深度学习中的 Transformer 模型 是一个在自然语言处理(NLP)领域取得革命性成功的架构,其核心创新是完全依赖 自注意力机制(Self-Attention),彻底摒弃了传统循环神经网络(RNN)和卷积神经网络(CNN)中的序列对齐或局部特征提取。
文章目录
- 一、传统序列处理模型的不足:RNN的缺陷
-
- [1.1 性能限制](#1.1 性能限制)
- [1.2 长期记忆衰减](#1.2 长期记忆衰减)
- 二、告别循环:Transformer模型的整体架构
-
- [2.1 核心架构:编码器-解码器框架](#2.1 核心架构:编码器-解码器框架)
- [三、进化的里程碑:Transformer 模型的优势](#三、进化的里程碑:Transformer 模型的优势)
Transformer模型最初在2017年的论文 《Attention Is All You Need》 中被提出,目前已成为包括 GPT、BERT 在内的大型语言模型(LLM)的基础架构。

一、传统序列处理模型的不足:RNN的缺陷
在 Transformer 模型出现之前,深度学习在处理序列数据(文本、语音)时,主要依赖于循环神经网络(RNN) 及其变体 长短期记忆网络(LSTM) 和 门控循环单元(GRU)。
而RNN 模型的设计灵感来源于人类阅读和理解文本的线性过程,它的核心思想是:信息必须按时间步骤依次处理,正是这种依赖于循环结构的设计,埋下了难以克服的瓶颈。
1.1 性能限制
RNN在处理一个序列时,模型必须严格按照时间顺序,逐个处理词语,每个词语在处理时都会以附加之前的输出,即必须顺序处理,而GPU擅长并行处理大规模矩阵运算,RNN 的顺序结构导致其无法充分利用 GPU 的强大并行能力,无论是训练还是推理,速度都受到严格限制,序列越长,等待时间越久。
1.2 长期记忆衰减
在文本理解中,理解句子中相隔较远的两个词语之间的关系至关重要,然而RNN 在处理长序列时容易出现下列问题:
- 信息稀释:长期记忆能力往往是其致命弱点,当信息必须通过数十甚至数百个时间步的循环传递时,早期输入的信息在反复的矩阵乘法中会逐渐被稀释或遗忘。
- 梯度消失:在反向传播过程中,经过长距离传播的梯度容易变得非常小(梯度消失),导致模型权重无法有效更新,使得模型无法学习到序列起点和终点之间的有效关联。
正是这些在效率和准确性上的根本缺陷,迫使深度学习社区寻求一种全新的、能够实现完全并行化并有效捕捉全局上下文的架构,最终催生了以 自注意力机制 为核心的 Transformer 模型。
二、告别循环:Transformer模型的整体架构
Transformer 模型最激进的创新在于它完全摒弃了 RNN 的循环连接,从而实现了前所未有的并行计算能力。它的架构基于经典的 编码器-解码器(Encoder-Decoder) 框架,但每一个组件都被设计为可以独立、同时工作。
2.1 核心架构:编码器-解码器框架
Transformer 的架构基于经典的 编码器-解码器(Encoder-Decoder) 框架,但每一个组件都被重新设计,可以独立、同时工作。
- 编码器(Encoder)------"理解者": 它的任务是读入输入的文字,然后把每个词转换成包含丰富上下文信息的"密码"(使用嵌入算法将词转换为向量,可以简单理解为用一组数字去表示词语)。编码器由完全相同的结构堆叠而成,每一层都试图比上一层更深地理解句子。
- 解码器(Decoder)------"创作者": 它的任务是根据编码器提供的"密码",一个字一个字地吐出目标文字。它不仅会关注已经翻译出来的词,还会不断回头去问编码器:"那个词在原文里是什么意思?"
