Spark SQL Catalyst 优化器详解
一、Spark SQL Catalyst 导览
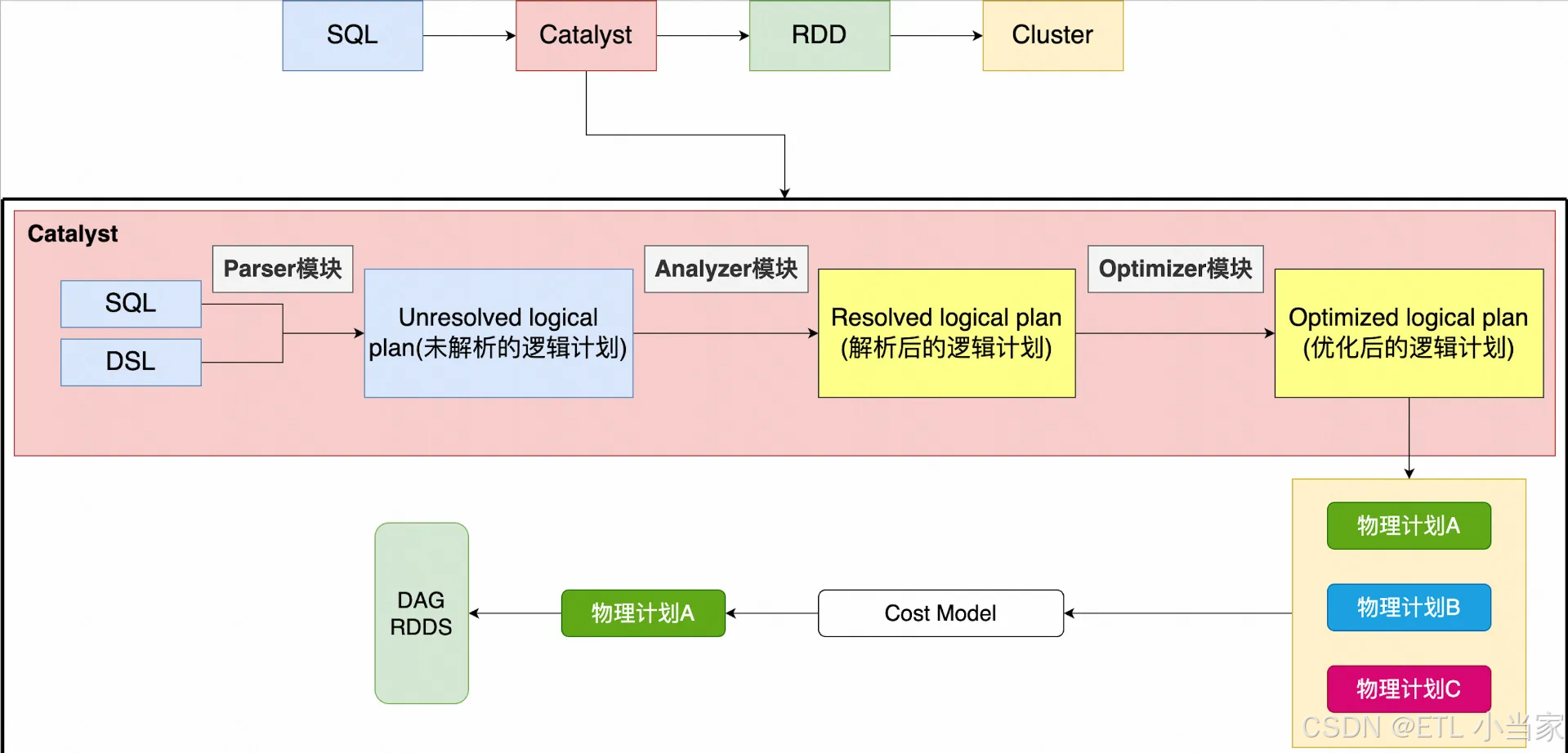
宏观来看:Spark SQL 语句,经过一个优化器(Catalyst),转化为 RDD,交给集群执行。
整个 Catalyst 分三个模块:Parser 模块 、Analyzer 模块 、Optimizer 模块
- Parser 模块:将 Spark SQL 字符串解析为抽象语法树 AST,称为未解析的逻辑计划(Unresolved Logical Plan,ULP)
- Analyzer 模块:借助数据的元数据信息将 ULP 解析为逻辑计划(Logical Plan,LP)
- Optimizer 模块:根据各种 RBO、CBO 优化策略得到优化后的逻辑计划(Optimized Logical Plan,OLP),主要是对 Logical Plan 进行剪枝、合并等操作,进而删除掉一些无用计算,或对一些计算的多个步骤进行合并
其中 RBO 是基于规则优化,CBO 是基于代价优化。
常用的规则有:谓词下推 、列裁剪 、常量累加 。
二、Parser 模块
将 Spark SQL 字符串切分成一个一个的 token,再根据一定的语义规则解析为一个抽象语法树 AST。Parser 模块目前基本都使用第三方类库 ANTLR 来实现,比如 Hive、Presto、Spark SQL 等。
三、Analyzer 模块
对 Parser 生成的"未解析逻辑计划"进行语义校验和元数据绑定,最终生成已解析逻辑计划,比如说:
- 元数据绑定:校验表/列/函数是否存在(比如检查 Catalog 中是否有 user 表,user 表是否有 name 和 age 列)
- 类型检查 :校验数据类型是否合法(比如
age > 18中 age 必须是数值类型,不能是字符串)
四、Optimizer 模块
Optimizer 是 Catalyst 的核心,分为 RBO 和 CBO 两种。
4.1 RBO(基于规则的优化)
RBO 的优化策略就是对语法树再次进行一次遍历,模式匹配能够满足特定规则的节点,再进行相应的等价转换,即将一棵树等价地转换为另一棵树。
谓词下推(Predicate Pushdown):将过滤条件(谓词逻辑)尽可能提前执行,减少下游处理的数据量。比如在涉及 Parquet、ORC 这类存储格式时,结合文件注脚(Footer)中的统计信息,下推的谓词能大幅减少数据扫描量,降低磁盘 I/O 开销。对于不同类型的连接(Join),谓词下推规则有所不同:
| 连接类型 | on 后的条件 | where 后的条件 |
|---|---|---|
| 内连接(Inner Join) | 对左右两表都做过滤 | 对左右两表都做过滤 |
| 左外连接(Left Join) | 对右表进行过滤 | 对左表进行过滤 |
| 右外连接(Right Join) | 对左表进行过滤 | 对右表进行过滤 |
注意:外关联时,过滤条件写在 on 与 where,结果不一样。
列剪裁(Column Pruning):在扫描数据源时,只读取那些与查询相关的字段,避免读取不必要的列,减少数据读取量和传输量。
常量替换(Constant Folding) :当表达式中存在常量时,Catalyst 会自动计算并替换。例如条件 age < 12 + 18,会被自动替换为 age < 30。
4.2 CBO(基于代价的优化)
CBO 通过综合考虑数据的统计信息、操作算子的代价等因素,计算不同执行计划的代价,从而选择最优的物理执行计划,以提升查询性能。