目录
乱码问题产生的根本原因
编码
编码:将人类可读的字符,按照指定字符集规则转换为二进制数据(如:UTF-8 下 "中"→0xE4B8AD)
解码
将二进制数据,按照相同字符集规则还原为字符(如:0xE4B8AD→UTF-8→"中")。
原因
- 数据的编码和解码使用的不是同一个字符集
例如:当我们把字符通过utf-8进行编码(字符->1010,编码过程),再用GBK进行解码成字符的时候就会乱码
写入文件时用 UTF-8 编码,读取时用 GBK 解码;或文件本身编码与编辑器打开编码不一致
如:用记事本以 ANSI(GBK)保存的文件,用 VS Code 以 UTF-8 打开会乱码
- 使用了不支持某个语言文字的字符集
例如,一些ISO系列的字符集就没有记录中文字符和1010的关系,若使用该系列字符集进行中文字符的处理,就一定出现乱码
单字节字符集(如 ASCII、ISO-8859-1):仅支持英文字符、部分符号,无中文、日文等多字节字符的映射;
区域性字符集(如 GBK、Big5):仅支持特定区域的字符(GBK 支持中文,Big5 支持繁体中文,Shift_JIS 支持日文);
通用字符集(如 UTF-8、UTF-16):支持全球几乎所有字符(基于 Unicode 字符库)。
各个字符集的兼容性
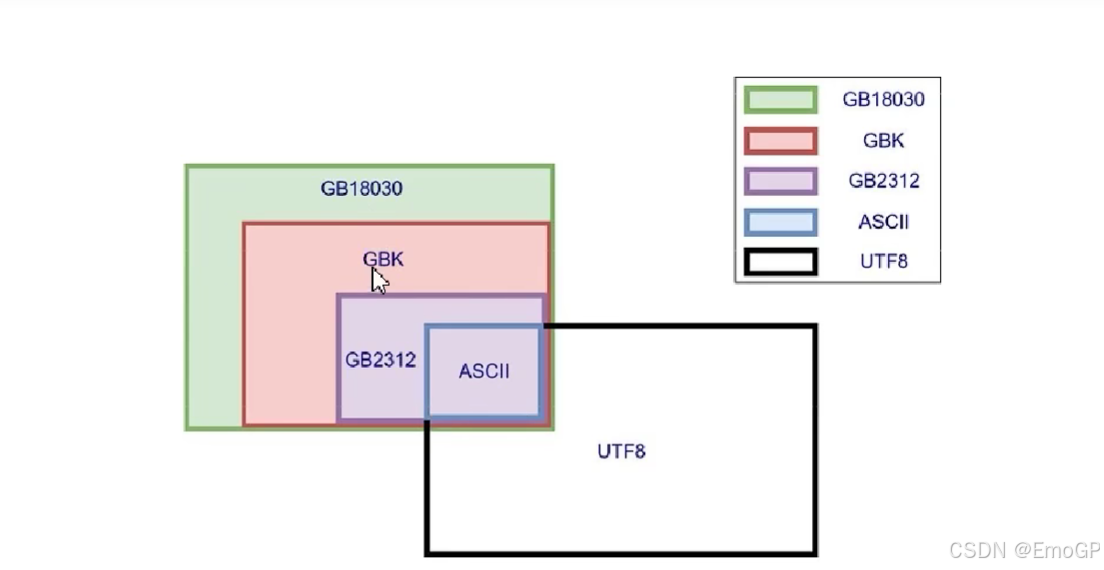
由上图得知,上述字符集都兼容了ASCII
