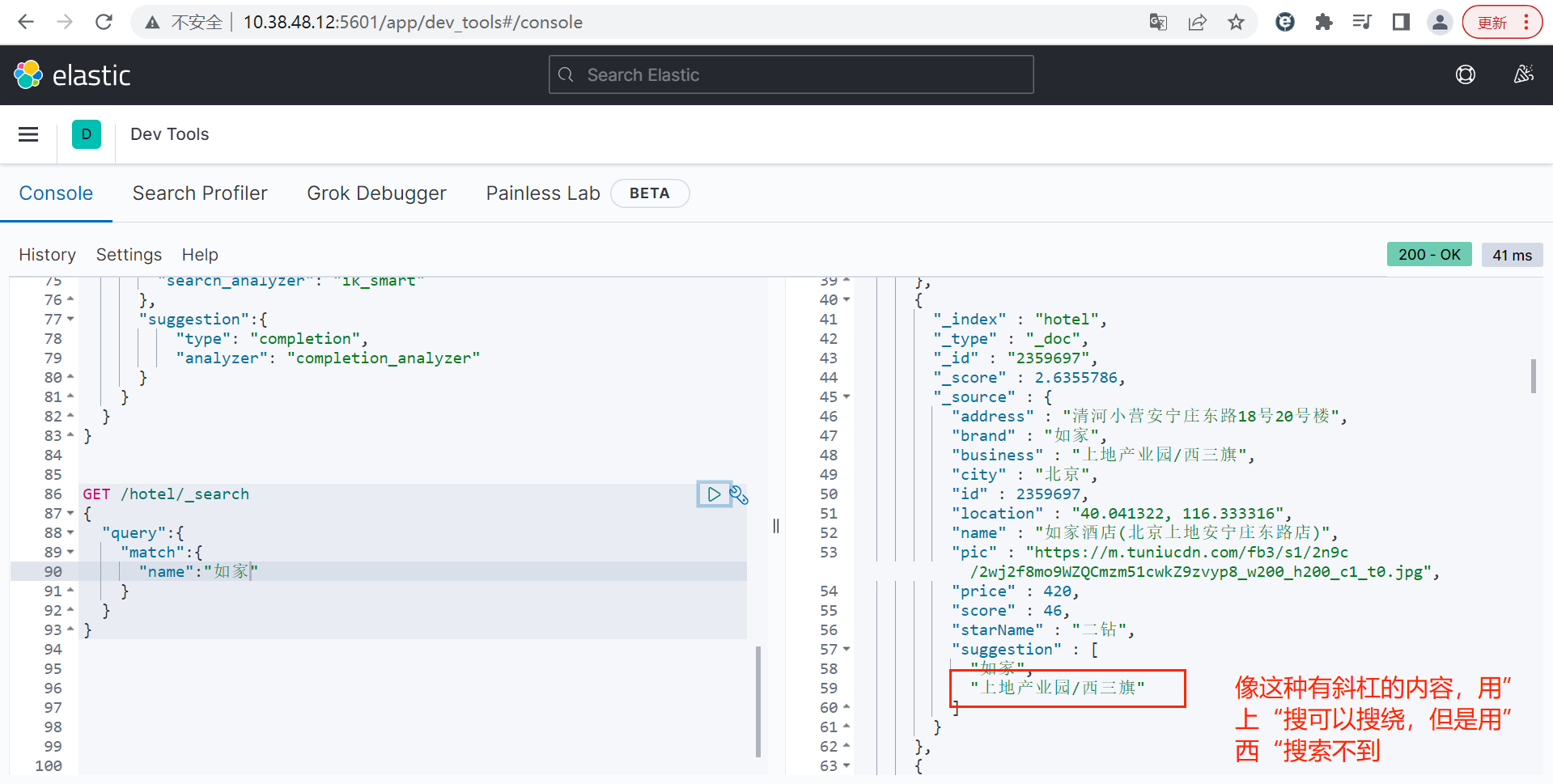
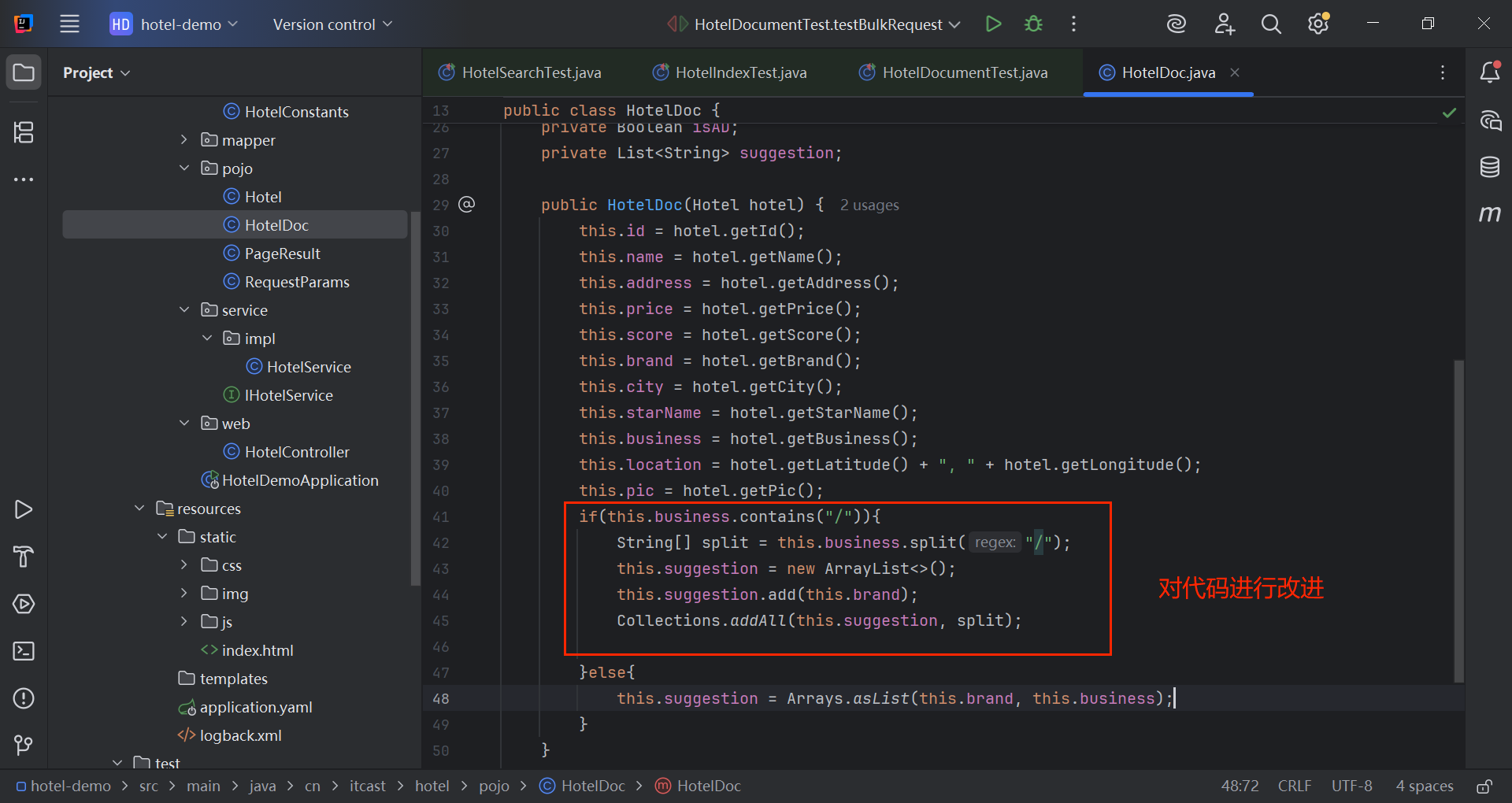
还有一个细节需要处理:
java
@Data
@NoArgsConstructor
public class HotelDoc {
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String location;
private String pic;
private Object distance;
private Boolean isAD;
private List<String> suggestion;
public HotelDoc(Hotel hotel) {
this.id = hotel.getId();
this.name = hotel.getName();
this.address = hotel.getAddress();
this.price = hotel.getPrice();
this.score = hotel.getScore();
this.brand = hotel.getBrand();
this.city = hotel.getCity();
this.starName = hotel.getStarName();
this.business = hotel.getBusiness();
this.location = hotel.getLatitude() + ", " + hotel.getLongitude();
this.pic = hotel.getPic();
if(this.business.contains("/")){
String[] split = this.business.split("/");
this.suggestion = new ArrayList<>();
this.suggestion.add(this.brand);
Collections.addAll(this.suggestion, split);
}else{
this.suggestion = Arrays.asList(this.brand, this.business);
}
}
}
java
GET /hotel/_search
{
"suggest":{
"suggestions":{
