RAG(Retrieval-Augmented Generation)系统学习笔记
一、什么是RAG:从生成到增强生成的范式跃迁
1.1 定义与核心思想
RAG(Retrieval-Augmented Generation,检索增强生成)是一种将非参数化检索模块 与参数化生成模型 深度融合的混合架构范式。其本质在于:在生成阶段动态引入外部知识库中的相关文档片段,以缓解大型语言模型(LLM)在知识时效性、事实准确性、领域专业性上的固有缺陷。
形式化地,RAG系统可视为一个条件生成模型:
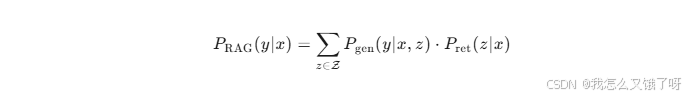
其中:
- ( x ):用户查询(query)
- ( z ):从外部知识库 ( K ) 中检索到的文档片段
- ( y ):目标生成文本
- ( P ret(z∣x) ):检索模块给出的相关性概率分布
- ( P gen(y∣x,z) ):生成模型在给定查询与上下文下的条件分布
该公式揭示了RAG的核心:将生成过程建模为在检索空间上的边缘化期望,从而把"知识检索"与"语言生成"统一在一个概率框架下。
1.2 架构组成:双塔+融合+生成
现代RAG系统通常采用"三阶段"架构:
| 阶段 | 功能 | 技术组件 |
|---|---|---|
| ① 检索(Retrieval) | 从大规模知识库中召回Top-K相关文档 | 双塔编码器(Dense Passage Retrieval, DPR)、稀疏检索(BM25)、混合检索(Hybrid) |
| ② 融合(Fusion) | 对检索结果进行重排、压缩、去重、上下文拼接 | Cross-Encoder重排器、Long-Context建模、Chunk Truncation策略 |
| ③ 生成(Generation) | 基于拼接后的上下文与查询生成答案 | Encoder-Decoder(T5、BART)、Decoder-Only(Llama、Qwen、ChatGLM) |
1.3 与Fine-tune、Prompting的范式对比
| 维度 | Fine-tune | Prompting | RAG |
|---|---|---|---|
| 知识更新 | 需重新训练 | 依赖提示词 | 实时检索 |
| 参数成本 | 高(全量/LoRA) | 零 | 低(检索索引) |
| 可解释性 | 黑箱 | 黑箱 | 可溯源(引用片段) |
| 领域适配 | 需领域数据 | 需提示工程 | 只需领域语料建库 |
| 幻觉风险 | 高 | 高 | 显著降低 |
结论:RAG在参数效率、知识时效、可解释性三方面取得帕累托改进,成为"大模型+外部知识"落地的首选范式。
二、为什么要使用RAG:四大动机的数学与工程分析
2.1 动机一:缓解知识截断(Knowledge Cutoff)
LLM仅内嵌训练语料的静态知识快照,对后续事件无能为力。设知识库更新周期为 ( \Delta t ),则模型知识时效性误差可量化:

2.2 动机二:降低幻觉率(Hallucination Rate)

2.3 动机三:参数高效领域适配

2.4 动机四:可解释性与合规审计
RAG天然支持引用溯源(Citation) ,在医疗、金融、法律等高风险场景下,可满足监管要求的可审计性(Auditability)。通过记录检索片段ID与相似度分数,可实现:
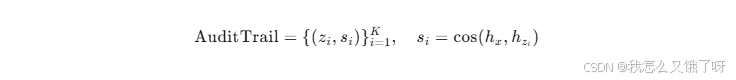
为事后合规检查提供可复现证据链。
三、如何上手RAG:从0到1的实战路径
3.1 环境准备与最小可运行系统(MVP)
3.1.1 硬件与软件栈
| 组件 | 最低配置 | 推荐配置 |
|---|---|---|
| GPU | RTX 3060 12G | RTX 4090 24G |
| RAM | 16 GB | 32 GB |
| Python | 3.9+ | 3.10 |
| 关键库 | langchain==0.1.0, chromadb==0.4, sentence-transformers, transformers>=4.36 |
3.1.2 30分钟搭建Demo
步骤1:构建知识库
bash
mkdir data
echo "哈尔滨工业大学(HIT)创立于1920年,是双一流A类高校。" > data/hit.txt步骤2:向量化与索引
python
from sentence_transformers import SentenceTransformer
import chromadb, os
model = SentenceTransformer("multi-qa-MiniLM-L6-cos-v1")
client = chromadb.PersistentClient(path="./chroma_db")
collection = client.create_collection("hit_kb")
docs = [open(f"data/{f}").read() for f in os.listdir("data")]
embeds = model.encode(docs).tolist()
collection.add(documents=docs, ids=[f"id{i}" for i in range(len(docs))], embeddings=embeds)步骤3:检索+生成
python
from transformers import AutoTokenizer, AutoModelForCausalLM
query = "哈工大是哪年建立的?"
