目录
[4.1 MaskDecoder.predict_masks](#4.1 MaskDecoder.predict_masks)
[4.1.2 TwoWayTransformer.forward](#4.1.2 TwoWayTransformer.forward)
[4.1.2.1 TwoWayAttentionBlock.forward](#4.1.2.1 TwoWayAttentionBlock.forward)
[4.1.2.2 self.self_attn------Attention.forward](#4.1.2.2 self.self_attn——Attention.forward)
如何理解自注意力机制呢?我自己还不了解我自己吗,还要用这种方式?
所以说其实是如果我是token的话,我的身份是受整个向量的其他token影响的,每个token都去询问一遍其他所有token以确定自己的身份,是这样理解吗
[4.1.2.3 self.cross_attn_token_to_image------Attention.forward](#4.1.2.3 self.cross_attn_token_to_image——Attention.forward)
[为什么out = F.scaled_dot_product_attention(q, k, v, dropout_p=dropout_p) 之后out: torch.Size(1, 8, 9, 16)](#为什么out = F.scaled_dot_product_attention(q, k, v, dropout_p=dropout_p) 之后out: torch.Size([1, 8, 9, 16]))
[如何理解attn = softmax(q_h @ k_h.transpose(-2,-1) / sqrt(d_k))和out_h = attn @ v_h](#如何理解attn = softmax(q_h @ k_h.transpose(-2,-1) / sqrt(d_k))和out_h = attn @ v_h)
[代入SAM2分割这一情景,如何理解attn = softmax(q_h @ k_h.transpose(-2,-1) / sqrt(d_k))和out_h = attn @ v_h](#代入SAM2分割这一情景,如何理解attn = softmax(q_h @ k_h.transpose(-2,-1) / sqrt(d_k))和out_h = attn @ v_h)
[4.1.2.4 自注意力和交叉注意力有什么区别?为什么要先自注意力?](#4.1.2.4 自注意力和交叉注意力有什么区别?为什么要先自注意力?)
[4.1.2.5 为什么q和k都要加个绝对位置编码,然后v没加而直接就是keys?](#4.1.2.5 为什么q和k都要加个绝对位置编码,然后v没加而直接就是keys?)
[4.1.2.6 MLP.forward](#4.1.2.6 MLP.forward)
一、前言
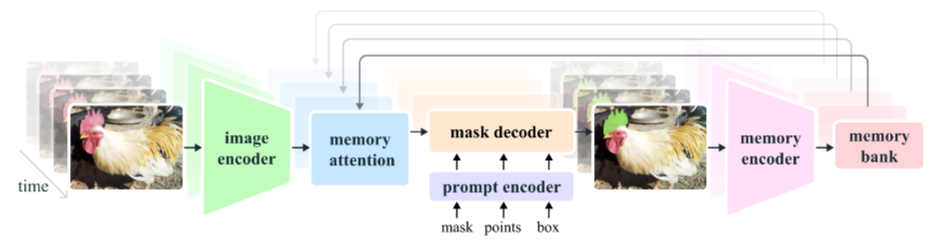
下面是第一帧情况下的函数调用顺序。
2.12 <重点> add_new_prompt
2.13 <重点> _run_single_frame_inference
2.14 <重点> track_step
2.15 <重点> _prepare_memory_conditioned_features
2.16 _use_multimask
2.17 <重点> _forward_sam_heads
2.18 提示编码器:类PromptEncoder.forward
2.19 类PositionEmbeddingRandom.forward_with_coords
2.20 类PromptEncoder.get_dense_pe
2.21 掩码解码器 类MaskDecoder.forward
2.22 类MaskDecoder.predict_masks
2.23 TwoWayTransformer.forward(这篇开头在这)
2.24 TwoWayAttentionBlock.forward
2.25 Attention.forward(这篇结束在这)
2.26 <重点> MLP.forward
2.27 Attention.forward
2.28 LayerNorm2d.forward
2.29 MaskDecoder._dynamic_multimask_via_stability
2.30 MaskDecoder._get_stability_scores
2.31 fill_holes_in_mask_scores
2.32 _get_maskmem_pos_enc
2.33 _consolidate_temp_output_across_obj
2.34 _get_orig_video_res_output
四、MaskDecoder.forward
4.1 MaskDecoder.predict_masks
4.1.2 TwoWayTransformer.forward
sam2/modeling/sam/transformer.py
hs, src = self.transformer(src, pos_src, tokens)
上面这句进去就是调用TwoWayTransformer的forward函数。
python
class TwoWayTransformer(nn.Module):
"""
双向 Transformer:
1. 先让「稀疏点 token」(queries) 与「稠密图像 token」(keys) 做若干层双向 cross-attention;
2. 最后再让 queries 单独对图像做一次 attention,得到增强后的 queries 作为最终输出。
图像 token 只做中间传递,最终原样返回。
"""
def __init__(
self,
depth: int, # 双向 attention block 重复次数
embedding_dim: int, # 通道维度 C
num_heads: int, # 多头注意力的头数
mlp_dim: int, # FFN 中间层维度
activation: Type[nn.Module] = nn.ReLU,
attention_downsample_rate: int = 2, # Attention 内部 Q/K 下采样比例
) -> None:
super().__init__()
self.depth = depth
self.embedding_dim = embedding_dim
self.num_heads = num_heads
self.mlp_dim = mlp_dim
self.layers = nn.ModuleList()
# 堆叠 depth 个双向 attention block
for i in range(depth):
self.layers.append(
TwoWayAttentionBlock(
embedding_dim=embedding_dim,
num_heads=num_heads,
mlp_dim=mlp_dim,
activation=activation,
attention_downsample_rate=attention_downsample_rate,
skip_first_layer_pe=(i == 0), # 第一层无需给 query 加 PE(已在输入时加好)
)
)
# 最后一层:queries → 图像的 attention
self.final_attn_token_to_image = Attention(
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
)
self.norm_final_attn = nn.LayerNorm(embedding_dim)
def forward(
self,
image_embedding: Tensor, # [B, C, H, W]
image_pe: Tensor, # [B, C, H, W] 图像位置编码
point_embedding: Tensor, # [B, Np, C] 点提示的 embedding(已含 PE)
) -> Tuple[Tensor, Tensor]:
"""
Returns:
processed point embedding [B, Np, C]
processed image embedding [B, H*W, C] (与输入内容相同,仅 reshape)
"""
# image_embedding: torch.Size([1, 256, 64, 64])
# image_pe: torch.Size([1, 256, 64, 64])
# point_embedding: torch.Size([1, 9, 256])
# 1. 把图像展平成 token 序列
bs, c, h, w = image_embedding.shape
