在做过 Elasticsearch 中文搜索研发的同学中,IK 分词器几乎是标配。它简单、高效,覆盖了大多数中文业务场景,被广泛用于电商、资讯、社区等搜索系统。然而,在一些业务场景中,IK 分词器可能会带来意想不到的线上事故,尤其是在大促、热词高峰等对搜索稳定性要求极高的时期。本文将通过一个真实事故的复盘,解析开源 IK 分词器架构设计中的不足,并介绍阿里云 ES Serverless 如何通过"索引级词典"能力,彻底解决热更新引发的搜索错配问题。
一、事故复盘:一次常规操作,引发 P0 事故
背景
某电商平台大促前夕,运营发现网络热梗 "哈基米"(指代猫咪/宠物)的搜索量飙升。由于 IK 默认词典中没有该词,查询时会被切分为 哈, 基, 米 ------导致召回了大量无关商品,转化极低。运营立即提出需求:必须让"哈基米"精确匹配相关商品。
操作过程
"标准"的变更:
-
在已有词典中新增词组"哈基米",并触发了集群所有节点的热更新。
-
_analyze 接口验证通过:哈基米 已被正确识别为一个完整 Term。
事故发生
然而,就在词典热更新完成的那一瞬间,线上的实时搜索崩了
-
新数据(正常): 刚刚上架的"哈基米"商品能搜到。
-
旧数据(消失):之前写入的所有包含"哈基米"描述的存量商品,全部搜不到了!
原因却扑朔迷离------没有改动索引,却瞬间导致存量数据全部失效。
**结果:**本来想提升用户体验,结果搜索挂了,GMV 跌了,一次常规优化演变成了 P0 级线上事故。

二、深度解析:IK词典热更新的"时空错乱"
为什么会这样?这并非 ES 的 Bug,而是 开源 IK 插件的设计机制 与 倒排索引特性 之间的一次正面碰撞。
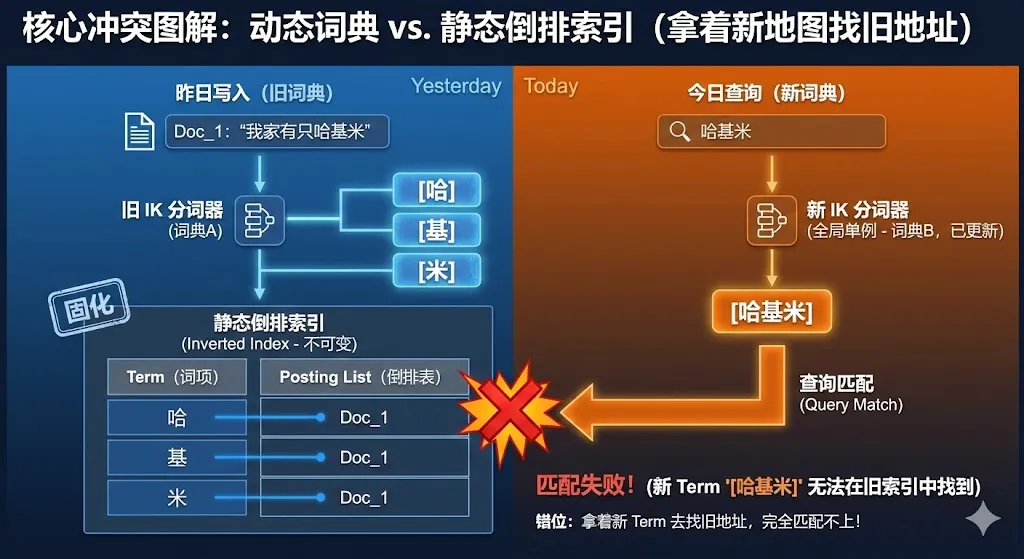
核心冲突:动态词典 vs 静态索引
- IK 插件的"全局单例"机制(The Global Singleton):
IK 分词器采用全局共享词典的实现策略。这意味着,一旦触发热更新,整个集群上所有使用 IK 的索引(无论新旧)都会立即、强制使用新词典进行查询分词。这是一个"牵一发而动全身"的操作。
- ES 索引的"不可变"特性(The Immutable Index):
当写入文档时,其字段内容经过分词后,生成的 Term 被写入倒排索引。数据一旦写入,生成的倒排索引(Term)就被"固化"了。
这就是冲突的根源: 你为了"未来"的数据(新热词)更新了全局词典,却无意中破坏了"过去"数据的查询匹配逻辑。
错位图解:拿着新地图找旧地址
让我们清晰地梳理下事故发生的过程:
-
热更新前(旧词典): "哈基米"被切分为 哈, 基, 米 三个单字存入倒排索引。
-
热更新后(新词典): 当"哈基米"被加入到词典后,搜索词"哈基米"被解析为整体 Term 哈基米。
结果:
拿着新 Term 哈基米 去找旧索引里的单字 哈、基、米 完全匹配不上!这就像是"时空错乱":你拿着今天的新地图(新词典),去导航昨天的旧城市(旧索引),路早就变了,当然找不到目的地。
三、传统解法:三种"续命"方案
在搜索系统里,词典版本错配是一类高频且棘手的问题:
-
一旦新词典上线,而索引里的数据仍是按旧分词规则建立,搜索便可能非预期的异常。
-
对用户而言,表现是老数据匹配结果异常,之前可以搜索到的数据全部"消失"了。
-
对运维而言,要保证 新词典配置 与 索引数据分词结果 同步,需要在"性能、体验、成本"之间做艰难平衡。