"text":"h",
"completion":{
"field":"suggestion",
"skip_duplicates":true,
"size":10
}
}
}
}2.4.1 理论:RestAPI实现自动补全
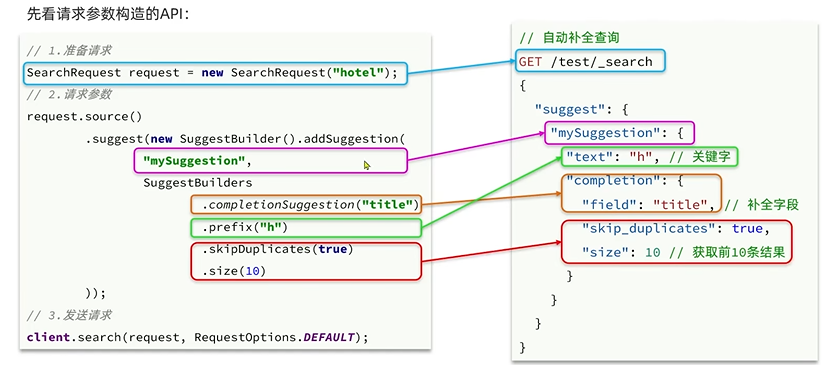
java
@Test
void testSuggest() throws IOException {
//1.创建Request对象
SearchRequest request=new SearchRequest("hotel");
//2.准备DSL语句
request.source().suggest(new SuggestBuilder().addSuggestion(
"suggestions",
SuggestBuilders.completionSuggestion("suggestion")
.prefix("h")
.skipDuplicates(true)
.size(10)
));
//3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
System.out.println(response);
//4.解析结果
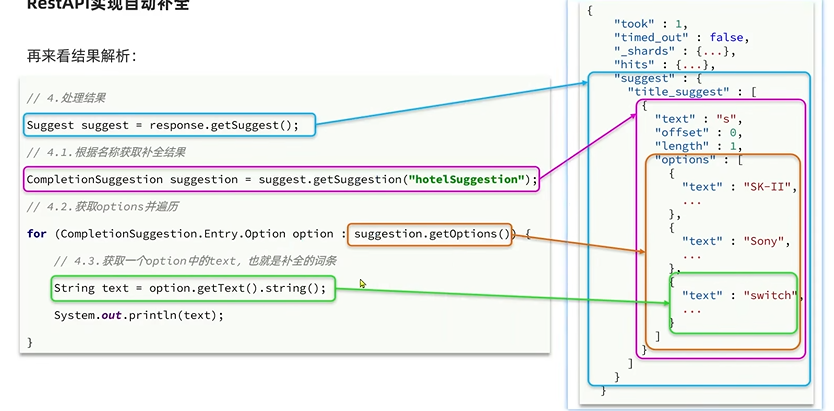
Suggest suggest = response.getSuggest();
//4.1 根据补全查询名称,获取补全结果
CompletionSuggestion suggestions = suggest.getSuggestion("suggestions");
//4.2获取options
List<CompletionSuggestion.Entry.Option> options = suggestions.getOptions();
//4.3遍历
for(CompletionSuggestion.Entry.Option option : options){
String text=option.getText().toString();
System.out.println(text);
}
}
2.4.2 前端页面实现
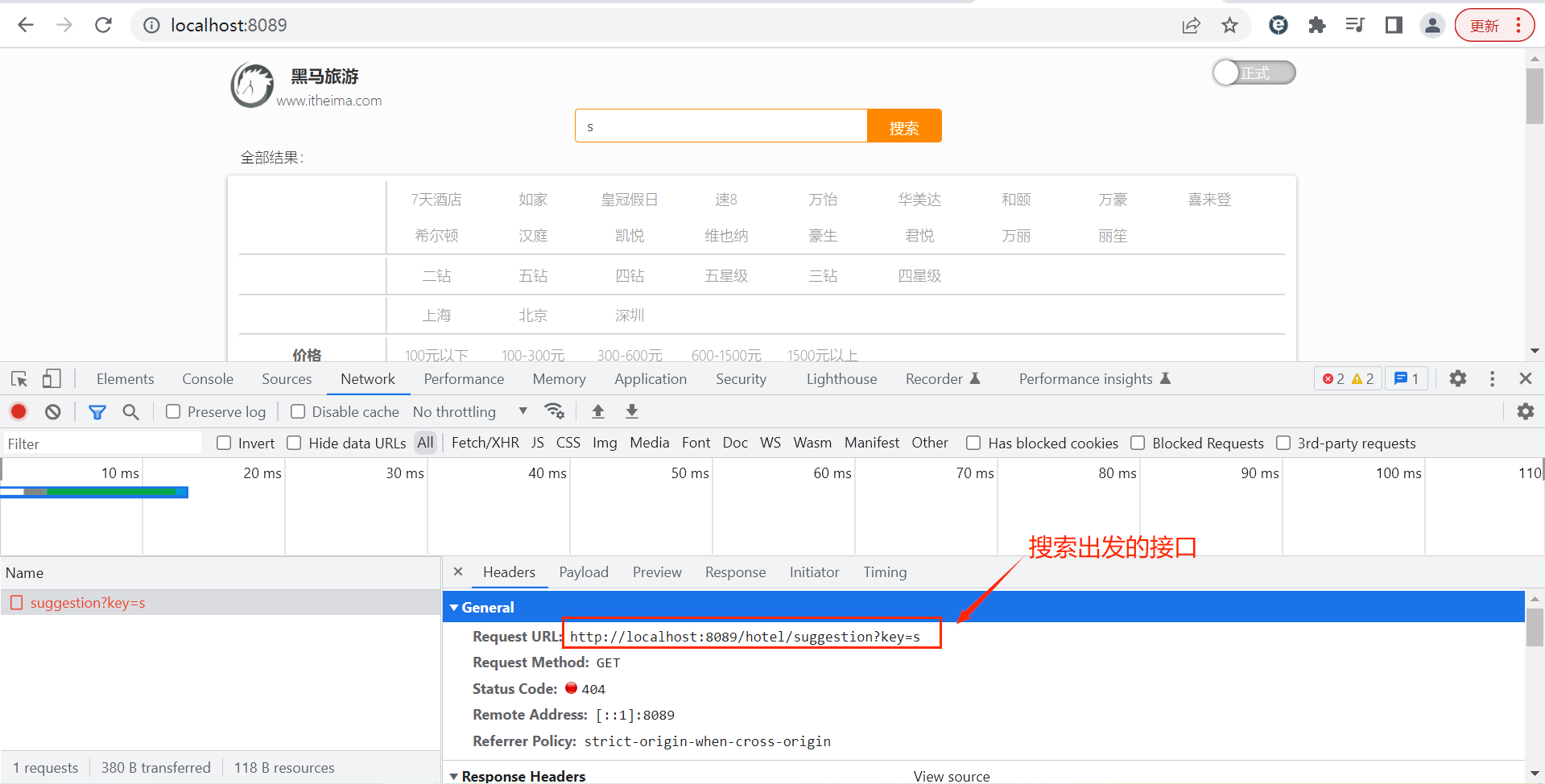
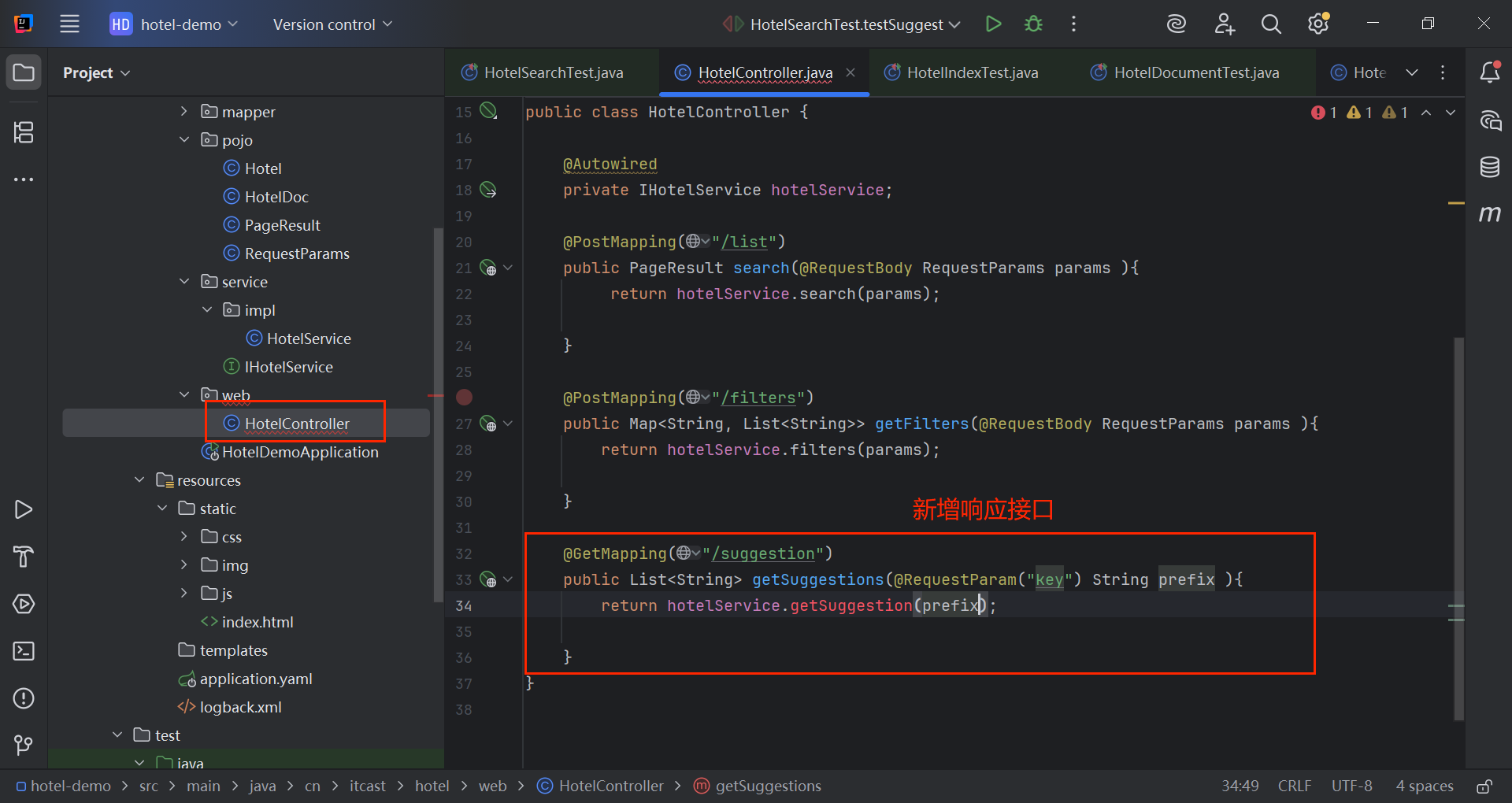