# bs:1 c:256 h:64 w:64
image_embedding = image_embedding.flatten(2).permute(0, 2, 1) # [B, H*W, C]
# image_embedding: torch.Size([1, 4096, 256])
image_pe = image_pe.flatten(2).permute(0, 2, 1) # [B, H*W, C]
# image_pe: torch.Size([1, 4096, 256])
queries = point_embedding # [B, Np, C]
# queries: torch.Size([1, 9, 256])
keys = image_embedding # [B, H*W, C]
# keys: torch.Size([1, 4096, 256])
# 2. 逐层双向 attention 更新 queries 和 keys
for layer in self.layers:
# 进入TwoWayAttentionBlock.forward
queries, keys = layer(
queries=queries,
keys=keys,
query_pe=point_embedding, # 每次把原始 PE 作为 Q 的偏置传进去
key_pe=image_pe,
)
# 3. 最后一层:queries 再对图像做一次 attention
q = queries + point_embedding # 残差加回原始 PE
k = keys + image_pe
attn_out = self.final_attn_token_to_image(q=q, k=k, v=keys) # [B, Np, C]
queries = queries + attn_out # 残差连接
queries = self.norm_final_attn(queries) # LayerNorm
# 4. 返回增强后的 queries 和原图 token(下游只拿 queries 用即可)
return queries, keys整体流程一句话总结
"稀疏点 token" 先和"稠密图像 token"在多层的双向 cross-attention 里互相更新;
最后再把更新后的点 token 单独对图像做一次 attention 并残差+Norm,得到最终点特征。
图像 token 只充当信息搬运工,原样返回即可。
4.1.2.1 TwoWayAttentionBlock.forward
sam2/modeling/sam/transformer.py
for layer in self.layers:
进入TwoWayAttentionBlock.forward
queries, keys = layer(
queries=queries,
keys=keys,
query_pe=point_embedding, # 每次把原始 PE 作为 Q 的偏置传进去
key_pe=image_pe,
)
python
class TwoWayAttentionBlock(nn.Module):
def __init__(
self,
embedding_dim: int,
num_heads: int,
mlp_dim: int = 2048,
activation: Type[nn.Module] = nn.ReLU,
attention_downsample_rate: int = 2,
skip_first_layer_pe: bool = False,
) -> None:
"""
一个 Transformer 块,内部 4 步:
1) sparse queries 自注意力
2) queries cross-attend 到 dense keys(token→image)
3) 对 queries 做 MLP
4) dense keys cross-attend 到 sparse queries(image→token)
通过双向交叉,实现"稀疏点"与"稠密图"信息互通。
"""
super().__init__()
# 1. 自注意力
self.self_attn = Attention(embedding_dim, num_heads)
self.norm1 = nn.LayerNorm(embedding_dim)
# 2. token→image 交叉注意力
# 又进入TwoWayAttentionBlock.forward
# attention_downsample_rate:2
self.cross_attn_token_to_image = Attention(
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
)
self.norm2 = nn.LayerNorm(embedding_dim)
# 3. MLP
self.mlp = MLP(
embedding_dim, mlp_dim, embedding_dim, num_layers=2, activation=activation
)
self.norm3 = nn.LayerNorm(embedding_dim)
# 4. image→token 交叉注意力
self.norm4 = nn.LayerNorm(embedding_dim)
# attention_downsample_rate:2
self.cross_attn_image_to_token = Attention(
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
)
self.skip_first_layer_pe = skip_first_layer_pe # 首块是否给 Q 加 PE
def forward(
self, queries: Tensor, keys: Tensor, query_pe: Tensor, key_pe: Tensor
) -> Tuple[Tensor, Tensor]:
# 输入形状示例:
# queries: torch.Size([1, 9, 256]) 稀疏点 token
# keys: torch.Size([1, 4096, 256]) 稠密图像 token
# query_pe:torch.Size([1, 9, 256]) 稀疏点token的绝对位置编码
# key_pe:torch.Size([1, 4096, 256]) 稠密图像token的绝对位置编码
# ---------- 1. 自注意力 ----------
# self.skip_first_layer_pe: True
if self.skip_first_layer_pe: # 首层不加 PE,直接 self-attn
# queries: torch.Size([1, 9, 256])
queries = self.self_attn(q=queries, k=queries, v=queries)
# queries: torch.Size([1, 9, 256])
else:
q = queries + query_pe # 残差加 PE
attn_out = self.self_attn(q=q, k=q, v=queries)
queries = queries + attn_out # 残差连接
queries = self.norm1(queries) # [B, 9, 256]
# queries: torch.Size([1, 9, 256])
# ---------- 2. token→image 交叉注意力 ----------
q = queries + query_pe # 给 query 加 PE
# q: torch.Size([1, 9, 256])
k = keys + key_pe # 给 key 加 PE
# k: torch.Size([1, 4096, 256])
# q: torch.Size([1, 9, 256])
# k: torch.Size([1, 4096, 256])
# keys: torch.Size([1, 4096, 256])
attn_out = self.cross_attn_token_to_image(q=q, k=k, v=keys) # 下采样在内部完成
# attn_out: torch.Size([1, 9, 256])
queries = queries + attn_out # 残差
# queries: torch.Size([1, 9, 256])
queries = self.norm2(queries) # [B, 9, 256]
# queries: torch.Size([1, 9, 256])
# ---------- 3. MLP ----------
mlp_out = self.mlp(queries)
