上篇还是唐突了,上来直接打田英,被秒的毫无还手之力。于是先搜了一下整体攻略。
一、node整体架构
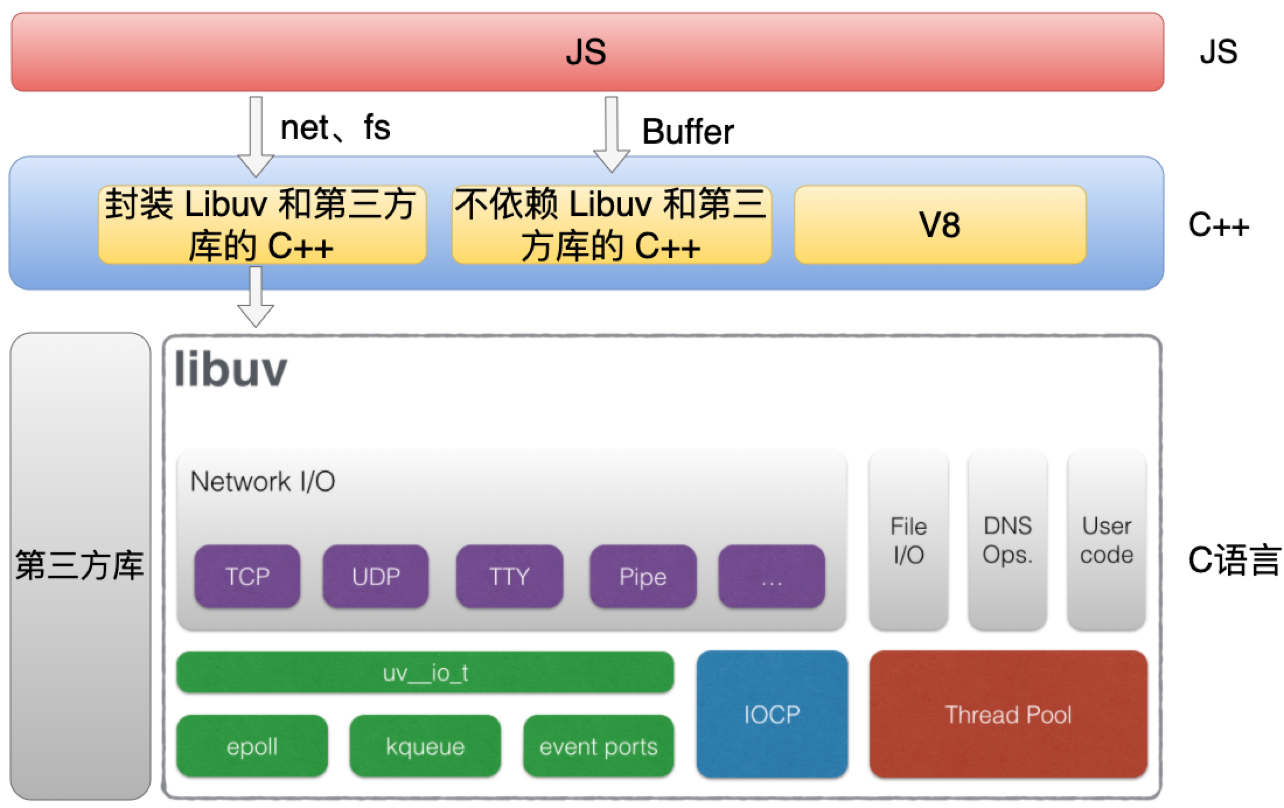
Node.js 代码主要是分为三个部分,分别是C、C++ 和 JS。
- JS 代码就是我们平时在使用的那些 JS 的模块,比方说像 http 和 fs 这些模块。
- C++ 代码主要分为三个部分,第一部分主要是封装 Libuv 和第三方库的 C++ 代码,比如net 和 fs 这些模块都会对应一个 C++ 模块,它主要是对底层的一些封装。第二部分是不依赖 Libuv 和第三方库的 C++ 代码,比方像 Buffer 模块的实现。第三部分 C++ 代码是 V8 本身的代码。
- C 语言代码主要是包括 Libuv 和第三方库的代码,它们都是纯 C 语言实现的代码。
1.Libuv
是一个异步模块 ,c实现的 ,先pass
临时了解一点就是, 阻塞任务是放线程池里的,不阻塞主线程
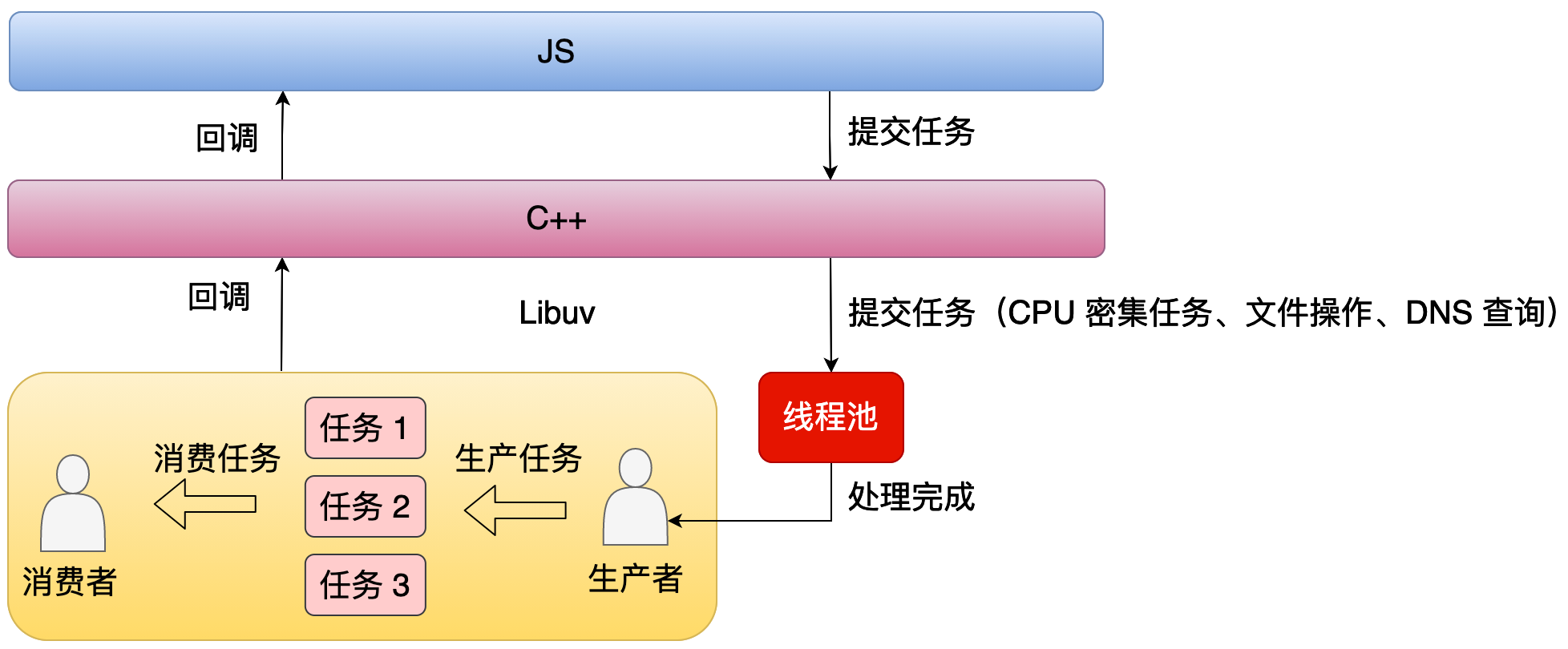
当应用层提交任务时,比方说像 CPU 计算还有文件操作,这种时候不是交给主线程去处理的,而是直接交给线程池处理的。线程池处理完之后它会通知主线程。
2.v8
V8 在 Node.js 里面主要是有两个作用,第一个是负责解析和执行 JS。第二个是支持拓展 JS 能力,作为这个 JS 和 C++ 的桥梁
Isolate:首先第一个是 Isolate 它是代表一个 V8 的实例,它相当于这一个容器。通常一个线程里面会有一个这样的实例。比如说在 Node.js主线程里面,它就会有一个 Isolate 实例。
Node.js 的主线程就是一个 Isolate,都是对立的 ,
Context:Context 是代表我们执行代码的一个上下文,它主要是保存像 Object,Function 这些我们平时经常会用到的内置的类型。如果我们想拓展 JS 功能,就可以通过这个对象实现。
比如chrome两个标签页,通用一个chrome但是互不通上下文
ObjectTemplate:ObjectTemplate 是用于定义对象的模板,然后我们就可以基于这个模板去创建对象。
OFunctionTemplate:FunctionTemplate 和 ObjectTemplate 是类似的,它主要是用于定义一个函数的模板,然后就可以基于这个函数模板去创建一个函数。
FunctionCallbackInfo: 用于实现 JS 和 C++ 通信的对象。
当 JS 调用 C++ 函数时,V8 会把 JS 传过来的参数(Args)、this 指针、返回值的位置,全部打包成一个 FunctionCallbackInfo 对象传给 C++
Handle:Handle 是用管理在 V8 堆里面那些对象,因为像我们平时定义的对象和数组,它是存在 V8 堆内存里面的。Handle 就是用于管理这些对象。****V8 的 Handle 是为了应对对象移动
HandleScope:HandleScope 是一个 Handle 容器,HandleScope 里面可以定义很多 Handle**,它主要是利用自己的生命周期管理多个 Handle。**


这个demo 就是新增了一个自定义的函数,demo.test () ,那我们的document.all呢
先回忆以下document.all:
明明存在,但 typeof 是 'undefined',做 if 判断时是 false,且 == null 为 true),在 V8 的术语中被称为 Undetectable(不可检测的对象)。
