当自动驾驶车辆只会"机械模仿",而无法"灵活决策"时,真正的智能就无从谈起。DIVER 框架的核心使命,正是赋予机器这种"思考"和"选择"的能力。
本文深入解析了 DIVER (Reinforced Diffusion for End-to-End Autonomous Driving) ------ 一个将扩散模型 的生成能力与强化学习 的优化目标相结合,以解决自动驾驶规划中 "行为保守" 与 "模式崩溃" 问题的创新性端到端框架。
1. 核心问题:为什么模仿学习会让自动驾驶"畏手畏脚"?
目前主流的端到端自动驾驶系统严重依赖模仿学习 。这种方法存在一个根本性局限:模型学习的唯一目标是最小化与数据集中"唯一"专家轨迹的差距。这导致两个严重后果:
- 行为保守与模式崩溃:模型倾向于生成最"像"专家、最"平均"的轨迹,不敢做出变道、超车等必要但略有风险的决策。即使生成多条轨迹,它们也往往高度相似,失去了多模态预测的意义。
- 安全与多样性矛盾:模型为了追求与专家轨迹的L2距离最小,可能会忽略碰撞风险、交通规则等更高层次的语义目标。
DIVER的提出,正是为了打破这一瓶颈。其核心思想可概括为:
"让扩散模型负责天马行空地'想象'多种可能(生成多样性),再让强化学习负责脚踏实地地'评估'和'优化'这些可能(确保安全与合理)。"
2. DIVER 技术框架总览
下图清晰地展示了DIVER的工作流程:感知信息经过编码后,一方面通过条件扩散模型生成多模态轨迹,另一方面通过强化学习模块,利用精心设计的奖励函数对这些轨迹进行评价和优化,最终输出既多样又安全的驾驶规划。
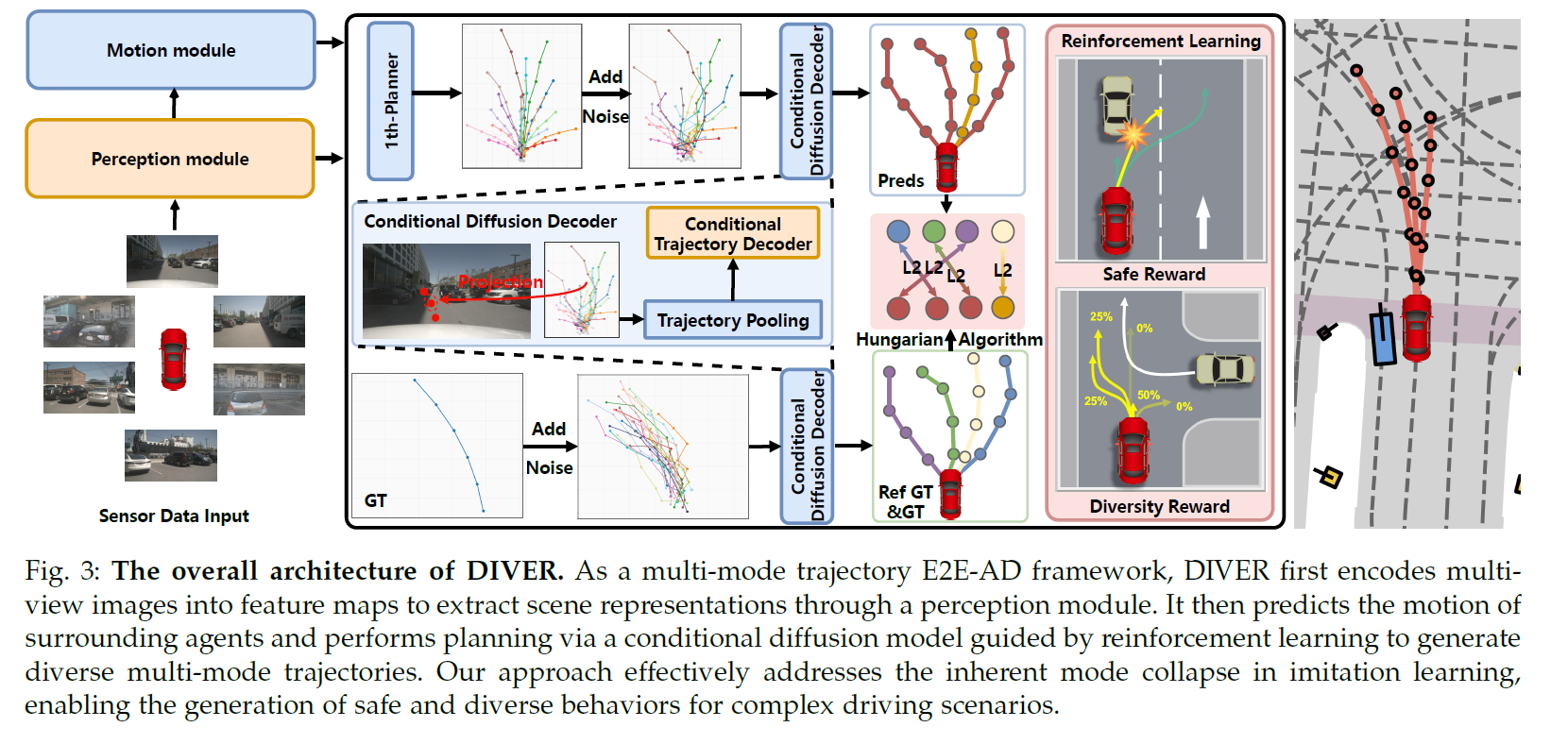
DIVER 整体框架图:融合扩散生成与强化学习优化的端到端自动驾驶规划流程
2.1 两大核心技术支柱
支柱一:策略感知扩散生成器 (Policy-Aware Diffusion Generator, PADG)
PADG并非简单地回归一条轨迹,而是学习一个未来轨迹的分布。
- 条件化生成:它以高清地图、周围动静态障碍物信息为条件,确保生成的轨迹符合场景结构。
- 多模态锚点:引入多条"参考轨迹"作为生成引导,鼓励模型覆盖变道、跟驰、转弯等多种驾驶策略,从源头上抑制模式崩溃。
- 匹配训练:使用匈牙利算法,让模型生成的K条轨迹分别去匹配K条不同的参考专家行为,而非挤向同一点。
