Nemotron 3 支持 1M token 的上下文窗口,使模型能够在大型代码库、长文档、延展式对话以及聚合检索内容之上进行持续推理。与依赖碎片化分块启发式方法不同,智能体可以将完整的证据集合、历史缓冲区和多阶段规划全部保留在单一上下文窗口中。
就在刚刚,英伟达正式开源发布了其新一代AI模型:NVIDIA Nemotron 3。
Nemotron 3 系列由三种型号组成:Nano、Super 和 Ultra。官方介绍其具备强大的智能体、推理和对话能力。
在官方放出的测试数据中,Nemotron 3 Nano"拳打"Qwen3-30B,"脚踢"GPT-OSS-20B:
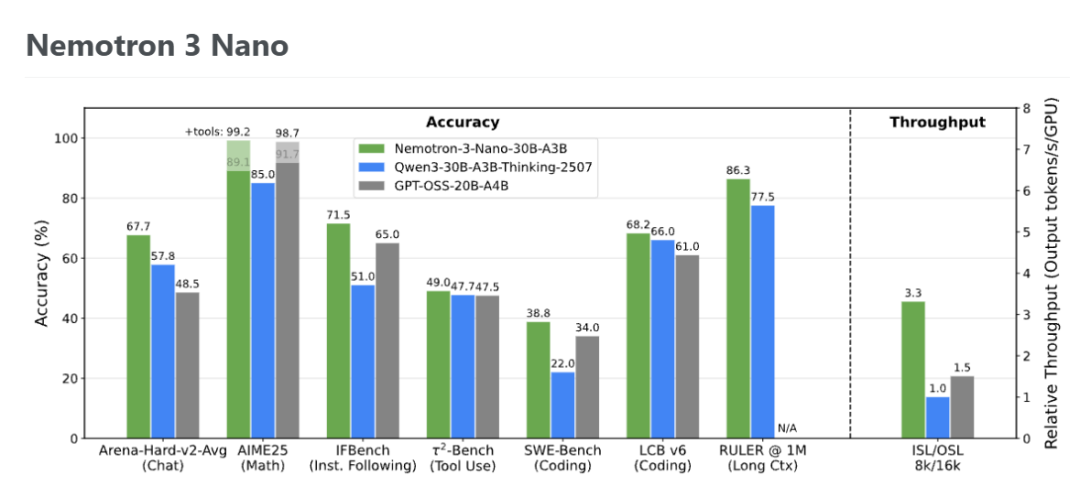
- 在覆盖多个类别的主流基准测试中,整体准确率优于 GPT-OSS-20B 和 Qwen3-30B-A3B-Thinking-2507。
- 在单张 H200、8K 输入 / 16K 输出的配置下,Nemotron 3 Nano 的推理吞吐量分别比 Qwen3-30B-A3B 高 3.3 倍 ,比 GPT-OSS-20B 高 2.2 倍。
- 支持最高 100 万(1M)token 的上下文长度,并且在不同上下文长度下的 RULER 测试中,性能均优于 GPT-OSS-20B 和 Qwen3-30B-A3B-Instruct-2507。
Image
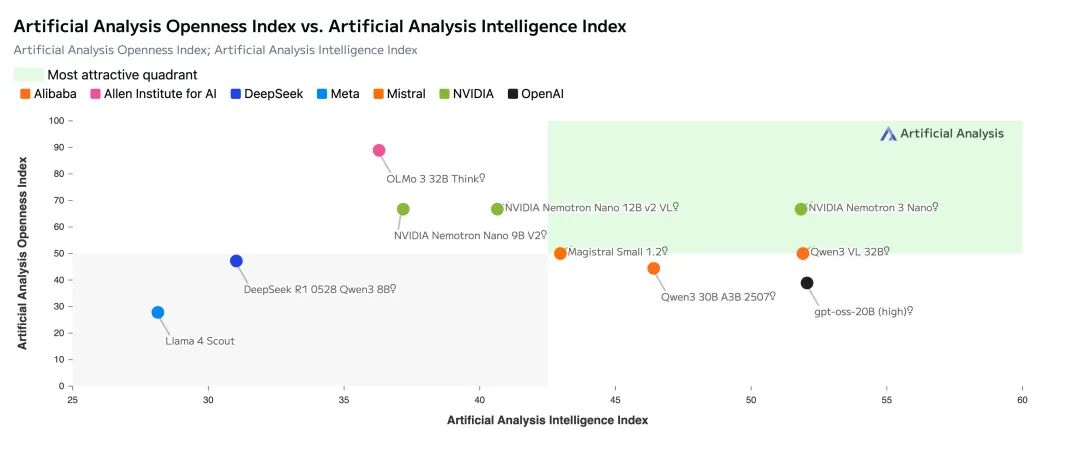
在Artificial Analysis的数据中,Nemotron 3 Nano也基本能和Qwen3-30B、GPT-OSS-20B 比肩。
官方还展示了一个在 Nemotron 3 Nano 上运行的桌椅逻辑谜题,可以看出其推理速度相当可观。
官方指出,Nemotron 3 Nano的推理速度比二代 Nano 快 4 倍,比同规模级的其他领先模型快 3.3 倍。
模型、代码库和技术报告也统统开源:
模型:https://huggingface.co/blog/nvidia/nemotron-3-nano-efficient-open-intelligent-models
代码:https://github.com/NVIDIA-NeMo/Nemotron
技术报告:https://research.nvidia.com/labs/nemotron/files/NVIDIA-Nemotron-3-Nano-Technical-Report.pdf
