文章目录
- 用.py文件运行yolo模型
- 设置默认终端
- 启动虚拟环境
- 在.py文件中输入测试代码
- 启动测试代码的指令
- 得到测试结果
- 测试代码二
- 保存检测结果
- 模型预测部分常见参数及使用方法介绍
- [安装 jupyterlab](#安装 jupyterlab)
- [jupyterlab 使用](#jupyterlab 使用)
用.py文件运行yolo模型
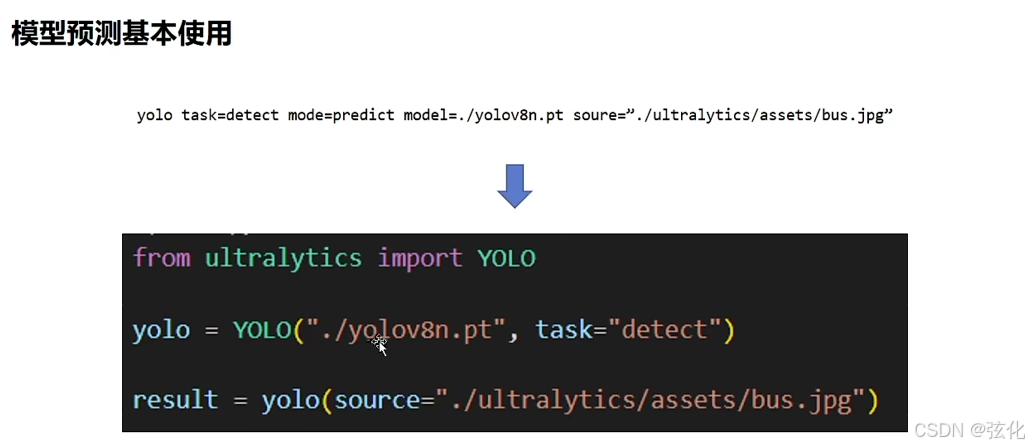
内容对应关系:
两种方式实现的是同一目标(对bus.jpg进行目标检测),参数一一对应:
命令行方式:通过yolo命令直接调用,参数包括task=detect(任务:目标检测)、mode=predict(模式:预测)、model(模型文件)、source(输入图片路径)。
Python API 方式:通过导入ultralytics库的YOLO类,加载模型后调用预测方法,参数与命令行保持一致。
设置默认终端
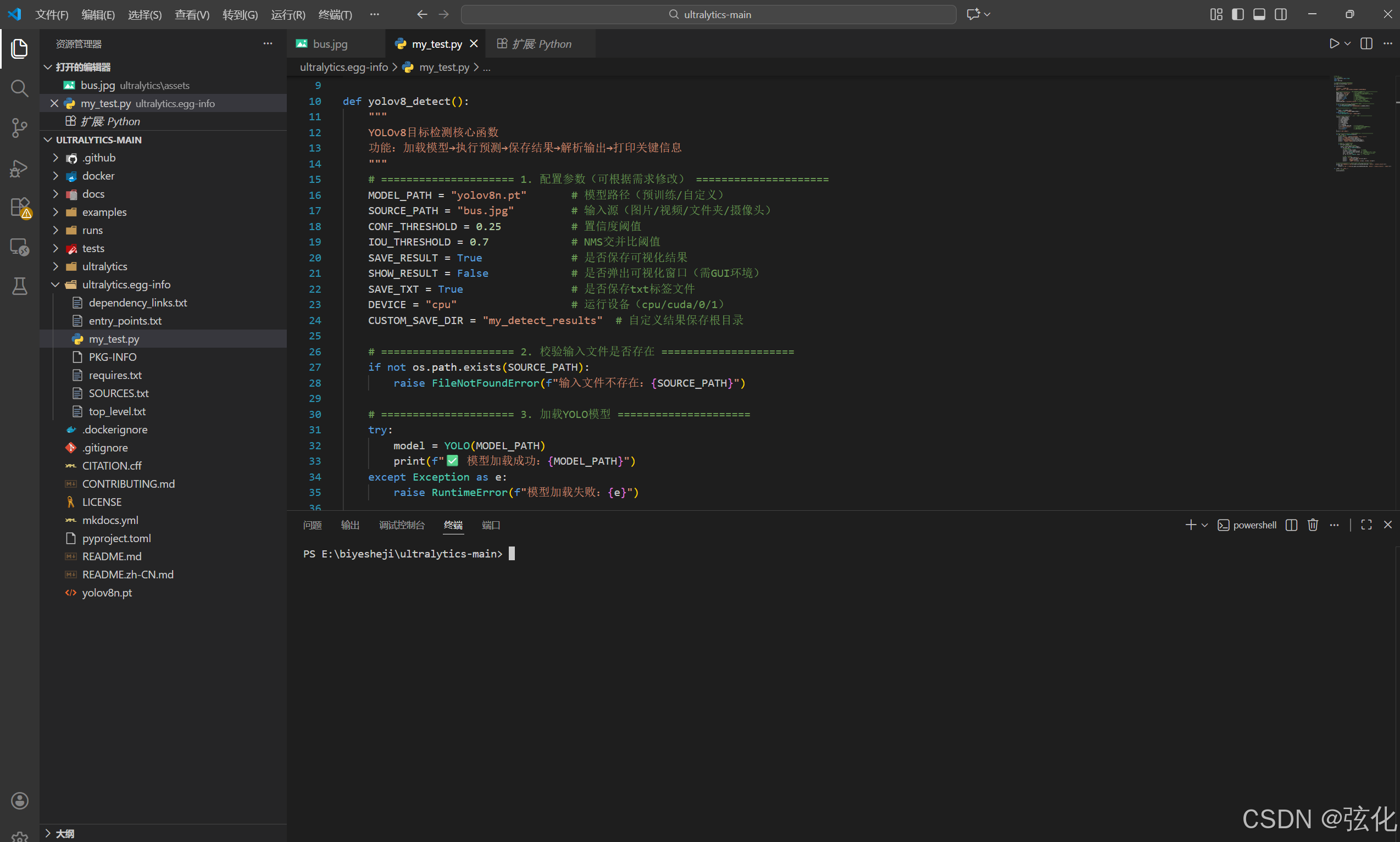
- 注意到如果不进行默认终端设置,默认使用的终端为powershell,但不能直接运行,
conda activate yolov8
这是因为:
一、PowerShell 和 CMD 的核心区别
CMD 是基于 DOS 的传统命令行工具,功能基础,主要支持批处理脚本,管道仅传递文本,无执行策略限制。PowerShell 是现代自动化环境,基于.NET,支持 cmdlet 和面向对象编程,管道传递数据对象,自带脚本执行策略(默认禁止运行脚本),且兼容多数 CMD 命令。
二、PowerShell 无法直接执行 conda activate yolov8 的原因
默认执行策略限制,PowerShell 默认禁止运行任何脚本,Conda 激活脚本会被拦截;
Conda 的activate是专为 CMD 设计的批处理脚本,PowerShell 对其环境变量传递支持不足;
未通过conda init powershell初始化,PowerShell 缺少 Conda 环境的适配配置。
故需要切换默认终端:
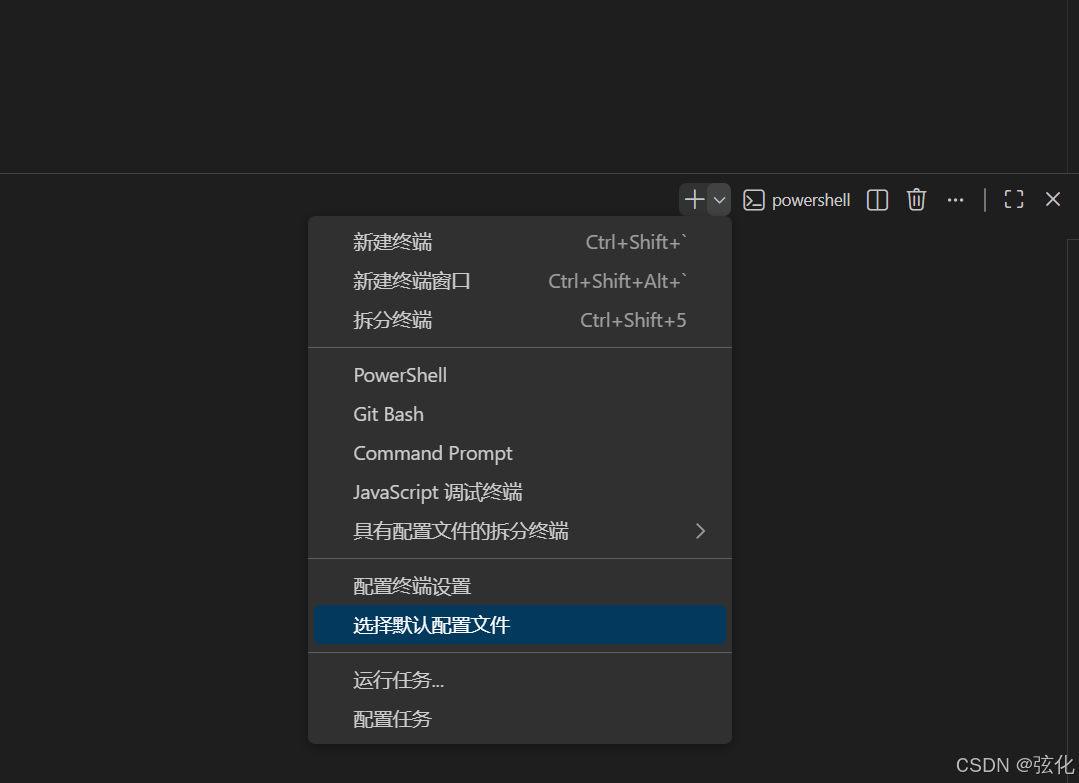
如下图,选择cmd即可
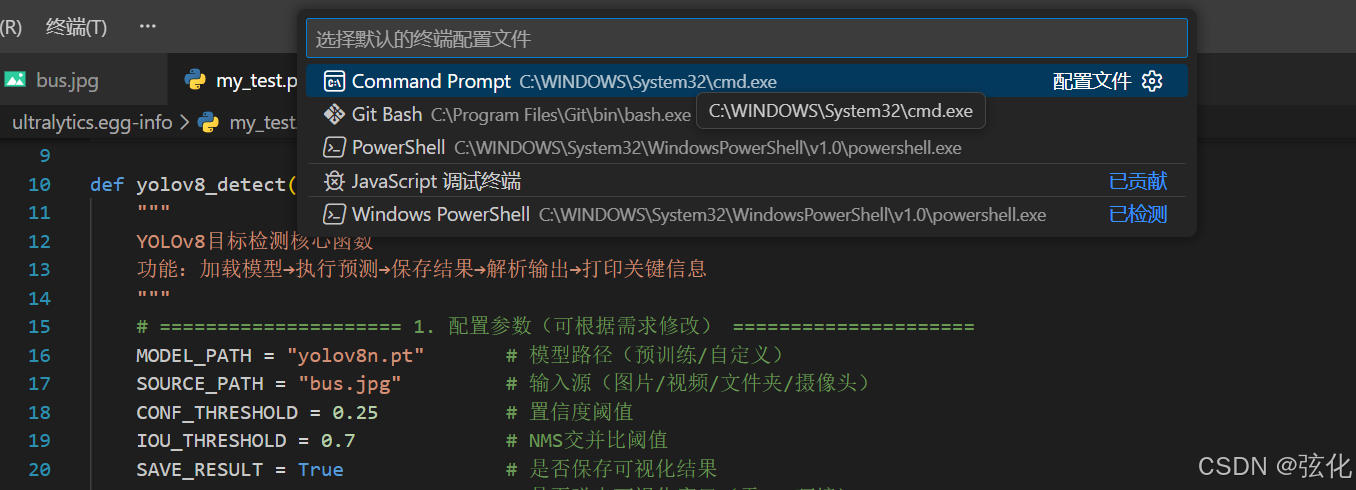
之后再次新建终端,新建的终端即为cmd终端
启动虚拟环境
cmd终端中执行:
bash
conda activate yolov8 (yolov8 替换为你创建的虚拟环境的名称,我的环境名称为yolov8_new
,故我需要输入的指令为:
conda activate yolov8_new )在.py文件中输入测试代码
