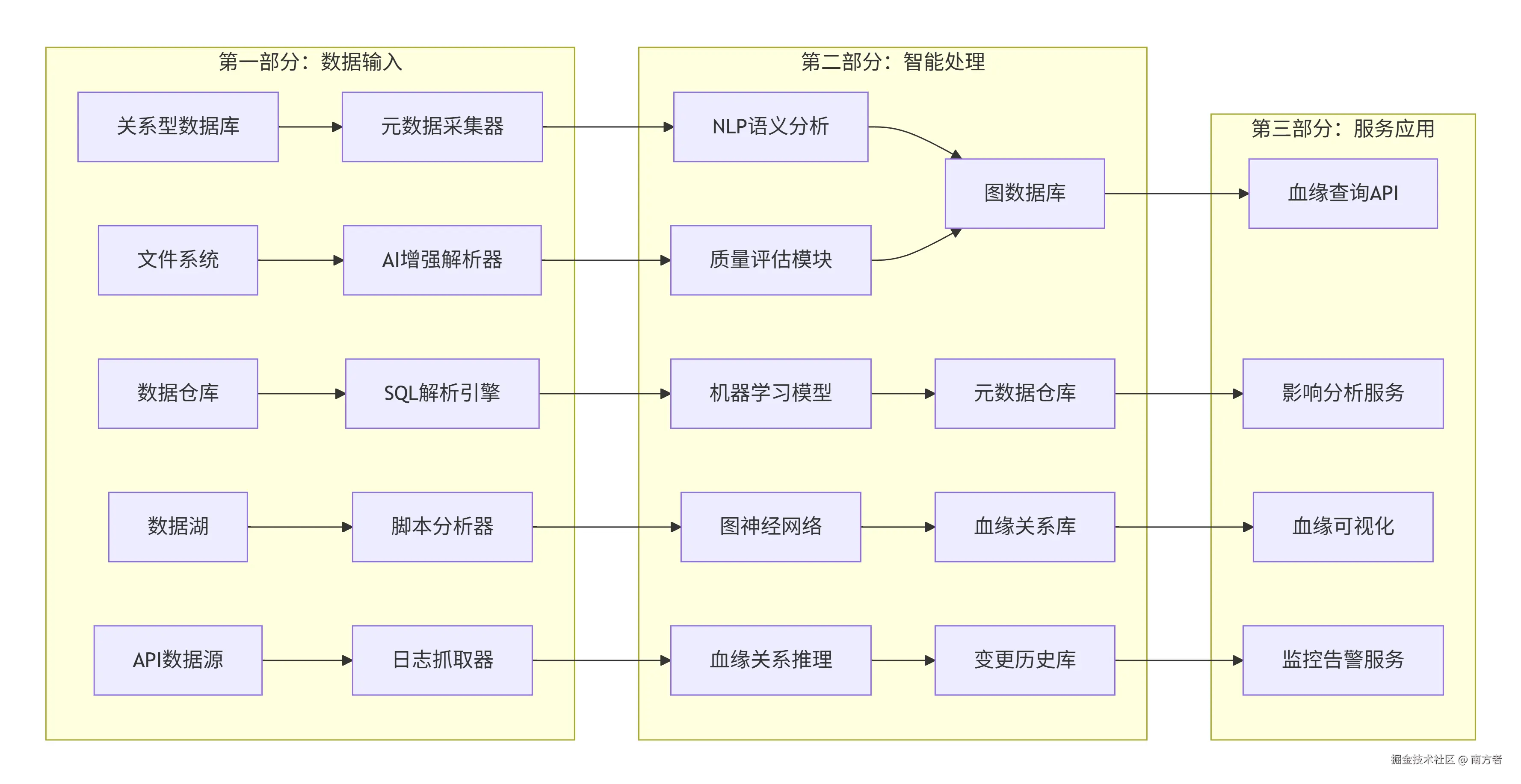
📖 系统架构设计
1.1 整体架构概述
该系统是采用微服务架构,通过 AI 技术自动发现和追踪数据在异构ETL环境中的血缘关系。
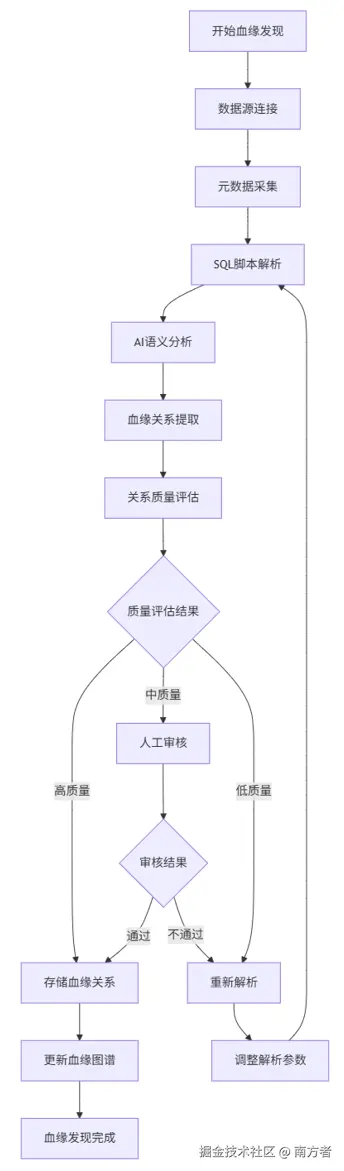
📖 数据血缘发现流程
2.1 自动化血缘发现流程
2.2 SQL 解析与血缘提取
基于 AI 的 SQL 解析引擎:
python
class AISQLLineageExtractor:
def __init__(self):
self.nlp = spacy.load("en_core_web_sm")
self.classifier = pipeline("text-classification",
model="distilbert-base-uncased")
def extract_lineage_from_sql(self, sql_query, context=None):
"""
从SQL查询中提取数据血缘关系
"""
# 解析SQL结构
parsed = sqlparse.parse(sql_query)[0]
# 使用sql_metadata进行基础解析
parser = Parser(sql_query)
# AI增强的语义分析
ai_insights = self.analyze_sql_semantics(sql_query, context)
# 构建血缘关系
lineage_data = {
'input_tables': parser.tables,
'input_columns': parser.columns,
'output_columns': self.extract_output_columns(parsed),
'transformations': self.extract_transformations(parsed, ai_insights),
'confidence_score': ai_insights.get('confidence', 0.8),
'parsing_metadata': {
'query_type': self.classify_query_type(sql_query),
'complexity_score': self.calculate_complexity(sql_query),
'ai_analysis': ai_insights
}
}
return lineage_data
def analyze_sql_semantics(self, sql_query, context):
"""使用AI分析SQL语义"""
# 构建分析提示
analysis_prompt = f"""
Analyze the following SQL query and extract data lineage information:
SQL: {sql_query}
Context: {context}
