
本文Demo:https://github.com/openvino-book/Milvus-Phrase-Match-Demo
今天还是来继续聊聊做企业级知识库,那些常见的避坑小技巧,这一次的主题是短语检索。
如果你做过搜索、日志分析、知识库、RAG,那么你一定被下面这几个场景折磨过:
-
明明日志里有 `connection reset by peer`,就是搜不到?
-
"北京 上海" 和 "上海 北京" 能不能算一个短语?
-
英文还好说,中文只要分词一错误,检索就直接废掉?
-
RAG 想加"必须包含某短语"的硬条件,向量模型却完全表达不了?
别慌! Milvus 2.6 的 Phrase Match 就是来解决这一切的。
Phrase Match = 倒排索引基础 + 严格词序 + 位置信息 + 灵活距离调节(slop) **,**不仅中英文通吃,更能让你的短语匹配精度直接拉满。
01
为什么你会马上爱上 Phrase Match?
我们先不上来讲原理, 而是从一个工程师每天都在遭遇的场景------错误日志检索------直接开始.
你有这样的日志:
perl
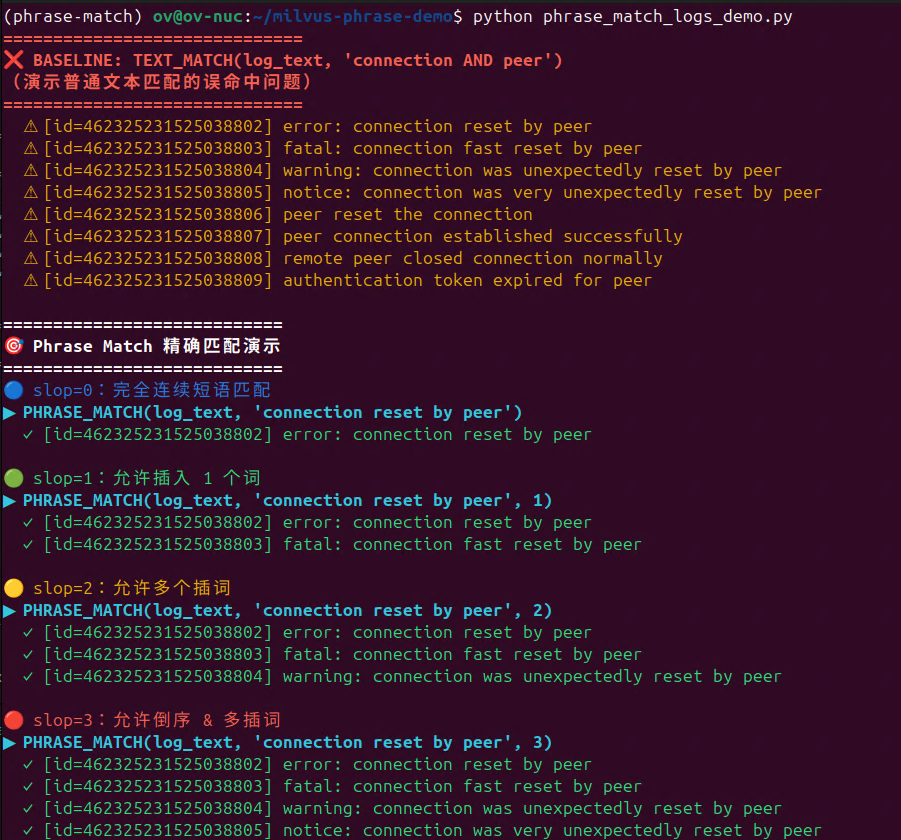
connection reset by peerconnection fast reset by peerconnection was suddenly reset by the peerpeer reset connection by ...peer unexpected connection reset happened当你想找 `"connection reset by peer"` 的所有变体时......
