人类利用有限的注意力资源从大量信息中快速筛选出高价值信息的手段,是人类在长期进化中形成的一种生存机制,人类视觉注意力机制极大地提高了视觉信息处理的效率与准确性。
深度学习中的注意力机制从本质上讲和人类的选择性视觉注意力机制类似,核心目标也是从众多信息中选择出对当前任务目标更关键的信息。
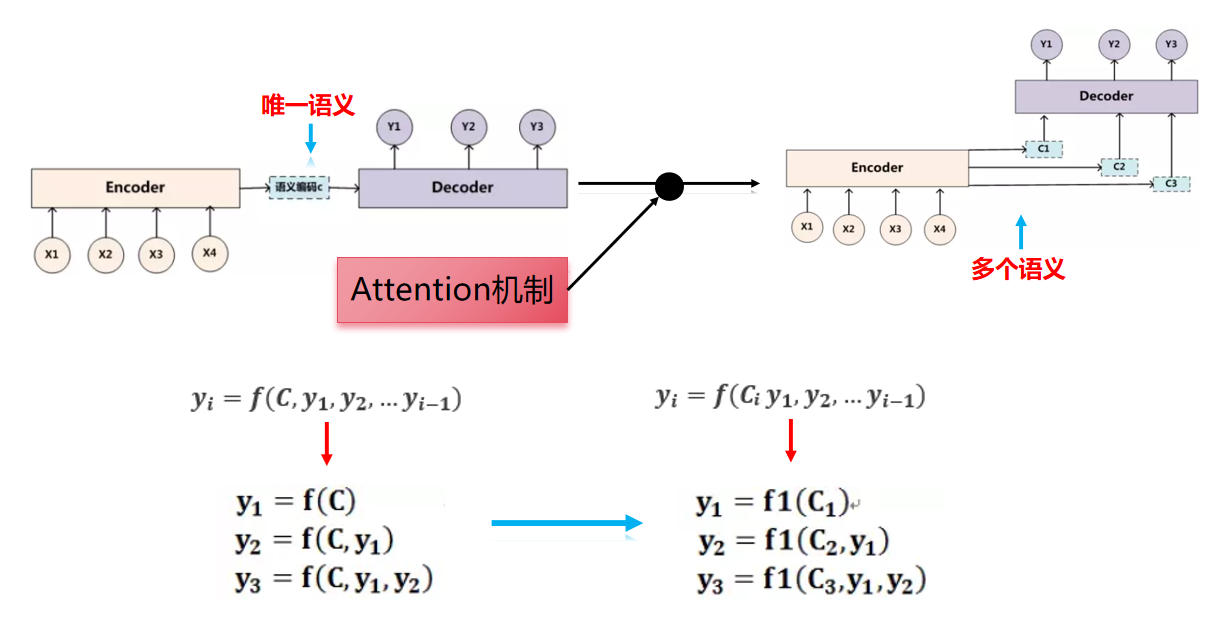
传统的解码编码模型:
对于解码器Decoder来说,其任务是根据句子Source的中间语义表示C和之前已经生成的历史信息y_1,y_2,...y_i−1,来逐个生成i时刻要生成的单词

但是这种方式存在一些问题:无论翻译哪一个目标单词,所使用的输入句子Source的语音编码C都是一样的没有任何的区别。即:无法聚焦关键信息,长序列时易丢失细节

Attention机制
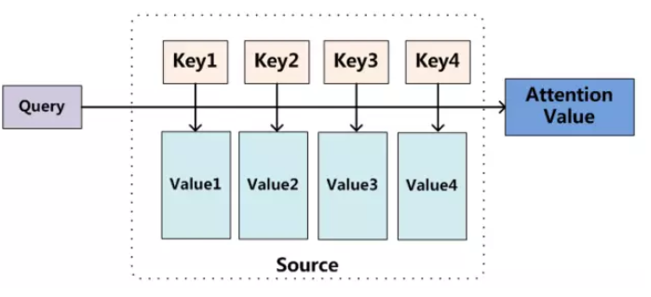
注意力机制(Attention Mechanism)是深度学习中模拟人类注意力选择性聚焦的核心技术,它让模型在处理数据时,能够自动分配不同的权重,重点关注和任务相关的关键信息,弱化无关冗余内容。
当我们阅读一句话时,不会平均分配注意力,比如看到 "猫追着老鼠跑",会自然聚焦 "猫""老鼠""追" 这些核心词,而非 "着""跑" 这类辅助成分;看一张照片时,会优先关注主体(比如画面里的人),而非背景的花草。
注意力机制就是让模型复刻这个过程:
- 计算注意力权重:衡量输入数据中每个部分和当前任务的 "相关性",权重越高,代表越重要;
- 加权求和:用注意力权重对输入特征进行加权,突出关键信息,抑制无用信息;
- 输出聚焦后的特征:作为后续任务的输入。
经典范式
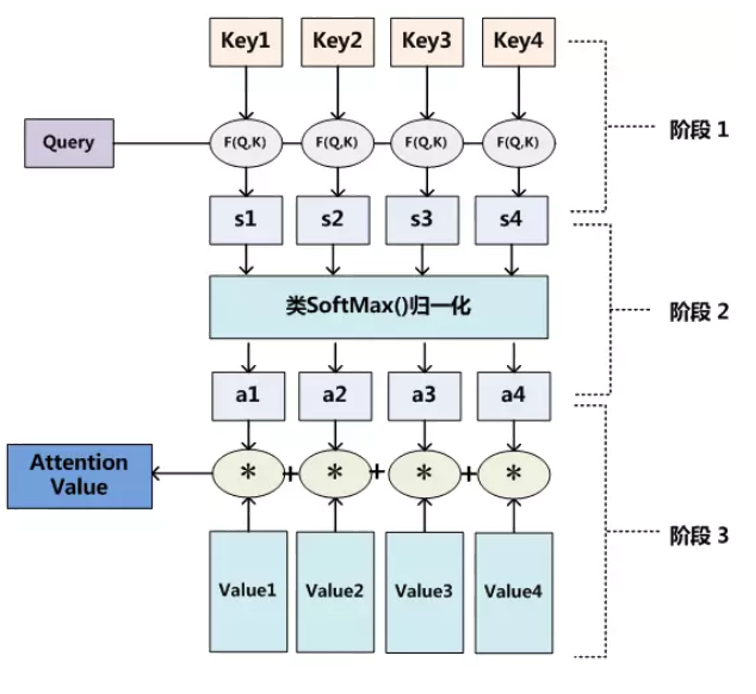
