一、早停策略(Early Stopping)
1. 核心问题:为什么需要早停?
深度学习模型训练时,随着 epoch 增加,模型在训练集 上的误差会持续下降,但在验证集 上的误差会先下降(模型学习到泛化能力),后上升(模型开始过拟合训练数据)。早停的本质是:在验证集性能达到峰值时停止训练,避免模型继续学习训练集的噪声,从而保留泛化能力最强的模型状态。
2. 核心原理与关键参数
早停的核心逻辑是 "监控验证集指标,当指标不再提升时停止训练",需明确 3 个关键参数(缺一不可):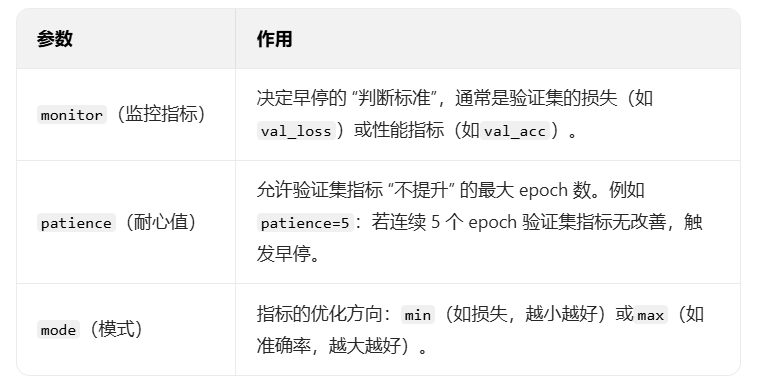
补充细节:
- "指标改善" 的定义 :默认是 "严格优于历史最优",但实际中会设置
min_delta(最小改善幅度),例如min_delta=0.001:只有当指标变化超过 0.001 时,才认为是 "改善",避免因微小波动误判。 - 恢复最优权重 :早停时,模型的最后一个 epoch 权重可能不是最优的(因为
patience期间指标已下降),因此需要在训练中实时保存验证集最优的权重,早停后加载该权重。
3. 常见实现方式
早停通常通过框架自带的回调函数(Callback)实现,无需手动编写逻辑,主流框架(TensorFlow/Keras、PyTorch Lightning)均支持:
(1)TensorFlow/Keras 实现
Keras 内置EarlyStopping回调函数,直接传入训练的callbacks列表即可:
from tensorflow.keras.callbacks import EarlyStopping
# 定义早停策略
early_stopping = EarlyStopping(
monitor='val_loss', # 监控验证集损失
patience=5, # 连续5个epoch无改善则停止
min_delta=0.0001, # 最小改善幅度(避免微小波动)
mode='min', # 损失越小越好
restore_best_weights=True # 早停后恢复验证集最优的权重(关键!)
)
# 训练时传入callbacks
model.fit(
x_train, y_train,
validation_data=(x_val, y_val), # 必须有验证集,否则早停无意义
epochs=100, # 最大epoch数(早停会提前终止)
batch_size=32,
callbacks=[early_stopping] # 加入早停回调
)(2)PyTorch 实现(需手动逻辑或用 Lightning)
PyTorch 原生无内置早停,需手动记录验证集指标并判断,或使用PyTorch Lightning的EarlyStopping:
# PyTorch Lightning 实现(推荐,简洁高效)
from pytorch_lightning.callbacks import EarlyStopping
# 定义早停策略
early_stopping = EarlyStopping(
monitor='val_loss',
patience=5,
min_delta=0.0001,
mode='min',
restore_best_weights=True
)
# 训练时传入callbacks
trainer = Trainer(callbacks=[early_stopping], max_epochs=100)
trainer.fit(model, train_dataloaders=train_loader, val_dataloaders=val_loader)(3)PyTorch 原生手动实现(了解逻辑)
import torch
# 初始化参数
best_val_loss = float('inf')
patience = 5
current_patience = 0
max_epochs = 100
for epoch in range(max_epochs):
# 训练步骤
model.train()
train_loss = train_one_epoch(model, train_loader)
# 验证步骤
model.eval()
with torch.no_grad():
val_loss = val_one_epoch(model, val_loader)
# 早停判断
if val_loss < best_val_loss - 0.0001: # 满足最小改善幅度
best_val_loss = val_loss
current_patience = 0 # 重置耐心值
# 保存最优权重(见下文"模型权重保存")
torch.save(model.state_dict(), 'best_model.pth')
else:
current_patience += 1
if current_patience >= patience:
print(f"早停触发:epoch {epoch+1},验证损失无改善")
break # 停止训练4. 早停的注意事项
2. 保存的核心内容
深度学习模型的 "权重" 本质是模型中可学习的参数(如卷积核、全连接层的权重矩阵)
-
必须有独立验证集:验证集不能与训练集重叠,否则无法反映泛化能力(早停会失效)。
-
避免监控训练集指标 :若监控
loss(训练集损失),早停会永远不触发(训练损失持续下降),导致过拟合。 -
restore_best_weights的重要性 :若不设置为True,早停后模型会保留 "最后一个 epoch" 的权重(可能已过拟合),而非 "验证集最优" 的权重。 -
patience的选择 :根据任务调整,简单任务(如 MNIST 分类)可设3-5,复杂任务(如 CNN 图像分割)可设10-20(避免因指标波动误停)二、模型权重保存(Model Checkpointing)
1. 核心目的:为什么要保存权重?
