
文章目录
- Abstract
- Introduction
- [Deep learning architectures for semantic segmentation](#Deep learning architectures for semantic segmentation)
-
- [Feature encoder based methods](#Feature encoder based methods)
-
- [VGG network](#VGG network)
- [Residual learning frameworks](#Residual learning frameworks)
- [Regional proposal based methods](#Regional proposal based methods)
- [Recurrent neural network based methods](#Recurrent neural network based methods)
- [Upsampling / Deconvolution based methods](#Upsampling / Deconvolution based methods)
- [Increase resolution offeature based methods](#Increase resolution offeature based methods)
- [Enhancement of features based methods](#Enhancement of features based methods)
- [Semi and weakly supervised concept](#Semi and weakly supervised concept)
- [Spatio-temporal based methods](#Spatio-temporal based methods)
- [Methods using CRF / MRF](#Methods using CRF / MRF)
- [Alternative to CRF](#Alternative to CRF)
- [Datasets and evaluation for deep learning techniques](#Datasets and evaluation for deep learning techniques)
- [Analysis & discussion](#Analysis & discussion)
- [Open problems and challenges](#Open problems and challenges)
-
- [Open problems and possible solutions](#Open problems and possible solutions)
-
- [Reducing complexity & computation](#Reducing complexity & computation)
- [Apply to adverse conditions](#Apply to adverse conditions)
- [Need large and high quality labeled data](#Need large and high quality labeled data)
- Overfitting
- [Segmentation in real-time](#Segmentation in real-time)
- [Video / 3D segmentation](#Video / 3D segmentation)
- Conclusion
Abstract
语义分割是计算机视觉系统中的一项具有挑战性的任务。为解决这一问题,人们开发了许多方法,涵盖自动驾驶汽车、人机交互、机器人技术、医学研究、农业等领域。其中许多方法都是基于深度学习范式构建的,且已展现出显著的性能。基于此,我们提议对这些方法进行综述,首先根据其架构背后的共同概念将其分为十类;其次,概述用于评估这些方法的公开可用数据集;此外,介绍用于衡量其准确性的通用评估矩阵;再者,重点关注部分方法,并仔细研究其架构,以探究它们如何取得所报告的性能;最后,通过讨论一些开放性问题及其可能的解决方案来总结全文。
Introduction
近年来,深度学习在语义分割方面的研究工作通过使用神经网络得到了显著的改进。神经网络自 20 世纪 40 年代以来就有很长的历史,但直到 20 世纪 90 年代才受到研究人员的广泛关注1。由于数码相机、手机摄像头的兴起以及计算能力的提升(随着 GPU 成为通用计算工具,其速度越来越快),神经网络取得了巨大的进步。
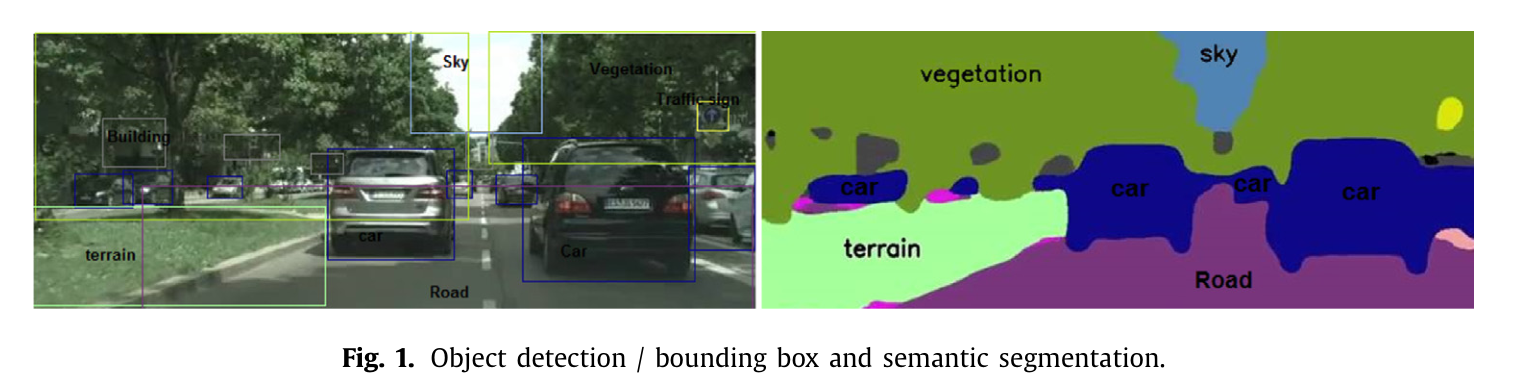
深度神经网络在语义分割方面表现极为出色,即为每个区域或像素标注出属于物体或非物体的类别。语义分割在图像理解中起着重要作用,并且对于图像分析任务至关重要。它在计算机视觉和人工智能领域有着多种应用------自动驾驶2,3、机器人导航4、工业检测5、遥感6;在认知与计算科学领域------显著对象检测7,8;在农业科学领域9;在时尚领域10------对服装物品进行分类;在医学科学领域11------医学影像分析等。早期用于语义分割的方法包括纹理森林12、基于随机森林的分类器13,而深度学习技术则实现了更精确且速度更快的分割14。语义分割需要进行图像分类、对象检测以及边界定位。图 1 展示了对象检测的一个实例,其中包括边界框以及将每个像素分类为不同的类别(汽车、道路、天空、植被、地形等)。深度学习是机器学习的一个新分支领域,其发展势头迅猛,以至于想要跟上其最新进展(尤其是那些涉及语义分割的研究)都变得非常困难。这些研究涵盖了新方法的开发、现有方法的改进以及它们在新应用领域的应用。这就是为什么目前缺乏关于这一领域的最新综述的原因。
一些调查和综述论文探讨了深度学习和语义分割领域的进展与创新。朱等人15所做的一项综述涵盖了大量关于语义分割主题的论文和领域,包括交互方法、超像素的最新发展、对象提议、语义图像解析、图像共分割、半监督和弱监督以及完全监督的图像分割。托马16提出了分割算法的分类体系以及完全自动、被动的语义分割算法的概述。尼梅耶尔等人17对用于自动驾驶场景理解的基于神经网络的语义分割进行了综述。郭等人18提供了语义分割方法的综述,即基于区域的方法、基于 FCN 的方法和弱监督方法。他们总结了图像语义分割的优点、缺点和主要挑战。耿等人19对基于卷积神经网络的语义分割的最新进展进行了综述,并介绍了在帕斯卡尔 VOC 2012 语义分割挑战中取得良好结果的最新开发策略。加西亚-加西亚等人20对用于语义分割的深度学习方法进行了详细综述,阐述了其在该领域的贡献和意义。洪山等人21所作的全面综述,根据手工设计特征、学习特征和弱监督学习对不同方法进行了分类。
本文的贡献在于:
- 现有的方法根据其架构所基于的共同概念被分为十种不同的类别。这种分类全面总结了这些方法的特点,既相互启发又有所差异。
- 涵盖了超过 100 种不同的模型和 33 个公开可用的数据集,详细说明了每个模型的语料库、原始架构、测试基准以及每个数据集的特征。此外,我们还提供了截至目前在每个数据集上表现最佳且分类准确率最高的方法。
- 通过分析这些方法的结构设计及其在评估数据集上的表现,重点阐述了这些方法是如何实现其目标的。
- 最后,一些尚未解决的问题以及可能的解决方案也进行了讨论。
在本次调查中,所有模型均经过精心挑选,并根据其架构设计和对领域的贡献相互关联起来。这包括提高准确性、降低计算复杂度、开发新方法以及改进现有方法。本文所报告的所有结果均取自原始论文。我们努力涵盖了深度神经网络在语义分割方面的大部分研究成果。本次调查将有助于新研究人员加深对这些杰出成果的理解。
Deep learning architectures for semantic segmentation
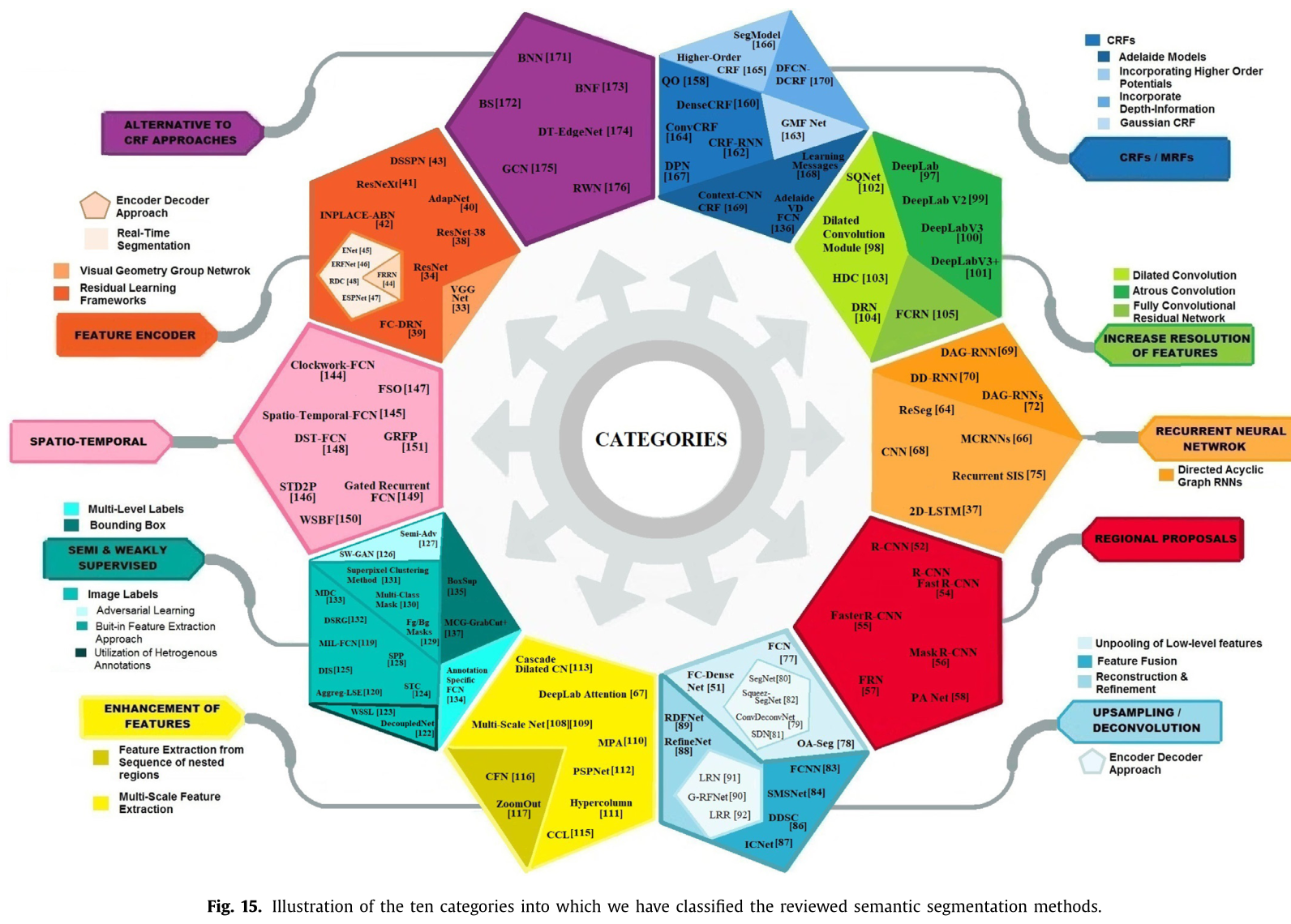
本节提供了所有回顾过的语义分割方法的细节。我们已经将这些方法分为十(10)类,以表格的形式列出了每个方法,它的主要思想,它的架构起源,测试基准,发布日期,以及代码的可用性(表13提供了可用源代码的链接)。