三个不同版本,百万token上下文
Nemotron3 提供三种不同规模的版本:
- Nano:最小模型,激活参数规模为 3.2B (包含 embedding 时为 3.6B )、总参数规模为 31.6B,用于目标明确、效率要求极高的任务,在准确性上优于同类模型,同时在推理中保持极高的成本效益。
- Super:比 Nano 大约4倍,参数规模约为100B,面向多智能体应用,并具备高精度推理能力。
- Ultra:比 Nano 大约16倍,参数规模约为500B,配备更强大的推理引擎,适用于更加复杂的应用场景。
Nemotron 3 支持 1M token 的上下文窗口,使模型能够在大型代码库、长文档、延展式对话 以及聚合检索内容 之上进行持续推理。与依赖碎片化分块启发式方法不同,智能体可以将完整的证据集合、历史缓冲区和多阶段规划 全部保留在单一上下文窗口中。
官方指出,这一超长上下文能力得益于 Nemotron 3 的混合式 Mamba--Transformer 架构 ,该架构能够高效处理极长序列。同时,MoE 路由机制降低了单个 token 的计算开销,使得在推理阶段处理如此大规模序列在实际中具备可行性。
在企业级检索增强生成(RAG) 、合规性分析 、持续数小时的智能体会话 或单体代码仓库理解等场景下,1M token 的上下文窗口能够显著提升事实对齐能力,并减少上下文碎片化问题。
官方表示,目前 Nano 版本已正式发布,Super 和 Ultra 预计将在 2026 年上半年发布。
突破性专家混合架构,大幅提高效率
此次 Nemotron 3 系列最大的技术亮点在于:引入了开放的混合式 Mamba--Transformer MoE 架构 ,面向多智能体系统 中的高速、长上下文推理场景。
英伟达已经在其多款模型中采用了混合Mamba-TransformerMoE架构,其中包括Nemotron-Nano-9B-v2。
Nemotron 3 将三种架构整合进同一个主干网络中:
- Mamba 层:用于高效的序列建模
- Transformer 层:用于高精度推理
- MoE 路由机制:实现可扩展的计算效率
Mamba 在极低内存开销 下即可有效追踪长程依赖关系 ,即使在处理数十万 token 时也能保持稳定性能。Transformer 层则通过精细的注意力机制进行补充,捕捉代码操作、数学推理或复杂规划等任务所需的结构性与逻辑关系。
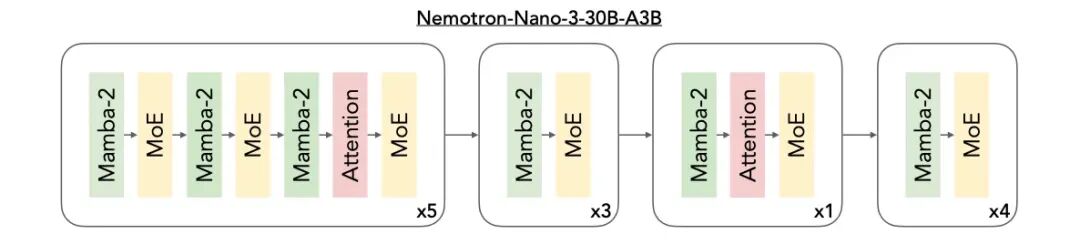