为缓解这一问题,业内常用三种方案来给业务"续命"------即在不彻底停机的情况下,尽量让新词生效并维持线上查询稳定。
三种常用方案详情如下:
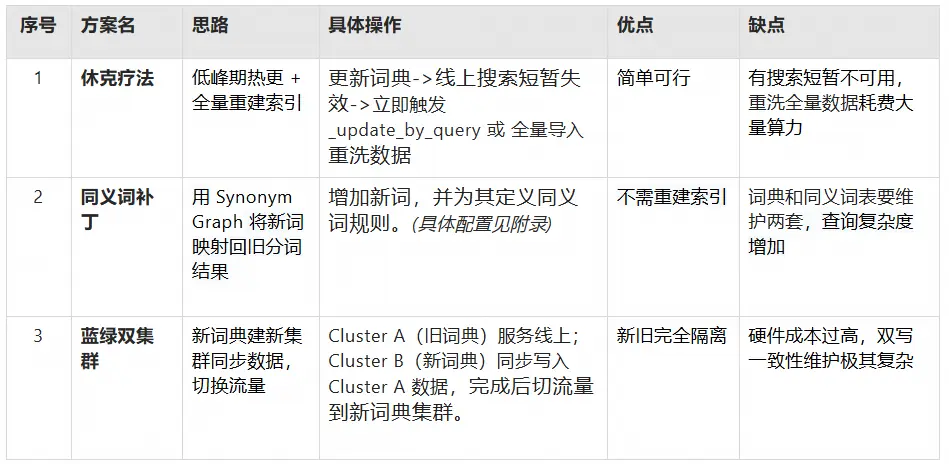
然而,这些方案无一能够同时做到:
-
无感热更新:让用户完全察觉不到后台切换过程
-
精准匹配新词:新热词即刻命中,不受旧分词影响
-
不影响存量数据搜索:老数据搜索结果保持稳定无偏差
正因为如此,我们需要寻找一种既能让词典版本与数据版本完美对齐,又不会牺牲线上可用性的全新解法。
四、阿里云 ES Serverless 破局:索引级词典隔离
所以,为了解决开源 IK 插件的"全局单例"词典机制导致的冲突,阿里云 ES Serverless 通过在内核层面的改造,推出 "集群-索引-分词器"三级词典配置体系:
多级词典体系设计
该体系将词典的控制权从"集群/节点级"下放,允许在不同层级进行精细化配置,并遵循明确的优先级规则:分词器级别 > 索引级别 > 集群(租户)级别。
-
集群级(Cluster-level):由管控平台统一下发基础词典,保障全集群(租户)基础词汇一致性,优先级最低。
-
索引级(Index-level):为每个索引绑定专属扩展词典和停用词典,精准解决"时空错位"问题的关键。
-
分词器级(Analyzer-level):为索引内的某个自定义分词器配置专用词典,满足特定字段的特殊分词需求,优先级最高。
典型场景示例:对 实时新增热词 场景,"索引级别词典"能力提供了完美的解决方案,可为不同索引绑定不同版本,例如:
-
product_v1 → dict_v1
-
product_v2 → dict_v2
它们可在同一集群内互不干扰、并行存在,让新旧版本词典同时在线,彻底解决"新旧不兼容"的时空错乱问题。
热更新无感流程
以"哈基米"为例:
-
Step 1 隔离运行
-
product_v1(绑定别名product_alias) 仍用旧词典 dict_v1。
-
线上用户查询不受影响,存量数据照常匹配。
-
Step 2 构建新索引
-
新建 product_v2 并绑定含"哈基米"的 dict_v2。
-
用离线链路或 _reindex 将数据写入新索引。
-
建议:
对于大规模业务,建议直接复用 T+1 离线链路(如 DTS/ODPS/Flink),将数据重新灌入 product_v2。这是最标准、最高效的做法。
-
Step 3 原子切换流量
-
数据追平后,将product_v2 绑定到 product_alias ,同时下掉product_v1,实现流量的原子切换。
效果
通过这一套 多级词典 + 流量原子切换 的组合拳,我们实现了 词典版本与数据版本的完美对齐:
- 零中断:
更新全程用户无感,整个更新和切换过程对线上用户完全透明,没有服务中断或查询失败的窗口。
- 精准匹配:
流量切换后,新词即刻生效,新旧数据查询逻辑对齐,搜索"哈基米"立刻精准命中,且整个过程没有任何"查询断层"或"服务闪断"。
- 弹性支持:
结合 Serverless 的自动扩缩容,应对大促算力峰值。

额外优势:内核优化的隐性收益
除了索引级词典,Serverless 版本还具有以下优势:
-
避免词典脑裂:保证集群内节点词典统一。
-
无感升级:同步开源 IK 与原生 ES 新特性。这些能力让你的热词更新从一件"高风险运维操作",变成稳定、安全的日常操作。
五、附录
