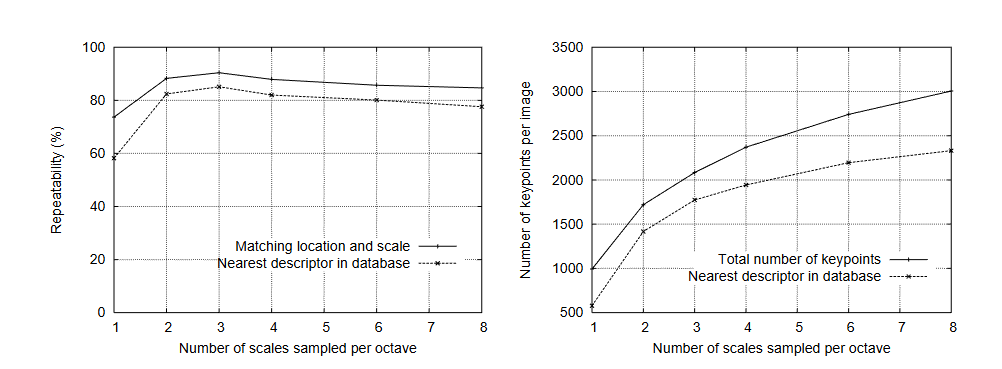
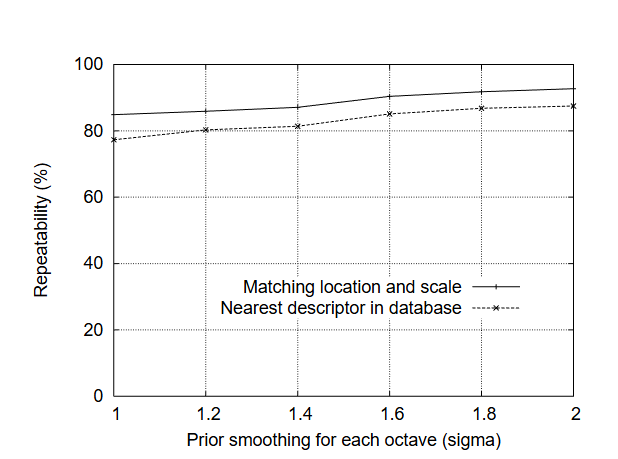
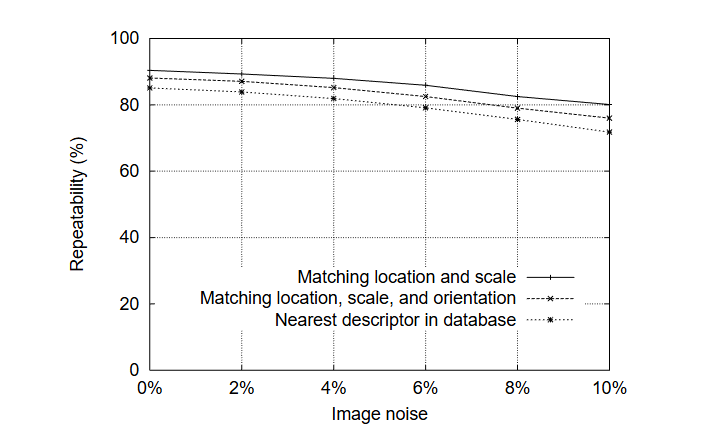
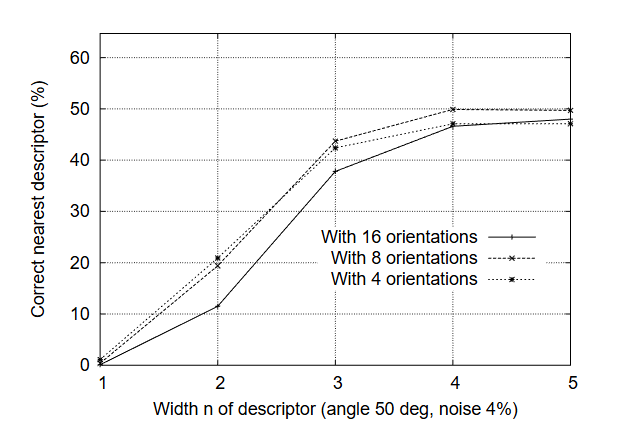
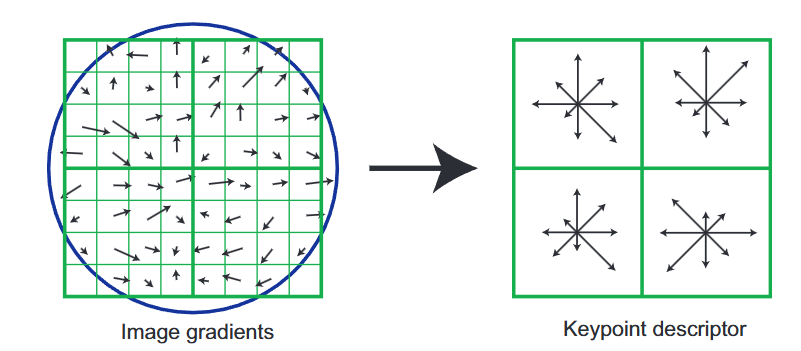
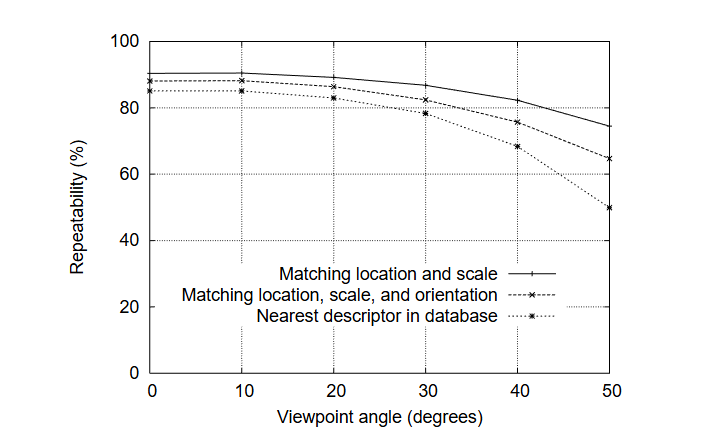
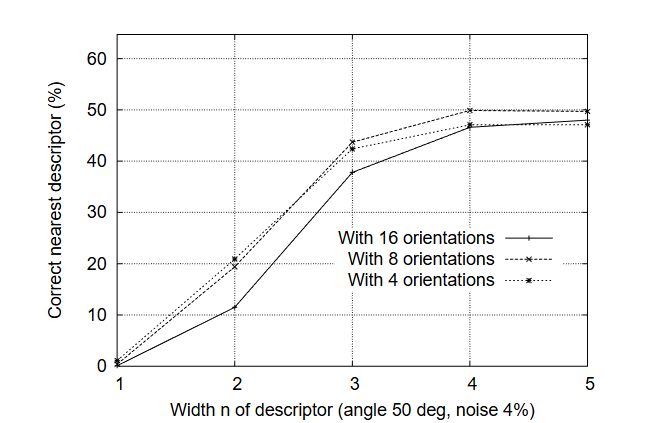
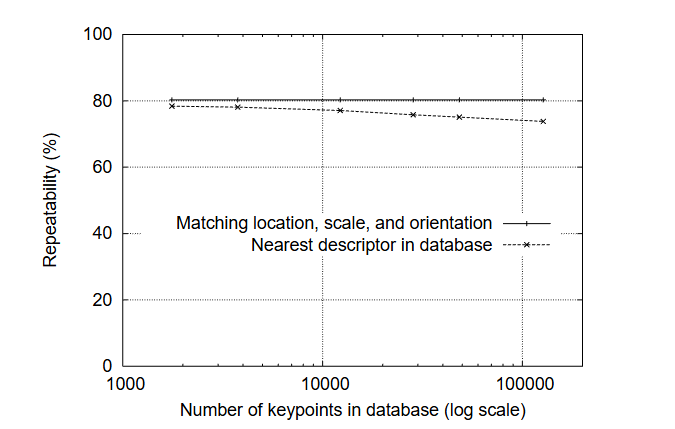
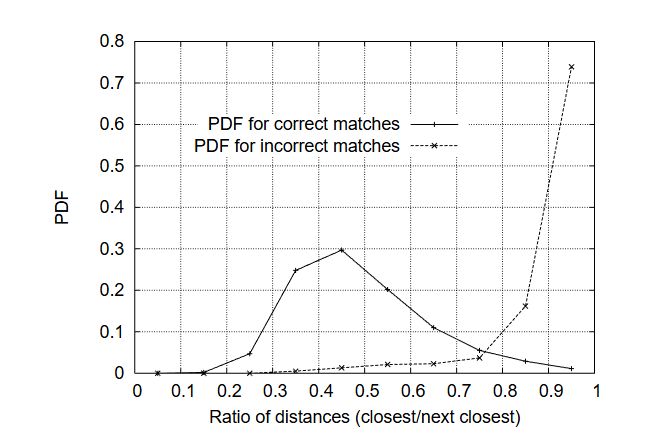
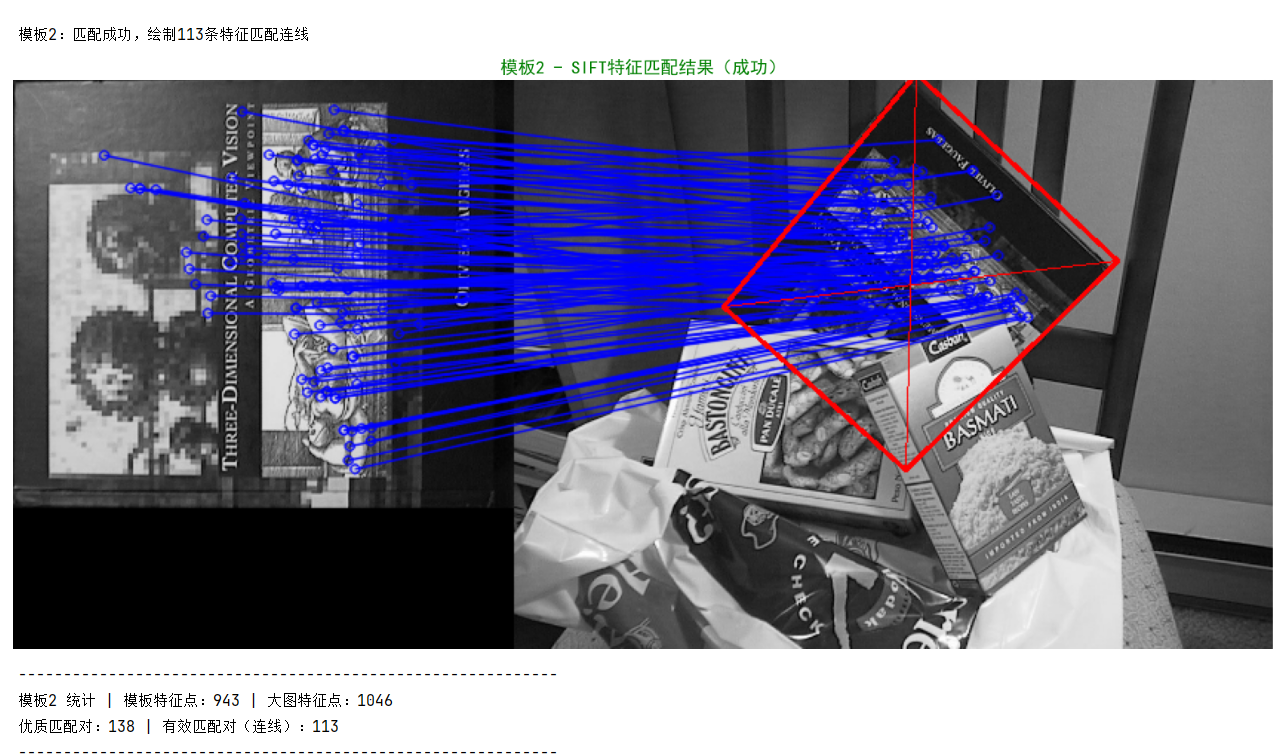
SIFT(Scale-Invariant Feature Transform,尺度不变特征变换)由加拿大教授David G. Lowe于1999年首次提出[1],对应论文为《Object recognition from local scale-invariant features》;并于2004年在《International Journal of Computer Vision》期刊发表完善版本[2],论文为《Distinctive image features from scale-invariant keypoints》。
SURF(Speeded Up Robust Features,加速稳健特征)由Herbert Bay等人于2006年在ECCV会议首次提出[3],对应论文为《Surf: Speeded up robust features》;并于2008年 发表扩展完整版[4],论文为《Speeded-up robust features (SURF)》。
对于一幅二维灰度图像 I ( x , y ) I(x,y) I(x,y),其在尺度 σ \sigma σ 下的尺度空间表示 L ( x , y , σ ) L(x,y,\sigma) L(x,y,σ) 数学定义为:
L ( x , y , σ ) = G ( x , y , σ ) ∗ I ( x , y ) L(x,y,\sigma) = G(x,y,\sigma) * I(x,y) L(x,y,σ)=G(x,y,σ)∗I(x,y)
其中各参数与符号的含义:
∗ * ∗:表示二维卷积运算(图像处理中,卷积用于实现核函数对图像的平滑、滤波等操作);
G ( x , y , σ ) G(x,y,\sigma) G(x,y,σ):二维高斯核函数 ,是尺度空间构建的核心,其数学表达式为:
G ( x , y , σ ) = 1 2 π σ 2 e − x 2 + y 2 2 σ 2 G(x,y,\sigma) = \frac{1}{2\pi\sigma^2} e^{-\frac{x^2 + y^2}{2\sigma^2}} G(x,y,σ)=2πσ21e−2σ2x2+y2
设图像 I ( x ) I(x) I(x)(一维简化,二维可直接推广)的尺度空间为 L ( x , σ ) L(x,\sigma) L(x,σ)( σ \sigma σ 为尺度参数),且尺度空间由线性算子 H ( x , σ ) H(x,\sigma) H(x,σ) 与图像卷积生成( L ( x , σ ) = H ( x , σ ) ∗ I ( x ) L(x,\sigma) = H(x,\sigma) * I(x) L(x,σ)=H(x,σ)∗I(x)),则该尺度空间需满足:
平移不变性 :若图像 I ( x ) I(x) I(x) 平移 a a a 得到 I ( x − a ) I(x-a) I(x−a),则其尺度空间也对应平移 a a a,即 L ( x − a , σ ) = H ( x , σ ) ∗ I ( x − a ) L(x-a,\sigma) = H(x,\sigma) * I(x-a) L(x−a,σ)=H(x,σ)∗I(x−a)。
尺度不变性(伸缩不变性) :若图像 I ( x ) I(x) I(x) 伸缩 s s s 得到 I ( x / s ) I(x/s) I(x/s),则其尺度空间满足 L ( x / s , σ ) = k ( s ) ⋅ L ( x , σ / s ) L(x/s,\sigma) = k(s) \cdot L(x, \sigma/s) L(x/s,σ)=k(s)⋅L(x,σ/s)( k ( s ) k(s) k(s) 为归一化常数)。
物理意义:先对图像用小尺度平滑,再用大尺度平滑,等价于直接用一个合并后的更大尺度平滑,确保尺度空间的连续性和单调性(尺度增大,图像平滑程度只增不减)。 步骤2:推导满足公理的线性算子 H ( x , σ ) H(x,\sigma) H(x,σ) 只能是高斯函数
由平移不变性 推导:满足平移不变性的线性卷积算子,在频域中对应「乘法运算」(卷积定理),且其傅里叶变换 H ^ ( k , σ ) \hat{H}(k,\sigma) H^(k,σ) 与位置 x x x 无关,仅与频率 k k k 和尺度 σ \sigma σ 有关,即 H ^ ( k , σ ) = H ^ ( ∣ k ∣ , σ ) \hat{H}(k,\sigma) = \hat{H}(|k|,\sigma) H^(k,σ)=H^(∣k∣,σ)(仅与频率幅值有关,具有旋转不变性,二维场景更易推广)。
由半群性质 推导:对算子 H ( x , σ ) H(x,\sigma) H(x,σ) 取傅里叶变换(利用卷积定理:卷积的傅里叶变换等于傅里叶变换的乘积),则半群性质可转化为频域表达式:
H ^ ( k , σ 2 ) ⋅ H ^ ( k , σ 1 ) = H ^ ( k , σ 1 2 + σ 2 2 ) \hat{H}(k,\sigma_2) \cdot \hat{H}(k,\sigma_1) = \hat{H}(k,\sqrt{\sigma_1^2 + \sigma_2^2}) H^(k,σ2)⋅H^(k,σ1)=H^(k,σ12+σ22 )
