目录
-
- 一、研究背景与问题
- 二、核心方法:SuperCLIP框架
-
- [1. 核心思路](#1. 核心思路)
- [2. 技术细节](#2. 技术细节)
- 三、实验结果与分析
-
- [1. 实验设置](#1. 实验设置)
- [2. 关键实验结果](#2. 关键实验结果)
- 四、消融实验与参数分析
- 五、研究贡献与未来方向
-
- [1. 主要贡献](#1. 主要贡献)
- [2. 未来方向](#2. 未来方向)
- 六、研究局限性
一、研究背景与问题
-
CLIP的优势与局限
- 优势:对比语言-图像预训练(CLIP)通过在共享嵌入空间中对齐图像与文本,在零样本分类、图像-文本检索等视觉-语言任务中实现了强泛化能力,其核心依赖大规模噪声网页数据训练。
- 局限:CLIP仅优化全局图像-文本相似度,忽略token级监督,导致无法充分利用文本中的细粒度语义信号(如物体属性、空间关系、动作),尤其在处理长且详细的描述文本时问题更突出;且依赖超大批次(通常16k以上)训练,小批次下性能显著下降。
-
现有解决方案的不足:现有改进方法或依赖额外标注数据集(如UniCL依赖人工标注类别标签),或引入大量计算开销(如RegionCLIP需处理区域提案),均难以在"无额外成本"与"细粒度对齐"间平衡。
论文:SuperCLIP: CLIP with Simple Classification Supervision
作者:Weiheng Zhao1 Zilong Huang2 ˚ Jiashi Feng2 Xinggang Wang1
单位:School of EIC, Huazhong University of Science and Technology,ByteDance
代码:Code & Models: https://github.com/hustvl/SuperCLIP
请各位同学给我点赞,激励我创作更好、更多、更优质的内容!^_^
关注微信公众号 ,获取更多资讯

二、核心方法:SuperCLIP框架
1. 核心思路
在CLIP的视觉编码器后添加轻量级线性层,引入基于分类的监督信号,直接利用原始文本token引导视觉编码器关注文本中的语义实体及其视觉表现,在仅增加0.077%计算量(FLOPs)且无需额外标注数据的前提下,增强细粒度视觉-文本对齐。

图1:评估图像-文本检索中的细粒度对齐。每一行都呈现了视觉和语义上非常相似的成对图像和说明文字,但在细粒度的语义区分上有所不同,例如对象状态(例如雕像与真实)、空间关系(例如外部与内部)和动作(例如坐与站)。虽然图像和文本在意义上很接近,但SuperCLIP在正确区分这些细粒度语义区别方面表现出比CLIP更强的能力。附录A.1提供了其他示例。
2. 技术细节
(1)文本token的监督信号构建
- K-hot向量表示 :将文本通过CLIP的子词分词器处理为token ID,构建V维(V为词汇表大小)K-hot向量
y,其中文本中存在的token对应位置为1,其余为0。 - IDF加权优化 :为解决停用词或通用词判别性低的问题,引入逆文档频率(IDF)加权,计算token权重
w_c = log(|D|/(1+df(c)))(|D|为数据集总样本数,df(c)为tokenc出现的文档数),并归一化得到加权标签分布ŷ。
(2)损失函数设计
- 分类损失(L_Class :通过线性层将视觉编码器输出映射为logit,计算加权标签分布
ŷ与模型预测的交叉熵,强制模型关注所有文本token的语义信号。 - 总损失(L_Total :将分类损失与CLIP原对比损失结合,即
L_Total = L_CLIP + L_Class,无需改变CLIP原有训练流程。
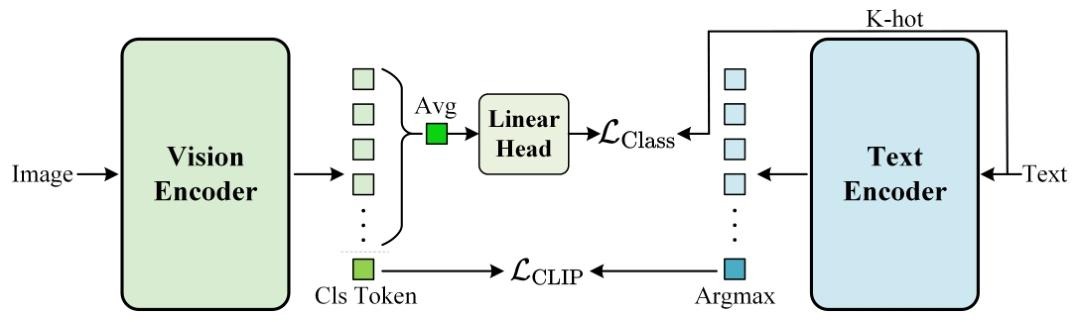
图2:我们建议的SuperCLIP的整体架构。在CLIP框架中引入简单的基于分类的监督是很简单的。它只需要在图像编码器中添加一个轻量级的线性层,将平均图像特征映射到文本分类目标,而不需要对原始的对比学习范式进行任何更改。
三、实验结果与分析
1. 实验设置
- 预训练数据:主要基于DataComp数据集(约1.3B图像-文本对),部分实验使用Recap-DataComp(LLaMA-3重新生成的细粒度描述数据)。
- 评估任务:零样本分类(ImageNet-1K val/v2)、图像-文本检索(COCO、Flickr30K)、纯视觉任务(语义分割PASCAL/ADE20K、深度估计NYUv2)、多模态LLM集成(LLaVA-1.5+Vicuna-7B)。
2. 关键实验结果
(1)不同模型规模的性能提升
| 模型 | 预训练数据量 | ImageNet-1K val(零样本分类) | COCO图像检索(Recall@1) | Flickr30K文本检索(Recall@1) |
|---|---|---|---|---|
| CLIP(B-512M) | 512M样本 | 60.5% | 29.0% | 73.3% |
| SuperCLIP(B-512M) | 512M样本 | 63.5%(+3.0%) | 31.3%(+2.3%) | 75.6%(+2.3%) |
| CLIP(L-512M) | 512M样本 | 66.1% | 32.7% | 76.4% |
| SuperCLIP(L-512M) | 512M样本 | 70.1%(+4.0%) | 35.9%(+3.2%) | 79.3%(+2.9%) |
| CLIP(L-12.8B) | 12.8B样本 | 79.0% | 43.9% | 87.0% |
| SuperCLIP(L-12.8B) | 12.8B样本 | 80.0%(+1.0%) | 45.5%(+1.6%) | 88.1%(+1.1%) |
(2)细粒度对齐能力验证
- 词-图像相似度分析:SuperCLIP显著提升物体状态(如"statue" vs "real")、空间关系("inside"vs"outside")、动作("sitting"vs"standing")等细粒度词的相似度排名,而CLIP更关注物体类别词(如"zebra""kite")。
- 统计指标:SuperCLIP的词相似度标准差(0.0213)低于CLIP(0.0340),长尾效应更弱,语义关注更均衡。
(3)小批次训练性能优化
- 当批次大小从32K降至1K时,CLIP零样本分类准确率下降超10%,而SuperCLIP仅下降约5%;线性探测任务中,SuperCLIP在各批次大小下性能稳定,验证分类监督对批次大小不敏感。
(4)跨框架与纯视觉任务泛化
- CLIP-style框架:在SigLIP、FLIP上集成SuperCLIP后,零样本分类准确率提升最高3.7%(SigLIP),文本检索提升最高5.3%(FLIP)。
- 纯视觉任务:SuperCLIP在PASCAL语义分割(mIoU +7.7%)、ADE20K分割(mIoU +4.1%)、ImageNet线性探测(+1.5%)上均有显著提升,证明视觉编码器特征更具判别性。
(5)多模态LLM集成
将SuperCLIP作为LLaMA-1.5的视觉编码器,在VQAv2(69.6% vs 67.8%)、MMBench(55.9% vs 49.1%)等任务上优于CLIP,验证跨模态泛化能力。
四、消融实验与参数分析
- 分类损失权重(λ):当λ从0.4增至1.0时,所有任务性能持续提升;λ>1.0时,文本检索仍提升,分类与图像检索饱和,推荐λ≥1.0。
- IDF加权作用:添加IDF加权后,ImageNet-1K分类准确率提升2.3%,COCO图像检索提升1.6%,证明其有效过滤低判别性token。
五、研究贡献与未来方向
1. 主要贡献
- 提出SuperCLIP框架,通过轻量级线性层与分类监督,让CLIP充分利用文本细粒度语义,无需额外数据与大量计算。
- 缓解CLIP小批次性能下降问题,同时在零样本任务、纯视觉任务、多模态LLM中均实现性能提升。
- 具备强泛化性,可无缝集成到SigLIP、FLIP等CLIP-style框架。
2. 未来方向
- 探索将分类监督从"文本到视觉"扩展到"视觉到文本",进一步优化文本编码器性能。
六、研究局限性
- 未涉及模型在极端长尾数据(如极低频率语义组合)下的表现;
- 未评估SuperCLIP在小模型(如TinyCLIP)上的性能,需验证轻量化场景的适用性。