概述
本文是笔者的系列博文 《Bun技术评估》 中的第二十二篇。
在本文的内容中,笔者主要想要来探讨一下Bun中的Stream数据流相关的问题。
这个问题本来应该在系列文章讲二进制的那篇中探讨的,其实也有简单涉及,但考虑到篇幅的限制,价值内容相对独立,还有这个技术在Nodejs/Bun生态中的重要性,觉得是有必要进行专门的讨论的。
Stream的简单理解
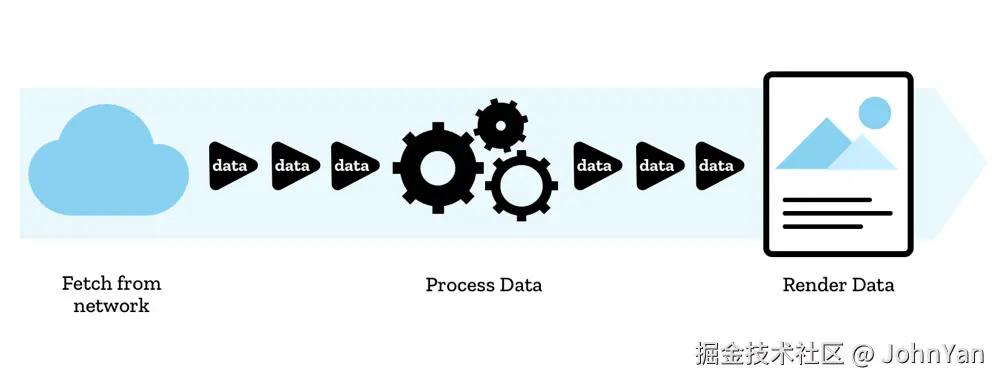
Stream即数据流。笔者的理解,它的基本思想就是,如果要处理的数据非常大(比如视频文件、很大的数据库记录集)等等,可能系统没有能力一次性整体的处理,这时可以考虑将其分解成为一系列连续而有序的小数据块来进行操作者,一次只处理这一小片,那么对于系统而言的压力和能力要求就不会那么高了。这种连续而又有序的小型数据片段,就像山中的小溪一样,被称为数据流,简称为流(Stream),还是非常贴切和形象的。
Stream是一种非常重要的软件工程思想,它的本质就是分解和分治,无论是巨大的数据,或者是复杂的问题,可以用某种方式,将其分解称为一系列小型的数据集合和功能模块,从而构造一个可以扩展的系统,并能够处理和解决越来越庞大负载的系统和数据。
Stream最大的意义就是在工程上,通过特殊的过程和方法,可以有能力处理原本由于资源限制无法处理的数据。从而使系统的运行和资源使用(主要是内存占用),降低到一个可以接受的水平,从而保证系统平稳正常运行,而不会由于资源超载而崩溃。
当然,Stream的应用,也是有一定的条件和限制的。就是需要这个大型的数据和问题,是可以被进行切分的,数据中的不同片段,来逻辑上是不相互干扰和影响的,最后的处理结果,也可以组合起来形成一个完整的逻辑结果的。所以并非所有大型数据和处理,都可以应用Stream的方法。这一点,需要我们能够正确的理解和体会,并应用到适当的场景当中。
在软件工程上,Stream是一个通用的思想和方法。当然落实到具体的应用中,它们也分别有具体的技术定义和实现。比如在Web技术体系中,Stream也是一个非常重要的标准化的技术。体现在在比较新的Web API标准中,是包括了Stream的相关部分的。比如下面这段内容,就是在MDN中,例举的一个典型的在浏览器中如何进行数据的流处理的案例:
就是实际上,在经典的HTTP请求/响应模式中,响应数据数据的传输,其实就是围绕着响应数据流的构造和操作展开的。例如,一个成功的 fetch 请求返回的响应体可以暴露为ReadableStream,之后你可以使用 ReadableStream.getReader() 创建一个 reader 读取它,使用 ReadableStream.cancel() 取消它等等。
方法论
由于这个相关的需求和问题都非常经典,所以随着大量长期的应用和实践,在各种开发场景中,对于数据流的处理,已经形成了比较完善和一致的方法论,通常认为基于此方法论的概念、表述和具体技术实现,是比较合理的。
第一个要理解的几个核心概念,笔者认为应该是Source、Sink和Pipe:
- Source 源
Source代表数据从哪里流出。比如一个文件、一个网络连接、一个传感器。它是数据的起点。
- Sink 汇
Sink的原意是"水池",就是汇集的目的地。在IT术语中,就是数据汇/接收器,是数据流动的"终点"或"目的地"。比如另一个文件、另一个网络连接、或者内存中的一块缓冲区(比如 ArrayBufferSink)。它是数据的终点。
- Pipe 管道
管道,就是一种数据形态转换的抽象。通过管道,程序可以读取Source和拆分后的数据片段,或者写入数据片段后传输到Sink。
结合起来看,整个数据流可以看作: Source → Pipe → Sink。
接下来,就是数据流动的方向和处理的机制。无论是数据源和数据汇,要使数据流动起来,就必须有一个管道,这时我们就可以看出来,如果这个管道用于从源中读取数据,那么它就是一个"读取流",读取的过程中,它会将数据进行分片来方便处理;而如果它控制数据流向汇,它就是一个写入流,同样,写入的过程也应当是可控的分片传输。这两种操作,都需要有一套相应的标准化的处理和控制方式。
这样说起来还是比较抽象。笔者看到有一个很形象的比喻,就是汽车工厂的流水线操作。这里有两种类型的流水线。一种是将从上游企业运来的半成品包装进行拆包,分解成一个个的小的原始零件,送到后续工序进行加工或者组装;还有一类是将各种零部件,在流水线上,组装成为最后的整车。这两种就可以类比成为读取流和写入流。

基于上述概念和理解,我们就可以将其抽象总结成程序实现中的一些具体的类和方法:
- ReadableStream(RS) 可读取流对象
定义了可以用于读取数据源的一种机制。这是一个虚拟的数据管道,起始一头是源,管道的另一头会产生分片的数据,提供给读取器进行读取和处理。
在上面的例子中,可读流就是那个用于零件拆包和分发的传送带。它可以将零部件从大包装中拆出来,放在传送带上,并由传送带上的工人取走进行后续加工和处理。