支柱二:基于群组相对策略优化的强化学习 (GRPO)
这是DIVER的灵魂所在。它将扩散模型的去噪过程本身视为一个可学习的"策略",并用强化学习来优化它。
核心奖励函数设计:
- 多样性奖励:鼓励多条生成轨迹之间保持合理距离。
- 安全性奖励:严厉惩罚靠近障碍物的轨迹点。
- 舒适度奖励:追求平顺的加速度和转向变化。
- 交通规则奖励:鼓励遵守车道线、交通灯等规则。
通过优化这些与最终驾驶体验直接相关的目标,DIVER生成的轨迹不仅在几何上合理,在驾驶逻辑上也更优、更安全。
3. 从代码结构看DIVER的实现
DIVER的代码库组织得非常清晰,体现了优秀的工程实践。其核心结构基于自动驾驶开源框架 adzoo/sparsedrive 构建。
3.1 项目目录精讲
adept-thu/DIVER/ # 项目根目录
├── configs/ # 🎛️ 实验配置中心
│ ├── DIVER_small_b2d_stage2_targetpoint_multiplan.py # DIVER主配置
│ ├── momad_*.py # MomAD基线模型配置
│ └── sparsedrive_*.py # SparseDrive基线模型配置
├── adzoo/sparsedrive/ # 🏗️ 核心代码根目录
│ └── mmdet3d_plugin/ # 💡 核心算法实现区 (PADG, GRPO训练逻辑在此)
├── scripts/ # 🚀 一键执行脚本
│ ├── train.sh # 训练脚本
│ ├── test.sh # 测试脚本
│ └── visualize.sh # 可视化脚本
├── tools/ # 底层工具脚本
├── leaderboard/ # 闭环仿真评估接口 (CARLA)
├── scenario_runner/ # 场景运行器
└── docs/ # 文档关键目录解读:
configs/:这是项目的控制塔。通过修改配置文件(如选择DIVER_*.py),可以轻松切换模型、数据集、训练阶段和规划模式。adzoo/sparsedrive/mmdet3d_plugin/:这是算法创新的心脏。所有DIVER新增的模块,包括PADG和GRPO训练循环,都在这里实现。scripts/:提供了从训练到可视化的完整命令行入口,极大简化了使用流程。
