写在前面
本系列推文为《R for Data Science (2)》的中文翻译版本。所有内容都通过开源免费的方式上传至Github,欢迎大家参与贡献,详细信息见:
Books-zh-cn 项目介绍:
Books-zh-cn:开源免费的中文书籍社区
r4ds-zh-cn Github 地址:
https://github.com/Books-zh-cn/r4ds-zh-cn
r4ds-zh-cn 网站地址:
https://books-zh-cn.github.io/r4ds-zh-cn/
目录
-
15.1 介绍
-
15.2 模式基础
-
15.3 关键函数
-
15.4 模式细节
15.1 介绍
在Chapter14中,你学习了许多处理字符串的实用函数。 本章将重点介绍使用 正则表达式(regular expressions) 的函数,这是一种用于描述字符串模式的简洁而强大的语言。 术语"regular expression"有些拗口,因此大多数人将其简称为"regex"或"regexp"。
本章将从正则表达式的基础知识以及数据分析中最实用的 stringr 函数开始。 随后将拓展你对模式匹配的认知,涵盖七个重要新主题(转义、锚定、字符类、简写字符类、量词、优先级和分组)。 接着我们将讨论 stringr 函数可处理的其他模式类型,以及允许调整正则表达式操作的各种"标志"。 最后将概述 tidyverse 和 base R 中其他可能使用正则表达式的场景。
15.1.1 先决条件
本章我们将使用来自 tidyverse 核心成员 stringr 和 tidyr 的正则表达式函数,以及 babynames 包的数据。
library(tidyverse)
library(babynames)本章将结合使用简单的内联示例(帮助你理解基础概念)、婴儿姓名数据,以及来自 stringr 的三个字符向量:
-
fruit包含80种水果的名称。 -
words包含980个常见英语单词。 -
sentences包含720个短句。
15.2 模式基础
我们将使用str_view()来理解正则表达式模式的工作原理。 在上一章中,我们使用str_view()来更好理解字符串与其打印表示形式之间的区别,现在我们将使用它的第二个参数------一个正则表达式。 当提供此参数时,str_view()将仅显示字符串向量中匹配的元素,用<>包围每个匹配项,并尽可能用蓝色高亮显示匹配部分。
最简单的模式由字母和数字组成,它们会精确匹配这些字符:
str_view(fruit, "berry")
#> [6] │ bil<berry>
#> [7] │ black<berry>
#> [10] │ blue<berry>
#> [11] │ boysen<berry>
#> [19] │ cloud<berry>
#> [21] │ cran<berry>
#> ... and 8 more字母和数字会精确匹配,因此被称为**字面字符(literal characters)。 而大多数标点符号(如., +, *, [, ], ?)具有特殊含义,被称为 元字符(metacharacters)**。 例如,.可以匹配任意字符,所以"a."会匹配任何包含字母"a"且后接另一个字符的字符串:
str_view(c("a", "ab", "ae", "bd", "ea", "eab"), "a.")
#> [2] │ <ab>
#> [3] │ <ae>
#> [6] │ e<ab>或者我们可以找出所有包含字母"a"、后接三个任意字母、最后接字母"e"的水果名称:
str_view(fruit, "a...e")
#> [1] │ <apple>
#> [7] │ bl<ackbe>rry
#> [48] │ mand<arine>
#> [51] │ nect<arine>
#> [62] │ pine<apple>
#> [64] │ pomegr<anate>
#> ... and 2 more量词(Quantifiers) 控制模式匹配的次数:
-
?使模式成为可选项(即匹配 0 次或 1 次) -
+允许模式重复(即至少匹配一次) -
*允许模式成为可选项或重复(即匹配任意次数,包括0次)ab? matches an "a", optionally followed by a "b".
str_view(c("a", "ab", "abb"), "ab?")