令 σ 1 = σ \sigma_1 = \sigma σ1=σ, σ 2 = d σ \sigma_2 = d\sigma σ2=dσ(微小尺度增量),且当 σ → 0 \sigma \to 0 σ→0 时, H ( x , 0 ) = δ ( x ) H(x,0) = \delta(x) H(x,0)=δ(x)( δ ( x ) \delta(x) δ(x) 为狄拉克函数,对应无平滑的原始图像),通过求解这个函数方程,可得 H ^ ( k , σ ) = e − c ⋅ k 2 ⋅ σ 2 \hat{H}(k,\sigma) = e^{-c \cdot k^2 \cdot \sigma^2} H^(k,σ)=e−c⋅k2⋅σ2( c c c 为正的常数,确保尺度增大时,频域高频成分被抑制,对应图像平滑)。
由逆傅里叶变换 还原空间域算子:对 H ^ ( k , σ ) = e − c ⋅ k 2 ⋅ σ 2 \hat{H}(k,\sigma) = e^{-c \cdot k^2 \cdot \sigma^2} H^(k,σ)=e−c⋅k2⋅σ2 进行逆傅里叶变换,可得空间域的算子形式:
H ( x , σ ) = 1 4 π c σ 2 e − x 2 4 c σ 2 H(x,\sigma) = \frac{1}{\sqrt{4\pi c \sigma^2}} e^{-\frac{x^2}{4c \sigma^2}} H(x,σ)=4πcσ2 1e−4cσ2x2
令 c = 1 / 4 c = 1/4 c=1/4(归一化处理,使高斯函数的积分值为1,保证平滑操作不改变图像的整体亮度),则该算子即为一维高斯函数 :
H ( x , σ ) = 1 2 π σ e − x 2 2 σ 2 H(x,\sigma) = \frac{1}{\sqrt{2\pi}\sigma} e^{-\frac{x^2}{2\sigma^2}} H(x,σ)=2π σ1e−2σ2x2
等比系数 k = 2 1 / s k = 2^{1/s} k=21/s(保证相邻层尺度的均匀递增)。
则第 o o o 个八度( o = 0 , 1 , 2 , . . . o=0,1,2,... o=0,1,2,...)、第 i i i 层( i = 0 , 1 , 2 , . . . , s i=0,1,2,...,s i=0,1,2,...,s)对应的尺度 σ ( o , i ) \sigma(o,i) σ(o,i) 计算公式为:
σ ( o , i ) = σ 0 × k i × 2 o \sigma(o,i) = \sigma_0 \times k^i \times 2^o σ(o,i)=σ0×ki×2o
示例计算( o = 0 , 1 o=0,1 o=0,1, i = 0 , 1 , 2 i=0,1,2 i=0,1,2):
则第 o o o 个八度( o = 0 , 1 , 2 , . . . o=0,1,2,... o=0,1,2,...)、第 i i i 层( i = 0 , 1 , 2 , . . . , s i=0,1,2,...,s i=0,1,2,...,s)对应的尺度 σ ( o , i ) \sigma(o,i) σ(o,i) 计算公式为:
σ ( o , i ) = σ 0 × k i × 2 o \sigma(o,i) = \sigma_0 \times k^i \times 2^o σ(o,i)=σ0×ki×2o
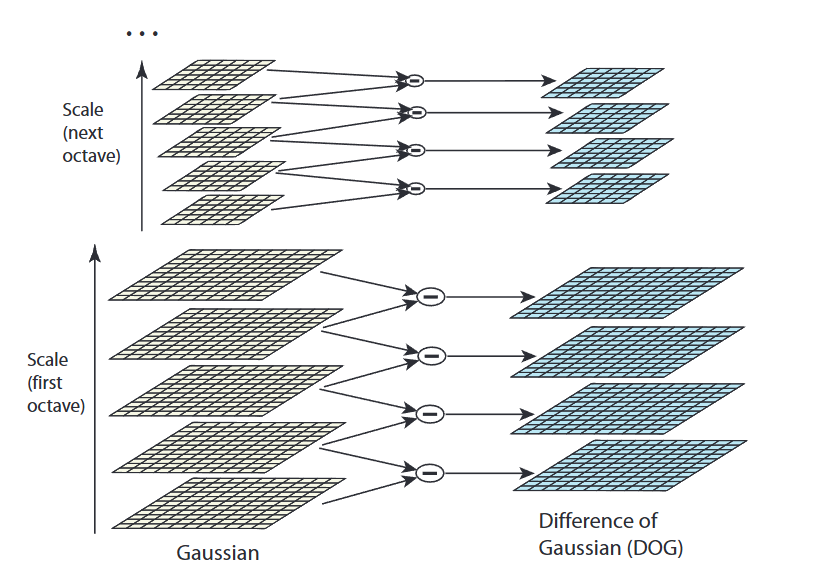
3. 特征候选点提取:高斯差分金字塔(DoG)
直接在高斯金字塔中寻找特征点计算量较大,SIFT通过高斯差分(Difference of Gaussians, DoG) 简化运算,DoG图像能有效突出图像中的极值点(即潜在特征点),且计算效率更高。
(1) DoG的数学定义
对于高斯金字塔中同一八度内的相邻两层图像 L ( x , y , σ i ) L(x,y,\sigma_{i}) L(x,y,σi) 和 L ( x , y , σ i + 1 ) L(x,y,\sigma_{i+1}) L(x,y,σi+1),其高斯差分图像 D ( x , y , σ i ) D(x,y,\sigma_i) D(x,y,σi) 定义为:
D ( x , y , σ i ) = L ( x , y , σ i + 1 ) − L ( x , y , σ i ) D(x,y,\sigma_i) = L(x,y,\sigma_{i+1}) - L(x,y,\sigma_i) D(x,y,σi)=L(x,y,σi+1)−L(x,y,σi)
补充说明:DoG是尺度归一化拉普拉斯算子( σ 2 ∇ 2 G \sigma^2\nabla^2G σ2∇2G) 的高效近似,拉普拉斯算子擅长检测图像极值点,但直接计算复杂度高,DoG通过简单的相邻层相减,在保证检测效果的同时大幅降低了计算成本。
数学推导
核心关联:热扩散方程
高斯核 G ( x , y , σ ) = 1 2 π σ 2 e − x 2 + y 2 2 σ 2 G(x,y,\sigma) = \frac{1}{2\pi\sigma^2}e^{-\frac{x^2+y^2}{2\sigma^2}} G(x,y,σ)=2πσ21e−2σ2x2+y2 满足热扩散方程,其尺度导数与拉普拉斯算子直接关联:
∂ G ∂ σ = σ ∇ 2 G \frac{\partial G}{\partial \sigma} = \sigma \nabla^2 G ∂σ∂G=σ∇2G
其中 ∇ 2 = ∂ 2 ∂ x 2 + ∂ 2 ∂ y 2 \nabla^2 = \frac{\partial^2}{\partial x^2} + \frac{\partial^2}{\partial y^2} ∇2=∂x2∂2+∂y2∂2 为二维拉普拉斯算子,该式表明:高斯核随尺度 σ \sigma σ 的变化率,与它的拉普拉斯变换成正比。
