本文来源:k学长的深度学习宝库,点击查看源码&详细教程。深度学习,从入门到进阶,你想要的,都在这里。包含学习专栏、视频课程、论文源码、实战项目、云盘资源等。

1、研究背景与动机
(1)人体姿态估计的重要性
人体姿态估计的任务,就是从图片或视频中自动找到人体的关键点(比如头部、肩膀、肘关节、膝盖等),并精确标注它们的位置。这项技术应用非常广泛,比如:
动作识别:识别一个人是在走路、跑步还是跳舞。
人机交互:通过肢体动作与计算机或设备互动。
动画与虚拟现实:驱动虚拟角色的动作。
视频监控与体育分析:精确分析运动员动作或行为模式。
因此,这个任务在计算机视觉里既是基础性研究课题,又有很强的实际价值
(2)传统方法的局限
在深度学习出现前,研究人员常用概率图模型或手工特征方法来估计人体姿态。但这些方法有明显缺点:对复杂背景、多人场景或姿态变化的鲁棒性很差。
随着深度卷积神经网络的兴起,性能有了飞跃。主流做法通常是:
先下采样:输入图像经过多层卷积,分辨率逐渐降低,以提取高级语义特征。
再上采样:通过转置卷积(反卷积)、插值或对称结构,把低分辨率特征恢复到高分辨率,用来预测关键点热图。
例如:
Hourglass 网络:用对称的"高到低"和"低到高"结构来恢复细节。
SimpleBaseline:简单地在最后阶段用转置卷积恢复分辨率。
但这些方法有两个关键问题:
高分辨率信息丢失:先下采样再恢复,往往损失了细节。
融合不充分:不同尺度的特征交互有限,导致关键点预测缺乏空间精度
(3)提出 HRNet 的动机
为了解决上述问题,研究者提出了 高分辨率网络(HRNet)。 它的核心想法是:
全程保持高分辨率表征,而不是先丢失再恢复。
并行连接多分辨率子网络,让高分辨率和低分辨率特征在整个训练过程中持续交互、融合。
这样,网络既能保留丰富的空间细节,又能结合低分辨率特征的语义信息,从而得到更精确、更鲁棒的关键点定位结果。
一句话总结: 👉 HRNet 的动机,就是"避免高分辨率信息的损失,通过持续的多尺度融合,让关键点预测既清晰又精准"
2、核心创新点
(1)全程保持高分辨率
以往的方法大多是:先把图像分辨率降得很低,再想办法恢复到高分辨率。但这种"先丢后补"的方式,必然导致细节缺失。
HRNet 的不同之处在于:
从头到尾都保留一条 高分辨率子网络。
即使在网络变深的过程中,也不会让高分辨率信息"消失"。
👉 这样就能保证预测的关键点热图细节更清晰,定位更准确
(2)并行多分辨率子网络
传统方法一般是"串行"设计(高分辨率 → 低分辨率 → 再恢复)。 HRNet 则采用了 并行结构:
在高分辨率子网络的基础上,逐步加入低分辨率子网络。
各个分辨率的子网络是 同时存在并并行工作的,而不是"先后顺序"。
👉 这种设计使得不同分辨率的特征可以同时被学习和利用,而不是等到最后才进行一次融合
(3)重复的多尺度信息交换(多尺度融合)
HRNet 不仅让不同分辨率的子网络并行存在,还引入了 频繁的信息交换机制:
每一阶段,都会把高分辨率和低分辨率特征进行双向传递。