MoE组件 在不引入稠密计算成本的前提下,显著放大了模型的有效参数规模 。对于每个 token,仅会激活部分专家网络 ,从而降低延迟并提升吞吐量。该架构尤其适合多智能体集群场景:大量轻量级智能体需要并发运行,各自生成计划、检查上下文,或执行基于工具的工作流。
官方指出,与Nemotron 2 Nano相比,这一设计"最多可实现4倍的token吞吐量提升",并通过将推理token的生成量最多减少60%,显著降低了推理成本。
Nemotron 3 Super 和 Ultra 在实现更先进的精度和推理性能的同时,也引入了一项突破性创新:latent MoE(潜在空间专家混合) 。
各个专家在共享的潜在表示空间 中进行计算,随后再将结果投射回 token 空间 。这种设计使模型在相同推理成本 下能够调用多达 4 倍的专家数量 ,从而在细微语义结构、领域抽象 以及多跳推理模式等方面实现更强的专门化能力。
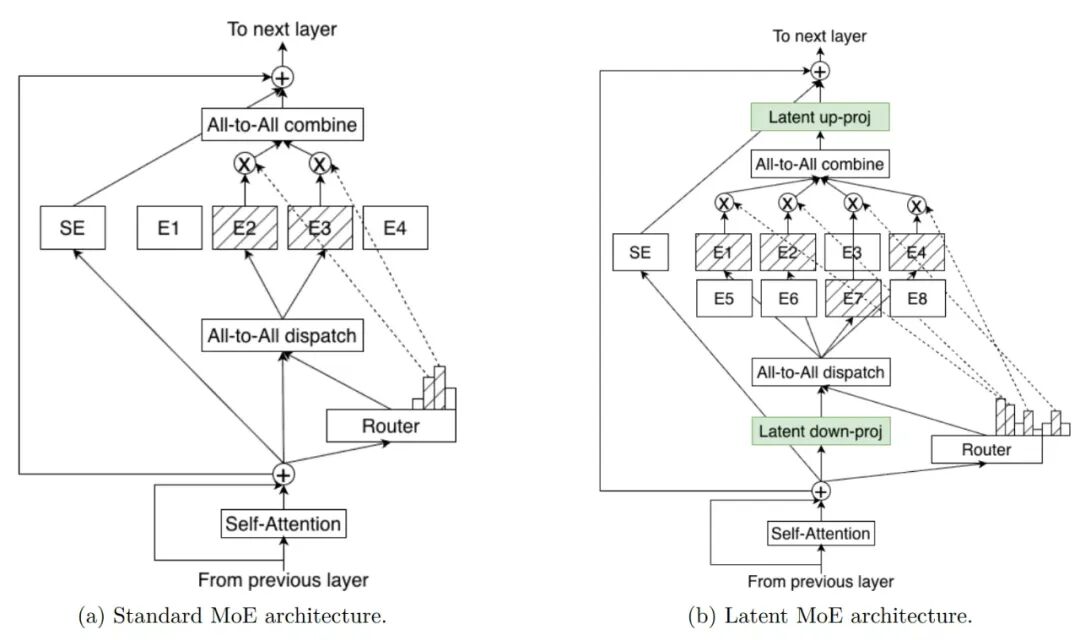
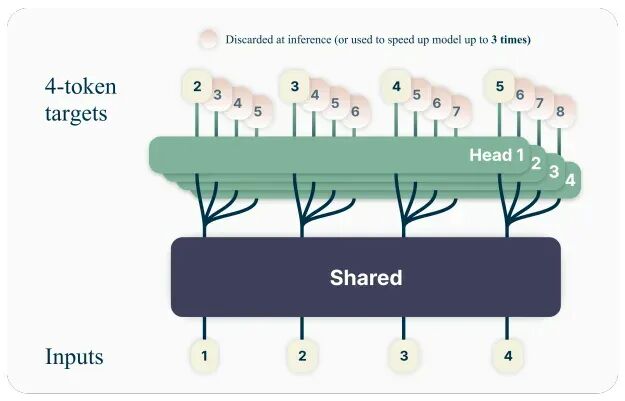
新模型中还采用了多token预测(MTP),使模型能够在一次前向计算中预测多个未来 token ,显著提升长序列推理和结构化输出的吞吐量。在规划、轨迹生成、延展式思维链 或代码生成等场景中,MTP 可以降低延迟并提升智能体的响应速度。
值得注意的是,在预训练过程中,Super 与 Ultra 版本采用的是 NVFP4 格式。NVFP4 是NVIDIA 的 4 位浮点格式,在训练和推理中具有业界领先的成本-精度表现。
针对 Nemotron 3,官方设计了更新版 NVFP4 训练方案 ,以确保在 25T token 的预训练数据集上实现准确且稳定的预训练 。在预训练过程中,大部分浮点乘加运算均使用 NVFP4 格式完成。
NeMo Gym:多环境强化学习(RL)训练
为了使 Nemotron 3 更好地对齐真实的智能体行为,模型在后训练阶段通过 NeMo Gym 中的多环境强化学习进行训练。
NeMo Gym 是一个用于构建和规模化强化学习环境的开源库。这些环境评估模型执行动作序列的能力,而不再局限于单轮回答,例如生成正确的工具调用、编写可运行的代码,或产出满足可验证标准的多步骤规划。
这种基于轨迹的强化学习训练方式,使模型在多步工作流中表现更加稳定可靠,能够减少推理漂移,并更好地处理智能体流水线中常见的结构化操作。