通俗解释 :
这个式子本质上就是高斯核函数对尺度参数 σ \sigma σ求偏导的结果
你可以这么理解:
高斯核 G ( x , y , σ ) G(x,y,\sigma) G(x,y,σ)是一个关于 x , y , σ x,y,\sigma x,y,σ的三元函数,我们固定 x , y x,y x,y,只让 σ \sigma σ变化,对 σ \sigma σ求偏导,就得到 ∂ G ∂ σ \frac{\partial G}{\partial \sigma} ∂σ∂G。
右边的 ∇ 2 G \nabla^2 G ∇2G是对 x , y x,y x,y求二阶偏导再相加(拉普拉斯算子),表示高斯核在空间上的"凹凸变化率"。
之所以叫"热扩散方程",是因为这个偏导关系和物理上"温度随时间的变化率与温度空间分布的凹凸率成正比"的规律完全一样,只是把"时间 t t t"换成了"尺度 σ \sigma σ"。
有限差分近似尺度导数
工程中无法直接计算连续的尺度导数 ∂ G ∂ σ \frac{\partial G}{\partial \sigma} ∂σ∂G,因此用两个邻近尺度 k σ k\sigma kσ 和 σ \sigma σ( k > 1 k>1 k>1 为固定尺度因子)的高斯核之差,做有限差分近似:
∂ G ∂ σ ≈ G ( x , y , k σ ) − G ( x , y , σ ) k σ − σ \frac{\partial G}{\partial \sigma} \approx \frac{G(x,y,k\sigma) - G(x,y,\sigma)}{k\sigma - \sigma} ∂σ∂G≈kσ−σG(x,y,kσ)−G(x,y,σ)
通俗解释 :
这个式子就是你学过的导数定义的近似应用
导数的极限定义是: f ′ ( x ) = lim Δ x → 0 f ( x + Δ x ) − f ( x ) Δ x f'(x) = \lim_{\Delta x \to 0} \frac{f(x+\Delta x) - f(x)}{\Delta x} f′(x)=limΔx→0Δxf(x+Δx)−f(x)。
在这里,我们把 G ( x , y , σ ) G(x,y,\sigma) G(x,y,σ) 看作关于 σ \sigma σ 的函数 f ( σ ) f(\sigma) f(σ),那么尺度导数 ∂ G ∂ σ \frac{\partial G}{\partial \sigma} ∂σ∂G 就是 f ′ ( σ ) f'(\sigma) f′(σ)。
推导DoG与尺度归一化拉普拉斯的等价性
将热扩散方程代入上述有限差分公式,两边同乘 σ ( k σ − σ ) \sigma(k\sigma - \sigma) σ(kσ−σ) 整理可得:
G ( x , y , k σ ) − G ( x , y , σ ) ≈ ( k − 1 ) σ 2 ∇ 2 G G(x,y,k\sigma) - G(x,y,\sigma) \approx (k-1)\sigma^2 \nabla^2 G G(x,y,kσ)−G(x,y,σ)≈(k−1)σ2∇2G
左侧 G ( x , y , k σ ) − G ( x , y , σ ) G(x,y,k\sigma) - G(x,y,\sigma) G(x,y,kσ)−G(x,y,σ) 即为DoG算子 ,右侧 σ 2 ∇ 2 G \sigma^2 \nabla^2 G σ2∇2G 为尺度归一化拉普拉斯算子 , ( k − 1 ) (k-1) (k−1) 为常数因子(不影响极值点的位置判断)。
通俗解释 :
这一步就是简单的代数代入+移项整理,没有任何高深技巧。
我们已经有两个式子:
热扩散方程: ∂ G ∂ σ = σ ∇ 2 G \displaystyle \frac{\partial G}{\partial \sigma} = \sigma \nabla^2 G ∂σ∂G=σ∇2G
有限差分近似: ∂ G ∂ σ ≈ G ( x , y , k σ ) − G ( x , y , σ ) k σ − σ \displaystyle \frac{\partial G}{\partial \sigma} \approx \frac{G(x,y,k\sigma) - G(x,y,\sigma)}{k\sigma - \sigma} ∂σ∂G≈kσ−σG(x,y,kσ)−G(x,y,σ)
把左边相等的东西"连等"起来:
σ ∇ 2 G ≈ G ( x , y , k σ ) − G ( x , y , σ ) k σ − σ \sigma \nabla^2 G \approx \frac{G(x,y,k\sigma) - G(x,y,\sigma)}{k\sigma - \sigma} σ∇2G≈kσ−σG(x,y,kσ)−G(x,y,σ)
两边同乘分母 ( k σ − σ ) (k\sigma - \sigma) (kσ−σ),移到左边:
G ( x , y , k σ ) − G ( x , y , σ ) ≈ σ ( k σ − σ ) ∇ 2 G G(x,y,k\sigma) - G(x,y,\sigma) \approx \sigma(k\sigma - \sigma) \nabla^2 G G(x,y,kσ)−G(x,y,σ)≈σ(kσ−σ)∇2G
最终就得到:
G ( x , y , k σ ) − G ( x , y , σ ) ≈ ( k − 1 ) σ 2 ∇ 2 G G(x,y,k\sigma) - G(x,y,\sigma) \approx (k-1)\sigma^2 \nabla^2 G G(x,y,kσ)−G(x,y,σ)≈(k−1)σ2∇2G
结论:DoG 就是 尺度归一化拉普拉斯 乘上一个常数,常数不影响找极值点,所以 DoG 可以代替它用。
关键结论