queries = queries + mlp_out # 残差
queries = self.norm3(queries) # [B, 9, 256]
# ---------- 4. image→token 交叉注意力 ----------
# 注意:这里"角色互换"------用图像 token 做 Q,去 attend 稀疏点
q = queries + query_pe # 稀疏点继续当"被 attend"的 K/V
k = keys + key_pe # 图像当 Q
attn_out = self.cross_attn_image_to_token(q=k, k=q, v=queries) # 形状 [B, 4096, 256]
keys = keys + attn_out # 残差更新图像 token
keys = self.norm4(keys) # [B, 4096, 256]
# 返回更新后的 (queries, keys),供下一层或下游使用
return queries, keys总结
稀疏点先 self-attn,增强自身上下文。
再把增强后的点去 attend 图像,提取对应位置特征。
过一遍 MLP,进一步非线性变换。
最后让图像 token 反过来看这些点,把"哪些区域有点"信息写回图像特征。
于是"点"与"图"完成一次双向融合,形状全程保持不变:
queries 始终 B, Np, C,keys 始终 B, H·W, C。
注意上面TwoWayAttentionBlock初始化里面,创建Attention的时候,自注意力是没有传入downsample_rate,所以是默认的1,而交叉注意力是传入downsample_rate=2的,这也是为什么后面线性映射的时候自注意力的Attention是没有降维的(一直是256),而交叉注意力的Attention里面线性映射的时候降维到128了(不过最后会升回256)
4.1.2.2 **self.self_attn------**Attention.forward
sam2/modeling/sam/transformer.py
TwoWayAttentionBlock.forward中
queries = self.self_attn(q=queries, k=queries, v=queries)
上面的语句进入Attention的forward
python
class Attention(nn.Module):
"""
标准多头注意力,但支持「把 Q/K/V 映射到更低维度」以节省计算。
内部使用 PyTorch 2.x 的 scaled_dot_product_attention,可自动选 Flash / Mem-efficient / Math kernel。
"""
def __init__(
self,
embedding_dim: int, # 输入 token 的通道数 C
num_heads: int, # 头数 h
downsample_rate: int = 1, # 把 C 压缩成 C//downsample_rate,再分头
dropout: float = 0.0,
kv_in_dim: int = None, # 如果 K/V 的输入维度与 Q 不同,可单独指定
) -> None:
super().__init__()
self.embedding_dim = embedding_dim
self.kv_in_dim = kv_in_dim if kv_in_dim is not None else embedding_dim
# downsample_rate:1
self.internal_dim = embedding_dim // downsample_rate # 压缩后的通道
self.num_heads = num_heads
assert self.internal_dim % num_heads == 0, "num_heads 必须整除 internal_dim"
# 线性映射:Q 来自 embedding_dim,K/V 可能来自别的维度
self.q_proj = nn.Linear(embedding_dim, self.internal_dim)
self.k_proj = nn.Linear(self.kv_in_dim, self.internal_dim)
self.v_proj = nn.Linear(self.kv_in_dim, self.internal_dim)
# 输出再映射回原始通道
self.out_proj = nn.Linear(self.internal_dim, embedding_dim)
self.dropout_p = dropout
# 把 [B, N, C] 拆成 [B, h, N, C//h] 以便并行算多头
def _separate_heads(self, x: Tensor, num_heads: int) -> Tensor:
# x:[1,9,256] num_heads:8
b, n, c = x.shape
x = x.reshape(b, n, num_heads, c // num_heads)
# [1,9,8,32]
return x.transpose(1, 2) # [1,8,9,32]
# 逆操作:把 [B, h, N, C//h] 还原成 [B, N, C]
def _recombine_heads(self, x: Tensor) -> Tensor:
b, n_heads, n_tokens, c_per_head = x.shape # [1,8,9,32]
x = x.transpose(1, 2) # [1,9,8,32]
return x.reshape(b, n_tokens, n_heads * c_per_head) # [1,9,256]
def forward(self, q: Tensor, k: Tensor, v: Tensor) -> Tensor:
# 输入示例:q/k/v 均为 [1,9,256]
# 1. 线性映射 + 降维
q = self.q_proj(q)
# q: [1,9,256]
k = self.k_proj(k)
# k: [1,9,256]
v = self.v_proj(v)
# v: [1,9,256]
# 2. 拆头
q = self._separate_heads(q, self.num_heads)
# q: [1,8,9,32]
k = self._separate_heads(k, self.num_heads)
# k: [1,8,9,32]
v = self._separate_heads(v, self.num_heads)
# v: [1,8,9,32]
# 3. 计算 dropout 开关(推理时关闭)
# self.training: False
dropout_p = self.dropout_p if self.training else 0.0
# dropout_p: 0.0
# 4. 调用最优 kernel 做 scaled dot-product attention
with torch.backends.cuda.sdp_kernel(
# USE_FLASH_ATTN: False
enable_flash=USE_FLASH_ATTN, # 全局开关:是否尝试 FlashAttention
# OLD_GPU:True dropout_p:0.0 MATH_KERNEL_ON:True
enable_math=(OLD_GPU and dropout_p > 0.0) or MATH_KERNEL_ON, # 兜底 math kernel
enable_mem_efficient=OLD_GPU, # 老 GPU 可开 memory-efficient
):
out = F.scaled_dot_product_attention(q, k, v, dropout_p=dropout_p) # [1,8,9,32]
# 5. 合并头 + 输出投影
# out: torch.Size([1, 8, 9, 32])
out = self._recombine_heads(out)
# out: torch.Size([1, 9, 256])
out = self.out_proj(out)
# out: torch.Size([1, 9, 256])
return out
先把 Q/K/V 线性映射到更低维度
internal_dim,省计算。拆成多头形状,用 PyTorch 官方
scaled_dot_product_attention自动选最快 kernel。计算完再合并头,并线性映射回原始通道数。
整个模块对外保持"输入 B, N, C → 输出 B, N, C"的透明接口,内部按需降维。
线性映射前后维度是不变的,那它里面做了什么?有什么作用?