3.2 快速开始指南
bash
# 1. 克隆仓库并安装依赖
git clone https://github.com/adept-thu/DIVER.git
cd DIVER
pip install -r requirements.txt
# 2. 按照README准备数据集 (如nuScenes, Bench2Drive)
# ...
# 3. 使用脚本启动训练 (示例:在Bench2Drive上训练)
bash scripts/train.sh configs/DIVER_small_b2d_stage2_targetpoint_multiplan.py
# 4. 使用脚本进行可视化评估
bash scripts/visualize.sh work_dirs/您的实验目录/4. 实验结果:数据胜于雄辩
DIVER在多个具有挑战性的自动驾驶基准测试中均取得了领先性能。
4.1 闭环仿真性能(最能反映真实驾驶能力)
在基于真实数据构建的 NAVSIM 仿真平台上,DIVER在综合规划质量指标(PDMS)上达到88.3分 ,优于之前的扩散模型基线。可视化结果直观显示,在复杂路口,DIVER能生成覆盖直行和左转的多种合理轨迹,而基线模型轨迹则高度重叠。
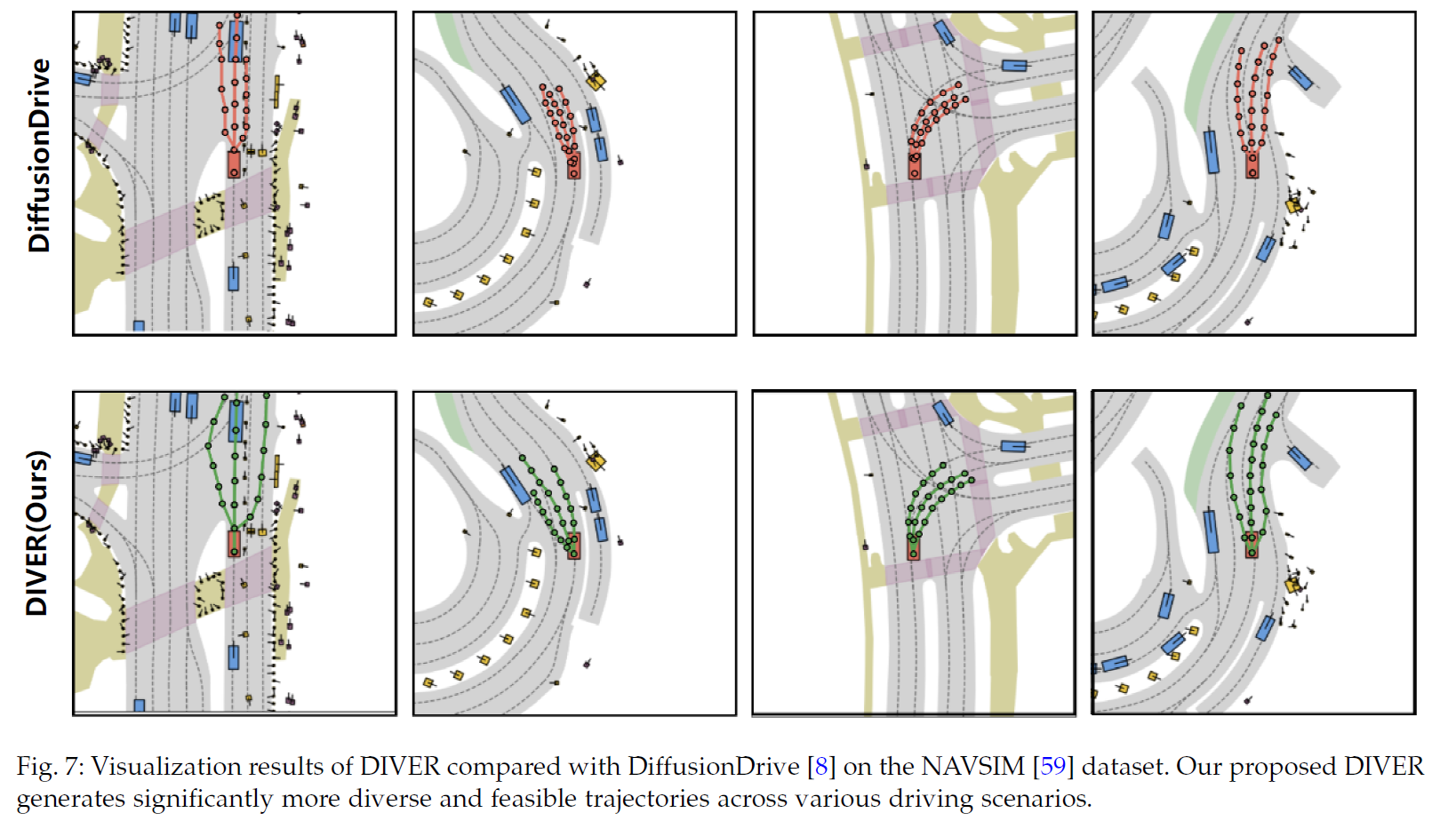
DIVER(下)在复杂路口生成了多样化的合理轨迹,而基线模型(上)的轨迹则趋于重合,缺乏决策多样性。
在强调交互的 Bench2Drive 基准上,DIVER的表现同样出色:
| 模型 | 驾驶分数 (DS) ↑ | 成功率 (SR) ↑ | 舒适度 (Comf) ↑ |
|---|---|---|---|
| SparseDrive (强基线) | 44.54 | 16.71% | 48.63 |
| DIVER (Ours) | 49.21 | 21.56% | 54.72 |
4.2 开环预测与鲁棒性测试
DIVER不仅在标准场景下表现优异,在更具挑战性的设置下也展现了强大的鲁棒性。