#> [1] │
#> [2] │
#> [3] │b ab+ matches an "a", followed by at least one "b".
str_view(c("a", "ab", "abb"), "ab+")
#> [2] │
#> [3] │ab* matches an "a", followed by any number of "b"s.
str_view(c("a", "ab", "abb"), "ab*")
#> [1] │
#> [2] │
#> [3] │
字符类(Character classes) 由[]定义,允许您匹配一组字符,例如[abcd]会匹配"a"、"b"、"c"或"d"。 您还可以使用^开头来反向匹配:[^abcd]会匹配除"a"、"b"、"c"、"d"以外的任何字符。 我们可以利用这个思路来查找包含被元音字母包围的"x",或被辅音字母包围的"y"的单词:
str_view(words, "[aeiou]x[aeiou]")
#> [284] │ <exa>ct
#> [285] │ <exa>mple
#> [288] │ <exe>rcise
#> [289] │ <exi>st
str_view(words, "[^aeiou]y[^aeiou]")
#> [836] │ <sys>tem
#> [901] │ <typ>e你可以使用 交替符(alternation) ,|,在一个或多个备选模式中进行选择。 例如,以下模式会查找包含"apple"、"melon"或"nut"的水果,或者包含重复元音的水果。
str_view(fruit, "apple|melon|nut")
#> [1] │ <apple>
#> [13] │ canary <melon>
#> [20] │ coco<nut>
#> [52] │ <nut>
#> [62] │ pine<apple>
#> [72] │ rock <melon>
#> ... and 1 more
str_view(fruit, "aa|ee|ii|oo|uu")
#> [9] │ bl<oo>d orange
#> [33] │ g<oo>seberry
#> [47] │ lych<ee>
#> [66] │ purple mangost<ee>n正则表达式非常紧凑且使用大量标点符号,因此初看可能令人难以应对且难以阅读。 别担心;通过练习你会逐渐掌握,简单的模式很快就会变得得心应手。 让我们通过练习一些实用的 stringr 函数来启动这个学习过程。
15.3 关键函数
既然你已经掌握了正则表达式的基础知识,现在让我们将其与一些 stringr 和 tidyr 函数结合使用。 在接下来的部分中,你将学习如何检测匹配项的存在与否、如何统计匹配次数、如何用固定文本替换匹配项,以及如何使用模式提取文本。
15.3.1 检测匹配项
str_detect() 会返回一个逻辑向量:当模式匹配字符向量中的元素时返回 TRUE,否则返回 FALSE。
str_detect(c("a", "b", "c"), "[aeiou]")
#> [1] TRUE FALSE FALSE由于 str_detect() 返回的逻辑向量与初始向量长度相同,它非常适合与 filter() 配合使用。 例如,以下代码可以找出所有包含小写字母 "x" 的热门姓名:
babynames |>
filter(str_detect(name, "x")) |>
count(name, wt = n, sort = TRUE)
#> # A tibble: 974 × 2
#> name n
#> <chr> <int>
#> 1 Alexander 665492
#> 2 Alexis 399551
#> 3 Alex 278705
#> 4 Alexandra 232223
#> 5 Max 148787
#> 6 Alexa 123032
#> # ℹ 968 more rows我们也可以将str_detect()与summarize()结合使用,配合sum()或mean()函数:sum(str_detect(x, pattern))可统计匹配的观测值数量,而mean(str_detect(x, pattern))则能计算匹配的比例。 例如,以下代码片段计算并按年份细分了包含字母"x"的婴儿姓名比例,并通过可视化展示。 从结果来看,这类名字近年来的受欢迎程度似乎急剧上升!