这是 Transformer 架构的核心注意力模块,也是目前最常用的注意力计算方式,公式如下:Attention(Q,K,V)=softmax(dkQKT)V其中三个核心概念可以用 "检索" 场景类比:
- Query(查询向量):当前任务的 "需求",比如翻译时的目标词特征;
- Key(键向量):输入数据的 "索引",比如翻译时的源词特征;
- Value(值向量):输入数据的 "内容",和 Key 一一对应,是最终要加权的特征。
计算步骤拆解:
- 计算 Query 和所有 Key 的相似度(点积),得到 "相关性分数";
- 除以dk(dk是 Key 的维度),避免维度过高导致分数过大,影响 softmax 效果;
- 用 softmax 把分数转化为0~1 之间的注意力权重,权重之和为 1;
- 用权重对 Value 加权求和,得到聚焦后的特征。
刚才的例子: Key(键):每个单词的 "特征向量" Value:每个单词的 "词义" Query(查询):想查的 "目标单词特征"
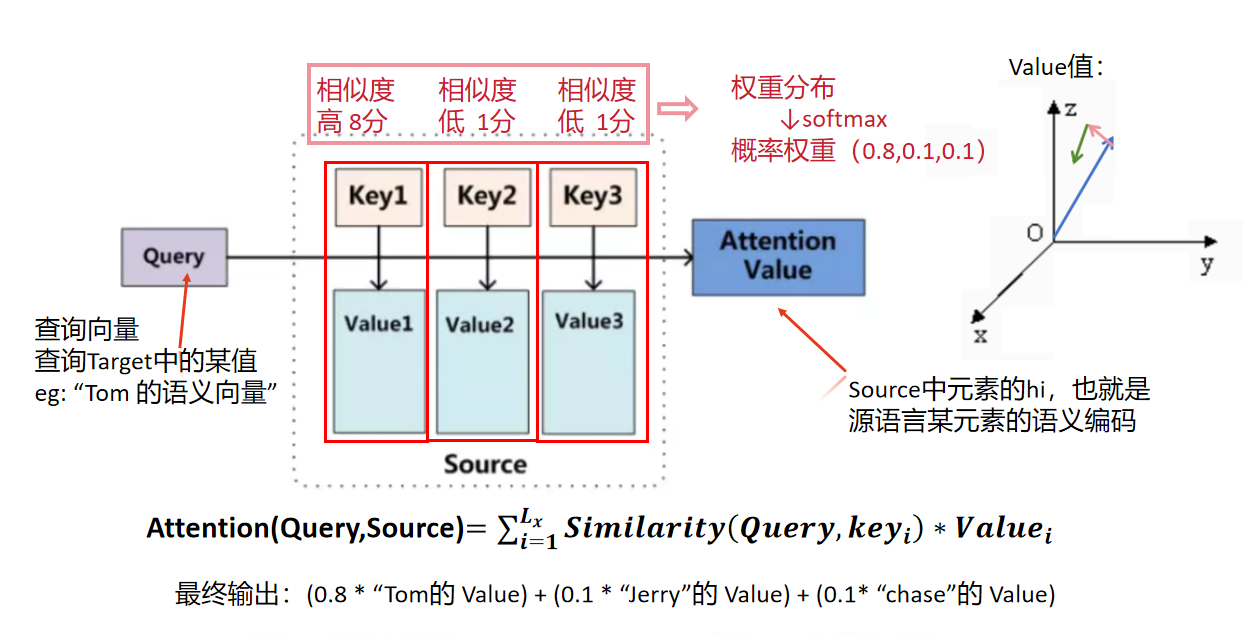
具体过程
不管哪种注意力,都离不开三个关键向量,可类比成 "检索" 场景:
- Query(查询向量) :代表当前任务的需求。比如机器翻译中,要翻译目标句的第 3 个词,这个词的特征就是 Query;图像分类中,"识别动物" 这个任务的特征就是 Query。
- Key(键向量) :代表输入数据的索引。比如翻译时的源语言单词特征、图像里每个像素块的特征,用来和 Query 匹配 "相关性"。
- Value(值向量) :代表输入数据的实际内容。是最终要被加权的对象,和 Key 一一对应,Key 负责算权重,Value 负责提供有用信息。
注:这三个向量不是凭空来的,而是由原始输入通过三个可学习的线性变换矩阵 (WQ,WK,WV)生成的,即
1. 计算 Query 与 Key 的相似度(相关性分数)