| 测试场景 | 关键挑战 | DIVER表现 | 结论 |
|---|---|---|---|
| 长时域预测 (6秒) | 规划稳定性与预见性 | 多样性最高(0.62),碰撞率最低(1.91%) | 能进行更稳定、更长远的规划 |
| 对抗场景 (Adv-nuSc) | 对抗性干扰的车辆 | 平均碰撞率最低(0.752%) | 在面对恶意干扰时表现出极强的韧性 |
| 恶劣天气 (nuScenes-C) | 传感器噪声与遮挡 | 在雨、雪、雾天碰撞率全面低于基线 | 对感知退化具有良好容错性 |
5. 总结与展望
DIVER框架通过巧妙的**"生成-优化"协同范式**,为端到端自动驾驶的决策多样化问题提供了一个强有力的解决方案。其实验结果充分证明,追求多样性与保障安全性并非不可兼得。
- 对学术界的价值:DIVER提供了一个融合生成模型与强化学习的清晰范例,其代码结构清晰,模块化程度高,非常适合作为新研究工作的起点。
- 对工业界的启示:将高层驾驶目标(安全、舒适、合规)直接作为损失函数的一部分进行优化,是迈向更可靠、更拟人化自动驾驶系统的关键一步。
未来的潜在方向:
- 奖励函数工程:探索更精细、更稠密的奖励信号设计。
- 与世界模型结合:将DIVER的规划器与能够预测环境变化的世界模型相结合,实现更前瞻的决策。
- VLA(Vision-Language-Action)集成:引入大型视觉-语言模型,为驾驶决策提供更高层次的语义理解和常识推理。
DIVER已经迈出了从"模仿驾驶"到"智能决策"的关键一步,其开源代码无疑将加速这一领域的创新进程。
相关资源
- 论文原文 : DIVER: Reinforced Diffusion Breaks Imitation Bottlenecks in End-to-End Autonomous Driving
- 官方代码仓库 : https://github.com/adept-thu/DIVER
- 技术解读 : 知乎专栏文章
希望这篇解析能帮助你深入理解DIVER。如果你在复现代码或理解细节时有任何疑问,欢迎在评论区交流讨论。