值得注意的是,英伟达还为广大开发者开源了NeMo Gym,可以带来以下能力:
- 覆盖数学、代码、工具使用、多轮推理以及 Agentic 工作流 的开箱即用强化学习环境
- 支持构建具备可验证奖励逻辑的自定义强化学习环境
- 与 NeMo RL 及其他训练框架的生态互操作性 (包括 TRL、Unsloth ,以及正在推进中的 VeRL)
- 高吞吐的 rollout 编排能力,支持大规模强化学习训练
- 为开发者在自有模型上实施强化学习提供一条切实可行的路径
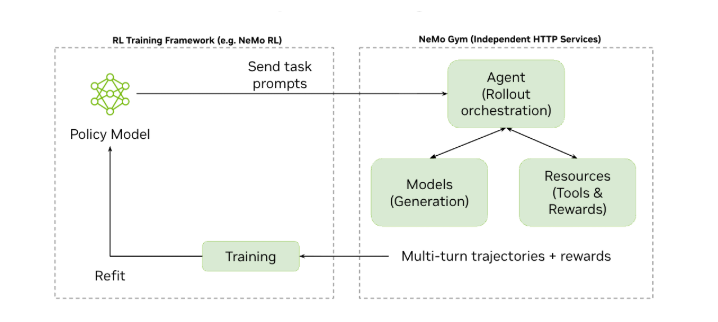
Diagram illustrating interaction between an RL Training Framework on the left and NeMo Gym on the right. The training framework sends task prompts to the agent server in the NeMo Gym. The agent server coordinates with the policy model server and external resources server to collect rollouts and verify task performance. The scored trajectories are returned back to the Training Framework for model updates.
github链接:https://github.com/NVIDIA-NeMo/Gym
英伟达为什么要做模型?
看到这里,有些朋友可能会有疑问了:英伟达不是一家做GPU的硬件公司吗?为什么要做自己的AI模型呢?
实际上,除了提供芯片和GPU之外,英伟达也提供大量自有模型,涵盖物理仿真、自动驾驶等多个领域。2024年,英伟达就发布了 Nemotron 品牌下的首批模型,基于 Meta 的 Llama 3.1 设计。
此后,英伟达推出了多款不同尺寸和针对特定场景调校的 Nemotron 型号,并且都以开源形式发布,供其他公司使用。包括Palantir Technologies在内的一些企业,已经将英伟达的模型整合进自身产品中。
就在上周,英伟达还宣布了一款新的开放推理视觉语言模型 Alpamayo-R1,专注于自动驾驶研究。英伟达表示,增加了更多涵盖其 Cosmos 世界模型的工作流程和指南,这些模型是开源且采用宽松许可,以帮助开发者更好地利用这些模型开发物理 AI。
