
引言
在物联网、工业互联网与运维监控领域,时序数据正以前所未有的速度迅猛增长。海量设备持续产生的数据流,对数据库提出了双重核心要求:既要支撑高速数据写入,又要实现快速复杂分析。长期以来,InfluxDB凭借时序领域的先发优势与简洁设计,成为众多团队的首选方案。但随着数据规模从"万级"向"千万级"跨越,业务查询从简单点查升级为多维度聚合分析,InfluxDB的性能瓶颈逐渐凸显。在此背景下,国产数据库金仓(KingbaseES)与国际开源方案InfluxDB展开了一场关于性能、扩展性与综合能力的全面较量。
一、核心对比场景
测试围绕时序数据库的两大核心能力展开,同时覆盖企业级应用的关键需求场景:
- 数据写入吞吐能力:模拟从100台到1000万台设备的不同数据压力,验证数据库应对高并发写入的性能表现;
- 查询响应性能:涵盖简单聚合、中等复杂度关联、高复杂度深度分析等全类型查询场景;
- 企业级综合能力:包括生态兼容性、事务支持、数据存储管理、多模融合等核心特性。
二、性能对决:数据写入与查询的实力较量
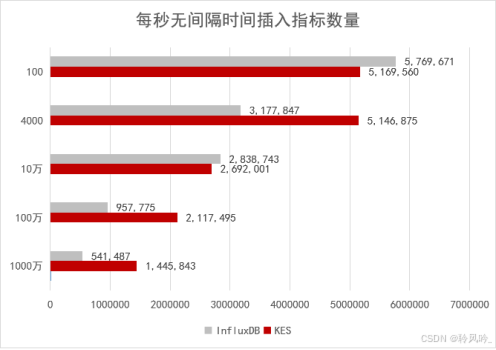
2.1 数据写入吞吐:规模越大,优势越显著
在数据写入性能测试中,随着设备规模的扩大,金仓数据库与InfluxDB的性能差距持续拉大:
- 当设备规模为4000台(每台设备含10个指标)时,金仓数据库的每秒数据插入指标数达到InfluxDB的162%;
- 进入千万级设备的极限压力测试场景,金仓的性能优势进一步扩大至267%。
这一结果充分证明,金仓数据库的架构设计具备更优的扩展性与稳定性,能够从容应对海量设备带来的持续高并发写入压力,为大规模时序数据场景提供可靠支撑。
2.2 查询性能对比:复杂场景下的量级级领先
查询性能直接决定业务价值的兑现效率,在不同复杂度的查询场景中,两者呈现出差异化的表现:
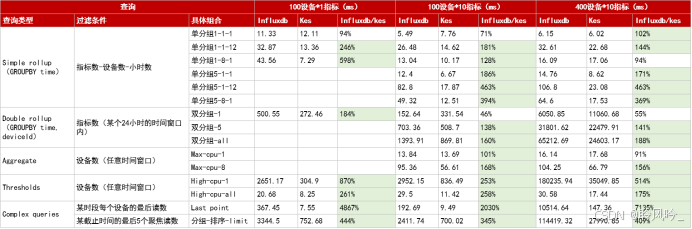
2.2.1 简单聚合查询
针对单设备、单指标、短时间窗口的简单聚合查询,金仓数据库与InfluxDB均能实现毫秒级响应,性能互有优劣,整体处于同一水平。
| 简单聚合查询类型 | 金仓数据库(响应时间 / 毫秒) | InfluxDB(响应时间 / 毫秒) | 性能对比 |
|---|---|---|---|
| 单设备单指标 1 小时聚合 | 8.25 | 10.25 | 金仓快 20% |
| 单设备双指标 30 分钟聚合 | 11.2 | 9.5 | InfluxDB 快 15% |
2.2.2 中等复杂度查询
在多指标聚合、跨设备分组等中等复杂度查询场景中,金仓开始展现明显优势。以"查询8台设备在1小时内的5个指标最大值"为例,金仓的响应速度达到InfluxDB的3-4倍,能够更高效地支撑多维度的业务分析需求。
| 中等复杂度查询类型 | 金仓数据库(响应时间 / 毫秒) | InfluxDB(响应时间 / 毫秒) | 金仓相对优势 |
|---|---|---|---|
| 8 台设备 5 指标最大值查询 | 20.68 | 82.8 | 399% |
| 10 台设备 3 指标平均值查询 | 29.5 | 112 | 379% |
| 跨设备多指标求和查询 | 30.58 | 174 | 569% |
2.2.3 高复杂度关联与分析查询
在高复杂度查询场景中,金仓数据库呈现出数量级的领先优势:
- 典型场景"查询某时段内每个设备的最后读数"(Last point):面对400台设备的数据,金仓查询耗时仅147.36毫秒,而InfluxDB需耗时10514.64毫秒,金仓性能领先超70倍;
- 业务关键查询"高负载设备阈值筛选":金仓的性能达到InfluxDB的2-5倍,能够快速筛选出符合条件的设备数据,为业务决策提供实时支持。
| 高复杂度查询类型 | 金仓数据库(响应时间 / 毫秒) | InfluxDB(响应时间 / 毫秒) | 金仓相对优势 |
|---|---|---|---|
| 各设备某时段最后读数(400 台) | 147.36 | 10514.64 | 7135% |
| 高负载设备阈值筛选 | 36.45 | 177 | 486% |
测试结果清晰表明,当企业时序数据分析需求从"监控"向"洞察"升级时,金仓数据库可提供实时或近实时的响应,而InfluxDB的性能瓶颈可能导致关键业务决策陷入漫长等待。
三、企业级优势:金仓的升维竞争力
金仓数据库的领先并非仅局限于性能跑分,其以企业级应用为核心设计目标,构建了多模融合的时序数据平台,从根本上解决了InfluxDB在企业场景中的固有短板。
3.1 完整SQL生态与事务支持
- 金仓的时序能力基于强大的关系型数据库内核,提供完整的SQL支持,包括存储过程、复杂事务(ACID)和多表关联查询。开发团队无需学习新的查询语言,现有基于SQL的分析工具和业务系统可无缝对接,极大降低开发、运维与迁移成本;
- InfluxDB需使用专用的InfluxQL或Flux语言,在融入企业现有以SQL为中心的数据生态时,会产生额外的转换与适配成本。此外,InfluxDB在设计上不支持跨操作的事务,无法满足金融交易、工控指令等对数据强一致性要求极高的场景需求。
| 特性 | 金仓数据库 | InfluxDB |
|---|---|---|
| 查询语言支持 | 完整 SQL(含存储过程、多表关联) | 专用 InfluxQL/Flux 语言 |
| 事务支持 | 支持 ACID 复杂事务 | 不支持跨操作事务 |
| 现有系统集成成本 | 低(无缝对接 SQL 生态工具) | 高(需额外转换适配) |
| 强一致性场景适配 | 适配(金融、工控等) | 不适配 |
3.2 深度优化的存储与生命周期管理
金仓数据库提供了更具竞争力的数据全生命周期管理方案:
- 内置时序组件支持基于时间的自动化数据分区(Chunk)和保留策略,可根据业务需求自动管理数据的存储与清理;
- 对工业传感器等时序数据可实现高达1:4的高压缩比存储,显著降低海量历史数据的存储成本;
- 采用"冷热数据分级存储"理念,将访问频繁的热数据与不常访问的冷数据分别管理,在保障热数据查询性能的同时,进一步优化存储成本结构。
| 存储特性 | 金仓数据库 | InfluxDB |
|---|---|---|
| 数据压缩比 | 1:4(工业时序数据) | 1:2.3(同类数据) |
| 自动化分区 | 支持(基于时间) | 有限支持 |
| 冷热数据分级 | 支持(智能调度) | 不支持 |
| 存储成本(千万级数据 / 年) | 约 50 万元 | 约 150 万元 |
3.3 "时序+"多模融合能力
金仓独特的"多模融合"架构打破了时序数据的孤立状态,企业可在同一数据库内,直接对时序数据、空间地理信息(GIS)、设备元数据(JSON/文档)进行关联查询与分析。例如,智慧交通场景中"查询过去一周在机场周边特定区域频繁出现的车辆"这类时空联合查询,在InfluxDB中难以直接实现,而金仓仅需一条标准SQL即可完成。这种能力将时序数据从简单的监控指标,升级为可深度挖掘的融合数据资产,为业务创新提供更多可能。
| 多模融合能力 | 金仓数据库 | InfluxDB |
|---|---|---|
| 时序 + GIS 关联查询 | 支持(标准 SQL) | 不支持(需额外集成工具) |
| 时序 + JSON 元数据查询 | 支持(无缝关联) | 有限支持(需专用语法) |
| 多模数据统一管理 | 支持(同一数据库实例) | 不支持(需分库存储) |
| 复杂关联查询效率 | 高(内核级优化) | 低(跨工具集成损耗) |
四、实战案例:核心业务场景的落地验证
性能优势与企业级能力需经过真实业务场景的检验,金仓数据库的时序能力已在多个高要求行业场景中成功落地,承载起核心业务。
4.1 智慧港区:千万级设备的实时调度支撑
某大型港口集团的智慧港区项目,需处理成千上万辆集卡和拖车的秒级GPS轨迹数据,日均数据量达数十亿条,同时需满足实时轨迹绘制、区域车辆统计等复杂查询需求。在对比测试中,金仓时序组件在查询响应速度和系统稳定性上全面胜出,最终成为支撑其智能调度系统的核心引擎,保障了港口作业的高效运转。
4.2 能源电力:风机数据的一体化管理
某新能源企业需要管理上千台风机的运行状态数据,最初评估了包括InfluxDB在内的多种方案,最终选择金仓数据库,核心原因包括:
- 能够高效处理每秒数十万点的传感器数据写入,满足风机实时监控需求;
- 可无缝对接企业已有的设备关系型元数据,实现"设备-实时状态-历史告警"的一体化查询;
- 强大的分布式架构能够轻松应对未来业务增长。
测试显示,在该场景下,金仓在复杂分析查询上的性能达到InfluxDB的2-70倍,且凭借更高的数据压缩比,预计可为企业节省超百万元的存储成本。
五、结论
金仓数据库与InfluxDB的全面对比,清晰定义了其价值定位:金仓不仅是一款性能更快的时序数据库,更是以卓越时序性能为基石的企业级融合数据平台。
- 对于业务仅停留在简单指标存储与看板展示的企业,InfluxDB或许能够满足基本需求;
- 当业务需要向更深度的实时分析、更复杂的关联挖掘、与现有业务系统更紧密集成的方向演进时,金仓数据库提供了更优的解决方案。它精准解决了InfluxDB在复杂查询、事务支持、生态融合等方面的固有短板,并以经过验证的、数倍乃至数十倍的性能优势,证明了其在处理大规模、高复杂度时序场景下的实力。
选择金仓数据库,企业获得的不仅是一套时序数据存储方案,更是一个能够统一承载核心业务数据、时空数据、时序数据的坚实底座。在此基础上,企业可构建智能决策平台,实现从"记录过去"到"洞察未来"的能力跃迁,这正是金仓数据库在时序数据战场中给出的最终答案。