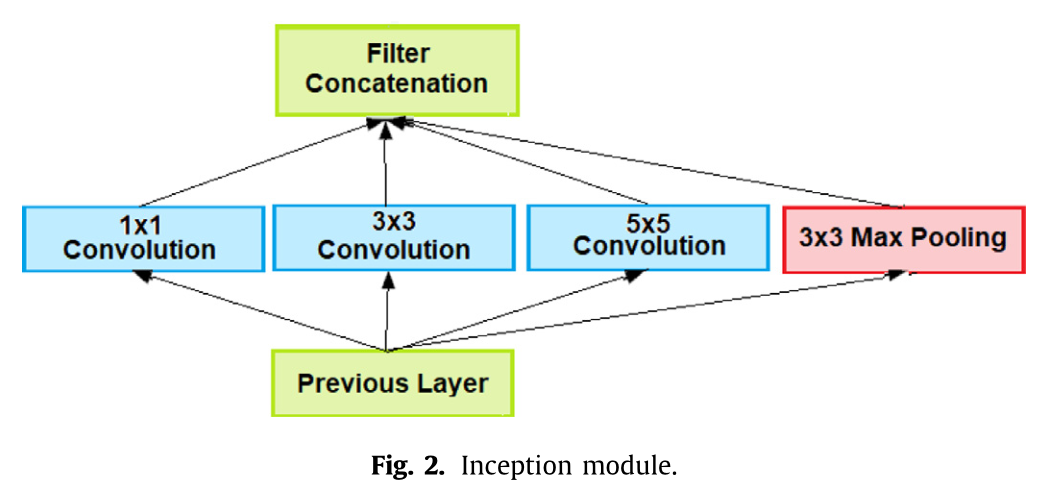
近年来,深度卷积神经网络(CNNs)取得了显著的成功,这使得语义分割领域取得了巨大的进展。卷积神经网络的首次成功应用是由勒坎等人开发的22。他们引入了一个名为 LeNet5 的架构,用于读取邮政编码、数字,并在图像的多个位置提取特征。后来,亚历克斯·克里泽维斯基发布了一个大型深度卷积神经网络(AlexNet)23,这被认为是该领域最具影响力的出版物之一。AlexNet 是 LeNet 的更深层、更宽的版本,用于学习复杂的对象和对象层次结构。泽尔和弗格斯24提出了 ZFNet,这是对 AlexNet 结构的微调。他们提出了一种在网络模型的任何层可视化特征图的技术。该技术使用多层反卷积网络将特征激活投影回输入像素空间。林等人25基于微型神经网络提出了一个基于网络的网络模型,这是一种多层感知器(MLP)26,由多个具有非线性激活函数的全连接层组成。塞格迪等人27提出了一种高效的深度神经网络,名为"谷歌网络"。他们引入了一个名为"初始模块"的结构,如图 2 所示,该模块由 1×1、3×3 和 5×5 的卷积滤波器以及一个池化层组合而成。它减少了每一层的特征数量和运算量,从而节省了时间和计算成本。
同为上述作者的28一文中,他们提出了一种被称为"BN-Inception"的算法,用于构建、训练以及运用批标准化方法进行推理。Szegedy 等人29进一步在其先前模块的基础上引入了两个新的模块------Inception V2 和 Inception V3,并进行了部分重大修改(例如,将卷积分解以及采用网格缩减技术),从而形成了新的模块。随后,Szegedy 等人30将 Inception 架构中的滤波器拼接阶段替换为残差连接,以提高效率和性能。他们提出了 Inception-ResNet-v1、Inception-ResNet-v2 以及一种纯的 Inception 变体,即 Inception V4。Chollet 等人31提出了一个名为"Xception"的模块,意为"极端的 inception"。他们用32中提出的深度卷积分离卷积来替换 inception 模块。表 1 展示了 GoogLeNet 模块。
Feature encoder based methods
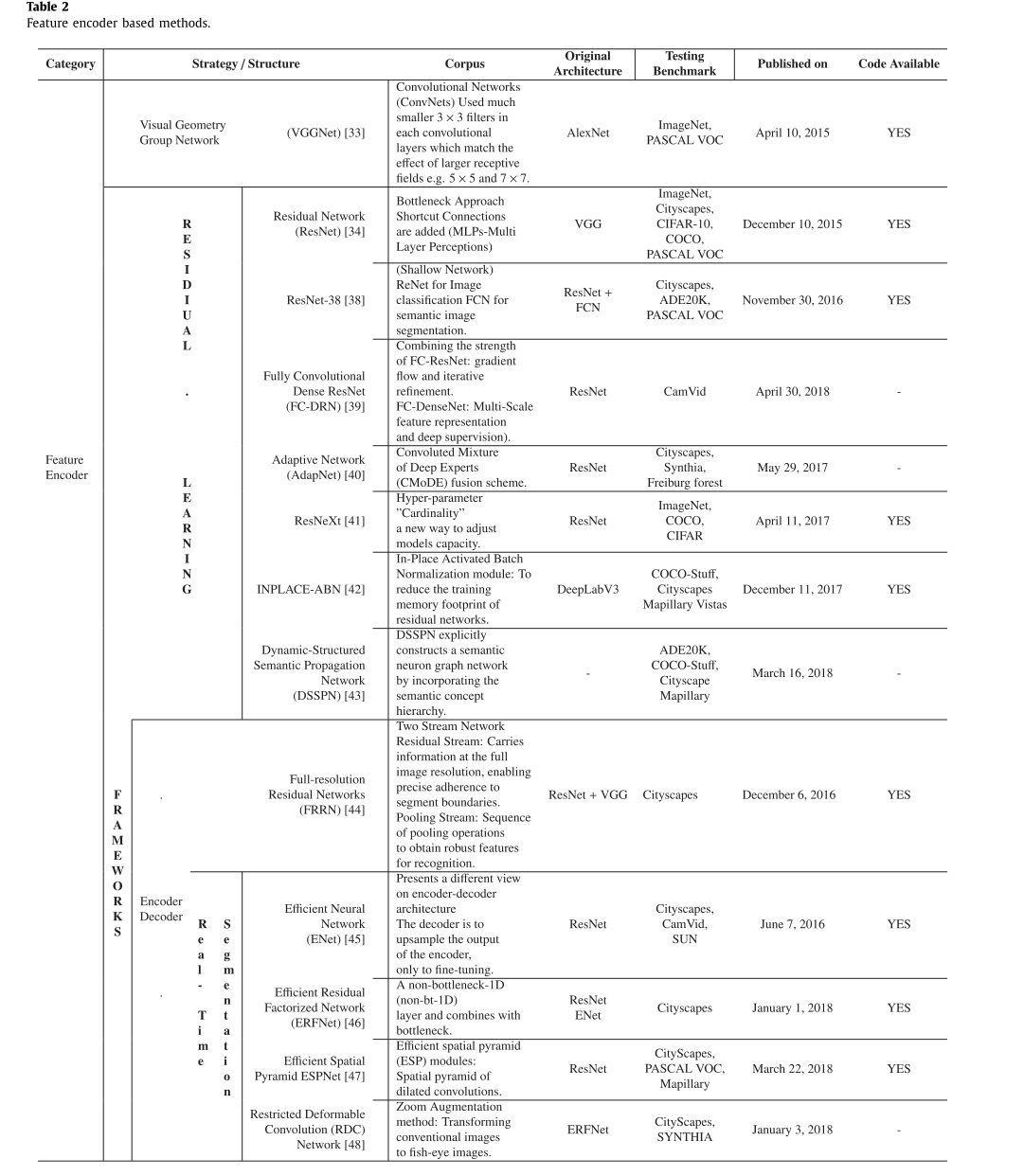
VGG 33 和 ResNet 34 这两种方法是用于特征提取的最主流的手段。在这一类别中,我们回顾了这些方法及其在表 2 中所呈现的不变性。该概念背后的思路是基于堆叠的卷积层、ReLU 层和池化层来提取特征图。
VGG network
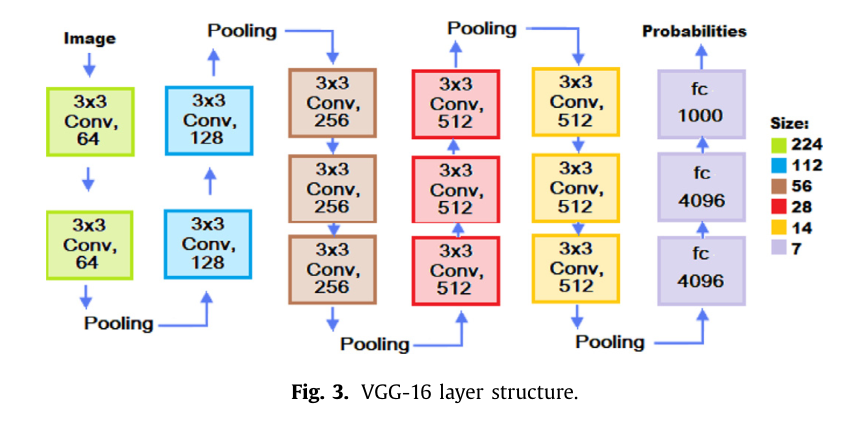
由牛津大学著名的视觉几何小组提出的 VGG 网络33。与 LeNet22 和 AlexNet23 不同,VGG 网络在序列中使用了多个 3×3 的卷积操作,能够达到与更大感受野(例如 5×5 和 7×7)相媲美的效果。然而,由于其拥有较大的分类器,因此需要大量的参数和学习能力。图 3 展示了一个具有 16 层卷积层的 VGG 网络。
Residual learning frameworks
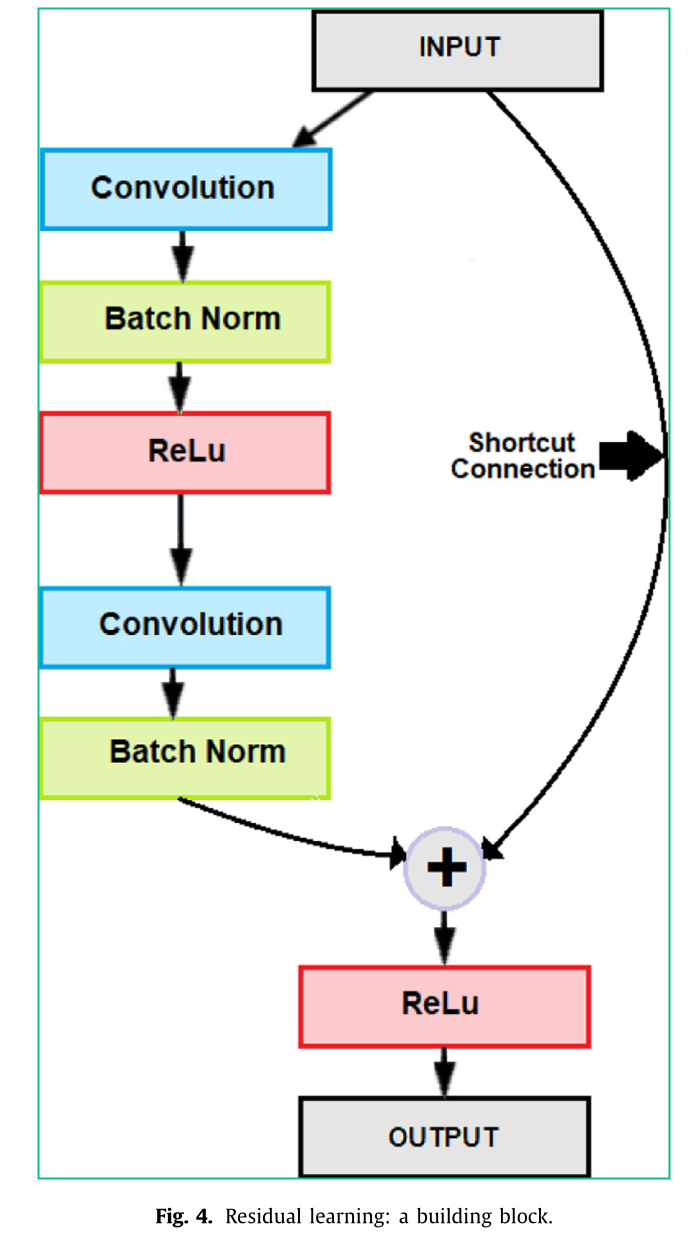
残差学习框架包括采用残差块34作为其架构中基本构建单元的方法。残差网络 - ResNet 34 是用于语义分割的最流行且应用最广泛的神经网络。训练具有大量层的深度神经网络是很困难的,随着深度的增加,其性能会达到饱和状态,甚至会因梯度消失问题而开始下降。在 35--37 中提出了几种解决方案,但似乎没有一种真正解决了这个问题。He 等人 34 通过引入身份捷径连接(即跳过一层或多层)有效地解决了梯度消失问题,如图 4 所示。他们提出了一种预激活变体残差块,在该块中,在反向传播的回传过程中,梯度可以轻松地通过捷径连接流动而不会受到阻碍。
有几种架构是基于 ResNet、其变体以及相关解释的。帕斯克等人45提出了一种名为高效神经网络(ENet)的编码器/解码器方案网络。该网络与 ResNet 的瓶颈方法类似,专为需要低延迟操作的任务(例如移动电话或电池供电设备)而设计。在49,50中,作者提出了通过随机丢弃其层并在测试时使用整个网络来训练深度网络的反直觉方法。吴等人38提出了一个名为 ResNet-38 的神经网络,在其中他们在残差网络的训练/测试时间中添加和删除层。他们分析了残差单元的有效深度,并指出 ResNet 表现为浅层网络的线性组合。波赫伦等人44提出了具有强大定位和识别性能的全分辨率残差网络(FRRN),用于语义分割 。FRRN 展现出与 ResNet 相同的优越训练特性,具有两个处理流:残差流和池化流。残差流携带全图像分辨率的信息,并能够精确遵循分割边界。汇聚流会经历一系列的汇聚操作,以获取用于识别的稳健特征。这两个流在全图像分辨率下通过残差进行耦合,以实现语义分割的强识别和定位性能。谢等人41提出了一种改进的 ResNet,称为 ResNeXt,遵循了与 inception 模块27,30相同的拆分-变换-合并策略,只是不同路径的输出是进行拼接的,并且所有路径具有相同的拓扑结构。因此,这使得设计能够扩展到任何数量的变换。借鉴 ResNet-50 34 的想法,瓦拉达等人40提出了一种称为自适应网络或 AdapNet 的架构。他们在 ResNet 的第一个卷积层之前引入了一个具有 3×3 核大小的额外卷积层,这使得网络能够在更短的时间内学习到更多高分辨率的特征。他们还提出了基于卷积混合的深度专家融合方案(CMoDE),用于从互补的模态和频谱中学习稳健的核。所提出的模型根据场景条件自适应地对特定类别的特征进行加权。受到 ENet 的启发,Romera 等人46提出了一种用于实时语义分割的高效残差分解网络 ERFNet。ERFNet 提出了一个非瓶颈一维(non-bt-1D)层,并以一种能最大程度发挥其学习性能和效率的方式将其与瓶颈设计相结合。将 ERFNet 视为基准,邓等人......48 提出了一种名为"受限可变形卷积"(RDC)的新编码器-解码器方法,用于处理道路场景的语义分割,以应对大幅变形的图像。它能够通过学习卷积滤波器的形状(基于输入特征图)来模拟几何变换。他们还提出了缩放增强方法,将标准图像转换为鱼眼图像。梅塔等人47为他们新的高效神经网络提出了一个名为"高效空间金字塔"(ESP)的卷积模块。ESP 模块由点式卷积(降低复杂度)和扩张卷积的空间金字塔(提供较大的感受野)组成。最近,卡索瓦诺等人39提出了一种名为全卷积密集残差网络(FC-DRN)的网络架构。其基本理念是将网络架构 FC-ResNet(梯度流动和迭代优化)和 FC-DenseNet 51(多尺度特征表示和深度监督)的优势相结合。梁等人43提出了一种动态结构化语义传播网络(DSSPN),该网络通过将语义概念层次结构纳入网络构建中来构建一个大型语义神经元图。在语义传播图中,每个神经元负责在词层次结构中分割出一个概念的区域。他们提出了密集语义增强神经块,在该块中,每个神经元学习到的特征会进一步传播到其子神经元,以演化出用于识别更精细概念的特征。布洛等人42提出了原地激活批量标准化(INPLACE-ABN)架构模块,以减少残差网络 ResNeXt 41 和 ResNet-38 38 的训练内存占用。
近期研究中对 VGG 和 ResNet 方法的侧重,使得在语义分割方面取得了显著成果。残差学习框架遵循"跳跃连接"这一核心理念,这是它们成功的关键所在。然而,在大规模应用时可能会导致内存问题。这些开创性的研究使得能够训练出性能良好的更深网络成为可能。
Regional proposal based methods
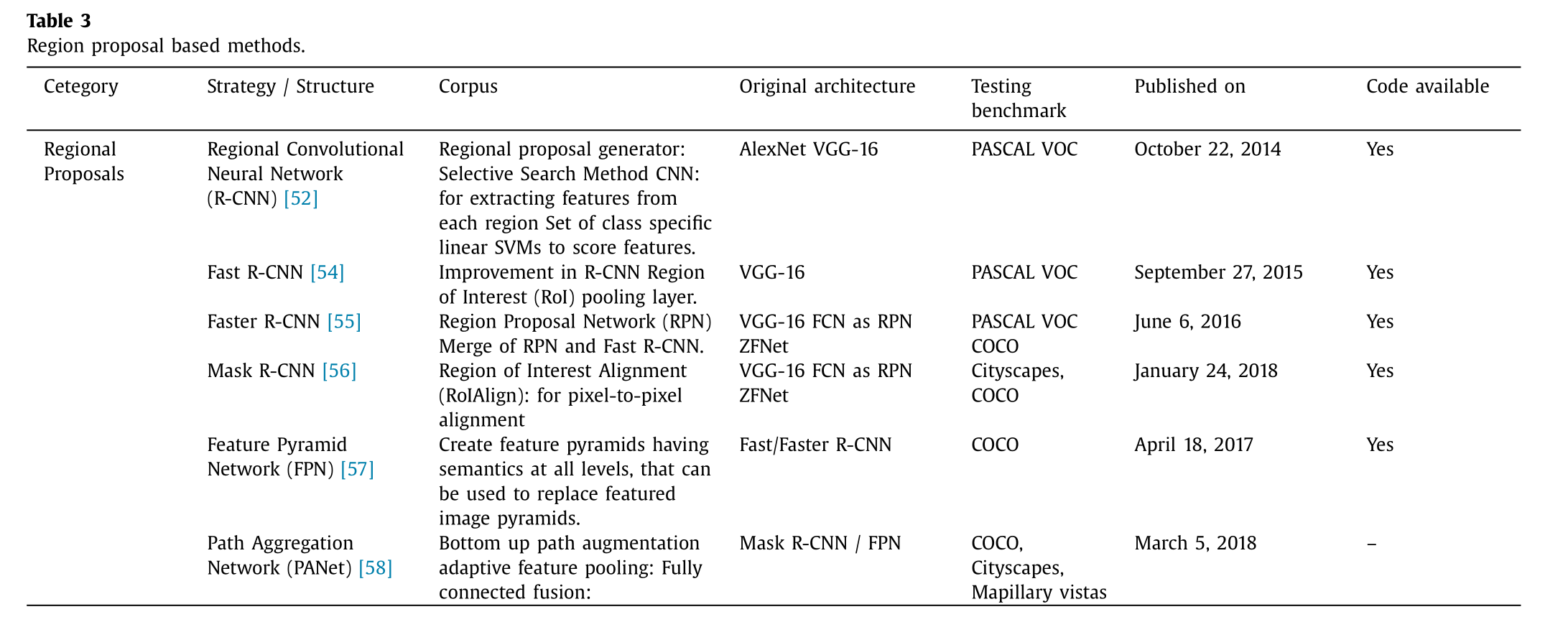
区域提议算法在计算机视觉领域(尤其是在对象检测技术方面)具有很大的影响力。其核心思想是根据不同的颜色空间和相似性指标来检测区域,然后进行分类(这些区域提议可能包含对象),这种分类通常被称为区域级预测。区域卷积神经网络(R-CNN)及其衍生版本如表 3 所示。