bash
from ultralytics import YOLO
yolo = YOLO("./yolov8n.pt", task="detect")
result = yolo(source="./ultralytics/assets/bus.jpg")启动测试代码的指令
激活yolov8_new环境后,直接用环境内的python命令运行脚本(无需指定系统 Python 路径):
cmd
(yolov8_new) E:\biyesheji\ultralytics-main>python e:/biyesheji/ultralytics-main/my_test.py
bash
python e:/biyesheji/ultralytics-main/my_test.py得到测试结果

-
检测任务核心信息
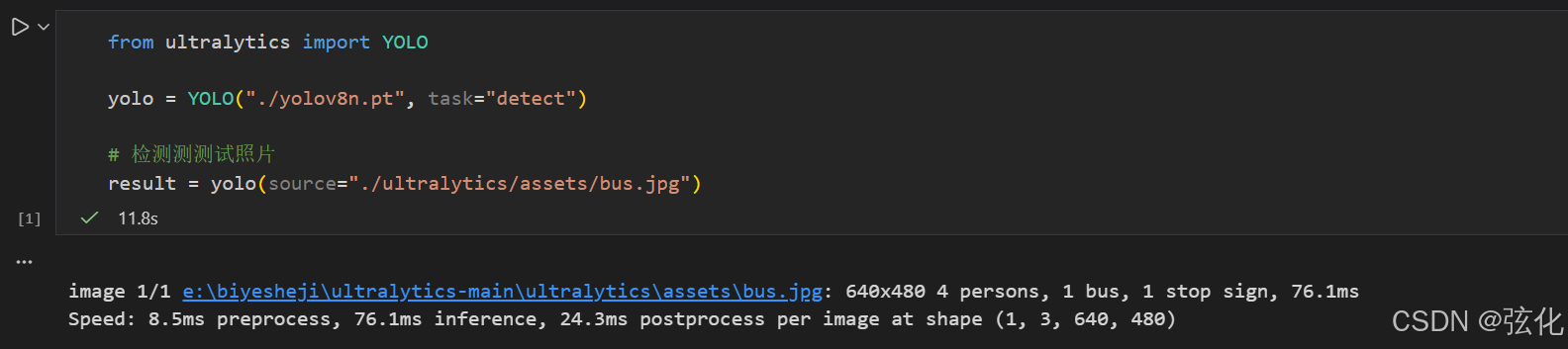
处理对象:路径为E:\biyesheji\ultralytics-main\ultralytics\assets\bus.jpg的图片,尺寸为 640×480;
检测结果:识别出 4 个行人(persons)、1 辆公交车(bus)、1 个停车标志(stop sign);
单图检测耗时:76.9ms。
-
性能耗时分解
检测流程的各阶段耗时(反映模型运行效率):
预处理(preprocess):8.3ms(负责图片缩放、格式转换等准备工作);
推理(inference):76.9ms(模型对图片的核心计算过程);
后处理(postprocess):24.1ms(负责合并重叠检测框、格式化结果等);
模型输入形状:(1, 3, 640, 480)(对应 1 张图片、3 通道(RGB)、宽高 640×480)。
测试代码二
bash
from ultralytics import YOLO
yolo = YOLO("./yolov8n.pt", task="detect")
# 检测测测试照片
# pip install mssresult = yolo(source="./ultralytics/assets/bus.jpg")
# screen参数代表检测当前屏幕
result = yolo(source="screnn")需先安装依赖
bash
pip install mss -i https://pypi.org/simple/启动程序指令
bash
python e:/biyesheji/ultralytics-main/my_test.py
# python 后面跟的文件地址就是程序代码所在的地址运行结果:
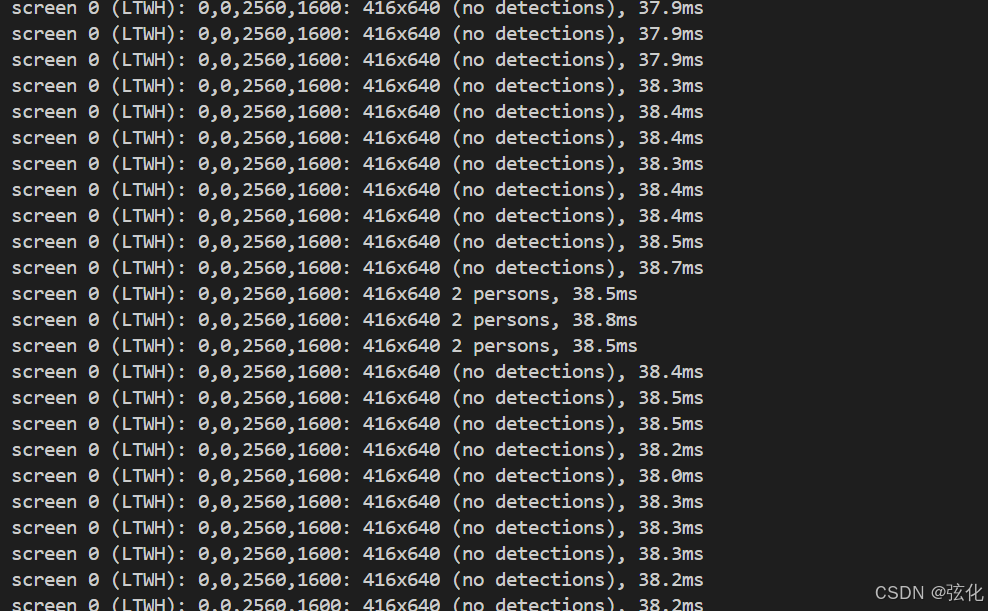
保存检测结果
代码
bash
from ultralytics import YOLO
yolo = YOLO("./yolov8n.pt", task="detect")
# 检测测测试照片
# result = yolo(source="./ultralytics/assets/bus.jpg")
# screen参数代表检测当前屏幕
#result = yolo(source="screen")
# 检测并保存照片
result = yolo(source="./ultralytics/assets/bus.jpg", save = True) 执行指令
bash
python e:/biyesheji/ultralytics-main/my_test.py运行结果

根据提示查看保存的结果
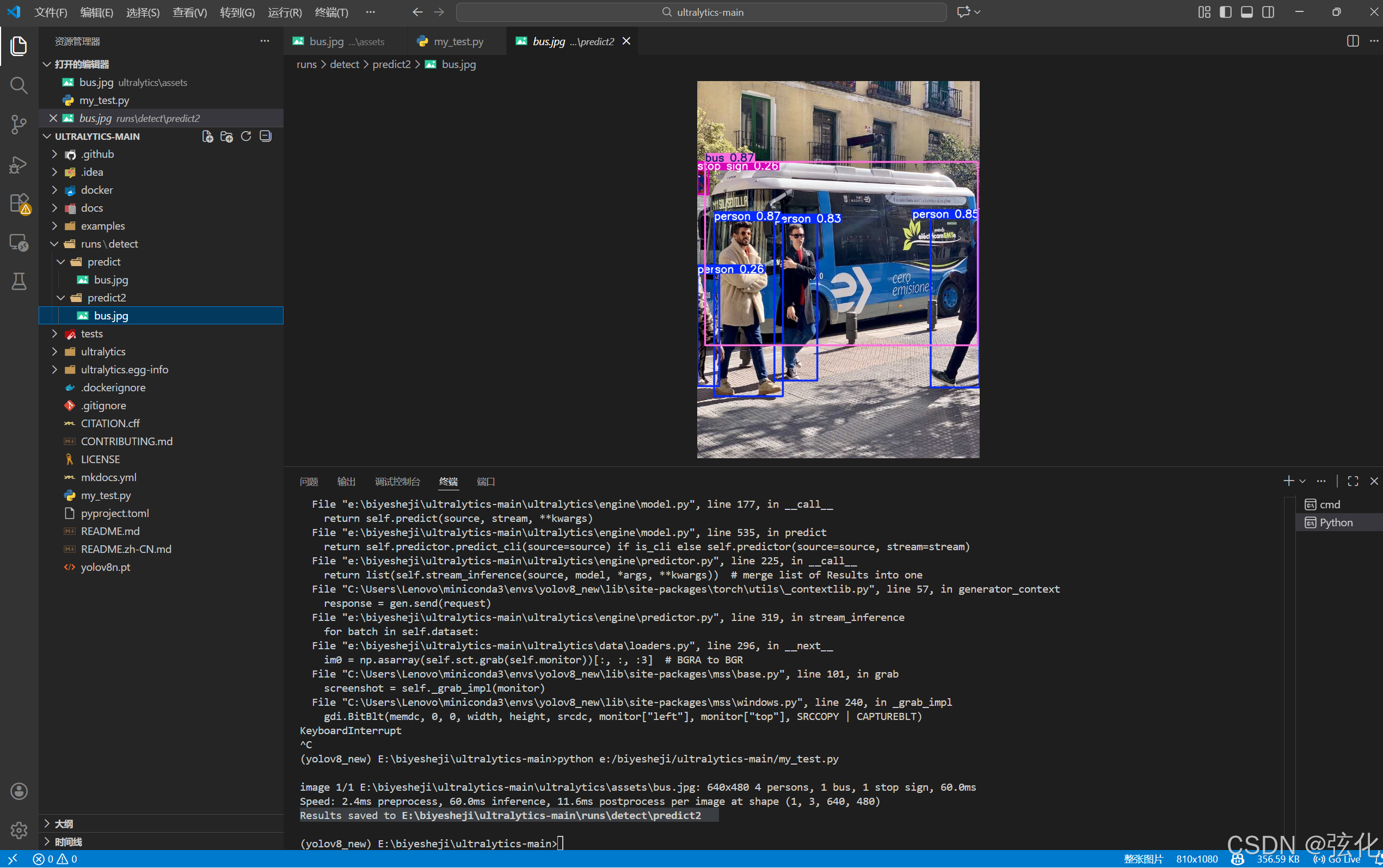
模型预测部分常见参数及使用方法介绍
- source
含义:预测的输入源(虽列在 "可选参数" 中,但实际预测需必选),支持图片路径、视频路径、文件夹路径、摄像头(如source=0)、屏幕(source="screen")等。
调整 & 用法:
命令行:yolo predict source="bus.jpg"
Python API:model.predict(source="bus.jpg") - show
含义:是否弹出窗口可视化预测结果,默认False(不显示)。
调整 & 用法:
场景:需要实时查看检测 / 分割效果时开启。
命令行:yolo predict source="bus.jpg" show=True
Python API:model.predict(source="bus.jpg", show=True) - save_txt
含义:是否将预测结果保存为.txt标签文件,默认False;保存的文件包含目标的类别 ID、归一化坐标等信息。
调整 & 用法:
场景:需要后续用标签文件做二次处理(如统计目标数量)时开启。
命令行:yolo predict source="bus.jpg" save_txt=True
Python API:model.predict(source="bus.jpg", save_txt=True) - save_conf
含义:保存结果(如save_txt=True时)是否包含置信度分数,默认False。
调整 & 用法:
场景:需要在标签文件中记录目标的置信度时开启。
命令行:yolo predict source="bus.jpg" save_txt=True save_conf=True
Python API:model.predict(source="bus.jpg", save_txt=True, save_conf=True) - save_crop
