一,zookeeper是什么
ZooKeeper 可以理解为分布式系统的 "协调管家"------ 它是一个开源的分布式协调服务,专门帮多个分散的服务器(比如集群里的机器)"商量事儿、同步信息、保持一致",让复杂的分布式系统能有序运行。
1.1、它的核心作用
- 统一配置管理:比如你有 10 台服务机器,要改一个配置(比如数据库密码),不用挨个改 ------ 把配置存在 ZooKeeper 里,所有机器自动同步最新配置。
- 服务注册 & 发现:比如 Dubbo 微服务集群里,服务启动后会在 ZooKeeper 里 "登记" 自己的地址;其他服务要调用它时,直接去 ZooKeeper 查地址就行(不用硬写死 IP)。
- 分布式锁:多个机器抢着操作同一个资源(比如抢库存),ZooKeeper 能帮它们 "排队",保证同一时间只有一台机器能操作。
- 集群选主:像 Kafka、HBase 集群,需要选一个 "老大(Leader)" 干活,ZooKeeper 能帮它们快速选出 Leader,就算 Leader 挂了,也能立刻重新选一个。
- 节点上下线监听:服务机器宕机了,ZooKeeper 能实时感知到(通过 "临时节点"),并通知其他依赖它的服务。
1.2、它的核心特点
- 强一致性:不管你问集群里哪台 ZooKeeper 机器,拿到的ss信息都是一样的(不会出现 "一台说库存剩 10,另一台说剩 5" 的情况)。
- 高可用:用奇数台机器组成集群(比如 3/5 台),哪怕挂了 1-2 台,整个服务还能正常工作。
- 实时性:数据变化后,能在毫秒级同步给所有依赖的机器。
- 轻量级:本身不存大量数据,只存 "关键协调信息"(比如配置、地址、锁状态)。
1.3、 数据模型
ZooKeeper 的存储像简化版的文件系统:
- 数据存在 "节点(znode)" 里,结构是层级目录(比如
/dubbo/service/user)。 - znode 分两种核心类型:
- 持久节点:创建后一直存在,除非手动删除(比如存配置)。
- 临时节点:创建它的机器掉线后,节点会自动消失(刚好用来做 "服务上下线监听")。
1.4、谁会用到它?
几乎所有主流分布式框架都依赖它:
- 消息队列:Kafka(用它存主题配置、选 Leader)
- 微服务:Dubbo(服务注册发现)
- 大数据:HBase、Spark(集群选主、配置同步)
二. 第一次启动选举机制核心流程
ZooKeeper 首次启动时,选举需满足 "超过集群节点数的半数"(5 节点需至少 3 票),流程示例:
- 单节点启动(如 Server1):发起选举并投自己 1 票,但票数不足 3 票,状态保持 LOOKING(寻找 Leader);
- 第二个节点启动(如 Server2):再次发起选举,Server1、Server2 互投并交换选票,但总票数仍不足 3 票,继续保持 LOOKING;
- 后续节点启动(如 Server3):当第 3 个节点参与选举时,若某节点获得≥3 票,则该节点成为 Leader,其余节点转为 Follower。
2.1. 关键概念解析
- 角色与状态 :
- Leader:集群的主节点,负责事务请求处理与数据同步;
- Follower:从节点,负责处理读请求、转发写请求给 Leader;
- LOOKING:节点处于 "寻找 Leader" 的状态,选举完成后 Leader 转为 LEADING,Follower 转为 FOLLOWING。
- 投票依据:选举优先选择事务 ID(zxid,反映数据最新程度)更大的节点;若 zxid 相同,则选择 myid(节点唯一标识)更大的节点。
2.2. 机制的核心作用
通过 "半数票通过" 的规则,确保集群启动时能快速选出唯一 Leader,避免 "脑裂"(多个 Leader 共存),维持集群的统一服务能力,是 ZooKeeper 保证一致性与高可用的基础。
三,Kafka
3.1 它是什么
Kafka 是由 Apache 软件基金会开发的分布式流处理平台,最初由 LinkedIn 设计并开源,核心定位是高吞吐、可持久化、可水平扩展的消息队列(消息中间件),同时支持流数据的发布、订阅、存储和实时处理。
3.2、核心特性