用点积 计算 Query 和每个 Key 的匹配程度,分数越高,说明这个 Key 对应的输入越符合当前 Query 的需求。公式:相似度分数=这里的点积会把 Q(维度 dk)和 KT(维度 dk)相乘,得到一个相似度矩阵,矩阵里的每个元素,就是一个 Query 和一个 Key 的匹配度。
2. 缩放 + Softmax,生成注意力权重
-
缩放:除以 dk(dk是 Key 的维度)。原因是当 dk 很大时,点积结果会很大,导致 Softmax 输出趋近于 0 或 1,梯度消失。缩放能让分数分布更合理。
-
Softmax 归一化 :把缩放后的分数转化为 0~1 之间的权重,且所有权重之和为 1。权重越高,对应 Value 的重要性越强。
-
3.加权求和,输出聚焦特征
用注意力权重矩阵,对 Value 向量做加权求和 ------ 权重高的 Value 会被重点保留,权重低的 Value 会被弱化。最终得到的就是聚焦关键信息后的特征。
通俗类比:注意力的工作像 "找钥匙开门"
你的需求(Query):"我要开卧室门";
家里的钥匙(Key):卧室钥匙、客厅钥匙、厨房钥匙,每个钥匙都有 "标签"(特征);
钥匙对应的门(Value):卧室门、客厅门、厨房门;
计算相似度:你的需求和卧室钥匙的标签最匹配,给它打 90 分,其他钥匙打 10 分;
归一化权重:卧室钥匙权重 0.9,其他 0.1;
加权选门:重点选卧室门(Value),成功开门 ------ 这就是注意力机制的聚焦效果。
自注意力机制(Self attention)
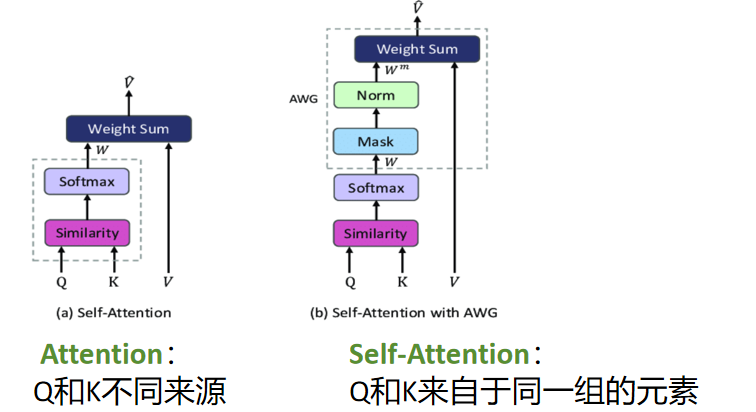
自注意力机制是注意力机制变体,Q、K、V 同源,均来自输入 X。它挖掘 X 内部元素关联,通过计算相似度生成权重,聚焦关键信息。无需外部序列,直接捕捉输入内部相关性,可并行计算长距离依赖,是 Transformer 核心,为序列数据提供高效全局建模能力。
自注意力和注意力机制的区别:
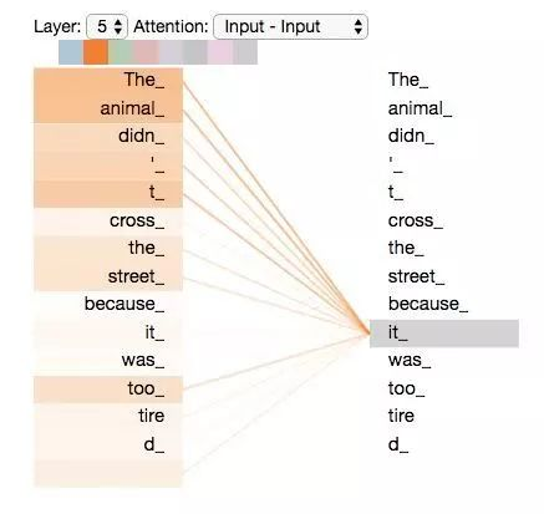
从宏观视角看自注意力机制:
这是 Transformer 模型注意力机制的可视化展示,以句子 "The animal didn't cross the street because it was too tired" 为示例,右侧聚焦代词 "it_" ,左侧多个单词(如 "The_""animal_" 等 )通过线条指向它,线条体现注意力权重,直观呈现模型如何识别 "it_" 与其他单词(尤其是 "animal_" )的指代关联。
自注意力(Self - Attention)是注意力机制的一种关键形式,在自然语言处理等领域广泛应用,核心要点如下:
核心概念
- 输入关联 :自注意力中,Query(查询)、Key(键)、Value(值)都来自同一组输入数据 。比如处理句子时,每个词都会生成对应的 Q、K、V,用于挖掘词与词之间的关联。
- 内部依赖捕捉:通过计算输入内部元素间的注意力权重,捕捉数据自身的长距离依赖关系,像文本里代词与前文名词的指代关联,突破传统模型(如 RNN)串行处理的限制,并行计算提升效率。
计算流程
自注意力的具体计算流程可拆解为以下步骤,基于公式展开:
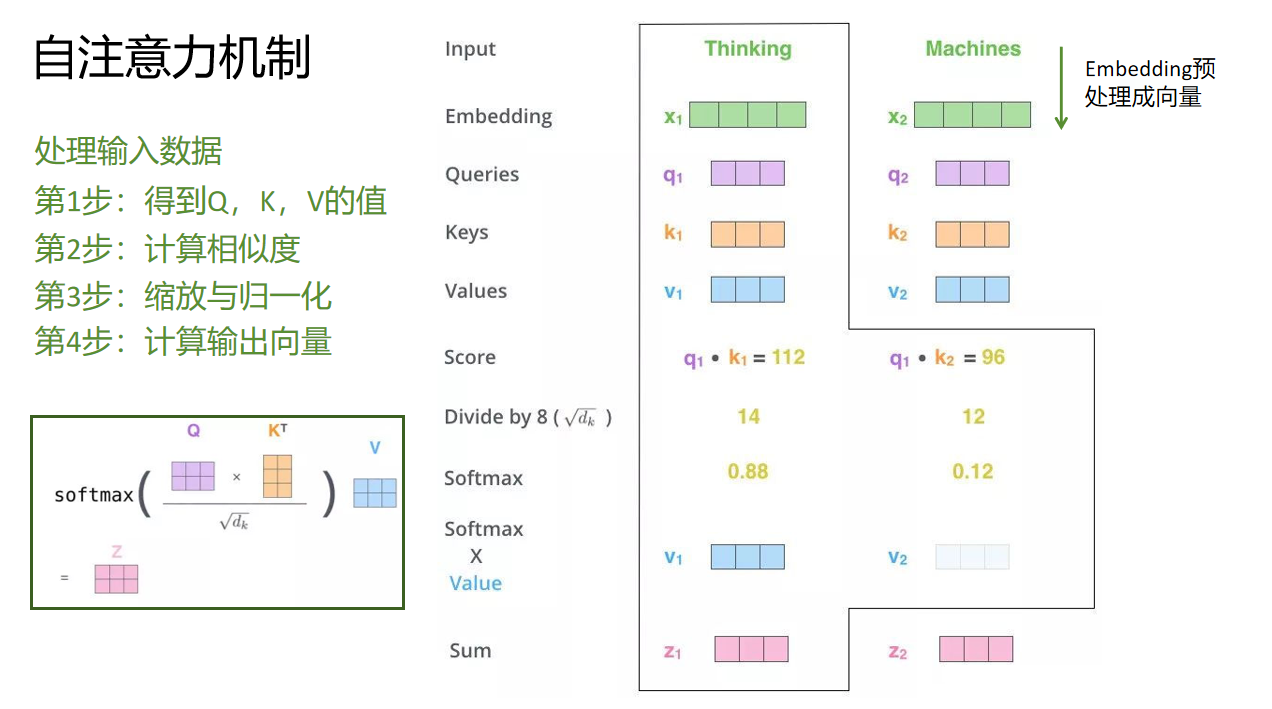
1. 输入与线性变换
输入:给定一组输入数据(如文本的词向量序列、图像的特征图序列等 ),记为 X,其维度通常为 序列长度,特征维度 ,可表示为 X=x1,x2,...,xn ,其中 xi 是第 i 个输入元素的特征向量。
生成 Q、K、V :通过 3 个可学习的线性变换矩阵 WQ、WK、WV ,对输入 X 做线性变换,得到 Query(查询)、Key(键)、Value(值)矩阵:变换后,Q、K、V 维度均为 序列长度,dk(dk 是变换后的维度,通常远小于原始输入特征维度,用于控制计算复杂度 )。