"维度不变"只是 最外圈 的假象------
forward里 真正做矩阵乘的维度 已经被q_proj / k_proj / v_proj压成了internal_dim = embedding_dim // downsample_rate,自注意力这里是取downsample_rate=1算完注意力再用
out_proj把通道升回来。所以"线性映射"里面干了三件事:
降维投影 (省钱)
把原始
C映射到C/r(r=downsample_rate,默认 1 即不降;SAM 里常取 2)。参数量与计算量都近似降为 1/r²。
多头拆分准备
投影后的通道必须能被
num_heads整除,才能直接.reshape(..., heads, dim_per_head)。这一步把"物理维度"转成"逻辑头维度",后面
sdpa并行算 h 个头。可学习的线性组合 (混通道)
即使 r=1 不降维,投影矩阵仍是 满秩可训练参数 ,给每个头提供不同的子空间,
否则所有头都看到完全相同的 Q/K/V,多头就退化成"单头复制"。
形象一句话
"先压通道省钱,再拆头并行,最后升通道还给你" ------外表看 B,N,C→B,N,C,里面其实偷偷把计算搬到了更小的空间。
你的意思是,本来q,k,v都是相同的,线性映射之后就不同了是吗,那如何理解线性映射呢?后面什么要对q、k、v拆头,为什么是拆8个头?F.scaled_dot_product_attention做了什么?out_proj做了什么?
把四个问题拆成四步,一次讲清:
线性映射到底干了什么
输入
q=k=v=x确实完全一样,但
q_proj、k_proj、v_proj是三个独立的权重矩阵 (形状都是[C, C/r])。各自乘一遍后,得到三套不同 的
Q/K/V,通道数只剩C/r。这就是 Attention 论文里最经典的"用三个线性层把同一批 token 变成查询-键-值"。
为什么要"拆 8 个头"
投影后的
internal_dim必须能被头数整除,于是
internal_dim = num_heads × (dim_per_head)。SAM 把
num_heads设成 8,相当于把256 → 8×32;每个头只看 32 维的子空间,并行学 8 组不同的相似度函数,最后再拼回来。
头数=8 是超参,经验值;越大越分散,计算量也线性涨。
F.scaled_dot_product_attention内部做了什么给定
[B, h, N, d]的Q/K/V,它一步完成:
scores = Q @ K.transpose(-2,-1) / sqrt(d) # [B,h,N,N] 相似度 attn = softmax(scores, dim=-1) # 行归一化得权重 output = attn @ V # 加权求和并自动选 FlashAttention / memory-efficient / math 三种 kernel 中最快且支持你硬件的那一条。
out_proj的作用多头输出拼完后形状是
[B, N, internal_dim],但下游网络期望原通道C;
out_proj就是一个Linear(internal_dim, C),把压缩后的特征升维+线性混合 ,再残差接回原路径。它同时让不同头的信息再次融合,并恢复网络下一层所需的通道数。
一句话串起来:
"同一份
x过三个独立线性层 得到Q/K/V→ 压通道 → 拆 8 个头并行算相似度 → 拼回 → 再线性映射回原始通道。"
这里很多函数进不去,标记一下
如何理解自注意力机制呢?我自己还不了解我自己吗,还要用这种方式?
"自己还不了解自己吗?"------这句话把"自注意力"拟人化了,结果就绕进了死胡同。
把它当成纯数学的"特征再分配" 来看,就通了:
token ≠ 人
每个 token 只是 C 维向量,同一位置在不同层含义一直在变 。
"了解我自己"不是指它突然有了意识,而是用全局信息重新给这 C 个数加权,让"该强调的子空间放大,该抑制的噪声归零"。
没有全局视野的向量 = 局部盲人
单层 Conv 或 FFN 只能看到邻域(甚至只能看单点);
自注意力把整句/整图所有位置 拉成一张相似度表,一次完成任意两两通信 。
结果:
"猫" token 发现当前特征里"狗"分量很高,就把这部分降权;
"边界" token 发现远处还有一条同向边界,就把对应特征加强。
这就是上下文校正,而不是"自我怀疑"。
数学上就是"可学习的加权平均"
new_x_i = Σ_j softmax( (x_i W_q)(x_j W_k)^T /√d ) · (x_j W_v)权重矩阵 W 训练好后,每个位置自动知道该抄谁、抄多少 。
所谓"自"仅表示 Query、Key、Value 都来自同一组 x,不引入额外外部信号。
为什么一定要"投影三次"
如果直接用
x点积x,只能得到原始特征 的相似度;投影成
Q/K/V后,网络可以给"查询侧""键侧""值侧"各自学不同的子空间 ,否则就退化成固定核的平滑,没有可学习参数。
拆多头 = 多组"聚光灯"
8 个头 ≈ 8 台不同颜色的探照灯,每台只照 32 维,
有的专盯"颜色相似",有的专盯"空间相邻",最后拼起来就同时兼顾多种上下文线索。
一句话收尸:
自注意力不是让 token"反省人生",而是给它一次"看完全局再重新整理自己特征"的机会;
三次线性映射 + 多头 + softmax 加权,只是让这次"整理"变得可学习、可并行、多视角。
你的意思是token是我的局部,我的局部与局部之间要互相了解是吗
可以这么类比,但别再往"人"上靠------把"局部"想成纯数据块就不会绕:
一张图被切成 64×64 的小 patch,每个 patch 只"看见"自己那 8×8 像素;
它对应的 token 向量里,也许有"边缘""红色""纹理"这些分量,但不知道 20 个 patch 之外还有一条同方向的边缘 。
自注意力就是让这条"局部边缘" token 去查整张图里所有其他边缘 token,发现"哦,原来咱俩在同一条大轮廓上",于是把自己的"轮廓置信度"拉高。
一句话里,"bank" 这个 token 如果只盯自己,无法区分"河岸"还是"银行";
它扫完全句,发现前面有"river",就把"水"相关的分量加大,把"金融"分量压掉。