- 高吞吐量Kafka 专为处理海量数据设计,通过 "顺序写磁盘""批量发送""零拷贝" 等机制,单节点可轻松支撑每秒数十万条消息的读写,远超传统消息队列(如 RabbitMQ)。
- 分布式与可扩展性 采用分区(Partition)+ 副本(Replica)架构:
- 分区:Topic 被拆分为多个分区,分布在不同 Broker 节点,实现水平扩展;
- 副本:每个分区有主副本(Leader)和从副本(Follower),保障数据容错性。
- 持久化存储消息并非临时存储,而是以日志文件形式持久化到磁盘,支持按时间或大小保留数据,可作为 "数据湖" 存储离线数据。
- 高容错性集群中单个 Broker 节点故障不会影响整体服务,Leader 副本故障时,Follower 会自动选举成为新 Leader,保证服务连续性。
- 实时流处理内置 Kafka Streams 库,支持对数据流进行实时聚合、过滤、转换等操作,无需依赖外部流处理框架(如 Flink、Spark Streaming)。
核心组件:ZooKeeper(Kafka < 3.0)负责管理集群元数据(如 Broker 节点状态、分区 Leader 选举),3.0 后支持内置 KRaft 模式替代 ZooKeeper。
3.3、典型应用场景
- 日志收集作为日志管道,将分布式系统(如微服务、ELK 架构)的日志集中收集到 Kafka,再由 Logstash 消费并转发到 Elasticsearch 存储分析(这也是你熟悉的 ELK 与 Kafka 结合的典型场景)。
- 消息队列解耦微服务间的同步调用,实现异步通信(如订单系统下单后,通过 Kafka 通知库存系统扣减库存)。
- 实时数据处理对接流处理框架(如 Flink),处理实时数据(如电商实时推荐、风控系统实时检测)。
- 数据备份与同步作为数据传输中间件,实现数据库(如 MySQL)的 binlog 同步到数据仓库(如 Hive)。
3.4 架构
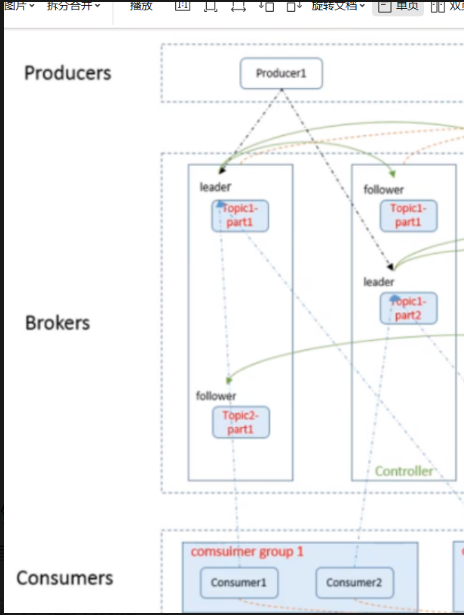
简单理解,kafka就是多条处理高并发的消息队列。
在 Kafka 中,Log(消息日志文件)和 Index(索引文件)是一一对应的 "配套文件",共同服务于 Partition 的消息存储与快速查询,核心关联基于 **Segment(日志分段)** 实现。
3.5、基础结构:Partition 由多个 Segment 组成
Kafka 的每个 Partition 并非单个大文件,而是被拆分为多个Segment(日志分段),每个 Segment 包含两类核心文件:
.log文件:存储实际的消息内容(以顺序追加的方式写入);.index文件:存储消息偏移量(Offset)与.log 文件物理位置的映射关系 (即索引);(此外还有.timeindex文件,是基于时间戳的索引,辅助按时间查询消息)
3.6、Log 与 Index 的一一对应关系
每个 Segment 的.log 和.index 文件共享相同的 "基准偏移量" 文件名,例如:
- 某 Segment 的基准偏移量是
1000(表示该 Segment 存储的第一条消息偏移量是 1000),则对应的文件是:1000.log:存储偏移量 1000 及之后的消息;1000.index:存储该 Segment 内消息 Offset 对应的物理存储位置(字节偏移量)。
3.7、核心协作逻辑(以 "根据 Offset 查询消息" 为例)
- 定位 Segment :当需要查找某 Offset(如 1050)的消息时,Kafka 先找到对应的 Segment(基准偏移量≤1050 的最大 Segment,即
1000.log对应的 Segment); - 查询 Index 文件 :在
1000.index中,查找与目标 Offset(1050)最接近的前序索引项(例如索引中存了 (5, 1200),表示相对偏移量 5(即绝对 Offset=1000+5=1005)对应的消息在.log 文件的 1200 字节位置); - 读取 Log 文件:从.log 文件的 1200 字节位置开始,顺序读取直到找到 Offset=1050 的消息。
3.8、协作价值
- 高效查询:避免直接遍历大.log 文件,通过 Index 快速定位消息位置,大幅提升读取性能;
