git rebase
- 冲突示范
- [学习rebase 从放弃git pull开始](#学习rebase 从放弃git pull开始)
-
- [为什么git pull会需要解决冲突?](#为什么git pull会需要解决冲突?)
- rebase优化
冲突示范
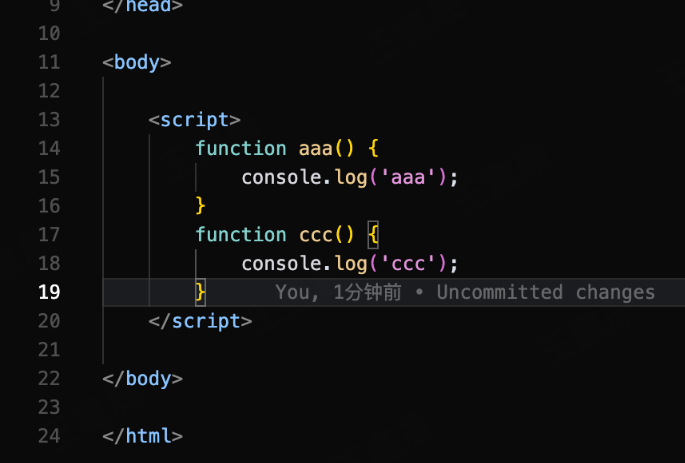
开发者小王开发代码新增了一个b函数 & 提交

开发者小李新建了一个c函数准备提交
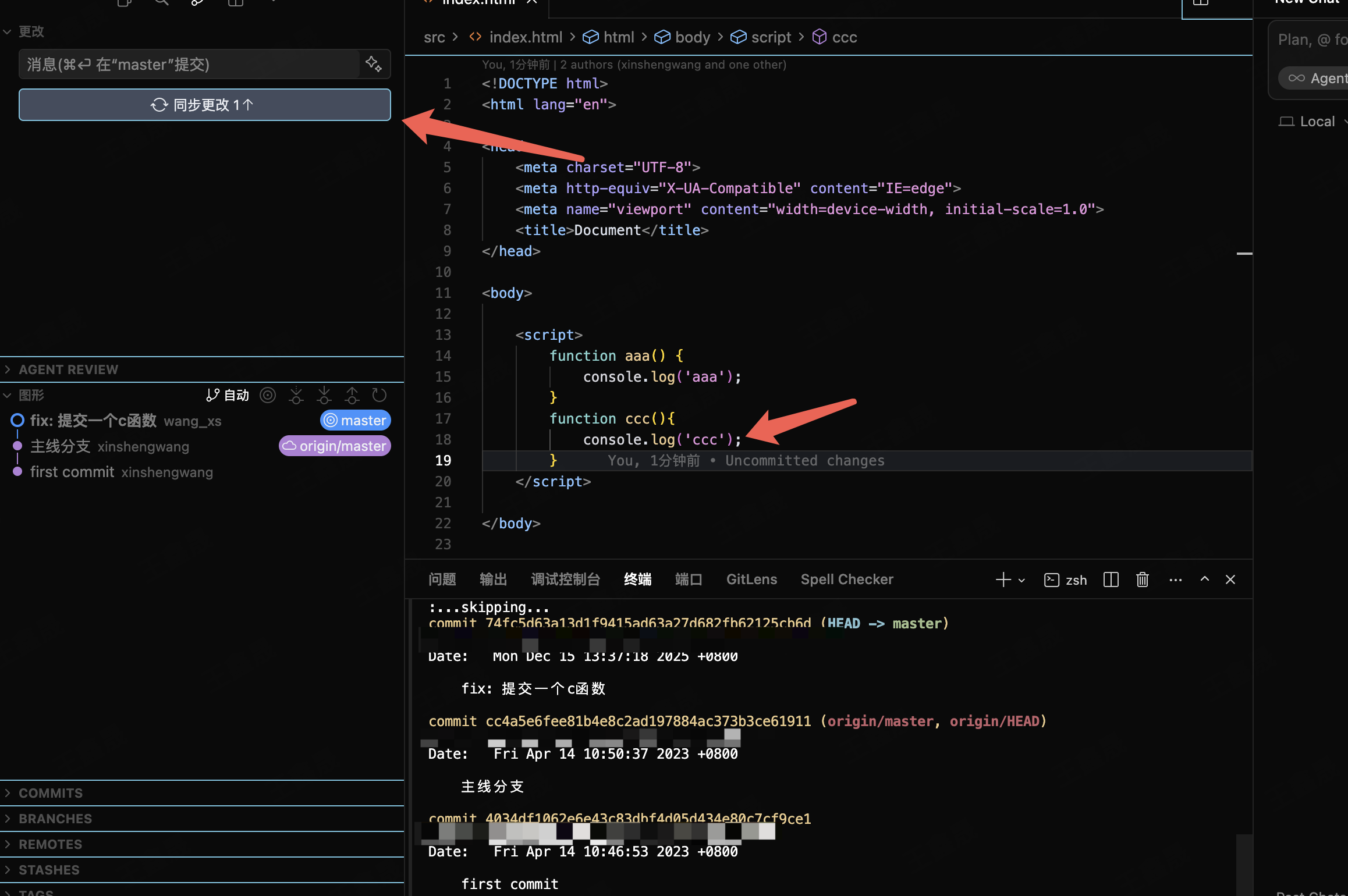
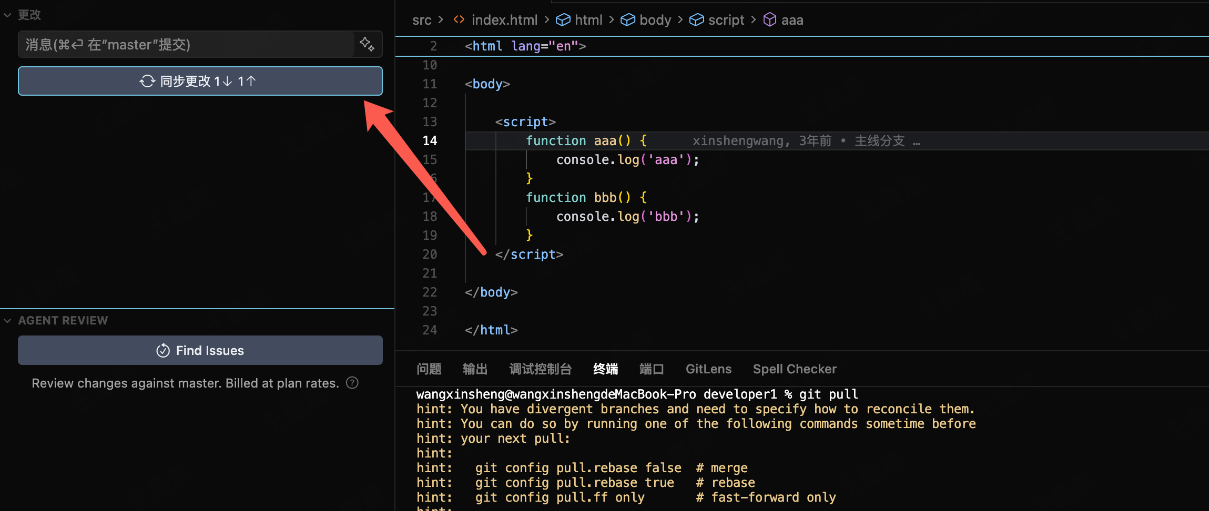
此时提交代码会提示先拉取代码
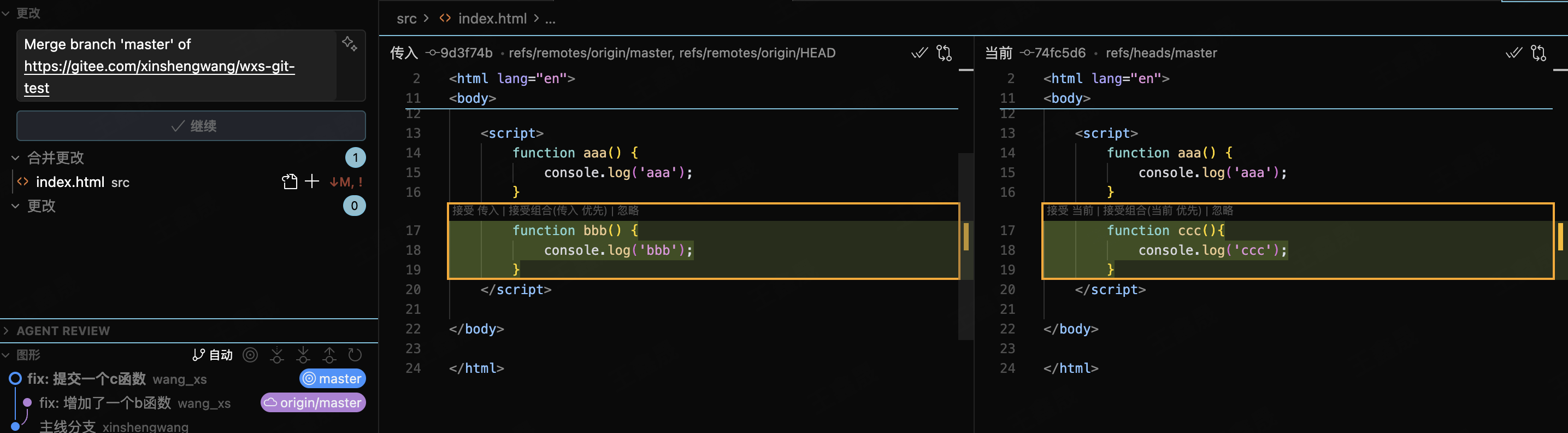
出现这种情况常见的解决方式是小王找到小李一起决策下采取哪一段代码,合并之后推送到远程仓库。相信日常的工作流都是如此
js
从主分支拉取代码->开发->完成开发->从主分支拉取最新代码->解决冲突(如果有)->推送
checkout ------------------> pull -------------> merge ------> push但是如果以这个工作流开发的话,git分支图示如下
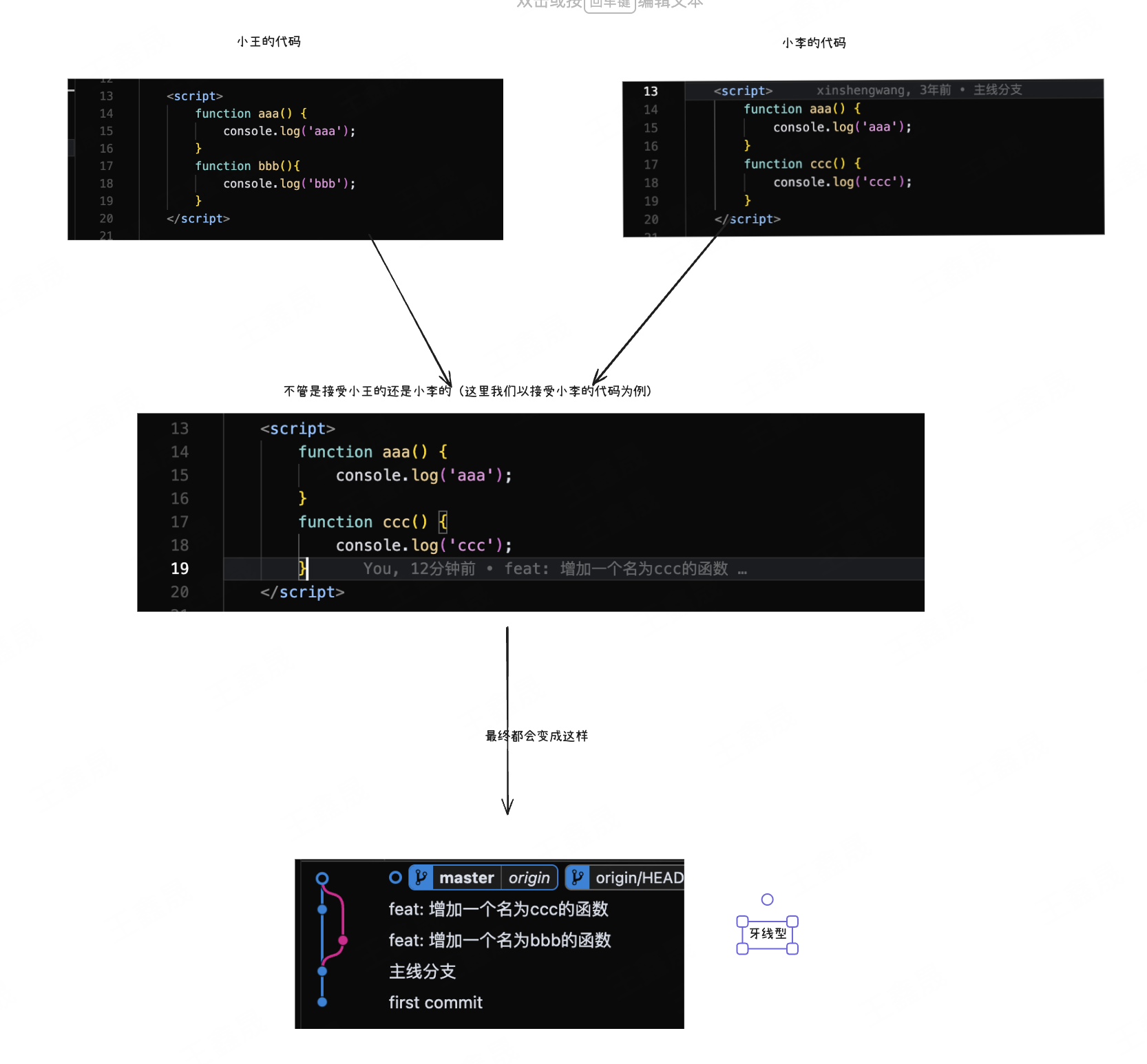
这里我们是以个例进行展示,如果需求过大或者开发人员过多就会变成分支地狱
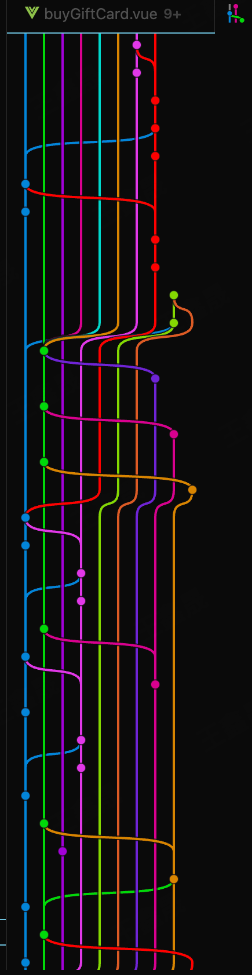
背景原因是在合并分支之后丢了一行代码,然后倒查时找都找不到从而学习了下rebase大法。
学习rebase 从放弃git pull开始
以上述实验打个🌰

为什么git pull会需要解决冲突?
首先要知道 git pull = git fetch + git merge,那么也就是说 即使本地和远程有冲突文件,执行git fetch也不会立马让你解决冲突
假设小王新建了ccc函数&推送到了远端
小李本地开发b函数还没有推送
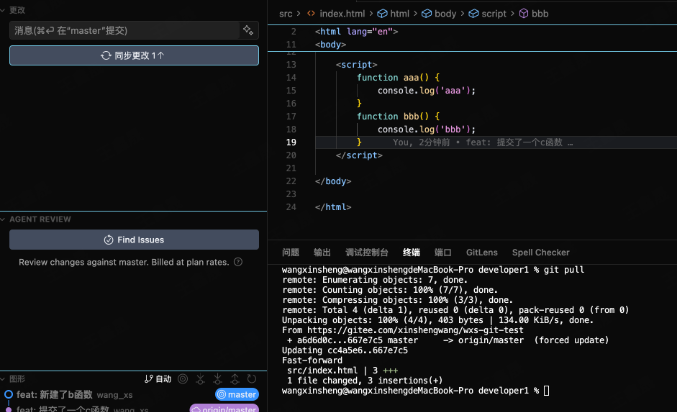
这时候小李直接push的话,git会提示让你先拉取最新代码,但是如果直接pull代码,那么就会直接解决冲突 & 图示也会变成"牙线"如下
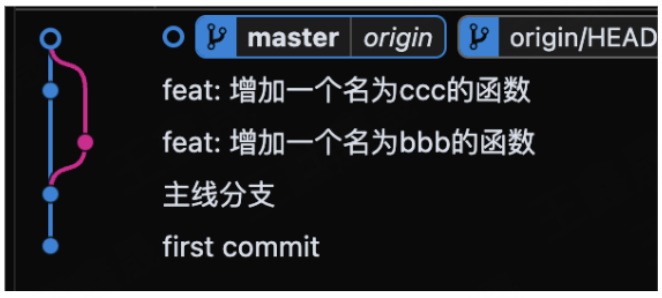
但是如果我们先执行git fetch,那么只会把代码从远程拉下,而不会直接merge
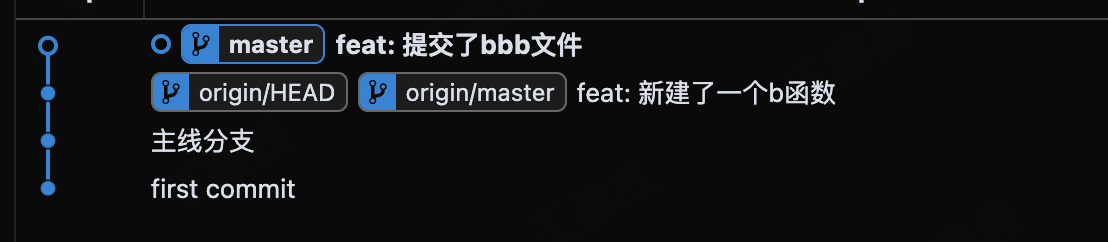
随后,在这一步我们不执行git merge,而是使用rebase大法,rebase的原理是把你本地的代码和远程没有合并的commit逐个比较,比较完成之后把最新的代码放到远程代码的后面,那么合并之后(解决冲突无法避免)的git图示会是一条线形的直观图示。
rebase优化
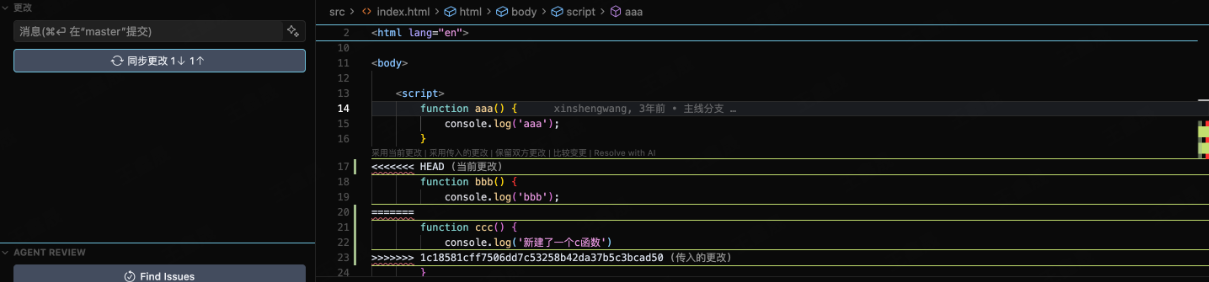
可能有人注意到了,rebase会将远程未合并的的commit逐个比较。那么如果出现下述的情况git rebase就会比git pull麻烦很多
在还没拉下分支最新代码之前本地提交如下
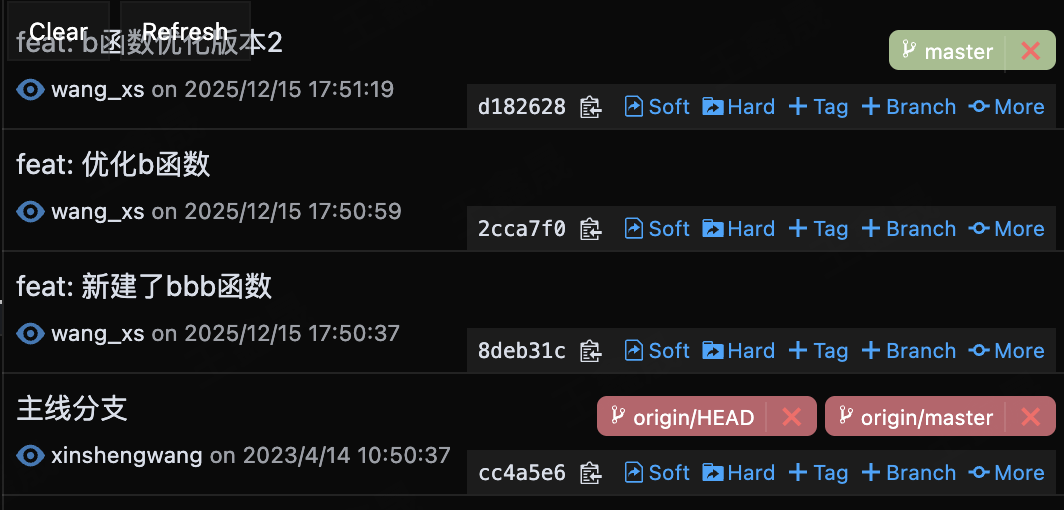
且这三次改动都是同一行或同一个函数,此时执行变基且有冲突时,git会要求你处理三次冲突(因为rebase会把代码和每一次commit做对比)

此时我们可以执行的优化操作是 git rebase -i,这个操作是合并我们本地的三个提交,因为可以看出来,我们本地三个提交都是为了优化b函数,那么这三个commit可以直接合并,更多的业务场景是我们在开发统一个需求的时候往往会对应一大堆的提交记录,本质上都是为了同一个需求,我们把本地无意义的commit信息合并之后,就可以在rebase时只处理一次冲突。
// 终端输入
git rebase -i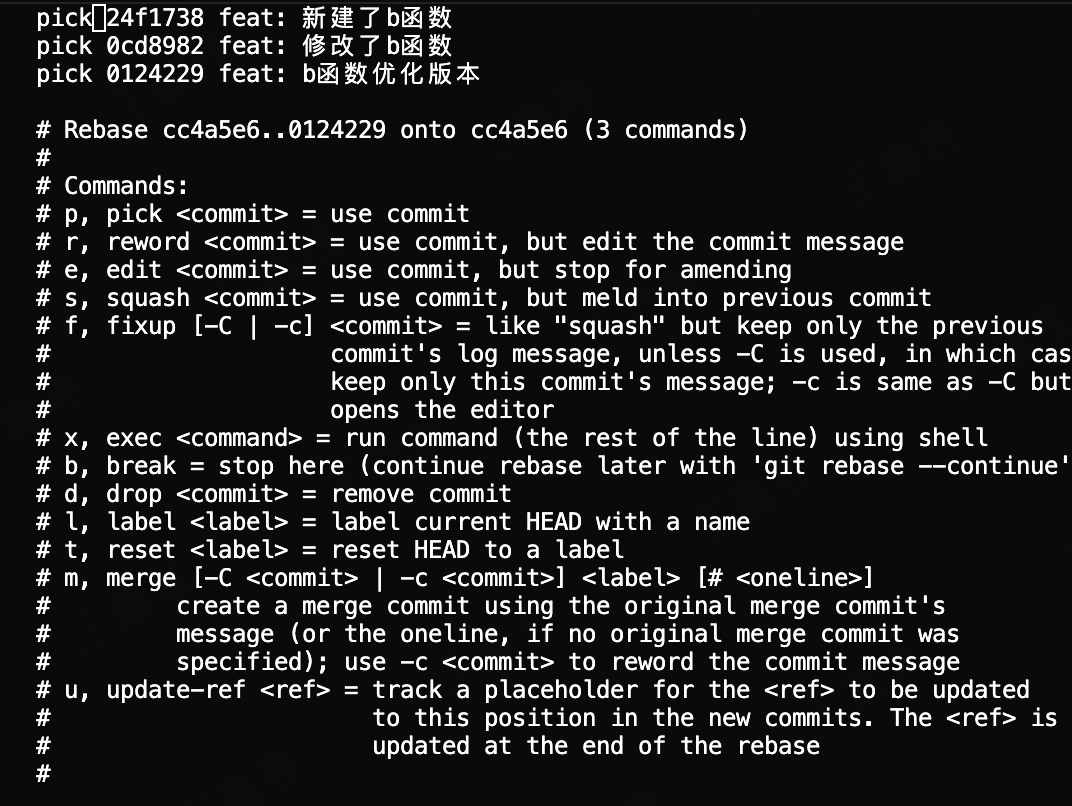
这里我们示范两种操作
合并commit
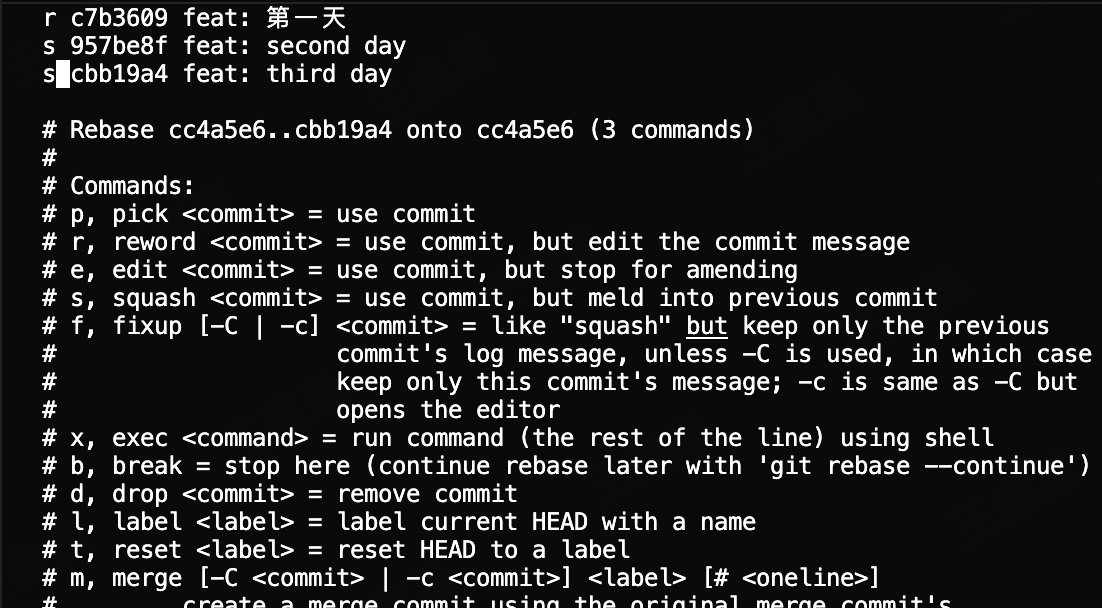
可以看到所有提交记录前都是pick,这里我们把第一条commit改成r(reword),后面的commit全部改成s(squash)
后续操作还会出来一个vim编辑器,能让你修改第一条信息
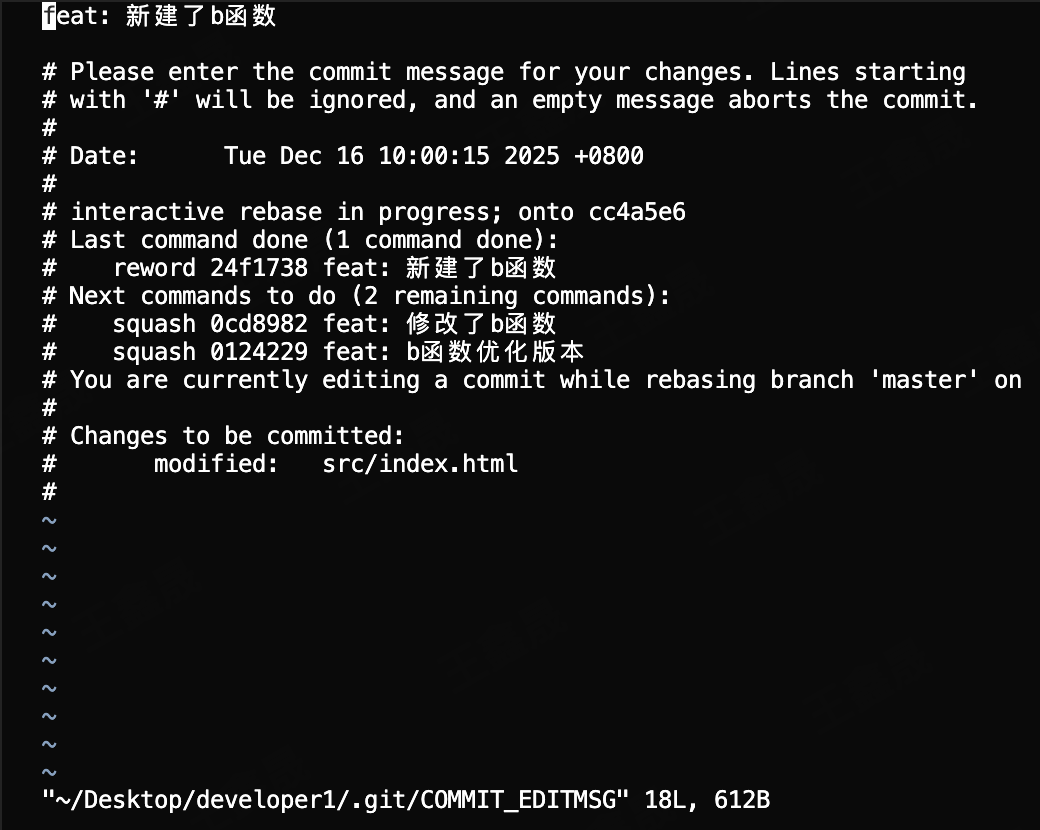
可以在这里编辑commit信息的最终版本变成下图
常用于优化代码 我们需要知道每一次commit信息
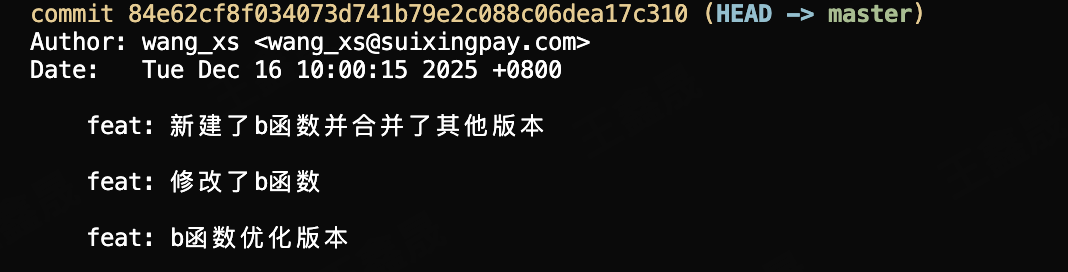
只保留一次commit
大多数场景下我们只需要保留一次commit信息,如以下的业务开发场景
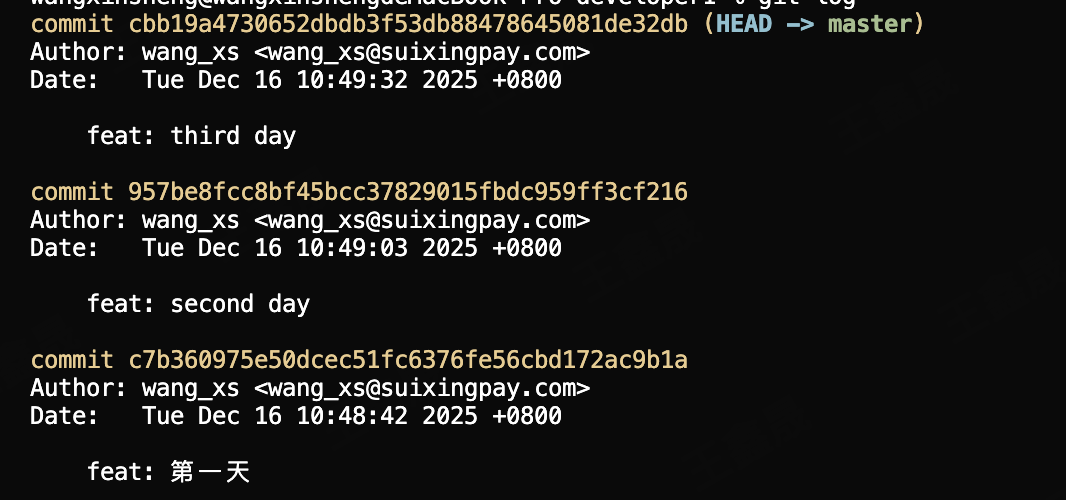
我们并不关心commit信息,想要commit信息和需求强绑定的情况下可以把第一条commit改成r,后面的所有commit改成f(fixup),然后在之后的vim编辑器中修改合并之后的commit信息即可
第一次rebase -i 打开的vim编辑器
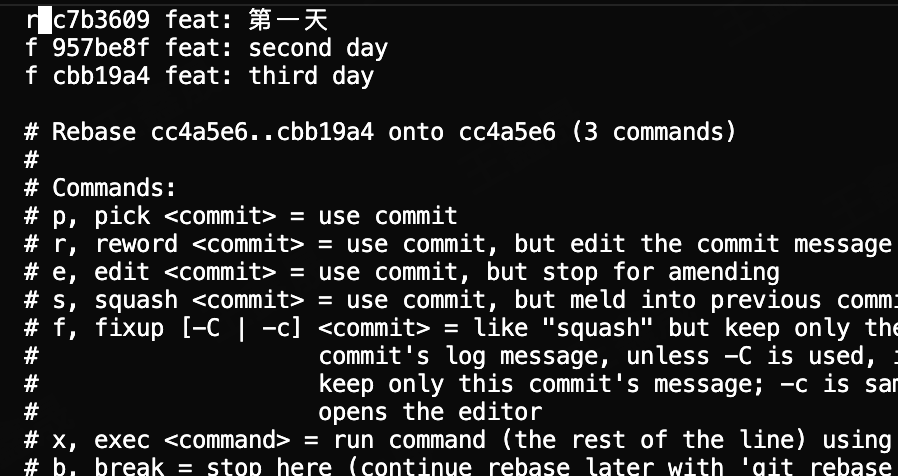
保存退出之后第二次打开的vim编辑器
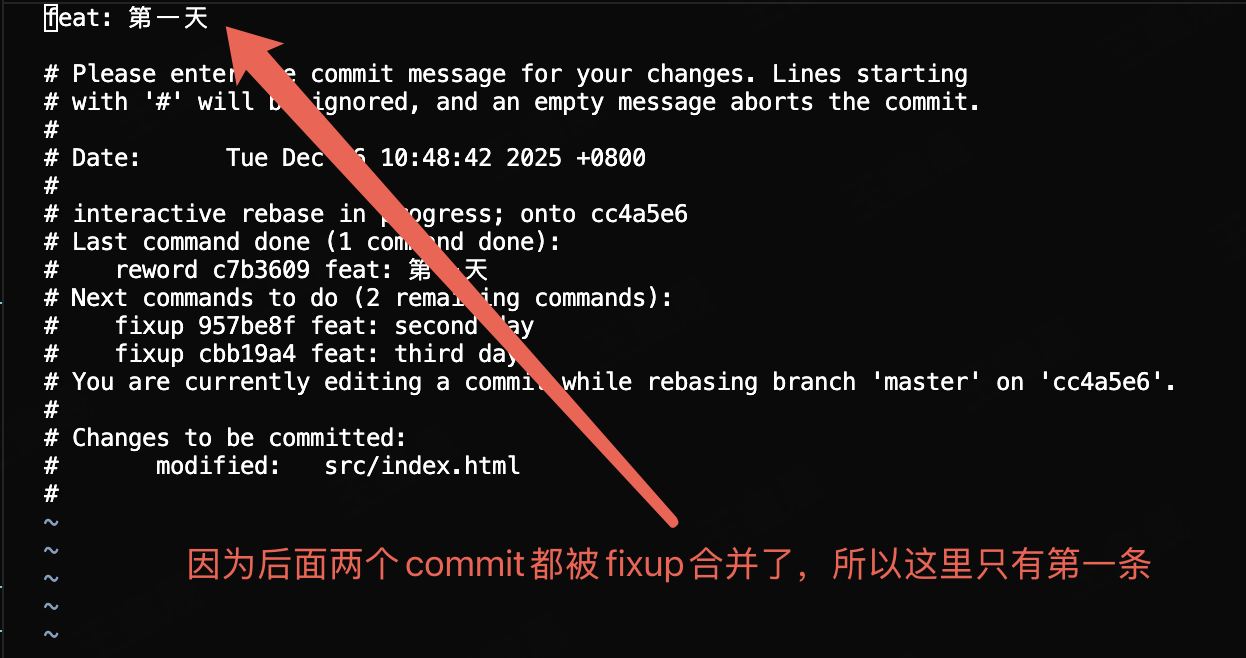
修改第一条
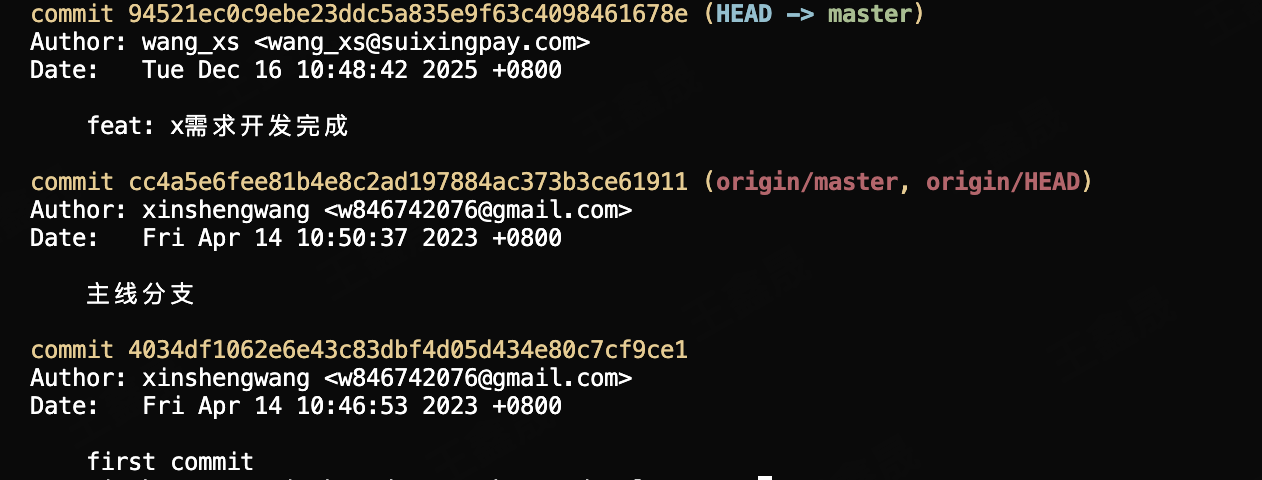
总结
需要保留所有commit信息的,第一条用r,后续都用s(squash),不需要保留其他无关commit信息的,第一条用r,后续都用f(fixup)