2. 计算注意力分数(关联度)
点积计算:将 Q 与 K 的转置 KT 做矩阵点积,得到注意力分数矩阵 Score ,公式为:Score=QKT矩阵点积的结果中,Scorei,j 表示第 i 个 Query 与第 j 个 Key 的关联程度(相似度 )。
缩放操作:为避免点积结果因维度 dk 过大导致 Softmax 函数梯度消失或数值不稳定,对注意力分数矩阵做缩放,除以 dk :Scaled_Score=dkScore
3. 注意力权重归一化
Softmax 归一化 :对缩放后的注意力分数矩阵 Scaled_Score 按行做 Softmax 函数处理,将每行分数转化为 0,1 区间的概率分布,且每行概率和为 1 ,得到注意力权重矩阵 Attention_Weights :其中,Attention_Weightsi,j 表示第 i 个输入元素对第 j 个输入元素的注意力权重(即第 j 个元素对第 i 个元素的重要程度 )。
4. 加权求和输出
特征融合:用注意力权重矩阵 Attention_Weights 对 V 矩阵做加权求和,得到自注意力的输出 Output :Output=Attention_WeightsV输出矩阵中,Outputi,: 是第 i 个输入元素经自注意力处理后的新特征,融合了所有输入元素与该元素的关联信息(权重高的元素特征被重点保留 )。
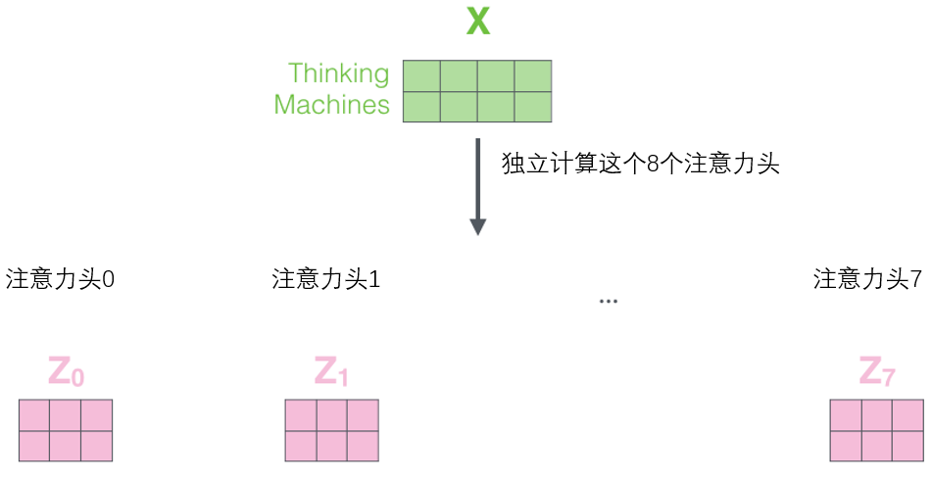
多头注意力机制
多头注意力机制(Multi-Head Attention)是自注意力机制的扩展,核心是通过并行的多个注意力 "头",让模型同时捕捉输入数据中不同维度、不同类型的关联信息,提升特征表达的丰富性。
多头注意力机制的核心思想是"分而治之"。它不是只进行一次注意力计算,而是将输入的查询、键和值分别线性到不同的子空间中,然后并行地进行多次注意力计算。
