
随着机器学习即服务(MLaaS)和云原生AI平台的普及,越来越多的企业将AI模型部署在公有云、混合云环境中。这种转变降低了基础设施门槛,但也使模型本身成为攻击者的直接目标。与传统软件不同,AI模型包含可提取的知识资产、依赖特定数据分布,且其行为具有非确定性特征,这使得传统云安全控制措施难以完全覆盖其风险暴露面。
本文将探讨AI模型在云环境下面临的独特安全挑战,并从全生命周期视角分析可行的安全管理策略,涵盖开发、部署、运维和治理环节的技术实践与组织流程。
AI模型在云环境下的核心安全风险
1. 模型资产暴露面扩大
云部署意味着模型文件(如TensorFlow SavedModel、PyTorch .pt文件)需要存储在对象存储、容器镜像仓库或模型注册表中。这些二进制文件包含大量训练数据的知识蒸馏,攻击者可通过API接口、存储桶配置错误或供应链污染直接获取模型副本。研究表明,即使只获得模型推理API的访问权限,通过查询攻击(Query Attack)仍可高效提取模型架构和参数。
2. 数据流复杂度增加
云AI工作流涉及多阶段数据转换:原始数据存储、预处理流水线、特征工程、训练集版本管理。每个环节都可能引入投毒风险。例如,在共享存储桶中,恶意租户可能通过未正确隔离的权限篡改公共数据集;在Serverless预处理函数中,注入恶意代码可持久污染特征空间。
3. 多租户隔离挑战
在Kubernetes等容器化环境中,模型服务通常以Pod形式运行。若未配置适当的资源隔离(如GPU时间片隔离、内存隔离),攻击者可通过侧信道攻击(如Flush+Reload)窃取其他租户模型的权重信息。此外,共享GPU集群中的NCCL通信库漏洞可能导致跨容器模型参数泄露。
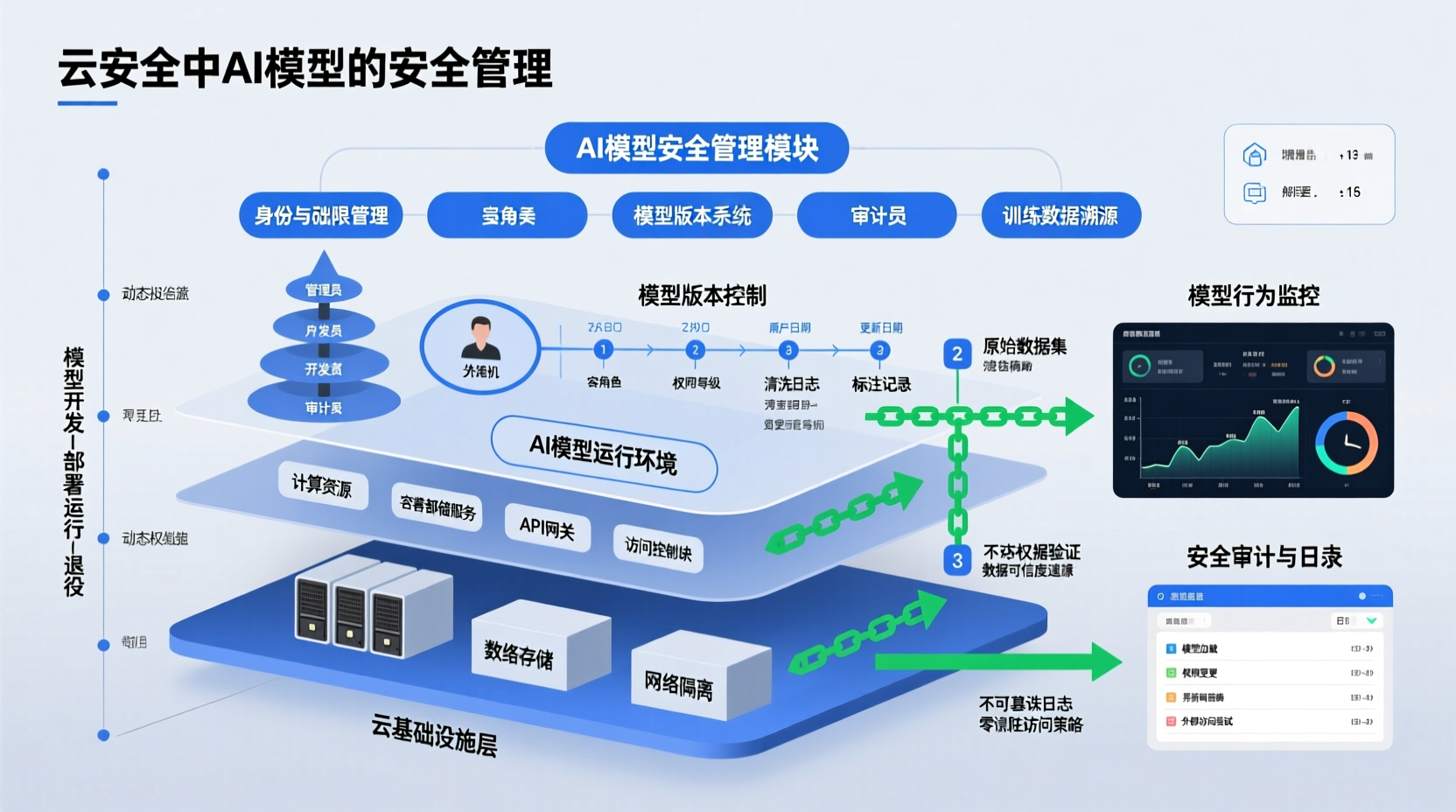
全生命周期安全管理框架
开发阶段:安全左移
训练数据治理
在数据摄取阶段应实施来源验证与完整性检查。技术上可采用:
- 数据溯源(Data Provenance):使用MLflow或DVC记录数据集版本、哈希值和创建者身份,确保训练数据可审计
- 异常检测:对数据分布进行统计监控,识别潜在的投毒样本。孤立森林(Isolation Forest)或基于自编码器的重构误差检测可标记偏离正常分布的注入数据
- 差分隐私预处理:在数据标注和清洗环节引入噪声机制,降低成员推断攻击(Membership Inference Attack)的成功率
模型训练环境隔离
