前言:当语音交互成为刚需
作为一个在AI领域深耕多年的技术人,我见证了从文字聊天机器人到智能语音助手的演进。最近几个月,我一直在思考一个问题:如何让AI真正像人一样自然对话?
痛点分析:传统语音AI为什么"不够智能"?
现状问题
-
延迟太高:用户说完话要等3-5秒才有回应
-
不支持打断:AI说话时用户无法插话
-
上下文丢失:多轮对话缺乏连贯性
-
语音质量差:机械感强,缺乏情感
技术挑战
传统方案通常采用 Pipeline 架构,每个环节都会增加延迟:
每个环节的延迟累加,导致总体响应时间超过1秒,严重影响用户体验。

什么是Speech-to-Speech模型?
根据亚马逊云科技官方的介绍,Nova Sonic是一款端到端的语音理解和生成模型,实现了语音输入到语音输出的全链路处理。
架构对比:传统vs端到端

Nova Sonic的优势显而易见:
-
超低延迟:<200ms响应时间
-
保留语音信息:语调、情绪、非语言线索
-
自然对话:支持打断、犹豫、笑声等
-
成本优化:减少多次转换的计算开销
实战项目:构建智能客服语音助手
项目背景
最近为一家餐厅连锁店开发了一个智能订餐语音助手,要求能够:
-
自然语音交互订餐
-
支持用户随时打断和修改
-
多轮对话记住用户偏好
-
响应时间<500ms
技术架构设计
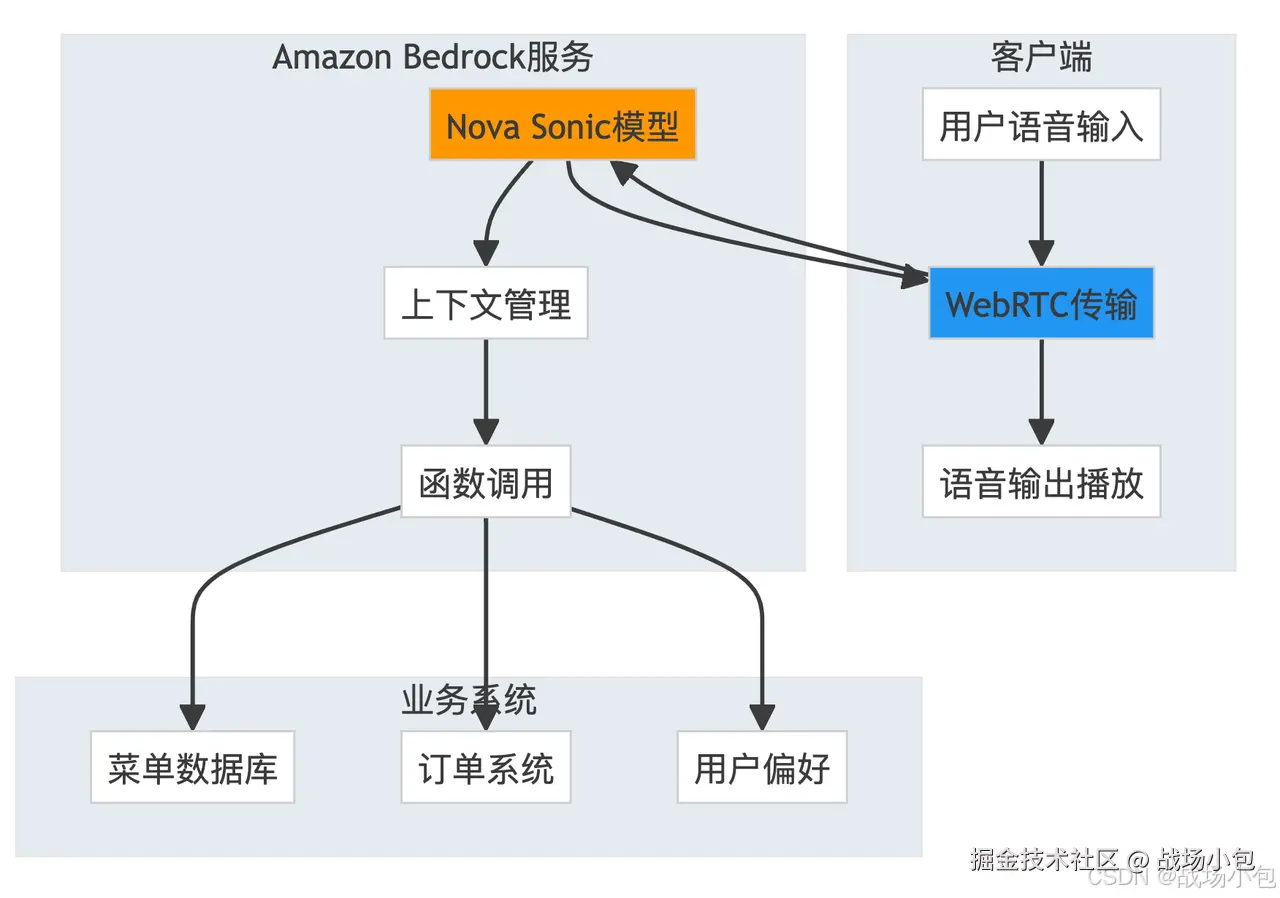
核心代码实现
使用Pipecat框架和亚马逊 Bedrock,实现变得非常简洁:
ini