java
@GetMapping("/suggestion")
public List<String> getSuggestions(@RequestParam("key") String prefix ){
return hotelService.getSuggestion(prefix);
}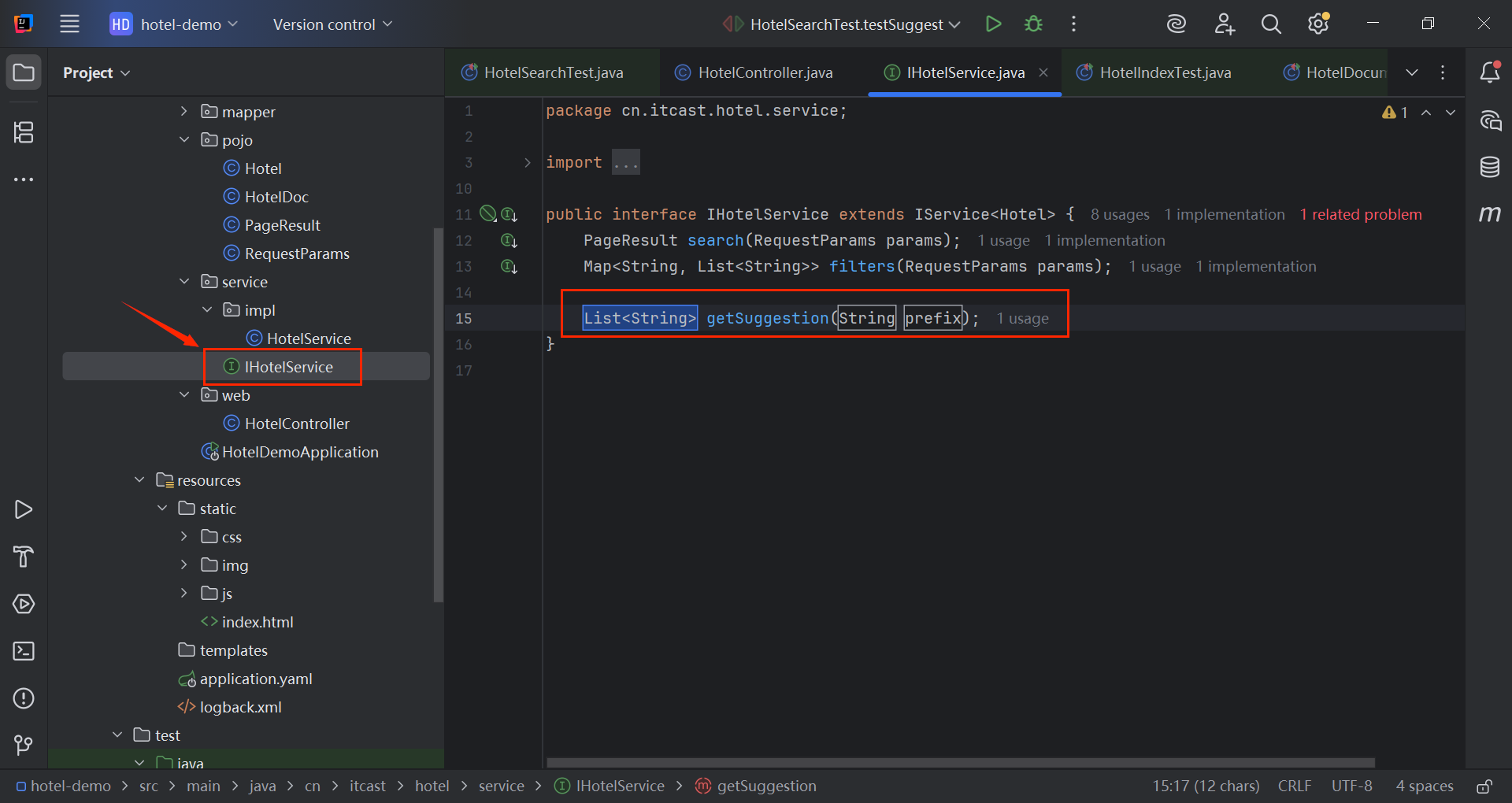
java
List<String> getSuggestion(String prefix);
java
@Override
public List<String> getSuggestion(String prefix) {
try {
//1.创建Request对象
SearchRequest request=new SearchRequest("hotel");
//2.准备DSL语句
request.source().suggest(new SuggestBuilder().addSuggestion(
"suggestions",
SuggestBuilders.completionSuggestion("suggestion")
.prefix(prefix)
.skipDuplicates(true)
.size(10)
));
//3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.解析结果
Suggest suggest = response.getSuggest();
//4.1 根据补全查询名称,获取补全结果
CompletionSuggestion suggestions = suggest.getSuggestion("suggestions");
//4.2获取options
List<CompletionSuggestion.Entry.Option> options = suggestions.getOptions();
//4.3遍历
List<String> list= new ArrayList<>(options.size());
for(CompletionSuggestion.Entry.Option option : options){
String text=option.getText().toString();
list.add(text);
}
return list;
} catch (IOException e) {
throw new RuntimeException(e);
}
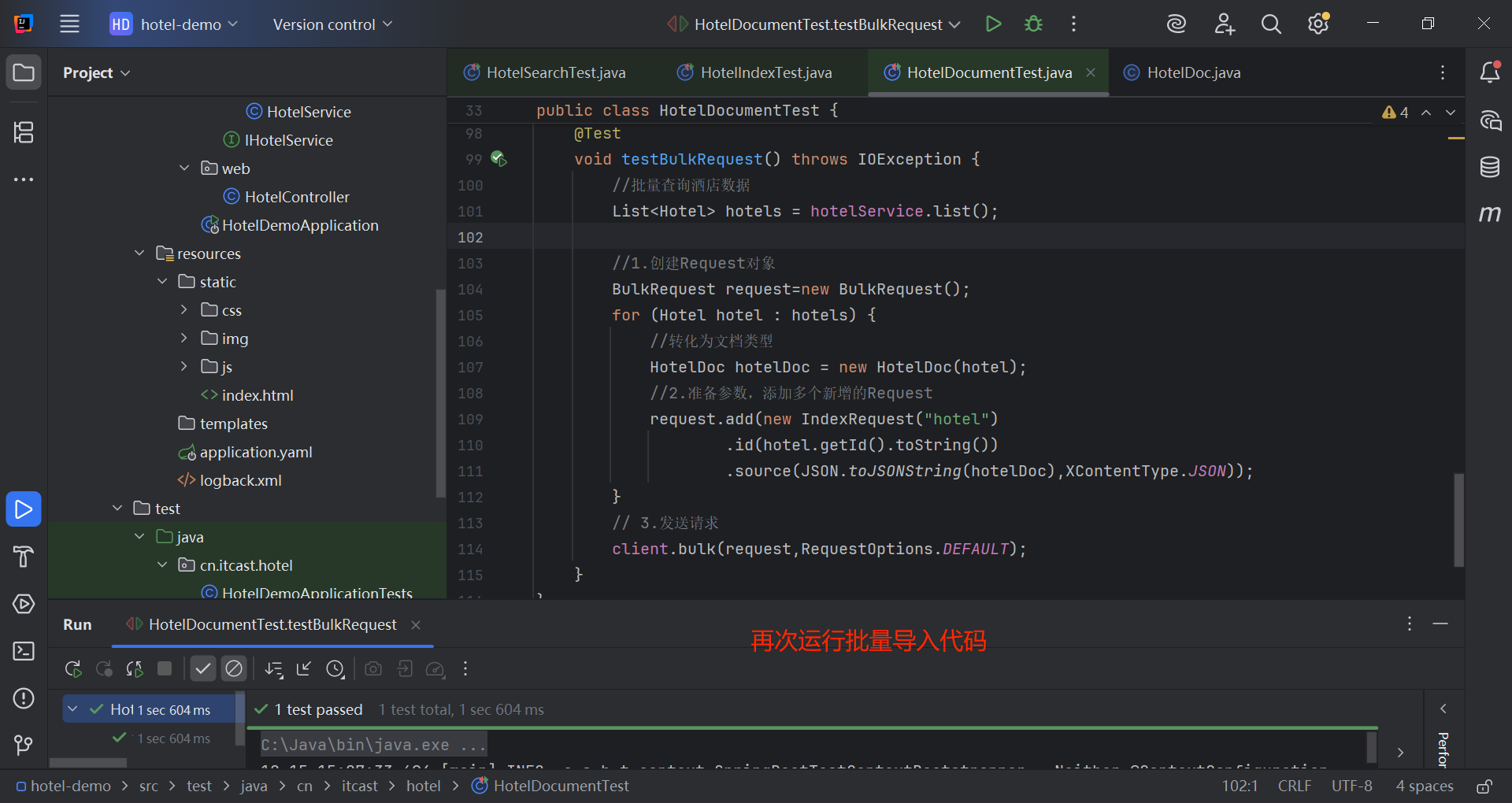
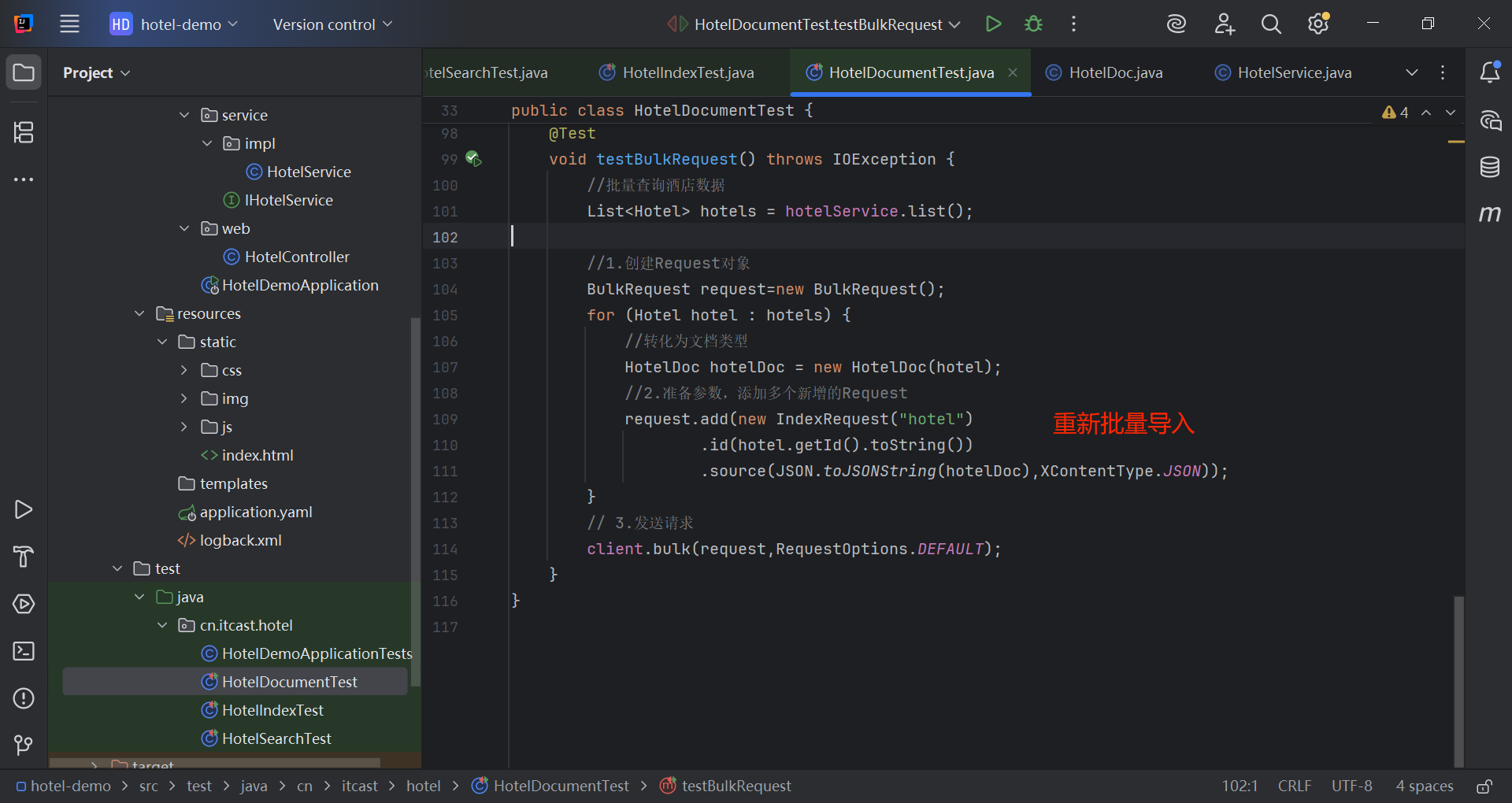
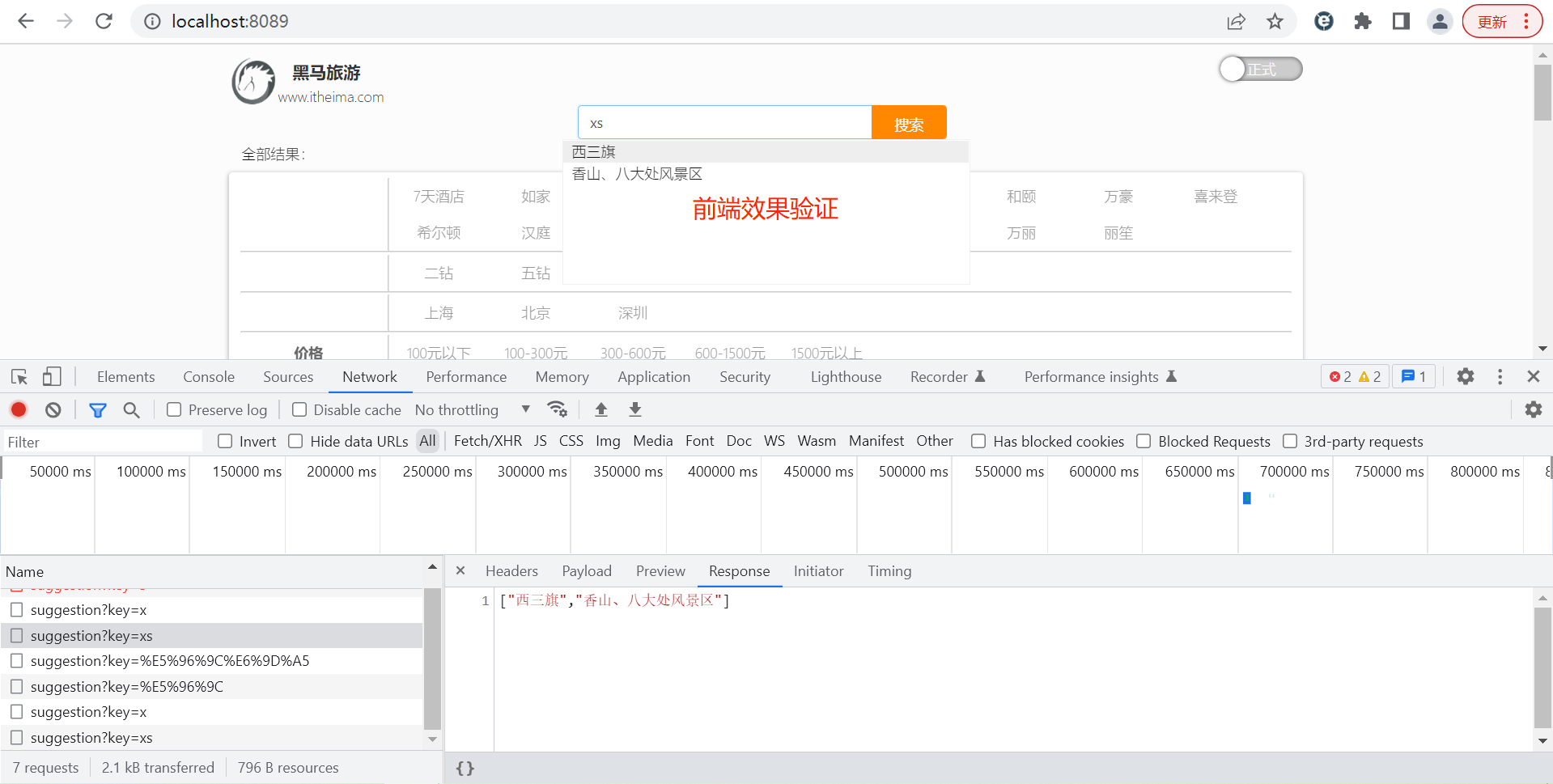
}重启服务测试:
三、数据同步
3.1 三种方案
数据同步与业务无关,但是非常重要,面试也经常问。
elasticsearch中的酒店数据来自于mysql数据库,因此mysql数据发生变化时,elasticsearch也必须跟着改变,这个就是elasticsearch与mysql之间的数据同步。
在微服务中,负责酒店管理(操作mysql)的业务与负责酒店搜索(操作elasticsearch)的业务可能在两个不同的微服务上,数据该如何实现同步。
(1)方案一:同步调用
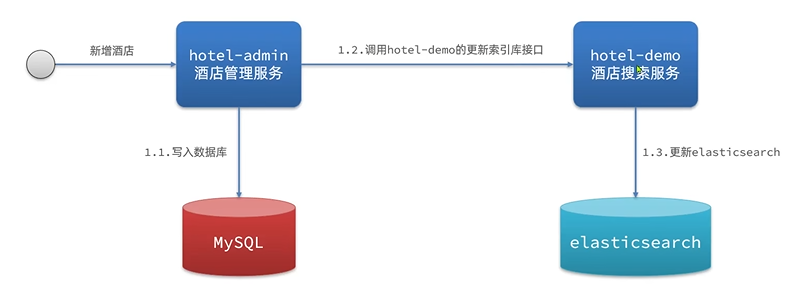
写mysql、调用根据索引库接口和更新elasticsearch先后执行,耗时较长。
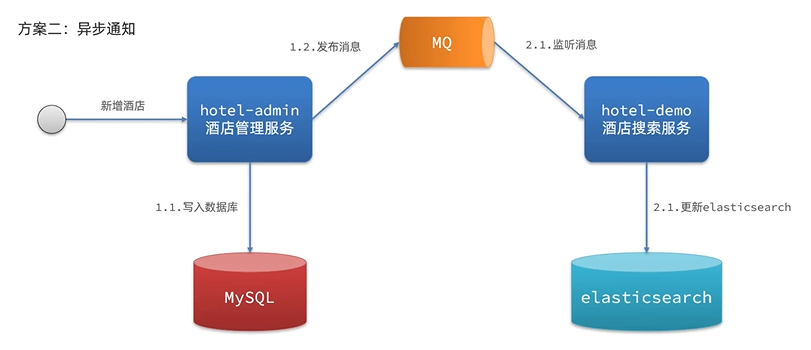
(二)方案二:异步通知
(三)监听binlog
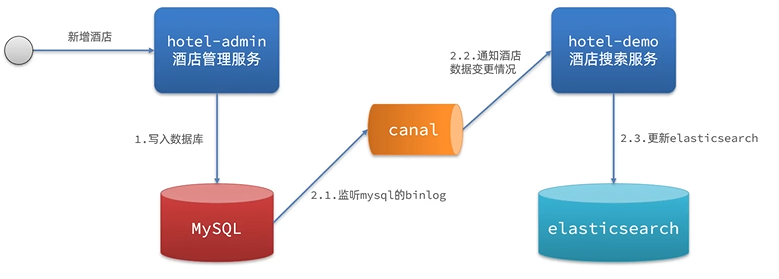
mysql的binlog默认是关闭的。开启后,binlog可以记录mysql的增删改查操作,可以利用类似于canal这样的中间件监听binlog,一旦发生binlog变化则通知酒店数据变更情况。但是开启binlog对于mysql性能影响大,增加数据库负担,且实现负责都高。
3.2 MQ方案实现

3.2.1 导入项目
数据库即为博文《Springcloud篇7-Elasticsearch-1》与《Springcloud篇8-Elasticsearch-2》的酒店数据。
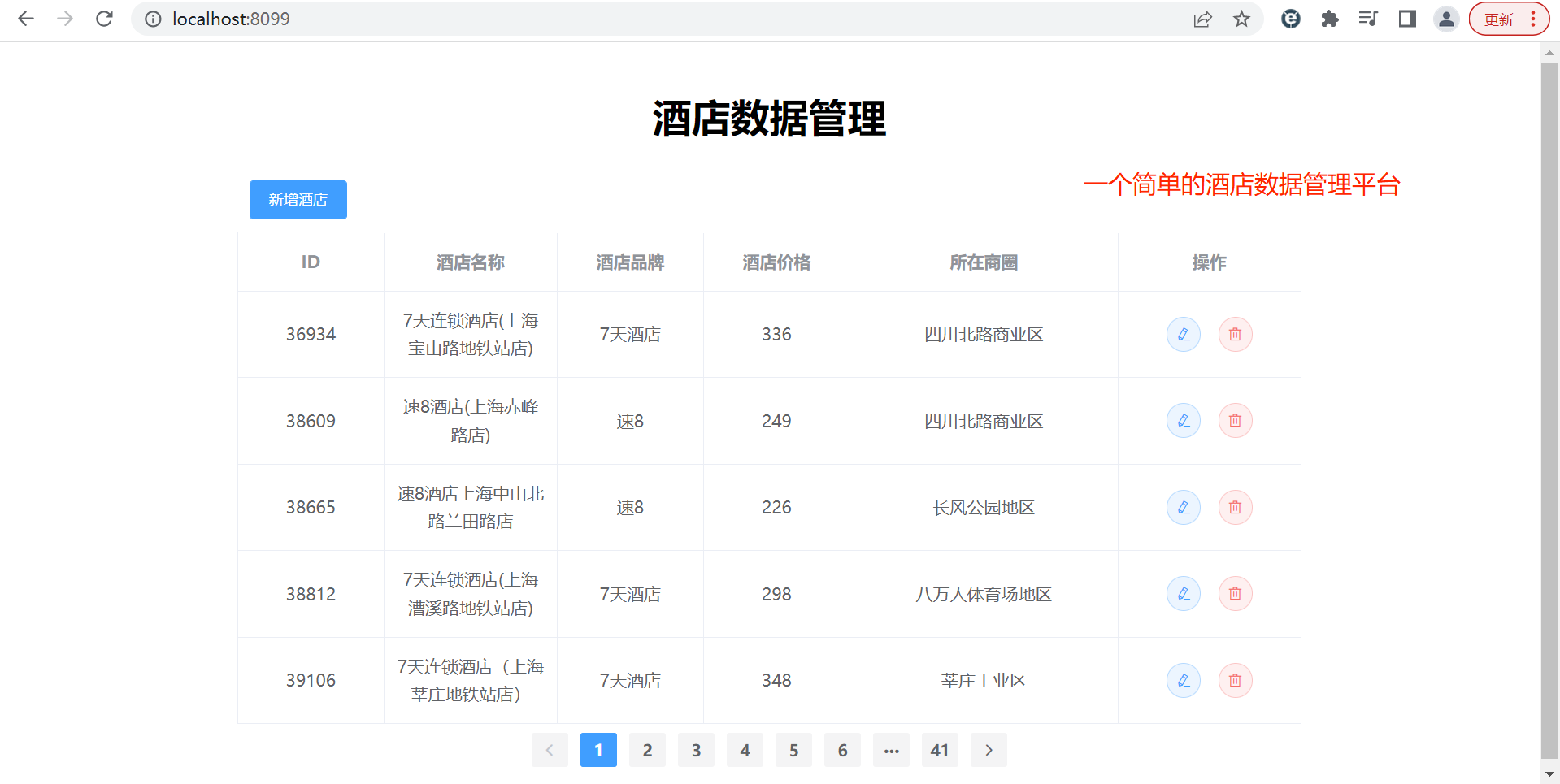
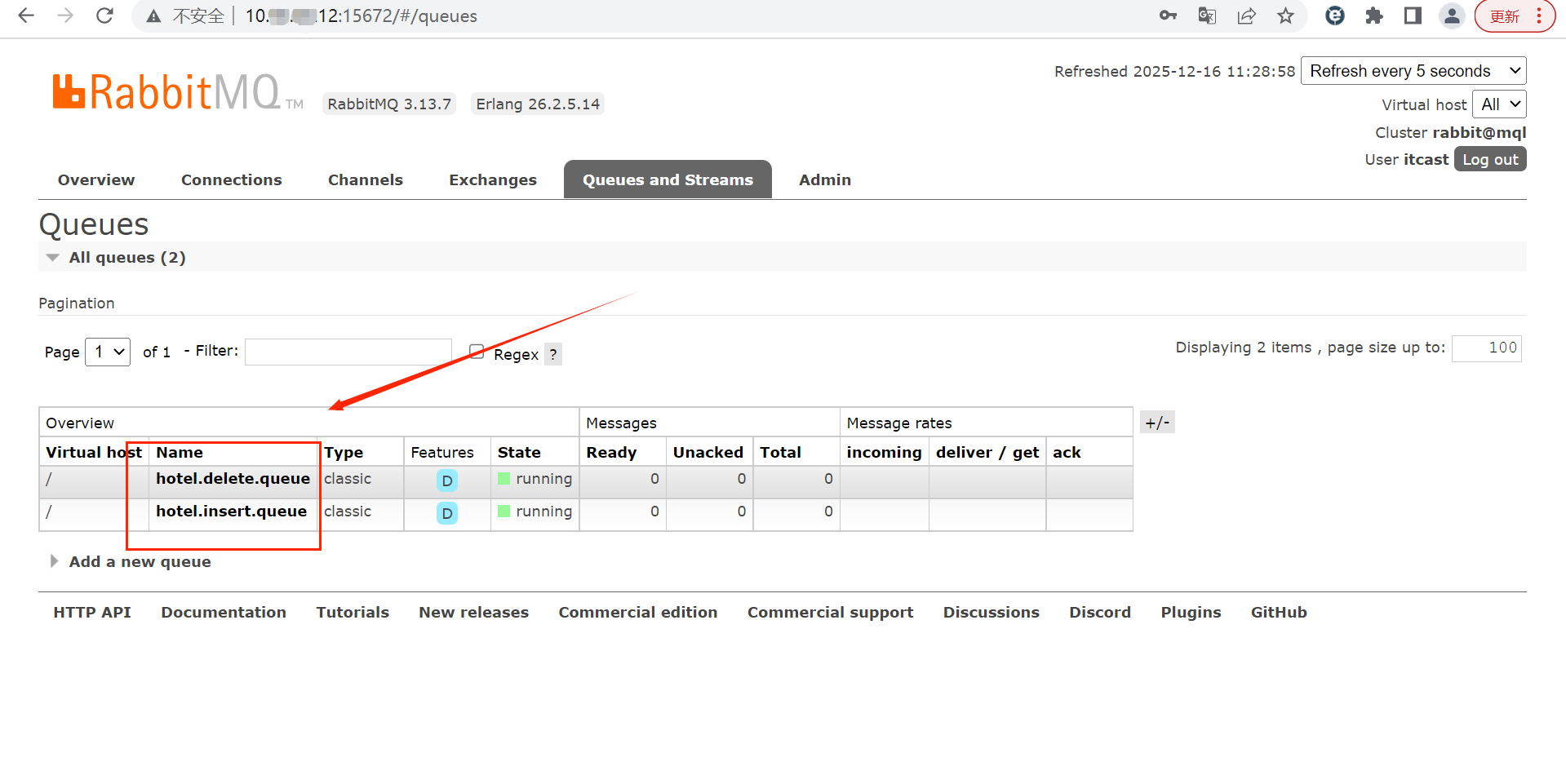
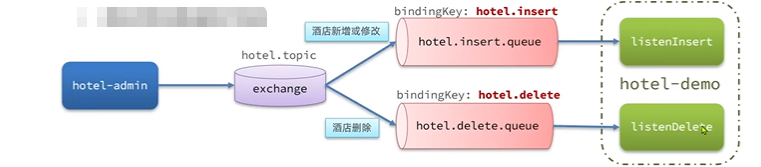
3.2.2 声明exchange,queue,RoutingKey
虽然对mysql中的数据有增删改操作,但对于elasticsearch都是往索引库里插入数据(id不存在是新增,id存在是改,可以把增和改合成一个业务),删除也是一个业务,即一共两个业务,两个消息队列。
注意:是在《Springcloud篇7-Elasticsearch-1》与《Springcloud篇8-Elasticsearch-2》的hotel-demo项目中修改。
xml
<!-- amqp -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
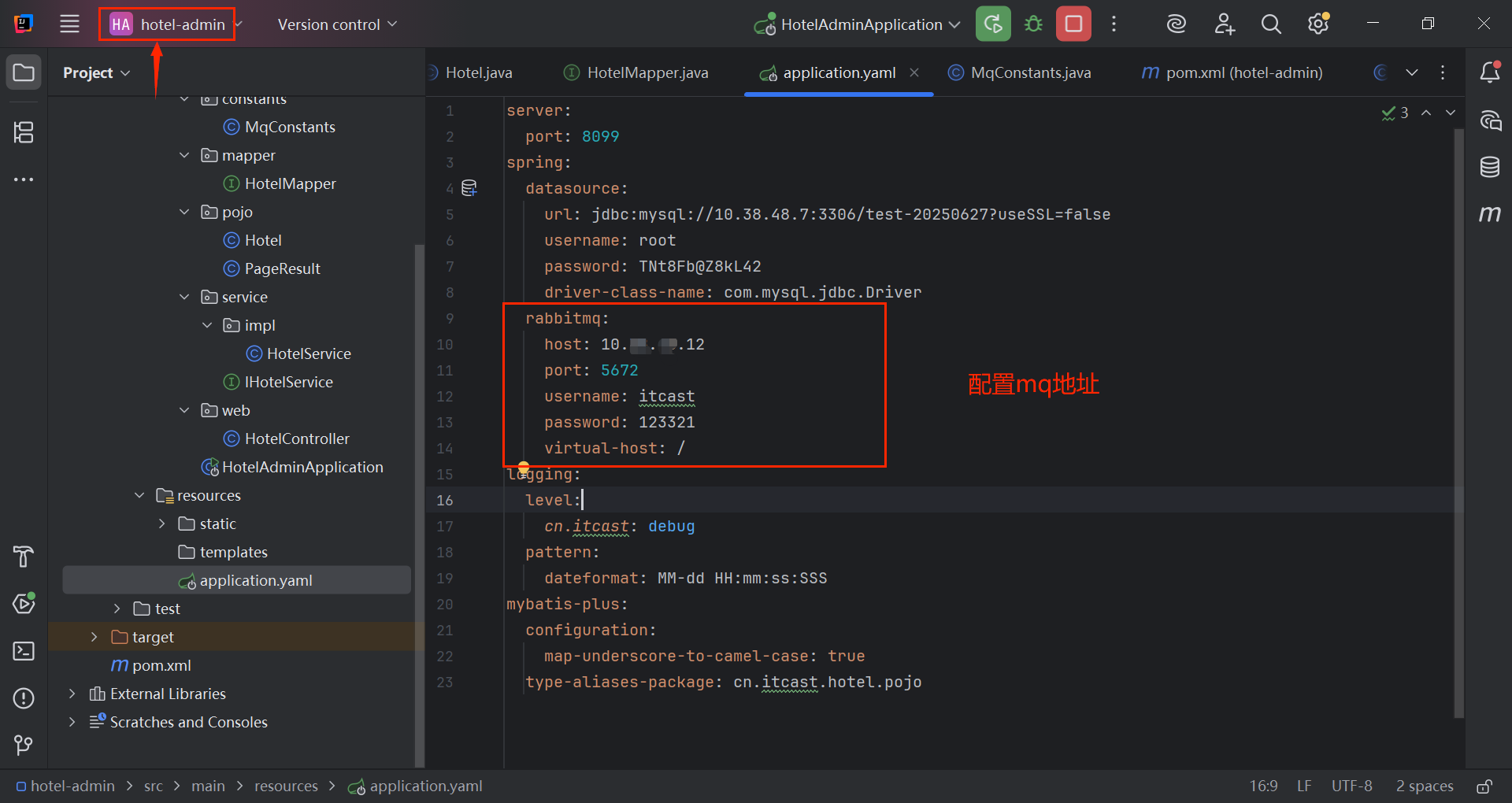
yaml
rabbitmq:
host: 10.xx.xx.12
port: 5672
username: itcast
password: 123321
virtual-host: /
java
public class MqConstants {
/*
* 交换机
*/
public final static String HOTEL_EXCHANGE = "hotel.topic";
/*
* 监听新增和修改的队列
*/
public final static String HOTEL_INSERT_QUEUE = "hotel.insert.queue";
/*
* 监听删除的队列
*/
public final static String HOTEL_DELETE_QUEUE = "hotel.delete.queue";
/*
* 新增或修改的RoutingKey
*/
public final static String HOTEL_INSERT_KEY = "hotel.insert";
/*
*删除的RoutingKey
*/
public final static String HOTEL_DELETE_KEY = "hotel.delete";
}
java
@Configuration
public class MqConfig {
@Bean
public TopicExchange topicExchange() {
return new TopicExchange(MqConstants.HOTEL_EXCHANGE,true,false);
}
@Bean
public Queue insertQueue() {
return new Queue(MqConstants.HOTEL_INSERT_QUEUE,true);
