Apache Flink 2025年技术现状与发展趋势
📋 概述
Apache Flink 在2025年迎来了重大的技术变革,从单纯的流处理引擎演进为统一的 Data + AI 平台。这也是为什么重新开一个单独的Flink专题的原因。本文档全面分析Flink的最新技术现状、核心特性和未来发展趋势。
🚀 版本发展历程
最新版本状态 (2025年12月)
还记得2020年夏天,深南大道溜达着,Flink更新了1.12,这个版本是真正流批一体的一个重要里程碑。恰如今年,Flink又迎来了架构的重大升级。
| 版本 | 发布时间 | 重要特性 | 状态 |
|---|---|---|---|
| Flink 2.2.0 | 2025年12月4日 | AI能力增强、物化表优化 | 🟢 最新稳定版 |
| Flink 2.1.0 | 2025年7月31日 | Data+AI统一平台 | 🟡 稳定版 |
| Flink 2.0.0 | 2025年3月24日 | 架构重大升级 | 🟡 稳定版 |
| Flink 1.20.x | 2024年 | 传统架构最后版本 | 🔴 维护模式 |
版本升级建议
- 生产环境: 推荐使用 Flink 2.1.0+
- 新项目: 直接采用 Flink 2.2.0
- 老项目: 制定从 1.x 到 2.x 的迁移计划
🏗️ 核心架构演进
1. 分离式状态存储架构 (Disaggregated State Storage)
传统架构问题:
- 计算和状态管理紧耦合
- 大状态作业的扩缩容困难
- 故障恢复时间长
新架构优势:
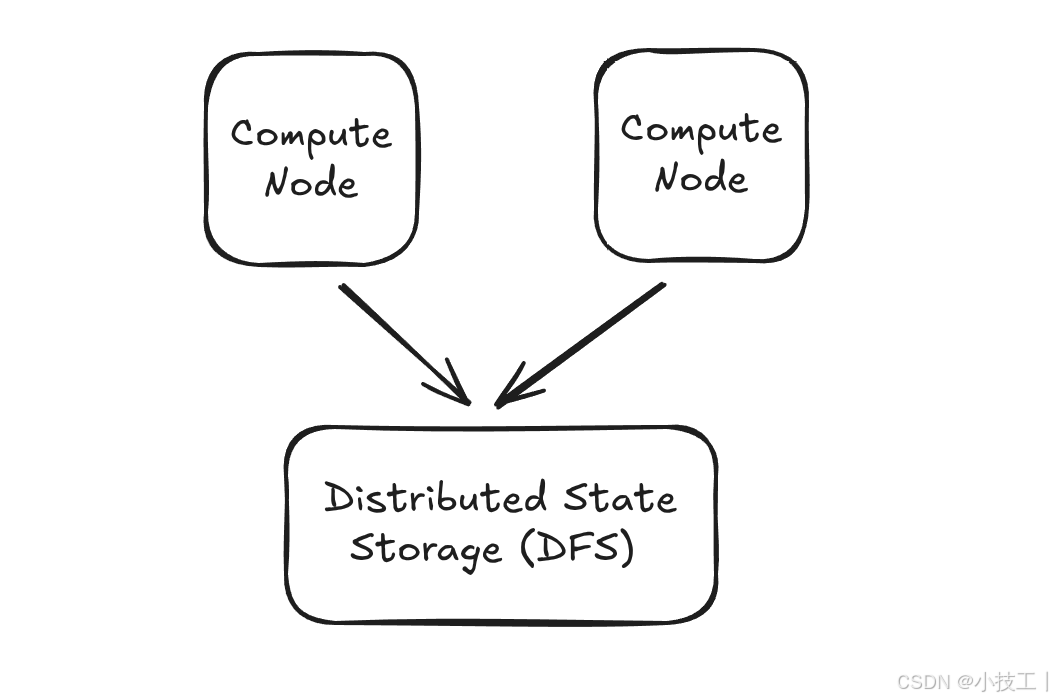
技术实现:
- 基于分布式文件系统(DFS)的状态存储
- 异步状态API支持高延迟访问场景
- 云原生架构,完美适配Kubernetes
2. DataStream API V2
设计目标:
- 解决V1 API的历史包袱
- 提供更清晰的编程模型
- 更好的性能和可维护性
核心组件:
java
// DataStream V2 核心API
DataStream<T> stream = env.fromSource(source);
stream.process(new ProcessFunction<T, R>() {
@Override
public void processElement(T value, Context ctx, Collector<R> out) {
// 处理逻辑
}
});🤖 Data + AI 统一平台
1. 实时AI能力
核心特性:
- Process Table Functions (PTFs): 最强大的用户自定义函数
- 实时模型推理: 支持在线机器学习
- 智能流处理: AI驱动的数据处理优化
应用场景:
sql
-- 实时AI推荐示例
CREATE TABLE user_behavior (
user_id BIGINT,
item_id BIGINT,
behavior_type STRING,
ts TIMESTAMP(3)
) WITH (
'connector' = 'kafka',
'topic' = 'user_behavior'
);
-- 使用PTF进行实时推荐
SELECT user_id, recommended_items
FROM user_behavior
CROSS JOIN LATERAL TABLE(ai_recommend(user_id, behavior_type));2. 流批一体增强
技术实现:
- 统一的执行引擎
- 自动优化查询计划
- 透明的数据源切换
📊 物化表 (Materialized Tables)
核心概念
物化表是Flink 2.x的重要特性,实现了流批一体的数据管理(懂得都懂,之前有多麻烦,后面会单独说一下):
sql
-- 创建物化表
CREATE MATERIALIZED TABLE sales_summary (
product_id BIGINT,
total_sales DECIMAL(10,2),
sale_count BIGINT,
PRIMARY KEY (product_id) NOT ENFORCED
) PARTITIONED BY (product_id)
WITH (
'format' = 'parquet'
)
FRESHNESS = INTERVAL '1' MINUTE
AS SELECT
product_id,