- 节省空间 :Index 是稀疏索引(并非每条消息都建索引),仅存储部分 Offset 的映射,平衡索引效率与存储空间;
- 便于管理:Segment 的分段设计(默认按大小或时间滚动),让.log 和.index 可以独立清理、归档,避免单个文件过大。
3.9,基础单 Topic + 双 Broker 集群(模拟示意图)
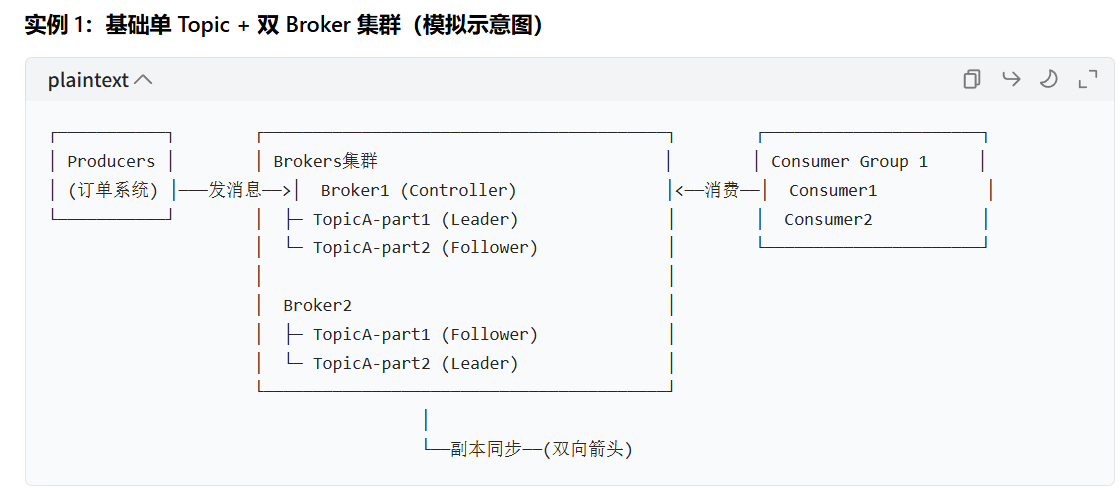
- 结构说明:1 个 Topic(TopicA)拆分为 2 个 Partition,分布在 2 个 Broker;每个 Partition 的 Leader/Follower 分属不同 Broker,避免单点故障。
- 交互:生产者发消息到 TopicA 的 Leader 副本;消费者组 1 的 2 个消费者分别消费 2 个 Partition。
四,消息队列(MQ)
4.1 是什么
消息队列(Message Queue,MQ)是一种基于异步通信模式的中间件,核心作用是通过 "存储 - 转发" 机制实现分布式系统间的解耦、异步交互与流量调控,是保障高并发、高可用分布式架构的关键组件。
4.1.1、核心概念
- Producer(生产者):向 MQ 发送消息的应用 / 服务,负责产生并投递消息。
- Consumer(消费者):从 MQ 订阅并消费消息的应用 / 服务,处理消息内容。
- Broker(服务节点):MQ 的服务端,负责存储消息、转发消息、管理生产者 / 消费者连接。
- Message(消息):通信的基本单位,包含消息体(业务数据)、消息头(路由、属性等元数据)。
- Topic/Queue(消息容器) :
- Queue(队列):点对点模式的容器,消息只能被一个消费者消费,消费后删除。
- Topic(主题):发布 - 订阅模式的容器,消息可被多个消费者订阅消费,支持广播。
- 核心通信模式 :
- 点对点(P2P):消息进入 Queue,唯一消费者获取并处理,适用于任务分发(如订单处理)。
- 发布 - 订阅(Pub/Sub):消息发布到 Topic,所有订阅者均可接收,适用于广播通知(如系统告警)。
4.1.2、特性
- 系统解耦上游系统只需将消息发送到 MQ,无需关心下游系统的具体实现;下游系统按需订阅消息,系统间不再直接耦合(如订单系统无需直接调用库存、支付、物流系统,仅发送订单消息到 MQ 即可)。
- 异步通信替代同步调用,上游系统发送消息后无需等待下游响应,直接返回结果,提升接口响应速度(如用户注册后,同步返回 "注册成功",异步通过 MQ 完成短信发送、积分发放)。
- 削峰填谷应对突发流量(如电商秒杀、双十一),MQ 将瞬时高并发请求存储起来,下游系统按自身处理能力匀速消费,避免系统被压垮。
- 可靠性保障支持消息持久化、重试机制、死信队列(DLQ),确保消息不丢失、不重复消费(或可追溯)。
- 扩展性提升可通过增加 Consumer 节点横向扩展消费能力,或增加 Broker 节点扩容存储 / 转发能力,适配业务增长。
4.2、典型应用场景
- 分布式系统解耦微服务架构中,替代服务间的同步 RPC 调用,降低服务依赖(如用户下单流程:订单服务→MQ→库存服务 / 支付服务 / 物流服务)。
- 流量削峰秒杀活动中,将瞬时几十万订单请求写入 MQ,订单处理系统按每秒几千的速度消费,避免数据库宕机。
- 异步任务处理非核心流程异步化(如注册后发送验证码、下单后生成物流单、评论后更新热搜榜)。
- 日志集中收集结合 ELK 架构,通过 MQ(如 Kafka)收集分布式系统的日志,再由 Logstash 消费转发到 Elasticsearch 分析。
- 跨系统数据同步数据库 binlog 通过 MQ 同步到数据仓库、缓存或其他业务系统(如 MySQL binlog→Kafka→Hive/Redis)。
五。发布/订阅模式
发布 / 订阅(Publish/Subscribe,Pub/Sub)是消息队列(MQ)中核心的异步通信模式,核心特征是 "一对多" 的消息分发机制:消息发布到指定主题(Topic)后,所有订阅该主题的消费者均可接收并处理消息,适用于需要广播通知或多系统协同处理同一消息的场景。