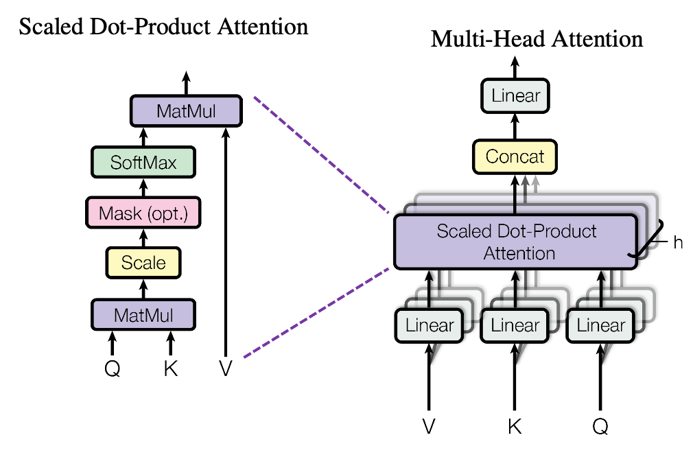
多头注意力机制(Multi-Head Attention)是 Transformer 架构的核心组件,其本质是通过多个并行的注意力头捕捉输入序列中不同维度、不同范围的依赖关系,最终融合这些头的输出得到更全面的特征表示。
它的具体步骤可以分为 5 个核心环节,以下结合数学公式和直观解释展开说明:
1. 输入准备与线性投影
多头注意力的输入是三个向量:查询向量(Query, Q)、键向量(Key, K)、值向量(Value, V)。在 Transformer 中,这三个向量通常来自同一输入序列(自注意力),或来自不同序列(交叉注意力,如编码器 - 解码器注意力)。
-
输入原始向量:假设输入序列的维度为
。
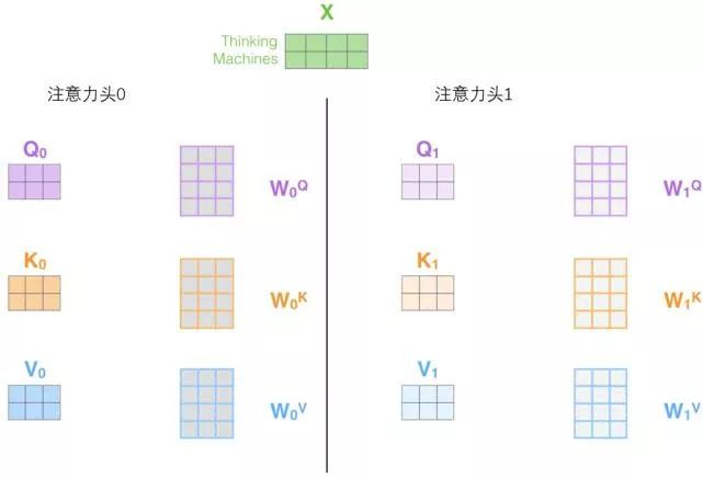
-
线性投影:为了生成多个注意力头,需要对 Q,K,V 分别做 h 次独立的线性变换(h 为注意力头的数量,Transformer 中默认 h=8)。每个头对应的投影权重矩阵为
第 i 个头的投影计算:
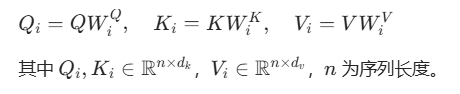
2. 计算注意力分数(缩放点积注意力)
每个注意力头独立计算 缩放点积注意力,这一步的目的是衡量 Qi 与 Ki 之间的相似度,进而为 Vi 分配权重。
- 点积计算相似度:将 Qi 和 Ki 的转置矩阵相乘,得到原始注意力分数矩阵 Si:Si=QiKiT矩阵维度:Si∈Rn×n,其中 Sijk 表示第 j 个查询向量与第 k 个键向量的相似度。
- 缩放操作 :当 dk 较大时,点积结果会偏大,导致 Softmax 函数输出趋于极端(梯度消失)。因此需要除以
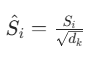