plain
v8::Isolate* isolate = v8::Isolate::New(create_params);
v8::Isolate::Scope isolate_scope(isolate);
v8::HandleScope handle_scope(isolate);
//上下文
v8::Local<v8::Context> context = v8::Context::New(isolate);
v8::Local<v8::ObjectTemplate> ghost_template =v8::ObjectTemplate::new(isolate);
ghost_template->MarkAsUndetectable();
ghost_template->Set(isolate,"name",v8::String::NewFormUf8Literal(isolate,"im a goase");
// 实例化对象 编译
v8::Local<v8::Object> ghost_instance=ghost_template->NewINstance(context).ToLocalChecked();
//设置全局变量
v8::Local<Object> globalInstance = context->Global();
globalInstance->Set(context, v8::String::NewFromUtf8Literal(isolate, "myGhost"), ghost_instance
).Check();
//js里能直接找到myGhost 对象。 3.js和c++的通信

当在 JS 层调用刚才定义 test 函数时,就会相应的执行 C++ 层的 test 函数。这个函数有一个入参是 FunctionCallbackInfo,在 C++ 中可以通过这个对象拿到 JS 传来一些参数,这样就完成了 JS 层到 C++ 层通信。经过一系列处理之后,还是可以通过这个对象给 JS 层设置需要返回给 JS 的内容,这样可以完成了 C++ 层到 JS 层的通信。
4.加载js的流程
Node.js 中有五种模块加载器。
- JSON 模块加载器
- 不做任何逻辑执行,只是单纯的数据读取。
- 用户 JS 模块加载器
plain
// Node.js 偷偷加的头
(function (exports, require, module, __filename, __dirname) {
// --- 这里面才是你写的代码 ---
const a = 1;
module.exports = a;
// -------------------------
// Node.js 偷偷加的尾
});- 原生 JS 模块加载器
- Node.js 自带的模块(如 http, fs)。读内存 -> 包装执行 -> 传入特殊的 internalBinding 用来调 C++。
- 内置 C++ 模块加载器
- Node.js 初始化时注册链表 -> 根据名字找节点 -> 执行钩子。
- Addon 模块加载器
直击核心,怎么把jsdom 内置到node ,方便后面补环境直接内置,2. 怎么让js调用走到我们自己的c++函数里,要hook哪个函数吗还是有拦截器 ,ai答案如下:
第一部分:怎么把 jsdom 内置到 Node.js 中?
首先你要认清一个事实:jsdom** ****本质上是一个巨大的、纯 JavaScript 写的库**,它并不是 C++ 模块。它依赖了 parse5, tough-cookie, cssstyle 等几十个其他 npm 包。
如果你想让 Node.js 一启动就自带 jsdom(不需要 npm install),通常有两条路:
方案 A:使用 Node.js 的快照功能(Snapshot)------ 推荐
这是 Node.js 18+ 提供的现代方案。你可以把 jsdom 加载到内存堆中,然后把这个堆"保存"下来。下次启动 Node.js 时,直接恢复这个堆,jsdom 就已经在里面了。
步骤逻辑:
- 写一个脚本 snapshot.js,里面 require('jsdom') 并挂载到 global。
- 编译 Node.js 时使用 --build-snapshot 参数或者运行时生成快照。
- 分发这个带有快照数据的 Node.js 二进制文件。
这种方式不需要修改 Node.js 源码,只是利用了 V8 的快照机制。
方案 B:硬改 Node.js 源码(把 JS 打包进二进制)------ 极难
如果你非要像 http 或 fs 模块一样把 jsdom 内置进 Node.js 源码:
- 移动文件 :你需要把 jsdom 及其所有依赖包(这非常多)的源码放到 Node.js 源码的 lib/ 目录下(或者 deps/ 目录)。
- 修改构建脚本:修改 node.gyp,把这些新加入的 JS 文件列入编译列表。Node.js 在编译时会把 lib/ 下的 JS 文件转成 C++ 里的字符数组(这就是"内置 JS 模块"的原理)。
- 暴露模块:你需要修改 lib/internal/bootstrap/node.js 或者直接在你的 JS 里使用 internalBinding 来让外部能访问到它。
第二部分:怎么执行自己的函数
就是刚才的 document.all ,做一个函数模板 ,挂载全局
第三部分:是否有拦截器
DOM 有个特性:你访问 window.abc,即使 abc 没定义,浏览器内部也可能去查找 ID 为 abc 的元素。或者 document.body 这种属性,它不是简单的对象属性,而是对应到底层的 Getter。
这就需要用到 V8 的 Accessors (访问器) 和 Interceptors (拦截器/属性处理器)。
场景: 只要 JS 访问 obj.xxx,无论 xxx 是什么,都先走到 C++ 函数里。
plain
// 这是一个"属性拦截器"回调
// property: JS 访问的属性名 (比如 "body", "div1")
// info: 其他信息
void MyPropertyGetter(v8::Local<v8::Name> property,
const v8::PropertyCallbackInfo<v8::Value>& info) {
v8::Isolate* isolate = info.GetIsolate();
v8::String::Utf8Value key(isolate, property);
printf("JS 正在尝试访问属性: %s\n", *key);
// 可以在这里判断,如果是 "body",就返回一个 C++ 包装的 Body 对象
if (strcmp(*key, "body") == 0) {
info.GetReturnValue().Set(v8::String::NewFromUtf8Literal(isolate, "[Body Element]"));
}
// 如果不设置返回值,V8 会继续按正常流程查找属性
}
// 注册拦截器
void SetupGhostObject(v8::Isolate* isolate, v8::Local<v8::ObjectTemplate> templ) {
// SetHandler 用于设置拦截器
// NamedPropertyHandlerConfiguration 专门拦截字符串类型的属性访问
templ->SetHandler(v8::NamedPropertyHandlerConfiguration(MyPropertyGetter));
}这个拦截器 就相当于proxy了,找函数追踪。
后面再找找怎么保护函数 应该就可以了。
二、kale
什么是宏,和函数的区别,哪里用到宏
核心区别对比表
| 特性 | 宏 (#define) | 函数 (Function) |
|---|---|---|
| 处理阶段 | 预处理阶段 (编译之前) | 编译/运行阶段 |
| 本质 | 文本替换 (Copy-Paste) | 代码跳转 (Call/Return) |
| 代码体积 | 变大 (用了多少次就粘贴多少份代码) | 不变 (逻辑只有一份,重复调用) |
| 运行速度 | 极快 (没有调用开销,直接执行指令) | 有微小开销 (压栈、跳转、恢复现场) |
| 参数类型 | 无类型 (什么都能传,容易出错) | 强类型 (类型不匹配会报错) |
| 副作用 | 极大 (如 a++ 被执行多次) | 安全 (参数先计算好再传入) |
| 调试 | 很难 (断点打不到宏内部,看到的代码和执行的不一样) | 容易 (可以单步进入) |
什么情况用宏?(宏的生存空间)
既然函数这么好,为什么还要宏?因为有些事只有宏能做,函数做不到。
1. 想要"获取代码本身的信息"时 (Logging)
函数只能拿到变量的值 ,拿不到变量的名字 ,也拿不到这行代码在第几行。
- 场景:打印日志。
代码:
- codeCdownloadcontent_copyexpand_less
plain
// 函数做不到打印 "__LINE__"(行号),因为它永远只知道它自己被定义在哪一行
#define LOG_ERROR(msg) printf("Error in file %s at line %d: %s\n", __FILE__, __LINE__, msg)2. 想要"控制编译器开关"时 (条件编译)
函数是运行时执行的,但有时候我们需要代码压根就不参与编译。
- 场景:跨平台、调试开关。
代码:
plain
// 平台检测
#ifdef _WIN32
#define PLATFORM "Windows"
#define PATH_SEPARATOR '\\'
#elif __linux__
#define PLATFORM "Linux"
#define PATH_SEPARATOR '/'
#elif __APPLE__
#define PLATFORM "macOS"
#define PATH_SEPARATOR '/'
#endif3. 想要"生成代码"或"拼接变量名"时
函数不能凭空创造变量名,但宏可以。
- 场景:自动生成结构体、反射、路由映射。
代码:
plain
#define DECLARE_VAR(type, name) type name##_variable = 0;
DECLARE_VAR(int, my);
// 展开变成: int my_variable = 0;还有,宏里面 一个# 是转字符串 两个##是拼接。
更多文章,敬请关注gzh:零基础爬虫第一天