"休克疗法"更新指南
假设线上的索引是 product_v1。
a. 准备阶段:更新词典并验证词典是否生效
ⅰ. 更新 IK 远程词典,加入词组"哈基米"。
ⅱ. 等待词典加载完成,并测试新词组是否生效。
b. 执行阶段:索引数据更新
ⅰ. 选择业务低峰期(如凌晨),调用 _update_by_query API,对索引中全部数据进行更新。
ini
POST /product_v1/_update_by_query?refresh=true&conflicts=proceed
# 如果使用异步方式,可以通过以下命令查看任务状态
GET /_tasks?detailed=true&actions=*update_by_query*c. 验证阶段:验证分词是否生效
ⅰ. 待 _update_by_query 任务完成后,可以通过termvectors来查看实际索引的词。
bash
GET /product_v1/_termvectors/{id}传统方案"打补丁"实操指
为"哈基米"紧急上线同义词补丁
a. 准备阶段:在词典中新增"哈基米",定义带同义词的查询分词器
ⅰ. 通过 PUT /_settings API,加入 synonym_graph 过滤器和使用它的新分词器。
bash
PUT /product_v1/_settings
{
"analysis": {
"filter": {
"my_synonym_graph": {
"type": "synonym_graph",
"synonyms": [
// 核心规则:将新词映射回旧的切分结果
"哈基米, 哈 基 米"
]
}
},
"analyzer": {
"my_search_analyzer": {
"tokenizer": "ik_smart",
"filter": [ "my_synonym_graph" ]
}
}
}
}b. 应用阶段:将同义词规则应用到索引字段,并更新 Mapping
ⅰ. 最后,更新字段的 mapping,指定在查询时使用我们新定义的 my_search_analyzer。
json
PUT /product_v1/_mapping
{
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word", // 写入时保持原样,分词为[哈,基,米]
"search_analyzer": "my_search_analyzer" // 查询时应用同义词补丁
}
}
}c. 效果 :完成以上操作后,搜索"哈基米"就能匹配到包含 哈 基 米 的旧文档了。
Serverless 配置实操
前提 :已经在 Serverless 控制台上传词典,词典ID标识为 dict_v1 和 dict_v2
Step 1: 线上服务稳定运行
在创建索引 product_v``1 时,为其指定词典 dict_v1(如在创建索引时未指定词典,也可以通过PUT {index}/_settings REST API配置)
bash
PUT /product_v1
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1,
"ik.extra_dict_ids": "dict-v1"
},
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}
}
或
PUT /product_v1/_settings
