大家好!我是大聪明-PLUS!
在这个项目中,我今年夏天接到了一个颇具挑战性的任务:在Linux内核中实现以太网接口的PROTO_DOWN选项。内核默认仅支持vxlan和macvlan接口的PROTO_DOWN选项,而以太网接口是否支持则取决于网络设备驱动程序。
本文将详细介绍这项任务中与 Linux 内核相关的部分。我投入了大量时间和精力来实现这项需求,并希望与社区分享我的经验。我会尽可能详细地解释每个步骤,以便您即使从未进行过内核开发,也能在此基础上构建自己的开发流程。本文不仅对程序员有用,对 Linux 爱好者也很有帮助,因为它更侧重于操作系统操作的细节,而非编程本身。

首先,我必须弄清楚内核中 PROTO_DOWN 的工作原理,并理解为什么我们的驱动程序不支持它。然后,我必须找到修复方法并将其集成到我们的代码中。
这是我第一次接触 Linux 内核代码,我兴奋不已。我之前用了三年 Arch 作为我的主要操作系统,也用过六年其他 Linux 发行版。我对操作系统及其组件的工作原理略知一二。我一直对事物运作的原理充满好奇,这也是我最初使用 Linux,后来又转而使用 Arch 的原因。现在,我进入了下一个阶段------探索 Linux 的奥秘究竟有多深。
我首先需要的是一个实验环境。试图修改宿主机的内核来进行开发是非常愚蠢且危险的------当然,这确实是我的第一步。不过我并没有搞砸任何东西,所以我们跳过这部分。下一步是使用虚拟机。在我看来,通过图形安装程序手动安装系统既费时又无趣。但我用的是 Arch Linux,所以我知道如何使用文本模式安装程序来安装系统。
接下来,我找到了将虚拟磁盘挂载到主机系统的方法,并在其上安装了系统。这种安装方式与使用带有 Live CD 镜像的 U 盘安装系统并无二致。正是基于此,我编写了一个脚本,用于自动创建 Arch 虚拟机镜像。
虚拟拱门
使用脚本创建图像非常快;我不到一分钟就能完成。

Arch 安装时间
下一步是构建内核。这一步骤是在容器中完成的,而不是在虚拟机中。这样可以节省资源并加快构建速度。构建本身很简单:只需调用 `make` 命令并指定目标即可。自行配置内核非常困难且耗时。创建一个能够正常运行的配置则更加困难。最初,我尝试使用图形化工具自行配置。但这样构建的内核无法运行,我意识到这不是一个可行的方案。我需要一个合适的配置。
通常情况下,一个正常运行的系统会有一个内核配置文件,其中包含构建过程中使用的配置参数。它通常位于*`/boot/config-*` 目录* 下。我们的交换机也有一个这样的配置文件,所以我以此为基础进行配置。有了合适的配置文件后,我切换到了虚拟的Debian 系统,因为它更接近我们的操作系统。
内核构建系统支持多种不同的构建目标:
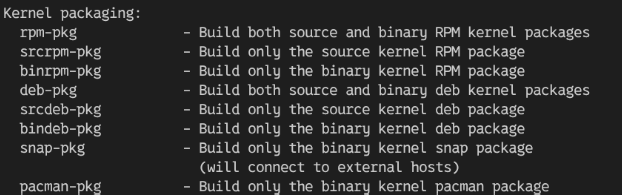
可用的内核构建包
Debian 使用apt ,所以我构建了一个 deb 包。在许多发行版中,以软件包形式分发是更新内核的标准方法。当时,我对这一切的工作原理并不完全了解,所以这是最好的入门选择。
构建内核 deb 包
我将软件包传输到虚拟机,并使用软件包管理器进行了安装。重启后,我本以为会在引导加载程序菜单中看到新内核,但它并没有出现。幸运的是,旧内核没有被删除,所以我能够使用它启动系统。
Grub 引导程序没有显示内核,所以我推测问题出在引导加载程序的配置上。我打开 grub.cfg 文件,发现里面没有任何关于内核的信息。我记得 Arch Linux 有一个可以生成引导加载程序设置的脚本,后来我又找到了一个类似的 Debian 脚本。但是用这种方法生成的配置在我这里却不起作用:系统根本无法启动。
为了避免费力去研究自动生成的文件并尝试修复它,我决定弄明白它的工作原理。在学习了语法之后,我自己创建了配置文件,并成功启动了内核。这证实了这种方法是有效的,这也是你现在能看到这篇文章的原因。:)
准备环境
你需要QEMU 来运行虚拟机,需要Docker 来进行开发。除了显而易见的用途之外,还需要 Docker 才能通过chroot在虚拟机中运行其他发行版。在把所有东西都放到容器里之前,我尝试过所有操作都在主机上完成。但是,由于我运行的是 Arch Linux,而 Debian 系统需要用到,所以没有容器我根本无法完成这些工作。
QEMU 和 Docker 是您最需要的工具。其余的实用程序在大多数发行版中都已预装,即使没有预装,手动安装也没问题。我的仓库中的脚本会检查您的系统是否安装了必要的实用程序,并报告任何缺失的命令。
安装 Debian
我非常不喜欢手动安装 Debian,所以很高兴能够使用控制台命令来安装系统。这可以自动创建镜像,加快工作环境的准备速度。也许你使用的是其他发行版,不知道如何安装或者无法使用命令行安装。在这种情况下,你可以选择手动安装。关键是要得到一个 qcow2 格式的磁盘。你也可以使用其他格式,但那样的话就需要修改我的脚本,因为它们是为 qcow2 格式设计的。
首先,我们需要创建一个虚拟磁盘。它将包含虚拟系统。创建一个原始镜像。
`qemu-img create `-o` `preallocation=`falloc `-o` `nocow=`on `-f` raw disk.raw 10G`这条命令会创建一个原始 格式的虚拟磁盘文件,方便用户快速上手。使用预分配选项,我们让 QEMU 为元数据分配空间,其余空间则保持未分配状态。10G显然表示磁盘大小。稍后我们会将原始文件转换为 qcow2 格式,转换后的文件将占用系统所需的空间。