- 掩码处理(可选) :在解码器的自注意力 中,需要防止模型看到未来的 token,因此会对 S^i 施加一个掩码矩阵(Mask)------ 将未来位置的分数设为 −∞,经过 Softmax 后这些位置的权重会变为 0。
- Softmax 归一化:对缩放后的分数矩阵进行 Softmax 运算,得到归一化的注意力权重矩阵 Ai:Ai=Softmax(S^i)矩阵中每行的元素之和为 1,代表当前查询对所有键的注意力分配比例。
3. 计算注意力输出
将注意力权重矩阵 Ai 与值向量 Vi 相乘,得到第 i 个头的注意力输出 Oi:
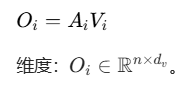
这一步的本质是加权求和 ------ 对值向量按照注意力权重进行加权,突出重要信息,弱化无关信息。
4. 多头输出拼接
将 h 个注意力头的输出 O1,O2,...,Oh 按列维度拼接(Concatenate),得到一个维度更大的矩阵 Oconcat:
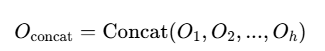
维度变化:每个 Oi 的维度是 n×dv,拼接后 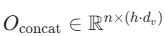 。由于 h⋅dv=dmodel,拼接后的维度会还原为输入的 dmodel。
。由于 h⋅dv=dmodel,拼接后的维度会还原为输入的 dmodel。
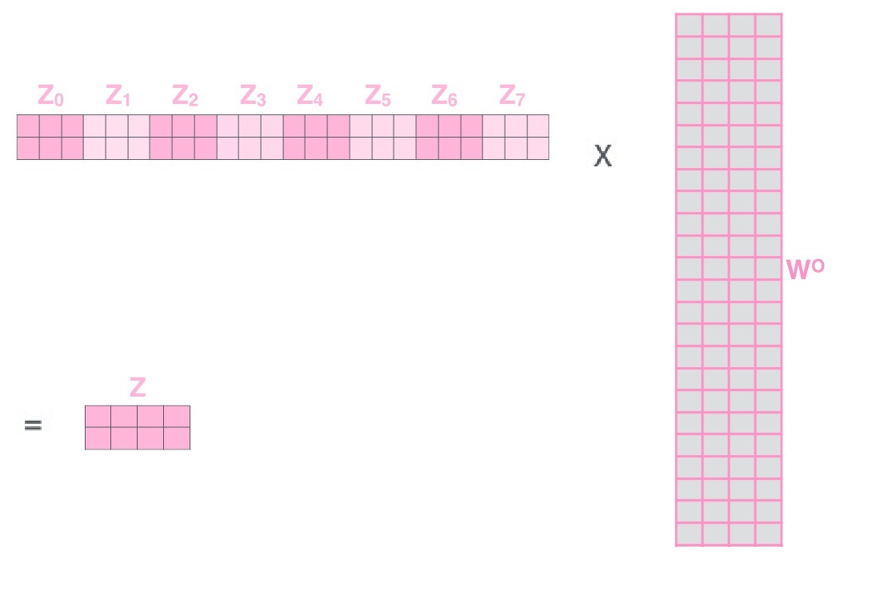
5. 最终线性变换
对拼接后的矩阵进行一次全局线性变换,将其映射到最终的输出维度,得到多头注意力的最终结果:
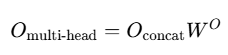
其中 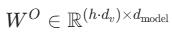 是可学习的权重矩阵,最终输出
是可学习的权重矩阵,最终输出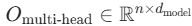 。
。