DoG算子是尺度归一化拉普拉斯算子的高效近似,既继承了 σ 2 ∇ 2 G \sigma^2 \nabla^2 G σ2∇2G 「检测稳定极值点、实现尺度不变性」的核心优势,又通过「图像相减」的简单操作,避免了直接计算二阶偏导数的高复杂度,更易工程实现。
补充说明
尺度归一化拉普拉斯算子 σ 2 ∇ 2 G \sigma^2 \nabla^2 G σ2∇2G 是实现真正尺度不变性的核心(Lindeberg, 1994),其极值点的稳定性优于梯度、Harris角点等其他特征检测算子。
公式中的尺度因子 k k k 对应高斯金字塔中的等比系数 k = 2 1 / s k=2^{1/s} k=21/s( s s s 为每个八度内的层数)。
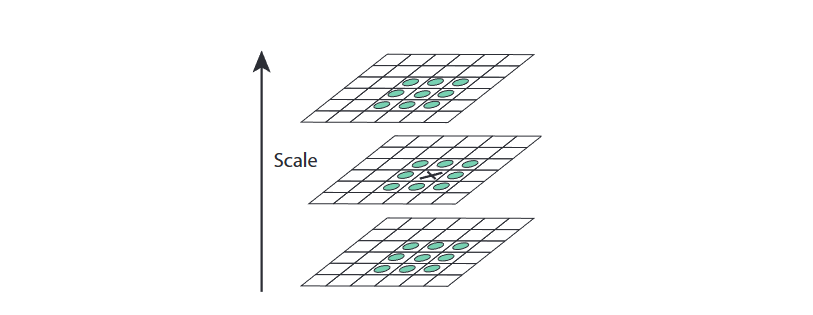
解释:DoG金字塔的特征候选点是基于图像像素网格筛选的离散坐标(如 ( i , j ) (i,j) (i,j)像素位置、第 k k k层尺度),但DoG函数 D ( x , y , σ ) D(x,y,\sigma) D(x,y,σ)是连续的尺度-空间函数,其真实极值点(最突出的特征点)可能位于两个像素的间隙(亚像素)或两个尺度层的中间(亚尺度),而非恰好落在离散采样点上。
把DoG函数 D ( x , y , σ ) D(x,y,\sigma) D(x,y,σ)在候选点处做3D二次泰勒展开( x , y x,y x,y是空间坐标, σ \sigma σ是尺度),相当于用平滑曲面拟合候选点周围的像素值。
解释:3D指函数包含 x x x(横向空间)、 y y y(纵向空间)、 σ \sigma σ(尺度)三个维度,二次泰勒展开是利用多元函数在某点的函数值、一阶梯度和二阶导数,构建一个局部连续的二次多项式曲面,该曲面能精准逼近候选点邻域内DoG函数的真实分布,将离散的像素响应值转化为连续的数学模型。
泰勒展开式(原点设为候选点):
D ( x ) = D + ∂ D ∂ x T x + 1 2 x T ∂ 2 D ∂ x 2 x D(\boldsymbol{x}) = D + \frac{\partial D}{\partial \boldsymbol{x}}^T \boldsymbol{x} + \frac{1}{2}\boldsymbol{x}^T \frac{\partial^2 D}{\partial \boldsymbol{x}^2} \boldsymbol{x} D(x)=D+∂x∂DTx+21xT∂x2∂2Dx
其中 x = ( x , y , σ ) T \boldsymbol{x}=(x,y,\sigma)^T x=(x,y,σ)T是候选点到真实极值点的偏移量, D D D及其导数均在候选点处计算。
详细推导过程(最终落地到当前泰勒展开式):
符号定义:设离散候选点为 ( x 0 , y 0 , σ 0 ) (x_0,y_0,\sigma_0) (x0,y0,σ0),真实极值点为 ( x 0 + x , y 0 + y , σ 0 + σ ) (x_0+x,y_0+y,\sigma_0+\sigma) (x0+x,y0+y,σ0+σ),定义偏移向量 x = ( x , y , σ ) T \boldsymbol{x}=(x,y,\sigma)^T x=(x,y,σ)T(3×1列向量, x , y x,y x,y为空间偏移, σ \sigma σ为尺度偏移, T ^T T表示转置以满足后续矩阵运算维度要求)。
展开依据:根据多元函数泰勒级数定理,连续光滑的DoG函数 D ( x , y , σ ) D(x,y,\sigma) D(x,y,σ)在候选点邻域内(偏移量 x \boldsymbol{x} x足够小),可忽略三次及以上高阶无穷小项,仅保留至二次项进行多项式逼近。
逐项构建展开式:
零阶项:候选点处的DoG函数值 D D D(已知量,无偏移时的函数值);
一阶项:一阶梯度向量与偏移向量的内积 ∂ D ∂ x T x \frac{\partial D}{\partial \boldsymbol{x}}^T \boldsymbol{x} ∂x∂DTx,其中 ∂ D ∂ x = ∂ D ∂ x , ∂ D ∂ y , ∂ D ∂ σ T \frac{\partial D}{\partial \boldsymbol{x}}=\left\\frac{\\partial D}{\\partial x},\\frac{\\partial D}{\\partial y},\\frac{\\partial D}{\\partial \\sigma}\\right^T ∂x∂D=∂x∂D,∂y∂D,∂σ∂DT(3×1列向量,由候选点处三个方向的一阶偏导数构成),转置后为1×3行向量,与3×1列向量 x \boldsymbol{x} x内积得到标量,表征线性函数变化量;
二阶项: 1 2 x T ∂ 2 D ∂ x 2 x \frac{1}{2}\boldsymbol{x}^T \frac{\partial^2 D}{\partial \boldsymbol{x}^2} \boldsymbol{x} 21xT∂x2∂2Dx,其中 ∂ 2 D ∂ x 2 \frac{\partial^2 D}{\partial \boldsymbol{x}^2} ∂x2∂2D为3×3对称海森矩阵(由候选点处的二阶偏导数与混合偏导数构成),偏移向量转置后(1×3)依次乘海森矩阵(3×3)、偏移向量(3×1),得到标量,表征二次曲率修正量,前置系数 1 2 \frac{1}{2} 21为泰勒展开的固有系数;
整合落地:将零阶项、一阶项、二阶项整合,最终得到当前泰勒展开式 D ( x ) = D + ∂ D ∂ x T x + 1 2 x T ∂ 2 D ∂ x 2 x D(\boldsymbol{x}) = D + \frac{\partial D}{\partial \boldsymbol{x}}^T \boldsymbol{x} + \frac{1}{2}\boldsymbol{x}^T \frac{\partial^2 D}{\partial \boldsymbol{x}^2} \boldsymbol{x} D(x)=D+∂x∂DTx+21xT∂x2∂2Dx。