nocow 选项仅适用于 btrfs 文件系统;它对其他文件系统无效。对于 btrfs 文件系统,它应该可以减轻性能损失。以下是 QEMU 文档中的相关说明:
当虚拟机镜像文件托管在 Btrfs 文件系统时,其性能较低,尤其是在虚拟机上的客户机也使用 Btrfs 作为文件系统时,性能下降更为明显。关闭写时复制 (COW) 是一种缓解性能问题的办法。
我用的是 btrfs 文件系统和 PCIe 5.0 硬盘,没发现什么区别。不过,如果你愿意的话,可以把奶牛图案去掉。
接下来,我们需要格式化虚拟磁盘。我们将使用GPT 分区 和传统 BIOS 。为什么不选择UEFI 呢?虚拟UEFI 需要OVMF ,这是一款用于支持虚拟机中 UEFI 的软件。BIOS不需要任何额外组件,因此这个方案更简单。虽然UEFI 可以配合 OVMF 使用,但如果您使用的是非标准架构,可能难以安装 OVMF。因此,我们将使用 BIOS。BIOS 分区需要 1 MB 的空间,剩余空间将分配给系统并格式化为ext4。
以下命令将在磁盘上创建一个gpt表:
`parted `-s` disk.raw mktable gpt`以下命令将在文件中创建一个 1 MB 的分区。该分区位于磁盘地址空间的前两个兆字节之间。这是主分区,系统启动需要用到它。
`parted `-s` disk.raw mkpart primary 1M 2M`接下来,我们需要将其标记为可启动分区。`bios_grub`标志表示我们将使用 BIOS。"1"表示这是启动分区:
`parted `-s` disk.raw `set` `1` bios_grub on`最后一步是将所有剩余磁盘空间分配给系统根分区。该分区将作为主分区,起始大小为 2 MB,紧接在 BIOS 分区之后。"100%"表示所有剩余空间已使用完毕。
`parted `-s` disk.raw mkpart primary ext4 2M `100`%`命令执行完毕后,虚拟磁盘将被分成两个分区。第一个分区用于启动系统,我们之后不会再对其进行任何操作。第二个分区将包含系统以及运行系统所需的一切文件。
现在需要将虚拟磁盘连接到主机系统。这可以通过使用loop 设备来实现。该命令相当于将物理磁盘连接到系统,但它适用于虚拟磁盘:
sudo` losetup `--find` `--partscan` disk.raw`系统中将出现一个新的虚拟文件设备,它链接到虚拟磁盘文件。请找出磁盘连接的位置:
`losetup `-a`
/dev/loop0: []: (/home/mrognor/Desktop/Qemu/disk.raw)`此命令显示设备**/dev/loop0** 指向文件disk.raw 。设备名称可能因系统而异。本文将使用loop0 ,但请务必将其替换为您自己的设备名称。
将磁盘上的第二个分区格式化为ext4 文件系统。操作系统将安装在此分区上。不要忘记设置循环设备名称。
sudo` mkfs.ext4 /dev/loop0p2`现在您可以将循环设备挂载到主机系统。以下命令会将虚拟磁盘的第二个分区挂载到主机系统。/mnt是分区路径。
sudo` mount /dev/loop0p2 /mnt`您的虚拟磁盘会像真实磁盘一样连接到您的系统。您可以像在物理计算机上一样,从U盘安装操作系统到虚拟磁盘上。
现在你需要找到系统分区的UUID。这个标识符可以帮助你在系统启动时识别磁盘。注意不要与循环设备混淆。
`lsblk -f /dev/loop0p2
NAME FSTYPE FSVER LABEL UUID FSAVAIL
FSUSE% MOUNTPOINTS
loop0p2 ext4 1.0 f0509427-31bf-4216-9155-7607141c6267 9.2G
0% /mnt`系统启动时需要用到这个UUID ,请将其保存到某个地方。
有一个用于安装 Debian 的debootstrap 脚本。为了避免将其安装在主机系统上,我们将使用Docker 容器 。我将使用debian:trixie,因为旧版本的容器不支持所需的软件版本。
`docker run `-it` `--mount` `src=`/mnt`,target=`/mnt`,type=`bind `--rm` `--privileged` debian:trixie`此命令将启动一个具有管理员权限的 Debian 容器。包含已挂载虚拟磁盘的*/mnt*目录也将挂载到容器中。这样,容器内就可以像访问普通目录一样访问该磁盘。
我们将把所有安装所需的软件包安装到一个临时容器 中,而不是Docker 镜像中 , 因为我们只需要它们一次。Debootstrap用于系统本身,而grub2用于安装引导加载程序:
`apt-get update `-y` && apt-get install `-y` debootstrap grub2`之后,您可以使用以下命令安装系统:
`debootstrap trixie /mnt`这条命令会将 trixie 安装到*/mnt* 目录。由于 Linux 系统中一切皆文件,你可以想象这条命令只是将整个 Debian 文件结构放入*/mnt目录。*
