文章目录
- [Depth Anything](#Depth Anything)
- [Depth Completion](#Depth Completion)
- [Monocular Depth Estimation](#Monocular Depth Estimation)
Depth Anything
MiDaS->Depth-Anything
一文贯通单目深度估计-从早期卷积网络到Depth Anything系列-从原理到源码精讲
Depth-Anything
V1(2024年)单目深度估计
DA本身是在做相对深度估计,而不是绝对深度估计(又叫metric depth,度量深度),意味着场景并没有尺度信息,深度只是相对关系。
天空区域的disparity值设为0(disparity值是深度值的倒数,为0表示无穷远区域)。


Deep Anything容易受到透明物体和反射的影响
V2(2024年6月)
最近出现的单目深度估计可以分为两组。一组基于BEiT和DINOv2这样的判别模型,例如Depth Anything;而另一组基于Stable Diffusion这样的生成模型,例如Marigold。


真实数据的优点

合成数据优点

合成数据的缺点

- Video DepthAnyThing(2025年1月)
Depth Completion
Depth Completion(深度补全)是一项计算机视觉任务,旨在从稀疏、不完整或低分辨率的深度测量数据中恢复出完整、高分辨率的深度图。以下是关于该任务的详细解释:
任务定义
输入:通常包括一个稀疏的深度图(如来自LiDAR、结构光传感器或双目视觉的稀疏点云)以及对应的RGB图像(可选)。
输出:一个密集的、高分辨率的深度图,其中每个像素都对应一个有效的深度值。
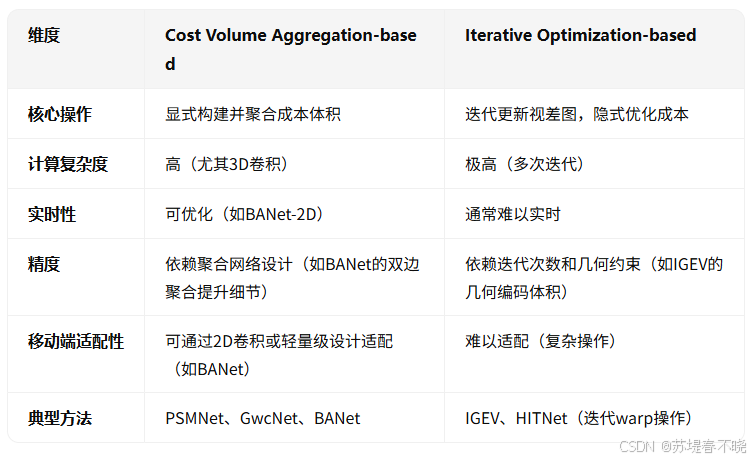
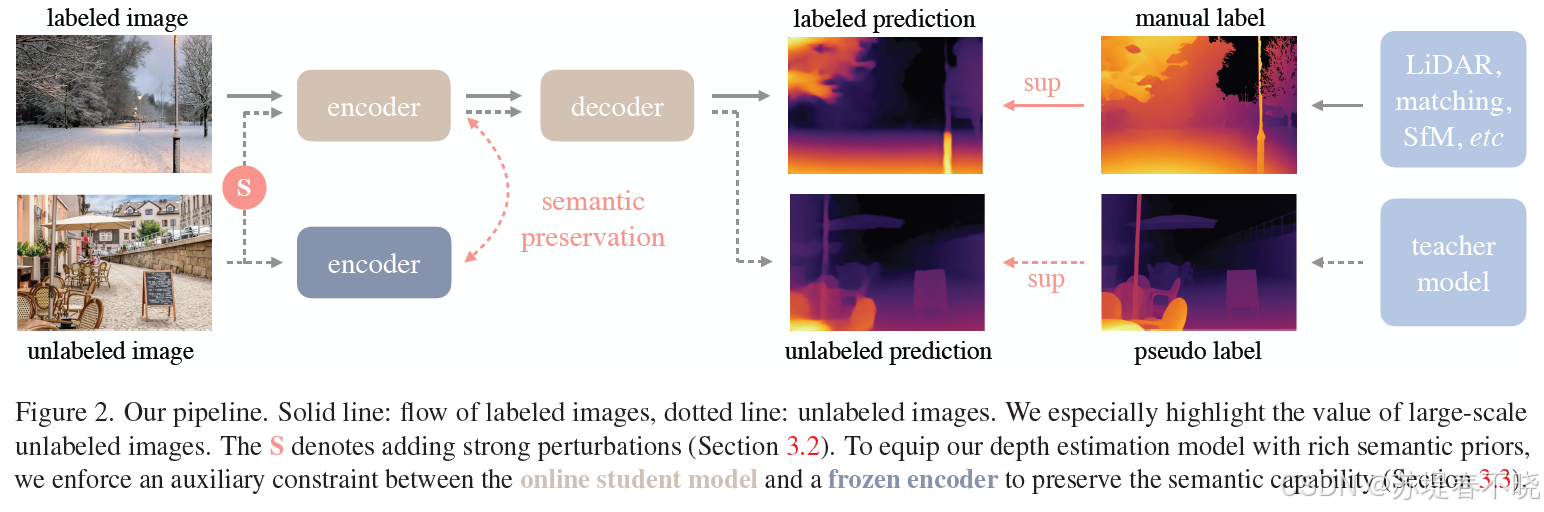
Monocular Depth Estimation
参考学习整理来自:如何实现视觉深度估计?单/双目+几何算法/深度学习网络