RS的标准方法,包括start()开始、cancel()取消、getReader()获得读取器等等。
- Reader(RD) 读取器
读取器可以读取拆分后的数据,然后根据业务需求进行加工和处理。业务系统可以在这里实际定义数据的转换和操作方式。这样就实现了业务和stream范式的解耦。
RD的标准方法,包括cancel()读取、read()读取等。
在上面的例子中,读取器就是传送带旁边的工人,他基于需求,从传送带上取下(读取)自己需要的零件,进行加工和处理。
- ReaderController(RC) 控制器
可以定义数据拆分和策略和行为,并在流数据读取时,可以进行相关的控制。如读取操作、暂停、分片的大小、水位控制等等。
在工厂示例中,控制器就是在拆包流水线源头工作的拆包工人。他负责将包装好的零件从包装中拆出来,并放在流水线上,显然,他可以控制拆包程度(大小),速度,或者在发现传送带堆积时,暂停工作等等。
RC的主要方法是enqueue()入队,它可以用于手动控制向管道中放入数据,由于这些数据是有序的,所以使用队列的形式。
但通常情况下,这个控制器是自动工作的,并不需要开发者编写程序进行设置或者干预。在读取流机制创建之后,它就可以按照默认的设定启动,立刻开始数据源读取和分片的传输。当然,它可能也会按照流量控制策略,在数据流消费无法匹配(取决于读取器的能力和缓冲区状态)的情况下,减慢或者暂停读取工作。一般情况下,这些策略都内置在流的实现程序当中,自动执行。
- WritableStream(WS) 可写流对象
基本上是可以看成读取流的"镜像模式"或者"逆模式"。就是写入器每次只写入一小片数据,然后就可以在流的目标对象上逐渐组装成为完整的数据。
在工厂示例中。写入流对象就是总装流水线。它负责连接生产零部件的工人和总装的工人,将零部件组装成为产品。
WS的标准方法,可能包括abort()撤销、close()关闭和getWriter()获得写入器等等。
- Writer 写入器
写入器,负责将数据片段写入流水线,这些数据会在最后组合成为最后的完整数据。这些数据通常由业务系统产生和操作。
在工厂示例中,写入器就是在总装流水线旁边工作的工人。他们负责将加工好的零部件放在流水线上,传输到最后的组装工人那里,进行组装。
WT的标准方法包括write()写入、close()关闭等等。
- WriterController 写入控制器
写入控制器在管道的尽头工作,将来自管道的数据自动组合起来,形成最终结果。
和读取控制器类似,写入控制器的工作也是自动运行的,正常情况下,开发者不需要进行额外的配置和管理。
在工厂示例中,写入控制器,就是总装功能,它组装来自传送带上的零部件,然后按照规则,将此组装成最终的产品。这个步骤通常是自动化的不用业务系统进行干预和控制。
- TransformStream 转换流
大部分数据流的完整处理过程,其实是一个数据流和数据汇的完整转换操作。因为对于各种业务而言,数据流和数据片段只是为了高效和安全处理的中间环节,所以通常这些数据流都是组合起来使用的,就是所谓转换流。转换流其实就是一个写入流,但它的数据来源就是一个标准数据源,而非一个写入器。
还是以工厂作为示例。这时从零件包装,到成品出产,就使用同一条流水线了。工人在流水线上取出零件,然后进行加工,随即立即放回到流水线上,然后在流水线的尽头,就可以组装成最后的成品。
- TransfromController 转换流控制器
数据片段的转换,发生在转换控制器当中。控制器可以从流中获得原始数据片段,处理后,再将处理后的片段写入转换流。
显然,转换流是不需要所谓的Reader或者Writer的,因为它相关的处理,都在内部完成,在定义流的时候就提供了,不会暴露在外部。
现实场景中,常见的转换流控制器实现,包括数据压缩、数据加密和解密、数据编码和解码等等,很多编程系统直接提供了内置实现了这些机制的转换流,开发者可以直接应用在业务系统当中。
- Pipe 管道(泵)
Pipe,原意是管道的意思。在Unix系统中,是一个非常重要的技术和概念(|管道操作符)。它可以将任意命令的输出结果,作为另一个命令的输入,这样极大的提高了系统的灵活性和可扩展性,让系统管理人员可以在不编写程序的情况下,仅仅通过命令的组合,就可以完成很多系统维护、管理和数据处理的工作。
数据流Stream参考了这个重要的思想,增加了管道的机制,通过定义通用的接口和方法,就可以将流连接起来。最常见的情况,就是将读取流和写入流连接起来,读取流输出的数据片段,直接流动到另一个写入流当中进行处理,这个通常用于简化开发,和将数据流的处理简化和模块化,来满足各种不同的需求和场景。
上面就是通用的Stream相关的概念和方法,在不同的程序和系统中,它们应当只是在实现细节上略有差异。下面我们就可以具体探讨在Bun中的相关技术和实现了。
Bun的Stream实现
在Bun中,对于流处理提供了一套比较完善的API,它实现了Web API的ReadableStream和WritableedStream。并且也通过node:stream兼容模块,实现了兼容的Readable、Writable、Pipeline和Duplex(双工)等方法。
注意这里的说法,就是Bun并没有完全独立的创建一套新的实现,而是采用了和标准Web API兼容的做法,这个做法,最大程度的降低了前后端程序兼容的问题,是一个非常好的开发体验。
ReadableStream 读取流
我们先来看一看标准模型:
js
// 创建流和写入内容
const stream = new ReadableStream({
start(controller) {
controller.enqueue("hello");
controller.enqueue("world");
controller.close();
},
});
// 读取流
for await (const chunk of stream) {
console.log(chunk);
}从这个示例我们可以看到,Bun的实现,简化了Reader的使用,可以直接将stream作为Reader来使用。所以这个模式很简单,先创建一个ReadableStream实例。这时可以传入一个带有start方法的参数,它会在流创建时被调用执行,同时传入一个contrller对象;程序可以使用这个控制器来操作数据,或者关闭数据流。这个流实例,同时也是一个读取器,遍历流,就可以获取数据片段队列。
然后我们来看一个更实用的示例。这也是一个比较典型的应用场景,就是作为文件服务,基于请求,响应一个大型文件的内容。为了降低其内存占用,可以使用流化的方式来实现。
js
const filePath = './very-large-file.txt';
Bun.serve({
port: 3000,
async fetch(request) {
const file = Bun.file(filePath);
if (!await file.exists()) {
return new Response('File not found', { status: 404 });
}
// 创建可读流
const readableStream = new ReadableStream({
async start(controller) {
try {
const fileHandle = await Bun.file(filePath).arrayBuffer();
const chunkSize = 1024 * 64; // 64KB 分块
const data = new Uint8Array(fileHandle);
for (let i = 0; i < data.length; i += chunkSize) {
const chunk = data.slice(i, i + chunkSize);
controller.enqueue(chunk);
// 可以添加延时模拟网络传输
// await Bun.sleep(10);
}
controller.close();
} catch (error) {
controller.error(error);
}
}
});
return new Response(readableStream, {
headers: {
'Content-Type': 'text/plain',
'Content-Length': file.size.toString(),
'Transfer-Encoding': 'chunked'
}
});
}
});简单说明一下:
- 可以将读取流对象,作为Bun HTTP Server的响应内容,这时Bun会将响应信息进行流化处理传输到客户端
- 需要在HTTP响应头中,声明响应形式为"chunked",即数据流
- 通过重写读取流的start方法,定义如何进行读取
- start的参数,就是当前的controller,用于控制数据入队操作
- 程序中模拟了分片读取文件内容的操作,此处可以控制每次读取数据的大小
- 调用控制器的enqueue(入队)方法,向目标传输数据片段
上面的示例,其实是使用程序控制模拟了分片读取的操作,其实在bun中,可以直接将file转化成为读取流(无需手动创建流和入队操作),它可以自动创建一个读取流,并进行默认的入队操作:
js
try {
const file = Bun.file(filePath);
const fileStream = file.stream();
return new Response(fileStream, {
headers: {
'Content-Type': file.type || 'application/octet-stream',
'Content-Length': file.size?.toString() || '',
'Content-Disposition': `attachment; filename="${file.name}"`
}
});
} catch (error) {
return new Response('File not found', { status: 404 });
}其实,bun中,还有更简单的方式,就是直接使用bun file对象,它也会使用自动使用流化方式工作,简单而高效:
js
Bun.serve({
port: 3000,
async fetch(request) {
const file = Bun.file(filePath);
// 直接返回文件对象,Bun 会自动处理流式传输
return new Response(file);
}
});WriteableStream 写入流
使用流化的方式,从一个HTTP服务器上下载文件,并保存到本地,就是写入流的一个典型的应用场景。在Bun中的参考示例代码如下:
js
async function downloadFileStreamed(url, filePath) {
const response = await fetch(url);
if (!response.ok) {
throw new Error(`HTTP ${response.status}: ${response.statusText}`);
}
// 获取文件大小(用于进度显示)
const contentLength = response.headers.get('content-length');
const totalSize = contentLength ? parseInt(contentLength) : null;
let downloadedSize = 0;
const writer = Bun.file(filePath).writer();
const reader = response.body.getReader();
try {
while (true) {
const { done, value } = await reader.read();
if (done) break;
// 写入数据块
writer.write(value);
downloadedSize += value.length;
// 显示下载进度
if (totalSize) {
const progress = (downloadedSize / totalSize * 100).toFixed(1);
console.log(`Download progress: ${progress}% (${downloadedSize}/${totalSize} bytes)`);
}
}
writer.end();
console.log(`Download completed: ${downloadedSize} bytes`);
} catch (error) {
writer.end();
throw error;
} finally {
reader.releaseLock();
}
}简单说明和分析:
- 流写入,需要先创建一个写入流
- Bun.file本身就可以创建一个写入流,然后获取其Writer
- 写入的内容,其实来自http request的response body的streamReader
- 读取器循环读取数据片段后,立即执行write方法,写入目标文件
- read方法,可以返回读取操作是否已经完成,作为循环中断的依据
- 跳出循环后,使用end方法,关闭writer,释放资源
Bun流下载写入文件,也有简单形式,它会自动以流化方式进行操作:
js
// 最简单的方式 - Bun 自动处理流式传输
async function downloadFileSimple(url, filePath) {
try {
const response = await fetch(url);
if (!response.ok) {
throw new Error(`HTTP ${response.status}: ${response.statusText}`);
}
// Bun.write() 会自动处理流式写入
const result = await Bun.write(filePath, response);
console.log(`Download completed: ${result} bytes written`);
return result;
} catch (error) {
console.error('Download failed:', error.message);
throw error;
}
}Transform Stream 转换流
Transform也是标准Web API,所以下面的示例来说MDN。
js
const stream = new TransformStream({
transform(chunk, controller) {
controller.enqueue(chunk.toUpperCase());
},
});
// Write data to be transformed
const writer = stream.writable.getWriter();
writer.write("hello ");
writer.write("world");
writer.close();
// Read transformed data
const reader = stream.readable.getReader();
let done = false;
let output = "";
while (!done) {
const result = await reader.read();
if (result.value) {
output += result.value;
}
done = result.done;
}
console.log(output);从示例代码的结构,笔者感觉,这个TransformStream就是在内部同时使用了一个读取流和一个写入流。然后暴露一个一个transform回调方法。这个方法回调时,会传入两个参数,trunk就是输入的数据片段,还有一个控制器可以用于在数据处理后,调用enqueue方法输出结果数据片段。
要控制Transform的输入,可以先获取转换流实例的写入器,然后像普通的写入流一样写入数据片段;同样,要获取转换流的输出,可以通过获取转换流的读取器,并循环调用其read方法来实现。读取的内容,包括转换后的数据片段,和结果状态,用于控制结束读取过程。
Pipe 管道操作
在流技术中,管道操作,就是将流直接连接起来,简化实现和管理。
笔者认为,下面这个MDN提供的示例比较有代表性,可以很好的帮助我们来理解和分析这个问题:
js
const upperCaseStream = ()=> new TransformStream({
transform(chunk, controller) {
controller.enqueue(chunk.toUpperCase());
},
});
const appendDOMStream = (el)=> new WritableStream({
write :(chunk)=> el.append(chunk)
});
fetch("./lorem-ipsum.txt").then((response) =>
response.body
.pipeThrough(new TextDecoderStream())
.pipeThrough(upperCaseStream())
.pipeTo(appendDOMStream(document.body))
);这个示例中,定义和使用了三种不同类型的流:
- 一个系统内置的文本解码流,这其实是一个转换流,将二进制数据解码成文本
- 一个转换流,可以将输入的文本,转换成为大写
- 一个写入流,重写了写入规则,将数据片段内容,扩展到一个DOM元素当中
这里的主要内容,其实是如何使用Pipe来处理流:
- Pipe方法,是readStream对象提供的接口方法,用于连接其他的流
- PipeThrough,表示连接一个转换流,它可以接收读取流的内容,进行转换操作,输出结果,还是一个读取流,然后就继续连接下一个处理环节
- PipeTo, 表示连接一个写入流,一般在处理的最后一个环节使用
所以这段代码实现的功能是:
- 请求一个网络地址
- 使用读取流方式,获取响应内容
- 使用文本解码流,将响应内容,进行UTF8文本解码,输出解码后的文本流
- 使用自定义的文本转换流,将输入文本流,转换成大写,并输出转换后的文本流
- 最后一步,输出到一个写入流,它可以扩展DIV的内容
在这个过程中,我们应该可以理解到,使用Pipe来连接转换流和写入流,可以非常灵活的实现业务处理的需求,体现在其模块化、解耦和可插拔性,非常流畅和优雅。
Duplex 读写流(双工流)
Duplex的原意是双工的意思,在通信协议和术语中,就是只一个通道,即可以读,也可以写。典型的通信双工通道,就是TCP连接,当连接建立成功之后,双方都可以同时收发信息进行通信。
作为流而言,Duplex流是一个同时可读又可写的流。 笔者虽然不是特别清楚其实现机制,但简单构想,可能并不是一般想象的那么复杂。最简单的方式,就是在同一个流对象里面,包含一对读写流组合起来,分别负责收发信息,就可以双工的效果。就像以太网网线(下图)的定义一样,一对网线负责发送信息,另一对负责接收信息,但都包装在一起,看起来就是同时收发了。

下面这个示例,展示了读写流是如何定义的:
js
const { Duplex } = require('stream');
class MyDuplex extends Duplex {
_read(size) {
// 实现读取逻辑
this.push('一些数据');
this.push(null); // 结束流
}
_write(chunk, encoding, callback) {
// 实现写入逻辑
console.log('写入:', chunk.toString());
callback(); // 表示写入完成
}
}
const duplex = new MyDuplex();Bun没有实现读写流方面的内容,它是基于Nodejs的Duplex实现的。这里就不展开讨论了。
Bun内置和兼容流
简单的总结一下,在Bun中,内置的流实现相关技术和类包括:
- ReadableStream,内置读取流类
- WritableStream,内置写入流类
- TransformStream,内置转换流类
- 服务端,Request处理,HTTP的请求内容,可以作为流读取, Request.body.stream()
- 服务端,Response对象,响应内容构造时可以传入一个读取流
- 客户端,Request操作,请求内容,可以传入写入流作为参数
- 客户端,Fetch Response,可以使用stream()作为流读取
- Bun.file().stream(), 表示一个文件读取流
- Bun.file().write(),可以将写入流作为参数
- Bun兼容部分Nodejs流API(例如可以访问 node:stream / stream.Readable.from 等),但部分细节可能有差异,要小心使用
- ArrayBufferSink(ABS),数组缓存汇, 后详
- Async Generator Streams (AGS), 异步生成器流,后详
可以看到,Bun本身提供的流特性已经足够丰富和强大,基本上可以满足各种应用场景的需求。所以基于篇幅和内容的原因,这里暂时就不讨论和nodejs流技术兼容的问题了。
Bun stream 高级特性
除了标准的数据流操作之外,Bun还提供了一些相关技术,可以在特定场景下,简化开发和使用。
Direct Readable Stream(DRS) 直接读取流
DRS是Bun提供的一个优化版本的ReadableStream。在签名的代码中,我们可以看到,写入数据块时,默认使用enqueue方法,就是加入队列,然后进行操作。这个过程中,每个数据块都会被先复制到队列中进行等待,直到流准备发送更多数据时才被处理。DRS可以直接写入目标,避免了不必要的数据复制和队列管理逻辑,更加简单高效。
DRS的标准应用方式如下:
js
const stream = new ReadableStream({
type: "direct",
pull(controller) {
controller.write("hello");
controller.write("world");
},
});简单说明一下:
- 需要指定类型为 direct
- 需要重写pull方法
- 注意调用的是controller的write方法,而非enqueue
为什么提供DRS? 笔者认为是Bun提供的一个在简单应用场景下的更适合的选择。DRS的优势是简单直接,资源占用更小;缺点是缺乏更完善的队列控制机制。选择直接流还是缓冲流需要根据具体的应用场景和性能要求进行权衡:如果开发者能够确保应用的场景和环境(业务流程短,并且可控),就可以选择DRS;否则如果需要在复杂的网络和应用场景中工作,就应当选择标准RS,它可以使数据流的处理更加稳定平滑。
Async generator streams (AGS) 异步生成器流
AGS是基于生成器模型的流操作技术。我们先来看一个示例:
js
// 异步方法
const response = new Response(
(async function* () {
yield "hello";
yield "world";
})(),
);
await response.text(); // "helloworld"
// 异步迭代器对象
const response = new Response({
[Symbol.asyncIterator]: async function* () {
yield "hello";
yield "world";
},
});
// 带控制器
const response = new Response({
[Symbol.asyncIterator]: async function* () {
const controller = yield "hello";
yield " ";
yield "Word!";
await controller.end();
},
});这里面没有使用数据流类和对象,而是直接使用了生成器模式Generator,也能够实现类似的功能,并且为Bun的流兼容。
ArrayBufferSink 数组缓冲汇
Bun.ArrayBufferSink类是一个用于构建未知大小ArrayBuffer的快速增量写入器。它可以使用流化的方式,构造和处理无法预知结构的ArrayBuffer数据,更方便和高效,因为传统方式可能需要手动合并拼接数据,并且频繁的分配和释放内存。
ABS的标准应用方式如下:
js
const sink = new Bun.ArrayBufferSink();
sink.start({
stream: true,
});
sink.write("h");
sink.write("e");
sink.write("l");
sink.flush();
// ArrayBuffer(5) [ 104, 101, 108 ]
sink.write("l");
sink.write("o");
sink.flush();
// ArrayBuffer(5) [ 108, 111 ]ArrayBufferSink的类定义如下:
js
/**
* Fast incremental writer that becomes an `ArrayBuffer` on end().
*/
export class ArrayBufferSink {
constructor();
start(options?: {
asUint8Array?: boolean;
/**
* Preallocate an internal buffer of this size
* This can significantly improve performance when the chunk size is small
*/
highWaterMark?: number;
/**
* On {@link ArrayBufferSink.flush}, return the written data as a `Uint8Array`.
* Writes will restart from the beginning of the buffer.
*/
stream?: boolean;
}): void;
write(chunk: string | ArrayBufferView | ArrayBuffer | SharedArrayBuffer): number;
/**
* Flush the internal buffer
*
* If {@link ArrayBufferSink.start} was passed a `stream` option, this will return a `ArrayBuffer`
* If {@link ArrayBufferSink.start} was passed a `stream` option and `asUint8Array`, this will return a `Uint8Array`
* Otherwise, this will return the number of bytes written since the last flush
*
* This API might change later to separate Uint8ArraySink and ArrayBufferSink
*/
flush(): number | Uint8Array<ArrayBuffer> | ArrayBuffer;
end(): ArrayBuffer | Uint8Array<ArrayBuffer>;
}其中有一些值得注意的细节:
- flush需要和stream类型配合使用,实现复用内部缓冲区的效果
- highWaterMark,可选背压设置参数,可能需要根据业务特点和实际情况来进行调节
- asUint8Array, 可选返回字节数组,默认是ArrayBuffer(纯二进制数据)
HighWaterMark(HWM)高水位线
虽然在绝大多数情况下,Bun中的流都是可以自动工作的。但作为开发者,需要理解控制器运行并影响稳定性的一个重要的概念,就是HighWaterMark,直译是高水位标记,还有一个更加学术的术语,叫"背压"。
本质上而言,所有的流技术,为了提高传输性能,都会设计一个内部缓冲区,以利于批量传输数据。这个HWM,应该就是指这个缓冲区的大小,和相应配套的流量控制策略。
HWM设置其实没有一定之规,取决于应用场景。通常认为,大文件传输的场合,应当适当提高HWM;频繁小片数据传输或者内存敏感的场景,可以考虑减小HWM来降低内存使用。Bun默认的HWM是16K。而且修改HWM好像不能直接通过参数设置,而是需要通过更底层的设置来实现。
小结
本文探讨了数据流相关的技术,包括Stream的基本原理,核心概念,方法论和标准模型等。随后结合Bun中相关的内容,展示了在Bun中的实现方式,和一些实际的应用场景。最后还扩展了Bun提供的流相关的技术和机制。