ASCII中有什么?英文字母和一些通常使用的符号,所以这些东西无论使用什么字符集都不会乱码
HTML乱码问题
设置项目文件的字符集要使用一个支持中文的字符集
有如下html文件,右下角表示编码方式是utf-8
告诉浏览器用utf-8进行解码
<meta charset="UTF-8">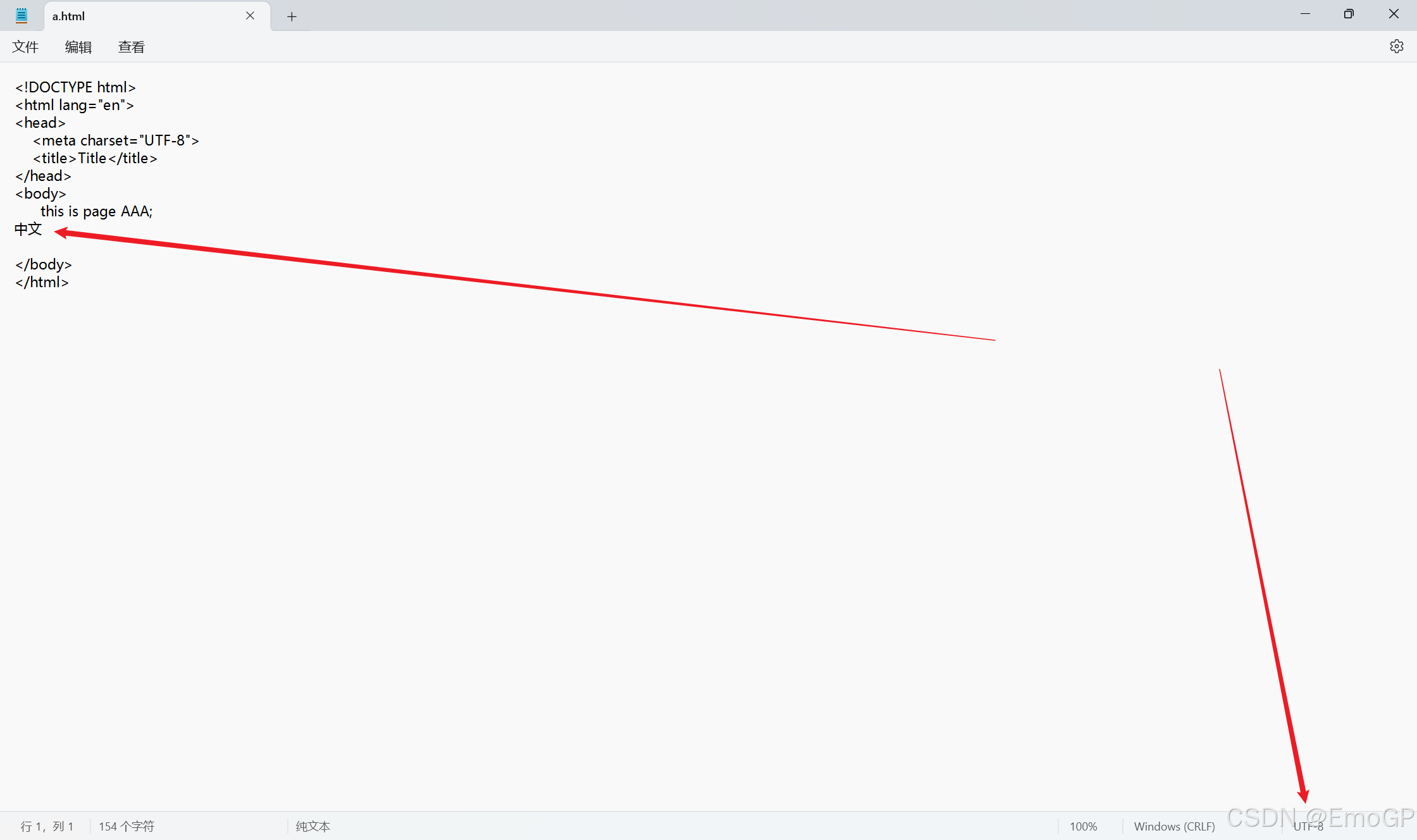