对 x \boldsymbol{x} x求导并令导数为0,解得真实极值点的偏移量:
x ^ = − ( ∂ 2 D ∂ x 2 ) − 1 ∂ D ∂ x \hat{\boldsymbol{x}} = -\left( \frac{\partial^2 D}{\partial \boldsymbol{x}^2} \right)^{-1} \frac{\partial D}{\partial \boldsymbol{x}} x^=−(∂x2∂2D)−1∂x∂D
详细推导过程(最终落地到当前偏移量公式):
极值点求导条件:连续函数的极值点满足"一阶梯度为0",因此对上述泰勒展开式 D ( x ) D(\boldsymbol{x}) D(x)关于偏移向量 x \boldsymbol{x} x求偏导。
逐项求导运算(基于矩阵求导基本法则,最终得到导函数表达式):
零阶项 D D D:不含变量 x \boldsymbol{x} x,求导结果为3×1零向量;
一阶项 ∂ D ∂ x T x \frac{\partial D}{\partial \boldsymbol{x}}^T \boldsymbol{x} ∂x∂DTx:求导结果为一阶梯度向量 ∂ D ∂ x \frac{\partial D}{\partial \boldsymbol{x}} ∂x∂D(3×1列向量);
二阶项 1 2 x T ∂ 2 D ∂ x 2 x \frac{1}{2}\boldsymbol{x}^T \frac{\partial^2 D}{\partial \boldsymbol{x}^2} \boldsymbol{x} 21xT∂x2∂2Dx:求导结果为 ∂ 2 D ∂ x 2 x \frac{\partial^2 D}{\partial \boldsymbol{x}^2} \boldsymbol{x} ∂x2∂2Dx(3×1列向量);
整合导函数: ∂ D ( x ) ∂ x = ∂ D ∂ x + ∂ 2 D ∂ x 2 x \frac{\partial D(\boldsymbol{x})}{\partial \boldsymbol{x}} = \frac{\partial D}{\partial \boldsymbol{x}} + \frac{\partial^2 D}{\partial \boldsymbol{x}^2} \boldsymbol{x} ∂x∂D(x)=∂x∂D+∂x2∂2Dx。
令导数为0,构建线性方程组: ∂ D ∂ x + ∂ 2 D ∂ x 2 x = 0 \frac{\partial D}{\partial \boldsymbol{x}} + \frac{\partial^2 D}{\partial \boldsymbol{x}^2} \boldsymbol{x} = 0 ∂x∂D+∂x2∂2Dx=0。
求解线性方程组,落地到偏移量公式:
移项整理:将已知量移至等式右侧,得到 ∂ 2 D ∂ x 2 x = − ∂ D ∂ x \frac{\partial^2 D}{\partial \boldsymbol{x}^2} \boldsymbol{x} = -\frac{\partial D}{\partial \boldsymbol{x}} ∂x2∂2Dx=−∂x∂D;
逆矩阵消元:由于DoG函数在局部满足凸性/凹性,海森矩阵 ∂ 2 D ∂ x 2 \frac{\partial^2 D}{\partial \boldsymbol{x}^2} ∂x2∂2D非奇异(行列式不为0),存在唯一逆矩阵 ( ∂ 2 D ∂ x 2 ) − 1 \left( \frac{\partial^2 D}{\partial \boldsymbol{x}^2} \right)^{-1} (∂x2∂2D)−1;
等式两边左乘逆矩阵: ( ∂ 2 D ∂ x 2 ) − 1 ⋅ ∂ 2 D ∂ x 2 x = ( ∂ 2 D ∂ x 2 ) − 1 ⋅ ( − ∂ D ∂ x ) \left( \frac{\partial^2 D}{\partial \boldsymbol{x}^2} \right)^{-1} \cdot \frac{\partial^2 D}{\partial \boldsymbol{x}^2} \boldsymbol{x} = \left( \frac{\partial^2 D}{\partial \boldsymbol{x}^2} \right)^{-1} \cdot (-\frac{\partial D}{\partial \boldsymbol{x}}) (∂x2∂2D)−1⋅∂x2∂2Dx=(∂x2∂2D)−1⋅(−∂x∂D);
化简落地:利用矩阵逆的性质( A − 1 ⋅ A = I A^{-1} \cdot A = I A−1⋅A=I,单位矩阵 I I I与向量相乘结果为原向量),左侧化简为 x \boldsymbol{x} x,最终得到真实极值点的偏移量公式 x ^ = − ( ∂ 2 D ∂ x 2 ) − 1 ∂ D ∂ x \hat{\boldsymbol{x}} = -\left( \frac{\partial^2 D}{\partial \boldsymbol{x}^2} \right)^{-1} \frac{\partial D}{\partial \boldsymbol{x}} x^=−(∂x2∂2D)−1∂x∂D。
将 x ^ \hat{\boldsymbol{x}} x^代入展开式,得到真实极值点的对比度:
D ( x ^ ) = D + 1 2 ∂ D T ∂ x x ^ D(\hat{\boldsymbol{x}}) = D + \frac{1}{2}\frac{\partial D^T}{\partial \boldsymbol{x}} \hat{\boldsymbol{x}} D(x^)=D+21∂x∂DTx^
