文章目录
在学习哈夫曼编码之前我们先了解一些前置知识:

下面举个例子,把值分别为1,2,3,4,5的5个叶节点组成一个哈夫曼树,我们先把5个叶结点看成5棵独立的树,此时森林中有5棵树,首先把1,2结点合并形成一颗根为3的新树,此时森林中有4棵树,然后挑选森林中权值最小的两棵子树也就是3和3形成一棵新的子树,新子树的根节点为6,此时森林中有三棵树,依次重复上述步骤形成最后的哈夫曼树,如下图所示:
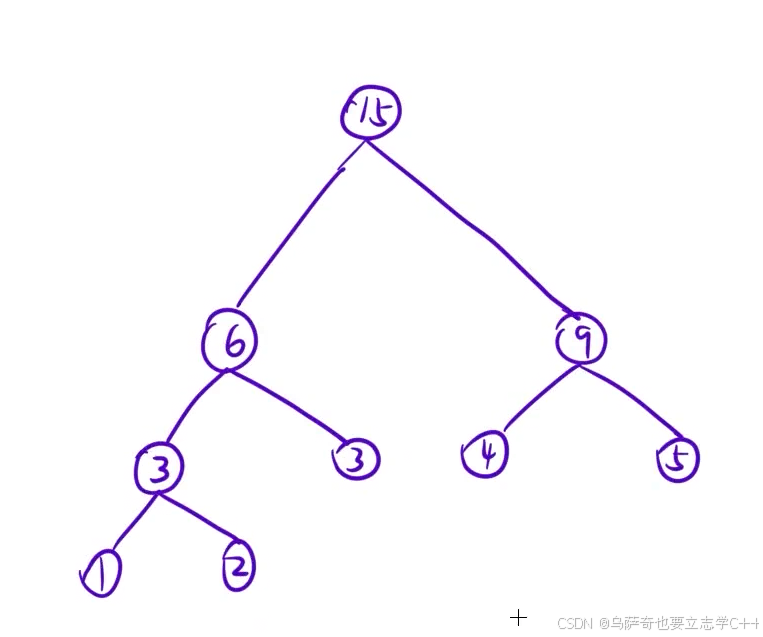
下面再说明一下如何通过上述的哈夫曼是合并操作得到带权路径长度:
33 = 1 + 2 + 3 + 3 + 6 + 4 + 5 + 9
可以简单理解成把合并形成的哈夫曼树除根结点以外的结点的权值全部加起来。
有了上面的前置知识,接下来引入本节的主角哈夫曼编码:

示例如下:
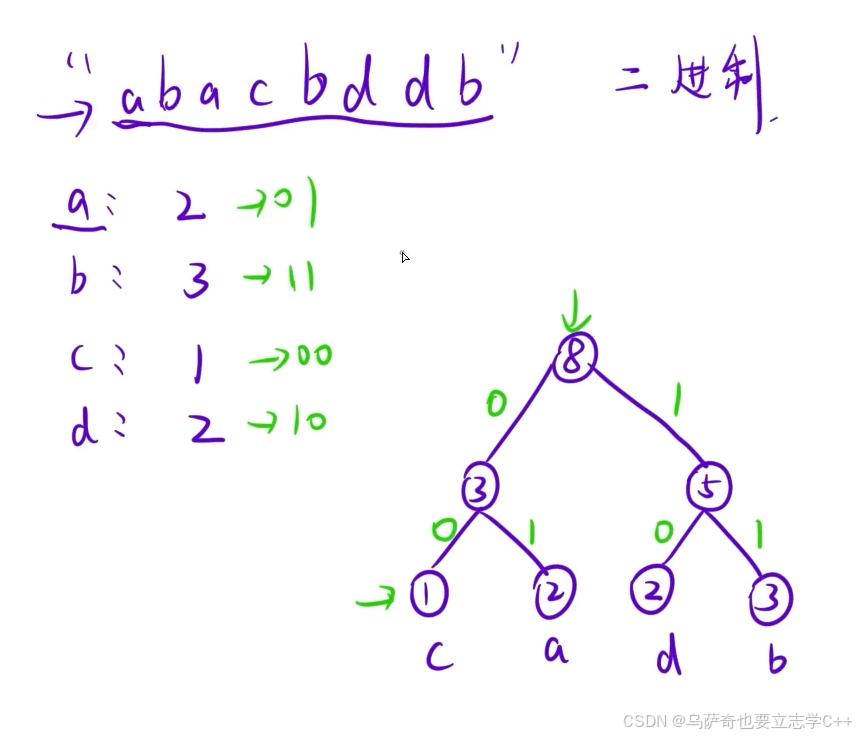
我们首先要知道编码是一种数据压缩的方式,比如上述的示例字符串:"abacbddb",字符串中的每一个字符都是8个比特位,如果我们采取编码操作,让每一个字符都用2个比特位表示的话,如 00 01 10 00 ,就可以进行数据压缩,哈夫曼编码就是一种压缩率最高的编码方式。
根据上面介绍的哈夫曼编码方式(8的左分支为0,右分支为1),我们可以得出a的编码是01,b是11,c是00,d是10,但是哈夫曼树的结构并不是唯一的,下面这棵树同样是哈夫曼树:
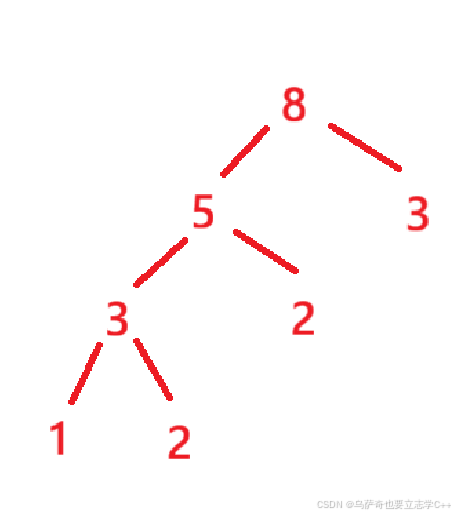