babynames |>
group_by(year) |>
summarize(prop_x = mean(str_detect(name, "x"))) |>
ggplot(aes(x = year, y = prop_x)) +
geom_line()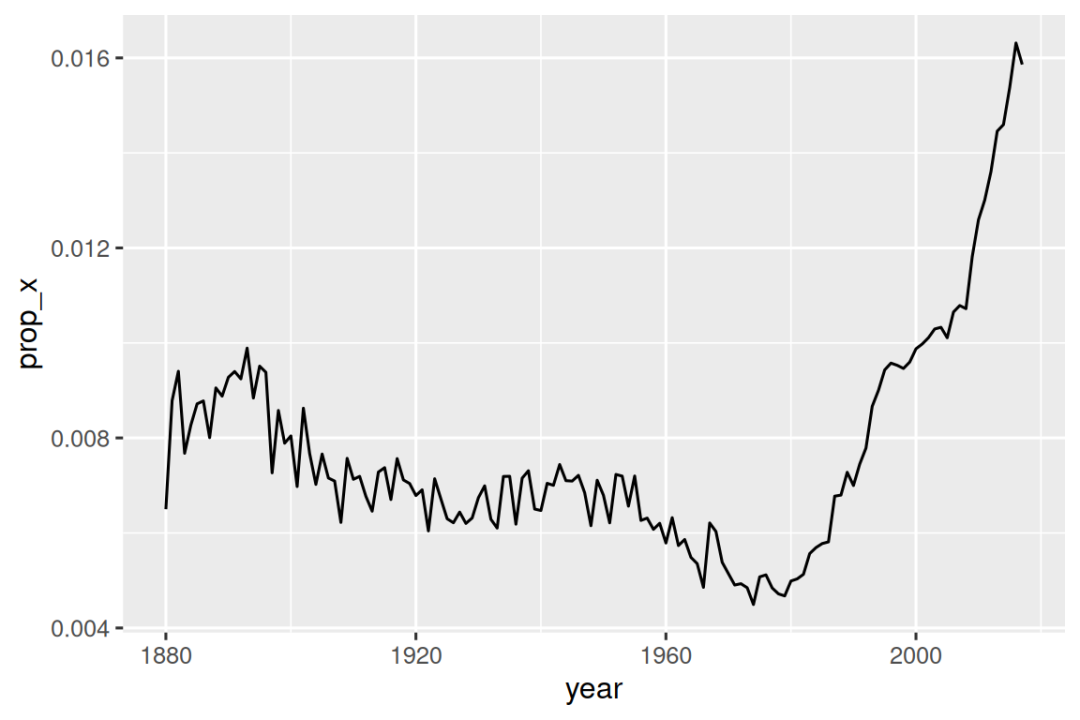
有两个与str_detect()密切相关的函数:str_subset()和str_which()。str_subset()返回一个仅包含匹配字符串的字符向量。str_which()返回一个给出匹配字符串位置的整数向量。
15.3.2 计数匹配项
在复杂度上比str_detect()更进一步的当属str_count():它不再返回简单的true/false判断,而是告诉你每个字符串中存在多少处匹配。
x <- c("apple", "banana", "pear")
str_count(x, "p")
#> [1] 2 0 1需要注意的是,每处匹配都从上一处匹配的结尾开始,也就是说正则表达式匹配永远不会重叠。 例如在"abababa"中,模式"aba"会匹配多少次?正 则表达式的答案是2次而非3次:
str_count("abababa", "aba")
#> [1] 2
str_view("abababa", "aba")
#> [1] │ <aba>b<aba>很自然地,我们会将str_count()与mutate()结合使用。 下面这个示例通过str_count()配合字符类来统计每个名字中元音和辅音的数量。
babynames |>
count(name) |>
mutate(
vowels = str_count(name, "[aeiou]"),
consonants = str_count(name, "[^aeiou]")
)
#> # A tibble: 97,310 × 4
#> name n vowels consonants
#> <chr> <int> <int> <int>
#> 1 Aaban 10 2 3
#> 2 Aabha 5 2 3
#> 3 Aabid 2 2 3
#> 4 Aabir 1 2 3
#> 5 Aabriella 5 4 5
#> 6 Aada 1 2 2
#> # ℹ 97,304 more rows如果仔细观察,你会发现我们的计算存在一些问题:"Aaban"包含三个"a",但我们的汇总结果只显示两个元音。 这是因为正则表达式区分大小写。 我们可以通过三种方式解决这个问题:
-
在字符类中添加大写元音字母:
str_count(name, "[aeiouAEIOU]")。 -
告知正则表达式忽略大小写:
str_count(name, regex("[aeiou]", ignore_case = TRUE))。我们将在@sec-flags进一步讨论。 -
使用
str_to_lower()将姓名转换为小写:str_count(str_to_lower(name), "[aeiou]")。
这种处理字符串的方法多样性相当典型 --- 通常有多种途径可以实现目标,既可以通过让模式更复杂,也可以对字符串进行预处理。 如果某种方法遇到困难,转换思路并从不同角度解决问题通常会很有帮助。
就本例而言,由于我们需要对姓名应用两个函数,我认为先进行转换会更简单:
babynames |>
count(name) |>
mutate(
name = str_to_lower(name),
vowels = str_count(name, "[aeiou]"),
consonants = str_count(name, "[^aeiou]")
)
#> # A tibble: 97,310 × 4
#> name n vowels consonants
#> <chr> <int> <int> <int>
#> 1 aaban 10 3 2
#> 2 aabha 5 3 2
#> 3 aabid 2 3 2
#> 4 aabir 1 3 2
#> 5 aabriella 5 5 4
#> 6 aada 1 3 1
#> # ℹ 97,304 more rows15.3.3 替换值
除了检测和计数匹配项外,我们还可以使用str_replace()和str_replace_all()来修改它们。str_replace()替换第一个匹配项,而顾名思义,str_replace_all()会替换所有匹配项。
x <- c("apple", "pear", "banana")
str_replace_all(x, "[aeiou]", "-")
#> [1] "-ppl-" "p--r" "b-n-n-"str_remove()和str_remove_all()则是str_replace(x, pattern, "")的便捷快捷方式:
x <- c("apple", "pear", "banana")
str_remove_all(x, "[aeiou]")
#> [1] "ppl" "pr" "bnn"在进行数据清理时,这些函数很自然地与mutate()配合使用,通常需要反复应用它们来逐层剥离不一致的格式。
15.3.4 提取变量
我们将讨论的最后一个函数是使用正则表达式将数据从某列提取到一个或多个新列中:separate_wider_regex()。 它是您在Section14.4.2学过的separate_wider_position()和separate_wider_delim()函数的同类函数。 这些函数属于 tidyr 包,因为它们作用于数据框的列,而非单个向量。
让我们创建一个简单数据集来演示其工作原理。 这里有一些源自babynames的数据,其中包含一组人员的姓名、性别和年龄,但格式相当奇怪:
df <- tribble(
~str,
"<Sheryl>-F_34",
"<Kisha>-F_45",
"<Brandon>-N_33",
"<Sharon>-F_38",
"<Penny>-F_58",
"<Justin>-M_41",
"<Patricia>-F_84",
)使用separate_wider_regex()提取这些数据时,我们只需构建一系列匹配每个片段的正则表达式。 若希望该片段的内容出现在输出中,我们需要为其命名:
df |>
separate_wider_regex(
str,
patterns = c(
"<",
name = "[A-Za-z]+",
">-",
gender = ".", "_",
age = "[0-9]+"
)
)
#> # A tibble: 7 × 3
#> name gender age
#> <chr> <chr> <chr>
#> 1 Sheryl F 34
#> 2 Kisha F 45
#> 3 Brandon N 33
#> 4 Sharon F 38
#> 5 Penny F 58
#> 6 Justin M 41
#> # ℹ 1 more row如果匹配失败,可以像使用separate_wider_delim()和separate_wider_position()时那样,通过设置too_short = "debug"来排查问题。
15.3.5 练习
-
哪个婴儿名字包含最多元音? 哪个名字的元音比例最高? (提示:分母是什么?)
-
将
"a/b/c/d/e"中的所有正斜杠替换为反斜杠。 如果尝试通过将所有反斜杠替换为正斜杠来撤销转换,会发生什么? (我们很快就会讨论这个问题。) -
使用
str_to_lower()实现一个简易版的str_replace_all()。 -
创建一个能匹配贵国常见电话号码格式的正则表达式。
15.4 模式细节
既然您已掌握模式语言的基础知识及其在 stringr 和 tidyr 函数中的运用,现在该深入了解更多细节了。 首先从 转义(escaping) 开始,它能让你匹配原本具有特殊含义的元字符。 接着,将学习 锚点(anchors) ,用于匹配字符串的首尾位置。 然后,深入了解 字符类(character classes) 及其简写形式,从而匹配集合中的任意字符。 随后,你会学习 量词(quantifiers) 的完整细节,这些量词控制着模式的匹配次数。 接着必须讨论 运算符优先级(operator precedence) 与括号这一重要(但复杂)的主题。 最后以模式 分组(grouping) 组件的具体细节作为结束。
这里使用的术语是各组成部分的技术名称。 这些名称未必都能直观体现其功能,但若后续需要搜索更多细节时,了解正确术语将非常有帮助。
15.4.1 转义
为了匹配字面意义的.,你需要使用**转义符(escape)**来告知正则表达式按字面意义匹配元字符。 和字符串一样,正则表达式使用反斜杠进行转义。 因此,要匹配一个.,你需要使用正则表达式\.。但这样会带来一个问题。 我们用字符串来表示正则表达式,而\在字符串中也用作转义符号。 所以要创建正则表达式\.,我们需要使用字符串"\\.",如下例所示。
# To create the regular expression \., we need to use \\.
dot <- "\\."
# But the expression itself only contains one \
str_view(dot)
#> [1] │ \.
# And this tells R to look for an explicit .
str_view(c("abc", "a.c", "bef"), "a\\.c")
#> [2] │ <a.c>在本书中,我们通常不会给正则表达式加引号,例如\.。 如果需要强调实际需要输入的内容,则会为其添加引号和额外的转义符号,如"\\."。
如果\在正则表达式中用作转义字符,那么如何匹配字面意义上的\呢? 你需要对它进行转义,构建出\\这样的正则表达式。 而为了构建这个正则表达式,你需要使用字符串,字符串本身也需要对\进行转义。 这意味着要匹配一个字面意义上的\,你必须写成"\\\\" --- 需要四个反斜杠才能匹配一个!
x <- "a\\b"
str_view(x)
#> [1] │ a\b
str_view(x, "\\\\")
#> [1] │ a<\>b或者,您可能会发现使用Section14.2.2介绍的原始字符串更简便。 这样可以避免一层转义:
str_view(x, r"{\\}")
#> [1] │ a<\>b如果您需要匹配字面字符 ., $, |, *, +, ?, {, }, (, ),除了使用反斜杠转义外还有另一种选择:可以使用字符类:[.], [$], [|], ... 所有这些都能匹配对应的字面值。
str_view(c("abc", "a.c", "a*c", "a c"), "a[.]c")
#> [2] │ <a.c>
str_view(c("abc", "a.c", "a*c", "a c"), ".[*]c")
#> [3] │ <a*c>15.4.2 锚点
默认情况下,正则表达式会匹配字符串的任意部分。 若需匹配字符串起始或结束位置,需要使用 锚点(anchor) :^ 匹配起始位置,$ 匹配结束位置:
str_view(fruit, "^a")
#> [1] │ <a>pple
#> [2] │ <a>pricot
#> [3] │ <a>vocado
str_view(fruit, "a$")
#> [4] │ banan<a>
#> [15] │ cherimoy<a>
#> [30] │ feijo<a>
#> [36] │ guav<a>
#> [56] │ papay<a>
#> [74] │ satsum<a>人们容易认为 $ 应该匹配字符串开头(因为美元金额通常这样书写),但这不符合正则表达式的规则。
若要强制正则表达式仅匹配完整字符串,需同时使用 ^ 和 $ 进行锚定:
str_view(fruit, "apple")
#> [1] │ <apple>
#> [62] │ pine<apple>
str_view(fruit, "^apple$")
#> [1] │ <apple>你也可以使用 \b 来匹配单词边界(即单词的开始或结束)。 这在配合 RStudio 的查找替换工具时特别有用。 例如,若要查找所有 sum() 的用法,可以通过搜索 \bsum\b 来避免匹配到 summarize, summary, rowsum 等函数:
x <- c("summary(x)", "summarize(df)", "rowsum(x)", "sum(x)")
str_view(x, "sum")
#> [1] │ <sum>mary(x)
#> [2] │ <sum>marize(df)
#> [3] │ row<sum>(x)
#> [4] │ <sum>(x)
str_view(x, "\\bsum\\b")
#> [4] │ <sum>(x)当单独使用锚点时,会产生零宽度匹配:
str_view("abc", c("$", "^", "\\b"))
#> [1] │ abc<>
#> [2] │ <>abc
#> [3] │ <>abc<>这有助于理解替换独立锚点时会发生的情况:
str_replace_all("abc", c("$", "^", "\\b"), "--")
#> [1] "abc--" "--abc" "--abc--"15.4.3 字符类
字符类(character class) ,或称 字符集(character set) ,允许你匹配集合中的任意字符。 正如前面讨论的,你可以用[]来自定义集合:[abc]会匹配"a"、"b"或"c",而[^abc]则匹配除"a"、"b"、"c"外的任意字符。 除了^之外,还有两个字符在[]内具有特殊含义:
-
-用于定义范围,例如[a-z]匹配所有小写字母,[0-9]匹配任意数字。 -
\用于转义特殊字符,因此[\^\-\]]会匹配^,-或]。
以下是一些示例:
x <- "abcd ABCD 12345 -!@#%."
str_view(x, "[abc]+")
#> [1] │ <abc>d ABCD 12345 -!@#%.
str_view(x, "[a-z]+")
#> [1] │ <abcd> ABCD 12345 -!@#%.
str_view(x, "[^a-z0-9]+")
#> [1] │ abcd< ABCD >12345< -!@#%.>
# You need an escape to match characters that are otherwise
# special inside of []
str_view("a-b-c", "[a-c]")
#> [1] │ <a>-<b>-<c>
str_view("a-b-c", "[a\\-c]")
#> [1] │ <a><->b<-><c>有些字符类因使用频率极高而拥有专属简写模式。 您已见过.,匹配除换行符外任意字符。 另外还有三组特别实用的对应简写:
-
\d匹配任意数字;
\D匹配任意非数字字符。 -
\s匹配任意空白字符(如空格、制表符、换行符);
\S匹配任意非空白字符。 -
\w匹配任意"单词"字符(即字母和数字);
\W匹配任意"非单词"字符。
以下代码通过选取字母、数字和标点符号来演示这六种简写模式。
x <- "abcd ABCD 12345 -!@#%."
str_view(x, "\\d+")
#> [1] │ abcd ABCD <12345> -!@#%.
str_view(x, "\\D+")
#> [1] │ <abcd ABCD >12345< -!@#%.>
str_view(x, "\\s+")
#> [1] │ abcd< >ABCD< >12345< >-!@#%.
str_view(x, "\\S+")
#> [1] │ <abcd> <ABCD> <12345> <-!@#%.>
str_view(x, "\\w+")
#> [1] │ <abcd> <ABCD> <12345> -!@#%.
str_view(x, "\\W+")
#> [1] │ abcd< >ABCD< >12345< -!@#%.>--------------- 未完待续 ---------------
本期翻译贡献:
@TigerZ生信宝库
注:本文已开启快捷转载,欢迎大家转载,只需标明文章出处即可。