Please identify:
1. Source tables and columns
2. Transformation logic
3. Target tables and columns
4. Any data quality operations
"""
# 使用NLP模型进行分析
analysis_result = self.nlp(analysis_prompt)
return {
'entities': [(ent.text, ent.label_) for ent in analysis_result.ents],
'dependencies': self.extract_semantic_dependencies(analysis_result),
'confidence': self.calculate_semantic_confidence(analysis_result)
}
# 使用示例
extractor = AISQLLineageExtractor()
sql = """
SELECT
customer_id,
SUM(order_amount) as total_spent,
COUNT(DISTINCT order_id) as order_count
FROM orders
WHERE order_date >= '2024-01-01'
GROUP BY customer_id
"""
lineage = extractor.extract_lineage_from_sql(sql)
print(f"发现的输入表: {lineage['input_tables']}")
print(f"输出列: {[col['name'] for col in lineage['output_columns']]}")📖 血缘关系存储设计
3.1 图数据库 Schema 设计
python
class DataLineageGraph:
def __init__(self, neptune_client):
self.client = neptune_client
def create_lineage_graph(self, lineage_data):
"""创建血缘关系图"""
# 创建表节点
table_nodes = {}
for table in lineage_data['input_tables'] + [lineage_data.get('output_table')]:
if table:
table_id = self.create_table_node(table)
table_nodes[table] = table_id
# 创建列节点和关系
for col_info in lineage_data.get('columns', []):
col_id = self.create_column_node(col_info)
# 创建列到表的关系
self.client.add_edge(