这就是局部与局部之间互相校正,而不是"谈心"。
数学上就是用相似度做加权平均 :
每个局部发出一个"查询向量",和其他所有局部的"键向量"点积,得到"我跟你有多相关";
再用这组相关度去加权所有局部的"值向量",更新自己 。
所以"局部了解局部"=用全局相似度重新加权融合信息,让原本孤立的 C 维向量变成"全局-aware"的新向量。
一句话:
不是 token 有了情感,而是它的数值列表通过"与所有邻居算相似度→加权抄作业"被重新填写了一次,从而带上全局上下文。
所以说其实是如果我是token的话,我的身份是受整个向量的其他token影响的,每个token都去询问一遍其他所有token以确定自己的身份,是这样理解吗
可以这么"拟人"地打比方,但一定记住------这只是帮你建立直觉的比喻,底层全是矩阵乘法,没有"身份""询问"这些意识活动:
在自注意力前,你(某个 token)手里的 C 个数字只来自你自己的小区域(8×8 像素或一个子词)。
自注意力让你把这张"全局相似度表"当成权重 ,去加权抄全场所有 token 的特征 ,然后用抄来的结果替换/加回自己原来的 C 个数字。
于是,新的 C 个数字里既保留了原来的局部线索,又混入了"谁跟我很像/谁对我重要"的全局信息。
下一层网络看到的新向量,就不再只是局部,而是全局-aware 的表示------这就是你说的"身份被其他 token 影响"。
所以,"询问"=点积算相似度,"确定身份"=用相似度加权平均后更新自己的特征向量 。
整个过程是可学习的线性投影 + 数值加权,没有任何语义层面的"自我认知"。
全局相似度表这是指q、k、v都有各自的可学习的权重矩阵是吗?那这个权重矩阵是怎么被初始化,怎么被学习的呢?它的数值是怎么来的? 是不是有种真值知道更新后的是不是正确的,然后反向更新这个权重矩阵呢?但这个真值是什么?
把"比喻"全部剥掉,只剩可学习的张量 和可求导的 loss,就清楚了:
三个权重矩阵哪来的
形状:
q_proj.weight [C, C/r],k_proj.weight [C, C/r],v_proj.weight [C, C/r]初始化:PyTorch 默认用
KaimingUniform或xavier_uniform随机采样,数值服从某种 scaled 均匀分布,与任务无关。它们就是普通 Linear 层 ,跟 CNN 的卷积核一样,一开始完全随机,没有任何"真值"先验。
"全局相似度表"怎么来的
前向时:
Q = x W_q, K = x W_k, S = Q K^T /√d
S就是[B, h, N, N]的"相似度表",每一次 forward 都重新算一次,不存储、不保留,也没有可学习参数 ;可学习的只有
W_q、W_k(以及W_v、out_proj)。数值怎么被"纠正"------没有"真值相似度"
下游任务给的才是终极真值:
分割任务:像素级 mask
分类任务:类别标签
生成任务:下一个 token ID
网络输出 → 与这些标签算交叉熵、MSE、Dice ... → 得到标量 loss → 反向传播一直走到
W_q、W_k、W_v、out_proj→ 自动求导调整矩阵元素。
没有任何人告诉模型"第 i 与 j 的相似度应该是 0.7",它只是发现"把这两个 patch 的权重调高,最终 mask 的 IoU 会变大",于是下次继续调高。
- 总结一句话
可学习的是四个线性矩阵,相似度表只是它们在前向时临时算出的副产品;
"对不对"由下游任务 loss 说了算,loss 只认最终输出与人工标签的差距,不认中间相似度。
这里感觉没有理清楚,标记一下
4.1.2.3 self.cross_attn_token_to_image**------**Attention.forward
TwoWayAttentionBlock.forward中
---------- 2. token→image 交叉注意力 ----------
q = queries + query_pe # 给 query 加 PE
q: torch.Size(1, 9, 256)
k = keys + key_pe # 给 key 加 PE
k: torch.Size(1, 4096, 256)
又进入Attention.forward
attn_out = self.cross_attn_token_to_image(q=q, k=k, v=keys) # 下采样在内部完成
queries = queries + attn_out # 残差
queries = self.norm2(queries) # B, 9, 256
python
class Attention(nn.Module):
"""
An attention layer that allows for downscaling the size of the embedding
after projection to queries, keys, and values.
"""
def __init__(
self,
embedding_dim: int,
num_heads: int,
downsample_rate: int = 1,
dropout: float = 0.0,
kv_in_dim: int = None,
) -> None:
super().__init__()
self.embedding_dim = embedding_dim # 原始输入维度(q 的输入维度)
self.kv_in_dim = kv_in_dim if kv_in_dim is not None else embedding_dim # k/v 的输入维度,可与 q 不同
# self.internal_dim = 256 // 2 = 128
self.internal_dim = embedding_dim // downsample_rate # 经过降采样后的"内部"维度,用于多头计算
self.num_heads = num_heads # 注意力头数
assert (
self.internal_dim % num_heads == 0
), "num_heads must divide embedding_dim."