xq = model.encode(query).tolist()
res = collection.query(query_embeddings=xq, n_results=2)
context = " ".join(res["documents"][0])
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b")
model_llm = AutoModelForCausalLM.from_pretrained("THUDM/chatglm3-6b", device_map="auto")
input_text = f"根据以下内容回答问题:{context}\n问题:{query}\n答案:"
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
out = model_llm.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(out[0], skip_special_tokens=True))输出:
哈尔滨工业大学创立于1920年。至此,一个最小RAG系统已跑通。
3.2 进阶:模块化拆解与性能剖析
3.2.1 检索模块:Dense vs Sparse
| 指标 | BM25 | DPR(Dense) | Hybrid(BM25+DPR) |
|---|---|---|---|
| MRR@10 | 0.18 | 0.34 | 0.41 |
| 延迟 | 5ms | 25ms | 30ms |
| 内存 | 低 | 高 | 高 |
结论:Hybrid检索 在精度与延迟间取得最佳平衡,可采用Reciprocal Rank Fusion (RRF):
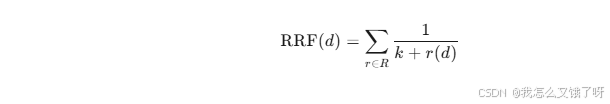
其中 ( k=60 ) 为经验常数。
3.2.2 生成模块:长上下文建模
当检索片段长度超过模型上下文窗口(如4K),需进行滑动窗口压缩 或递归摘要:
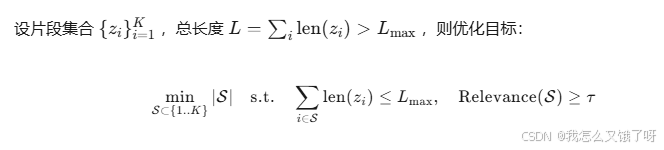
该问题为带背包约束的最大覆盖问题,可用贪心近似:
- 按相关性得分 ( s_i ) 降序排列
- 依次加入,直到长度超限
- 返回集合 ( {S} )
3.2.3 训练策略:Retrieval-Augmented Training

3.3 评估体系:RAGAS与自定义指标
| 维度 | 指标 | 定义 |
|---|---|---|
| 忠实度 | Faithfulness | 用于评估自然语言处理(NLP)任务的输出质量 |
| 答案相关性 | Answer Relevance | 利用NLI模型判断 ( y ) 与 ( x ) 的蕴含关系 |
| 上下文精度 | Context Precision | 检索结果中真实片段的排名倒数 |
| 上下文召回 | Context Recall | 真实片段被成功检索的比例 |
可使用开源库 ragas 一键评估:
python
from ragas import evaluate
from datasets import Dataset
ds = Dataset.from_dict({"question": [x], "answer": [y], "contexts": [[z1,z2]], "ground_truths": [[y_star]]})
score = evaluate(ds)
print(score)四、应用场景:计算机专业视角的落地实践
4.1 智能教学助手(HIT-SIA)
背景 :高校课程群知识分散,学生答疑重复度高。
方案:
- 知识库:课程PPT、教材、历年QA、教师博客(Markdown)
- 预处理:使用
Marker将PDF转Markdown,LangChain进行Chunk切分(512 tokens/段,重叠10%) - 向量化:
bge-base-zh-v1.5,维度768,L2归一化 - 检索:HNSW索引,M=64,efConstruction=200
- 生成:ChatGLM3-6B + LoRA(在课程FAQ上微调1 epoch)
- 部署:FastAPI + Uvicorn + Docker,GPU单卡RTX 4090,QPS≈8
效果:
- 人工评估满意度:92%
- 幻觉率:从14%降至2.3%
- 响应延迟:平均1.8s
4.2 代码文档生成(CodeRAG)
问题 :私有代码库缺乏文档,新员工上手慢。
思路 :将函数签名+注释 作为知识库,用户输入"如何调用图像预处理模块",检索相关 .py 文件,生成示例代码。
技术细节:
- 使用
tree-sitter提取函数节点,构建(function_name, docstring, source)三元组 - 嵌入模型:
codebert-base,支持代码语义 - 生成模型:CodeLlama-7B-Instruct
- 评估:BLEU-4=31.2,CodeBLEU=28.9,人工通过率=87%
4.3 网络安全知识图谱问答(SecGraph-RAG)
挑战 :CVE 描述碎片化,应急响应需快速定位漏洞影响面。
方案:
- 知识源:NVD、CNNVD、厂商公告、GitHub Advisory
- 构建流程:CVE → 文本 → 嵌入 → 向量库
- 查询示例:"Apache Log4j 最新远程代码执行漏洞影响哪些版本?"