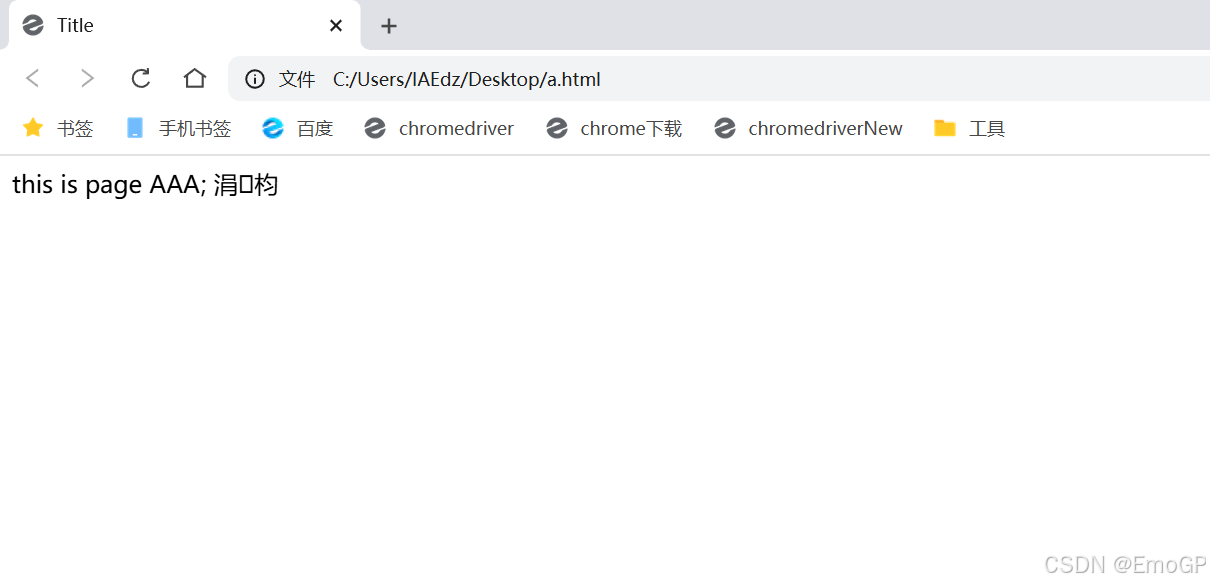
如果将meta charset改为GBK
用浏览器打开就会乱码
IDEA中比较智能
charset发生改变的时候,保存文件,会自动改变字符集
修改字符集
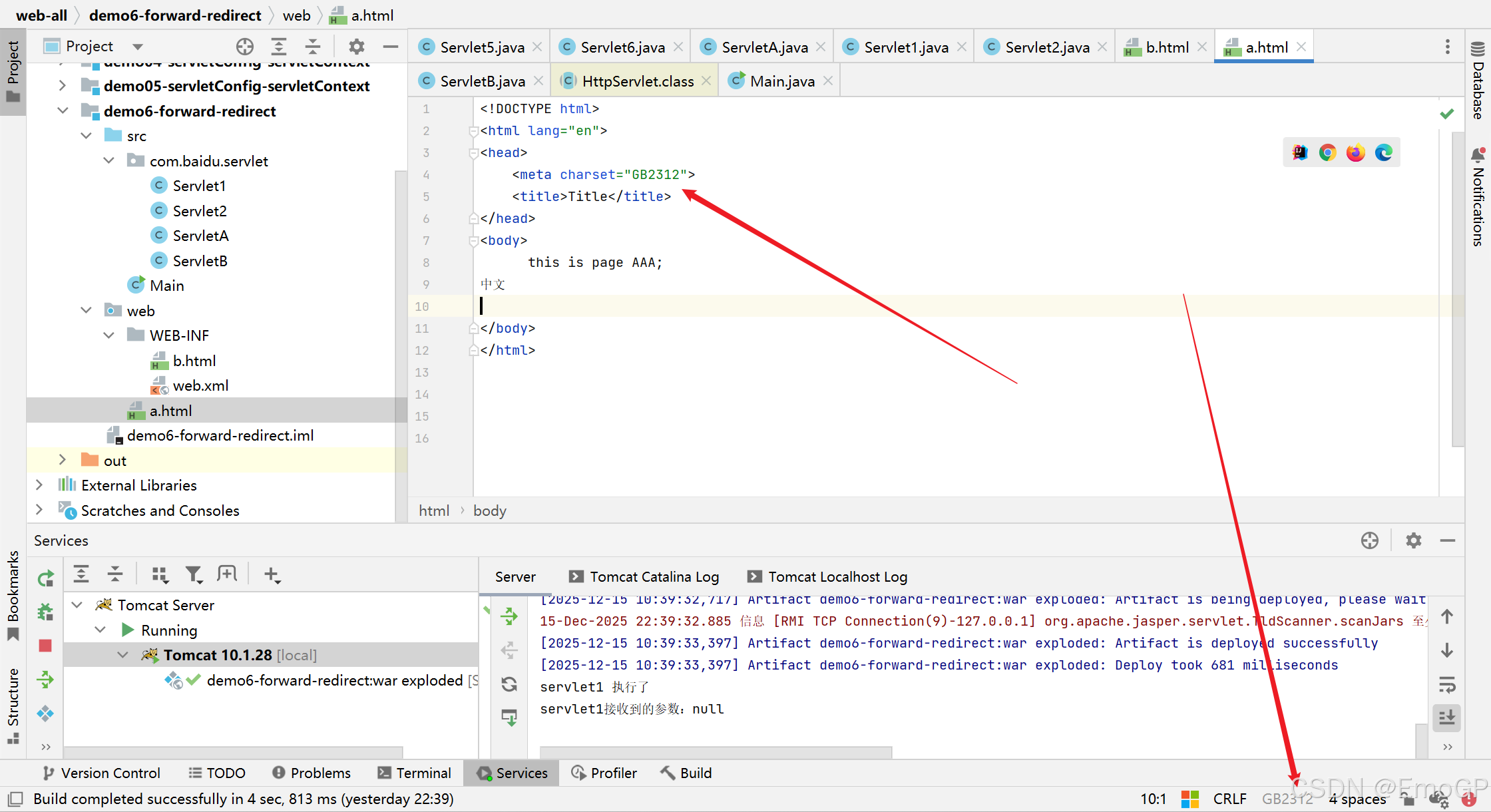
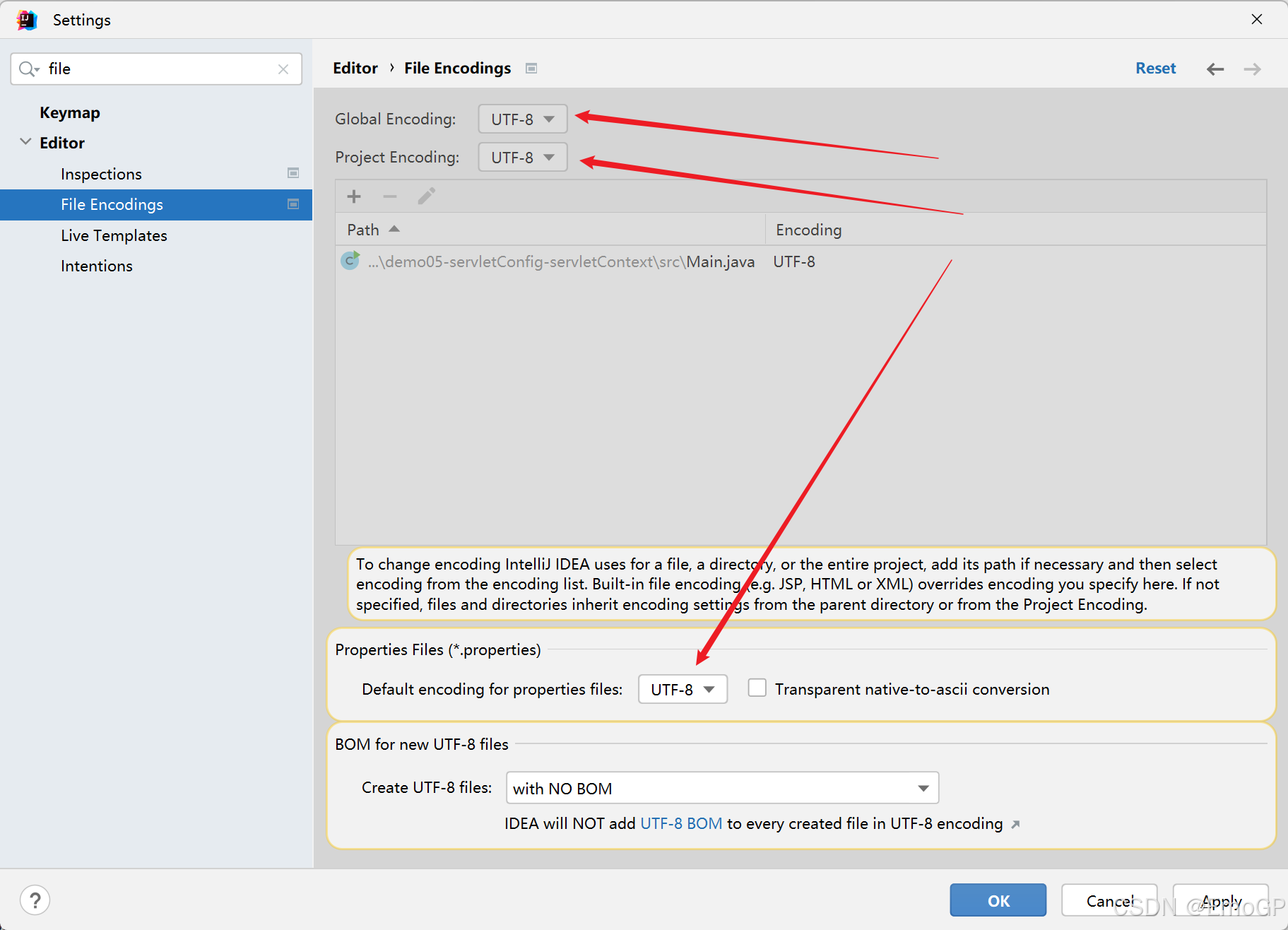
可在idea中修改如下几处都为UTF-8