这样,低分辨率特征能获得更多空间细节,高分辨率特征也能吸收更多语义信息。
👉 与传统只在部分层次做简单融合不同,HRNet 做到"多次、深度的双向融合",效果更强
(4)输出高分辨率表征
不同于许多方法在最后输出低分辨率结果再插值,HRNet 直接利用 高分辨率特征 来预测关键点热图。
这样得到的热图在 空间分布 上更精细。
在实验中,HRNet 在 COCO、MPII、PoseTrack 等主流数据集上均取得了显著优势。
👉 这就是 HRNet 在精度上大幅超越其他模型的根本原因
(5)总结:HRNet 的三大核心亮点
全程保持高分辨率表征 ------ 不再依赖"低分辨率 → 恢复"流程。
并行多分辨率子网络 ------ 高低分辨率共同学习,信息互补。
重复的多尺度融合机制 ------ 持续交互,保证细节与语义兼备。
一句话: 👉 HRNet 的创新点,就是通过 "高分辨率贯穿 + 多尺度并行 + 深度融合",实现了更精准的人体姿态估计。
3、模型的网络结构
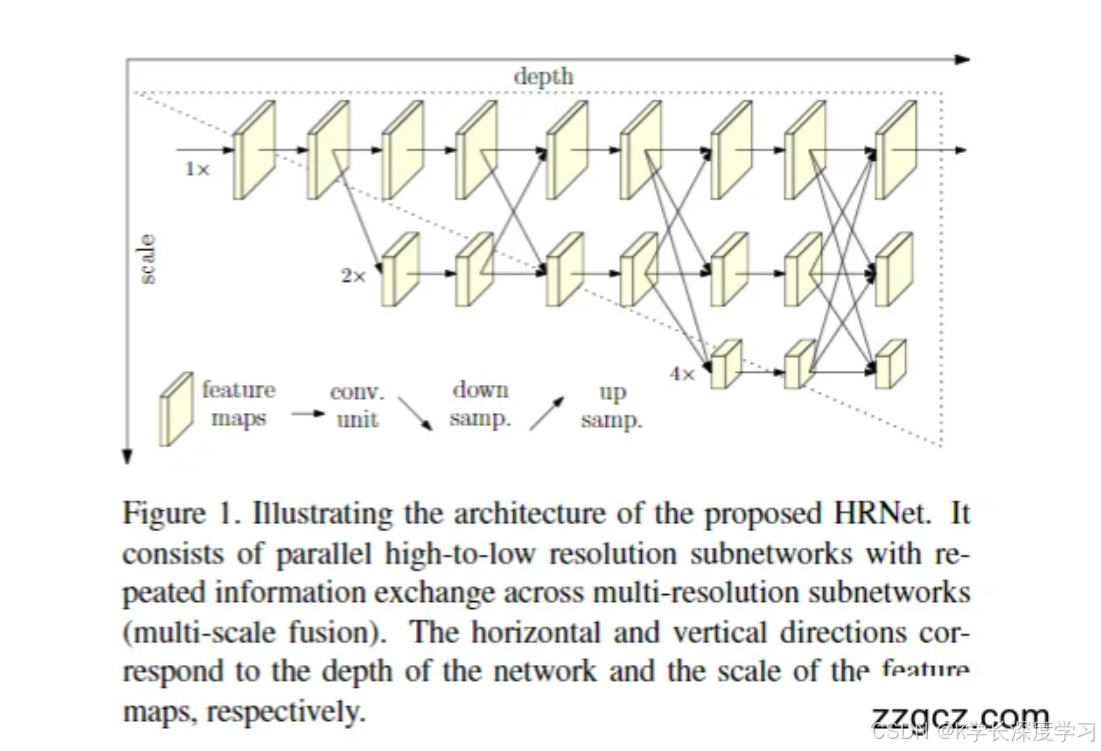
(1)整体结构概览
这张图展示了 HRNet 的核心架构:
横向(depth):表示网络的深度,每一列就是一个阶段(stage)。
纵向(scale):表示特征图的分辨率,从上到下依次是高分辨率(1×)、中等分辨率(2×)、低分辨率(4×),以此类推。
箭头:表示信息传递,包括卷积(conv unit)、下采样(down samp.)、上采样(up samp.)和跨分辨率的特征融合。
👉 简单理解:HRNet 同时保留多条分辨率不同的"子网络",并在整个训练过程中让它们不断互相交流信息。
(2)高分辨率子网络起始
网络一开始就从 高分辨率特征图(1×) 出发。
随着深度加深,会逐步引入低分辨率的子网络(比如 2×、4×),但高分辨率子网络始终保留。
👉 与传统模型不同,高分辨率不是在最后才恢复,而是全程都在。
(3)并行的多分辨率子网络
如图所示:
在每一个阶段,网络包含多个 不同分辨率的分支。
这些分支是 并行存在 的,而不是串行关系。
例如:
第一阶段:只有高分辨率分支。
第二阶段:多了一个 2× 分辨率分支。
第三阶段:又加入 4× 分辨率分支。
👉 这样做的好处是:网络可以同时学习"细节特征"(来自高分辨率)和"语义特征"(来自低分辨率)。
(4)多尺度融合(信息交换)
HRNet 的最大特色就在于 重复的多尺度融合:
在每个阶段结束时,所有分支之间都会进行信息传递。
具体方式:
高分辨率特征会被下采样,送到低分辨率分支。
低分辨率特征会被上采样,送回高分辨率分支。
这样,每一个分支的特征都会融合来自其他尺度的信息。
👉 图中纵向的斜线箭头,就表示这种 跨分辨率特征交互。
(5)输出阶段
最终,HRNet 输出的结果来自 高分辨率分支。
因为高分辨率分支在整个过程中不断吸收低分辨率特征的语义信息,同时保持了细节,所以能生成 又细致又精准的关键点热图。
(6)小结