但文件结构本身不足以启动系统。引导加载程序负责实际的启动过程,因此也需要安装在镜像中。我们将使用grub2。它的软件包已经安装在容器中;剩下的工作就是将引导加载程序本身安装到虚拟磁盘上。别忘了将 loop0 替换为您的设备。
`grub-install `--recheck` `--target=`i386-pc `--modules=`part_gpt `--boot-directory=`/mnt/boot /dev/loop0`此命令会将引导加载程序安装到*/mnt/boot* 。在虚拟磁盘上,这对应于*/boot*路径。
Debootstrap 不会安装操作系统内核。虽然我们会编译自己的内核,但最好还是安装一个预编译好的内核。这有助于验证修改。在 Debian 系统中,内核以*.deb 软件包的*形式提供。该软件包包含内核运行所需的一切,包括内核文件本身和所有内核模块。
容器用于同步主机和虚拟磁盘上的操作系统。使用chroot ,您可以将虚拟机镜像作为文件系统的根目录来运行命令。这应该等同于在正在运行的虚拟机中运行命令。实际上,内部流程会略有不同,但这对我们来说没问题。
虚拟磁盘以环路设备的形式挂载。它先挂载到主机系统,然后连接到 Docker 容器。在容器内部,使用 chroot 来访问客户操作系统。
让我们通过软件包管理器安装内核:
chroot` /mnt `bash` `-c` `'apt-get install -y linux-image-amd64'为了方便起见,我们添加一个用户密码:
chroot` /mnt `bash` `-c` `'echo "root:root" | chpasswd'至此,容器内的工作已完成,您可以退出容器:
exit要使系统启动,您需要指定哪些分区应该挂载到哪里。为此,您需要在fstab 文件中进行指定。该文件用于在系统启动期间挂载设备。打开该文件/mnt/etc/fstab并粘贴以下文本:
# Static information about the filesystems.`
`# See fstab(5) for details.`
`# <file system> <dir> <type> <options> <dump> <pass>`
`# /dev/loop0p2`
UUID=f0509427-31bf-4216-9155-7607141c6267 / ext4 rw,relatime 0 1`别忘了将UUID替换成你自己的 UUID。此文件指定将具有你提供的 UUID的分区挂载为文件系统的根目录。
接下来,你需要配置 GRUB,让它知道内核和 initrd.img 或 initramfs 的位置。Initramfs 是用于挂载主文件系统的引导文件系统。它加载到 RAM 中,包含检测已连接设备所需的一切信息。
使用引导加载程序配置文件/mnt/boot/grub/grub.cfg。将以下文本粘贴到该文件中,并务必将uuid替换为您自己的 uuid。
`set default=0
set timeout=5
uuid=f0509427-31bf-4216-9155-7607141c6267
menuentry 'Debian' --class arch --class gnu-linux --class gnu --class os 'gnulinux-simple-$uuid' {
insmod gzio
insmod part_gpt
insmod ext2
echo 'Loading Linux linux ...'
linux /vmlinuz root=UUID=$uuid rw loglevel=3 quiet console=ttyS0
echo 'Loading initial ramdisk ...'
initrd /initrd.img
}`第一行指定默认加载哪个条目。目前只有一个条目,因此该参数值为 0。
第二行指定了系统启动前的延迟时间。我建议预留一些时间,以便在修补后的内核出现任何错误时,您可以启动回原始内核。
启动选项通过menuentry 指定。以linux 开头的行在这里很重要。这是内核及其启动选项的路径。root用于挂载文件系统的根目录。我们将使用uuid 来标识分区。另一个重要的选项是console=ttyS0 。它允许您以文本模式启动系统,无需 创建单独的图形窗口,即可直接在控制台中工作。
新系统的 grub 窗口
安装完成。将虚拟磁盘从主机文件系统中分离:
sudo` umount `-l` /mnt
`sudo` losetup `-d` /dev/loop0`Raw 格式对于处理虚拟机来说并不方便,因此需要将其转换为 qcow2 格式:
`qemu-img convert `-f` raw `-O` qcow2 disk.raw disk.qcow2`之后您可以删除原始文件:
rm` disk.raw`要测试安装是否成功,请使用以下命令启动虚拟机:
`qemu-system-x86_64 `-enable-kvm` `-smp` `2` `-m` 1024m `-drive` `format=`qcow2`,file=`disk.qcow2 `-nographic` `-serial` mon:stdio`如果您使用的是非 x86 处理器,则 QEMU 启动命令会有所不同。