Tomcat控制台乱码
tomcat在idea中启动时候,有三个打印日志窗口
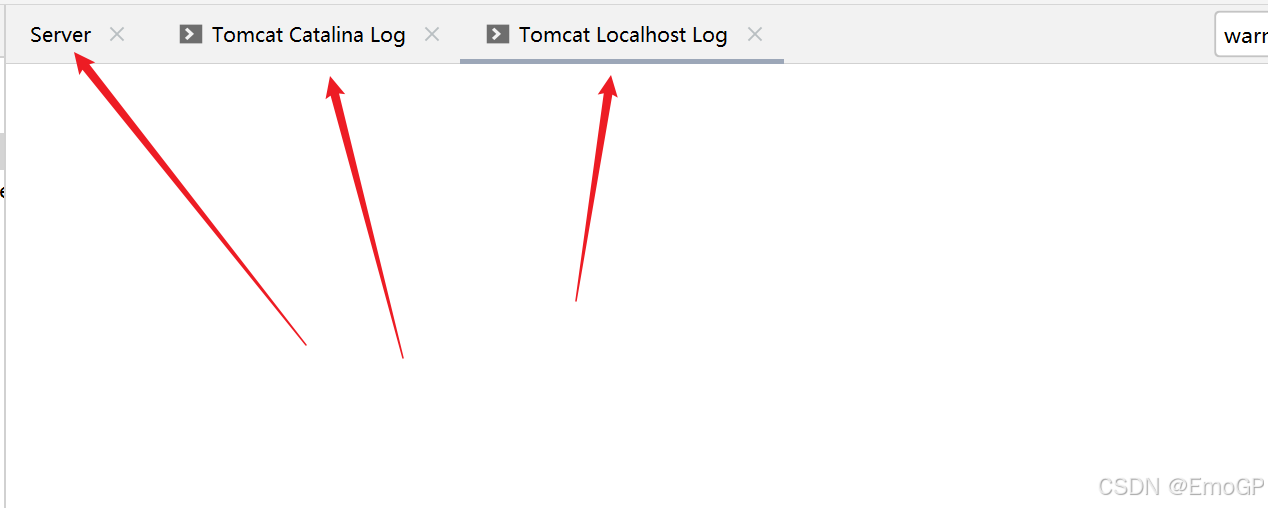
ConsoleHandler对应的就是Server窗口
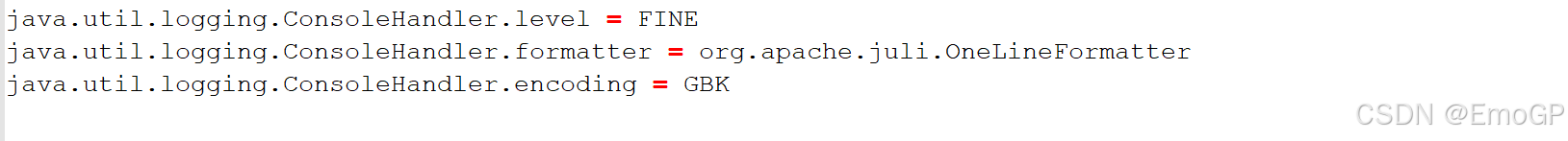
localhost对应Tomcat Localhost Log

catalina对应Tomcat Catalina Log

