CUDA(Compute Unified Device Architecture)是 NVIDIA 的通用并行计算平台,而 **cuDNN(CUDA Deep Neural Network Library)**则是在 CUDA 平台之上构建的、专门针对深度学习应用的高性能原语库。
它们之间的关系可以概括为:CUDA 是 GPU 通用计算的基础和编程模型,而 cuDNN 是利用 CUDA 实现的、针对深度学习工作负载的高度优化、即插即用的软件层。
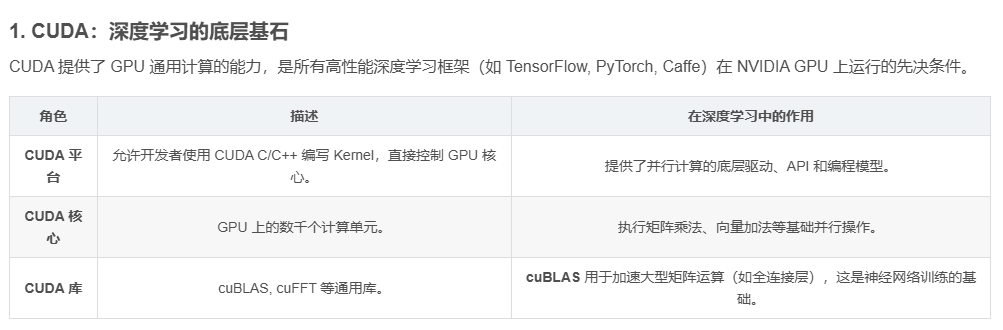
1. CUDA:深度学习的底层基石
CUDA 提供了 GPU 通用计算的能力,是所有高性能深度学习框架(如 TensorFlow, PyTorch, Caffe)在 NVIDIA GPU 上运行的先决条件。
| 角色 | 描述 | 在深度学习中的作用 |
|---|---|---|
| CUDA 平台 | 允许开发者使用 CUDA C/C++ 编写 Kernel,直接控制 GPU 核心。 | 提供了并行计算的底层驱动、API 和编程模型。 |
| CUDA 核心 | GPU 上的数千个计算单元。 | 执行矩阵乘法、向量加法等基础并行操作。 |
| CUDA 库 | cuBLAS, cuFFT 等通用库。 | cuBLAS 用于加速大型矩阵运算(如全连接层),这是神经网络训练的基础。 |
性能瓶颈:通用性 vs. 专业性
虽然可以直接用 CUDA 编写 Kernel 来实现神经网络中的操作(如卷积、池化),但要为所有可能的网络架构、输入尺寸和硬件类型编写出极致优化的 Kernel 难度极大。
例如,一个基本的 3 × 3 3 \times 3 3×3 卷积操作,可以有数十种不同的实现方法,每种方法在不同的 GPU 架构(如 Volta vs. Ampere)或不同的 Batch Size 下,性能表现都大相径庭。
这就是 cuDNN 存在的价值。
2. cuDNN:深度学习高性能原语库
cuDNN 是一个高度调优的 GPU 加速库,它为深度神经网络(DNN)提供了核心构建模块的高性能实现。
2.1 核心功能与优化
cuDNN 的主要功能是提供深度学习中常见的计算密集型操作的优化版本,这些操作被称为原语(Primitives):
| 原语操作 (Primitive) | 描述 | 在 cuDNN 中的优化 |
|---|---|---|
| 卷积 (Convolution) | 神经网络的核心计算,用于提取特征。 | 包含多种算法(如 FFT, Winograd, Implicit GEMM),根据输入尺寸和硬件自动选择最佳算法。 |
| 池化 (Pooling) | 缩小特征图尺寸(如 Max Pooling, Average Pooling)。 | 针对 GPU 并行访问模式进行了优化。 |
| 激活函数 (Activation) | ReLU, Sigmoid, Tanh 等非线性函数。 | 针对 32 线程 Warp 进行了高效的 SIMT 实现。 |
| 归一化 (Normalization) | Batch Normalization, Layer Normalization。 | 优化了跨线程块和跨通道的统计计算。 |
2.2 自动调优与自适应
cuDNN 的强大之处在于它的自适应能力。当深度学习框架调用 cuDNN 时:
-
查询算法: cuDNN 接收到卷积等操作的参数(输入尺寸、核尺寸、步长等)。
-
性能数据库: 它会查询内部的性能数据库,或者通过运行时**自动调优(Autotuning)**来评估当前硬件和参数组合下的最佳 Kernel 实现。
-
选择最优: cuDNN 选择并执行性能最佳的 GPU Kernel。
这意味着开发者可以编写标准的深度学习代码,而 cuDNN 保证底层计算始终使用 NVIDIA 提供的、针对特定 GPU 硬件(如 Tensor Cores)优化的最快代码路径。
3. 深度学习软件栈中的位置
cuDNN 在深度学习软件栈中位于 CUDA 和深度学习框架之间:
| 层次 | 软件/组件 | 描述 |
|---|---|---|
| 应用层 | 最终用户应用程序、自定义模型。 | - |
| 框架层 | TensorFlow, PyTorch, Caffe, MXNet。 | 提供模型构建、自动微分、高层 API。 |
| 加速库层 | cuDNN, cuBLAS。 | 实现框架调用的核心数学运算的高性能版本。 |
| 平台层 | CUDA Toolkit(包含运行时、驱动和编译器)。 | 提供了 GPU 编程接口和执行环境。 |
| 硬件层 | NVIDIA GPU(SM, CUDA Cores, Tensor Cores)。 | 物理计算资源。 |
3.1 框架与 cuDNN 的交互
当你在 PyTorch 中定义一个卷积层并执行前向传播时,实际的执行路径是:
PyTorch → 调用 cuDNN API → cuDNN 选择最优 CUDA Kernel → GPU 执行 \text{PyTorch} \rightarrow \text{调用 cuDNN API} \rightarrow \text{cuDNN 选择最优 CUDA Kernel} \rightarrow \text{GPU 执行} PyTorch→调用 cuDNN API→cuDNN 选择最优 CUDA Kernel→GPU 执行
如果没有 cuDNN,深度学习框架将不得不自己实现所有这些操作,或者使用通用的 CUDA 库(如 cuBLAS),其效率将远低于经过 cuDNN 针对性优化的版本。
4. CUDA 与 cuDNN 的升级和兼容性
-
CUDA 升级: 升级 CUDA Toolkit(如从 11.8 升级到 12.0)通常涉及驱动、编译器和基础库的更新。
-
cuDNN 升级: cuDNN 是一个独立的库文件集。
-
兼容性: 深度学习框架(如 PyTorch)的版本通常会指定它所依赖的最低 CUDA 版本 和推荐 cuDNN 版本。开发者必须确保这三者(框架、CUDA、cuDNN)的版本兼容,否则可能导致训练失败或性能下降。
总结:
CUDA 是 NVIDIA 的通用并行计算平台,提供了 GPU 编程的基础。cuDNN 是构建在 CUDA 之上的专业加速库,它通过提供高度优化的深度学习原语,充当了深度学习框架与 GPU 硬件之间的桥梁。正是这种分层结构和 cuDNN 的极致优化,才使得现代深度学习模型的高效训练成为可能。