col_id,
table_nodes[col_info['table']],
'BELONGS_TO'
)
# 创建血缘关系
for source_col in col_info.get('source_columns', []):
source_col_id = self.get_column_id(source_col)
if source_col_id:
self.client.add_edge(
source_col_id,
col_id,
'LINEAGE',
properties={
'transformation': col_info.get('transformation'),
'confidence': lineage_data.get('confidence_score', 0.8)
}
)3.2 血缘查询 API 设计
python
class LineageAPI(Resource):
@api.expect(lineage_model)
def post(self):
"""查询数据血缘关系"""
data = request.json
source_type = data.get('source_type')
source_name = data.get('source_name')
depth = data.get('depth', 3)
try:
# 执行血缘查询
if source_type == 'table':
result = self.get_table_lineage(source_name, depth)
elif source_type == 'column':
result = self.get_column_lineage(source_name, depth)
else:
return {'error': '不支持的源类型'}, 400
return jsonify({
'status': 'success',
'data': result,
'query': {
'source': source_name,
'depth': depth,
'timestamp': datetime.utcnow().isoformat()
}
})
except Exception as e:
return {'error': str(e)}, 500
def get_table_lineage(self, table_name, depth):
"""获取表级别血缘关系"""
graph = DataLineageGraph(neptune_client)
# 获取下游影响
downstream = graph.query_impact_analysis(table_name)
# 获取上游依赖
upstream = graph.query_root_cause(table_name, None)
return {
'table': table_name,
'downstream_impact': self.format_paths(downstream),