# 线性映射:把输入映射到统一的 internal_dim 空间
# embedding_dim:256 self.internal_dim:128
self.q_proj = nn.Linear(embedding_dim, self.internal_dim) # 仅 q 来自 embedding_dim
# self.kv_in_dim:256
self.k_proj = nn.Linear(self.kv_in_dim, self.internal_dim) # k/v 可能来自不同维度
self.v_proj = nn.Linear(self.kv_in_dim, self.internal_dim)
# 输出映射:把拼接后的多头结果再映射回原始 embedding_dim
# embedding_dim:256 self.internal_dim:128
self.out_proj = nn.Linear(self.internal_dim, embedding_dim)
self.dropout_p = dropout # attention dropout 比例
def _separate_heads(self, x: Tensor, num_heads: int) -> Tensor:
"""把 [B, N, C] 拆成 [B, num_heads, N, C//num_heads],方便并行算多头"""
b, n, c = x.shape
x = x.reshape(b, n, num_heads, c // num_heads)
return x.transpose(1, 2) # B x N_heads x N_tokens x C_per_head
def _recombine_heads(self, x: Tensor) -> Tensor:
"""与 _separate_heads 相反,把多头结果重新拼接回 [B, N, C]"""
# x: torch.Size([1, 8, 9, 16])
b, n_heads, n_tokens, c_per_head = x.shape
# b:1 n_heads:8 n_tokens:9 c_per_head:16
x = x.transpose(1, 2) # 先交换维度,变成 [B, N_tokens, N_heads, C_per_head]
# x: torch.Size([1, 9, 8, 16])
return x.reshape(b, n_tokens, n_heads * c_per_head) # B x N_tokens x C
def forward(self, q: Tensor, k: Tensor, v: Tensor) -> Tensor:
"""
参数:
q: [B, Nq, embedding_dim] 查询序列
k: [B, Nk, kv_in_dim] 键序列
v: [B, Nk, kv_in_dim] 值序列
返回:
out: [B, Nq, embedding_dim]
"""
# 输入:
# q: torch.Size([1, 9, 256])
# k: torch.Size([1, 4096, 256])
# v: torch.Size([1, 4096, 256])
# Input projections
# 初始化的时候 self.internal_dim = embedding_dim // downsample_rate
# downsample_rate = 2, 所以交叉注意力里的线性映射发生降维了
q = self.q_proj(q) # q: torch.Size([1, 9, 128])
k = self.k_proj(k) # k: torch.Size([1, 4096, 128])
v = self.v_proj(v) # v: torch.Size([1, 4096, 128])
# Separate into heads
q = self._separate_heads(q, self.num_heads) # q: torch.Size([1, 8, 9, 16])
k = self._separate_heads(k, self.num_heads) # k: torch.Size([1, 8, 4096, 16])
v = self._separate_heads(v, self.num_heads) # v:torch.Size([1, 8, 4096, 16])
# self.dropout_p:0 self.training:False
dropout_p = self.dropout_p if self.training else 0.0 # 推理时关闭 dropout
# dropout_p: 0.0
# Attention
# 根据 GPU 能力及配置选择最优 kernel:FlashAttention / Math / MemoryEfficient
with torch.backends.cuda.sdp_kernel(
enable_flash=USE_FLASH_ATTN, # USE_FLASH_ATTN:False
enable_math=(OLD_GPU and dropout_p > 0.0) or MATH_KERNEL_ON, # OLD_GPU:True dropout: 0.0 MATH_KERNEL_ON: True
enable_mem_efficient=OLD_GPU,
):
out = F.scaled_dot_product_attention(q, k, v, dropout_p=dropout_p)
# out: torch.Size([1, 8, 9, 16])
out = self._recombine_heads(out) # out: torch.Size([1, 9, 128])
out = self.out_proj(out) # out: torch.Size([1, 9, 256])
return out代码整体解释
作用:实现一个支持"降维"的多头交叉注意力层。
降维:通过
downsample_rate把 q/k/v 映射到更低的internal_dim再计算注意力,减少计算量;计算完再映射回原始embedding_dim。支持异构输入:k/v 的输入维度
kv_in_dim可与 q 的embedding_dim不同,方便像 ViT 编码器-解码器结构那样使用。多头拆分/合并:
_separate_heads与_recombine_heads负责把张量维度在"token"与"head"之间来回变换,以调用 PyTorch 的高效scaled_dot_product_attention。后端选择:
sdp_kernel的上下文管理器根据硬件与超参自动挑选 FlashAttention、Math 或 MemoryEfficient kernel,兼顾速度与显存。
为什么out = F.scaled_dot_product_attention(q, k, v, dropout_p=dropout_p) 之后out: torch.Size(1, 8, 9, 16)
一句话:因为
F.scaled_dot_product_attention在 "多头已经拆好" 的 4-D 张量上做的是 逐头计算 ,输出形状和输入的"头维"保持一致,所以
[B, num_heads, Nq, C_per_head]进去 → 同样形状出来。
详细推导
输入形状
q:
[1, 8, 9, 16]→ 含义[batch=1, heads=8, query_tokens=9, dim_per_head=16]k:
[1, 8, 4096, 16]v:
[1, 8, 4096, 16]
scaled_dot_product_attention内部逻辑对每一个头(
dim=1上切片)独立地执行:
python# 对于1个头,q乘以k的转置 [9, 16] x [16, 4096] = [9, 4096] attn = softmax(q_h @ k_h.transpose(-2,-1) / sqrt(d_k)) # [9, 4096] # 对于1个头,[9, 4096] x [4096, 16] = [9, 16] out_h = attn @ v_h # [9, 16]因此每个头都会得到一个
[9, 16]的输出。把 8 个头的结果按"头维"堆回去,就是
[1, 8, 9, 16]。输出形状
函数约定:
不改变头数
不改变 batch 大小
token 数始终与 q 的 token 数相同
特征维度始终与 v 的 per-head 维度相同
所以出来还是
[1, 8, 9, 16]。
小结
"多头"维度在
sdpa眼里只是普通的 batch 维度之一,它不会合并或重塑它;合并/重塑是_recombine_heads和out_proj后续才做的事。
如何理解attn = softmax(q_h @ k_h.transpose(-2,-1) / sqrt(d_k))和out_h = attn @ v_h
把"注意力"想成查资料:
q_h:你此刻想提的 问题(9 个关键词,每个 16 维向量)。
k_h:资料库里所有 标题(4096 条,每条也是 16 维向量)。
v_h:资料库里对应标题的 正文(4096 条,每条 16 维向量)。
1. 打分:问题与标题有多匹配
score = q_h @ k_h.transpose(-2, -1) # [9, 4096]每条问题向量与每条标题向量做 点积 (cosine 的分子),数值越大表示越相关。
除以
√d_k(√16 = 4)防止点积绝对值太大导致 softmax 饱和,这一步叫 scale。
2. 转成概率:softmax
attn = softmax(score, dim=-1) # [9, 4096],每行和为 1对每条问题(每一行)做 softmax,把"相关分"变成 选资料的概率分布 。
结果
attn[i, j]就是"问题 i 对标题 j 的关注权重"。
3. 拿概率去加权正文
out_h = attn @ v_h # [9, 16]按关注权重把 4096 条正文向量做 加权平均:
权重大的正文对结果贡献大;
权重小的几乎被忽略。
于是 4096 条信息被压缩成 9 条"精炼答案",维度仍保持 16。
一句话总结
"先算相关性,再按相关性加权求和"------这就是注意力机制的核心。
代入SAM2分割这一情景,如何理解attn = softmax(q_h @ k_h.transpose(-2,-1) / sqrt(d_k))和out_h = attn @ v_h
在 SAM 2(Segment Anything Model 2)里,这套注意力被用来做**"记忆-查询"** 式的跨帧传播:
- 不是普通 NLP 里的"单词→单词",而是
当前帧的像素查询 ← → 记忆库中过去帧的像素特征。把符号代入视频分割场景,就能一眼看懂那两行公式在干什么。
张量含义(单头视角,h 代表"每头")
q_h :当前帧 待解码的 9 个像素 token(可以是某个 prompt 点对应的窗口特征,也可以是整张特征图展平后采样得到的 9 个向量)。
k_h :记忆库里的 4096 个记忆位置(过去帧+当前帧已编码的高置信度像素特征,带空间-时间坐标)。
v_h :与 k_h 一一对应的 16 维掩码嵌入(memory value),后续要拿来加权求和,生成当前像素的掩码 logits。
打分 → softmax attn = softmax(q_h @ k_h.T / √d_k)
→ "当前 9 个像素" 分别对 "记忆库里 4096 个历史像素" 算相似度,再归一化。
结果每行是一个 4096 维的注意力权重 ,告诉模型:
"为了知道眼前这个像素是不是'狗',我最该看记忆库里的哪几个历史像素?"
加权求和 out_h = attn @ v_h
→ 用刚刚的权重,把记忆库里的 4096 条掩码嵌入 做加权平均,得到 9 条 16 维的聚合嵌入 。
这 16 维向量已经融合了跨帧、跨视角的物体一致性信息 ,后续再喂给轻量级解码器就能直接吐出当前 9 个像素的前景/背景概率 或实例掩码 logits。
一句话场景化总结
"当前像素问:'我以前长什么样?'
记忆库回答:'你跟我这些历史像素最像,按相似程度给你加权平均一下以前的掩码特征,你就知道自己该属于哪一类了。 '"
那两行公式就是**"找最像的历史像素 → 把它们的掩码特征借过来"** 的数学实现,保证视频里物体 mask 在帧间时序一致、ID 不跳变。
但现在只是第一帧图像预测
第一帧就用"记忆-查询"式注意力,看起来像是"自己查自己",但这一步仍然有意义,而且并不浪费。把公式放到 SAM 2 第一帧的上下文里,可以这样理解:
记忆库 ≠ 下一帧,而是同一帧内部
在 SAM 2 的 encoder 端,输入图像先被拆成 16×16 的窗口 token(外加绝对位置编码),这些 token 同时扮演 k 和 v ;而 q 则是更稀疏的 prompt token (用户给的 1 个点或 9 个框采样点对应的特征)。
因此
q_h:9 个 prompt token
k_h / v_h:4096 个图像 patch token
注意力就是"prompt 点应该去看图像的哪些区域 "------本质上是一次空间非局部聚合,而不是时序聚合。
softmax 打分 → 拿到"空间关联图"
attn = softmax(q_h @ k_h.T / √d_k)
这一步得到 9×4096 的权重:每个 prompt 点对全图所有 patch 的关注程度。
第一帧没有"历史",但全图 patch 本身就是最丰富的上下文 ;让 prompt 点直接"看到"整幅图,就能迅速把局部提示传播到全局目标区域,解决"一个点太小,边界在哪"的问题。
加权求和 → 生成"全局感知的 prompt 嵌入"
out_h = attn @ v_h
把权重乘回图像特征,得到 9 个已经融合了整幅图语义 的 16 维向量。
这些向量再送进解码器,就能回归出精细的实例掩码,而不会出现"只给一个点就只能猜出一个小圆" 的局部歧义。
一句话总结
第一帧的"记忆库"就是当前帧自身 的全部 patch;注意力做的事是
"用稀疏提示去查询整张图,把提示特征扩散成完整的物体表示 "------
所以它依旧是那两行公式,只是查询范围从'跨帧历史'变成了'同帧全局' ,目的都是把局部线索扩展成完整目标。
4.1.2.4 自注意力和交叉注意力有什么区别?为什么要先自注意力?
把"自注意力"和"交叉注意力"放到 SAM 2 的 TwoWayAttentionBlock 里,可以一句话区分:
自注意力 :同一组 token 内部"互相聊天"------稀疏点之间交换信息。
交叉注意力 :两组不同 token"跨组对话"------稀疏点 ⇄ 整张图交换信息。
1. 为什么先跑自注意力?