}
@Bean
public Queue deleteQueue() {
return new Queue(MqConstants.HOTEL_DELETE_QUEUE,true);
}
@Bean
public Binding insertQueueBinding(){
return BindingBuilder.bind(insertQueue()).to(topicExchange()).with(MqConstants.HOTEL_INSERT_KEY);
}
@Bean
public Binding deleteQueueBinding(){
return BindingBuilder.bind(deleteQueue()).to(topicExchange()).with(MqConstants.HOTEL_DELETE_KEY);
}
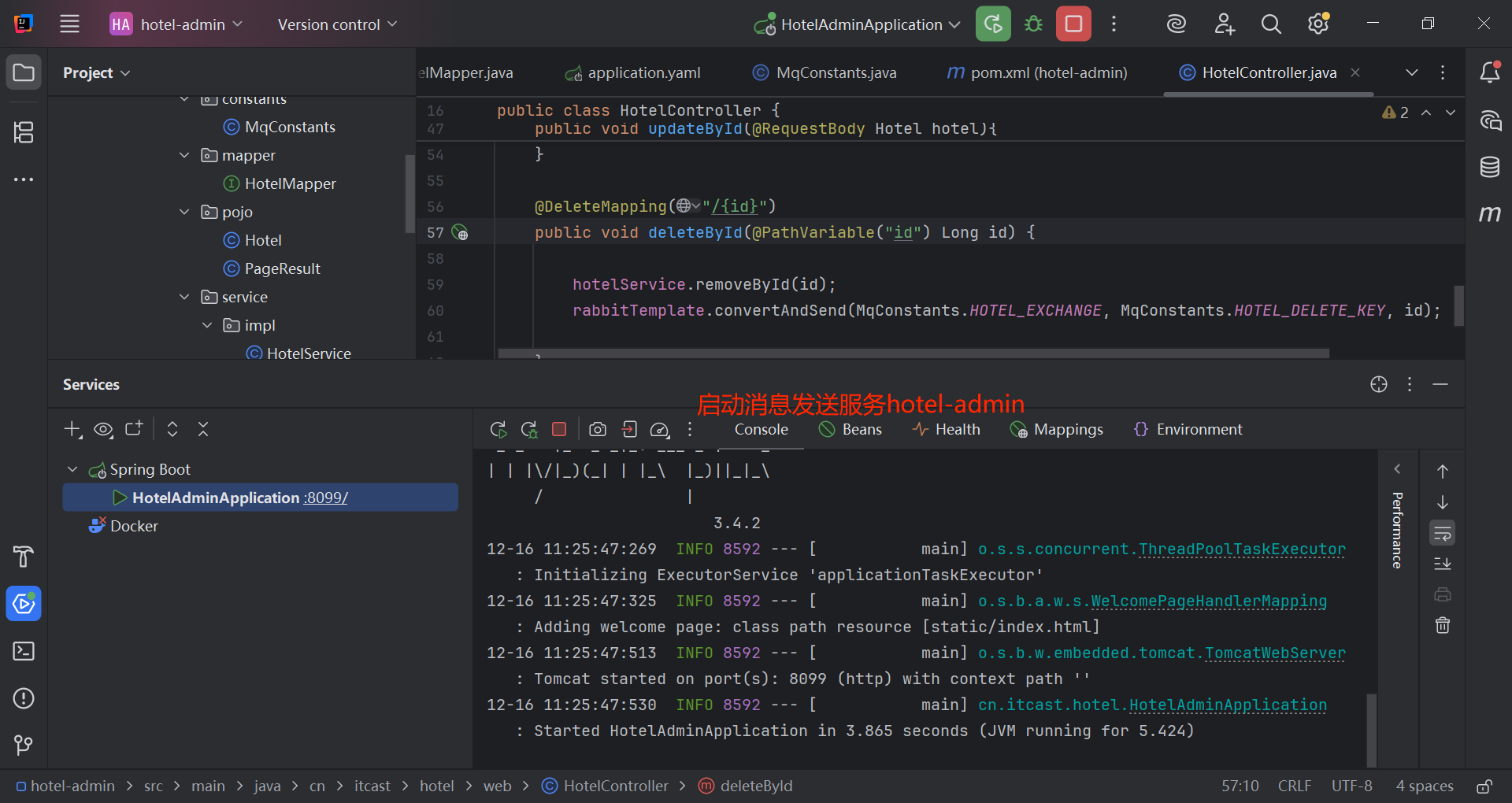
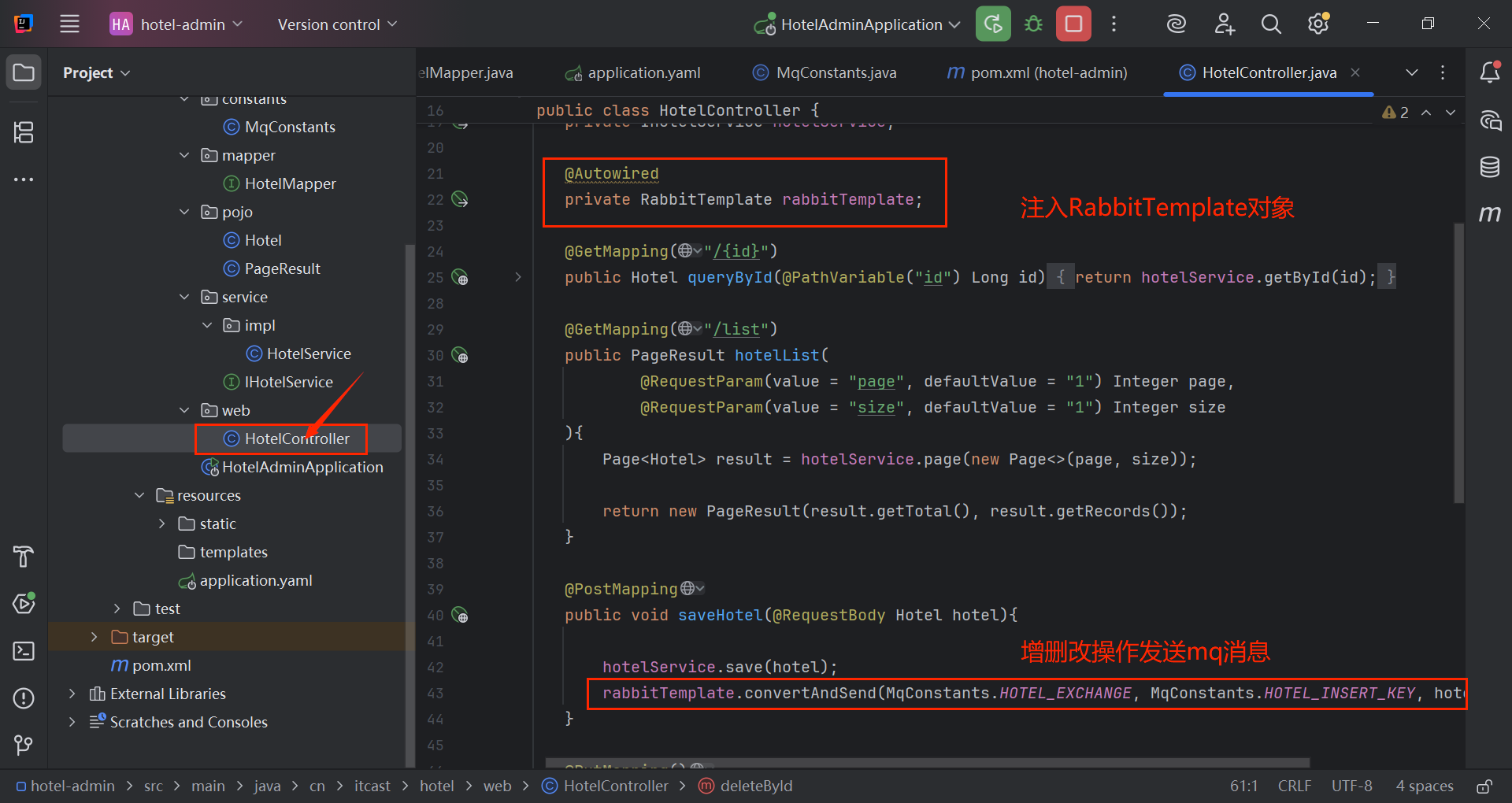
}3.2.3 hotel-admin服务的消息发送
java
RestController
@RequestMapping("hotel")
public class HotelController {
@Autowired
private IHotelService hotelService;
@Autowired
private RabbitTemplate rabbitTemplate;
@GetMapping("/{id}")
public Hotel queryById(@PathVariable("id") Long id){
return hotelService.getById(id);
}
@GetMapping("/list")
public PageResult hotelList(
@RequestParam(value = "page", defaultValue = "1") Integer page,
@RequestParam(value = "size", defaultValue = "1") Integer size
){
Page<Hotel> result = hotelService.page(new Page<>(page, size));