-
-enable-kvm - 启用内核内置的虚拟机管理程序,以加快运行速度。
-
-smp 2 --- 处理器核心数,您可以指定任意数字。
-
-m 1024m --- 内存大小。
-
-drive format=qcow2,file=disk.qcow2 --- 将磁盘连接到虚拟机。
-
-nographic --- 用于禁用创建图形窗口的键。
-
-serial mon:stdio --- 以文本模式启动系统的键。
虚拟机的登录名和密码是root:root 。要停止虚拟机,可以使用Ctrl-A + x 组合键或shutdown 0命令。
正在运行的虚拟机
此时,停止虚拟机。
准备 Docker 镜像
为了最大程度地减少错误并简化部署,构建过程将在 Docker 容器中进行。如上所述,这是一个可选步骤,您可以在主机上执行所有操作,但我建议使用容器。
创建一个包含以下内容的Dockerfile 。
`FROM debian:trixie
ARG DEBIAN_FRONTEND=noninteractive DEBCONF_NOWARNINGS=yes
RUN apt-get update -y && \
apt-get upgrade -y && \
apt-get install -y \
build-essential \
libncurses-dev \
debhelper \
dwarves \
gcc \
bc \
bison \
flex \
libssl-dev \
libelf-dev \
python3 \
rsync \
kmod \
zstd \
clangd \
bear \
cpio \
libdw-dev \
adduser`此镜像基于debian:trixie,并安装了构建所需的所有软件包。
要构建镜像,您需要使用以下命令:
`docker build `-t` kernel-dev .`此命令将构建一个名为 kernel-dev 的镜像。
构建内核
本项目中使用的是闭源内核,其源代码存储在公司服务器上。不过,这些说明是通用的,因此本文将以从 kernel.org Git 仓库获取的原始内核为例进行讲解。我还用 Debian 内核测试了该补丁,没有发现任何差异。如果您使用的是自己的内核,也很容易根据说明进行调整。
内核代码库非常庞大,如果您担心文件过大,可以从kernel.org 或项目的GitHub发布页面下载源代码压缩包。将代码库克隆到您的计算机:
git` clone https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git`将项目切换到所需的内核版本。您可以在虚拟机中直接找到它。运行它:
`qemu-system-x86_64 `-enable-kvm` `-smp` `2` `-m` 1024m `-drive` `format=`qcow2`,file=`disk.qcow2 `-nographic` `-serial` mon:stdio`调用 uname -a 命令:
`uname `-a我的结论是:
`Linux 4bc6af05e42a 6.12.43+deb13-amd64 #1 SMP PREEMPT_DYNAMIC Debian
6.12.43-1 (2025-08-27) x86_64 GNU/Linux`遗憾的是,并非所有镜像都包含所有标签,所以我切换到了内核 6.12:
cd` linux
`git` checkout v6.12
`cd` ..`现在我们需要获取内核配置文件。从目标系统(即需要打补丁的内核系统)获取。之前我直接从一台运行中的交换机上获取了配置文件,但现在我们将从虚拟机中获取。它位于 `/ boot` 目录下,名为*`config-*`* 。我们需要将此文件移动到*`linux`* 目录并保存为*`.config`*。
内核也可以使用预编译的 make 目标进行配置,例如defconfig 或tinyconfig。以下摘自 Makefile 的目标描述:
-
Defconfig --- 使用 ARCH 提供的 defconfig 中的默认值创建新配置。
-
Tinyconfig - 配置尽可能小的内核。
这些目标的组装速度比完整配置快得多,因此您可以使用它们来节省时间。
由于我们要操作虚拟磁盘上的文件,因此需要将其挂载到主机系统。遗憾的是,我们不能使用 Losetup,因为它不支持 qcow2 格式。要挂载此类磁盘,我们将使用nbd。这项技术允许您将虚拟磁盘作为网络块设备进行访问。
加载nbd内核模块以挂载虚拟磁盘:
sudo` modprobe nbd`执行该命令后,nbd 设备将被添加到系统中。
我的系统上的 NBD 设备列表
您的系统可能已经连接了一些 nbd 设备。您可以使用nbd-client命令进行检查。该命令将显示是否有任何设备连接到 nbd 设备:
`nbd-client `-c` /dev/nbd0`首先搜索空闲设备编号 0。如果命令没有返回任何结果,则可以连接到该设备。否则,请增加设备编号。找到可用空间后,将虚拟磁盘文件连接到该空间并将其挂载到主机文件系统中:
sudo` qemu-nbd `-c` /dev/nbd0 disk.qcow2
