Asyncio实现学习方案与实现逻辑
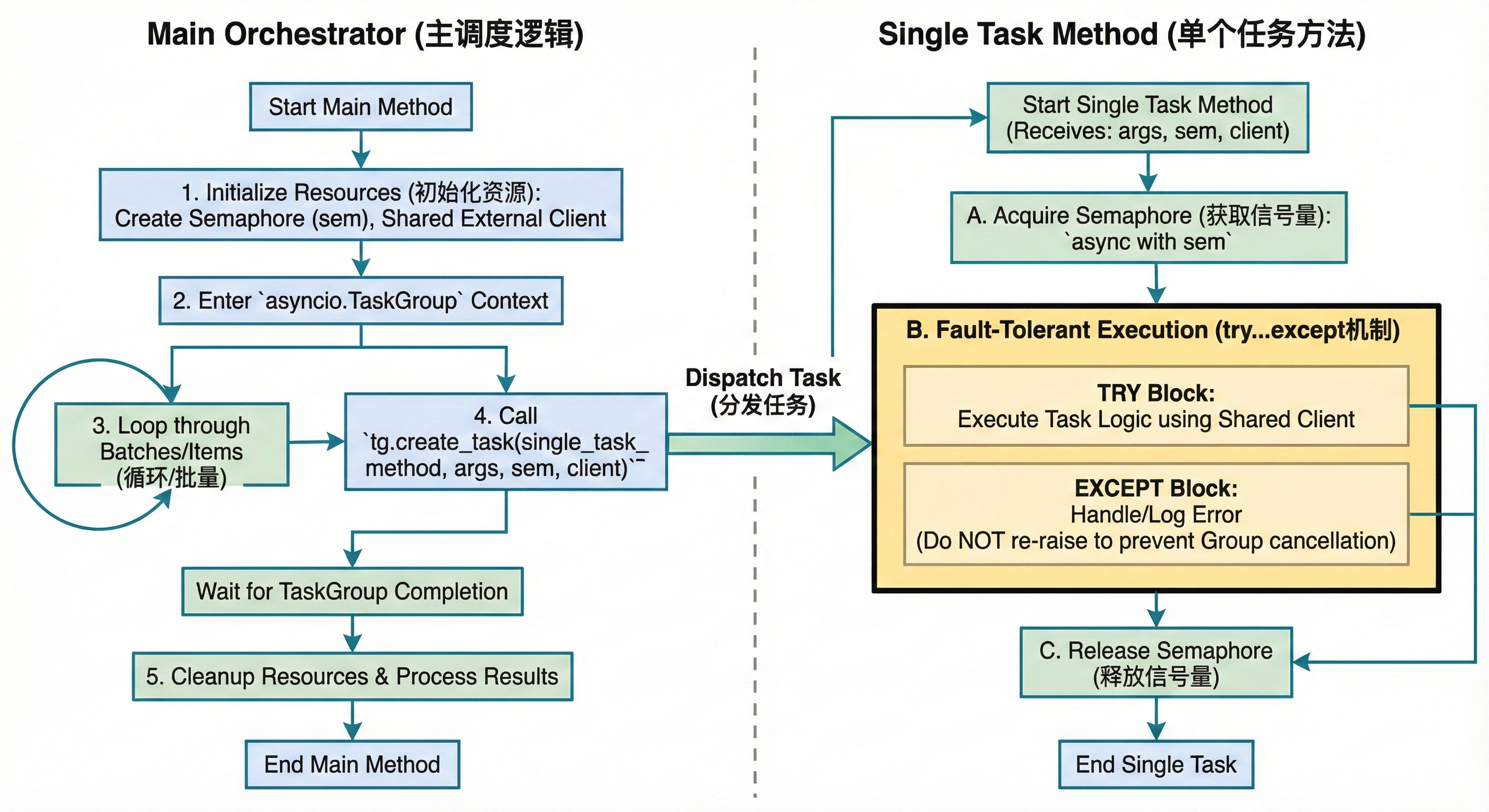
Asyncio具体的实现逻辑的流程:
- 初始化信号量sem来控制每次处理的数量
- 先实现单个任务方法,包括传入的参数都是单个处理的,一般单个方法中还要加入信号量
- 在另一方法中先通过创建外部client,防止每执行一次任务重启一次服务,再通过TaskGroup的方式用循环/批量将create_task去调用单个任务方法,并且通过tasks将任务记录
- 同时还要保证在TaskGroup中有try...except机制,防止因为一个任务错误而取消所有任务
🗺️ 总览:从入门到生产环境 (2周计划)
- 阶段一:核心思维与防坑 (Day 1-3) ------ 彻底搞懂"阻塞"与"非阻塞"。
- 阶段二:控制流与现代模式 (Day 4-6) ------ 掌握
TaskGroup、信号量与超时。 - 阶段三:真实世界的 I/O (Day 7-10) ------ 异步文件操作 (
aiofiles) 与 数据库 (asyncpg)。 - 阶段四:工程化实践 (Day 11-14) ------ 单元测试 (
pytest)、调试模式与性能分析。
🟢 第一阶段:核心思维与防坑 (Day 1-3)
目标 :不仅仅会写 async def,更要懂得如何不卡死事件循环。这是新手最容易犯错的地方。
1. 核心知识点
- Event Loop (事件循环):程序的"心脏",必须保持每秒几千次的空转,绝不能被一段代码卡住。
- Blocking (阻塞) :任何占用 CPU 超过 50ms 或进行同步 IO(如
requests.get、time.sleep)的操作。 - 解决方法 :使用
await让出控制权;对于必须同步的库,使用asyncio.to_thread扔到线程池。
2. 代码对比:错误的阻塞 vs 正确的异步
❌ 错误示范 (卡死 Loop)
Python
import asyncio
import time
async def blocking_task(name):
print(f"[{name}] 开始干活 (阻塞中...)")
# 💥 致命错误:time.sleep 暂停了整个线程,其他任务全部无法运行!
time.sleep(2)
print(f"[{name}] 结束")
async def main():
# 这里的 Task 2 必须等 Task 1 彻底运行完这2秒才能开始,完全串行了
await asyncio.gather(blocking_task("A"), blocking_task("B"))
if __name__ == "__main__":
asyncio.run(main())✅ 正确示范 (非阻塞)
Python
import asyncio
import time
async def async_task(name):
print(f"[{name}] 开始干活")
# ✨ 正确:asyncio.sleep 挂起当前任务,Loop 去执行其他任务
await asyncio.sleep(2)
print(f"[{name}] 结束")
# 💡 救命招数:如果你必须用同步库(如 requests/pandas)
def heavy_calculation():
time.sleep(2) # 模拟耗时计算
return "计算完成"
async def main():
start = time.perf_counter()
# 1. 纯异步任务
task1 = asyncio.create_task(async_task("A"))
# 2. 将同步阻塞代码扔到线程池运行,不卡 Loop
# (Python 3.9+ 新特性,旧版本用 loop.run_in_executor)
task2 = asyncio.to_thread(heavy_calculation)