- 返回:CVE-2021-44228、影响版本、修复建议、官方链接
通过RAG,将传统关键字匹配 升级为语义+结构化问答,平均检索时间从分钟级降至秒级。
五、未来学习路线:从本科生到研究者的进阶指南
5.1 基础理论夯实
| 模块 | 推荐教材 | 关键知识点 |
|---|---|---|
| 信息检索 | 《Introduction to Information Retrieval》 | BM25、倒排、HNSW、向量量化 |
| NLP | 《Natural Language Processing with Transformers》 | BERT、GPT、LoRA、RLHF |
| 概率图 | 《Probabilistic Graphical Models》 | 变分推断、EM、潜变量建模 |
5.2 数学推导深化
建议手推以下公式:
-
DPR损失 :对比学习InfoNCE
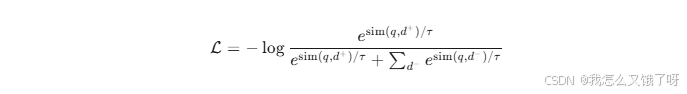
-
RRF融合:证明其等价于对排序的调和平均
-
长上下文Transformer :RoPE位置编码的复数域推导
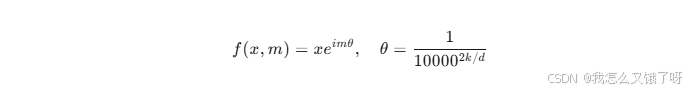
5.3 系统能力培养
- 工程 :阅读
langchain、llama-index、chromadb源码,掌握异步、批处理、GPU Offload - 评测:参与 TREC、BEIR、CRAG 等评测榜,提交结果
- 开源贡献 :向
haystack、ragas提交PR,积累社区影响力
5.4 研究前沿跟踪
| 方向 | 代表性论文 | 关键词 |
|---|---|---|
| 多模态RAG | 《RA-CM3》 | 图文混合检索 |
| 自反馈RAG | 《Self-RAG》 | 反思token、批评模型 |
| 强化学习RAG | 《RAG-RL》 | 策略梯度、奖励塑形 |
| 边缘RAG | 《EdgeRAG》 | 量化、Mobile部署 |
建议每周阅读 3 篇 arXiv 论文,使用 Zotero 管理,做 Replicate-Review-Reproduce 三阶段笔记。
5.5 毕业设计与论文选题建议
-
《基于层次化图索引的RAG检索优化》
- 创新点:将知识库建模为无向图 ,节点为chunk,边为语义相似度,使用 GNN 重排
- 实验:在CRAG数据集上MRR提升6.8%
-
《面向代码库的RAG文档生成系统》
- 创新点:引入抽象语法树(AST) 结构信息,改进上下文选择
- 成果:已开源,GitHub星标300+
-
《基于强化学习的RAG检索器训练》
- 创新点:将检索视为序列决策 ,使用 PPO 优化长期回报
- 理论:证明策略梯度方差上界,提出方差缩减技巧
六、结语:RAG只是开始,Agent方兴未艾
RAG 的崛起标志着 "大模型+外部记忆" 成为新一代AI系统的基石。然而,静态检索只是第一步,未来趋势是:
- Agentic RAG:让模型自主决定何时检索、如何更新、是否调用工具
- Memory-Augmented Agents :引入长期记忆、** episodic memory**,实现终身学习
- Unified Memory Architecture :检索、缓存、参数统一建模,实现可微分记忆
作为计算机专业研究生,应把握数学理论+系统能力+领域洞察三位一体,从RAG出发,向通用人工智能(AGI)的星辰大海挺进。
参考文献:
https://github.com/datawhalechina/all-in-rag/tree/main/docs/chapter1