详细推导过程(最终落地到当前对比度公式):
代入准备: x ^ \hat{\boldsymbol{x}} x^是已求解的真实极值点偏移量,满足极值点条件 ∂ D ∂ x + ∂ 2 D ∂ x 2 x ^ = 0 \frac{\partial D}{\partial \boldsymbol{x}} + \frac{\partial^2 D}{\partial \boldsymbol{x}^2} \hat{\boldsymbol{x}} = 0 ∂x∂D+∂x2∂2Dx^=0,整理可得 ∂ 2 D ∂ x 2 x ^ = − ∂ D ∂ x \frac{\partial^2 D}{\partial \boldsymbol{x}^2} \hat{\boldsymbol{x}} = -\frac{\partial D}{\partial \boldsymbol{x}} ∂x2∂2Dx^=−∂x∂D(后续化简用)。
代入泰勒展开式:将 x = x ^ \boldsymbol{x} = \hat{\boldsymbol{x}} x=x^代入原始泰勒展开式,得到 D ( x ^ ) = D + ∂ D ∂ x T x ^ + 1 2 x ^ T ∂ 2 D ∂ x 2 x ^ D(\hat{\boldsymbol{x}}) = D + \frac{\partial D}{\partial \boldsymbol{x}}^T \hat{\boldsymbol{x}} + \frac{1}{2}\hat{\boldsymbol{x}}^T \frac{\partial^2 D}{\partial \boldsymbol{x}^2} \hat{\boldsymbol{x}} D(x^)=D+∂x∂DTx^+21x^T∂x2∂2Dx^。
代入条件化简:将 ∂ 2 D ∂ x 2 x ^ = − ∂ D ∂ x \frac{\partial^2 D}{\partial \boldsymbol{x}^2} \hat{\boldsymbol{x}} = -\frac{\partial D}{\partial \boldsymbol{x}} ∂x2∂2Dx^=−∂x∂D代入上式第二项后的部分:
替换二阶项中的海森矩阵与偏移向量乘积: x ^ T ∂ 2 D ∂ x 2 x ^ = x ^ T ⋅ ( − ∂ D ∂ x ) \hat{\boldsymbol{x}}^T \frac{\partial^2 D}{\partial \boldsymbol{x}^2} \hat{\boldsymbol{x}} = \hat{\boldsymbol{x}}^T \cdot (-\frac{\partial D}{\partial \boldsymbol{x}}) x^T∂x2∂2Dx^=x^T⋅(−∂x∂D);
标量等价性: ∂ D ∂ x T x ^ \frac{\partial D}{\partial \boldsymbol{x}}^T \hat{\boldsymbol{x}} ∂x∂DTx^与 x ^ T ∂ D ∂ x \hat{\boldsymbol{x}}^T \frac{\partial D}{\partial \boldsymbol{x}} x^T∂x∂D均为标量,二者数值相等,因此 x ^ T ⋅ ( − ∂ D ∂ x ) = − ∂ D ∂ x T x ^ \hat{\boldsymbol{x}}^T \cdot (-\frac{\partial D}{\partial \boldsymbol{x}}) = -\frac{\partial D}{\partial \boldsymbol{x}}^T \hat{\boldsymbol{x}} x^T⋅(−∂x∂D)=−∂x∂DTx^;
合并项化简:将替换结果代入原式,得到 ∂ D ∂ x T x ^ + 1 2 ⋅ ( − ∂ D ∂ x T x ^ ) = 1 2 ∂ D ∂ x T x ^ \frac{\partial D}{\partial \boldsymbol{x}}^T \hat{\boldsymbol{x}} + \frac{1}{2} \cdot (-\frac{\partial D}{\partial \boldsymbol{x}}^T \hat{\boldsymbol{x}}) = \frac{1}{2}\frac{\partial D}{\partial \boldsymbol{x}}^T \hat{\boldsymbol{x}} ∂x∂DTx^+21⋅(−∂x∂DTx^)=21∂x∂DTx^;
整合落地:将化简后的项代入原式,消去复杂的二阶项,最终得到真实极值点的对比度公式 D ( x ^ ) = D + 1 2 ∂ D T ∂ x x ^ D(\hat{\boldsymbol{x}}) = D + \frac{1}{2}\frac{\partial D^T}{\partial \boldsymbol{x}} \hat{\boldsymbol{x}} D(x^)=D+21∂x∂DTx^。
(3)筛选规则与工程实现
对比度阈值:若 ∣ D ( x ^ ) ∣ < 0.03 |D(\hat{\boldsymbol{x}})| < 0.03 ∣D(x^)∣<0.03(像素值范围 0 , 1 0,10,1),判定为弱特征点,直接剔除。
偏移量修正:若 x ^ \hat{\boldsymbol{x}} x^某一维绝对值大于0.5,说明真实极值点更靠近相邻像素,切换到相邻像素重新拟合。
导数计算:DoG函数的一、二阶导数(梯度、海森矩阵)通过相邻像素差值近似计算,计算成本低。
(4)实验效果
初始832个候选点 图( b ) 经对比度筛选后,剩余729个 图( c ),剔除了12%的弱特征点,保留的特征点抗噪声能力更强。
The derivatives are estimated by taking differences of neighboring sample points.