伯克利大学的吉尔希克等人52提出了一种用于物体检测任务的首个基于区域的卷积神经网络(R-CNN)。R-CNN 由三个模块组成:区域提议生成器,其中他们使用了选择性搜索方法53,用于生成 2000 个具有最高物体包含概率的不同区域;卷积神经网络22用于从每个区域提取特征;最后,这些来自卷积神经网络的特征被用作一组特定类别线性支持向量机的输入。这些特征还被输入到边界框回归器中,以获得最准确的坐标并减少定位误差。图 5 展示了 R-CNN 的架构。
在54一文中,作者们提出了"快速 R-CNN"算法,其中采用了一种名为"RoIPool(感兴趣区域池化)"的技术,该技术提高了训练和测试的速度,并提升了物体检测的准确性。后来,微软的一个团队提出了一个名为"Faster-RCNN"的架构55。他们引入了区域提议网络(RPN),这是一种通过添加几层额外的卷积层来构建的全卷积网络(FCN),这些层能够在每个位置预测对象边界和对象性(即对象类别集合与背景的对比度)得分。RPN 生成区域提议(多种尺度和比例),并将它们输入到"Fast R-CNN"中进行对象检测。RPN 和"Fast R-CNN"共享其卷积特征,这降低了复杂性、提高了速度并整体上提高了对象检测的准确性。林等人57提出了特征金字塔网络(FPN),这是一种多尺度的深度卷积网络(ConvNet)的金字塔结构,创建了具有各级语义的特征金字塔,可以以最小的成本(功率、速度或内存)替换特征化图像金字塔。何等人56提出了掩码区域卷积神经网络(Mask-RCNN),将"Faster R-CNN"扩展到像素级别的图像分割。它在每个区域候选框(RoI)上添加了一个分支(小型 FCN),用于以像素对像素的方式预测对象掩码,同时与现有的用于边界框识别(分类和回归)的分支并行工作。Fast R-CNN 存在输入与输出之间像素对像素对齐不准确的缺陷(如图 6 所示)。Mask-RCNN 通过将区域候选框池化层替换为区域兴趣对齐(RoIAlign)层来解决这一问题,这是一种无需量化、能保留精确空间位置的层。如图 6 所示,它能保持精确的空间位置。最近,Liu 等人58提出了基于 Mask-RCNN 和 FPN 的网络,名为路径聚合网络(PANet),在基于提议的实例分割框架中增强了信息流。
基于区域的神经网络具有这样的优势:可以同时实现对象检测和分割。这些区域是由算法生成的(59 对其进行了深入分析),这些算法具有语义意义,并与对象相关。它可能包含一个对象类别,或者还有其他几个有助于确定语义标签的类别。此外,将包裹区域的提议输入到卷积神经网络中进行分类,可以降低计算成本。
Recurrent neural network based methods
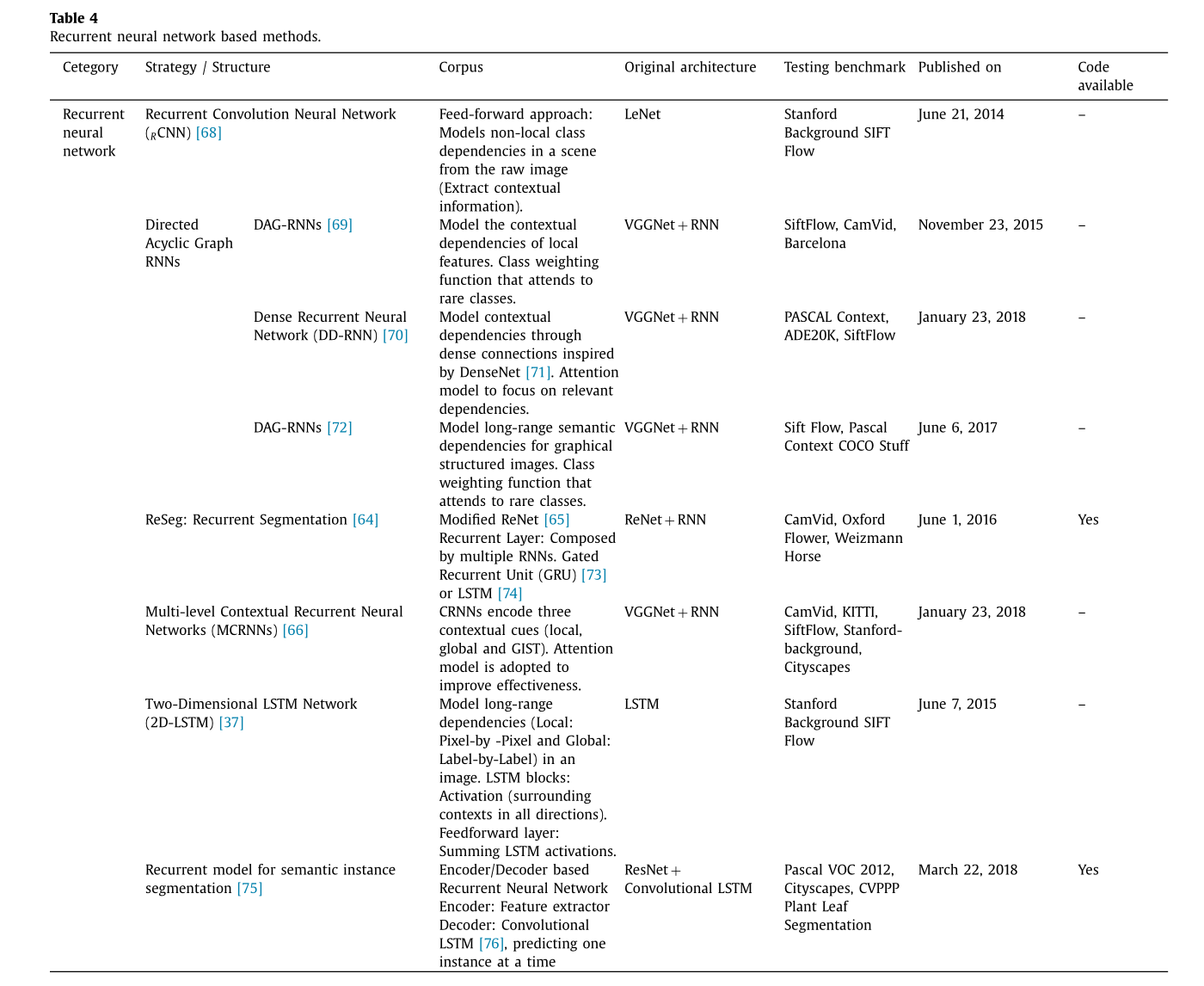
循环神经网络(RNN)最初是为处理序列数据而设计的60--62。除了在手写和语音识别方面取得的成就外,RNN 在计算机视觉任务(处理图像)中也非常成功。我们仅回顾了采用 RNN 的二维图像网络模型(将卷积层与 RNN 相结合)。由长短期记忆(LSTM)63模块组成的循环神经网络。RNN 能够从序列数据中学习长期依赖关系,并能够在序列中保持记忆,使其适用于许多计算机视觉任务,包括语义分割64,65和场景分割与标注66,67,基于 RNN 和 CNN 的组合使用。表 4 展示了基于 RNN 的方法。
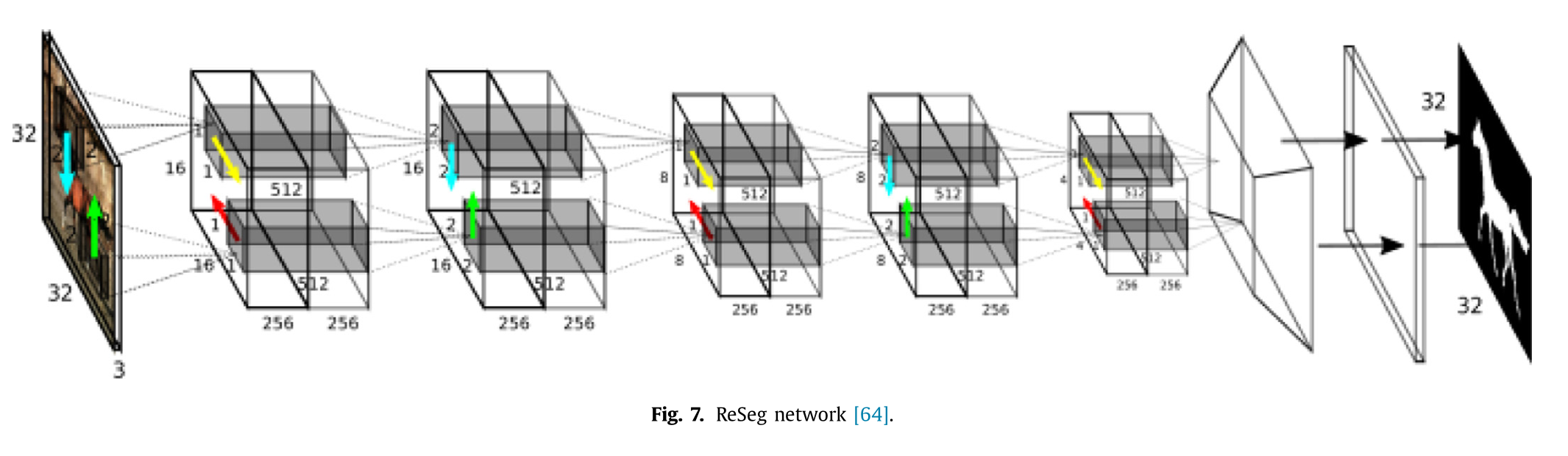
皮尼埃罗和科洛伯特68提出了一种卷积神经网络,该网络依赖于一种循环架构(RCNN)。RCNN 是一系列共享相同权重的浅层网络,在每个实例中使用缩小后的输入图像和网络前一实例的预测图,并自动学习平滑其预测标签。范等人66提出了用于场景标注的上下文 RNN。所提出的网络能够捕捉图像中的长程依赖关系(GIST、局部和全局特征)。这些特征(经过上采样)通过一个注意力模型67进行融合。萨尔瓦多等人75提出了一种基于编码器/解码器的循环神经网络架构,用于语义实例分割。所提出的架构与 FCN77架构非常相似(编码器:特征提取器),使用了跳接连接,但解码器部分是循环网络(卷积 LSTM76),每次预测一个实例(图像中的对象)并输出它们。比昂等人37提出了一种二维(2D)长短期记忆(LSTM)循环神经网络用于场景标注。2D LSTM 网络架构由四个 LSTM 块(用于传递周围语境)和一个前馈层(对 LSTM 激活值进行求和)组成。这种方法能够模拟图像中的长程依赖关系(包括局部和全局依赖关系)。维森等人64提出了一种基于 RNN 的架构,用于语义分割,称为 ReSeg,用于对从卷积神经网络中提取的局部通用特征的结构化信息进行建模。所提出的模型是对 ReNet 65 的修改和扩展版本。所提出的循环层由多个 RNN 组成(73,74),它们在水平和垂直方向上扫描图像(隐藏状态的输出),对局部特征进行编码,并提供相关的全局信息。ReNet 层堆叠在 FCN 的输出之上。图 7 展示了 Reseg 网络架构。
沙乌尔等人69使用图形递归神经网络(有向无环图递归神经网络,简称 DAG-RNN)来对图像中局部特征的长距离上下文依赖关系进行建模,以实现语义分割。他们提出了一种新的类别加权函数,以提高对非常见类别的识别准确率。受密集网络71的启发,范和凌70提出了一种具有图形结构的密集递归神经网络(DD-RNNs)架构,通过密集连接来对图像中的大量依赖关系进行建模。最近,沙乌尔等人72提出了一种 DAG-RNN 网络,用于对图形结构化的图像的长距离语义依赖关系进行建模(DAG-结构化)。他们提出的分割网络由三个模块组成:局部区域表示(使用预训练的 CNN)、上下文聚合(使用 DAG-RNN)和特征图上采样(反卷积网络)。他们还在训练过程中提出了一个类别加权损失,以克服类别不平衡问题或对罕见类别给予关注。
循环神经网络(RNN)在语义分割方面具有很大的优势;它具有循环连接(能够保留先前的信息)以及通过对图像进行长距离语义依赖关系的建模来捕捉图像中的上下文的能力。
Upsampling / Deconvolution based methods
卷积神经网络模型具有通过逐层传递自动学习高级特征的能力,但会牺牲空间信息。一个重要的理解是,在下采样操作中丢失的空间信息可以通过上采样和反卷积方法得以恢复 。其次是要开发用于提高空间精度的重建技术以及用于融合低层次和高层次特征的细化技术。表 5 展示了基于上采样/反卷积的方法。
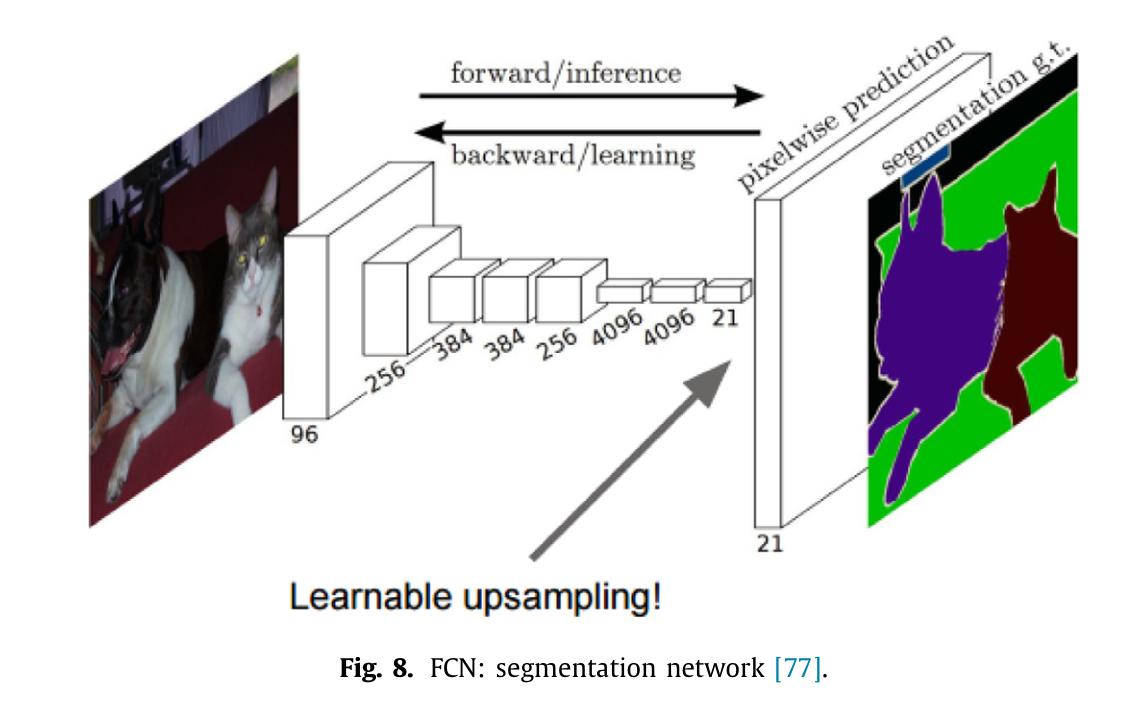
诺赫等人79利用这一理念,并通过学习反卷积网络开发了一个网络模型。卷积网络通过前馈操作来缩小激活值的大小,而反卷积网络则通过组合反池化和反卷积操作来扩大激活值。王等人78提出了一种对象感知的语义分割框架(OA-Seg),该框架使用了两个网络,即对象提议网络(OPN),用于预测对象边界框及其对象性得分,以及轻量级反卷积神经网络(Light-DCNN),用于将特征图进行上采样以获得更大的分辨率。朗等人77首先提出了全卷积网络(FCN),并在基于深度学习的语义分割方面取得了突破。FCN架构已成为语义分割的标准;大多数方法都采用了FCN架构。FCN将分类网络23,27,33转换为全卷积网络,并为任意大小的输入生成概率图。FCN通过在标准卷积网络中添加上采样层来从下采样层恢复空间信息。他们定义了一种跳跃式架构(浅层精细层),该架构将来自深层粗略层的语义信息与外观信息相结合,以实现精确且深入的分割。其基本思路是重新设计并优化分类模型(图像分类),以便从整个图像输入和整个图像真实值(语义分割的预测)中高效学习。这样一来,就能够将这些分类模型扩展到分割任务中,并通过多分辨率层组合来改进架构。图 8 展示了 FCN 架构。
巴德尼拉亚纳等人80提出了一种名为 SegNet 的编码器-解码器结构的深度全卷积神经网络。该编码器网络与 VGG 33 的拓扑结构相同,没有全连接层,之后是解码器网络(源自93),用于像素级分类。通过使用一组解码器(每个解码器对应一个编码器),SegNet 获得了比77中更高的分辨率。SegNet 的一个关键特点是信息传递是直接的,而非通过卷积进行传递。在处理图像分割问题,特别是场景分割任务时,SegNet 是最常用的最佳模型之一。