SUM(amount) as total_sales,
COUNT(*) as sale_count
FROM sales_stream
GROUP BY product_id;新特性 (Flink 2.2)
- 可选FRESHNESS子句: 不再强制要求指定刷新频率
- MaterializedTableEnricher接口: 支持自定义默认行为
- 智能默认值: 自动推断上游表的刷新频率
☁️ 云原生部署
Kubernetes集成
Flink Kubernetes Operator 特性:
- 自动扩缩容 (Auto-scaling)
- 基于数据负载的智能调度
- 强化的回滚管理
- 灵活的Savepoint处理
部署示例:
yaml
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
name: flink-app
spec:
image: flink:2.2.0
flinkVersion: v2_2
flinkConfiguration:
taskmanager.numberOfTaskSlots: "2"
serviceAccount: flink
jobManager:
resource:
memory: "2048m"
cpu: 1
taskManager:
resource:
memory: "2048m"
cpu: 1容器化优势
- 资源隔离: 更好的多租户支持
- 弹性伸缩: 根据负载自动调整资源
- 故障恢复: 快速的容器重启和迁移
🔧 连接器生态系统
增强的连接器框架
Flink 2.2 连接器改进:
- 更好的错误处理和重试机制
- 统一的配置接口
- 增强的监控和指标
主要连接器:
java
// Kafka连接器示例
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("localhost:9092")
.setTopics("input-topic")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();📈 性能优化
1. 异步状态API
优化场景:
- 高延迟状态访问
- 大状态作业
- 外部状态存储集成
性能提升:
- 非阻塞执行模式
- 最大化吞吐量
- 降低处理延迟
2. SQL优化器增强
重新实现的SQL算子:
- Joins (各种类型)
- Aggregates (窗口聚合、分组聚合)
- 状态化操作优化
🌟 企业级特性
1. 高可用性
- 精确一次状态一致性: Exactly-once语义保证
- 增量检查点: 最小化故障恢复时间
- 自动故障转移: 无人工干预的故障处理
2. 可观测性
监控指标:
- 吞吐量和延迟监控
- 状态大小和检查点监控
- 资源使用情况监控
集成工具:
- Prometheus + Grafana
- ELK Stack集成
- 分布式追踪支持
🔮 未来发展趋势
1. 技术发展方向
- 更深度的AI集成: 实时机器学习管道
- Serverless支持: 函数即服务模式
- 边缘计算: 支持边缘设备部署
- 多云部署: 跨云厂商的统一管理
2. 生态系统扩展
- Apache Paimon集成: 流式湖仓一体(流批一体、湖仓一体折腾那么多年,这算终极形态了吧?)
- 更多连接器: 支持更多数据源和目标
- 开发工具: 更好的IDE集成和调试工具
📚 学习路径建议
初学者路径
- 基础概念 → 流处理基本概念
- DataStream API → 从V1开始,逐步迁移到V2
- Table API/SQL → 声明式编程模式
- 部署运维 → 本地到云原生部署(积极拥抱云原生)
进阶路径
- 状态管理 → 深入理解状态后端
- 性能调优 → 监控、调优、故障排查
- AI集成 → 实时机器学习应用
- 架构设计 → 企业级流处理架构
🎯 最佳实践建议
1. 版本选择
- 新项目直接使用Flink 2.2+
- 关注社区发布节奏,及时升级
- 在测试环境验证新特性
2. 架构设计
- 优先考虑云原生部署
- 合理设计状态管理策略
- 重视监控和可观测性
3. 开发实践
- 使用Table API/SQL处理标准场景
- DataStream API处理复杂逻辑
- 充分利用连接器生态
总结 : 时隔5年,Apache Flink 2025年的发展标志着流处理技术的新纪元,从单一的流处理引擎演进为统一的Data + AI平台,为企业提供了更强大、更灵活的实时数据处理能力。