解释:DoG函数的一、二阶导数(如 D x x 、 D x y D_{xx}、D_{xy} Dxx、Dxy),是通过"相邻采样点的差值"来近似计算的,计算成本低且易于工程实现。
海森矩阵定义( D x x D_{xx} Dxx表示 D D D对 x x x的二阶偏导,其余同理):
H = D x x D x y D x y D y y H = \begin{bmatrix} D_{xx} & D_{xy} \\ D_{xy} & D_{yy} \end{bmatrix} H=DxxDxyDxyDyy
主曲率与特征值(论文原文):
The eigenvalues of H \mathbf{H} H are proportional to the principal curvatures of D D D.
解释:海森矩阵 H \mathbf{H} H的特征值,与DoG函数 D D D在该点的主曲率成正比。设 α \alpha α为"模最大的特征值", β \beta β为"较小的特征值",则 α \alpha α对应"最陡方向的主曲率", β \beta β对应"最平缓方向的主曲率"。
我们可以避免显式计算特征值------因为我们只关心特征值的比值。设 α \alpha α为模最大的特征值, β \beta β为较小的特征值,则可以通过 H \mathbf{H} H的迹得到特征值的和,通过行列式得到特征值的积:
Tr ( H ) = D x x + D y y = α + β , \text{Tr}(\mathbf{H}) = D_{xx} + D_{yy} = \alpha + \beta, Tr(H)=Dxx+Dyy=α+β,
Det ( H ) = D x x D y y − ( D x y ) 2 = α β . \text{Det}(\mathbf{H}) = D_{xx}D_{yy} - (D_{xy})^2 = \alpha\beta. Det(H)=DxxDyy−(Dxy)2=αβ.
比值判断规则:
定义主曲率比值 r = α / β r = \alpha/\beta r=α/β(论文默认 r = 10 r=10 r=10),若满足:
Tr ( H ) 2 Det ( H ) ≤ ( r + 1 ) 2 r \frac{\text{Tr}(\mathbf{H})^2}{\text{Det}(\mathbf{H})} \leq \frac{(r+1)^2}{r} Det(H)Tr(H)2≤r(r+1)2
则保留该点;否则(比值>10,说明是边缘点)剔除。
(3)特殊情况处理
若海森矩阵的行列式 D e t ( H ) < 0 Det(H) < 0 Det(H)<0,说明两个主曲率符号相反,该点不是真正的极值点,直接剔除。
详细解释:
行列式 D e t ( H ) = α β Det(H)=\alpha\beta Det(H)=αβ,若 D e t ( H ) < 0 Det(H)<0 Det(H)<0,说明 α \alpha α和 β \beta β一正一负------这意味着函数在该点"一个方向是上坡,另一个方向是下坡",是鞍点(不是极大值/极小值点),不符合"极值点"的定义,因此直接剔除。
对于邻域内的每个像素 ( x , y ) (x,y) (x,y),其梯度的幅值 m ( x , y ) m(x,y) m(x,y)和方向 θ ( x , y ) \theta(x,y) θ(x,y)计算如下:
m ( x , y ) = ( D ( x + 1 , y ) − D ( x − 1 , y ) ) 2 + ( D ( x , y + 1 ) − D ( x , y − 1 ) ) 2 , m(x,y) = \sqrt{\left( D(x+1,y) - D(x-1,y) \right)^2 + \left( D(x,y+1) - D(x,y-1) \right)^2}, m(x,y)=(D(x+1,y)−D(x−1,y))2+(D(x,y+1)−D(x,y−1))2 ,
θ ( x , y ) = arctan ( D ( x , y + 1 ) − D ( x , y − 1 ) D ( x + 1 , y ) − D ( x − 1 , y ) ) . \theta(x,y) = \arctan\left( \frac{D(x,y+1) - D(x,y-1)}{D(x+1,y) - D(x-1,y)} \right). θ(x,y)=arctan(D(x+1,y)−D(x−1,y)D(x,y+1)−D(x,y−1)).