吉哈西和福尔克斯92提出了一种名为"拉普拉斯金字塔重建与细化"(LRR)的网络,因为其架构采用了拉普拉斯重建金字塔94。该架构利用低分辨率特征图来重建一个粗略且低频的分割图,然后通过添加来自更高分辨率特征图的更高频率细节来细化这个图。林等人88提出了一个名为"细化网络"(RefineNet)的多路径神经网络。RefineNet 是一种受残差连接设计启发的编码器-解码器架构34,由三个组件组成:残差卷积单元(RCU)、多分辨率融合和链式残差池化。多路径网络利用多个层次的特征,以递归的方式用集中于低层次的特征来细化低分辨率特征,从而生成用于语义分割的高分辨率特征图。伊姆斯等人91提出了一种名为"标签细化网络"(LRN)的改进结构架构。LRN 能够在网络的多个层级中预测分割标签,并在更精细的尺度上逐步细化结果。LRN 是一种编码器-解码器架构,并在多个层级(解码器的每个阶段)都有监督机制。赵等人87提出了图像级联网络(ICNet),该网络能够有效地利用低分辨率图像中的语义信息以及高分辨率图像中的细节。该网络侧重于融合来自多个层的特征。他们提出了一个级联特征融合(CFF)单元,用于将低特征图与高特征图进行融合。傅等人81提出了堆叠反卷积网络(SDN),其灵感来源于黄等人71的研究。其基本思路是将多个浅层反卷积网络一层一层地堆叠起来,以恢复高分辨率的预测结果。杰古等51提出了全卷积密集网络(FC-DenseNet),这是对71的扩展,通过添加上采样路径和跳跃连接来恢复完整的输入分辨率。比林斯基和普里萨里乌86提出了遵循编码器-解码器策略的架构。编码器基于 ResNeXt 架构,解码器由块(密集解码器的快捷连接)组成,能够生成语义特征图,并在单次推理中实现多级融合。
吴等人95提出了一种全组合卷积网络(FCCN),以改进 FCN 的上采样操作。该网络遵循逐层上采样的策略,每次上采样操作后输入特征图的尺寸都会翻倍。他们还提出了一个软成本函数,进一步改进了训练过程。最近在83中,他们通过一个高度融合的网络扩展了 FCCN。所提出的网络主要有三个部分:特征下采样、组合特征上采样和多次预测。融合网络利用低层的多尺度特征信息。使用多个软成本函数来训练所提出的模型。受到 RefineNet 的启发,李等人89提出了 RGB-D 融合网络(RDFNet)用于语义分割。所提出的架构由两个特征融合块组成:多模态特征融合(MMF)用于融合不同模态下的特征(RGB 和深度),以及多级特征细化块用于进一步细化特征以进行语义分割。伊斯兰等人90提出了门控反馈细化网络(G-FRNet),这是一种编码器-解码器风格的架构。所提出的门控机制(门单元)会依次接收两个特征图,即具有较大感受野的低分辨率特征图和具有较小感受野的高分辨率特征图,并将它们组合起来以生成上下文信息。由编码器网络生成的不同空间维度的特征图在传递至解码器(反馈细化网络)之前会先通过门单元。细化网络会逐步细化特征标签图。最近,Nanfack 等人82提出了基于编码器-解码器的压缩-分割网络架构。编码器模块采用了基于 SegNet 的 SqueezeNet 架构(使用防火模块并移除平均池化层),该架构受到了 SegNet 的启发,但去除了 VGG 的所有全连接层。压缩-解码器模块是防火模块和 SqueezeNet 的卷积层的逆过程。
Increase resolution offeature based methods
另一种方法是通过使用空洞卷积97和扩张卷积98来恢复空间分辨率,这两种方法能够生成用于密集预测的高分辨率特征图。扩张卷积在卷积层中引入了另一个参数"扩张率"(描述卷积核中值之间的空间距离),它能够在不损失分辨率的情况下扩大感受野。表 6 展示了基于特征的网络模型分辨率的提升情况。
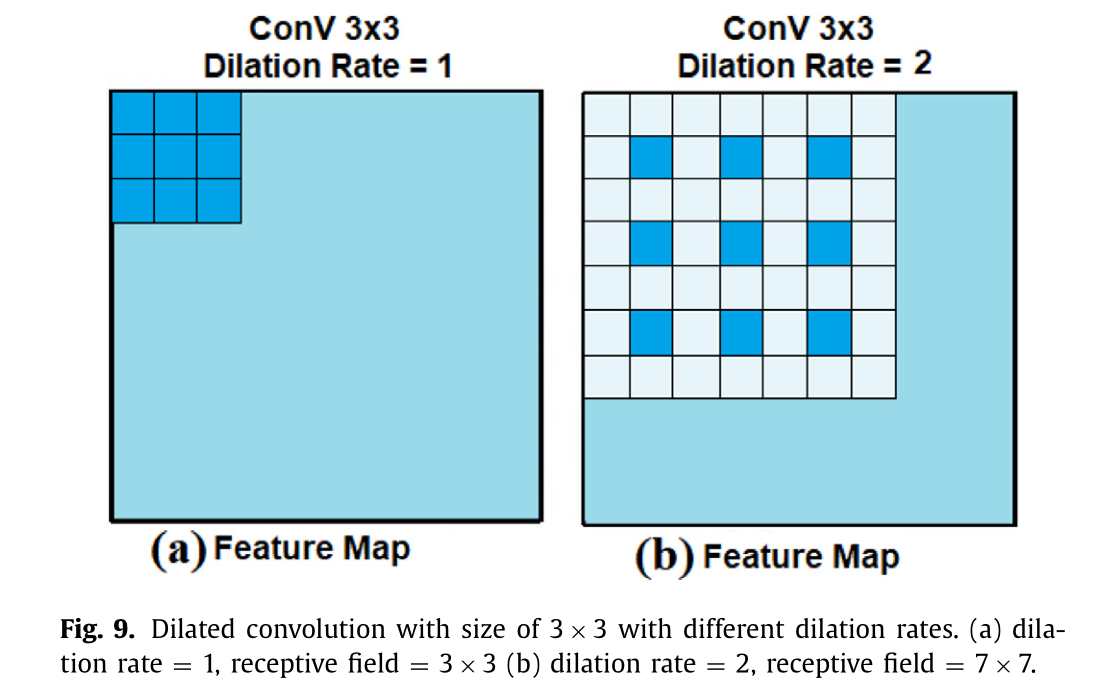
谷歌公司的 Chen 等人97提出了一种名为 DeepLab 的深度卷积神经网络模型。他们没有采用卷积操作,而是提出了 Atrous("空洞")卷积算法。Atrous 算法最初是由 Holschneider 等人106为计算无分采样小波变换(UWT)而开发的。DeepLab 架构与77中的架构相似,但进行了某些修改,例如将全连接层转换为卷积层、使用 8 像素的步幅、在最后两个池化层之后进行跳跃下采样,并通过引入零值来修改层中的卷积滤波器(将最后三个卷积层的长度增加 2 倍,第一个全连接层增加 4 倍)。所提出的方法与全连接条件随机字段(CRF)相结合,能够高效地生成语义准确的预测和详细的分割图。Yu 和 Koltun98开发了一个用于密集预测的卷积神经网络模块设计,使用扩张卷积来结合多尺度上下文信息,同时不损失分辨率,并对缩放后的图像进行分析以进行语义分割。此模块可在任何分辨率下插入到现有架构中。图 9 展示了具有不同膨胀率的膨胀卷积示例,这些膨胀率决定了卷积核中数值之间的间距。

特雷姆等人102提出了一种编码器-解码器结构架构(SQNet)。编码器是一种修改后的 SqueezeNet 架构(称为"火"),由卷积层和池化层组成。解码器基于并行扩张卷积层。吴等人105提出了一种全卷积残差网络(FCRN),这是一种用于生成任何更高分辨率特征图的新网络,且无需更改权重。他们提出了一种用低分辨率网络模拟高分辨率网络的方法,以及一种在线自举训练方法。在99中,陈及其团队提出了空洞空间金字塔池化(ASPP)模块,它由多个具有不同采样率的并行空洞卷积层组成,以在多个尺度上对物体进行强烈分割。图10展示了ASPP的示例。
所提出的网络基于最先进的 ResNet-101 34 图像分类深度卷积神经网络。他们将该网络与一个全连接的条件随机字段(CRF)相结合,以提高对象边界定位的准确性。于和科尔顿 104 提出了另一种深度神经网络,名为扩张残差网络(DRN),这是一种类似于残差网络 ResNet 34 的架构,在其中内部子采样层的一部分被扩张 98 替代,以提高分辨率。子采样操作意味着从一些内部层中去除步长,从而提高下游分辨率并减少后续层的接收域。他们还提出了一种方法来消除由膨胀操作引入的网格化伪影(即去网格化),这进一步提高了性能。随后,陈等人100重新审视了空洞卷积,并提出了一个名为 DeepLab V3 的新系统网络。他们在其中设计了新的模块,其中空洞卷积以级联或并行的方式工作(如图 11(a)所示的空间金字塔池化),通过采用多个空洞率来捕捉多尺度上下文,并使用批量归一化进行训练。他们的主要思想是复制 ResNet 34 中最后一个块的多个副本,并以级联的方式排列它们 。王等人103提出了一种名为设计密集上采样卷积(DUC)的方法。DUC 的基本思想是将标签图转换为具有多个通道的较小标签图(将标签图划分为具有与输入特征图相同高度和宽度的相等子部分)。他们还提出了在编码阶段的混合膨胀卷积(HDC)框架,在该框架中有效地扩大了网络的感受野以聚合全局信息。最近在101中,DeepLab V3+ (DeepLab V3 的扩展版本)被提出。受阿尔瓦雷斯等人107的研究启发,作者提出了一种解码器模块。在该模块中,编码器特征的采样率从100中的 16 倍提升至 4 倍,然后与具有与图 11(b)中所示相同空间分辨率的网络骨干网络的相应低级特征进行拼接。他们采用了 Xception 模型31,并对空洞空间金字塔池化(ASPP)和解码器模块都应用了深度可分离卷积(以降低计算复杂度)。
与使用更大滤波器的常规卷积相比,空洞卷积能够有效地扩大滤波器的视野范围,同时无需增加参数数量或计算量。在密集预测任务中,扩张卷积是一种简单但强大的替代方法,可作为反卷积的替代方案。
Enhancement of features based methods
基于特征的方法的改进包括在多尺度上提取特征,或者从一系列嵌套区域中提取特征。在用于语义分割的深度网络中,卷积神经网络(CNNs)被应用于图像的方形区域(通常称为以每个像素为中心的固定大小的核),通过观察其周围的小区域来标记每个像素。具有广泛和宽泛背景(感受野大小)的网络对于更好的性能至关重要,但这样做会增加计算复杂度。在保证计算效率的同时,可以考虑采用多尺度特征提取或从一系列嵌套区域中提取特征的策略。表 7 展示了基于特征的网络模型的改进情况。
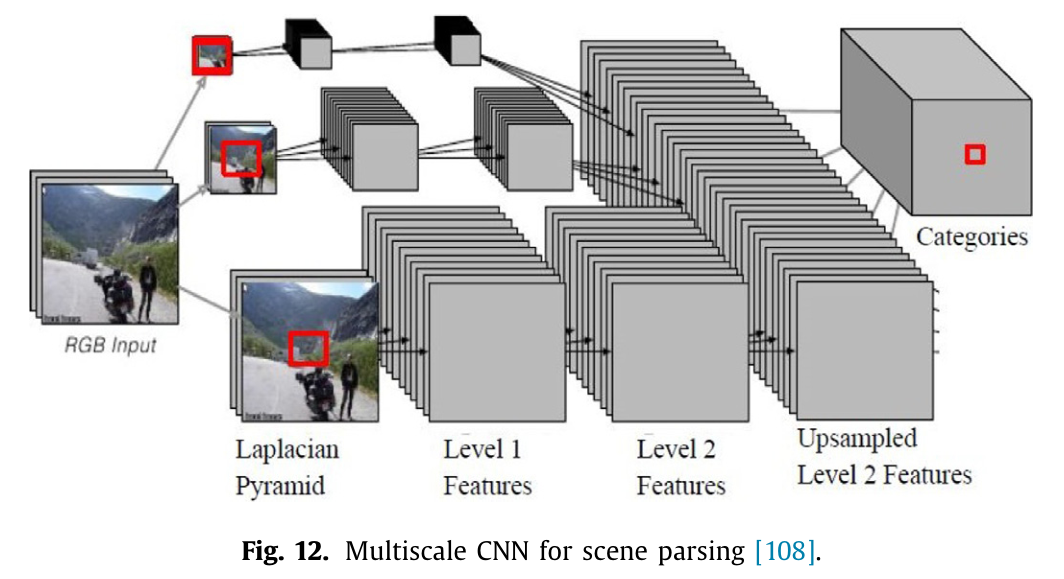
阿尔瓦雷斯等人107提出了一种网络算法,用于在不同尺度和分辨率下学习局部特征,该算法使用不同的核尺寸。这些特征通过加权线性组合(每个类别的特征具有不同的权重)进行融合,这些权重是在同一时间(离线)直接从训练数据中学习而来的。法雷伯等人108提出了一种方法,利用图 12 中所示的多尺度卷积网络从图像金字塔(输入图像的拉普拉斯金字塔版本)中提取多尺度特征向量。每个特征向量都对围绕每个像素位置的多个大小的区域进行编码,从而涵盖广泛的上下文。