'upstream_dependencies': self.format_paths(upstream),
'summary': {
'total_downstream': len(downstream),
'total_upstream': len(upstream),
'max_depth': depth
}
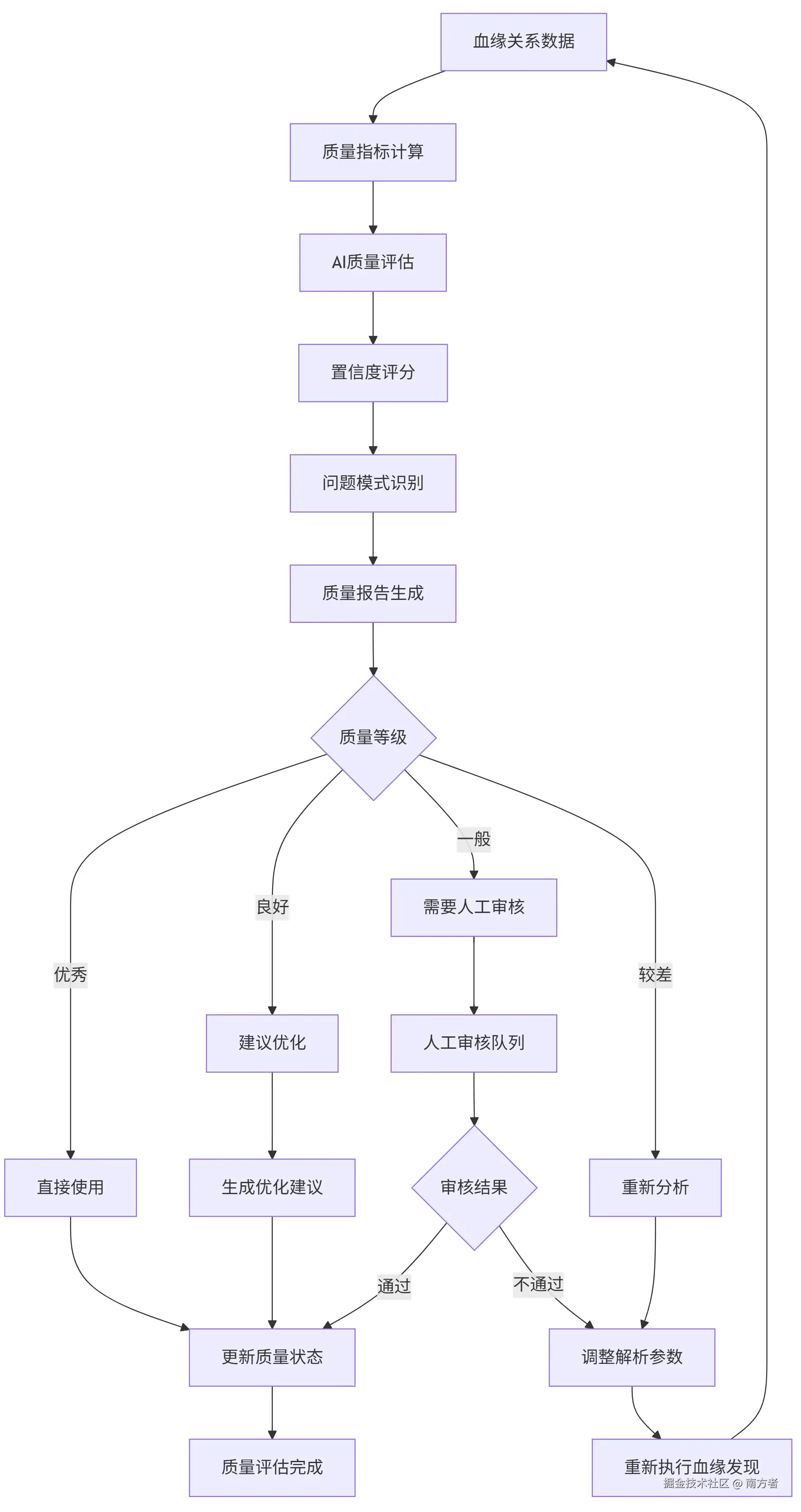
}📖 血缘质量评估流程
4.1 质量评估流程图
4.2 质量评估算法实现
python
class LineageQualityAssessor:
def __init__(self):
self.scaler = StandardScaler()
self.classifier = RandomForestClassifier(n_estimators=100)
self.quality_metrics = []
def assess_lineage_quality(self, lineage_data):
"""评估血缘关系质量"""
# 计算质量指标
metrics = self.calculate_quality_metrics(lineage_data)
# AI质量分类
quality_score = self.ai_quality_classification(metrics)
# 问题检测
issues = self.detect_quality_issues(lineage_data, metrics)
assessment_result = {
'overall_score': quality_score,
'quality_level': self.get_quality_level(quality_score),
'metrics': metrics,
'issues': issues,
'recommendations': self.generate_recommendations(issues, metrics),
'confidence': self.calculate_confidence(metrics, issues)
}
return assessment_result
def calculate_quality_metrics(self, lineage_data):
"""计算血缘质量指标"""
metrics = {}
# 完整性指标
metrics['completeness'] = self.calculate_completeness(lineage_data)
# 准确性指标
metrics['accuracy'] = self.calculate_accuracy(lineage_data)
# 一致性指标
metrics['consistency'] = self.calculate_consistency(lineage_data)