建议在独立虚拟网络中执行训练任务,通过安全组限制仅允许特定CI/CD Runner访问训练数据存储。容器镜像应采用最小化基础镜像(如distroless),并通过Trivy等工具扫描依赖库漏洞。对于多团队协作场景,可使用Kubeflow的Profile机制实现命名空间级资源隔离。
部署阶段:纵深防御
模型制品安全
模型文件在推送至云存储前应进行加密处理。实践中可采用:
- 对称加密:使用KMS管理的密钥对模型权重进行AES-256加密,解密仅在推理容器内存中完成
- 模型混淆:通过权重剪枝、结构重排或插入冗余计算图增加逆向工程难度。需注意这会带来5-15%的推理延迟开销
- 数字签名:使用Sigstore对模型制品签名,部署时验证签名防止供应链篡改
服务访问控制
云AI网关应实现:
- 配额与限流:基于令牌桶算法限制API调用频率,防止模型窃取攻击中的高频查询
- 身份认证:采用OAuth 2.0 + JWT方案,结合OPA(Open Policy Agent)实现细粒度策略控制。例如,限制特定用户组仅在特定VPC端点访问模型服务
- 输入 sanitization:在网关层部署对抗样本检测模块,使用MagNet或Feature Squeezing等技术过滤恶意输入
运行阶段:持续监控
运行时行为分析
部署后需监控模型的实际行为偏差:
- 预测分布漂移:通过Prometheus采集推理日志,计算预测标签分布的KL散度。若发现异常偏移(如某类别预测概率突增),可能表明遭遇投毒或概念漂移
- 查询模式分析:使用流处理引擎(如Apache Flink)分析请求IP、频率和输入特征,识别自动化攻击行为。例如,同一IP在短时间内发送数千条结构化查询,可能是模型提取攻击
- 资源监控:通过cAdvisor监控容器异常资源使用,GPU内存的异常峰值可能提示侧信道攻击
响应与缓解
检测到攻击后应触发自动化响应:
- 模型回滚:通过ArgoCD或Flux实现GitOps驱动的模型版本快速回滚
- 动态水印:在输出中注入不可见指纹,便于追踪泄露模型来源。研究表明,在模型logits层添加扰动可在不影响准确率的前提下实现90%以上的溯源准确率
关键技术实践深度解析
机密计算(Confidential Computing)
基于硬件的可信执行环境(TEE)为模型保护提供底层保障。例如:
- AMD SEV-SNP:可在加密内存中运行模型推理,防止云管理员或恶意宿主机访问模型明文
- NVIDIA Confidential Computing:A100/H100 GPU支持机密虚拟机,实现端到端的加密推理流水线