await asyncio.gather(task1, task2)
print(f"总耗时: {time.perf_counter() - start:.2f}s") # 应该是2秒左右,而不是4秒
if __name__ == "__main__":
asyncio.run(main())🔵 第二阶段:控制流与现代模式 (Day 4-6)
目标:掌握 Python 3.11+ 推荐的结构化并发(Structured Concurrency)。
1. 核心知识点
- TaskGroup (Python 3.11+) :比
gather更安全的任务管理方式,自动处理异常取消。 - Semaphore (信号量) :最重要的限流工具,防止你把下游服务打挂。
2. 实战代码:带限流的高并发采集
Python
import asyncio
import random
# 限制最大并发数为 5
sem = asyncio.Semaphore(5)
async def worker(task_id):
# 使用 async with 自动管理 acquire/release
async with sem:
print(f"工号 {task_id} 正在执行... (剩余名额: {sem._value})")
await asyncio.sleep(random.uniform(0.5, 1.5))
return f"结果-{task_id}"
async def main():
async with asyncio.TaskGroup() as tg:
tasks = []
for i in range(20):
# tg.create_task 会自动将任务加入管理
# 如果其中一个任务报错,TaskGroup 会自动取消其他所有任务
tasks.append(tg.create_task(worker(i)))
# 所有任务完成后,获取结果
results = [t.result() for t in tasks]
print(f"成功处理 {len(results)} 个任务")
if __name__ == "__main__":
asyncio.run(main())🟠 第三阶段:真实世界的 I/O (Day 7-10)
目标 :告别 open() 和同步数据库驱动。
1. 文件操作:aiofiles
不要在 async def 里直接用 with open(...),因为读写硬盘会阻塞 Loop。
Python
# pip install aiofiles
import aiofiles
import asyncio
async def write_log(text):
async with aiofiles.open('async_test.log', mode='a', encoding='utf-8') as f:
await f.write(f"{text}\n")
async def main():
# 并发写入 100 行
await asyncio.gather(*(write_log(f"Log entry {i}") for i in range(100)))
if __name__ == "__main__":
asyncio.run(main())2. 数据库操作:asyncpg (PostgreSQL)
比 psycopg2 快很多,且完全异步。
Python
# pip install asyncpg
import asyncpg
import asyncio
async def run():
conn = await asyncpg.connect(user='user', password='pwd', database='test', host='127.0.0.1')
# 插入数据
await conn.execute('''
INSERT INTO users(name, dob) VALUES($1, $2)
''', 'Bob', '1984-03-01')
