最近在生产环境部署Elasticsearch 8.13.2时,遇到了启动失败的问题,查看日志发现是bootstrap启动检查未通过(对应exit code 78)。经过排查,最终定位到两个基础配置问题,这里把完整的排查过程和解决方法分享出来,希望能帮到遇到同样问题的同学。
一、问题背景与日志核心信息
启动ES后,进程很快退出,查看 /data/elk/elasticsearch-8.13.2/logs/elasticsearch.log 日志,关键错误信息如下:
bash
[2025-12-17T11:27:43,258][ERROR][o.e.b.Elasticsearch ] [maria-02] node validation exception
[2] bootstrap checks failed. You must address the points described in the following [2] lines before starting Elasticsearch.
bootstrap check failure [1] of [2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
bootstrap check failure [2] of [2]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured从日志能明确:核心问题是2个bootstrap启动检查未通过 ,这是ES生产环境的强制检查(因为绑定了非本地回环地址192.168.184.152,而非127.0.0.1)。
二、日志关键信息拆解
在解决问题前,先理清日志里的有效信息,避免遗漏关键上下文。
1. 启动初期正常表现
日志开头有几个"正常信号",说明ES基础环境没问题,问题集中在启动检查阶段:
- 持久化缓存索引、弃用功能索引组件加载成功;
- 网络绑定正常,已绑定集群通信端口
9300(地址192.168.184.152:9300); - 因绑定非本地地址,自动触发生产环境
bootstrap检查(测试环境绑定127.0.0.1不会触发)。
2. 两个核心错误详解
错误1:vm.max_map_count系统参数过低
- 当前值:65530,ES要求最小值:262144;
- 作用:这个参数限制了进程可映射的虚拟内存区域数量,ES需要大量内存映射来高效处理索引文件,参数不足会导致ES无法正常加载索引。
错误2:集群发现配置缺失
- 原因:ES默认的集群发现配置仅适用于单机测试,生产环境必须明确集群节点信息,否则可能出现"脑裂"(多个主节点竞争)等问题;
- 要求:至少配置以下任一参数:
discovery.seed_hosts:集群所有节点的IP列表;discovery.seed_providers:节点发现的数据源(如文件);cluster.initial_master_nodes:集群初始主节点的名称列表(日志中节点名为maria-02)。
三、分步解决问题
针对两个错误,分别给出临时和永久解决方案,大家可根据部署场景选择。
1. 解决vm.max_map_count过低问题
方案1:临时生效(重启机器后失效,适合快速测试)
直接执行系统命令修改参数,无需重启ES:
bash
sysctl -w vm.max_map_count=262144方案2:永久生效(修改系统配置文件,适合生产环境)
通过编辑sysctl.conf文件,让参数在机器重启后仍有效:
bash
# 1. 编辑系统配置文件
vi /etc/sysctl.conf
# 2. 在文件中添加或修改以下行
vm.max_map_count=262144
# 3. 加载配置,让修改立即生效
sysctl -p2. 解决集群发现配置缺失问题
需要编辑ES的核心配置文件config/elasticsearch.yml,根据"单机生产环境"或"多节点集群"选择对应配置。
场景1:单机生产环境(仅1个节点)
添加以下配置(节点名用日志中的maria-02,IP用127.0.0.1):
yaml
discovery.seed_hosts: ["127.0.0.1"] # 本地节点IP
cluster.initial_master_nodes: ["maria-02"] # 节点名称(从日志中获取)场景2:多节点集群(示例3个节点)
假设3个节点IP分别为192.168.184.152、192.168.184.153、192.168.184.154,节点名分别为maria-02、maria-03、maria-04,配置如下:
yaml
discovery.seed_hosts: ["192.168.184.152", "192.168.184.153", "192.168.184.154"]
cluster.initial_master_nodes: ["maria-02", "maria-03", "maria-04"] # 所有节点名称四、验证修复与重启ES
两个问题都解决后,按以下步骤重启ES并验证是否成功。
1. 重启ES(建议用非root用户)
先停止残留进程,再启动ES(前台启动方便验证,成功后再切后台):
bash
# 1. 停止可能残留的ES进程
pkill -f elasticsearch
# 2. 前台启动ES(观察日志,确认无错误)
./bin/elasticsearch
# 3. 若前台启动成功,按Ctrl+C停止,再用后台启动(生产环境常用)
./bin/elasticsearch -d2. 验证启动成功
- 关键标志:日志中出现
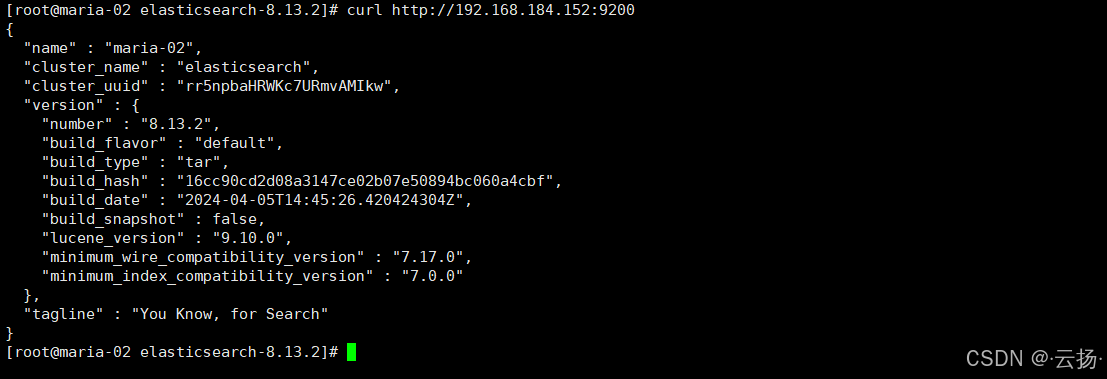
[INFO ][o.e.n.Node ] [maria-02] started,且无ERROR级别的日志; - 额外检查:可通过
curl http://192.168.184.152:9200(9200是ES HTTP端口)访问,返回节点信息即表示正常。
五、总结与注意事项
- 这是ES生产环境启动的常见基础问题,核心是"系统参数不足"和"生产环境配置缺失",并非复杂故障;
- 生产环境部署ES时,一定要先检查
vm.max_map_count、file descriptors等系统参数(可参考ES官方文档); - 集群配置需谨慎,
cluster.initial_master_nodes的节点名必须与实际节点名一致(可通过./bin/elasticsearch --name指定节点名); - 遇到启动失败,优先查看ES日志(路径在
logs/elasticsearch.log),bootstrap check failure类错误通常都有明确的解决指引。
如果大家在操作中遇到其他问题,欢迎在评论区交流~