return new PageResult(result.getTotal(), result.getRecords());
}
@PostMapping
public void saveHotel(@RequestBody Hotel hotel){
hotelService.save(hotel);
rabbitTemplate.convertAndSend(MqConstants.HOTEL_EXCHANGE, MqConstants.HOTEL_INSERT_KEY, hotel.getId());
}
@PutMapping()
public void updateById(@RequestBody Hotel hotel){
if (hotel.getId() == null) {
throw new InvalidParameterException("id不能为空");
}
hotelService.updateById(hotel);
rabbitTemplate.convertAndSend(MqConstants.HOTEL_EXCHANGE, MqConstants.HOTEL_INSERT_KEY, hotel.getId());
}
@DeleteMapping("/{id}")
public void deleteById(@PathVariable("id") Long id) {
hotelService.removeById(id);
rabbitTemplate.convertAndSend(MqConstants.HOTEL_EXCHANGE, MqConstants.HOTEL_DELETE_KEY, id);
}
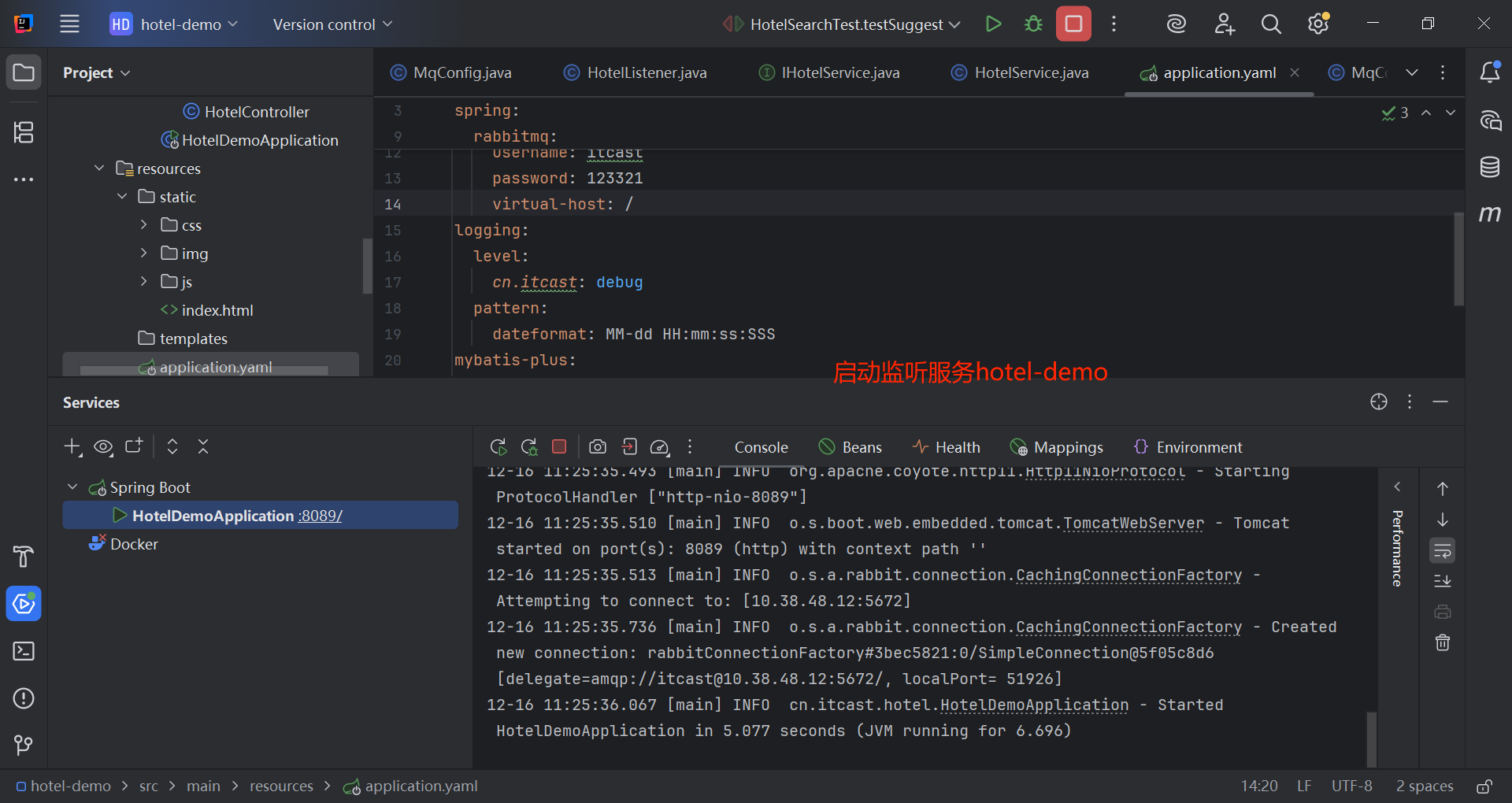
}3.2.4 hotel-demo的消息监听
java
@Component
public class HotelListener {
@Autowired
private IHotelService hotelService;
/*
* 监听酒店新增或修改的业务
*/
@RabbitListener(queues= MqConstants.HOTEL_INSERT_QUEUE)
public void listenHotelInsertOrUpdate(Long id){
hotelService.insertById(id);
}
/*