HRNet 的网络设计可以总结为三点:
始终保留高分辨率子网络 ------ 避免信息丢失。
多分辨率子网络并行 ------ 细节与语义兼顾。
重复的多尺度融合 ------ 持续双向信息交互,提升预测精度。
4、存在的重大缺陷
(1)计算量和存储开销大
问题:HRNet 在整个训练和推理过程中始终保留高分辨率分支,同时还并行维护多个低分辨率分支。
后果:
需要大量的显存(GPU memory)。
计算开销高,训练和推理速度都比常规方法慢。
影响:在实际应用中,很难部署到 移动设备 或 实时系统(例如边缘设备、手机、AR/VR 头显)。
👉 换句话说,HRNet 的"高精度"是用 高成本换来的
(2)结构复杂,难以扩展
HRNet 的多分辨率并行 + 多次融合结构,看起来像一个"大网格"。
相比简单的 Hourglass 或 SimpleBaseline,设计和实现更复杂,对新手研究者不太友好。
在需要进一步扩展到更大规模(比如多人姿态估计、3D 姿态估计)时,复杂度和计算量都会进一步爆炸。
(3)对数据和算力的依赖强
为了发挥 HRNet 的优势,需要在 大规模数据集(如 COCO、MPII)上进行训练。
如果数据量不足,网络可能无法充分利用多尺度特征。
此外,硬件依赖很强,没有高性能 GPU 几乎很难训练。
(4)通用性不足
HRNet 是专门为 人体姿态估计 设计的。
虽然它的思想(高分辨率保持 + 多尺度融合)也能推广到其他视觉任务(如分割、检测),但实际应用中需要做大量改动。
在一些任务中(例如小模型部署),它并不是最佳选择。
(5)总结
HRNet 的主要缺陷可以概括为:
高精度但高成本 ------ 模型大、算力需求高,难以部署到轻量级场景。
结构复杂 ------ 设计和扩展不如其他经典网络灵活。
依赖大规模数据和硬件 ------ 资源有限时难以复现论文效果。
任务适配性有限 ------ 针对姿态估计优化,但不一定适合所有视觉任务。
一句话总结:
👉 HRNet 是"实验室里的明星",在 benchmark 上表现非常强,但在实际应用中可能会因为算力和资源限制而遇到瓶颈。
5、后续基于此改进创新的模型
A. 轻量化与部署友好
为解决 HRNet 计算/显存开销大的痛点,出现了多款"保留高分辨率、但更省"的变体:
Lite-HRNet:用通道重排、逐点/深度可分卷积等设计,显著降低 FLOPs 和参数量,适合移动端/实时场景。
MobileHRNet / Dite-HRNet 等:在主干模块、融合单元上进一步做结构剪裁与算子替换,尽量维持 HRNet 的高分辨率特性,同时压缩模型体量。
何时用? 需要实时推理或边缘设备部署,但又想保留"高分辨率恒常保持"的优势。
B. 多人场景与更高分辨率热图
面向自下而上的多人姿态估计,强调高分辨率热图与多尺度特征:
HigherHRNet:在 HRNet 思路上强化高分辨率热图生成与多尺度融合策略,更适合多人关键点检测与关联。
何时用? 图片里多人密集、尺度差异大,需要在高分辨率上产生更细腻的关键点热图。
