Neo4j数据库中批量插入数据(数据在.csv文件中)
1、数据格式描述:
数据集介绍:

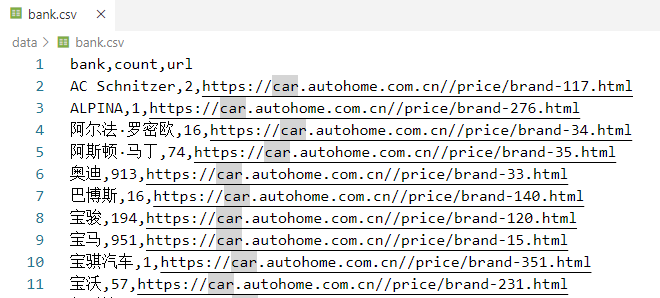
bank.csv - 汽车品牌数据
python
bank: 汽车品牌名称
count: 该品牌的车型数量
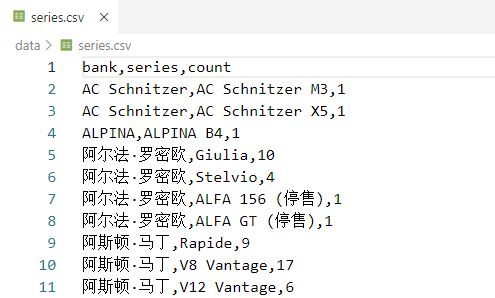
url: 汽车之家品牌的网址链接series.csv - 车系数据
python
bank: 所属品牌
series: 具体车系名称(如:"AC Schnitzer M3")
count: 该车系的车型数量2、将数据导入到Neo4j数据库中
将bank.csv 与 series.csv 上传到neo4j的import 目录下

然后登陆 http://192.168.8.216:7474/browser/ 依次分别执行上述节点与关系导入语句

python
# 遇上csv文件乱码,先用 记事本 打开文件,在另存为csv文件时选择utf-8转码
MATCH (n) detach delete n
# 导入汽车品牌表
LOAD CSV WITH HEADERS FROM "file:///bank.csv" AS line
CREATE (:Bank{name:line.bank, count:line.count})
# 导入品牌系列表
LOAD CSV WITH HEADERS FROM "file:///series.csv" AS line
CREATE (:Series{name:line.series, count:line.count})
# 导入关系表【这里关系表和品牌系列表一样】
LOAD CSV WITH HEADERS FROM "file:///series.csv" AS line
MATCH (entity1: Bank{name:line.bank}), (entity2: Series{name:line.series})
CREATE (entity1) - [:Subtype{type:line.relation}] -> (entity2)
# 本人执行如下:
LOAD CSV WITH HEADERS FROM "file:///series.csv" AS line
MATCH (entity1:Bank {name:line.bank})
MATCH (entity2:Series {name:line.series})
CREATE (entity1)-[:Subtype{type:"Subtype"}]->(entity2)
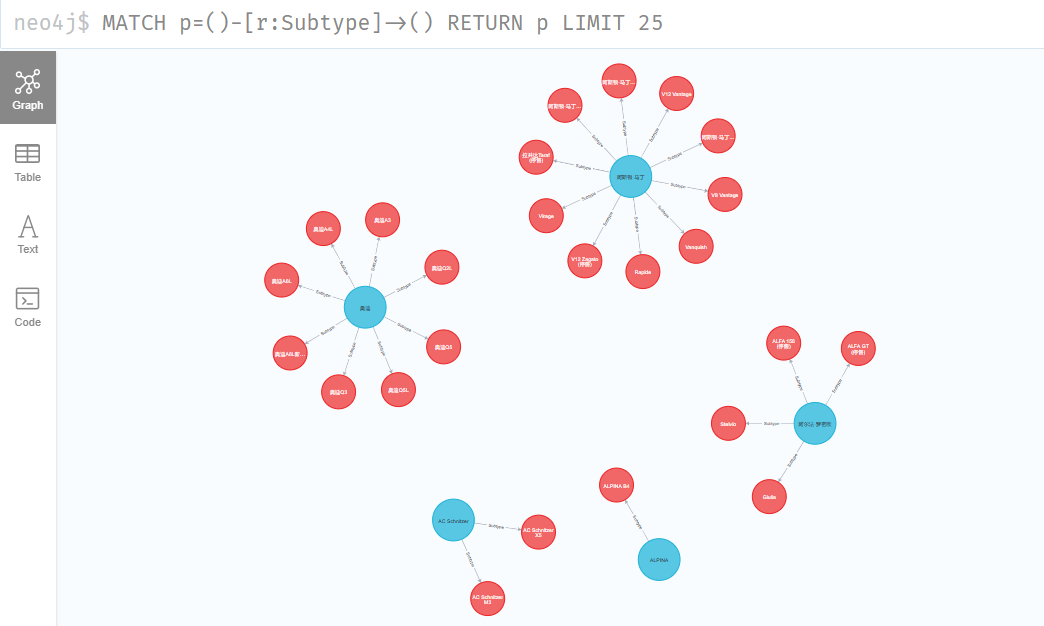
# 查询品牌及其关系
MATCH p=()-[r:Subtype]->() RETURN p LIMIT 250
CREATE CONSTRAINT ON (b: Bank)
ASSERT b.name is UNIQUE
match (n:Series) return n LIMIT 25