但哈夫曼树的最小带权路径长度是唯一的,并且最小带权路径长度就等于字符串的最短长度(长度 = 每个字符出现次数 * 该字符的哈夫曼编码的比特位数)。
举例补充解释:根节点到叶子结点的路径长度类比字符的编码的比特位数,例如上图红色的哈夫曼树叶子结点1,根节点到叶子结点1的路径长度为3,而它的编码为000,比特位数为3,根节点的权值类比字符出现次数。
哈夫曼编码
题目描述
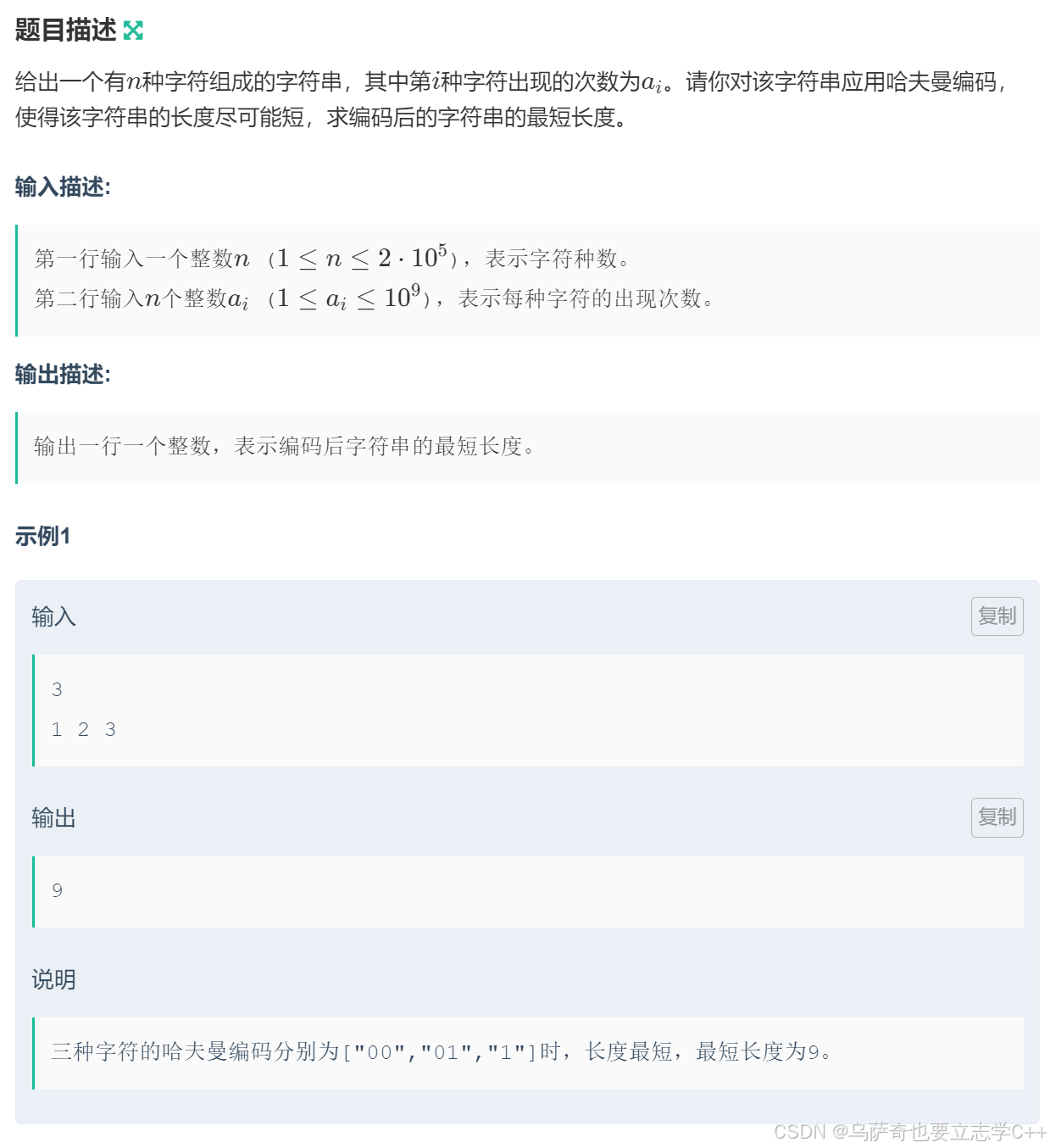
题目解析
本题是哈夫曼编码的简单模板题,需要利用哈夫曼编码解题,哈夫曼编码需要构建哈夫曼树,而构建哈夫曼树需要用到哈夫曼算法,哈夫曼算法的原理是每次都需要取两个权值最小的根结点,所以需要构建一个小根堆存储每种字符出现的次数。求字符串最短长度本质就是求哈夫曼树的带权路径长度,所以每次取两个权值最小的根结点,并把它们出堆,根据计算带权路径长度规则,把它们的和加到ret中,然后把它们的和重新入堆。
代码
cpp
#include <iostream>
#include <queue>
using namespace std;
typedef long long LL;
priority_queue<LL, vector<LL>, greater<LL>> pq;
int main()
{
int n;
cin >> n;
//输入数据,并把数据入堆
while(n--)
{
int a;
cin >> a;
pq.push(a);
}
//计算最短长度
LL ret = 0; //字符串最短长度
while(pq.size() > 1)
{
LL x, y; //取堆中权值最小的两个根结点
x = pq.top();
pq.pop();
y = pq.top();
pq.pop();
ret += x + y;
pq.push(x + y);
}
cout << ret << endl;
return 0;
}合并果子
题目描述
题目解析
本题也是一道简单模板题,思路基本和上题一样。
代码
cpp
#include <iostream>
#include <queue>
#include <vector>
using namespace std;
priority_queue<int, vector<int>, greater<int>> pq;
int main()
{
int n;
cin >> n;
while (n--)
{
int a;
cin >> a;
pq.push(a);
}
int ret = 0;
while (pq.size() > 1)
{
int x = pq.top();
pq.pop();
int y = pq.top();
pq.pop();
ret += x + y;
pq.push(x + y);
}
cout << ret << endl;
return 0;
}以上就是小编分享的全部内容了,如果觉得不错还请留下免费的赞和收藏
如果有建议欢迎通过评论区或私信留言,感谢您的大力支持。
一键三连好运连连哦~~