# 查询数据
values = await conn.fetch('''SELECT * FROM users WHERE name = $1''', 'Bob')
print(values)
await conn.close()
if __name__ == "__main__":
asyncio.run(run())🟣 第四阶段:工程化实践 (Debug & Test) (Day 11-14)
目标:写出健壮的异步代码。
1. 开启上帝视角:Debug 模式
当你发现程序变慢却不知道卡在哪里时,开启 Debug 模式。
Python
# 启动时开启 debug
# 它会告诉你:"某个协程阻塞了 Loop 超过 0.1秒!" 并打印出是哪一行代码。
asyncio.run(main(), debug=True)2. 单元测试:pytest-asyncio
传统的 unittest 无法测试 async 函数。
Python
# pip install pytest pytest-asyncio
import pytest
import asyncio
# 业务代码
async def add(a, b):
await asyncio.sleep(0.01)
return a + b
# 测试代码
@pytest.mark.asyncio
async def test_add():
result = await add(2, 3)
assert result == 5🎓 毕业挑战题目 (完善版)
为了验证学习成果,请尝试完成以下工具:
题目:异步端口扫描器 (Port Scanner)
需求:
- 输入 :一个 IP 地址 (如
192.168.1.1) 和端口范围 (1-1024)。 - 核心逻辑:
-
- 使用
asyncio.open_connection(ip, port)尝试连接。 - 设置
wait_for超时时间为 0.5 秒(扫描要快,超时的视为关闭)。
- 使用
- 并发要求:
-
- 同时扫描 1000 个端口(需要用到
Semaphore限制并发,否则系统报错 "Too many open files")。
- 同时扫描 1000 个端口(需要用到
- 输出:实时打印开放的端口号,最后统计总耗时。
提示:
- 如果
asyncio.open_connection没有抛出异常,说明端口是通的,记得writer.close()。 - 使用
try...except捕获TimeoutError和ConnectionRefusedError。
实现代码:
python
import asyncio
sem = asyncio.Semaphore(500)
async def scan_port(ip, port):
async with sem:
try:
reader, writer = await asyncio.wait_for(asyncio.open_connection(ip, port), timeout=0.5)
print(f"Port{port} is open")
writer.close()
await writer.wait_closed()
except ConnectionRefusedError:
print(f"{ip}:{port} 未开启")
except TimeoutError:
print(f"{ip}:{port} 超时")
async def main():
ip = "192.168.2.217"
ports = [i for i in range(8000, 15000)]
async with asyncio.TaskGroup() as tg:
tasks = []
for port in ports:
tasks.append(tg.create_task(scan_port(ip, port)))
# 运行主协程并统计耗时
asyncio.run(main())