库普里等人109也采用了类似的方法,并提出了一种卷积网络,利用图像深度信息来学习多尺度特征。刘等人110提出了名为"多尺度块聚合"(MPA)的策略。所提出的网络为对象解析生成多尺度块,同时对每个块进行分割和分类,并将它们聚合起来以推断对象。哈里哈拉恩等人111提出了一种像素分类方法(多层次抽象和尺度),即"超列"。其基本思路是提取卷积神经网络(CNN)早期层和末尾层的特征信息,以实现精确的定位和高语义表达,然后使用双线性插值对每个特征图进行缩放。此外,对于每个位置,会将部分或全部特征拼接成一个单一的向量。
Mostajabi 等人117提出了一种名为"Zoom-Out 使用超像素"的前馈分类方法(SLIC 118)。该方法从超像素周围的不同层次(局部层次:超像素本身;远距离层次:足以覆盖物体的一部分或整个物体的区域;场景层次:整个场景)的空间上下文中提取特征,以辅助该超像素的标记决策。然后,它在每个层次上计算特征表示,并将所有特征组合在一起,然后将它们输入到分类器中。Chen 等人67提出了基于注意力的模型,该模型能够每次选择要查看的输入部分以执行任务。所提出的注意力模型根据图像中呈现的对象尺度(例如,模型学会对粗尺度上的特征给予较大权重以处理大型对象)来学习根据多尺度特征进行加权。然后,对于每个尺度,注意力模型输出一个权重图,该图按像素对特征进行加权,然后将所有尺度上生成的 FCN 评分图的加权和用于分类。
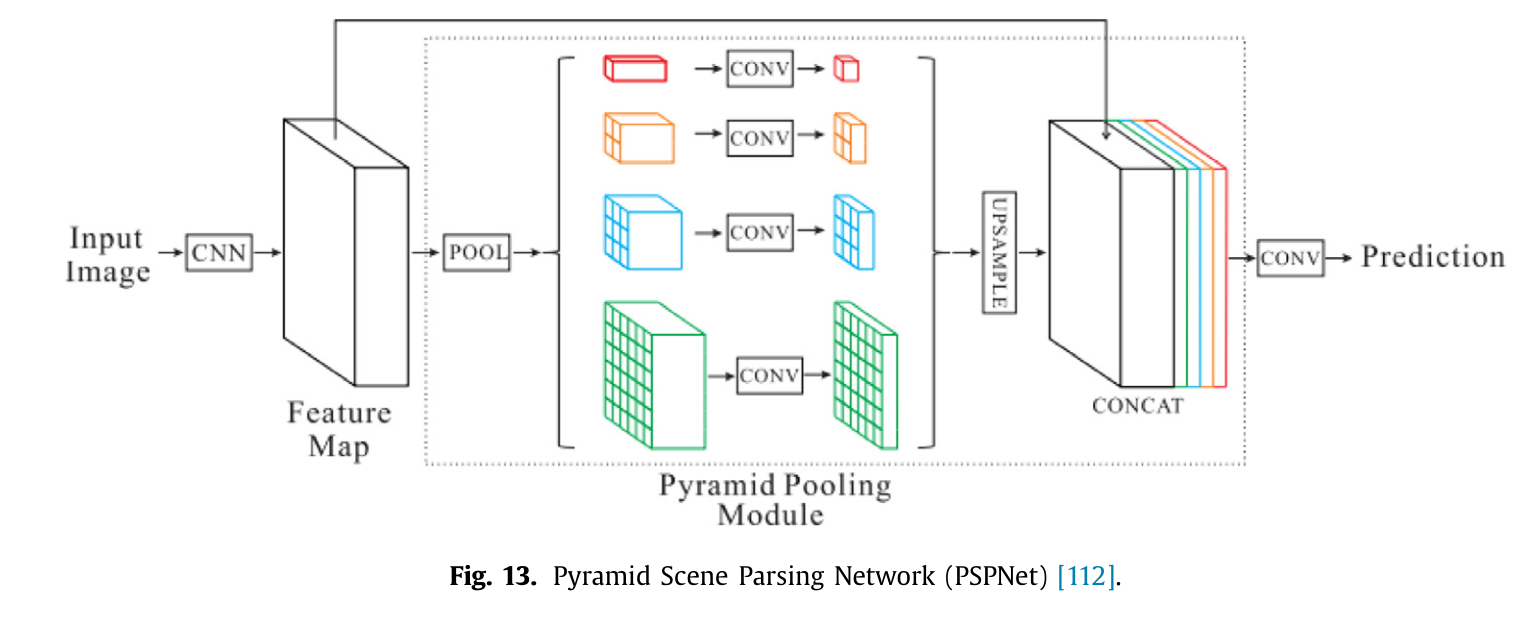
赵等人112提出了用于语义分割的金字塔场景解析网络(PSP-Net),该网络能够进行多尺度特征的整合。他们引入了由大核池化层组成的金字塔池化模块(如图12所示),该模块经实验证明是一种有效的全局上下文先验,包含了不同金字塔尺度的信息,并在不同子区域之间有所变化。它将特征图与并行池化层的上采样输出进行拼接。这一想法也被称为中间监督。这些表示被输入到卷积层中以获得最终的像素级预测。图13展示了PSPNet的架构。
沃和李113提出了一种具有多尺度扩张卷积层的深度网络架构,用于从多分辨率输入图像中提取多尺度特征。其基本思路包括级联扩张卷积(连续层连接),每一层的卷积率都高于前一层,从而实现更密集的特征图。然后,所有特征图都被调整至相同的分辨率,并融合到一个最大值层114中,以获得来自所有特征图的最具驱动性和主导性的特征。林等人116提出了一种名为级联特征网络(CFN)的网络。它利用深度信息,将图像划分为代表物体和场景视觉特征的层(多场景分辨率)。提出具有上下文感知的感知域 CaRF(基于超像素),将局部上下文的卷积特征聚合为强大的特征。CaRF 生成上下文表示,为低场景分辨率区域生成大型超像素,为具有更高场景分辨率的区域生成更精细的超像素。最近,丁等人115提出了一个上下文对比局部(CCL)模型,以获得多尺度特征(包括上下文和局部)。他们并未采用简单的求和方式,而是提出了门控求和融合策略,以整合合适的分数图,从而使网络能够选择更优且更符合期望的特征尺度。
有几种方法旨在捕捉多尺度特征,高层特征包含更多的语义信息而较少的位置信息。将多分辨率图像的优势与多尺度特征描述符相结合,能够在不损失分辨率的情况下提取图像中的全局和局部信息,从而提高了网络的性能。
Semi and weakly supervised concept
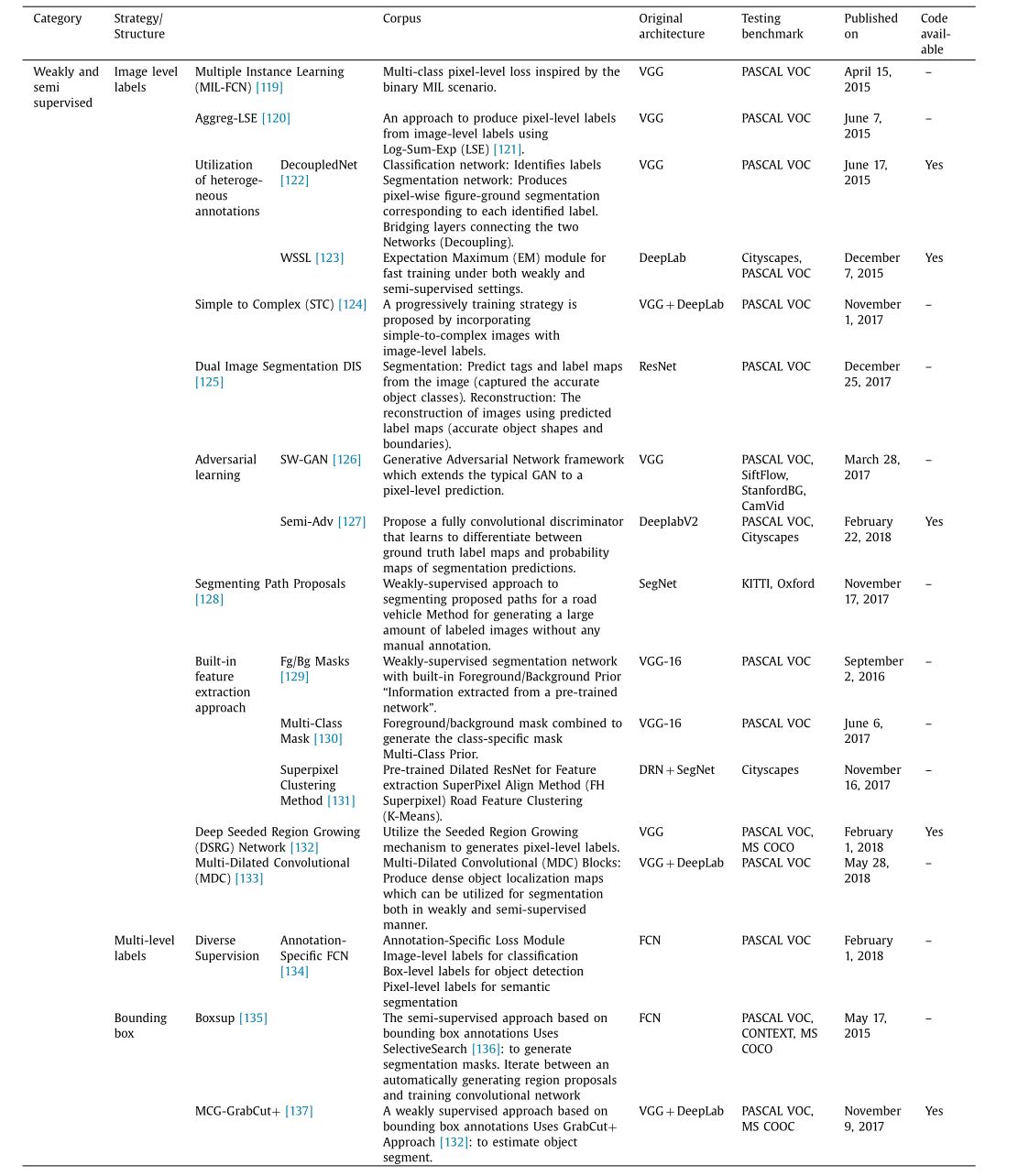
卷积神经网络(CNN)的深度正逐渐加深,其深度和宽度(网络的层数以及每一层的单元数量)不断增加。深度卷积神经网络需要大规模的数据集和强大的计算能力来进行训练。手动收集有标签的数据集非常耗时,并且需要大量的人力投入。为了减轻这些工作量,半监督或弱监督方法借助深度学习技术被应用。表 8 展示了用于语义分割的半监督和弱监督网络模型。
帕塔克等人119的研究是首个将针对物体识别进行预训练的卷积神经网络(CNN)进行微调的工作,该研究是在弱监督的分割环境中使用图像级别的标签来实现这一目标。他们引入了一种全卷积网络方法,该方法依赖于多实例学习(MIL-FCN)138,即从表示对象存在或不存在的弱图像级别标签中学习像素级别的语义分割。他们提出了一种受二元 MIL 情景启发的多类像素级别损失。皮尼埃罗和科洛伯特120提出了一种从图像级别标签生成像素级别标签的弱监督方法,使用对数和指数(LSE)121方法,该方法在训练过程中对图像的所有像素赋予相同的权重。帕潘德鲁等人123提出了一种使用弱标注(无论是单独使用还是与少量强标注结合使用)的弱监督和半监督学习方法。他们开发了一种称为期望最大化(EM)的方法,用于从弱标注数据中训练深度卷积神经网络(DCNN)。洪等人122提出了一种半监督方法(DecoupledNet),该方法使用两个独立的网络,一个用于分类(对对象标签进行分类),另一个用于分割(对每个分类标签进行图-地分割)。戴等人135提出了一种基于边界框标注的方法(BoxSup)。无监督的区域提议方法(选择性搜索53)用于生成分割掩码,这些掩码用于训练卷积网络。所提出的 BoxSup 模型,通过使用大量边界框进行训练,提高了对象识别的准确率(对象中间部分的准确率),并改善了对象边界。科赫雷娃等人139提出了一种用于语义分割的框驱动分割技术,该技术使用类似于 Grab Cut 的算法140从边界框标注中生成用于训练的输入标签,而无需修改训练过程。罗等人125提出了一种弱和半监督的双图像分割(DIS)学习策略,该策略执行分割(捕获准确的对象类别)和重建(准确的对象形状和边界)。其理念在于预测标签、生成标签图,并利用预测得到的标签图来重建图像。
萨勒等人129提出了带有内置前景/背景先验的弱监督分割网络。其主要思路是直接从网络自身中提取定位信息(提取前景/背景掩码)。随后在130中,他们扩展了这项工作,通过将前景/背景掩码与借鉴周等人141的思路从弱监督定位网络中提取的信息进行融合,来获得多类(特定类别的)掩码。斋藤等人131提出了一种方法,该方法使用从具有内置语义分割先验的预训练扩张式 ResNet 中提取的特征图。他们提出了一种超像素聚类方法来生成道路聚类(选择图像底部一半区域内的最大聚类),这些聚类被视为用于训练卷积神经网络进行分割的标签。巴恩斯等人128开发了一种用于自动驾驶应用的弱监督方法,用于生成大量带有路径提议的标注图像(来自多个传感器和驾驶过程中收集的数据),这些图像无需任何人工标注。叶等人134提出了一种从具有三种不同类型标注(即用于分类的图像级别标签、用于对象检测的框级别标签和用于语义分割的像素级别标签)的图像中学习卷积神经网络模型的方法。他们提出了一个特定于标注的损失模块(有三个分支,每个分支具有不同的损失函数),旨在为这三种不同的标注分别训练网络。
索利等人126提出了一种基于对抗学习的半监督语义分割方法,该方法受到生成对抗网络(GANs)142的启发。随后,尤尔达库尔和耶梅兹154提出了类似的方法,该方法包含两个子网络:分割网络(用于生成类别概率图)和判别网络(用于利用有标签和无标签数据生成空间概率图)。韦等人133提出了一种弱监督和半监督的方法,通过使用多个扩张卷积实现。他们提出了带有多扩张卷积块的增强分类网络(MDC),该网络生成密集的对象定位图,用于以弱监督和半监督的方式进行语义分割。黄等人124提出了一个弱监督网络,该网络利用图像内的上下文信息生成标签。他们提出了一个种子区域生长模块,利用图像标签从感兴趣的对象中找到小而细微的具有区分性的区域,以生成完整且精确的像素级标签,这些标签用于训练语义分割网络。韦等人143提出了一种从简单到复杂(STC)网络,这是一种弱监督方法,利用图像级别的标注。其基本思路是首先从简单的图像中学习(使用具有判别性的区域特征整合(DRFI)生成显著性图),然后将所学网络应用于复杂的图像(生成复杂图像的像素级分割掩码)以实现语义分割。
半监督和弱监督学习旨在减轻完全标注的负担。这些方法通过使用图像级别的标签(关于哪些对象类别存在的信息)和边界框(粗略的对象位置)的形式的弱标注来提高学习性能。
Spatio-temporal based methods
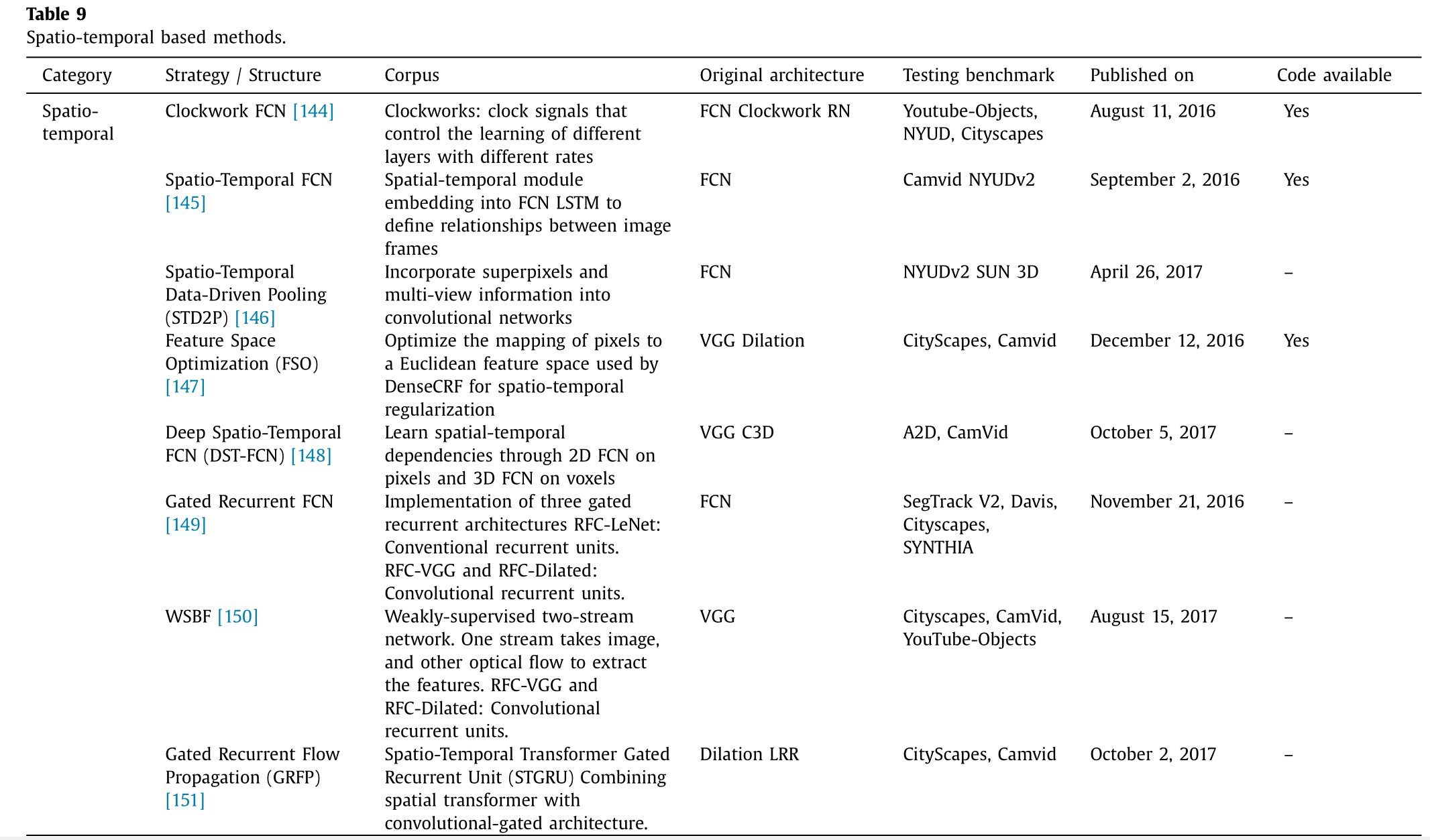