实施时需权衡性能损耗(通常5-20%)和生态成熟度。目前主流框架如TensorFlow Serving已支持在TEE中加载加密模型。
联邦学习与隐私增强
在跨云数据协作场景中,联邦学习可避免原始数据移动。但需配合:
- 安全聚合:使用同态加密或秘密共享确保参数聚合过程不泄露个体模型更新
- 差分隐私训练:在本地训练时添加噪声,防止从全局模型反推参与方数据
供应链安全
AI模型依赖复杂的软件供应链:
yaml
# 示例:模型供应链SBOM片段
dependencies:
- name: transformers
version: 4.21.0
vulnerabilities: [CVE-2022-xxx]
- name: onnxruntime
version: 1.12.0
provenance: "sha256:abc123..."应使用SLSA框架验证供应链完整性,并通过模型卡(Model Card)记录训练配置、性能指标和已知限制。
治理与合规考量
责任共担模型
云服务商负责底层基础设施安全,而模型安全由客户承担。需明确:
- 谁有权访问模型注册表?
- 模型版本升级的安全审批流程如何?
- 发生泄露时的应急响应SLA?
审计与可追溯性
所有模型操作应记录不可篡改日志。可使用:
- 云审计日志:AWS CloudTrail、Azure Activity Log记录API调用
- 模型溯源图:使用Neo4j等图数据库存储模型、数据、代码、人员之间的关系,支持影响分析
合规映射
不同行业对AI模型有不同要求:
- GDPR:需防范成员推断攻击,避免模型记忆个人数据
- ISO 42001:要求建立AI管理体系,包括风险评估和控制措施
- NIST AI RMF:提供识别、保护、检测、响应、恢复五阶段治理框架
总结
云环境中AI模型的安全管理需要从"以代码为中心"转向"以模型和数据为中心"的防护范式。核心在于将安全控制嵌入模型全生命周期:开发阶段通过数据治理和训练隔离降低内生风险,部署阶段采用加密、访问控制和输入过滤构建纵深防御,运行阶段依靠持续监控实现快速响应。
技术选型上,机密计算为敏感模型提供硬件级保障,而治理流程确保组织层面的责任落实。值得注意的是,安全措施需与业务价值平衡------过度保护可能影响模型迭代效率。建议从关键业务模型入手,逐步建立可复用的安全基线和自动化工具链。
随着AI监管趋严和攻击手段演进,模型安全将从可选增强转变为合规刚需。企业应提前布局相关能力,避免技术债积累。未来方向包括自动化红蓝对抗测试、基于形式化验证的模型鲁棒性证明,以及跨云的联邦安全治理协议,这些都将进一步推动云AI安全走向成熟。