含义:是否保存裁剪后的目标区域图片,默认False;开启后会生成单独的目标截图(如检测到的 "bus" 会被单独裁剪保存)。
调整 & 用法:
场景:需要提取检测到的目标时开启。
命令行:yolo predict source="bus.jpg" save_crop=True
Python API:model.predict(source="bus.jpg", save_crop=True) - hide_labels
含义:是否隐藏检测框上的类别标签,默认False(显示标签)。
调整 & 用法:
场景:仅需要检测框、不需要类别名称时开启。
命令行:yolo predict source="bus.jpg" hide_labels=True
Python API:model.predict(source="bus.jpg", hide_labels=True) - hide_conf
含义:是否隐藏检测框上的置信度分数,默认False(显示分数)。
调整 & 用法:
场景:仅需要检测框 / 类别、不需要置信度时开启。
命令行:yolo predict source="bus.jpg" hide_conf=True
Python API:model.predict(source="bus.jpg", hide_conf=True) - vid_stride
含义:视频预测的帧率步长,默认1(处理每 1 帧);如设为2,则每隔 1 帧处理 1 帧。
调整 & 用法:
场景:视频处理速度慢时,增大该值(如vid_stride=2)可减少处理帧数、提升速度(但会降低结果连续性)。
命令行:yolo predict source="video.mp4" vid_stride=2
Python API:model.predict(source="video.mp4", vid_stride=2) - line_thickness
含义:检测框的线条粗细(单位:像素),默认3。
调整 & 用法:
场景:图片分辨率高时,可调大(如line_thickness=5)让检测框更清晰;分辨率低时调小避免遮挡目标。
命令行:yolo predict source="bus.jpg" line_thickness=5
Python API:model.predict(source="bus.jpg", line_thickness=5) - visualize
含义:是否可视化模型的中间层特征图,默认False。
调整 & 用法:
场景:模型调试(如分析特征提取效果)时开启。
命令行:yolo predict source="bus.jpg" visualize=True
Python API:model.predict(source="bus.jpg", visualize=True) - augment