从种种举动可以看出,英伟达是有意推动构建开源生态了。
官方说法也证实了这一点。企业生成式 AI 副总裁 Kari Briski 表示,英伟达的目标是提供一个"人们可以信赖的模型"。
"我们会把这些 LLM 当作一个库来看待。我们会把它公开,让开发者检查代码,这样你们可以理解它、在它基础上构建、我们可以修复 bug、改进它,然后再把改进后的版本重新发布出去。我们越是开放,开发者的参与度就越高。"
英伟达创始人兼首席执行官黄仁勋也公开表示:
"开放式创新是人工智能进步的基础。通过Nemotron,我们正在把先进AI转变为一个开放平台,为开发者提供在大规模构建智能体系统时所必需的透明性和效率。"
因此有媒体指出,在OpenAI、Anthropic、Meta等一系列已经转向或正在转向闭源的美国公司中,英伟达有望成为美国最主要的开源模型提供商之一。
网友:实测打不赢Qwen和GPT
Nemotron 3 Nano 已经发布,很快在Reddit上引发了网友热议。不少网友指出,实测下来 Nano 的表现并没有比GPT-OSS-20B和Qwen3-30B更强。比如新模型虽然参数比 GPT OSS 20B 多 10B,但性能只是"匹配",并没有大幅超越。
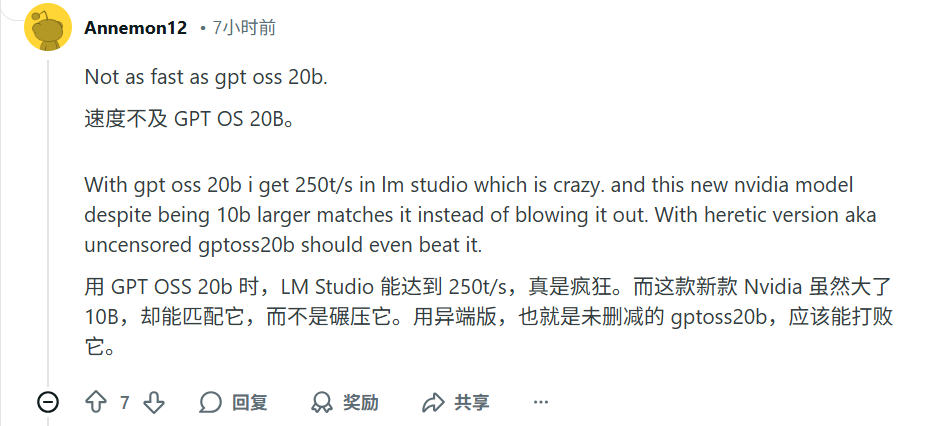
或是新模型的文件更大,不一定是 Qwen3-30B-A3B 的理想替代。

有网友用模型进行了微积分测试,结论是:GPT-OSS-20B在数学分析上表现更优。

还有网友发现,Nemotron 3 Nano 在长上下文和信息提取任务中仍存在幻觉、重复和推理不稳定的问题,而 Qwen3 系列在类似任务上表现更稳健,这可能是因为是llama.cpp对模型的发挥存在限制。

但总的来说,也是有不少网友点赞的,比如新模型在特定量化和硬件下的高吞吐性能,以及英伟达的开源精神。
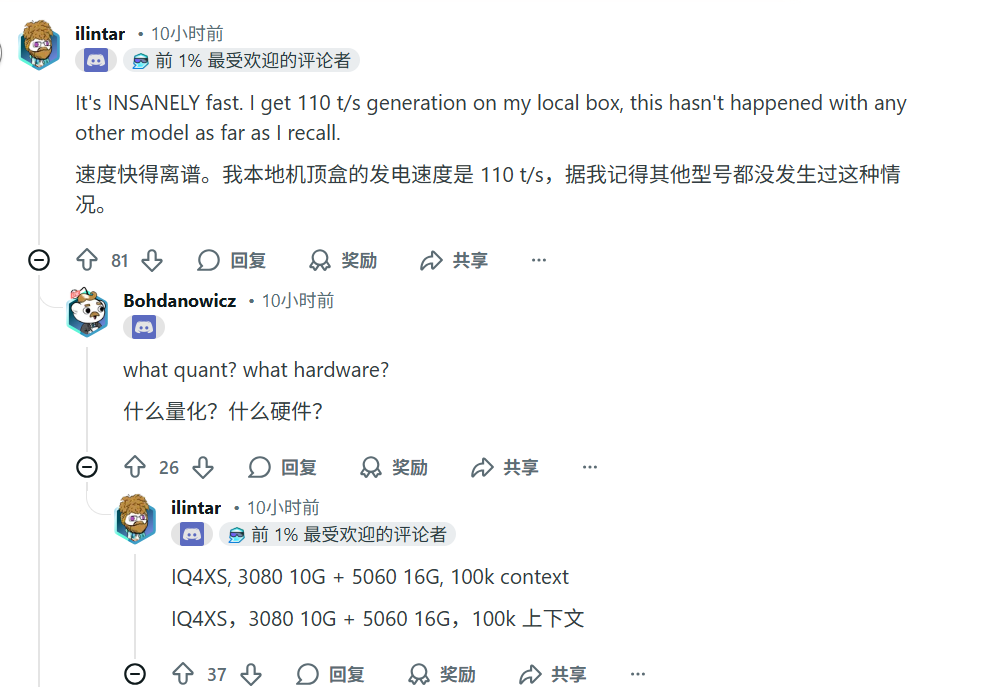
官方也发布了几个主要推理引擎(vLLM、SGLang、Tensor-RT)的Cookbooks,方便开发者部署和运行Nemotron 3 Nano。
感兴趣的朋友都可以去试试!
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。
因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量