在一段视频中,各帧之间相互关联,并具有时间信息(即连续帧序列的特征),这些信息对于从语义角度解读视频非常有用。时空结构化预测在有监督和半监督模式下都可能非常有用。表 9 展示了基于时空的用于语义分割的网络模型。
在循环神经网络(RNN)与卷积神经网络(CNN)的结合应用中,提出了多种视频分割方法。法伊亚兹等人145提出了一种全卷积网络------时空全卷积网络(STFCN),该网络利用空间和时间特征。他们提出了一个时空模块,利用长短期记忆网络(LSTM)的优势来定义时间特征。将单帧中区域的空间特征图输入到LSTM中,以推断与该帧之前同等区域的空间特征之间的关系。此外,将空间和时间信息输入到扩张卷积网络(98稍作修改)中进行上采样,并进行融合(求和操作)以进行语义预测。赫等人146提出了时空数据驱动池化模型(STD2P),这是一种通过使用超像素和光流来整合多视图信息的方法。多视图语义分割的目标是利用来自不同视图的潜在更丰富的信息,从而获得比单视图更好的分割效果。邱等人148提出了基于二维/三维的全卷积网络的架构模型,名为深度时空全卷积网络(DST-FCN),该模型利用了像素和体素之间的空间和时间依赖性。所提出的架构是一个双流网络,即顺序帧流(用于空间信息的 2DFCN 和用于时间信息的 ConvLSTM)和剪辑流(基于体素级别的 C3D 152 开发的 3DFCN)。帕维尔等人153提出了一种利用空间和时间信息来处理图像序列的循环卷积神经网络模型。尤尔达库尔和耶梅兹154提出了一种网络,它结合了 RGBD 视频中的颜色和深度信息,使用卷积和循环神经网络框架进行语义分割。
一些架构是基于门控循环架构来解决梯度问题的。巴拉斯等人155使用了每个像素感知信息(从深度卷积网络的不同层级提取的视觉表示)来利用门控循环单元循环网络捕捉视频中的时空特征信息。西姆等人149提出了一种基于门控循环架构的全卷积网络(RFCN)。按照两种方法,即传统的循环单元(RFCLeNet)和卷积循环单元(RFC VGG、RFC Dilated),使用了三种不同的架构,以较少的参数学习时空特征。尼尔森等人151提出了门控循环流传播网络。他们提出了时空变换门控循环单元(STGRU),将空间变换(用于光流变形)的优势与卷积门控架构(以自适应传播和融合估计)相结合。谢尔-哈默等人144提出了一种名为"钟表装置"的网络,它是由全连接网络和钟表式循环网络156组合而成的。该网络将各层分为不同速率(固定时钟速率或自适应时钟)的阶段,并通过跳跃连接将它们融合在一起。萨莱赫等人150提出了一种用于视频语义分割的弱监督框架,该框架对前景和背景类别一视同仁。其基本思想是同等对待多个前景对象和多个背景对象。他们提出了一种从分类器中提取特定类别热图的方法,无需像素级别或边界框标注即可对两种类别进行定位。库杜等人147提出了一种优化全连接条件随机场所使用的特征空间的模型,以进行空间-时间正则化。钱德拉等人157提出了一种用于空间-时间结构化预测的视频高斯条件随机场方法,这是对158方法的扩展。FCN 网络会获取单个像素的类别得分、空间成对项和时间成对项,这些信息会输入到 G-CRF 模块中,该模块执行推理(线性系统)以得出最终的预测结果。
Methods using CRF / MRF
语义分割涉及像素级别的分类,而这种像素级别的分类往往会产生不理想的结果(如错误、不准确和有噪声的预测),这些结果与图像的实际视觉特征无法相容159。
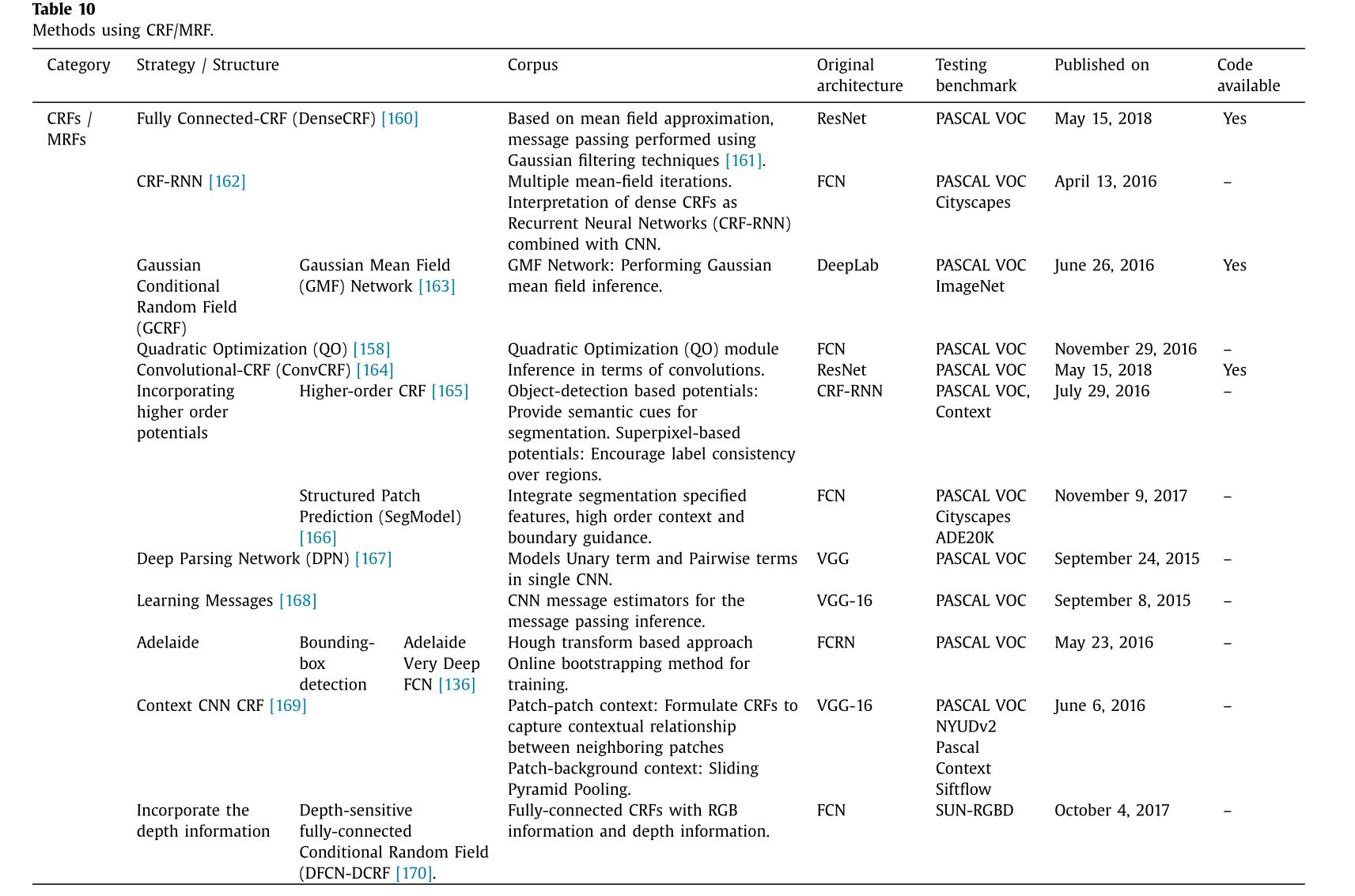
马尔可夫随机场(MRF)及其变体条件随机场是广泛用于解决这些问题的经典框架。它们既包含单个项(每个像素对标签分配的置信度)也包含成对项(相邻像素之间的约束)。卷积神经网络(CNNs)可以通过训练来模拟单个项和成对项的潜在值,以捕捉上下文信息。这种上下文为场景理解任务提供了重要信息,例如空间上下文,它为物体、场景和情况之间的语义兼容性/不兼容性关系提供了依据。条件随机场(CRFs)既可以作为后处理步骤,也可以作为端到端的处理方式,用于在语义分割中平滑和优化像素预测。它们将分类器的类别得分与像素和边缘或超像素之间局部交互所获取的信息相结合 。表 10 展示了使用 CRFs 的网络模型。
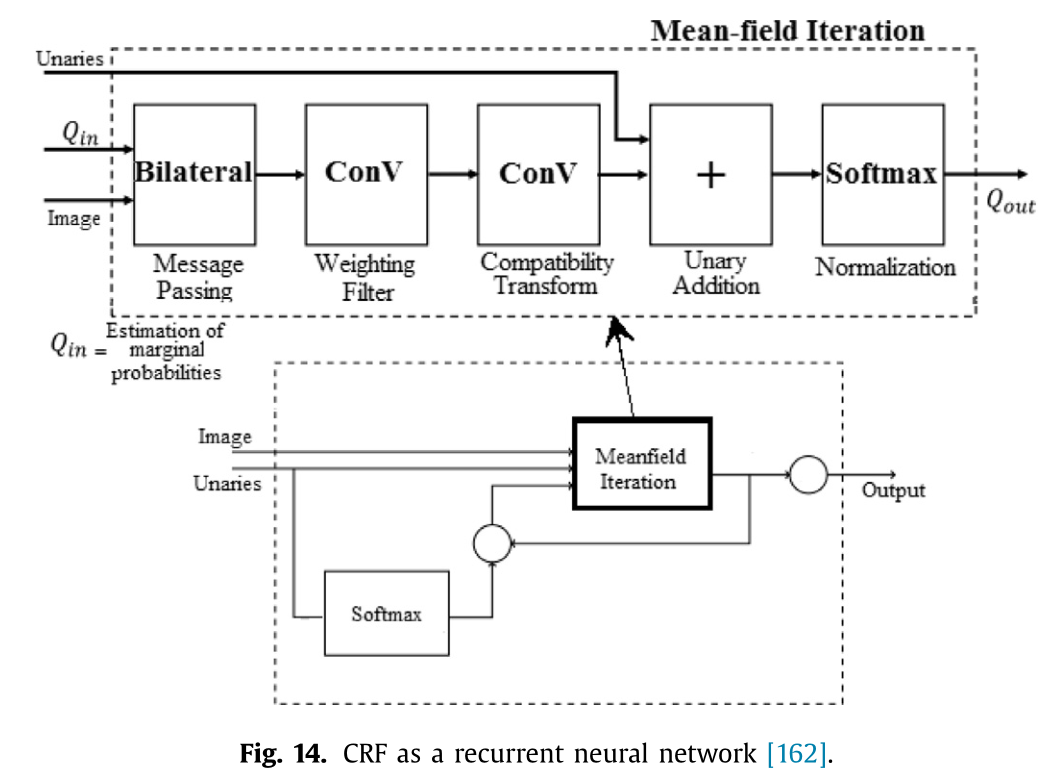
克拉恩布尔等人160提出了一种全连接的条件随机场(DenseCRF)模型,其中两两边界的潜在值由高斯核的线性组合来定义。该方法基于均值场近似,使用高斯滤波技术进行消息传递161。方法79,97,123,129,133,135,139,150将全连接条件随机场与其提出的深度卷积神经网络相结合,以生成准确的预测和详细的分割图,从而提高性能。郑等人162将具有高斯滤波技术的均值场推理算法应用于密集条件随机场,形成了一个循环神经网络(CRF-RNN),用于基于条件随机场的概率图模型的结构化预测。图 14 展示了条件随机场作为循环神经网络的形式。
维姆卢帕利等人163提出了一种名为高斯均值场(GMF)的模型,该模型用于对语义分割任务中的单元势能、成对势能以及高斯条件随机场推理进行建模。在所提出的网络中,每一层的输出都更接近其输入所估计的最大后验概率(MAP)。钱德拉等人158提出了一种使用二次能量函数的高斯条件随机场(G-CRF)模块,该模块能够捕捉单元和成对的相互作用。林等人169提出了一种上下文卷积神经网络(CNN)CRF模型,该模型共同学习卷积神经网络和条件随机场(CRF)。他们将CRF与卷积神经网络的成对势能相结合,以捕捉相邻块之间的上下文关系,并使用滑动金字塔池化(多尺度图像网络输入)来捕捉块与背景的上下文关系,这些关系可以结合起来以提高分割效果。168没有学习势能,而是提出了一种方法,学习用于结构化条件随机场(CRF)预测的消息传递推理的CNN消息估计器。泰希曼和西波拉164提出了卷积条件随机场(ConvCRFs)方法,该方法将消息传递推理重新表述为卷积形式。
一些方法采用了高阶势能(基于对象检测或超像素)并将其建模为卷积神经网络(CNN)的层,当使用平均场推理时效果显著,有助于提高语义分割性能。阿纳布等人165提出了一种方法,其中将 CRF 模型与对象检测器(用于为分割提供语义线索)和超像素(具有区域内的标签一致性)一起用于端到端可训练的 CNN 中的高阶势能。沈等人166提出了联合 FCN 和 CRF 模型(SegModel),该模型整合了指定的分割特征,构成了用于语义分割的高阶上下文和边界引导(基于双边滤波的 CRF)。刘等人167提出了深度解析网络(DPN),它在单个 CNN 中建模单个项和成对项(即高阶关系和标签上下文的混合),通过扩展 VGG 网络并添加一些用于建模成对项的层来实现高性能。江等人170将深度信息作为条件随机字段的互补信息加以利用。他们提出了深度敏感的全连接条件随机场与全卷积网络相结合的模型(DFCN-DCRF)。其基本思路是将深度信息添加到扩张卷积网络和全连接条件随机场中,以提高语义分割的准确性。
利用深度卷积神经网络进行条件随机场推理能够提高像素级别的标签预测效果,从而生成清晰的边界和密集的分割。有几种方法能够学习条件随机场中的任意潜在函数。它已被用作后处理步骤,以端到端的方式实现,并被表述为循环神经网络,并被纳入现有的神经网络中作为模块。
Alternative to CRF
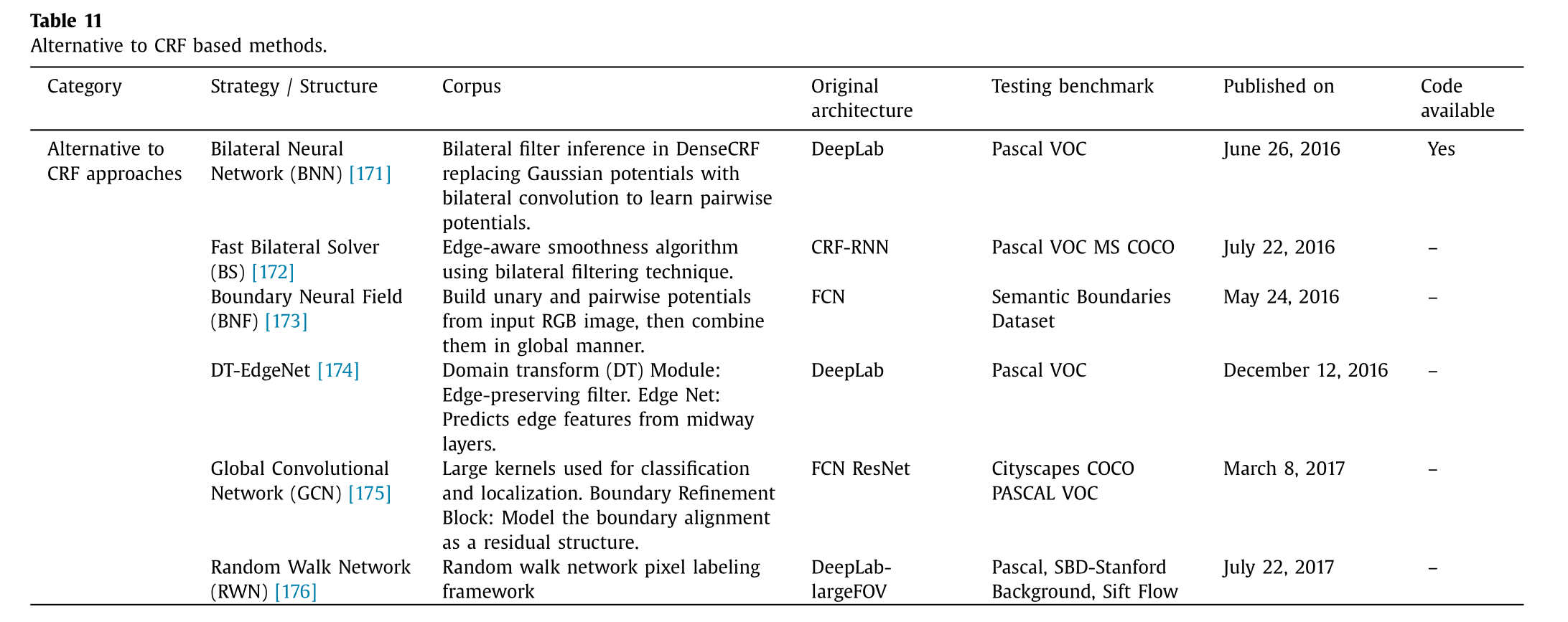
将条件随机字段整合到原始架构中是一项艰巨的任务,因为这会增加参数数量,并且在训练过程中会带来极高的计算复杂度。此外,大多数条件随机字段所使用的基于颜色的手工构建的相似性特征可能会导致空间上的错误预测。已有几种方法被提出以解决这些问题,并可作为条件随机字段的替代方案。表 11 展示了替代条件随机字段的网络模型。
伯塔西乌斯等人173提出了一种名为"边界神经场"(BNF)的全卷积网络架构,用于预测语义边界,并通过全局优化生成语义分割图。BNF 以全局方式将输入的 RGB 图像中的单元势能(由全卷积网络预测)和成对势能(基于边界的像素亲和力)结合在一起。其基本思想是为每个不同的对象类别为像素分配前景和背景标签,并应用约束松弛。随后在176中,他们提出了"卷积随机游走网络"(RWN)来解决同样的问题,该模型基于随机游走方法177。该网络模型预测语义分割势能和像素级别的亲和力,并通过所提出的随机游走层将它们结合在一起,该层应用空间平滑预测。