# 时效性指标
metrics['freshness'] = self.calculate_freshness(lineage_data)
# 复杂性指标
metrics['complexity'] = self.calculate_complexity(lineage_data)
return metrics
def ai_quality_classification(self, metrics):
"""使用AI进行质量分类"""
# 准备特征数据
features = np.array([[
metrics['completeness'],
metrics['accuracy'],
metrics['consistency'],
metrics['freshness'],
metrics['complexity']
]])
# 标准化特征
features_scaled = self.scaler.transform(features)
# 预测质量分数
quality_score = self.classifier.predict_proba(features_scaled)[0][1]
return quality_score
# 使用示例
assessor = LineageQualityAssessor()
quality_result = assessor.assess_lineage_quality(lineage_data)
print(f"质量评分: {quality_result['overall_score']:.2f}")
print(f"质量等级: {quality_result['quality_level']}")
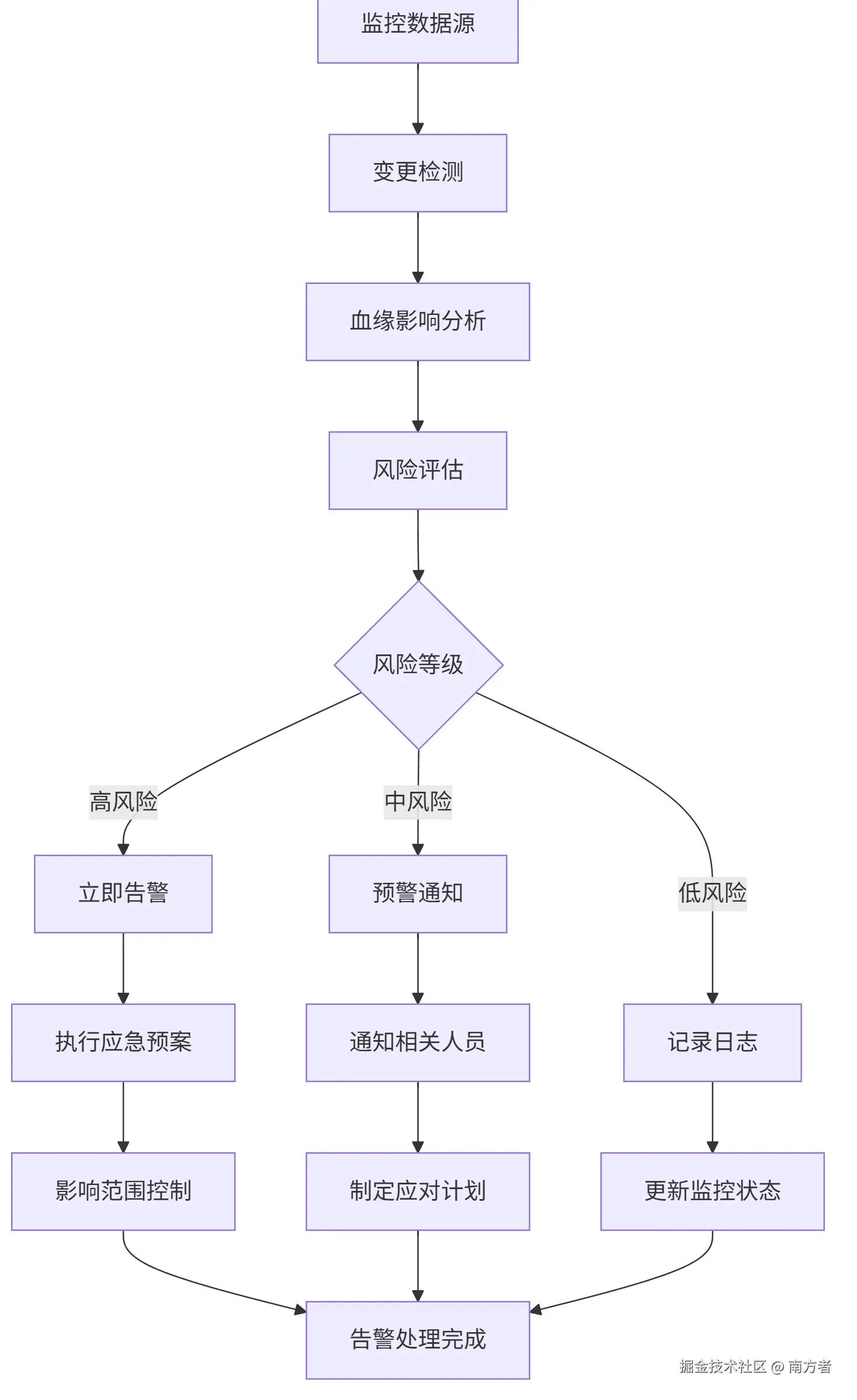
print(f"发现的问题: {len(quality_result['issues'])}个")📖 实时监控与告警
5.1 监控告警流程图
5.2 实时监控实现
python
class RealTimeLineageMonitor:
def __init__(self, kafka_config, lineage_graph, alert_service):
self.consumer = KafkaConsumer(
kafka_config['topic'],
bootstrap_servers=kafka_config['bootstrap_servers'],
value_deserializer=lambda m: json.loads(m.decode('utf-8'))
)
self.graph = lineage_graph
self.alert_service = alert_service
self.monitoring_rules = self.load_monitoring_rules()
async def start_monitoring(self):
"""启动实时监控"""
print("启动血缘关系实时监控...")