`sudo` mount /dev/nbd0p2 /mnt`复制内核配置文件。在虚拟机中,它位于*/boot* 目录下。虚拟机的文件系统挂载在*/mnt 目录* 下,因此完整路径为*/mnt/boot* 。该文件应放置在源代码目录中,并命名为*.config*。
cp` /mnt/boot/config-6.12.43`+`deb13-amd64 linux/.config`文件复制完成后,即可断开磁盘连接:
sudo` umount `-l` /mnt
`sudo` qemu-nbd `-d` /dev/nbd0`未来,磁盘的连接和断开将以类似的方式处理。或者,您也可以在虚拟机运行时直接使用SSH 。
现在我们可以开始构建了。为此,我们需要启动一个 Docker 容器。务必将其置于源代码仓库的上一级目录,因为 .deb 软件包是在源代码仓库的上一级目录中创建的。
`docker run `-it` `--rm` `--mount` `src=`.`,target=$(pwd),type=`bind `--privileged` `-w` `$(pwd)` kernel-dev`在容器内,进入源代码目录:
cd` linux`要在 QEMU 中运行内核,需要将以下选项添加到配置中:
`./scripts/config `-e` CONFIG_64BIT \
`-d` CONFIG_EMBEDDED \
`-d` CONFIG_EXPERT \
`-e` CONFIG_SERIAL_8250 \
`-e` CONFIG_SERIAL_8250_CONSOLE \
`-e` CONFIG_VIRTIO \
`-e` CONFIG_VIRTIO_MENU \
`-e` CONFIG_PCI \
`-e` CONFIG_VIRTIO_PCI \
`-e` CONFIG_VIRTIO_BLK \
`-e` CONFIG_EFI_PARTITION \
`-e` CONFIG_EXT4_FS \
`-e` CONFIG_BINFMT_ELF \
`-e` CONFIG_E1000 \
`-e` CONFIG_VIRTIO_NET`或者使用 make 目标:
make` kvm_guest.config`此配置将允许内核在 QEMU 中运行,并添加对虚拟网络设备的支持。-e 开关启用该选项,-d 开关移除该选项。
内核配置是整个过程中最复杂的部分。由于这是一份涵盖大多数开发场景的通用指南,我们将不再进行任何额外的配置更改。如果您不清楚具体需要启用或禁用哪些功能,最好不要进行任何修改。
附加配置点
随着内核的演进,会不断添加新功能,从而扩展其配置选项。旧版本内核的配置文件不包含这些新选项。构建之前,系统会检查所有选项,如果配置文件已过时,则会进行更新。运行构建过程时,用户可以交互式地选择新选项。
为了简化和自动化该过程,我们提供了一个特殊的 make 目标*------olddefconfig*。它会更新该文件并将所有新选项设置为其默认值:
make` olddefconfig`我在编译过程中遇到了一个问题。在一台配备 32GB 内存的工作笔记本电脑上,-j命令行选项make导致内存溢出,编译失败。我测试了多台不同处理器核心数和内存大小的设备,但从未遇到过此类问题。因此,指令中将使用" -jc"$(nproc)来表示编译线程数。您可以省略"c"选项$(nproc),但这可能会导致问题。在我的家用电脑上,我使用 32 个线程进行编译,这在峰值时需要 64GB 内存。
make` `-j$(nproc)` bindeb-pkg `LOCALVERSION=-patchedbindeb-pkg 选项用于指定构建 deb 软件包。需要注意的是,除了 deb 软件包之外,还可以构建rpm 、snap 和pacman 软件包。LOCALVERSION 选项用于向内核版本添加自定义字符串。您可以省略此选项,但添加此选项更方便:它可以帮助您快速识别内核版本。
组装可能需要相当长的时间,所以你或许应该去喝杯茶:

内核构建成功
恭喜!您已成功构建内核,现在它已与所有必需组件一起打包成 deb 软件包。内核软件包的名称类似于:linux-image-6.12.0-patched_6.12.0-1_amd64(不包含 dbg!)。系统还会创建其他软件包,但我们无需关注它们。deb 软件包名称以数字结尾,表示构建编号------例如,屏幕截图显示的是第一个构建版本。
DEB 包的每个新构建版本都会创建末尾带有递增版本号的文件,并且不会覆盖旧文件。这对于版本控制非常有用,但在自动化过程中务必注意这一点。现在您可以退出容器了。
安装内核
内核可以像普通的 deb 软件包一样安装。这是最简单便捷的方法,只需要一条命令即可。挂载虚拟磁盘:
sudo` qemu-nbd `-c` /dev/nbd0 disk.qcow2
`sudo` mount /dev/nbd0p2 /mnt`启动工作容器:
`docker run `-it` `--rm` `--mount` `src=`.`,target=$(pwd),type=`bind `--mount` `src=`/mnt`,target=`/mnt`,type=`bind `-w` `$(pwd)` `--privileged` kernel-dev`将包含新内核的文件复制到虚拟磁盘,记得将文件名更改为您自己的文件名,并且不要忘记写入版本号:
cp` linux-image-6.12.0-patched_6.12.0-1_amd64.deb /mnt/root/`将用户根目录切换 到虚拟机。由于 nbd 设备挂载到*/mnt* 目录,而主机路径*/mnt* 在容器内也映射到*/mnt目录,因此您需要* 切换 到*/mnt*目录。这样您就可以从容器内将软件包安装到虚拟磁盘上:
chroot` /mnt `bash安装包含新内核的 deb 软件包:
cd` root
dpkg `-i` linux-image-6.12.0-patched_6.12.0-1_amd64.deb`返回主机:
exit`
`exit好了,新内核安装完成。没什么复杂的。剩下的就是告诉引导加载程序新内核的信息。为此,你需要编辑grub.cfg 文件并添加一个条目。
打开文件/mnt/boot/grub/grub.cfg。在文件开头,将方括号 改为set default=0 `set default=1`。这将使第二个启动项默认启动。第二个启动项将启动新内核。在文件末尾添加以下文本:
`menuentry 'Debian patched' --class arch --class gnu-linux --class gnu --class os 'gnulinux-simple-$uuid' {
insmod gzio
insmod part_gpt
insmod ext2
echo 'Loading patched linux kernel ...'
linux /boot/vmlinuz-6.12.0-patched root=UUID=$uuid rw loglevel=3 quiet console=ttyS0
echo 'Loading initial ramdisk ...'
initrd /boot/initrd.img-6.12.0-patched
}`在 `/ etc/kernel/` 和`/etc/ initramfs/` 行中指定内核和initramfs 的正确路径非常重要。这些路径指向虚拟磁盘文件系统中的内核文件。在安装 DEB 包期间,它们会被添加到*`/boot` 目录* 。您的内核版本可能有所不同;请务必将其替换为正确的版本。linux /boot/vmlinuz-6.12.0-patched root=UUID=$uuid rw loglevel=3 quiet console=ttyS0``initrd /boot/initrd.img-6.12.0-patched
现在您可以断开虚拟磁盘的连接:
sudo` umount `-l` /mnt
`sudo` qemu-nbd `-d` /dev/nbd0`启动虚拟机:
`qemu-system-x86_64 `-enable-kvm` `-smp` `2` `-m` 1024m `-drive` `format=`qcow2`,file=`disk.qcow2 `-nographic` `-serial` mon:stdio`引导加载程序菜单中将自动选择包含内核的第二个条目。操作系统将在 5 秒后开始加载。
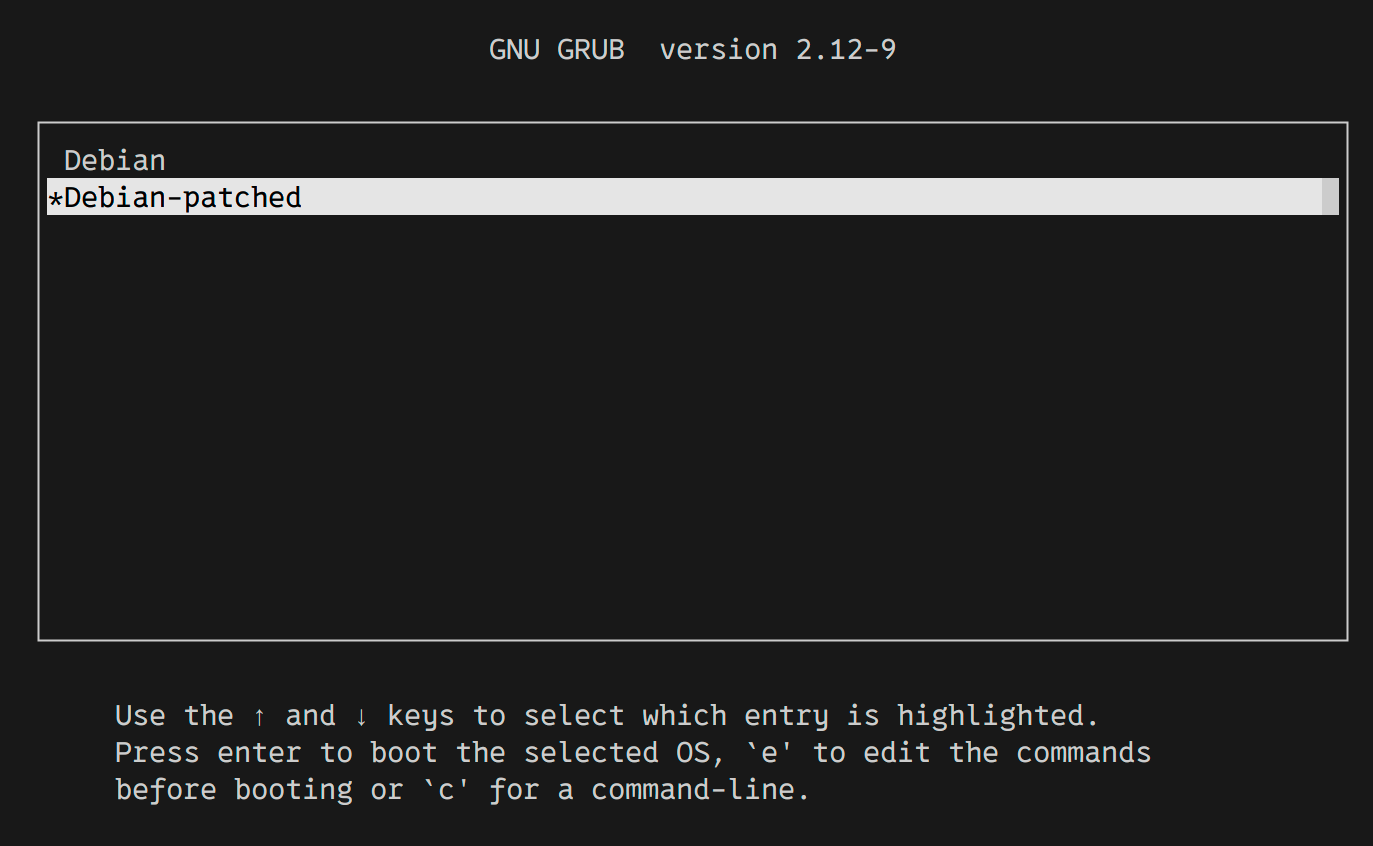
Grub 检测到两个内核不同的条目
如果一切操作正确,您将启动到您编译的内核!

新加载的内核
在内核开发过程中,您可能会修改各种组件。有些组件是内核的一部分,有些则是模块。.deb 包允许您更新所有组件,但这并非总是必要的。如果您正在修改内核而非模块中的代码,则无需重新编译所有内容并构建 .deb 包。只需构建一个新的内核文件即可,这比重新编译整个软件包要快得多。
随着我们继续开发内核代码,更新 deb 软件包也不会有什么不同,下一章将讨论文件的更新。
内核补丁
为了演示整个过程,我们对内核代码进行一些小的修改。打开linux/net/core 目录下的rtnetlink.c 文件。找到以下这行代码并将其替换为一些文本:Protodown not supported by device
if` (!dev->change_proto_down) {
NL_SET_ERR_MSG(extack, `"Hello world!"`);
return `-EOPNOTSUPP`;
}`这就是我们要修改的所有代码。之后,我们只需运行一个命令就能直观地看到这些更改。
将磁盘文件挂载到主机:
sudo` qemu-nbd `-c` /dev/nbd0 disk.qcow2
`sudo` mount /dev/nbd0p2 /mnt`进入构建容器:
`docker run `-it` `--rm` `--mount` `src=`.`,target=$(pwd),type=`bind `--mount` `src=`/mnt`,target=`/mnt`,type=`bind `-w` `$(pwd)` `--privileged` kernel-dev`进入内核目录并构建一个新的二进制文件。要构建单个内核文件而不是整个软件包,请使用不带目标的 make 命令:
cd` linux
`make` `-j$(nproc)` `LOCALVERSION=-patched之后,新内核将位于arch/x86/boot/bzImage目录下。请将虚拟机中的内核文件替换为新内核文件:
cp` arch/x86/boot/bzImage /mnt/boot/vmlinuz-6.12.0-patched`别搞错名称了。退出容器并卸载磁盘:
sudo` umount `-l` /mnt
`sudo` qemu-nbd `-d` /dev/nbd0`启动虚拟机:
`qemu-system-x86_64 `-enable-kvm` `-smp` `2` `-m` 1024m `-drive` `format=`qcow2`,file=`disk.qcow2 `-nographic` `-serial` mon:stdio`要查看更改,请运行以下命令:
`ip link `set` dev ens3 protodown on`结果大致如下:

这些变更实际上已经实施。
实际上,所有这些操作,包括替换内核文件和安装 DEB 软件包,都可以在运行的系统上完成。您可以使用scp传输必要的文件,并通过 ssh 安装软件包。由于 nbd 需要root 权限,这种方式可能更方便。仓库中提供了现成的脚本来实现这些操作。
我们本来可以就此结束,但为了获得更舒适的体验,最好启用LSP 服务器。它将为代码编辑器添加丰富的语言支持。我们将使用 clangd,因为它比 Intellisense 快得多,拥有适用于许多 IDE 的插件,而且我个人也更喜欢它。这将显著改善编码体验,尤其对初学者而言。
连接 clangd
本文将以 Code OSS(一个由社区开发的 VS Code 版本)为例,演示如何连接到它。连接到原生编辑器和其他编辑器的过程应该大同小异。
首先,将扩展程序安装到编辑器中:
扩展商店中的 clangd 页面
Intellisense 无法与 clangd 同时运行,因此如果您正在使用 Intellisense,可以创建一个单独的 VS Code 配置。为特定项目创建一个单独的配置,并在其中使用 clangd。不过,我建议您尽量经常使用 clangd 而不是 Intellisense。我很久以前就完全切换到了 clangd,从未后悔过。它唯一的缺点是默认配置,我不喜欢。但一旦根据自己的需求进行自定义,它就是一个非常强大的工具。
Clangd 非常智能,可以以多种模式运行。它可以仅使用项目中已有的文件在本地分析项目。然而,这种方式可能无法找到各种库和系统文件的头文件,也无法识别通过构建系统引入的额外头文件。
第二种操作模式是使用compile_commands.json 文件 。该文件包含所有项目构建信息,包括编译器选项以及所有包含和定义。它允许 LSP 服务器完整解析项目文件。现代构建系统(例如CMake)内置了生成该文件的功能。幸运的是,内核中有一个脚本可以生成此文件,但该脚本仅在内核构建完成后运行。如果您使用的是没有此脚本的旧内核,则可以使用 bear 工具。我最初也使用过 bear 工具,但脚本更方便。
由于构建过程在容器内进行,compile_commands.json 中的所有路径都将位于容器内。实际上,您可以让 clangd 在主机上运行。构建期间,主机和容器之间的所有路径都相同,因此compile_commands.json对主机也有效。但是,我更倾向于隔离构建环境,因此 clangd 将在容器内运行。这样可以实现无缝衔接:只需打开编辑器,一切都会自动运行。
你可能会问:为什么不直接在容器内打开编辑器呢?原因有二。首先,code-oss 不支持这种做法,所以我无法在容器内运行编辑器。其次,我的系统上有很多别名和其他设置,这些在容器内无法访问。因此,我在容器内运行 clangd,而编辑器和终端则保留在宿主机上。
在项目根目录下创建一个名为*`.vscode` 的文件夹。请记住,它应该位于核心源代码目录的上一级。在该文件夹中,创建两个文件:* `settings.json` 和*`clangd-in-container`*。您可以将第二个文件的名称更改为其他名称。
第一个文件是 VS Code 中的标准项目设置文件。请将以下文本添加到该文件中:
`{
"clangd.path": `"${workspaceFolder}/.vscode/clangd-in-container"`
}`此设置将覆盖 lsp 服务器二进制文件的路径,并将其替换为一个脚本。通过此设置,我们可以以任何我们想要的方式运行 clangd。
将以下文本添加到clangd-in-container脚本中:
# Symbolic links workaround`
`cd` `$(dirname "$0")`
`cd` ..
`# Wait compile_commands.json file`
`while` [ ! `-f` linux/compile_commands.json ];
`do`
`sleep` `1`
`done`
`# Launch lsp server`
docker run `-i` \
`--rm` \
`--mount` `src=`.`,target=$(pwd),type=`bind \
`-w` `$(pwd)` \
`--name` vs-code \
kernel-dev:latest `bash` `-c` `"clangd $*"添加前两行代码是为了解决符号链接的问题。之后,程序会启动一个循环,等待compile_commands.json文件生成。该文件由 一个 Python 脚本生成。在代码仓库中,构建完成后,该脚本会自动调用。
启动容器的命令比较复杂,需要单独解释。关键-i在于以交互模式启动容器。Clangd 通过标准输入/输出描述符与 IDE 通信,IDE 也以同样的方式与脚本通信。挂载是必要的,用于将源文件挂载到容器中并保存 clangd 缓存。该选项--name是可选的,但它可以简化正在运行的 Docker 容器列表。此选项-w对于正确的路径处理至关重要。它指向容器内的工作目录。IDE 和 lsp 服务器会交换项目文件的路径。IDE 提供本地主机路径,而 clangd 提供容器内的路径。
为了实现这一目标,这些路径需要对齐。这可以通过-w本地路径选项来实现,该选项允许将项目挂载到容器中,使用与主机上相同的路径。由于源文件是通过挂载的$(pwd),因此主机和容器之间的所有路径都将匹配。这样,IDE 甚至不会知道 clangd 正在容器中运行。
通过字符串调用 clangd $*。这将把传递给 bash 脚本的所有参数替换为 clangd 的启动参数。这样无需修改脚本即可进行自定义。
授予脚本运行权限:
chmod` `+`x clangd-in-container`现在需要生成compile_commands.json 文件。为此,请进入项目根目录下的容器:
`docker run `-it` \
`--rm` \
`--mount` `src=`.`,target=$(pwd),type=`bind \
`-w` `$(pwd)` \
kernel-dev:latest`然后调用compile_commands.json生成脚本:
cd` linux
python3 scripts/clang-tools/gen_compile_commands.py`如果没有脚本,请使用 bear。你需要清理构建并调用它bear -- make。打开任意*.c* 或*.h 文件*,索引就会开始。
索引核心文件
您可能会注意到编辑器指出的一些错误。这是 clangd 对编译选项的提示,因为它无法识别这些选项。因此,您需要禁用此功能。请.clangd在项目根目录创建一个文件,并添加以下设置:
CompileFlags:`
` Remove: [`-mpreferred-stack-boundary=3`,`
-mindirect-branch=thunk-extern`,`
-mindirect-branch-register`,`
-fno-allow-store-data-races`,`
-fmin-function-alignment=16`,`
-fconserve-stack`,`
-mrecord-mcount`]这些是我遇到的标志,但可能还有其他标志。只需指出错误信息即可找到标志名称并将其添加到此文件中。要将启动选项传递给 clangd,请打开settings.json 文件 并在其中指定它们clangd.arguments。这样您就可以自定义所有内容。以下是我的 settings.json 文件内容:
`{
"clangd.path": `"${workspaceFolder}/.vscode/clangd-in-container"`,
"clangd.arguments": [
`"-header-insertion=never"`,
`"--function-arg-placeholders=0"`
],
"explorer.excludeGitIgnore": `false`,
"search.useParentIgnoreFiles": `false`,
"search.useIgnoreFiles": `false`
}`至此,内核开发环境的手动准备工作就完成了。这个过程并不快,尤其考虑到内核构建时间,所以我创建了一个专门的代码仓库,以最大限度地减少必要的手动操作。
内核开发仓库
该项目实现了上述所有操作的自动化,并添加了一些便利功能,例如在虚拟机中运行 SSH 服务器。
主存储库文件是 config:
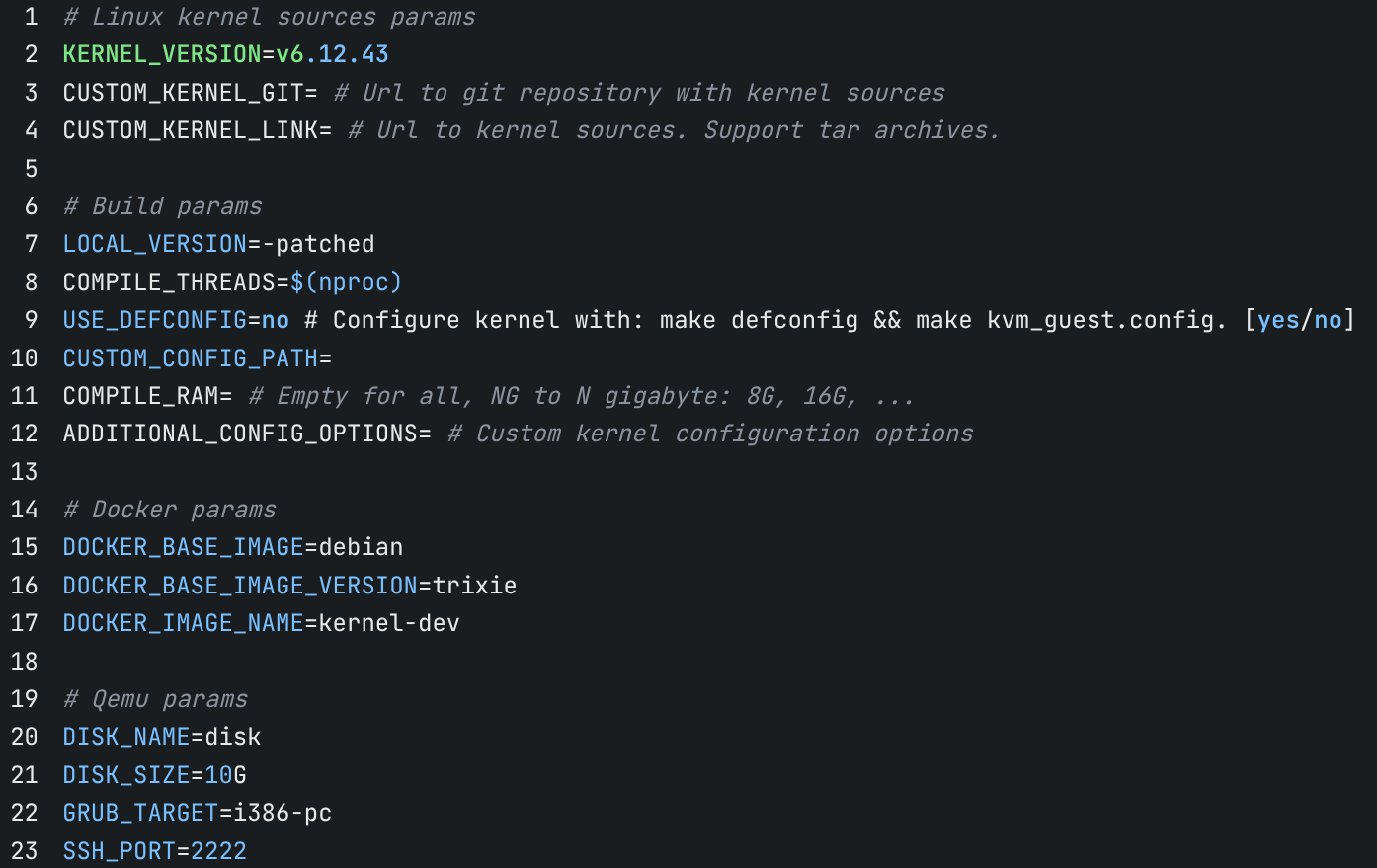
存储库配置
默认情况下,配置已完全就绪,但您可以根据需要进行自定义,例如添加内核源代码的链接。如果您计划从企业代码库修补内核,这将非常有用。目前,代码库中的脚本支持通过Git 下载以及指向tar 包的链接。
您可以使用 `USE_DEFCONFIG` 指定使用默认配置,以实现最快的构建速度。您还可以使用 `ADDITIONAL_CONFIG_OPTIONS` 添加自定义内核配置选项。这些选项将在下载源代码后、构建前应用。
您可以限制构建过程中使用的核心数和内存。请注意内存使用情况,如果内存不足,构建将会失败。仅在绝对必要时才限制内存,因为这会影响构建速度。
该仓库已完全准备好与 VS Code 配合使用,无需对 clangd 进行任何额外配置。仓库的scripts目录包含四种内核补丁脚本:通过挂载替换二进制文件、通过挂载安装 DEB 包、通过 scp 替换二进制文件以及通过 ssh 安装 DEB 包。
结论
我尽量用最简单明了的方式描述所有步骤,同时也揭示了操作系统的一些细微之处。我热爱Linux,也热爱学习它,所以我很想自己摸索、亲身实践,并将整个过程自动化。