让稀疏提示点先自我对齐
用户可能一次给了 1 个点、3 个点或 9 个框,这些提示彼此独立喂进网络。自注意力让它们先"通气":
点 A 知道点 B 也在物体上,于是更确信"这是一整个物体"而非孤立边缘。
点 C 落在背景,通过自注意力被其他前景点"投票"抑制,减少误报。
结果:每个 query token 的 256 维向量已经携带了多提示共识 ,再拿去和图像特征交叉时,查询信号更稳定、噪声更小。
保持排列等变性 (permutation-equivariant)
自注意力对输入顺序不敏感,保证"交换两个提示点顺序"输出不变,符合提示点的集合特性。
工程经验:先内聚、再外联
几乎所有 Transformer 块都遵循
"Self-Attn → Cross-Attn → FFN" 三部曲:
Self:把自己人说明白;
Cross:再出去谈合作;
FFN:最后各自消化。
这样梯度、收敛、精度都更友好。
2. 自注意力 vs. 交叉注意力 对照表
维度 自注意力 交叉注意力 Q/K/V 来源 同一组 token 不同组 token 输入形状 B, 9, 256 Q: B, 9, 256 K/V: B, 4096, 256 作用范围 稀疏点之间 稀疏点 ↔ 图像块 目的 提示点内部共识 把提示扩散到全图 / 把图特征回传提示 参数量 一套投影矩阵 两套投影矩阵(q_proj 与 kv_proj 分开) 计算复杂度 O(9²) 可忽略 O(9×4096) 主导
一句话总结
先自注意力 = 让"点"先达成内部共识 ,再代表整个物体去和整张图谈判;
否则每个点各说各话,交叉注意力会被噪声带偏,分割边缘就飘了。
4.1.2.5 为什么q和k都要加个绝对位置编码,然后v没加而直接就是keys?
q = queries + query_pe # 给 query 加 PE
q: torch.Size(1, 9, 256)
k = keys + key_pe # 给 key 加 PE
k: torch.Size(1, 4096, 256)
q: torch.Size(1, 9, 256)
k: torch.Size(1, 4096, 256)
keys: torch.Size(1, 4096, 256)
attn_out = self.cross_attn_token_to_image(q=q, k=k, v=keys) # 下采样在内部完成
attn_out: torch.Size(1, 9, 256)
为什么q和k都要加个绝对位置编码,然后v没加而直接就是keys?
一句话:
Q 和 K 需要"位置"来对齐"谁问谁",V 只负责"给答案"不需要位置。
注意力打分靠 Q·Kᵀ
相似度 scoreᵢⱼ = (qᵢ + peᵢ) · (kⱼ + peⱼ)
这里 pe 让网络知道
"第 i 个提示点" 与 "第 j 个图像块" 在图像坐标上是否对应 。
去掉 pe,所有向量就只剩"外观"没有"坐标",点乘结果会乱掉------提示点可能去 attend 很远但外观相似的区域。
V 只是"被加权取平均"的原材料
attn_out = Σⱼ αᵢⱼ · vⱼ
权重 αᵢⱼ 已经由 带位置的 Q、K 算好,vⱼ 用纯外观特征即可;
再把 pe 加进 V 只会把位置信息重复注入,反而让网络难以区分"外观"与"位置",实验上通常掉点。
工程惯例
Transformer 原始论文、DETR、SAM/SAM2 都沿用
"Q、K 加位置,V 不加" 的套路,已成为视觉任务默认配置。
记忆口诀
"打分需要地址,送货只看内容。"Q、K 带地址(pe)才能寄对快递;V 只管把货(特征)搬过来,地址早由权重 α 指定好了。
4.1.2.6 MLP.forward
sam2/modeling/sam2_utils.py
TwoWayAttentionBlock.forward里面调用了
mlp_out = self.mlp(queries)
python
# Lightly adapted from
# https://github.com/facebookresearch/MaskFormer/blob/main/mask_former/modeling/transformer/transformer_predictor.py # noqa
class MLP(nn.Module):
"""
经典多层感知机(MLP):
- 支持任意层数
- 最后一层不加激活
- 可选 sigmoid 输出
常用于 Transformer 中的 FFN 子模块。
"""
def __init__(
self,
input_dim: int,
hidden_dim: int,
output_dim: int,
num_layers: int,
activation: nn.Module = nn.ReLU,
sigmoid_output: bool = False,
) -> None:
super().__init__()
self.num_layers = num_layers
# 构造隐藏层维度列表:中间层全部用 hidden_dim
h = [hidden_dim] * (num_layers - 1)
# 顺序拼接 Linear:输入 → 隐藏 → ... → 输出
self.layers = nn.ModuleList(
nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim])
)
self.sigmoid_output = sigmoid_output # 是否对最后一层加 sigmoid
self.act = activation() # 实例化激活函数
def forward(self, x):
# x: torch.Size([1, 9, 256])
# 逐层前向:除最后一层外均接激活
for i, layer in enumerate(self.layers):
x = self.act(layer(x)) if i < self.num_layers - 1 else layer(x)
# i=0 x: torch.Size([1, 9, 2048]) # 第一层升维
# i=1 x: torch.Size([1, 9, 256]) # 第二层降回原维(残差分支用)
# self.sigmoid_output: False
if self.sigmoid_output:
x = F.sigmoid(x) # 若需要 0~1 范围则再套 sigmoid
# x: torch.Size([1, 9, 256])
return x
一个可复用的 MLP 积木,通常作为 Transformer 块里的 FFN(Feed-Forward Network)。
默认 2 层:先升维到 2048,再降回 256,配合残差连接,给模型增加非线性且保持通道维度一致。
sigmoid_output开关方便在需要概率输出(如 mask logits 后处理)时直接得到 0~1 值。