{
"index":{
"ik.extra_dict_ids": "dict-v1"
}
}将别名 product_alias 指向索引 product_v1
bash
POST /_aliases
{
"actions": [
{ "add": { "index": "product_v1", "alias": "product_alias", "is_write_index": true } }
]
}批量写入数据
css
PUT product_alias/_bulk
{"index": {"_id": 1}}
{"content": "哈雷彗星"}
{"index": {"_id": 2}}
{"content": "基础版本人工智能"}
{"index": {"_id": 3}}
{"content": "米是一种食物"}
{"index": {"_id": 5}}
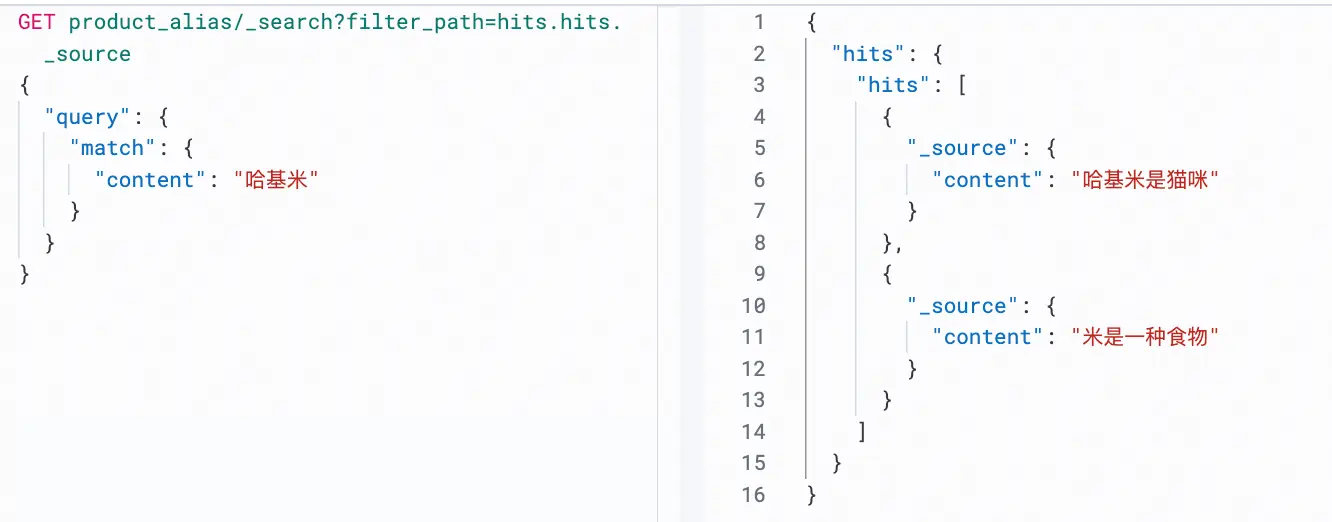
{"content": "哈基米是猫咪"}product_v1 将使用词典 dict_v1 运行。
bash
GET product_alias/_search
{
"query": {
"match": {
"content": "哈基米"
}
}
}
Step 2: 安全、无感的引入新词典
创建包含"哈基米"词组的新词典 dict_v2,新建索引 product_v2,并为其指定新词典
css
PUT product_v2
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1,
"ik.extra_dict_ids": "dict-v2"
},
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}
}通过 API _reindex 将 product_v1 索引中的数据更新到 product_v2 中。
json
POST _reindex
{
"source": {
"index": "product_v1"
},
"dest": {
"index": "product_v2"
}
}然后将别名 product_alias 指向索引 product_v2
bash
POST /_aliases
{
"actions": [
{ "remove": { "index": "product_v1", "alias": "product_alias" } },
{ "add": { "index": "product_v2", "alias": "product_alias", "is_write_index": true } }
]
}由于 products_v2 已经绑定了新词典,所有新写入的数据都会正确地将"哈基米"索引为一个完整的 Term。
此时查询结果如下:
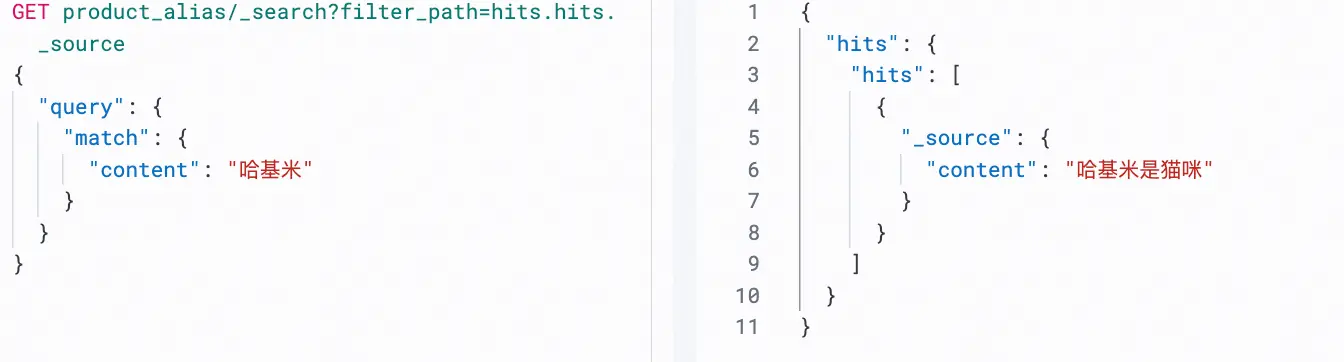
六、结尾
开源 IK 分词器的节点级全局词典机制,在动态热更新场景下,与 ES 的静态倒排索引天然冲突。传统解法要么牺牲业务连续性,要么增加运维成本。
阿里云 ES Serverless 通过 "索引级词典" 架构,彻底消除了这一冲突,实现:
-
新旧数据版本的无缝兼容
-
热更新过程的全程透明
-
集群资源的最大化利用
告别"配置地狱",回归业务价值!不再让一次简单的热词更新,变成线上事故。