详细解释:
梯度的 x x x分量: D x = D ( x + 1 , y ) − D ( x − 1 , y ) D_x = D(x+1,y) - D(x-1,y) Dx=D(x+1,y)−D(x−1,y)(水平方向相邻像素的DoG值差值,描述水平方向的亮度变化);
梯度的 y y y分量: D y = D ( x , y + 1 ) − D ( x , y − 1 ) D_y = D(x,y+1) - D(x,y-1) Dy=D(x,y+1)−D(x,y−1)(垂直方向相邻像素的DoG值差值,描述垂直方向的亮度变化);
幅值 m ( x , y ) m(x,y) m(x,y):是 D x D_x Dx和 D y D_y Dy的几何模长,代表"亮度变化的强弱";
方向 θ ( x , y ) \theta(x,y) θ(x,y):是梯度向量与 x x x轴的夹角,范围为 0 ∘ ∼ 360 ∘ 0^\circ \sim 360^\circ 0∘∼360∘,代表"亮度变化的方向"。
(3)梯度的加权统计
为了让靠近特征点的像素对方向的影响更大 ,需要对梯度幅值进行高斯加权 (用高斯函数给邻域内的梯度幅值分配权重):
w ( x , y ) = exp ( − ( x − x 0 ) 2 + ( y − y 0 ) 2 2 ( 1.5 σ ) 2 ) , w(x,y) = \exp\left( -\frac{(x-x_0)^2 + (y-y_0)^2}{2(1.5\sigma)^2} \right), w(x,y)=exp(−2(1.5σ)2(x−x0)2+(y−y0)2),
其中 ( x 0 , y 0 ) (x_0,y_0) (x0,y0)是特征点坐标, σ \sigma σ是特征点所在尺度层的尺度参数。
L2归一化(全局光照不变) :对128维向量做L2归一化,公式为:
d i ′ = d i ∑ j = 1 128 d j 2 \mathbf{d}'_i = \frac{\mathbf{d}i}{\sqrt{\sum{j=1}^{128} \mathbf{d}_j^2}} di′=∑j=1128dj2 di
作用:消除"全局亮度缩放"(如像素值整体×2)的影响------因为梯度幅值会随亮度缩放同步变化,归一化后可抵消该变化;同时,"全局亮度偏移"(如像素值整体+5)不影响梯度,天然具备不变性。
距离度量 :用"欧氏距离"计算待匹配图像特征 d n e w \mathbf{d}{new} dnew与数据库特征 d d b \mathbf{d}{db} ddb的相似度,距离越小,相似度越高。
比值筛选 :对 d n e w \mathbf{d}{new} dnew,找到数据库中"最近邻" d 1 \mathbf{d}{1} d1(距离最小)和"次近邻" d 2 \mathbf{d}{2} d2(距离第二小),若满足:
dist ( d n e w , d 1 ) dist ( d n e w , d 2 ) < 0.8 \frac{\text{dist}(\mathbf{d}{new}, \mathbf{d}{1})}{\text{dist}(\mathbf{d}{new}, \mathbf{d}{2})} < 0.8 dist(dnew,d2)dist(dnew,d1)<0.8
则保留 d n e w − d 1 \mathbf{d}{new}-\mathbf{d}_{1} dnew−d1为候选匹配;否则剔除(视为无正确匹配)。
对每个聚类,用3个及以上匹配点拟合affine变换矩阵(描述图像间的投影关系),公式为: x y 0 0 1 0 0 0 x y 0 1 . . . m 1 m 2 m 3 m 4 t x t y = u v ⋮ \left\\begin{array}{cccccc} x \& y \& 0 \& 0 \& 1 \& 0 \\\\ 0 \& 0 \& x \& y \& 0 \& 1 \\\\ \& \& ... \& \& \& \\end{array}\\right\left\\begin{array}{c} m_{1} \\\\ m_{2} \\\\ m_{3} \\\\ m_{4} \\\\ t_{x} \\\\ t_{y} \\end{array}\\right=\left\\begin{array}{c} u \\\\ v \\\\ \\vdots \\end{array}\\right x0y00x...0y1001 m1m2m3m4txty = uv⋮
其中 ( x , y ) (x,y) (x,y)为模型点坐标, ( u , v ) (u,v) (u,v)为图像点坐标, m 1 − m 4 m_1-m_4 m1−m4表征旋转/缩放/拉伸, t x , t y t_x,t_y tx,ty表征平移;
最小二乘解为: x = A T A − 1 A T b x=\leftA\^{T} A\\right^{-1} A^{T} b x=ATA−1ATb,剔除误差超阈值的outliers,迭代优化后,若剩余匹配点≥3,且"目标存在概率>98%",则确认匹配有效。
Left: Test image containing a train partially occluded by clutter. Right: The train is recognized by finding a consistent cluster of 5 matches (small squares) and fitting an affine transformation (parallelogram).
Top left: Training images of locations. Top right: Test image taken from a different viewpoint. Bottom: Recognized regions with keypoints (squares) and affine-transformed training image boundaries (parallelograms).
定义 :积分图像中任意像素点 I ∑ ( x , y ) I_{\sum}(x,y) I∑(x,y) 的值,等于原图像中以原点 ( 0 , 0 ) (0,0) (0,0) 和 ( x , y ) (x,y) (x,y) 为对角顶点的矩形区域内所有像素的和,公式为:
I ∑ ( x , y ) = ∑ i = 0 x ∑ j = 0 y I ( i , j ) I_{\sum}(x,y)=\sum_{i=0}^{x} \sum_{j=0}^{y} I(i,j) I∑(x,y)=i=0∑xj=0∑yI(i,j)
Hessian 矩阵定义 :对于图像 I I I 中任意点 ( x , y ) (x,y) (x,y),尺度 σ \sigma σ 下的 Hessian 矩阵为:
H ( x , σ ) = L x x ( x , σ ) L x y ( x , σ ) L x y ( x , σ ) L y y ( x , σ ) \mathcal{H}(x,\sigma)=\begin{bmatrix} L_{xx}(x,\sigma) & L_{xy}(x,\sigma) \\ L_{xy}(x,\sigma) & L_{yy}(x,\sigma) \end{bmatrix} H(x,σ)=Lxx(x,σ)Lxy(x,σ)Lxy(x,σ)Lyy(x,σ)
其中 L x x L_{xx} Lxx、 L x y L_{xy} Lxy、 L y y L_{yy} Lyy 分别是原图像与高斯二阶导数 ∂ 2 g ( σ ) ∂ x 2 \frac{\partial^2 g(\sigma)}{\partial x^2} ∂x2∂2g(σ)、 ∂ 2 g ( σ ) ∂ x ∂ y \frac{\partial^2 g(\sigma)}{\partial x\partial y} ∂x∂y∂2g(σ)、 ∂ 2 g ( σ ) ∂ y 2 \frac{\partial^2 g(\sigma)}{\partial y^2} ∂y2∂2g(σ) 的卷积结果。
关键近似 :用盒式滤波器 (Box Filters)替代高斯二阶导数,结合积分图像实现快速卷积。盒式滤波器的响应记为 D x x D_{xx} Dxx、 D y y D_{yy} Dyy、 D x y D_{xy} Dxy,则 Hessian 矩阵行列式的近似公式为:
d e t ( H a p p r o x ) = D x x ⋅ D y y − ( w ⋅ D x y ) 2 det(\mathcal{H}{approx})=D{xx} \cdot D_{yy} - (w \cdot D_{xy})^2 det(Happrox)=Dxx⋅Dyy−(w⋅Dxy)2
其中权重 w ≈ 0.9 w\approx0.9 w≈0.9(通过弗罗贝尼乌斯范数平衡能量守恒),计算式为:
w = ∣ L x y ( 1.2 ) ∣ F ⋅ ∣ D y y ( 9 ) ∣ F ∣ L y y ( 1.2 ) ∣ F ⋅ ∣ D x y ( 9 ) ∣ F = 0.912 ... ≃ 0.9 w=\frac{|L_{xy}(1.2)|F \cdot |D{yy}(9)|F}{|L{yy}(1.2)|F \cdot |D{xy}(9)|_F}=0.912\ldots\simeq0.9 w=∣Lyy(1.2)∣F⋅∣Dxy(9)∣F∣Lxy(1.2)∣F⋅∣Dyy(9)∣F=0.912...≃0.9
1 Lowe D G. Object recognition from local scale-invariant featuresC//Proceedings of the seventh IEEE international conference on computer vision. Ieee, 1999, 2: 1150-1157.
2 Lowe D G. Distinctive image features from scale-invariant keypointsJ. International journal of computer vision, 2004, 60(2): 91-110.
3 Bay H, Tuytelaars T, Van Gool L. Surf: Speeded up robust featuresC//European conference on computer vision. Berlin, Heidelberg: Springer Berlin Heidelberg, 2006: 404-417.
4 Bay H, Ess A, Tuytelaars T, et al. Speeded-up robust features (SURF)J. Computer vision and image understanding, 2008, 110(3): 346-359.