哪个乱码改哪个
sout乱码
如下内容设置为UTF-8后,IDEA在编译的时候也会使用UTF-8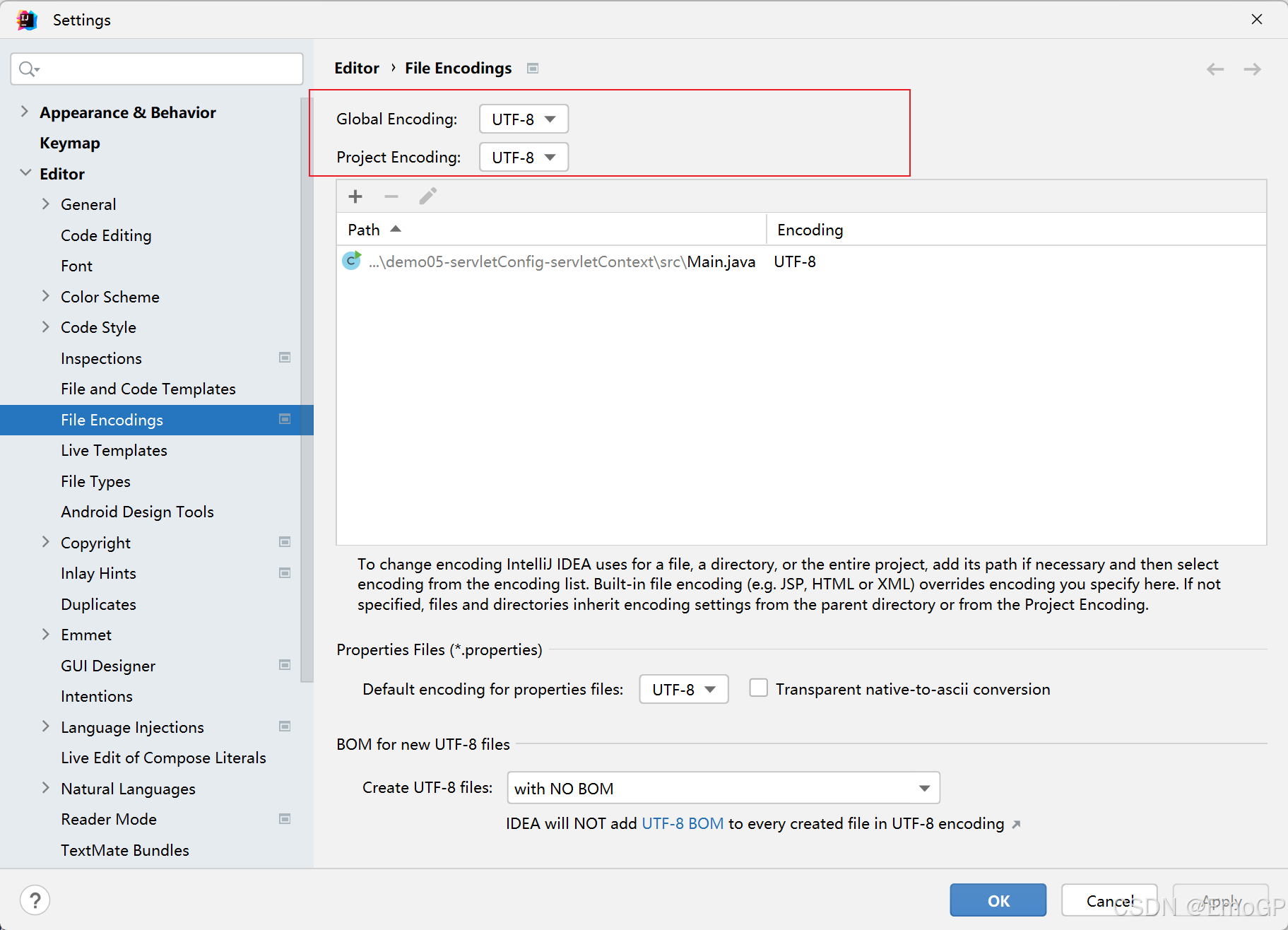
可以设置JVM加载.class文件时使用UTF-8字符集
-Dfile.encoding=UTF-8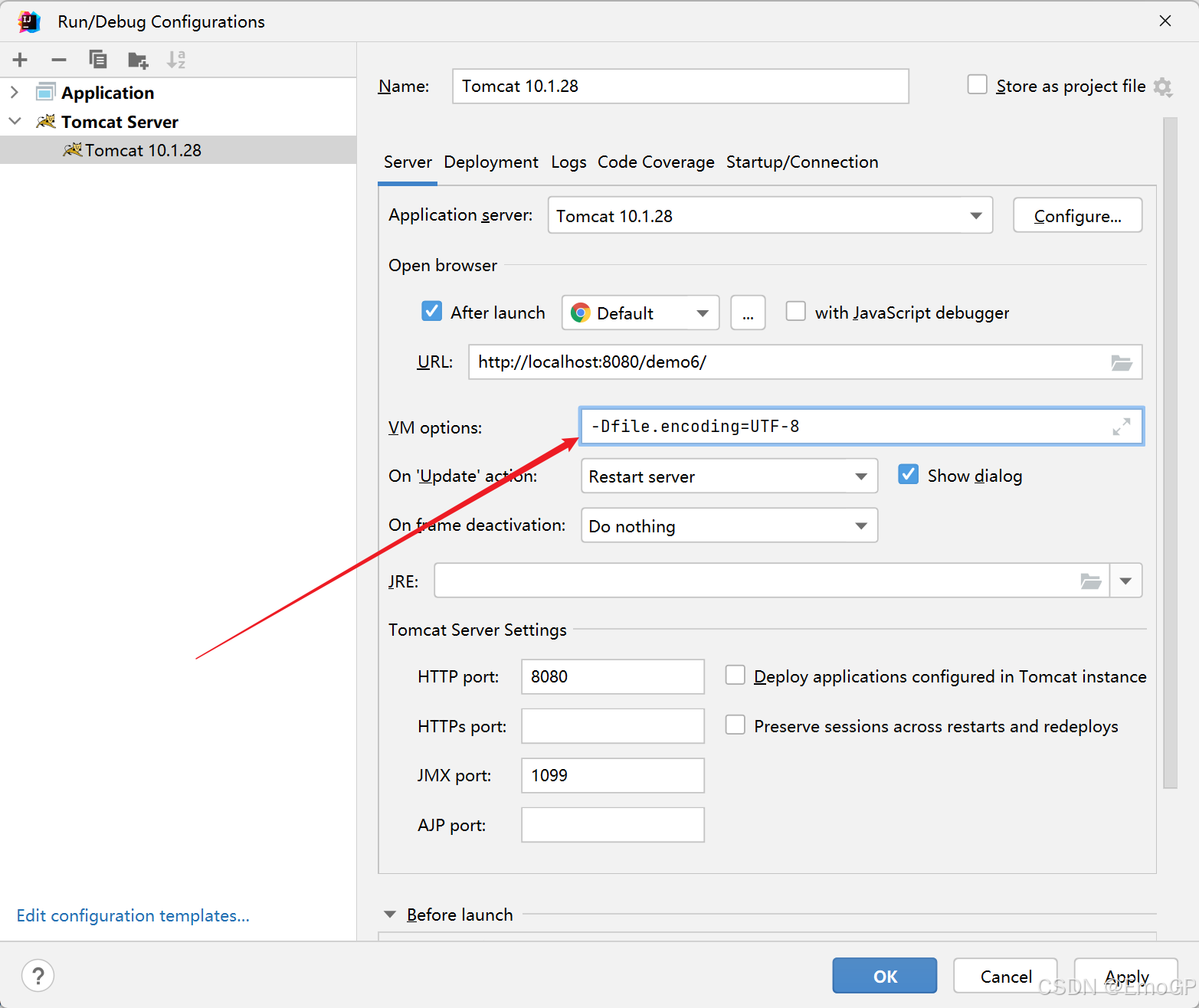
原理就是编译时和JVM加载字节码时字符集保持一致