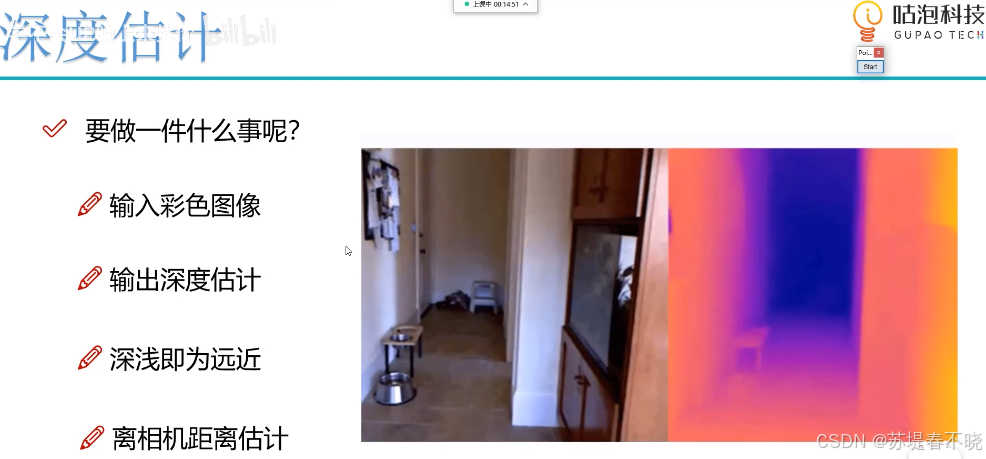


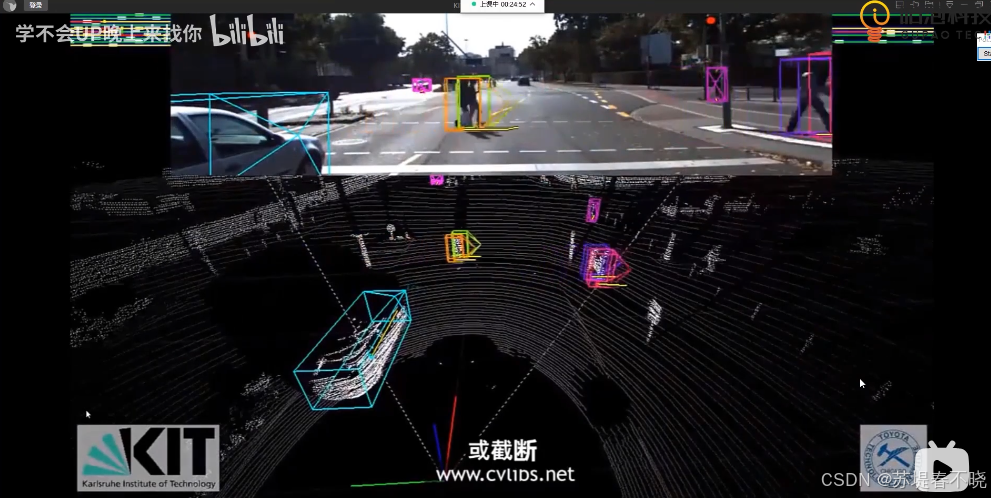
配合目标检测测距



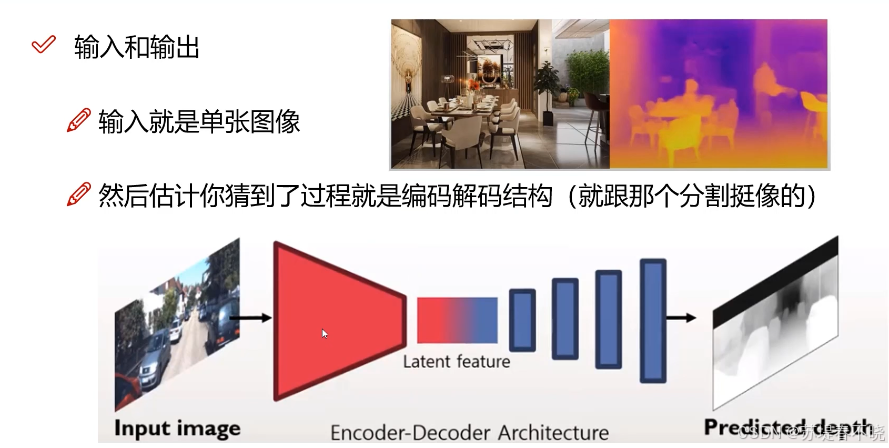
pipeline 和分割网络类似
以下面这篇论文为例
Song M, Lim S, Kim W. Monocular depth estimation using laplacian pyramid-based depth residualsJ. IEEE transactions on circuits and systems for video technology, 2021, 31(11): 4381-4393.
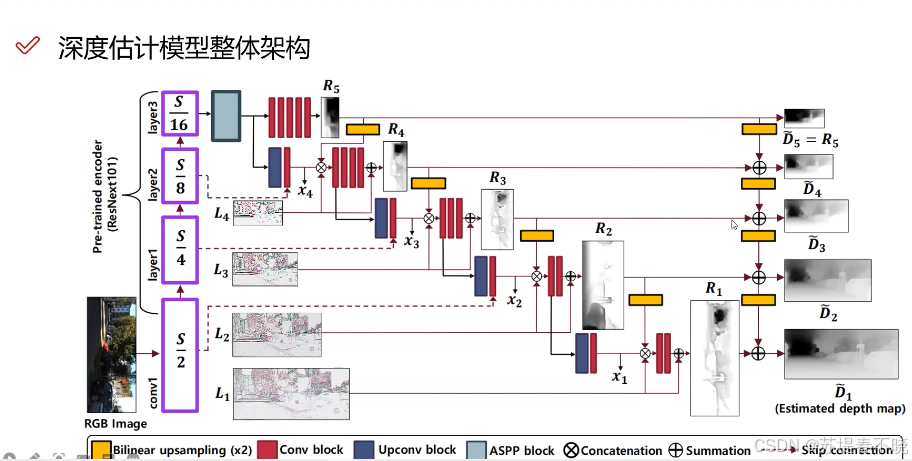


轮廓比较难学

用减法,laplace 金字塔,对应 code
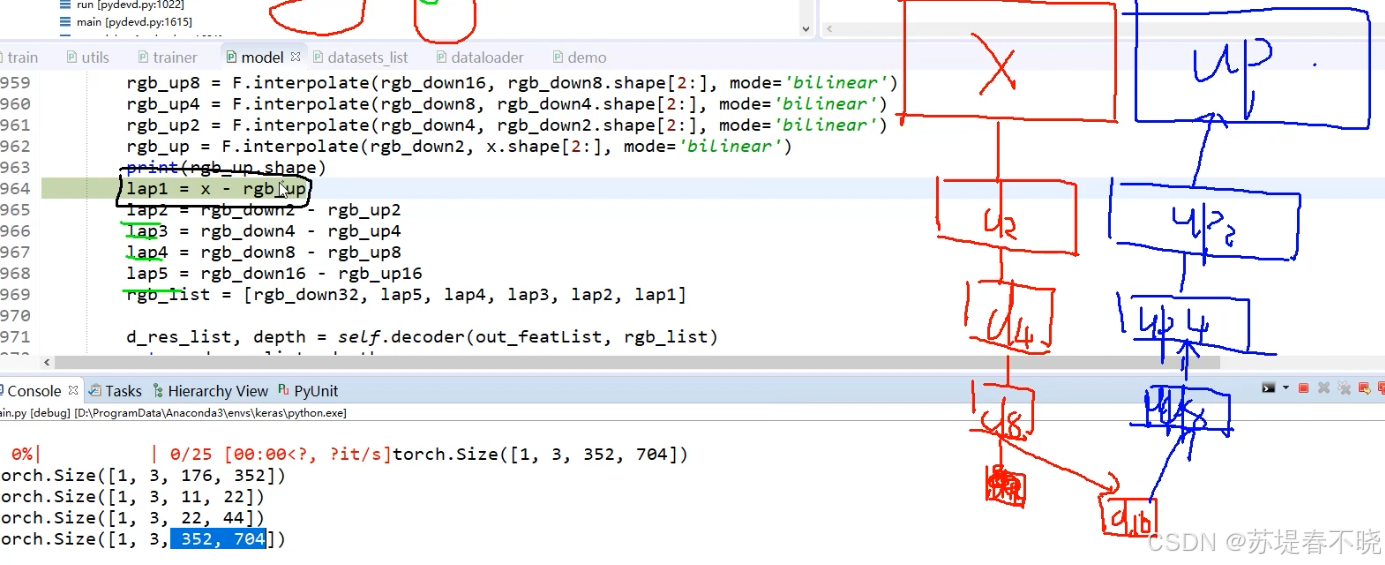
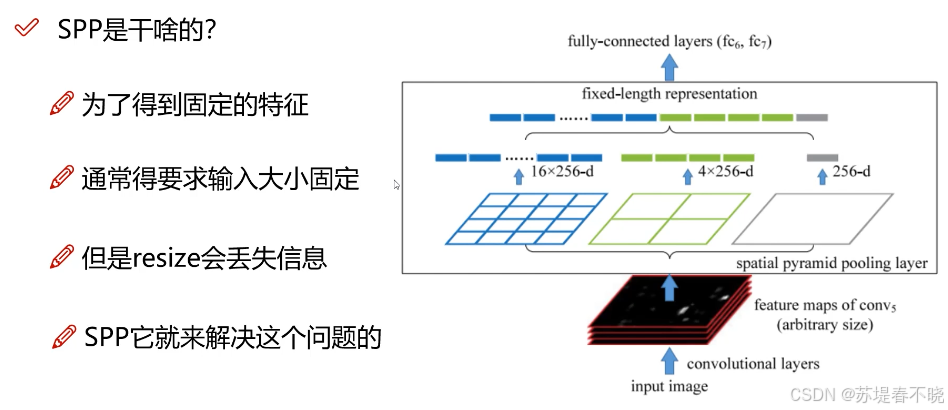
SPP

空洞卷积
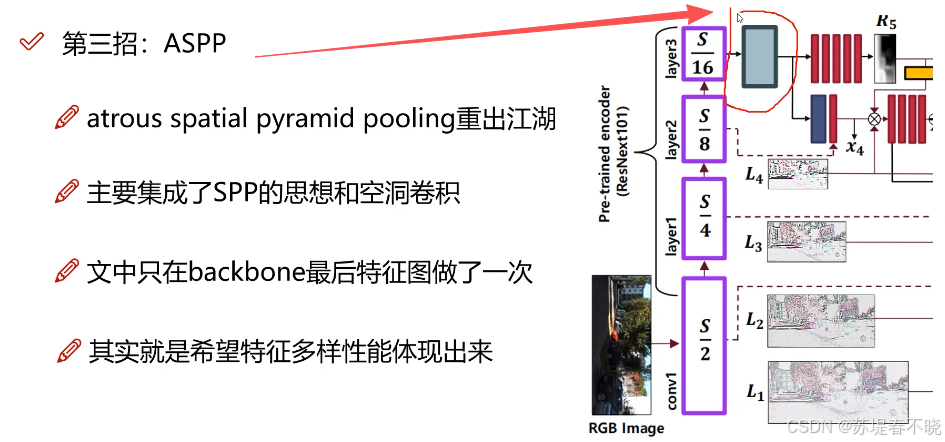
ASPP,蓝色处,空洞+SPP
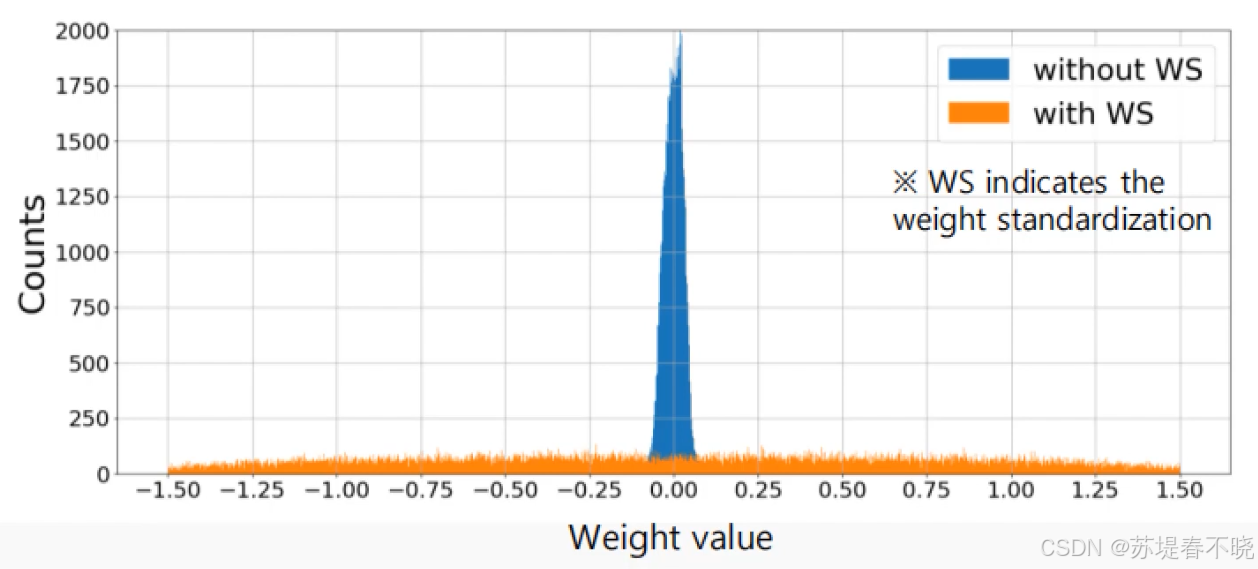
ASPP 之前卷积做了一个标准化的操作(减均值,除以方差)
对卷积做了标准化的操作

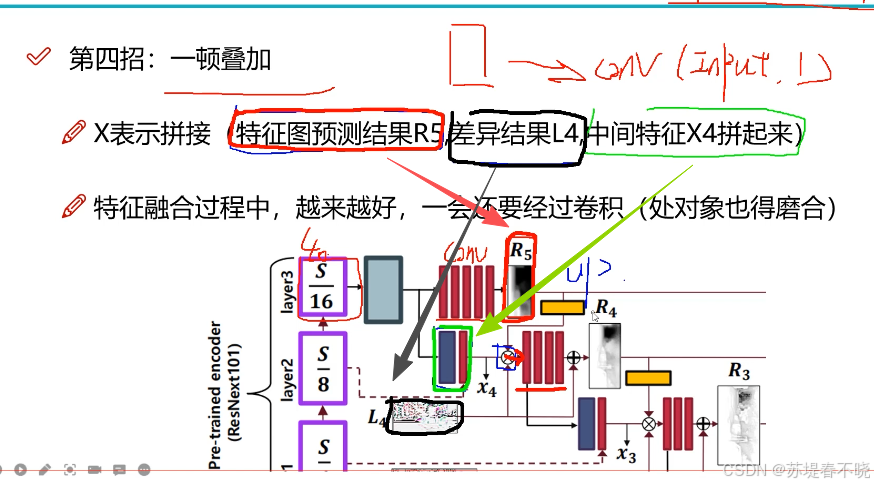
能用尽用,R 的 channel 为 1,蓝色 252,红色 3,黄色 1,concat 在一起 256

coarse to fine 的过程,D 的 channel 为 1
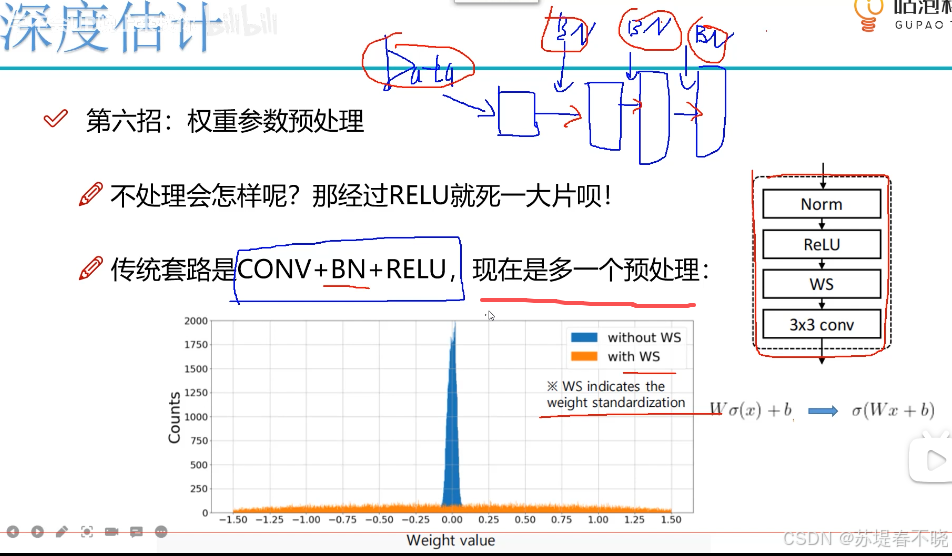
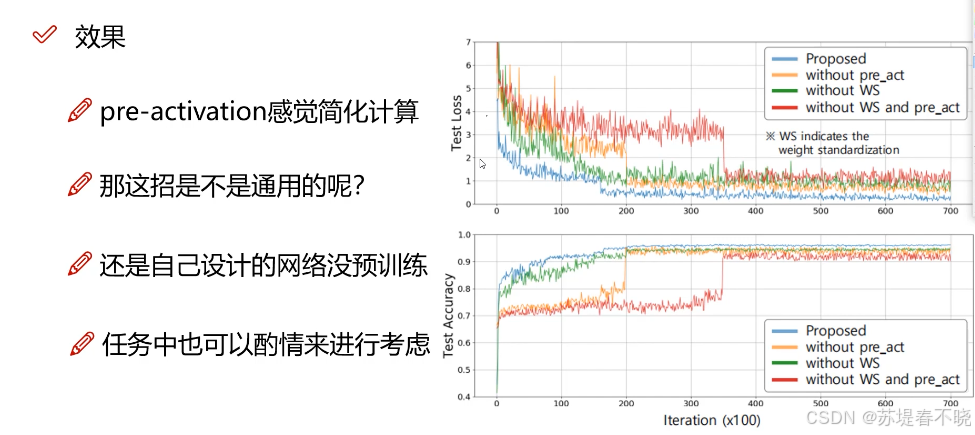
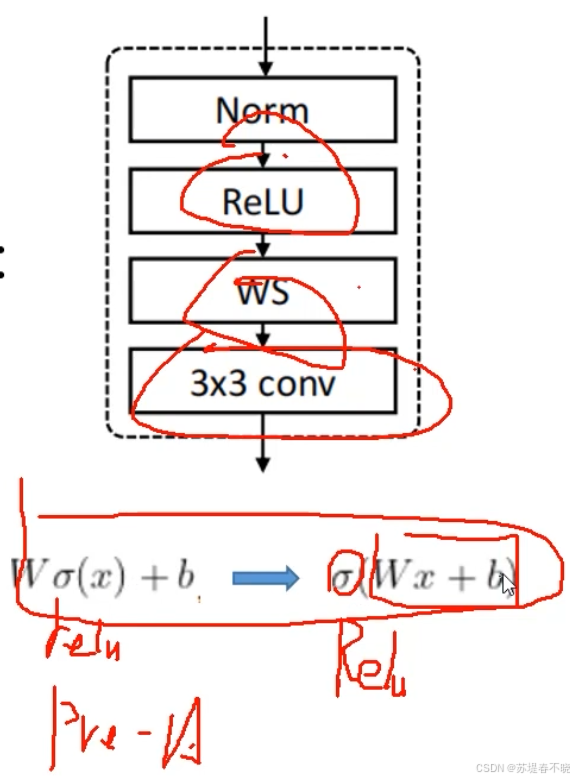
pre-activation 先 x 激活再 w 和 b

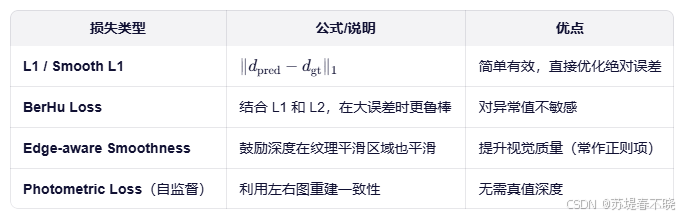
关于 D 的理解:要近都近,要远都远,有的地方比 GT 近,有的地方比 GT 远,不是好的预测
整个 loss,要求 predict 和 GT 越近越好,同时,predict 和 GT 的误差尽可能的同符号
公式化表达如下:scale invariant loss

公式2 表达的意思,两个点深度的变化应该和对应 GT 的变化保持一致
在单目深度估计中,由于缺乏绝对尺度(scale ambiguity),模型可能输出一个整体缩放后的深度图,但形状仍然正确

双目已有几何约束,不需要尺度模糊,引入尺度不变性反而违背了双目系统的物理基础
双目深度估计更合适的损失函数