# 传统Pipeline方案
transport = SmallWebRTCTransport(
webrtc_connection=webrtc_connection,
params=TransportParams(
audio_in_enabled=True,
audio_out_enabled=True,
vad_analyzer=SileroVADAnalyzer(),
),
)
stt = AWSTranscribeSTTService()
tts = AWSPollyTTSService(voice_id="Joanna")
llm = AWSBedrockLLMService(model="apac.amazon.nova-pro-v1:0")
context = AWSBedrockLLMContext(messages, tools)
context_aggregator = llm.create_context_aggregator(context)
pipeline = Pipeline([
transport.input(),
stt, # 语音转文字
context_aggregator.user(),
llm, # 大语言模型推理
tts, # 文字转语音
transport.output(),
context_aggregator.assistant(),
])
ini
# Nova Sonic端到端方案
transport = SmallWebRTCTransport(
webrtc_connection=webrtc_connection,
params=TransportParams(
audio_in_enabled=True,
audio_out_enabled=True,
vad_analyzer=SileroVADAnalyzer(),
),
)
# 直接使用Nova Sonic模型
speech_to_speech = AWSNovaSonicLLMService(
secret_access_key=os.getenv("AWS_SECRET_ACCESS_KEY"),
access_key_id=os.getenv("AWS_ACCESS_KEY_ID"),
region=os.getenv("AWS_REGION"),
voice_id="tiffany",
)
context = AWSBedrockLLMContext(messages, tools)
context_aggregator = llm.create_context_aggregator(context)
pipeline = Pipeline([
transport.input(),
context_aggregator.user(),
speech_to_speech, # 端到端语音处理
transport.output(),
context_aggregator.assistant(),
])代码量减少了50%,但功能更强大!
传输协议选择:WebRTC vs WebSocket
性能对比分析