贾潘尼等人171提出了一种基于高斯双边滤波器的网络,称为双边神经网络(BNN)。该网络通过在全连接条件随机场160中使用双边滤波器进行推理(通过将高斯势能替换为双边卷积来实现),以学习全连接条件随机场的成对势能。巴伦和波尔172提出了一种使用双边滤波技术的边缘感知平滑算法,将其命名为双边求解器。彭等人175提出了一种基于残差的边界细化模型------全局卷积网络(GCN),用于语义分割。他们提出了边界细化块(FCN 结构,不含全连接和全局池化层),将边界对齐建模为残差结构。陈等人174提出了一种具有域变换(DT)模块的模型,作为替代条件随机场的边缘保持滤波方法。该模型由三个模块组成。第一个模块基于 DeepLab 生成语义分割分数预测。第二个模块称为边缘网络,从中间层预测边缘特征,第三个模块是一个名为域变换(递归滤波)的边缘保持滤波器,该滤波器在179中提出。已有多种方法被提出,可作为 CRF 的替代方案,其优点在于计算速度快且参数数量较少。双边滤波技术在深度学习框架的构建中可能是一个有用的工具。
Datasets and evaluation for deep learning techniques
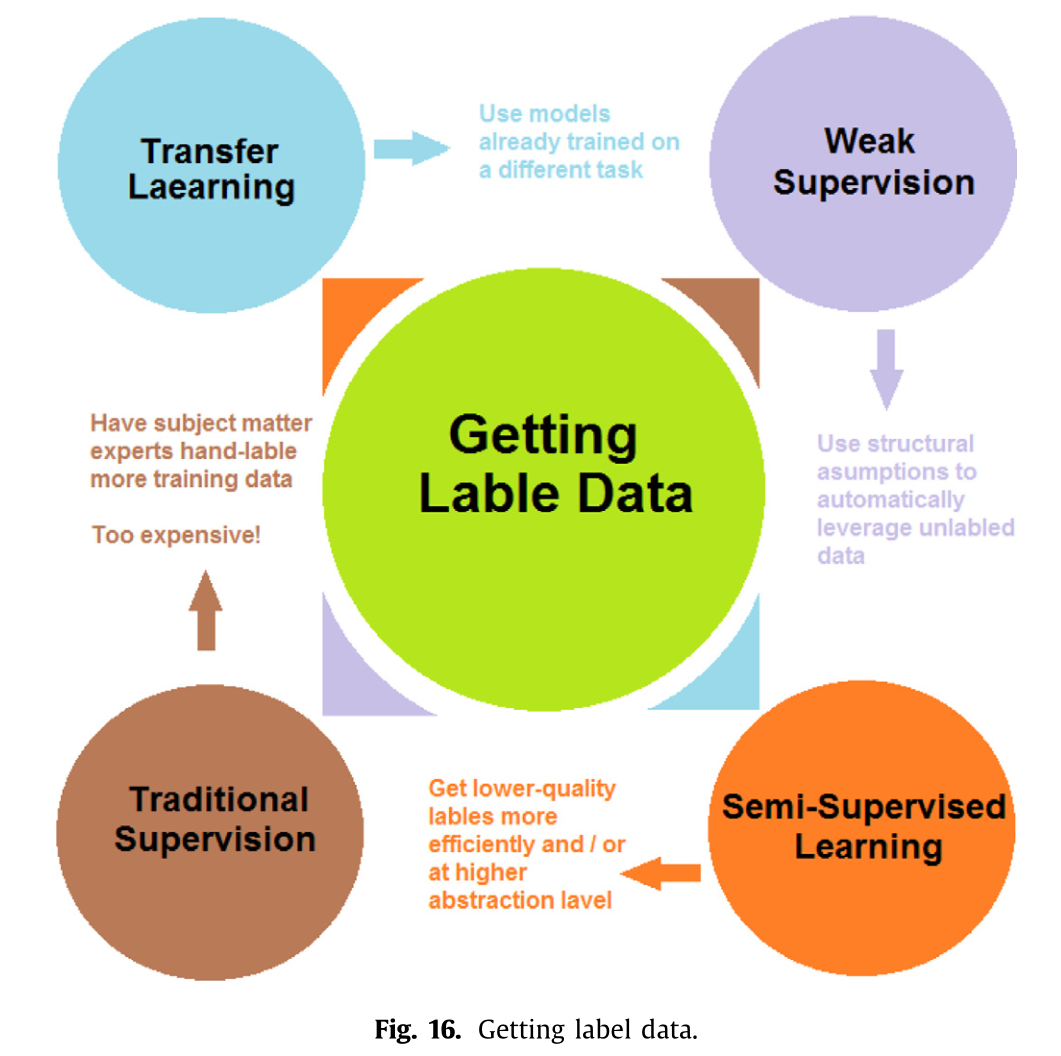
基于深度学习技术的任何分割系统所面临的最困难问题之一,就是如何收集数据以构建合适的数据集。如图 16 所示,有四种获取标注数据的方法。传统监督:人工标注数据;弱监督:利用未经过人工标注的无标签数据自动获取;半监督学习:部分标注数据和部分无标注数据;迁移学习:以预训练模型作为起点。
Datasets
该数据集充当了深度学习网络训练和测试的基准。在过去几年中,已经构建了多个用于深度学习的数据集,这促使研究人员创造出具有更强泛化能力的新模型和策略。这些数据集可以根据数据的性质进行分类。
汽车相关的数据集包括:CamVid 数据集180,该数据集被认为是首个具有语义标注视频的数据集;戴姆勒城市分割181、城市景观182、Mapillary 视图183以及最新的阿波罗景观场景解析184,后者专注于城市街道场景的语义理解。KITTI185 数据集用于各种计算机视觉任务,如 2D/3D 物体检测、立体视觉、光流和跟踪。合成数据集186,187由从真实开放世界的游戏中提取的 1000 张图像组成。
数据集具有普遍性;PASCAL VOC 188 是深度学习语义分割中最受欢迎且应用最广泛的数据集之一,CIFAR-10/100 189 包含多达 60,000 张图像,提供了 10 和 100 种不同类别的 32×32 小图像。一个非常出色的 ImageNet 190 数据集包含超过 1400 万张已标注图像,SegTrack v2 191 是一个视频分割数据集,每个帧都有多个对象的标注,而 PASCAL Context 192 是 PASCAL VOC 的附加标注集。微软-COCO 193 是一组包含复杂日常场景的图像集合,包含常见的自然物体;ADE20K 194 同时包含室内和室外图像,具有很大的变化;而 DAVIS 195 数据集包含具有像素级精确真实值的密集标注视频。最近开发的 COCO stuff 196 数据集通过为原始 COCO 数据集添加更全面的物品标注而进行了扩充。
室内环境数据集;NYUDv2 197 由来自各种室内场景的 RGB-D 图像和视频序列组成,康奈尔 RGB-D 198 包含已标注的办公室和家庭场景点云,ScanNet 199 包括超过 1500 个已标注的场景,其中包括 3D 相机姿态、表面重建和语义分割。斯坦福 2D-3D 200 包含来自 2D/3D 领域的相互注册的模态,包含 71882 张 RGB 图像(包括常规和 360°图像),以及相应的深度、表面法线和语义注释。SUN 3D 201 和 SUN RGB-D 202 数据集包含用于基于空间场景的大型空间的视频。理解。
对象数据集;RGB-D 对象 v2 203 包含 25000 张常见家居物品的图像,涵盖 51 个类别;YouTube 数据集 204 包含 126 个视频。
户外环境数据集;微软剑桥 205 包含 591 张关于 21 种物体类别的真实户外场景照片;格拉茨-02 206 是在 INRIA 创造的一个自然场景物体类别数据集。LabelMe 207 包含来自西班牙不同城市拍摄的 8 个不同类别的户外图像;巴塞罗那数据集 208 是 LabelMe 的一个子集;斯坦福背景 209 和 PASCAL SBD 210 是从 PASCAL VOC 收集的;Sift-flow 211 包含 2688 张 256×256 像素的图像和 33 个类别,而弗赖堡森林 212 则描绘了不同光照条件、阴影和太阳角度下的户外森林环境。
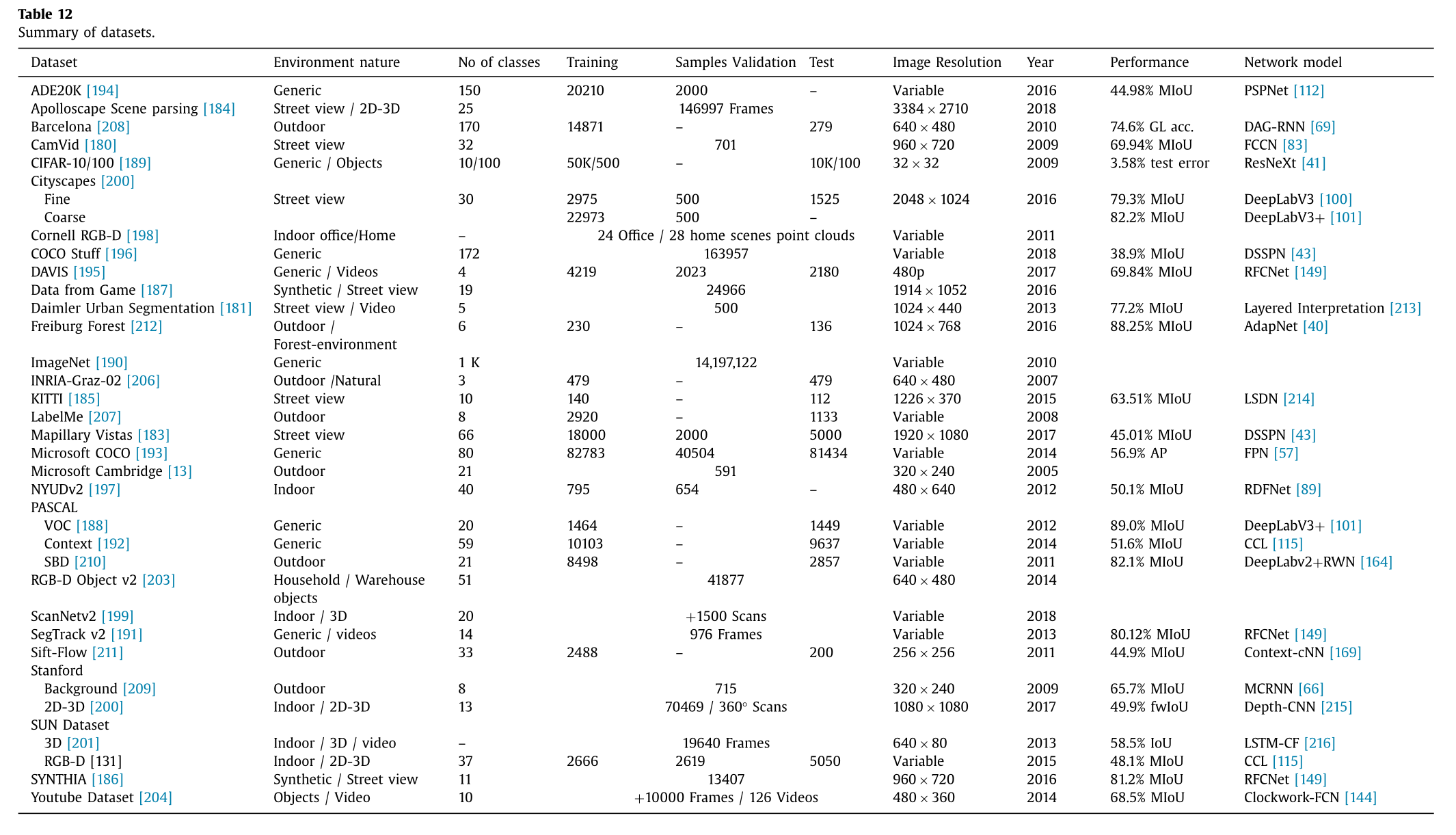
数据集的构建既耗时又费力,因此对于研究人员和开发人员而言,最实用且可行的方法是使用现有的标准数据集,这些数据集对于问题所涉及的领域具有足够的代表性。有些数据集已成为标准并被研究人员广泛使用,以便通过标准评估指标来比较他们的工作与他人的成果。在研究开始时选择数据集是一项具有挑战性的任务,因此对数据集的全面描述会有所帮助。在表 12 中,我们列出了深度学习网络所使用的、可公开获取的数据集。这些数据集提供了不同的信息,例如环境性质、类别数量、训练/测试样本数量、图像分辨率、构建年份以及模型在语义分割方面迄今取得的最佳性能(据我们所知)。托森等人13,198,203的数据集不用于语义分析,但可用于语义分割。黄等人184,199的数据集根本没有进行评估。所有这些数据集都提供了适当的像素级或点级标签。
Evaluation
我们介绍了用于语义分割的常用评估指标。语义分割系统的整体性能可以通过准确率、时间、内存和能耗等方面来评估。
准确性:语义分割系统的准确性是指分割结果的正确性衡量标准,即正确分割区域与真实情况区域的比率。
像素级准确率:正确分类的像素数量与总像素数量的比率。混淆矩阵术语用于描述分类模型的性能。
设 Ncls 为类别数量,Nxy 为属于类别 x 但被标记为类别 y 的像素数量。混淆矩阵报告了误报数量(Nxy)、漏报数量(Nyx)、真报数量(Nxx)和真不报数量(Nyy)
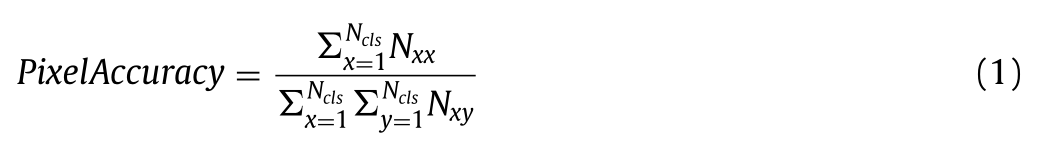
基于像素的分类准确率对于分类器的实际性能而言并不可靠,因为如果数据集不平衡(即某些区域只包含一种类别或标注图像的区域可能被粗略标注)的话,该准确率会得出错误的结果。
平均准确率:首先按类别计算出正确像素的比例,然后将这些比例累加起来,再除以类别总数 Ncls 得出平均准确率。
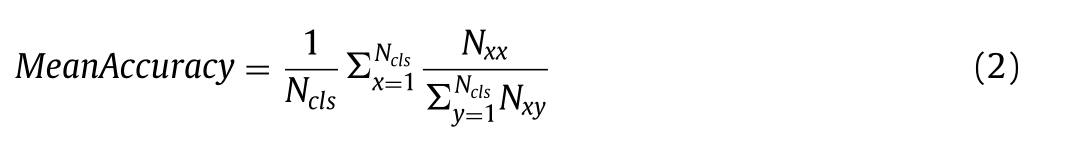
平均交并比(MIoU):真阳性数量 Nxx(交集)与真阳性数量 Nxx、假阴性数量 Nyx、假阳性数量 Nxy(并集)之和的比值。交并比是按类别分别计算后取平均值得出的。
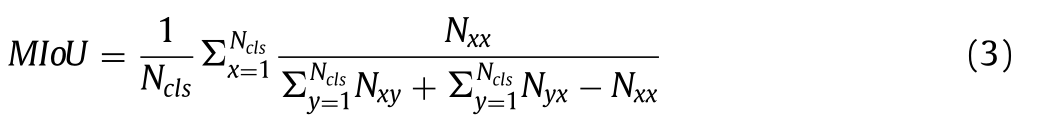
目前应用最为广泛的精度评估策略是 MIoU,因为它操作简便且易于理解。
频率加权交联(FWIoU)
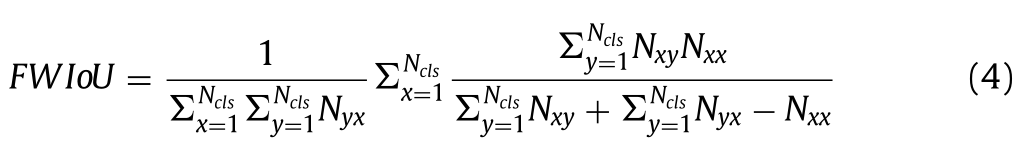

时间、记忆与功率:该系统的记忆和处理时间高度依赖于硬件以及后端的实现方式。使用图形处理器加速器(GPU)能使这些系统的处理速度非常快,但同时会消耗大量的内存和功率。大多数方法并未提供有关时间、内存和硬件的信息,而这些信息对于这些网络模型的应用(如移动设备、机器人、自动驾驶等)来说是非常关键的,因为在这些系统中通常功率和内存有限,而需要实现极其精确的图像分割。此外,这些信息可以帮助研究人员根据应用和需求进行估计、比较或选择方法。
Analysis & discussion
我们根据这些网络模型在数据集上的表现及其设计结构对其进行分析,以找出其取得成功的原因。由于大多数此类方法都是在极少数数据集上进行评估的,因此很难对这些方法进行比较。一些方法使用了不同的衡量标准,而且也缺乏关于实验设置(硬件、时间、内存)的信息。
AdapNet
这种改进要归功于该模型所学习到的高度具有代表性的多尺度特征,这些特征使得模型能够对《Synthia》和《城市景观》中距离较远的物体进行分割。AdapNet 模型的方法基于卷积神经网络专家(卷积深度专家混合体 - CMoDE)的组合,并融合了包括外观、深度和运动在内的多种模态。