含义:是否对输入源做数据增强(如翻转、缩放),默认False。
调整 & 用法:
场景:需要提升预测的鲁棒性(如应对不同角度的目标)时开启,但会增加预测耗时。
命令行:yolo predict source="bus.jpg" augment=True
Python API:model.predict(source="bus.jpg", augment=True) - agnostic_nms
含义:是否使用 "类别无关的 NMS(非极大值抑制)",默认False;开启后,不同类别之间的重叠检测框也会被抑制。
调整 & 用法:
场景:多类别目标严重重叠时,可减少冗余框(但可能误删不同类的合理框)。
命令行:yolo predict source="bus.jpg" agnostic_nms=True
Python API:model.predict(source="bus.jpg", agnostic_nms=True) - classes
含义:按类别过滤预测结果,仅保留指定类别的目标;如classes=0(仅保留 "person" 类)、classes=0,2(保留 "person" 和 "car" 类)。
调整 & 用法:
场景:仅关注特定类别的目标时使用(类别 ID 对应 COCO 数据集的类别,或自定义数据集的类别)。
命令行:yolo predict source="bus.jpg" classes=5(仅检测 "bus" 类,COCO 中 5 对应 bus)
Python API:model.predict(source="bus.jpg", classes=5) - retina_masks
含义:是否使用高分辨率的分割掩码,默认False;仅在分割模型(如 yolov8n-seg.pt) 中生效。
调整 & 用法:
场景:需要更精细的分割区域时开启,但会增加内存占用。
命令行:yolo segment predict source="bus.jpg" retina_masks=True
Python API:model.predict(source="bus.jpg", retina_masks=True)(需加载分割模型) - boxes
含义:在分割预测中是否显示检测框,默认True;仅在分割模型中生效。
调整 & 用法:
场景:仅需要分割掩码、不需要检测框时设为False。
命令行:yolo segment predict source="bus.jpg" boxes=False
Python API:model.predict(source="bus.jpg", boxes=False)(需加载分割模型)
在官网中可以查到其他的选项的参数详细说明
安装 jupyterlab
确保你在所用的虚拟环境中执行以下指令!!!!
bash
# 用官方源安装 JupyterLab
pip install jupyterlab -i https://pypi.org/simple/
# 国内靠谱镜像(如清华源)
pip install jupyterlab -i https://pypi.tuna.tsinghua.edu.cn/simple/JupyterLab 是 Jupyter 项目推出的下一代交互式开发环境(IDE),是经典 Jupyter Notebook 的升级版,核心用于数据科学、机器学习、代码调试与文档编写,以下是核心说明:
一、核心定位
JupyterLab 以 "交互式计算" 为核心,整合了代码编辑、文本编写、数据可视化、终端操作等能力,支持 Python、R、Julia 等数十种编程语言(核心适配 Python),是数据科学、机器学习(如 YOLOv8 开发)场景下的主流工具。
核心 : 变为交互式的编程
二、核心优势(对比传统 Notebook / 其他 IDE)
一站式开发:
同界面可打开代码文件(.py)、Jupyter 笔记本(.ipynb)、Markdown 文档、终端、图片 / 表格等,无需切换软件;
支持多窗口拆分、拖拽布局,适配复杂的代码 + 文档 + 数据联动场景(比如一边写 YOLOv8 代码,一边看检测结果可视化,一边记实验笔记)。
完全兼容 Jupyter Notebook:可直接打开、编辑、运行传统 .ipynb 笔记本文件,保留 "代码块逐行运行""实时输出结果" 的核心特性,同时新增更多便捷功能(如代码补全、语法高亮、一键格式化)。
轻量化 + 灵活:
基于浏览器运行(无需安装厚重客户端),启动后本地访问 localhost:8888 即可使用;
支持扩展插件(如代码折叠、主题美化、版本控制),可按需定制功能。
交互性极强:代码块运行结果(如 YOLOv8 的检测结果、数据图表、打印日志)实时显示在代码下方,支持增量调试(改一行运行一行),适合算法迭代、参数调优。
三、与你的场景(YOLOv8 开发)的适配性
可在 JupyterLab 中编写 / 运行 YOLOv8 代码,逐块调试(比如先加载模型、再测试单张图片预测、最后调整参数),实时查看检测结果可视化;
可整合 Markdown 笔记,记录实验参数、结果分析(比如 "conf=0.3 时检测准确率 XX%"),形成可复现的实验文档;
内置终端可直接执行 Conda 命令(如激活环境、安装依赖)、YOLOv8 命令行指令,无需切换系统终端。
四、核心使用流程(极简版)
安装后执行 jupyter lab 启动,自动打开浏览器界面;
新建 "Python 笔记本(.ipynb)" 或直接打开 .py 文件;
编写代码块(如 YOLOv8 预测代码),按 Shift+Enter 运行,实时查看结果;
可保存文件、导出为 PDF/HTML(便于分享实验结果)。
jupyterlab 使用
-
创建一个.ipynd文件
-
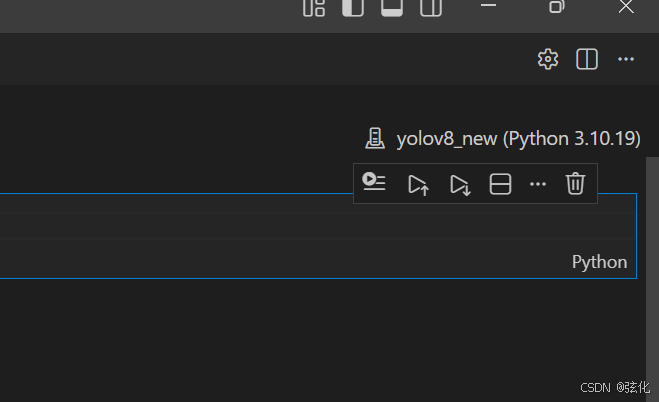
点击选择内核,然后选择需要使用的虚拟环境。
3 输入测试代码并运行
4 点击 :
5 在弹出的输入框中输入 result ,并运行
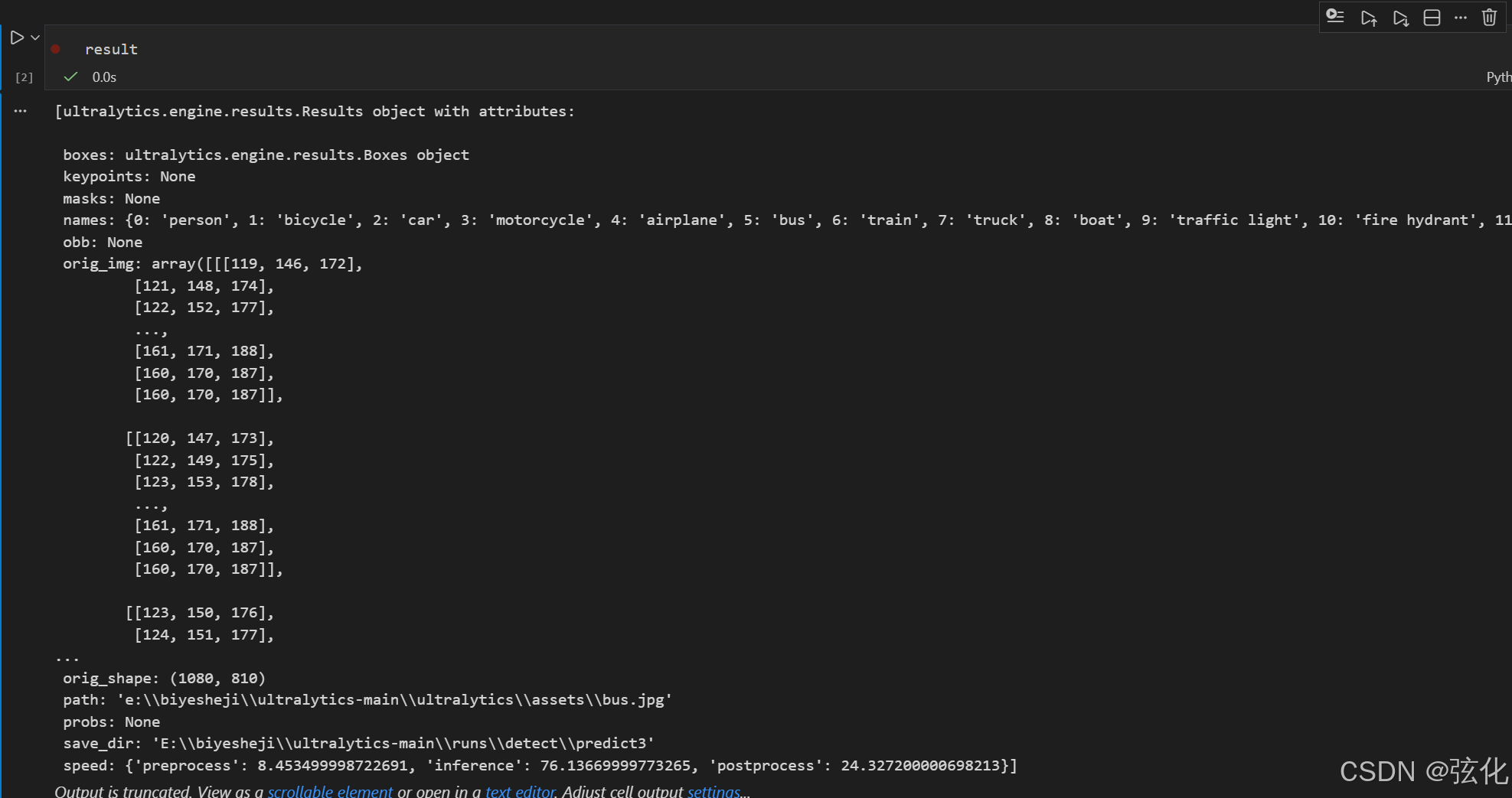
6 再次添加代码并运行(格式化)
bash
import matplotlib.pyplot as plt
# 这是 Jupyter Notebook 的 "魔法命令",作用是让matplotlib绘制的图像直接嵌入到 Notebook 单元格中(而非弹出独立窗口),适配交互式开发场景。
%matplotlib inline
# [...,::-1]:将 BGR 格式转换为 RGB 格式 ------matplotlib的imshow默认要求 RGB 格式,若不转换会出现颜色异常(如蓝色变红色)
plt.imshow(result[0].plot()[...,::-1])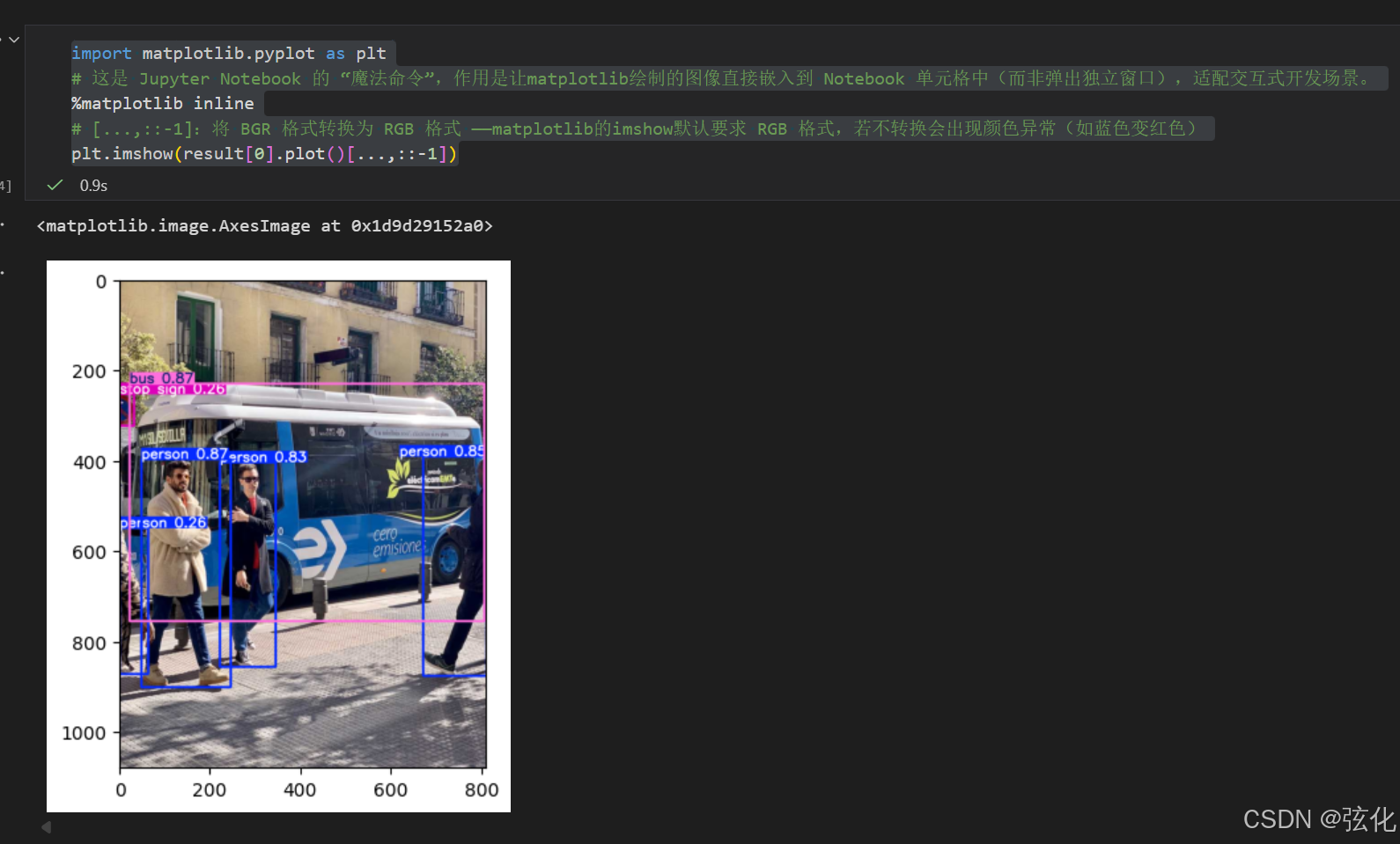
bash
result[0].boxes 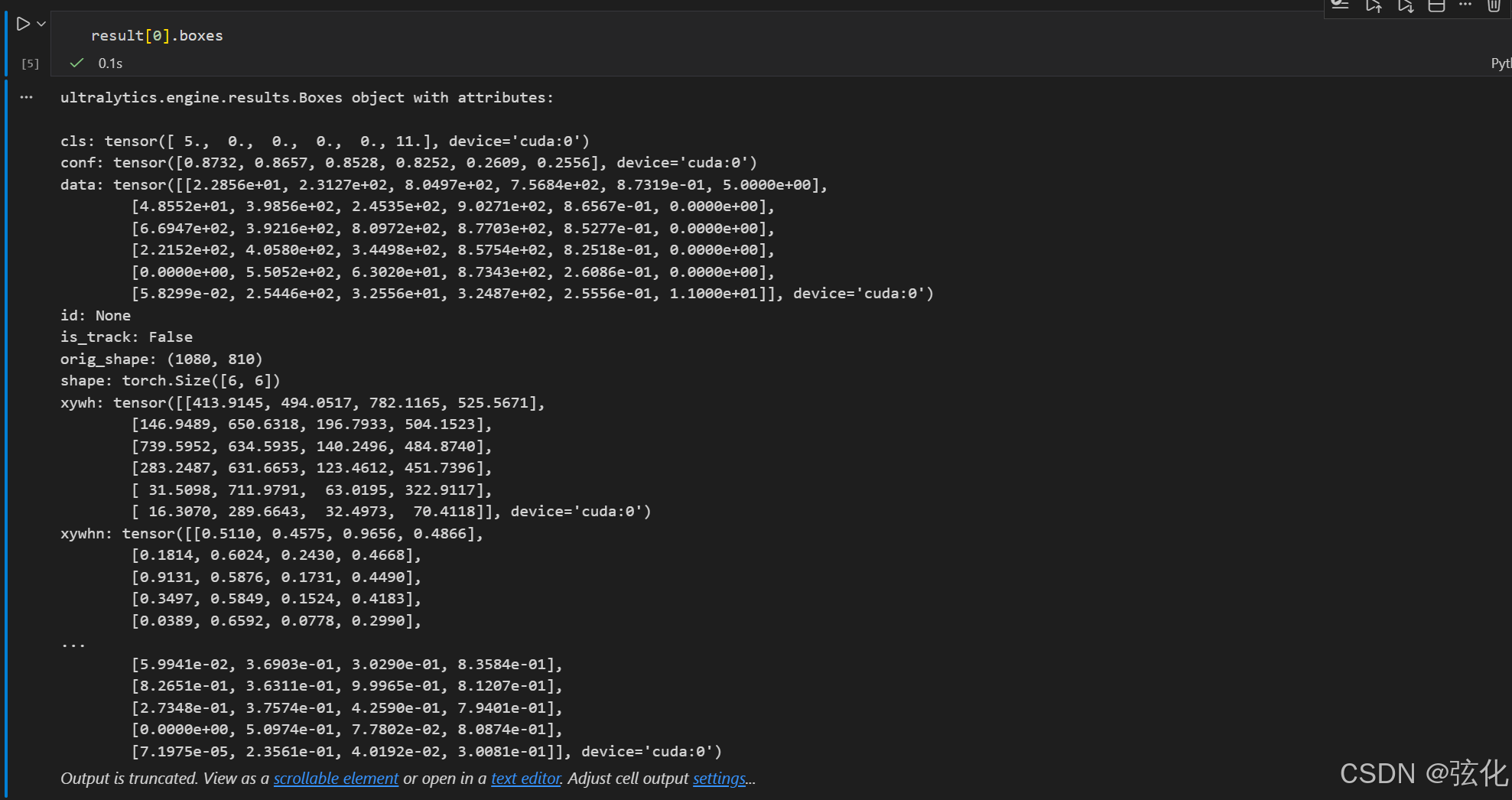
- 输出结果转为numpy的示范
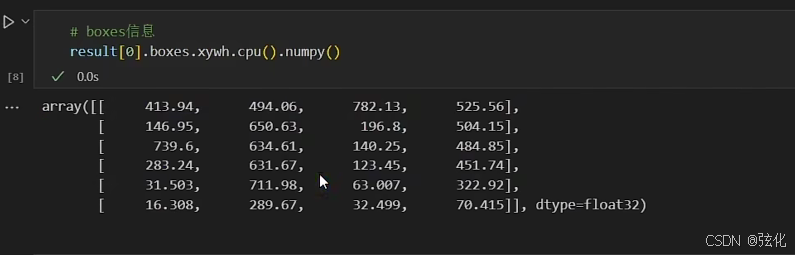
8 注意事项

第一点:为啥必须加%matplotlib inline?
你在 Jupyter 里想看到 YOLO 的检测结果图(比如带框的图片),必须先写%matplotlib inline这行。因为 YOLO 自己把 "画图的显示方式" 设成了 "只在后台偷偷画、不往页面上显示" 的模式;加了这行代码,才能让画好的检测图直接显示在 Jupyter 页面里 ------ 不然你跑了代码,也看不到结果图。
第二点:为啥要重新加载模型?
比如你第一次用模型预测时,把 "置信度阈值" 设成了 0.5;后来想改成 0.3,直接改参数再跑预测是没用的。因为模型加载一次后,会 "记住" 第一次的参数;必须重新写 "加载模型" 的代码(比如重新写model = YOLO('yolov8n.pt')),新参数才会生效 ------ 不然改了参数也是白改,模型还按老参数跑。
9 补充:
一、 YOLOv8 结果的result.boxes对象
在 YOLOv8 预测返回的Results对象中,result.boxes存储的是当前图片所有检测目标的核心检测框信息,是多个Box对象的集合,包含的关键数据:
坐标信息:支持多种格式(如xyxy(像素级左上角 + 右下角坐标)、xywh(像素级中心坐标 + 宽高)、xyxyn(归一化坐标)等);
置信度(conf):检测框对应目标的置信度(0-1 的数值,代表模型对该目标的判断确信程度);
类别 ID(cls):检测目标对应的类别索引(如 COCO 数据集里 0 对应 "person"、5 对应 "bus");
附加信息:若开启目标跟踪,还会包含track_id(跟踪 ID,用于关联不同帧的同一目标)。
二、保存到文件的 "boxes 文件"(如 labels 目录下的 txt)
当设置save_txt=True时,YOLOv8 会生成以.txt为后缀的 "boxes 文件"(存于runs/detect/predict/labels目录),每行对应一个检测框,内容格式为(基于归一化坐标):
bash
<类别ID> <x_center> <y_center> <width> <height> [置信度]类别 ID:目标对应的类别索引;
x_center/y_center/width/height:检测框的中心坐标、宽、高(均为相对于图片宽高的归一化值,范围 0-1,适配不同尺寸图片);
置信度:仅开启save_conf=True时包含,代表该检测框的置信度。