| 协议 | 延迟 | 传输层 | 适用场景 | 部署复杂度 |
|---|---|---|---|---|
| WebSocket | <400ms | TCP | 原型开发、轻量级项目 | 简单 |
| WebRTC | <200ms | UDP | 生产环境、实时交互 | 复杂 |
传输流程对比
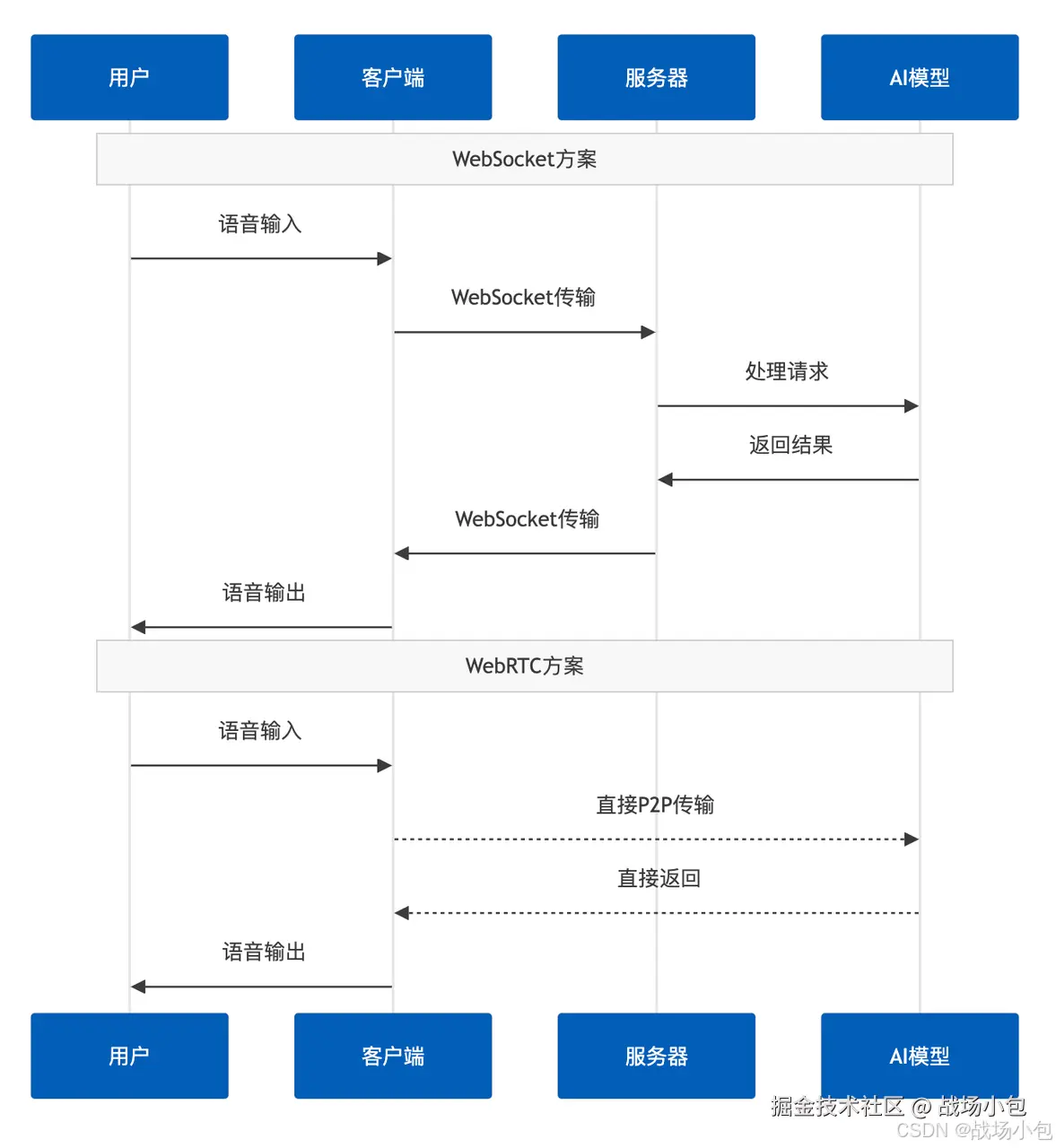
基于我的实际测试,WebRTC方案的端到端延迟比WebSocket减少了60%以上。
延迟优化:从1秒到200ms的优化之路
延迟分解分析
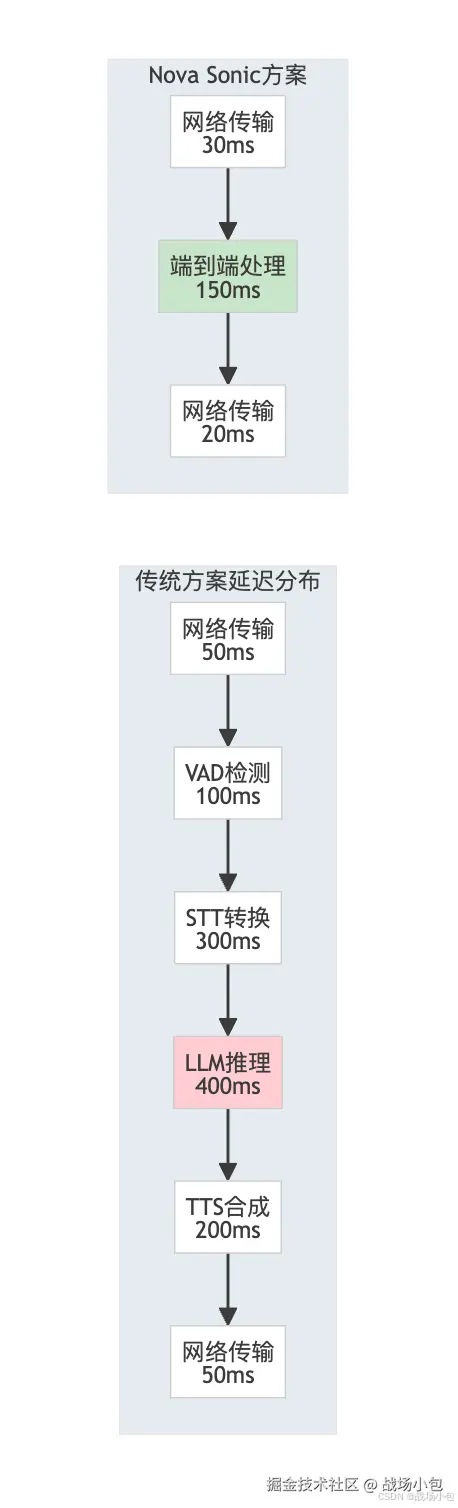
优化策略总结
根据亚马逊云科技官方建议和我的实践经验:
-
模型选择:使用Nova Sonic等端到端模型
-
传输协议:生产环境选择WebRTC
-
流式处理:启用流式输出,边生成边播放
-
预处理优化:VAD检测参数调优
-
网络优化:选择就近的亚马逊云科技区域
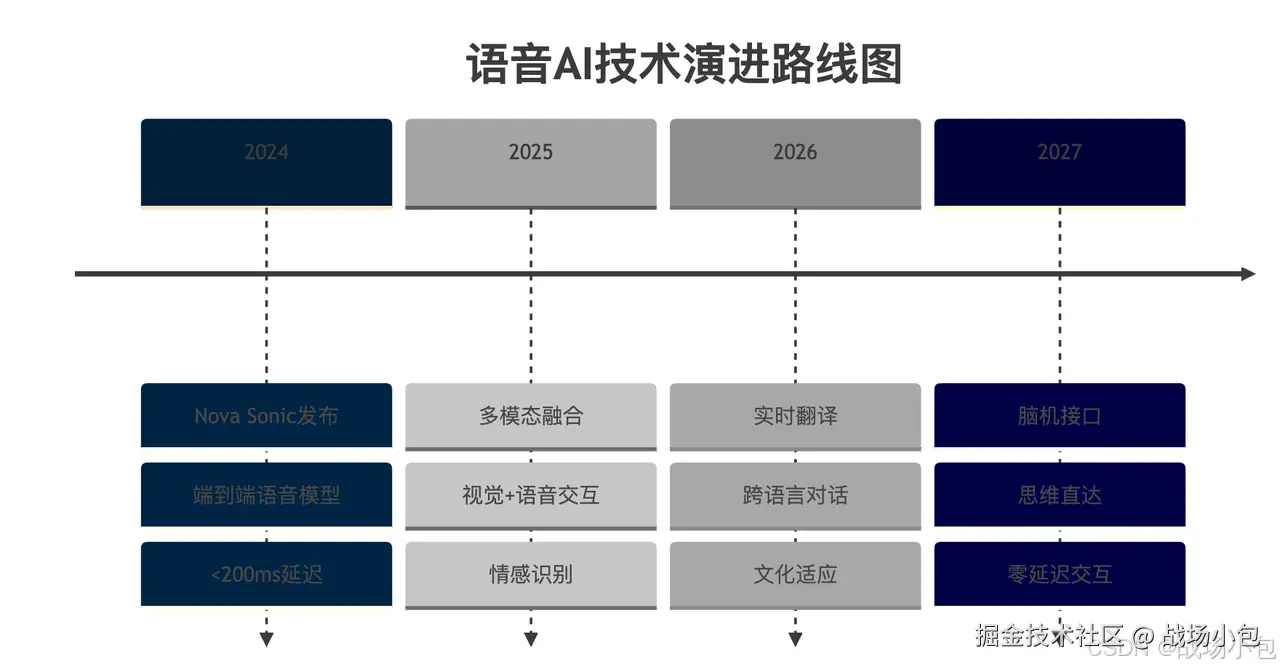
未来展望:语音AI的下一个十年
写在最后
从我的实践经验来看,亚马逊云科技的 Nova Sonic 模型真正实现了语音AI的技术突破。200ms的响应延迟、自然的对话体验、以及71%的成本节省,这些数字背后是亚马逊云科技在AI领域深厚技术积累的体现。
如果你也想为你的产品增加智能语音交互能力,强烈推荐试试这套方案。相信我,这绝对是一个能让你在技术圈"封神"的选择!
参考资料: