条带化
条带(stripe)是把连续的数据分割成大小相同的数据块,把每个数据库写入不同的磁盘的方法。
1)条带大小(stripe_unit):每个数据块的大小,如:RBD默认4M,那么12M的数据大小就会占3个stripe_unit。
2)条带宽度(stripe_count):image可以存储在多少个磁盘中,如:RBD 3副本,12M的数据就可以存储在3个OSD上。
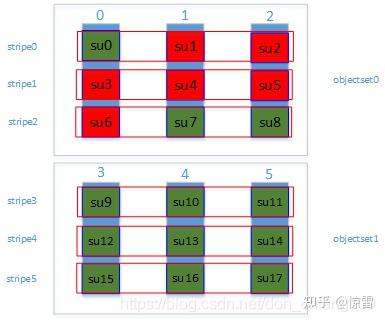
蓝色柱状:代表一个个Rados底层对象,默认4M;
绿色块su:代表了条带单元stripe_unit;
红色框stripe:代表了一个个条带;
objectset:代表对象组,一般一个对象组属于同一个文件。
object_size:对象的大小,就是Rados底层对象的大小,一般默认是4M;
su:对象分片大小,以上图例就是4/3 M;
stripe_count:条带宽度,也就是一个stripe横跨多少个对象,即:一个objectset中对象的个数,以上图例中stripe_count=3;
stripes_per_object:一个对象包含的对象分片数,以上图例中stripes_per_object=3;
Striper::file_to_extents()函数就是以RAID0的思想来分片,一个个条带连起来可以看成是逻辑上连续的,相当于线性的一堆地址空间,现在通过Striper::file_to_extents()函数,把一维坐标转换成三维坐标(objectset, stripeno, stripepos),这三位坐标分别表示哪一个objectset,哪一个stripe(条带),条带中的哪一个su(对象分片)。
这里假设一个对象大小3M,一个对象分片大小是1M,假如要读的文件占2个objectset,占了6个Rados对象,18个对象分片。要读取的对象分片序号是从第1第6,也就是文件的2M7M,相应的变量:
offset = 1M 表示读偏移量
len = 6M 表示要读取的大小
su = 1M
object_size = 3M
stripe_count = 3
stripes_per_object = 3
比如读取su1,经过地址空间转换:
一维地址空间:(offset, len) -> (1M, 6M)
三维地址空间:(objectset, stripeno, stripepos) -> (objectset0, stripe0, object1)
分析
📌 "file striping"就是"把文件切分成 object"这件事的正式名称和定义。
它告诉我们:
文件不是直接写进单个对象,而是被分成一段一段(stripe unit)后按规则轮流写到多个 object 上。
也就是说:
file striping = 依据 layout 切分成 object extents
striping 就是 object 切分逻辑,只不过文档里用的是"条带化存储"的术语。
| 字段 | 含义 |
|---|---|
| stripe unit | 小块数据单位(所有 chunk 都一样大小,除了最后一块可能不满) |
| stripe count | 一个条带跨几个 object |
| object size | 每个 object 最大能容纳多少条带 총量 |
write(file_offset, len)
↓
客户端根据 layout 切分
→ (object_no, object_offset, length)
↓
只有 object_no 被用来生成
↓
object_name
↓
hash(object_name + namespace)
↓
stable_mod
↓
PG
objectset的作用
你的理解已经非常接近"源码级正确"了 ,只差最后一个关键点:
👉 为什么在条带化(Striper)里还要引入 objectset 这个概念。
我先确认你的主线理解是对的 ,然后专门把 objectset 单独拎出来讲清楚,不用绕代码。
一、先确认:你这句话整体对不对?
你说的是:
写入一个文件
→ 调用
Striper::file_to_extents()→ 把文件条带化
→ 写入 object
→ 再映射到 PG
✔️ 结论:这条主线是完全正确的
更精确一点是:
text
write(file_offset, len)
↓
Striper::file_to_extents()
↓
得到一组 (object_no, object_offset, len)
↓
为每个 object_no 生成 object_name
↓
object_name + locator → 映射到 PG你理解得没有方向性错误。
二、那现在只剩一个问题:为什么要有 objectset?
我们直接回答这个问题。
三、objectset 是什么(一句话定义)
objectset 是"一组并行参与条带化的 object 的集合"。
- 它不是额外的对象
- 不是元数据
- 只是 编号规则里的一个"分组概念"
四、如果没有 objectset,会发生什么?(先看反例)
假设:
stripe_unit = 1MBstripe_count = 4- 没有 objectset
- object_no 就简单地一直轮转:
text
object 0
object 1
object 2
object 3
object 0
object 1
object 2
object 3
......问题来了 👇
❌ 问题 1:object 会无限长
-
object 0 会:
- offset 0MB
- offset 4MB
- offset 8MB
- offset 12MB
- ......
-
object 永远写不完
这会导致:
- 单 object 过大
- recovery / scrub / backfill 非常慢
- 单 object 成为热点
👉 Ceph 明确不允许 object 无限增长
五、objectset 的核心目的:控制 object 的"生命周期大小"
objectset 的作用可以总结为一句话:
"当一组 object 写满后,整体换一批新的 object 继续用。"
这就是 object_size 存在的真正意义。
六、objectset 是如何工作的(直觉版)
假设:
stripe_unit = 1MBstripe_count = 4object_size = 4MB
那么:
-
每个 object 最多装
4MB -
每个 object 能装
4 个 stripe_unit -
一组 object(objectset)包含:
textobject 0, 1, 2, 3
写入顺序是这样的:
objectset 0
text
第 1MB → object 0
第 2MB → object 1
第 3MB → object 2
第 4MB → object 3
第 5MB → object 0
第 6MB → object 1
第 7MB → object 2
第 8MB → object 3到这里:
- object 0~3 每个都写满 4MB
- objectset 0 用完
objectset 1(新的一批)
text
第 9MB → object 4
第 10MB → object 5
第 11MB → object 6
第 12MB → object 7
......👉 object_no 不是无限轮转,而是"批次式轮转"
七、objectset 在编号里的真实作用
现在你可以理解这个公式了:
text
object_no = objectsetno * stripe_count + stripepos含义拆开就是:
stripepos:在当前这一组里的第几个 object(0 ~ stripe_count-1)objectsetno:第几"批" object- 每一批 =
stripe_count个 object
objectset 只是 object_no 计算中的"批次编号"
八、objectset 和 PG / CRUSH 有关系吗?
❌ 直接关系:没有
✔️ 间接关系:有
原因:
- 不同 objectset → 不同 object_no
- 不同 object_no → 不同 object_name
- 不同 object_name → hash 不同 → PG 不同
👉 objectset 的意义在于:让 object 数量随文件增长而扩展,从而自然扩散到更多 PG / OSD
九、再用一句大白话总结 objectset(很重要)
stripe 决定"怎么轮流写",
objectset 决定"什么时候换一批新的 object"。
或者更直白一点:
objectset 是为了防止 object 无限变大,同时让文件增长时自动扩散到更多 object。
十、把你的原问题完整回答一遍(最终版)
是的,写文件时会通过
Striper::file_to_extents()把文件按 layout 条带化,生成一组对象级 IO;随后每个 object 会独立映射到 PG。引入 objectset 的原因,是为了在条带轮转的同时限制单个 object 的最大大小(object_size),当一组 object 写满后,整体切换到下一组 object,既避免 object 无限增长,又有利于后续的 PG 分布和并行处理。
一、总体主线(先立一条不会错的主干)
Ceph 中所有数据路径都遵循同一条主线:
文件 / 块(上层视角)
→ object(客户端切分)
→ PG(hash 决定)
→ OSD(CRUSH 决定)
切分发生在客户端,映射发生在 object 层。
二、第一阶段:文件 / 块如何切分为 object(客户端侧)
2.1 切分发生在哪里(明确边界)
切分为 object 永远发生在客户端侧,不在 OSD,不在 CRUSH。
| 使用方式 | 切分位置 |
|---|---|
| RBD(krbd) | Linux 内核 drivers/block/rbd.c |
| RBD(librbd) | Ceph 仓库 src/osdc/Striper.cc |
| CephFS(kernel) | 内核 fs/ceph/*(writeback 阶段) |
| CephFS(fuse / libcephfs) | Ceph 仓库 Striper.cc |
👉 OSD 从来不"切文件",只接收 object。
2.2 切分依据:layout(统一抽象)
不论 RBD 还是 CephFS,切分都基于 layout:
text
layout = {
stripe_unit,
stripe_count,
object_size,
pool_id
}含义:
stripe_unit:最小切分粒度stripe_count:并行分布到多少个 objectobject_size:单个 object 最大大小
2.3 切分结果是什么(非常重要)
一次写入:
text
write(file_offset, len)在客户端被切分为若干 对象级 IO 描述:
text
ObjectExtent {
object_no, // 第几个 object
object_offset, // object 内偏移
length, // 本次写入长度
buffer_mapping // 对应用户 buffer 的哪一段
}👉 到这一步为止:
- 文件 / inode / image 的概念 已经消失
- 后续流程 只认 object
三、第二阶段:object 的身份是什么(必须先讲清)
3.1 一个 object 的完整身份
在 Ceph 中,一个 object 由三样东西唯一确定:
text
(pool, object_locator, object_name)也可以简写为:
text
(object_name, object_locator, pool_id)3.2 object_name(OID,本质是字符串)
这是 RADOS 层真正看到的对象名。
不同上层系统生成规则不同:
| 场景 | object_name 组成 |
|---|---|
| CephFS | <inode>.<object_no> |
| RBD | rbd_data.<image_id>.<object_no> |
| RGW | bucket_id + object_key + part |
示例
CephFS:
text
10000000000001.0
10000000000001.1RBD:
text
rbd_data.3f2c9a6e7b8a.0
rbd_data.3f2c9a6e7b8a.1👉 这就是你看到的 "ino + ono",只是 CephFS 的一种实现方式。
3.3 object_locator(oloc)
object_locator 是 object 的"定位信息",主要包含:
pool_idnamespace
作用:
- 决定 object 属于哪个 pool
- namespace 用于同一 pool 内的逻辑隔离
- 参与 object → PG 的 hash
3.4 pool_id
-
pool 的唯一标识
-
关联:
pg_numpgp_numcrush rule
四、第三阶段:object 如何映射到 PG(核心流程)
注意:layout 在这里已经不参与了。
4.1 object → PG 的输入
只使用以下信息:
text
object_name
object_locator (namespace + pool_id)
OSDMap(pg_num / pgp_num)4.2 第一步:计算 hash seed
在函数:
text
OSDMap::object_locator_to_pg()逻辑是:
text
if (object has key)
hash(key + namespace)
else
hash(object_name + namespace)- 使用 hash 算法:
rjenkins - 得到结果:
text
seed (u32)4.3 第二步:seed → PG number
text
pg_ps = stable_mod(seed, pg_num, pgp_num)最终得到:
text
pgid = (pool_id, pg_ps)👉 到这里,PG 已经唯一确定。
五、第四阶段(补全):PG 如何映射到 OSD
虽然你重点是 PG,但链路必须完整。
text
pgid
↓
CRUSH(rule)
↓
up OSD set
↓
acting OSD setCRUSH 的输入随机种子来自:
text
pps = hash(pg_ps + pool_id)六、把完整流程压缩成一条"因果链"(最终版)
text
write(file_offset, len)
↓
客户端根据 layout
→ 切分为 (object_no, object_offset, len)
↓
生成 object_name + object_locator
↓
hash(object_name + namespace)
↓
stable_mod → PG
↓
CRUSH(PG) → OSD七、最容易混的点,统一纠正(你现在可以完全避免)
❌ OSD 切分文件
❌ layout 参与 PG 映射
❌ inode / image_id 参与 CRUSH
❌ OSD 知道"文件"
✅ object 在客户端切分
✅ PG 是 hash 算出来的
✅ CRUSH 只负责 PG → OSD
✅ OSD 只认 object
这是一个非常本质、而且问得很"工程师"的问题 。
你其实在问两件事:
- 数据被条带化、打散到很多 object 里,还"好管理"吗?
- 读文件时怎么办?难道要把这些 object 再拼回来?
答案先给你一句 不拐弯的结论,然后再慢慢展开:
条带化在 Ceph 里不仅"方便管理",而且是"更容易管理";
读文件时确实要"拼回来",但这个拼装是自动、并行、对应用透明的。
下面我分层给你讲。
一、先回答第一个问题:这样打散数据,真的好管理吗?
直觉上你可能会觉得 ❌
- 数据分散在很多 object
- object 又分散在很多 OSD
- 看起来"更乱了"
但在 Ceph 里,答案是 ✅ 更好管理
原因只有一句话:
Ceph 管理的最小单位本来就是 object,而不是文件。
二、为什么"以 object 为单位"反而更容易管理?
我们从 Ceph 的角度看。
1️⃣ Ceph 不关心"文件",只关心 object
在 OSD 看来:
- 没有"文件"
- 没有"目录"
- 没有"偏移连续性"
只有:
text
object A
object B
object C每个 object 都是:
- 独立的
- 有明确边界
- 可以单独复制、迁移、修复
👉 这正是分布式系统最喜欢的形态
2️⃣ 管理操作全部以 object 为原子
举几个你熟悉但没意识到的例子:
副本同步
- 同步的是:object
- 不是"文件的一部分"
recovery / backfill
- 修的是:object
- 不需要理解文件结构
scrub
- 校验的是:object
- 不需要跨 object 对齐
👉 object 是 Ceph 一切一致性与恢复的最小原子
3️⃣ 如果不条带化,会更难管理
假设:
- 一个 100GB 文件
- 对应 1 个巨大 object
会发生什么?
- recovery 要一次搬 100GB
- scrub 要扫描 100GB
- OSD down → 恢复极慢
- 网络抖动 → 整个 object 重传
👉 这才是"灾难级不可管理"
三、那读文件怎么办?(这是关键)
你问得非常对:
"数据被拆成这么多 object,读文件是不是要拼回来?"
答案是:
✅ 是的,要拼,但这是 Ceph 最擅长的事情
四、读文件的真实流程(一步步来)
我们还是从用户视角开始。
1️⃣ 应用发起 read
text
read(offset = X, length = Y)应用只关心:
- 我要哪一段数据
- 连续的字节流
2️⃣ 客户端做的第一件事(和写时一模一样)
客户端会:
用同一套 striping 规则,算出"这一段数据落在哪些 object 里"。
也就是说:
- 读用的
Striper::file_to_extents() - 和写用的是 同一套算法
👉 条带规则是对称的:写怎么切,读就怎么找
3️⃣ 客户端并行发起 object 读
假设你要读 8MB,结果是:
text
object 0 → 2MB
object 1 → 2MB
object 2 → 2MB
object 3 → 2MB客户端会:
text
同时向 object 0/1/2/3 发起 read而不是一个一个读。
4️⃣ OSD 只做一件事:读 object
每个 OSD:
- 只读自己负责的 object
- 完全不知道这是"文件的一部分"
5️⃣ 客户端自动拼装(关键)
当 object 数据返回后,客户端会:
- 按 offset 排序
- 填充到用户 buffer 对应位置
- 保证顺序正确
这一层拼装逻辑完全在客户端完成。
👉 对应用来说:
text
read() → 得到一段连续的数据五、用一个非常直观的比喻(一定要看)
写文件(条带化)
像是:
把一本书拆成很多页,
每一页分发给不同的仓库保存。
读文件(拼装)
像是:
按页码从不同仓库把页取回来,
按顺序装订成一本书,
你看到的还是完整的一本书。
六、为什么 Ceph 读反而可能更快?
因为读也是并行的
假设:
- stripe_count = 4
- 你读 8MB
结果:
- 4 个 OSD 同时读
- 网络并行
- 磁盘并行
👉 吞吐 ≈ 单 OSD 的 4 倍
七、条带化对"管理"和"性能"的双重好处总结
管理层面
| 好处 | 原因 |
|---|---|
| recovery 快 | object 小 |
| scrub 简单 | object 原子 |
| rebalance 平滑 | object 可迁移 |
| 故障隔离 | 单 object 失败不放大 |
读写性能层面
| 操作 | 效果 |
|---|---|
| 写 | 多 object 并行 |
| 读 | 多 object 并行 |
| 大文件 | 吞吐线性扩展 |
八、你现在应该形成的"最终直觉"
-
Ceph 不是"先有文件再拆"
-
Ceph 是:
一切以 object 为中心,文件只是客户端的抽象
-
条带化不是负担
-
条带化是:
- 为了并行
- 为了可恢复
- 为了可扩展
九、用一句话收尾(你可以直接记住)
Ceph 把文件打散成 object,是为了让"管理更简单、读写更快、恢复更稳";
读文件时的"拼装"是客户端的基本能力,对应用完全透明。
如果你愿意,下一步我可以给你画一张 "读 8MB 文件的并行时间线",和刚才的写时间线对照着看,你会发现读写在 Ceph 里的对称性非常漂亮。