PSPNet
PSPNet 基于深度监督损失为深度 ResNet-101 提出了有效的优化策略;它采用了两个损失函数:主要的 softmax 损失用于训练最终的分类器,而辅助损失则在第四阶段之后应用,这有助于优化学习过程。PSPNet 进行了多尺度测试,对预训练的 ResNet 的不同深度进行了实验,并且还进行了数据增强操作。
FCCN
FCCN 提出了一个能显著提升分割性能的代价函数,但在训练模型时,很少有研究人员尝试修改代价函数。FCCN 会在每个前一层输出层(包括最终输出层)上计算代价函数。
DeepLab V3
改进主要源于对超边界条件的调整:微调批归一化、改变批大小、增大裁剪尺寸、改变输出步幅、在推理过程中使用多尺度输入、添加左右翻转输入、基于 3475 张精细标注和额外 20000 张粗略标注的城市景观数据集进行训练。此外,使用在 ImageNet 和 JFT 数据集上预训练的 ResNet-101 模型,使其在 Pascal VOC 上的第二佳得分达到了 86.90 的 IoU。
DeepLab V3+
DeepLab V3+ 是 DeepLab V3 的一个改进版本,其输出步长改为 16 或 8(而非 32)。此外,它还针对 Xception 模块进行了调整,这进一步提升了性能。
无意义,
Open problems and challenges
Open problems and possible solutions
Reducing complexity & computation
深度神经网络不太适合在资源有限的移动平台(例如嵌入式设备)上部署,因为这些网络对内存的需求很高,且运行和耗电都很耗费时间。此外,由于推理所需的大量运算操作,还会出现计算复杂度方面的问题。重要的是要研究如何降低模型的复杂度,以实现高效率而不损失准确性。一些卷积神经网络压缩方法已被提出,以解决降低复杂度和计算成本的问题。王等人217提出了一种方法,用于挖掘并减少网络每层中从大量滤波器中提取的特征图中的冗余部分。金等人218提出了一种一次性整体网络压缩方法,包括三个步骤:排序选择、低秩张量分解和微调。霍利迪等人219将模型压缩技术应用于语义分割问题。Caffe2 是由脸书开发的可移植深度学习框架,能够训练大型模型,并允许为移动系统构建机器学习应用程序。压缩和加速深度神经网络取得了很大进展。然而,也存在一些潜在问题,例如:压缩可能会导致精度损失;存在分解操作;将信息传递到卷积滤波器在某些网络中并不适用。
Apply to adverse conditions
有一些网络模型已应用于实际具有挑战性的环境条件下,或用于应对诸如直接光照、镜面反射、季节变化、雾或雨等不利条件。尽管一些卷积神经网络模型将合成数据与真实数据结合使用,以提高针对具有挑战性环境条件的最先进的语义分割方法的性能。然而,迄今为止,利用来自现实世界的大量高质量数据仍然是不可或缺的。一种可能的解决方案是将合成数据与真实数据结合使用。显然,这两个数据域之间存在显著的视觉差异,为缩小这一差距,可以使用领域适应技术。霍夫曼等人220提出了一种用于在图像域之间转移语义分割全卷积网络的无监督领域适应方法。张等人221提出了一种课程式学习方法,以最小化领域差距。在222一文中,作者们提出了一种基于生成对抗网络(GAN)的域迁移方法,该方法通过一个生成器-判别器组合来将目标分布的信息转移到所学习的嵌入中。
Need large and high quality labeled data
深度神经网络的分类性能与数据集大小呈正相关。目前最先进的方法需要高质量的标注数据,但这些数据在大规模环境下难以获取,因为其耗时且需要大量人力。解决这一问题的有效方法是构建大规模且高质量的数据集,但这似乎很难实现。因此,研究人员依赖半监督和弱监督方法,使深度神经网络减少对大规模数据集标注的依赖。这些方法通过单独使用或结合少量强标注来使用额外的弱标注,从而显著提高了语义分割性能。然而,它们在准确性方面与完全监督学习方法相比仍存在差距。因此,这为改进工作带来了新的挑战。
Overfitting
如前所述,深度神经网络(DNN)需要大量的数据,并且只有在接收到大量数据集的情况下才能表现良好。目前大多数可用的数据集规模都相对较小,而且由于 DNN 模型变得非常复杂,以至于无法捕捉到解决某个问题所需的所有有用信息。当数据量有限时,该模型可能会面临"过拟合"的风险。过拟合指的是训练误差和测试误差之间的差距过大。正则化技术有助于解决这个问题。正则化是指我们对学习算法所做的任何修改,旨在降低其泛化误差,但不降低其训练误差60。在 DNN 中应用了其中的一些方法来防止过拟合,例如 L1 和 L2 正则化、Lp 范数、dropout、dropConnect。数据增强也被用于减少过拟合(例如,增加训练数据的大小------图像旋转、翻转、缩放、移动)。然而,正则化可能会增加训练时间(例如,使用 dropout 会使训练时间比相同架构的标准神经网络增加 2 倍或 3 倍),并且目前还没有针对 CNN 进行正则化的标准方法。引入更优或改进的正则化方法将是未来研究的一个有趣方向。
Segmentation in real-time
在不大幅降低精度的情况下实现实时语义分割至关重要,因为这在自动驾驶、机器人交互、移动计算等领域非常有用,因为运行时间对于评估系统的性能至关重要。用于语义分割的深度神经网络方法更注重准确性而非速度。大多数方法都远远达不到实时分割的要求。解决这个问题的一个可能方法是采用高效的方式进行卷积运算。已有几项研究致力于开发基于卷积分解(将卷积操作分解为多个步骤)的高效架构,以实现实时运行。一些用于卷积的计算高效模块被引入。例如,Inception 27、Xception 31、ResNet 34、ASP 99、ESP 47;ShuffleNet 223 和 MobileNet 224 都使用了分组卷积和深度卷积。另一个可能的解决方案是使用不同的技术(例如参数剪枝和共享 225、低秩分解和稀疏性 226 等)应用网络压缩来减小网络的规模。然而,实时语义分割仍缺乏更高的精度,因此必须开发新的方法和途径来平衡运行时间和精度之间的关系。
Video / 3D segmentation
深度神经网络(DNNs)已成功应用于二维图像的语义分割,但在三维图像和视频的语义分割方面应用较少,尽管其具有重要意义。多年来,已经提出了多种用于语义分割的视频和三维网络模型,并且取得了进展,但仍存在一些挑战。由于缺乏大量的三维图像和序列图像(视频)数据集,使得在三维和视频语义分割方面难以取得进展。在处理高分辨率和复杂场景(大量类别)时,三维网络的计算成本很高。在三维语义分割任务中,使用三维点云信息非常有效。张等人227提出了一种高效的大规模点云分割方法,将带有三维点云的二维图像融合到卷积神经网络(CNN)中,以分割复杂的三维城市场景。228,229中的作者提出了使用光谱信息对三维点云进行直接语义标注的方法。然而,与二维分割相比,三维分割方法面临许多挑战,即复杂性高、计算成本高、处理速度慢以及最重要的是缺乏三维数据集。在视频语义分割中,有两种方法可能有用,一种是用于降低计算成本(通过减少延迟);144,230 中的作者提出了设计的调度框架,该框架降低了视频语义分割的整体成本和最大延迟。然而,这些方法远远无法满足实时应用中的延迟要求。第二种方法是提高准确性(通过利用时间连续性------时间特征和视频帧之间的时间相关性)。已有几种方法145,146,148利用时间信息和空间信息来提高像素标注的准确性。
Conclusion
在本文中,我们对用于语义分割的深度学习技术进行了全面的综述。所调查的方法根据其架构所基于的共同概念被分为十类。我们还对这些方法进行了总结,针对每一种方法,都阐述了其主要思想、架构的起源、测试基准、代码可用性以及发表年份。这些方法已应用于 35 个数据集,并详细介绍了这些数据集的环境特性、类别数量、分辨率、图像数量以及截至目前为止在每种方法上取得最佳性能的情况(据我们所知)。我们主要分析了其中一些已报告取得高分的方法的设计和性能。目的是找出它们是如何做到这一点的。我们还讨论了一些开放性问题,并尝试提出一些可能的解决方案。这项调查表明,在准确性、速度和复杂性方面还有很大的改进空间。所以,我们接下来的工作就是选取其中的一些方法,通过弥补其不足之处或结合其优点来开发出一种新的方法。