❌ BM25没有词序意识:只能找"connection", "peer",词序全乱
❌ 向量检索没有硬约束:知道意思,却无法要求"必须包含短语"
🤯 结果:要么漏,要么误报,要么顺序乱,你根本无法准确定位问题
而 `Phrase Match` 只需一个参数:slop,就能轻松弥足上述技术的不足, 把检索目标的变体全部抓出来。
-
slop=0:必须完全连续(严格匹配)
-
slop=1:允许插一个词(自然语言常见变体)
-
slop=2:允许插多个词
-
slop=3:允许倒序(自然语言最难搞的部分)
运行`phrase_match_logs_demo.py`我们来看实际效果:
02
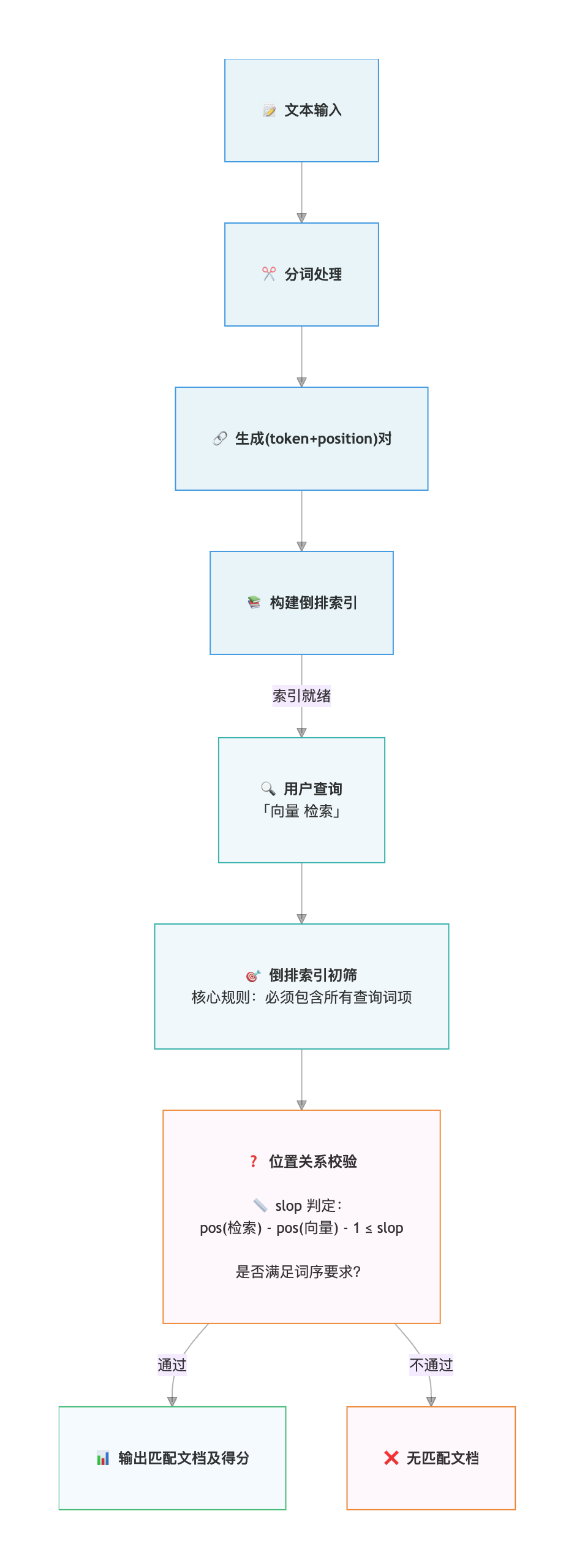
Phrase Match 是如何做到的?
Phrase Match 将传统 BM25「基于词频统计」的检索思路,演进为「短语结构感知」的精准匹配, 如下图所示:
03
中文 vs 英文 Phrase Match:实战小技巧
很多人觉得 Phrase Match 在中文"效果不好",其实在绝大多数情况下,是因为:
-
分词器没有设对(没用 `chinese` analyzer)
-
沿用英文的 slop 直觉,导致中文 slop 设得太小
在对中文进行 Phrase Match 时,`analyzer_params` 必须显式指定为 `"chinese"`:
makefile
```python# Chinese analyzer(基于中文分词)schema.add_field(field_name="text_zh",datatype=DataType.VARCHAR,max_length=2000,enable_analyzer=True,enable_match=True,analyzer_params={"type": "chinese"},)````⚠ 关于中文 slop:它和英文"数值表现"并不一样(官方 issue #45807( https://github.com/milvus-io/milvus/issues/45807**) 有详细解释)**
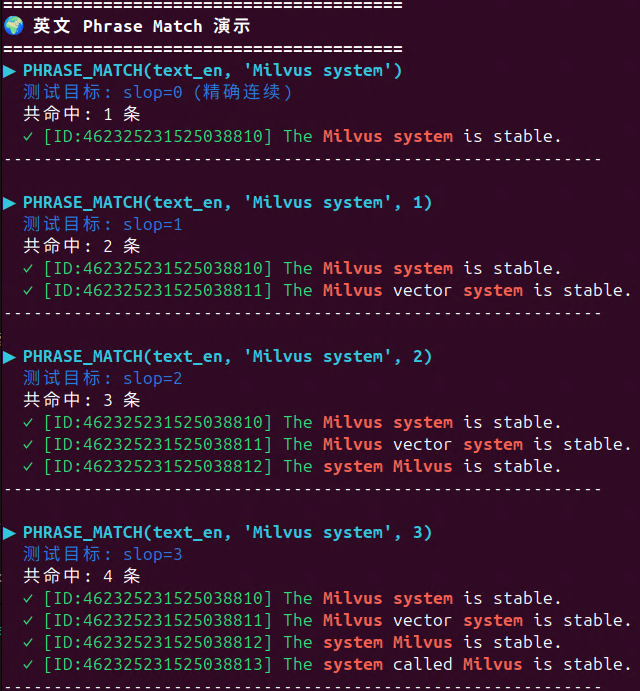
英文单词的 `positionLength = 1`
中文词的 `positionLength` 可能 大于 1
👉 结果就是:要匹配同样结构的短语,中文通常需要更大的 slop,数值也更"稀疏"(例如 1、3、5、7...)
运行 `phrase_match_multilang_demo.py` 看看实际效果:
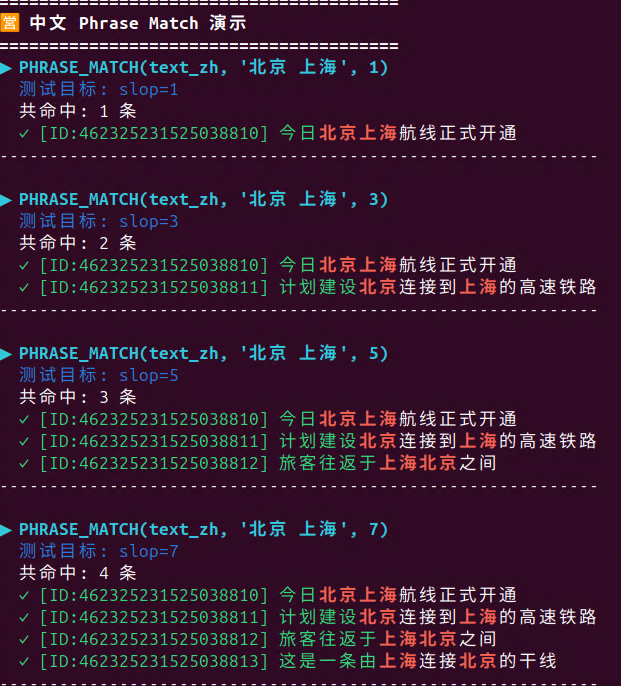
👉 关键结论可以这样理解:
-
概念上:中英文的 Phrase Match 规则是一致的------slop 都是在控制"短语中各个词之间允许多远的距离、是否允许插词/倒序"。
-
实现上 :因为中文的 `positionLength` 设计不同,同样的语义,在中文里往往需要更大的 slop 数值(例如英文用 2,中文可能要 5 才能覆盖到同一类倒序+插词情况)。
所以,如果你发现"中文 Phrase Match 不工作",通常不是 Milvus 的问题,而是:
-
分词器没用 `chinese`;
-
你用了"英文习惯"的 slop 上限,对中文来说还远远不够。
04
如何在生产环境中选择合适的 slop?
slop = 对短语的"容忍度"。越大 → 越宽松;超过 3 无意义。
slop 选择指南

总结
Phrase Match 作为向量检索落地的关键模块。 它能让你的系统从只能简单理解语义,升级为 "必须包含某短语 + 带语义理解 + 可控 + 可解释"的可落地产品。
关于知识库构建,大家还有什么类似的疑问,欢迎评论区留言。
go
作者介绍
张晶
Milvus北辰使者
阅读推荐
高精度知识库≠Milvus+llm!这份PaddleOCR+混合检索+Rerank技巧请收好
向量数据库新范式:分层存储,让数据从全量加载到按需加载 | Milvus Week
客服、代码、法律场景适配:Milvus Ngram Index如何百倍优化LIKE查询| Milvus Week
如何优化英伟达CAGRA,实现GPU建图+CPU查询,成本效率兼顾| Milvus Week
语义+R-Tree空间索引:Milvus如何帮外卖APP做3公里内美食推荐| Milvus Week