* 监听酒店删除的业务
*/
@RabbitListener(queues= MqConstants.HOTEL_DELETE_QUEUE)
public void listenHotelDelete(Long id){
hotelService.deleteById(id);
}
}
java
void insertById(Long id);
void deleteById(Long id);
java
@Override
public void insertById(Long id) {
try {
Hotel hotel = getById(id);
//转为文档类型
HotelDoc hotelDoc = new HotelDoc(hotel);
//1.创建Request对象
IndexRequest request=new IndexRequest("hotel").id(hotel.getId().toString());
//2.准备json文档
request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);
//3.发送请求
client.index(request,RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
@Override
public void deleteById(Long id) {
try {
//1.创建Request对象
DeleteRequest request=new DeleteRequest("hotel",id.toString());
//2.发送请求
client.delete(request,RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
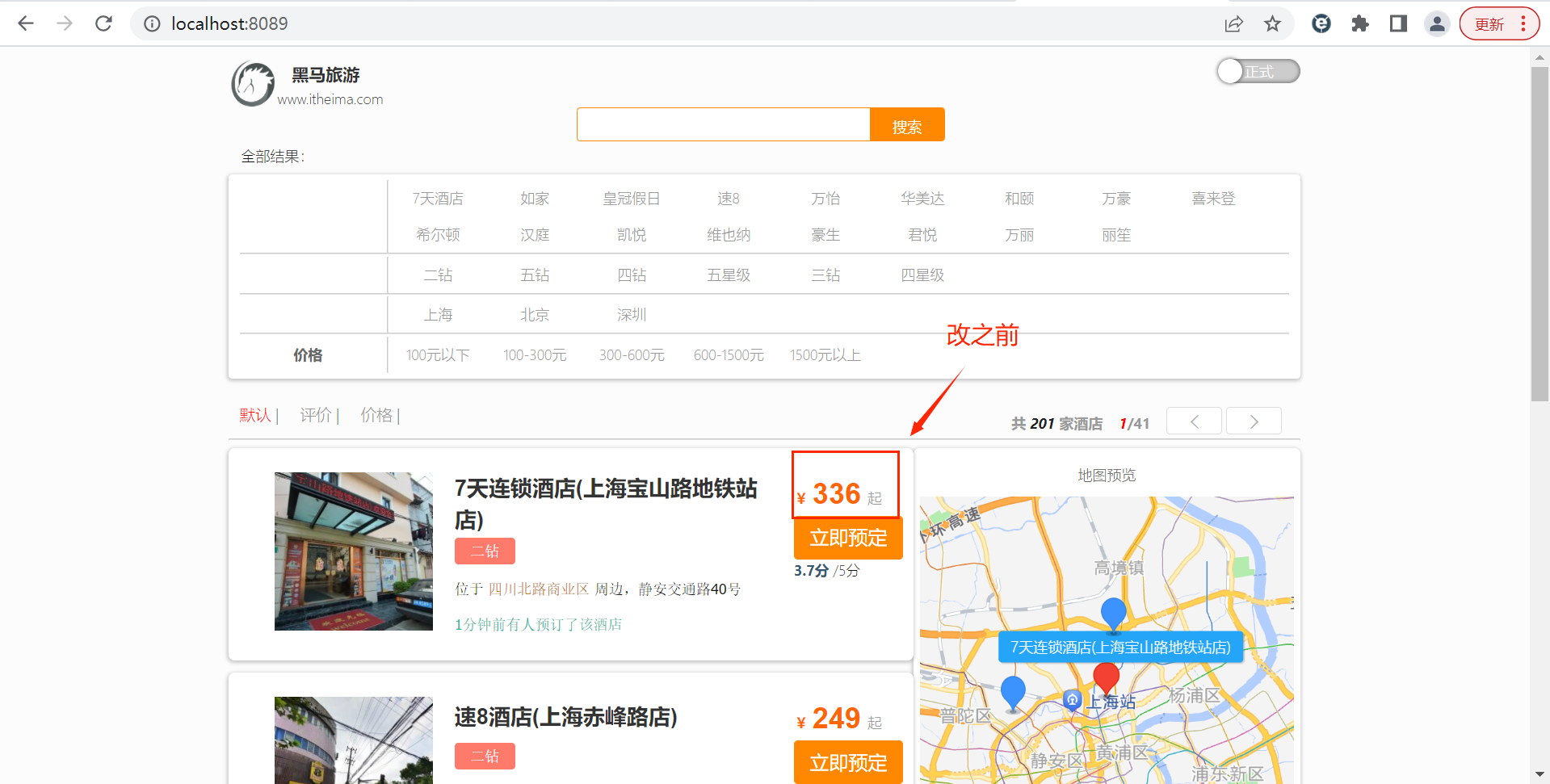
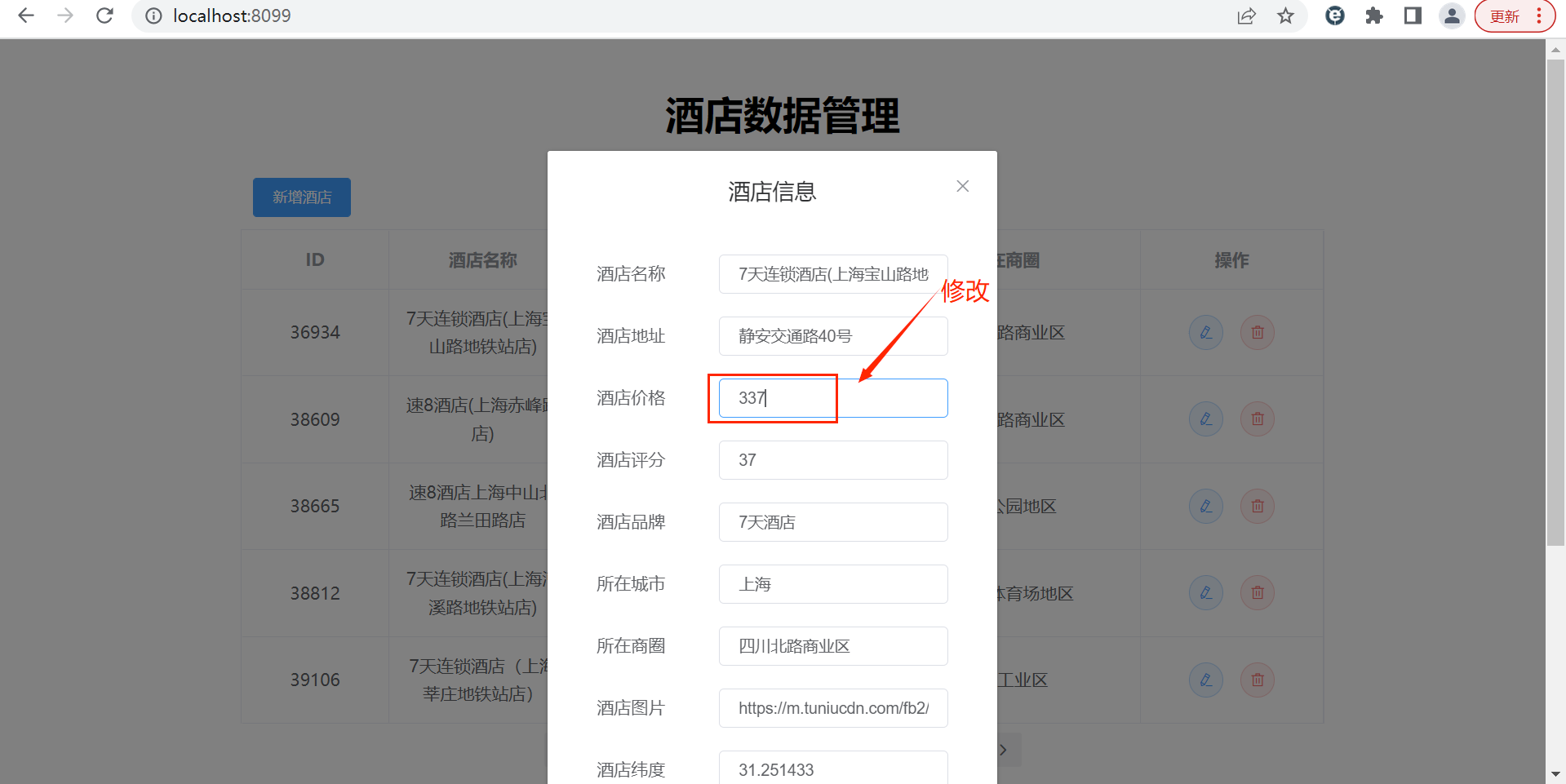
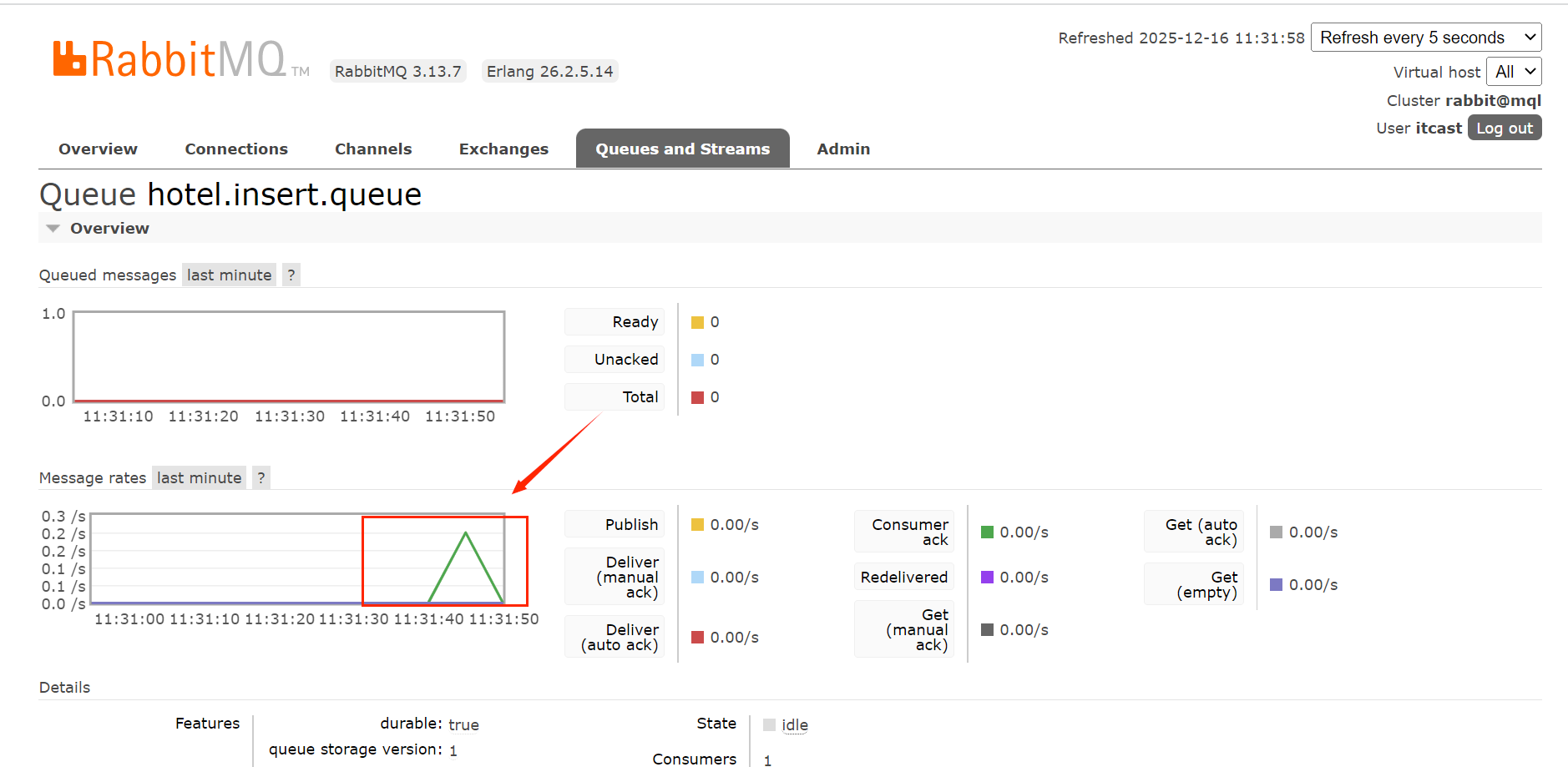
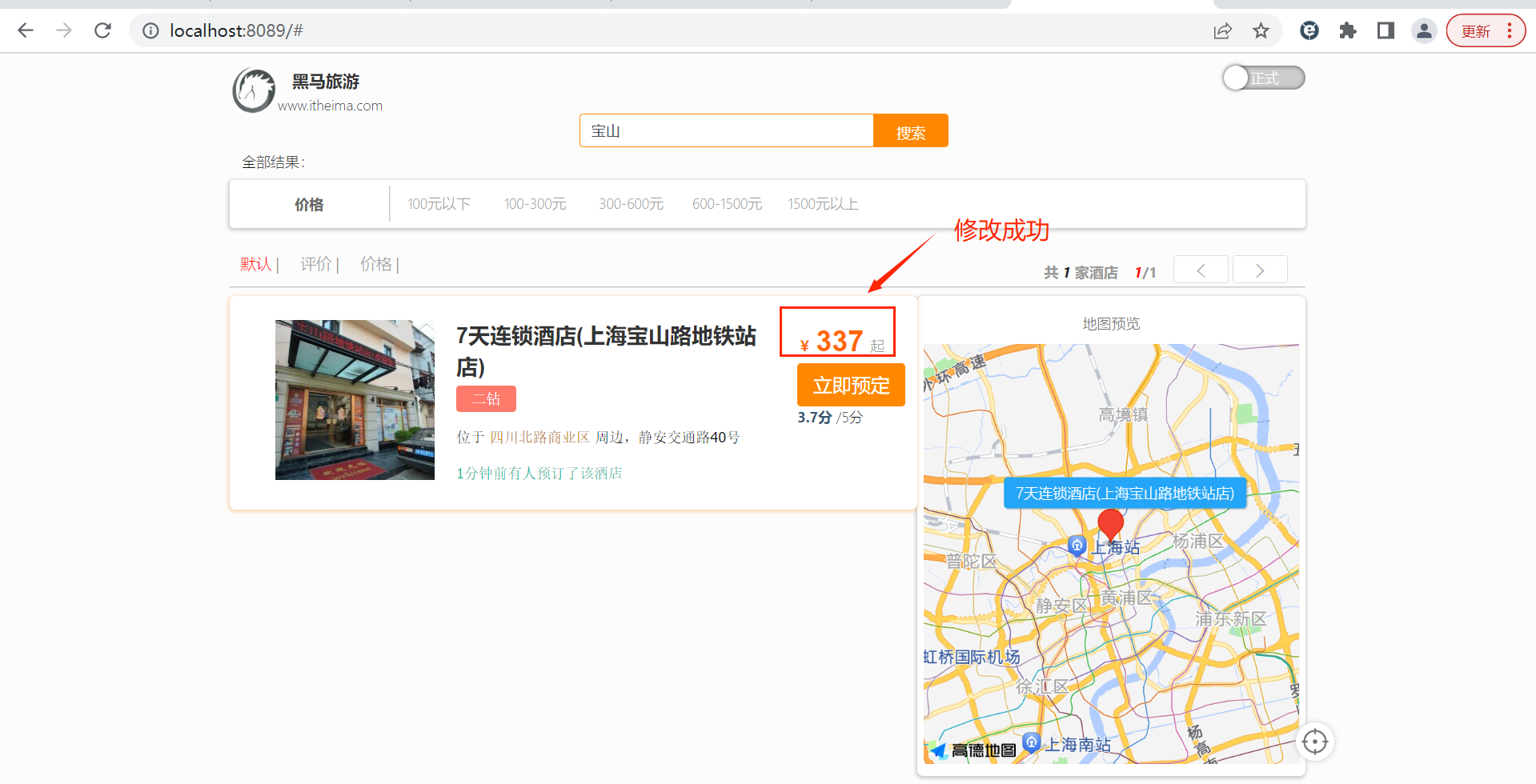
}3.2.5 启动服务测试
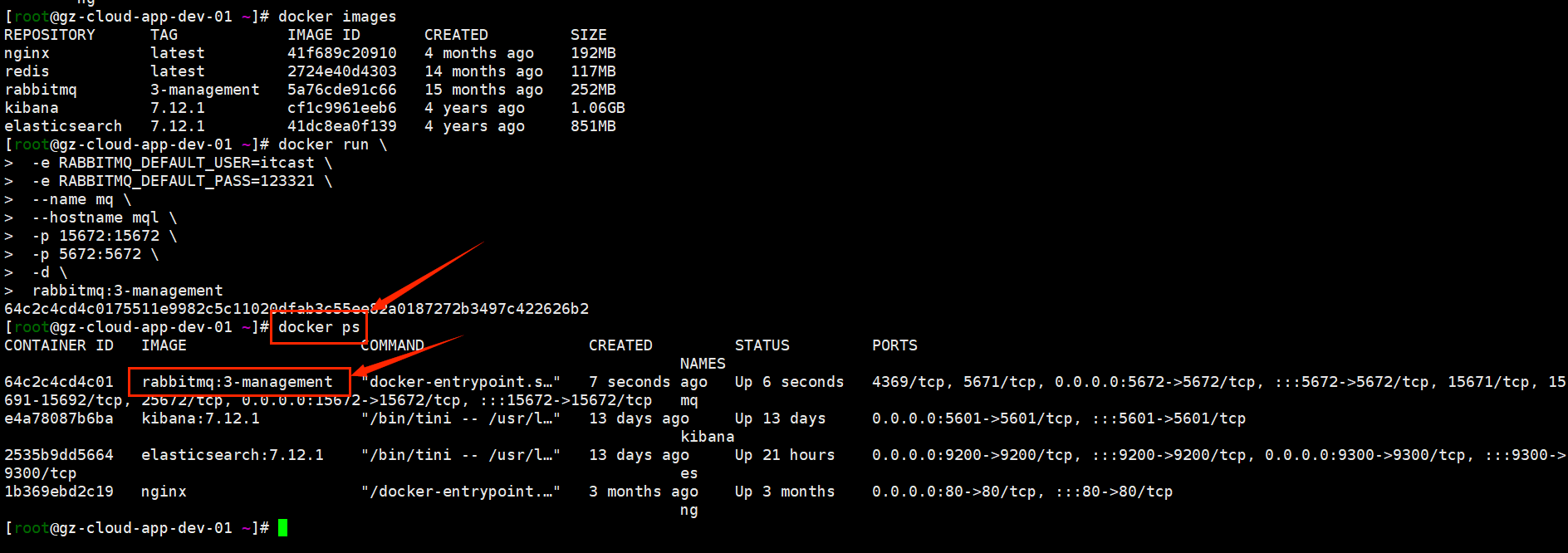
启动服务前确保rabbitmq服务启动: