随着物联网、工业互联网和运维监控领域的快速发展,时序数据处理的需求正以前所未有的速度增长。面对海量设备产生的持续数据流,企业急需一个既能高速写入又能快速分析的数据库引擎。
长期以来,InfluxDB 以其在时序领域的先发优势和简洁设计,成为许多团队的首选。然而,当数据规模从"万级"跃升至"千万级",业务查询从简单的点查变为复杂的多维度聚合时,InfluxDB 的性能瓶颈开始显现。
如今,国产数据库金仓(KingbaseES)与国际开源时序方案 InfluxDB 之间的性能较量,正在悄然改变行业格局。
一、真实测试见真章:复杂场景下性能优势显著
金仓数据库基于业界公认的开源时序基准测试套件 TSBS,与 InfluxDB 展开了多轮性能对比。测试结果清晰表明:在小规模、简单查询场景下,两者表现接近;但在大规模、复杂分析的真实生产环境中,金仓呈现出压倒性优势。
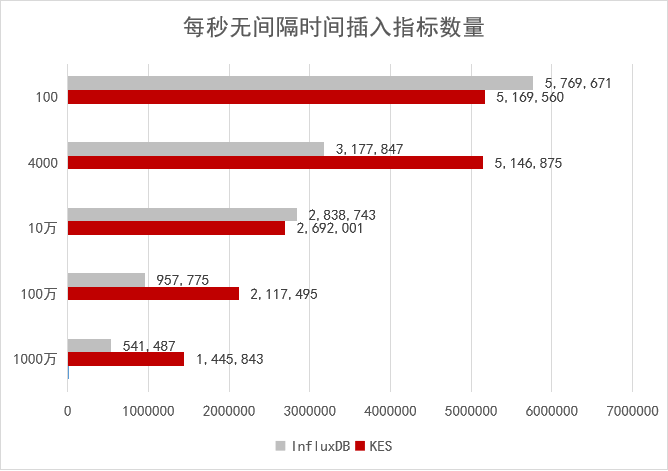
写入吞吐:规模越大,优势越明显
测试模拟了从 100 台到 1000 万台设备的数据写入压力。当设备数达到 4000 台(每台 10 个指标)时,金仓的每秒数据插入指标数已是 InfluxDB 的162% ;在千万级设备的极限压力测试中,性能优势进一步扩大至267%。这说明金仓在高并发持续写入场景下,具备更强的扩展性和稳定性。
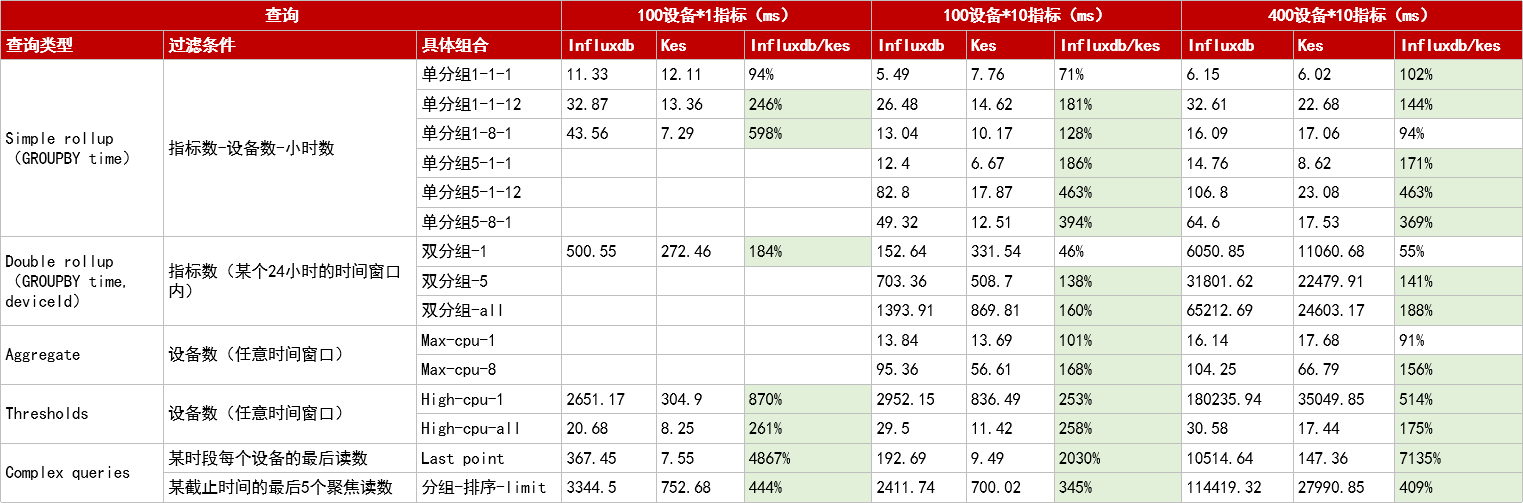
查询性能:复杂查询拉开数量级差距
在查询性能方面,两者在简单聚合查询中表现相当,但随着查询复杂度提升,金仓优势逐渐凸显:
- 中等复杂度查询(如跨设备分组、多指标聚合):金仓响应速度可达 InfluxDB 的 3 到 4 倍。
- 高复杂度分析查询 (如 Last point 查询、阈值筛选):金仓性能更是呈现数量级领先。例如,查询 400 台设备的"最后读数"场景中,金仓耗时仅为 147.36 毫秒,而 InfluxDB 需要 10514.64 毫秒,性能领先超过70 倍。
二、不只是跑分强:企业级能力全面领先
金仓的时序能力并非仅为性能而生,其设计目标是成为企业级、多模融合的数据平台,在多个方面解决了 InfluxDB 在实际应用中的短板。
完整 SQL 支持与事务保障
金仓时序功能构建于成熟的关系型数据库内核之上,提供完整的 SQL 语法、存储过程、ACID 事务支持及多表关联查询。这意味着企业无需学习新的查询语言,现有 SQL 生态可无缝接入,大幅降低开发和迁移成本。
相比之下,InfluxDB 需使用 InfluxQL 或 Flux 语言,与企业现有系统集成时存在适配负担。对于金融交易、工控指令等强一致性场景,金仓的事务支持至关重要。
智能存储与生命周期管理
金仓支持基于时间的自动化数据分区与冷热数据分级存储,实测对工业传感器类数据可实现高达1:4 的压缩比,显著降低存储成本。
多模融合:时序+空间+文档一体化查询
金仓支持在同一数据库中,对时序数据、地理信息(GIS)、JSON 文档等类型进行关联查询。例如,智慧交通场景中"查询过去一周机场周边频繁出现的车辆"这类时空联合分析,在金仓中一条 SQL 即可完成,而在 InfluxDB 中则难以直接实现。
三、实战验证:真实业务场景表现优异
金仓时序能力已在多个高要求行业场景中成功落地,支撑起核心业务系统:
- 某大型港口集团:需处理日均数十亿条车辆 GPS 轨迹数据,金仓在实时轨迹查询与区域统计中全面胜出,成为智能调度系统的核心引擎。
- 某新能源企业 :管理上千台风机传感器数据,金仓不仅支持每秒数十万点写入,还能与设备元数据无缝关联,实现一体化查询,复杂分析性能达 InfluxDB 的2 至 70 倍,同时显著降低存储成本。
四、总结:从时序工具到企业数据基座
与 InfluxDB 的对比清晰体现了金仓的价值定位:它不仅是更快的时序数据库,更是以时序为核心的企业级融合数据平台。
如果企业仅需简单的指标存储与展示,InfluxDB 或许足够。但如果业务正向深度分析、复杂关联、系统集成方向发展,金仓提供了更优的解决方案。
金仓不仅在复杂查询性能上实现数倍至数十倍提升,更在事务支持、SQL 生态、多模融合等方面补齐了 InfluxDB 的短板。选择金仓,企业获得的不仅是一个时序存储方案,更是一个能够统一承载时序、空间、业务数据的智能决策底座。
在数据驱动决策的今天,这种从"记录"到"洞察"的能力跨越,正是金仓在时序数据库赛道中给出的有力答案。