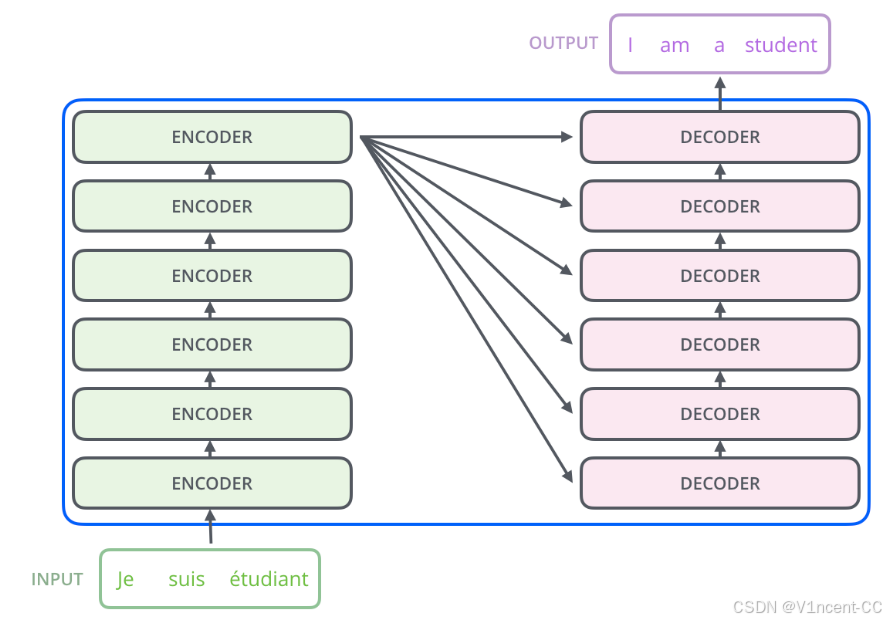
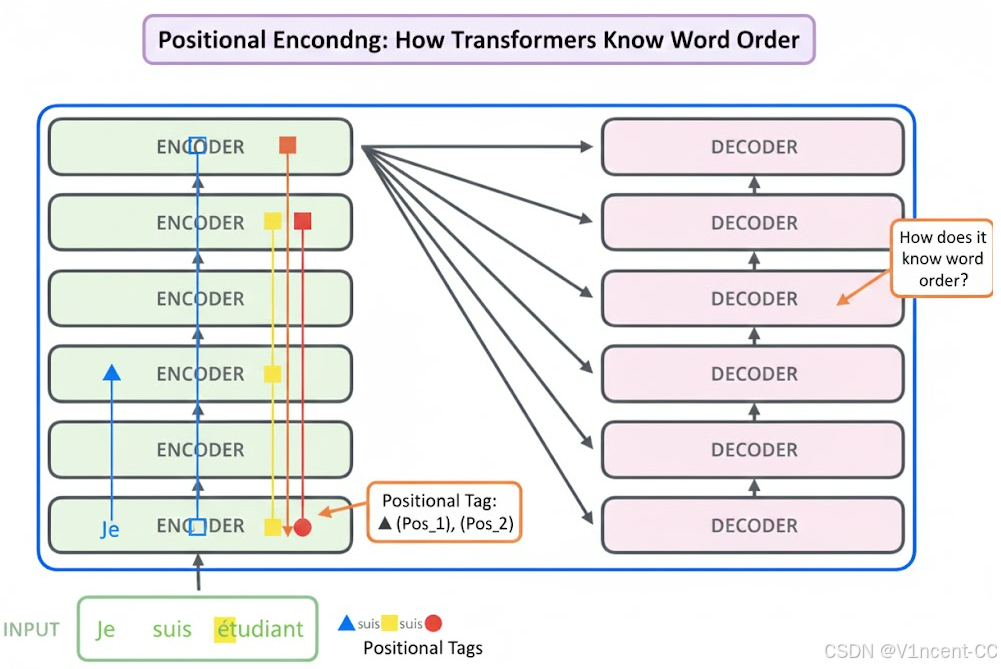
这种架构的关键特性可以是"一次性读入全句", 即编码器中每个位置的词都沿着各自的路径流动,即句子中的词语是并行通过模型的,但并行也会导致词语先后顺序的丢失。
那么Transformer是怎么知道词的先后顺序呢?为了避免模型认为"我爱吃鱼"和"鱼爱吃我"是一回事,Transformer 会给每个词贴上一个带有位置信息的"标签",让模型知道谁在前,谁在后。
翻译一个长句子时:
- 传统的 RNN 像是在"排队领盒饭": 必须等第一个词处理完,才能处理第二个词,如果句子很长,排在后面的词等得花儿都谢了,而且前面的信息传到后面时,往往已经"失真"了。
- Transformer 像是"一起过马路": 它不需要按顺序处理词语,而是把整句所有的词一次性"吞"进去(堆叠的编码器就像是斑马线,所有词语一起过),同时通过一种名为 "注意力" 的机制,允许每个词在理解自己时,去观察句子里的其他词,一眼看清所有词之间的关系。
三、进化的里程碑:Transformer 模型的优势
Transformer 引入了注意力机制(Self-Attention),这让它具备了两项核心优势:并行计算 与 全局关联。正是凭借这种"闪电速度"和"全局视野",Transformer 成为了当前人工智能领域最强大的模型之一,我们熟知的 ChatGPT、文心一言等大型语言模型,都是基于 Transformer 架构构建的,它不仅速度更快,更重要的是,它能更深层次、更准确地理解语言的复杂含义,这才是真正的里程碑。
下面为Transformer模型与其他深度学习模型的优劣势对比
| 维度 | RNN 家族 | CNN 结构 | Transformer 模型 |
|---|---|---|---|
| 计算模式 | 串行(Step-by-Step) | 局部并行 | 全并行(Parallel) |
| 感知距离 | 受限(长距离易遗忘) | 受限(取决于卷积核) | 理论无限(全局注意力) |
| 参数效率 | 较低(深层难以训练) | 较高 | 极高(适合超大规模模型) |
| 归纳偏置 | 强(假设时序关联) | 强(假设局部关联) | 弱(完全由数据驱动) |
| 典型应用 | 早期语音识别 | 图像处理 | GPT, BERT, Claude, Sora |
Transformer 模型的成功,本质上是从"时序建模"向"关系建模"的范式转移,它更像是一种高效的哲学:放弃了对序列先后顺序的固执坚持,选择了用大规模并行和全局注意力去换取对复杂规律的掌控。正是这种"暴力且优雅"的设计,开启了生成式 AI 的大航海时代。