C. 精度取向的"配套技法"(与 HRNet 常组合)
虽不完全是新主干,但与 HRNet 组合能显著提升精度:
DARK(Distribution-Aware coordinate Representation):改进热图后处理/坐标解码,减少量化误差,常与 HRNet 搭配提升 AP。
UDP(Unbiased Data Processing):更"无偏"的数据处理/解码流程,进一步榨干高分辨率热图的定位精度。
Integral Regression / Soft-argmax 等:将热图转坐标的方式优化,提升亚像素级定位。
何时用? 追求单人/多人关键点"最后 1--2 点 AP"的精度冲刺。
D. 与 Transformer 融合的高分辨率思路
在"保持高分辨率 + 跨尺度交互"的框架里,引入自注意力:
TokenPose:以 HRNet 为骨架引入 token 交互,增强长程依赖。
HRFormer:在高分辨率分支上用局部窗口/多头注意力,兼顾细节与全局建模。
ViTPose 等:虽以纯 Transformer 为主,但在训练策略与多尺度融合上承袭了"高分辨率、强融合"的思想,常与 HRNet 做性能对比或互补。
何时用? 算力允许,想要更强的全局关系建模与可扩展性。
E. 作为通用高分辨率 Backbone 的拓展
HRNet 的"高分辨率恒常保持"被广泛迁移到其它视觉任务:
语义分割:HRNet + OCR(OCRNet) 在分割上极具代表性;高分辨率 backbone 能更好保留边界与细节。
目标检测:HRNet-Backbone + HRFPN(或与常见 FPN 变体结合)提升小目标与密集目标的表现。
关键点以外的密集预测:如人像解析、姿态驱动的下游任务等,高分辨率特征都能带来边缘/局部结构上的收益。
何时用? 需要对边界/小物体/局部结构极其敏感的密集预测任务。
F. 视频与 3D 方向的延伸
时序 HRNet 系列/PoseTrack 系列方法:在 HRNet 框架上叠加时序建模(光流、时序注意力、时序卷积),提升视频姿态稳定性。
2D→3D 管线:以 HRNet 产出的高质量 2D 关键点为输入,再接 3D 回归/提升模块,增强 3D 姿态估计。
何时用? 视频场景抖动大、需求平滑连续,或需要把 2D 姿态进一步抬升到 3D。
选型建议(速查)
移动端/实时:Lite-HRNet / Dite-HRNet。
多人密集场景:HigherHRNet。
追求极限精度:HRNet(W32/W48)+ DARK/UDP/Integral Regression。
算力充足,想要全局建模:HRFormer / TokenPose /(或对比 ViTPose 等)。
语义分割/检测:用 HRNet 作为通用高分辨率 backbone(OCRNet、HRFPN 等)。
本文来源:k学长的深度学习宝库,点击查看源码&详细教程。深度学习,从入门到进阶,你想要的,都在这里。包含学习专栏、视频课程、论文源码、实战项目、云盘资源等。