for message in self.consumer:
try:
# 处理变更事件
await self.process_change_event(message.value)
except Exception as e:
print(f"处理监控事件失败: {e}")
# 发送监控错误告警
await self.send_monitoring_alert(
"MONITORING_ERROR",
f"处理变更事件时发生错误: {str(e)}",
"HIGH"
)
async def process_change_event(self, event):
"""处理数据变更事件"""
event_type = event.get('event_type')
resource_type = event.get('resource_type')
resource_name = event.get('resource_name')
# 分析变更影响
impact_analysis = await self.analyze_change_impact(
event_type, resource_type, resource_name
)
# 评估风险
risk_assessment = self.assess_change_risk(impact_analysis, event)
# 触发相应动作
await self.trigger_actions(risk_assessment, event)
async def analyze_change_impact(self, event_type, resource_type, resource_name):
"""分析变更影响范围"""
if resource_type == 'TABLE':
# 表级别影响分析
impact_paths = self.graph.query_impact_analysis(resource_name)
# 计算影响范围
impact_scope = {
'direct_impact': self.get_direct_dependencies(resource_name),
'indirect_impact': self.get_indirect_dependencies(resource_name, depth=3),
'critical_assets': self.identify_critical_assets(impact_paths),
'business_impact': self.assess_business_impact(impact_paths)
}
return impact_scope
elif resource_type == 'COLUMN':
# 列级别影响分析
impact_paths = self.graph.query_impact_analysis(None, resource_name)
return {
'column_impact': impact_paths,
'affected_reports': self.find_affected_reports(resource_name),
'data_quality_impact': self.assess_data_quality_impact(resource_name)
}
# 启动监控服务
async def main():
monitor = RealTimeLineageMonitor(