-
保留最优模型:训练过程中验证集性能最好的权重(用于最终部署)。
-
断点续训:训练中断(如服务器宕机、手动停止)后,可加载中间权重继续训练,无需从头开始。
-
复现实验:保存权重便于后续复现结果、微调模型。
3. 主流框架实现
(1)TensorFlow/Keras 保存权重
Keras 提供ModelCheckpoint回调函数,可与早停搭配,自动保存最优权重
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
# 定义权重保存回调(保存验证集最优权重)
checkpoint = ModelCheckpoint(
filepath='best_model_keras.h5', # 保存路径(.h5格式)
monitor='val_loss', # 与早停监控同一指标
mode='min',
save_best_only=True, # 只保存最优模型(关键)
save_weights_only=False, # False:保存整个模型(结构+权重);True:仅保存权重
verbose=1 # 保存时打印日志
)
# 搭配早停(注意:早停的restore_best_weights可省略,直接加载checkpoint文件)
early_stopping = EarlyStopping(monitor='val_loss', patience=5, mode='min')
# 训练时传入两个回调
model.fit(
x_train, y_train,
validation_data=(x_val, y_val),
epochs=100,
callbacks=[early_stopping, checkpoint]
)
# 加载权重(后续使用)
model.load_weights('best_model_keras.h5') # 仅加载权重(需先定义相同结构的模型)
# 或加载整个模型(无需提前定义结构)
from tensorflow.keras.models import load_model
loaded_model = load_model('best_model_keras.h5')2)PyTorch 保存权重
PyTorch 中常用torch.save()保存,torch.load()加载,需注意 "模型结构与权重匹配":
import torch
import torch.nn as nn
# 1. 定义模型结构(示例)
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.fc = nn.Linear(10, 1)
def forward(self, x):
return self.fc(x)
model = SimpleModel()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
# 2. 保存权重(三种常见场景)
## 场景1:仅保存最优权重(State Dict,推荐部署)
torch.save(model.state_dict(), 'best_model_pytorch.pth')
## 场景2:保存断点(用于续训,包含权重+优化器+epoch)
checkpoint = {
'epoch': 20, # 当前epoch
'model_state_dict': model.state_dict(), # 模型权重
'optimizer_state_dict': optimizer.state_dict(), # 优化器状态(学习率等)
'val_loss': 0.123, # 当前验证损失
}
torch.save(checkpoint, 'checkpoint_pytorch.pth')
# 3. 加载权重
## 场景1:加载仅权重(需先定义模型结构)
loaded_model = SimpleModel() # 必须先实例化相同结构的模型
loaded_model.load_state_dict(torch.load('best_model_pytorch.pth'))
loaded_model.eval() # 部署前需切换到评估模式(禁用Dropout、BatchNorm更新)
## 场景2:加载断点(续训)
checkpoint = torch.load('checkpoint_pytorch.pth')
loaded_model = SimpleModel()
loaded_optimizer = torch.optim.Adam(loaded_model.parameters(), lr=1e-3)
loaded_model.load_state_dict(checkpoint['model_state_dict'])
loaded_optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
start_epoch = checkpoint['epoch'] + 1 # 从下一个epoch继续训练
best_val_loss = checkpoint['val_loss']
# 继续训练
for epoch in range(start_epoch, 100):
train_one_epoch(loaded_model, loaded_optimizer, train_loader)
# ...(3)PyTorch Lightning 保存权重
Lightning 内置ModelCheckpoint回调,与早停无缝搭配:
from pytorch_lightning.callbacks import ModelCheckpoint, EarlyStopping
# 定义权重保存回调
checkpoint = ModelCheckpoint(
dirpath='./checkpoints/', # 保存目录
filename='best-model-{epoch:02d}-{val_loss:.4f}', # 文件名(包含epoch和损失)
monitor='val_loss',
mode='min',
save_best_only=True, # 只保存最优模型
save_weights_only=False, # 保存整个模型(LightningModule)
)
# 搭配早停
early_stopping = EarlyStopping(monitor='val_loss', patience=5, mode='min')
# 训练
trainer = Trainer(
callbacks=[early_stopping, checkpoint],
max_epochs=100,
default_root_dir='./logs/'
)
trainer.fit(model, train_loader, val_loader)
# 加载最优模型
from pytorch_lightning import Trainer
loaded_model = SimpleModel.load_from_checkpoint(checkpoint.best_model_path)