kafka_config={'bootstrap_servers': 'localhost:9092', 'topic': 'data-changes'},
lineage_graph=lineage_graph,
alert_service=alert_service
)
await monitor.start_monitoring()📖 影响分析与根因追踪
6.1 影响分析流程图
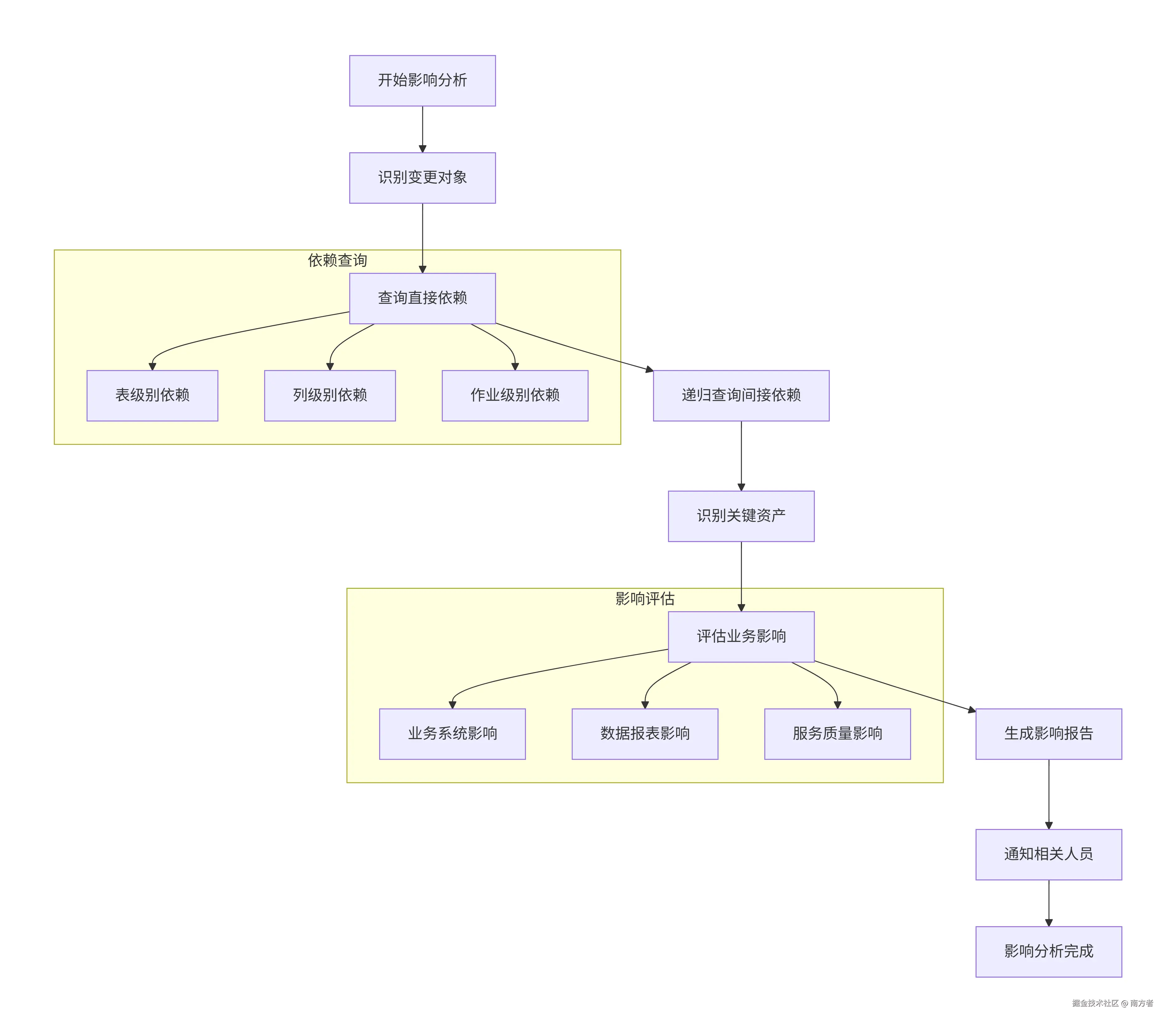
6.2 根因分析流程图
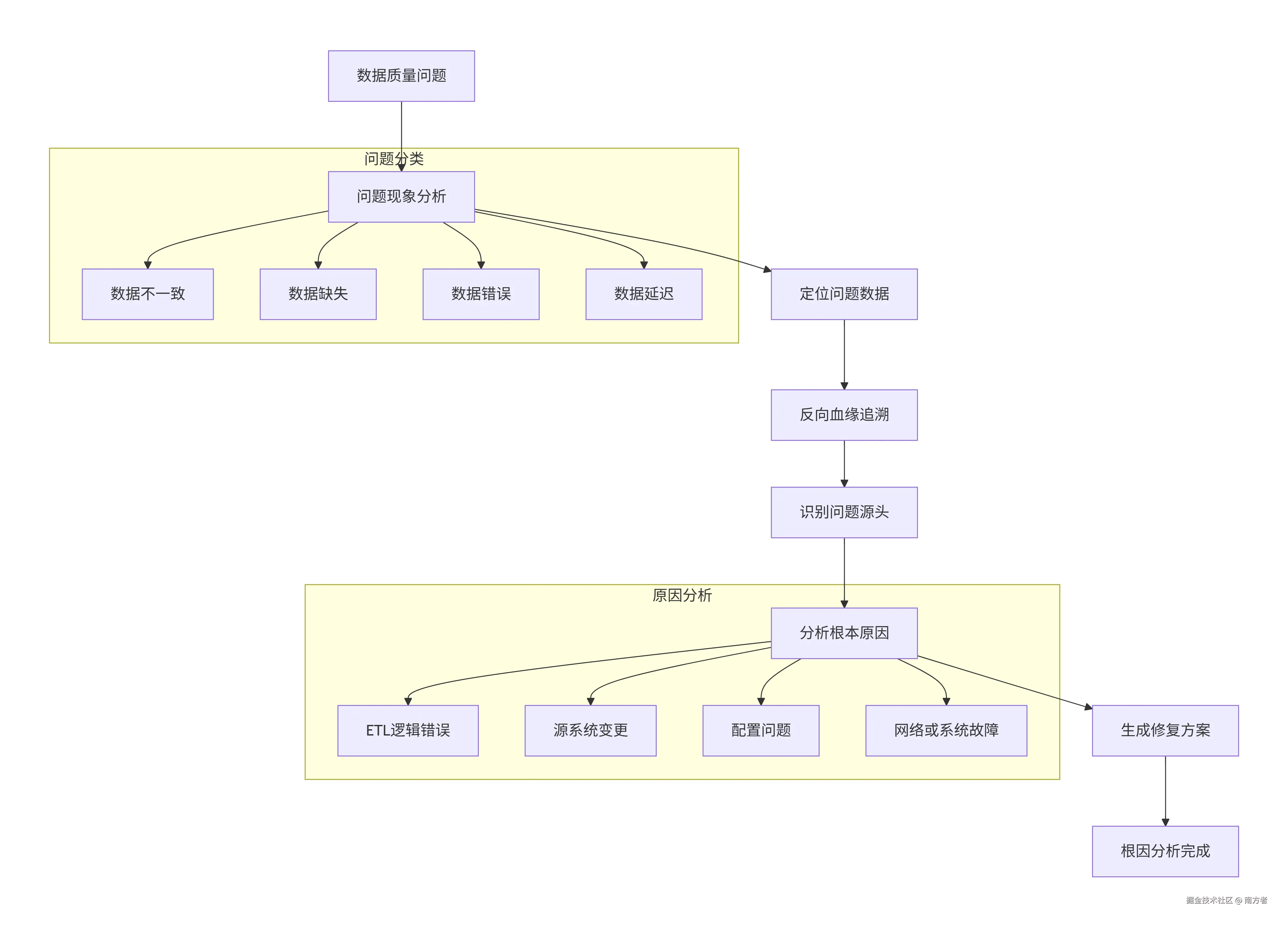
最后
这个增强版方案的核心在于利用 AI 技术(如 Amazon Bedrock 的 LLM 模型)提升血缘分析的自动化与智能化水平,准确解析复杂的数据逻辑,同时借助图数据库(Neptune)实现高效的血缘关系管理和分析。数据血缘系统通过构建透明、可信的数据链路,有效提升数据驱动决策的信心。
☞☞【传送门】
以上就是本文的全部内容啦。最后提醒一下各位工友,如果后续不再使用相关服务,别忘了在控制台关闭,避免超出免费额度产生费用~
- GitHub 代码仓库:sample-agentic-data-lineage
- 样例数据模型与模式结构,来源于 dbt-labs/jaffle-shop-classic
- Dbt-colibri: A lightweight, developer-friendly CLI tool and self-hostable dashboard for extracting and visualizing column-level lineage from your dbt projects.
- 仅供概念验证(POC)使用,不适用于生产环境