1.Redis应用场景
Download the in-memory data store used by millions of developers as a cache, vector database, document database, streaming engine, and message broker.
内存中存储数据。常被用于 缓存、向量数据库、文档数据库、流处理引擎、消息代理;
向量数据库 vs 文档数据库
存储单位 :向量(Vector),即高维数组(通常100-1536维)
核心操作:相似性搜索(Similarity Search)
数据特点:向量是数值型、密集的、固定维度的
存储单位 :文档(Document),通常是JSON/BSON格式
核心操作:CRUD、查询、聚合
数据特点:半结构化、嵌套、可变模式
Redis初心:用来作为一个"消息中间件"(消息队列,分布式系统下的生产者消费者模型),当前作为消息队列运用场景不多。
缓存场景: 对于单机程序,在内存中存数据是比Redis更优的选择;Redis只有在分布式系统中才能发挥威力的。
数据库场景: 相比于MySQL访问硬盘,Redis是访问内存,速度快 ,但容量小;(又大又快:Redis和MySQL结合使用,Redis存放热点数据)
2.从单机架构到微服务
2.1 单机架构
单机架构,应用服务和数据库服务都跑在一台服务器上;
大部分的业务场景,单机架构足以满足(硬件发展好);
如果业务进一步增长,用户量和数据量大,需要引入更多的主机;
一台主机硬件资源受限:1)CPU 2)内存 3)硬盘 4)网络 ......
处理解决方法:
1)开源 -> 简单粗暴的提升硬件资源
2)节流 -> 软件层面解决问题,优化算法,找出主要矛盾;
但是一台主机的主板,硬件拓展能力是有限的 -> 需要引入更多的主机 -> 分布式系统 -> 系统复杂度大大提高,出bug概率变高
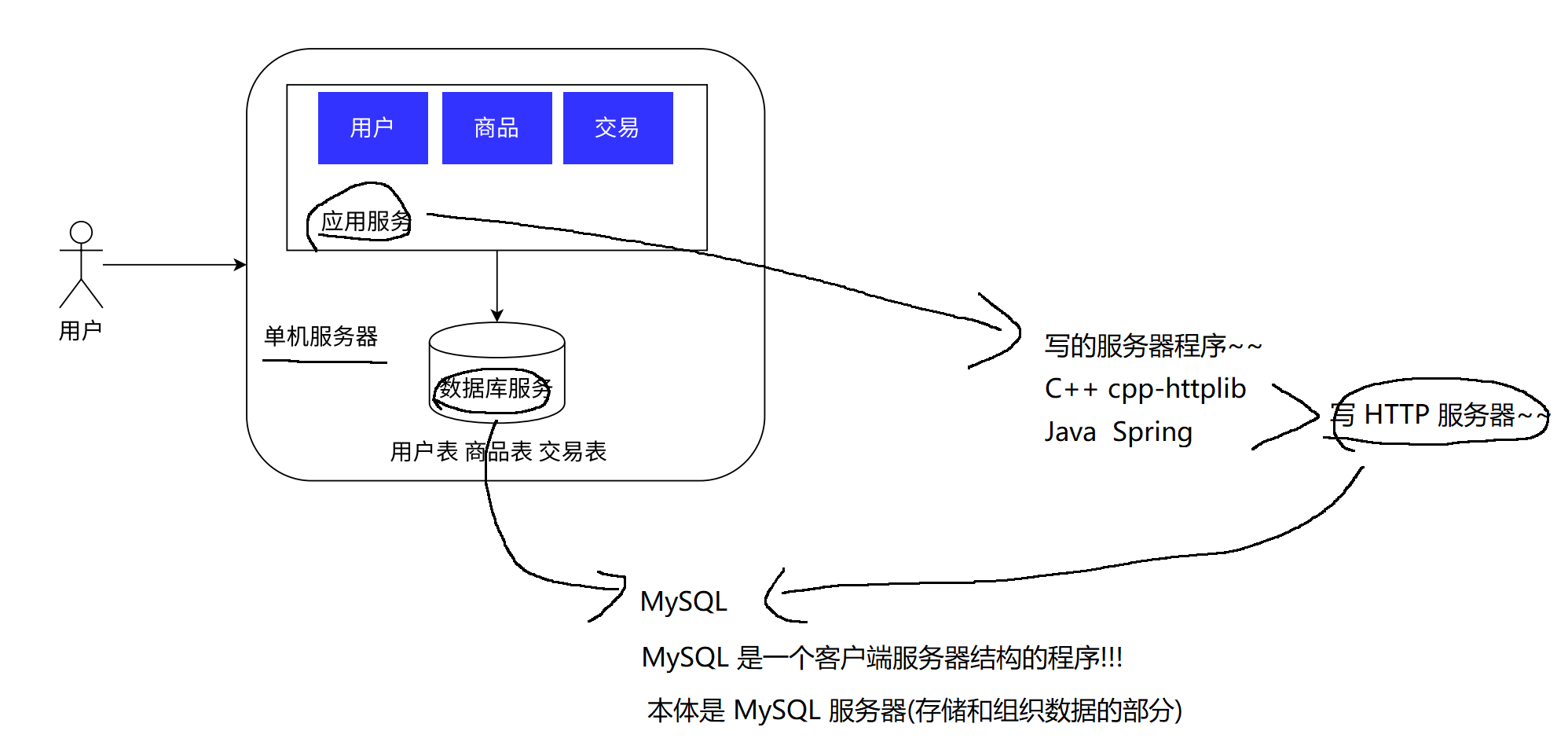
2.2 应用服务和数据库服务分离
应用服务器和存储服务器分离;就可以对症下药了, 应用服务器需要更多的CPU性能,内存,而存储服务器需要更大的容量,更快的读写速度(从而达到更高的性价比)
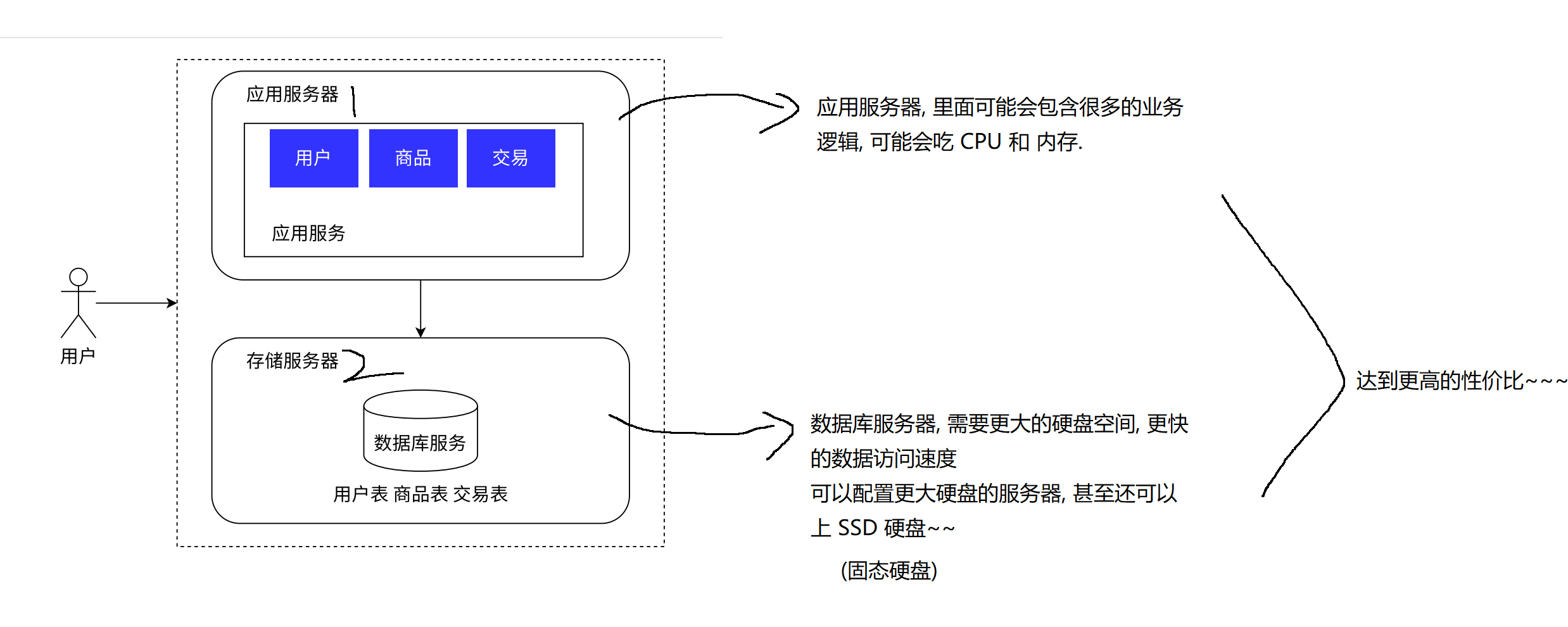
2.3 引入更多的服务器节点(如果请求量很大,一台应用服务器处理不过来)
通过负载均衡器/网关服务器,采用负载均衡的方式分配请求给应用服务器(这些应用服务器跑的业务相同)
负载均衡器只处理分配请求的逻辑,一般来说不会性能瓶颈;也可以有多个负载均衡器情况,例如多个机房。
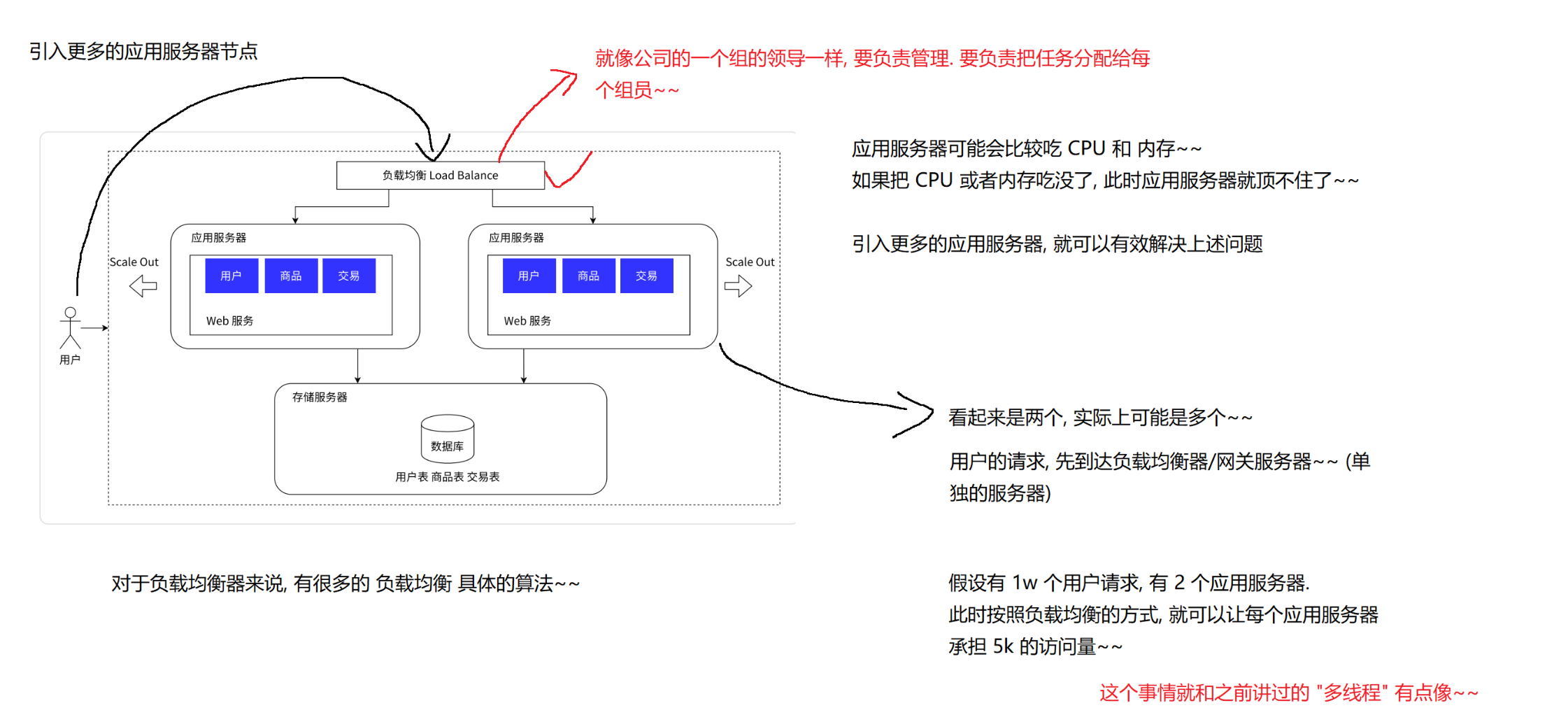
2.4 数据库读写分离(如果数据库请求量很大,一台数据库服务器处理不过来)
为什么是读写分离,而不是完全相同的服务呢?
读操作不修改数据,数据的一致性问题好保证;读操作比写操作频繁很多。
主从(master slave)
一主多从;从数据库的访问也通过负载均衡的方式进行;主数据库修改数据,同步到从服务器。
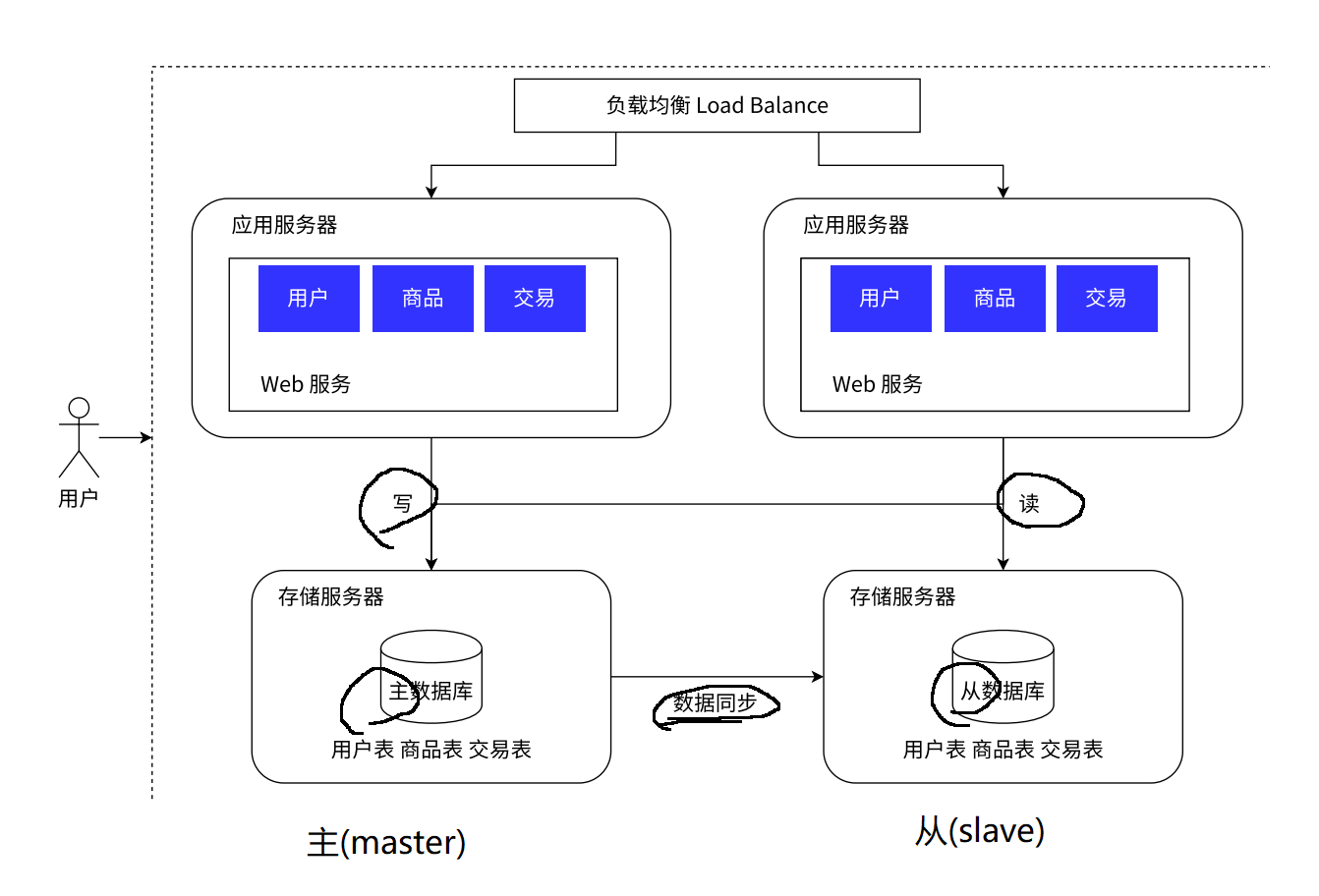
2.5 数据库性能瓶颈(访问硬盘)
引入缓存服务器 -> Redis;
缓存服务器中存放高频访问的热点数据,存储服务器依旧存放全量数据;(28原则)但需要注意缓存数据和数据库数据的数据一致性问题。
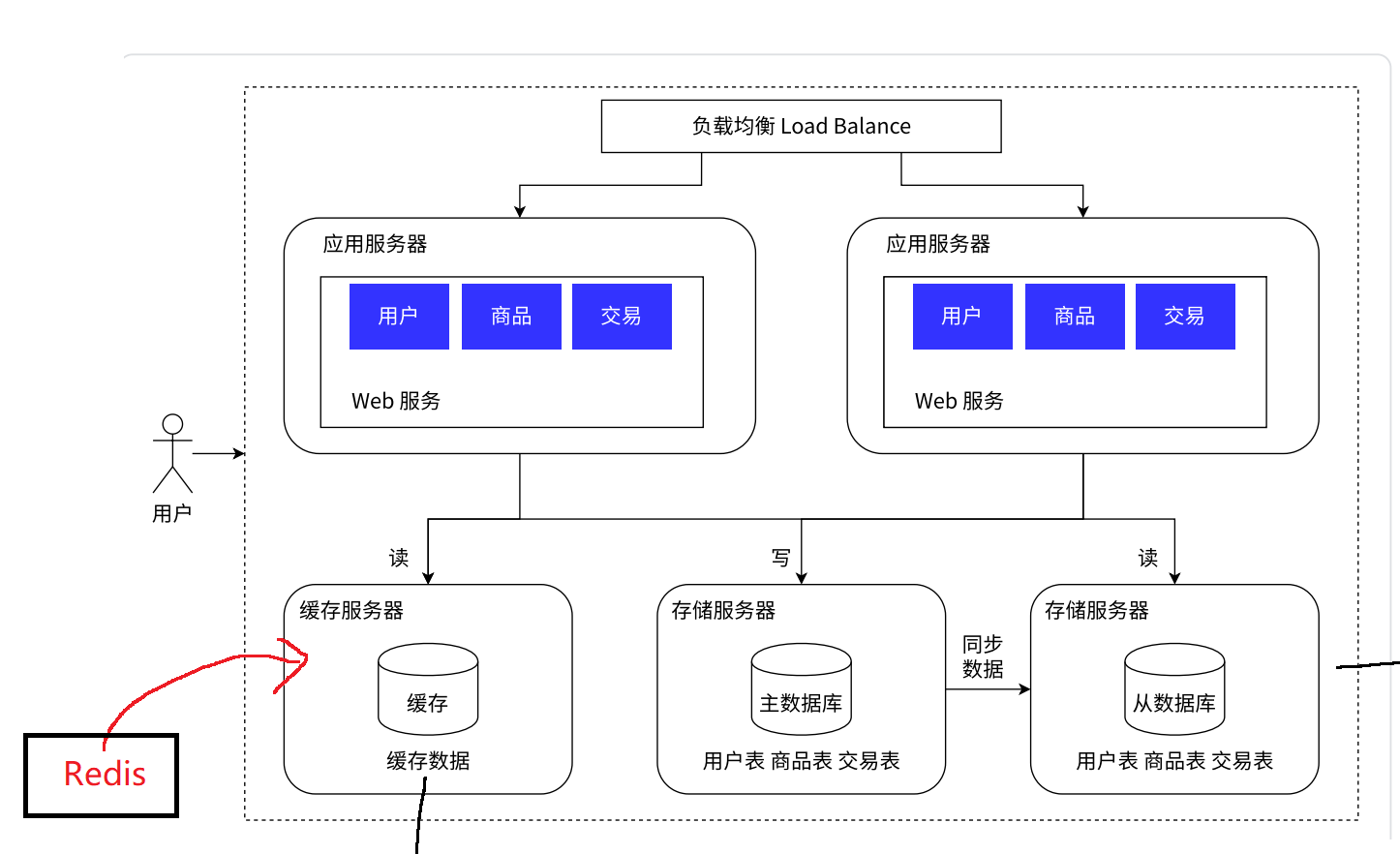
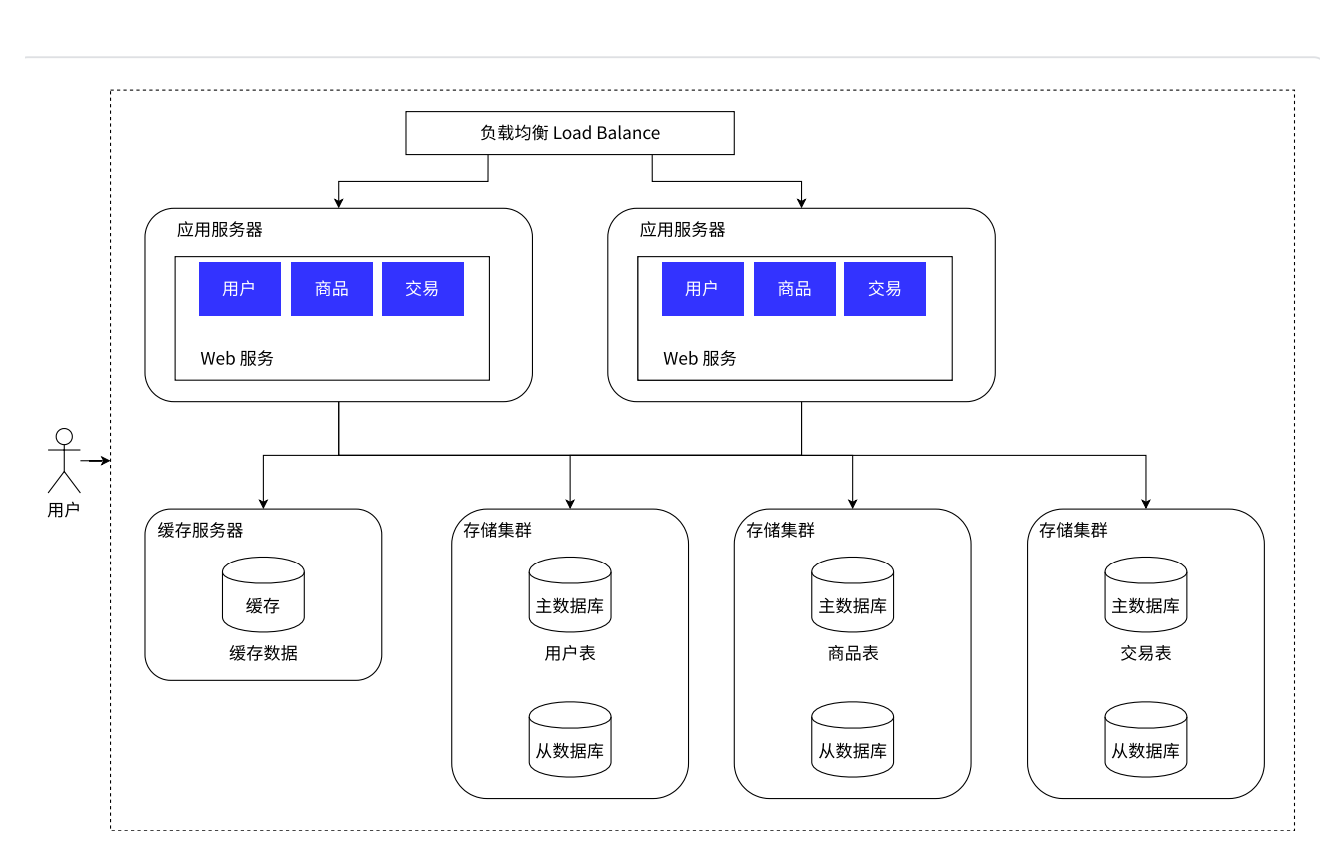
2.6 数据库分库分表**(一台主机的存储容量达到瓶颈了)**
主从数据库为一个存储集群,根据不同的数据库或表划分不同的存储集群(既保证原本的性能,又增加了容量)。
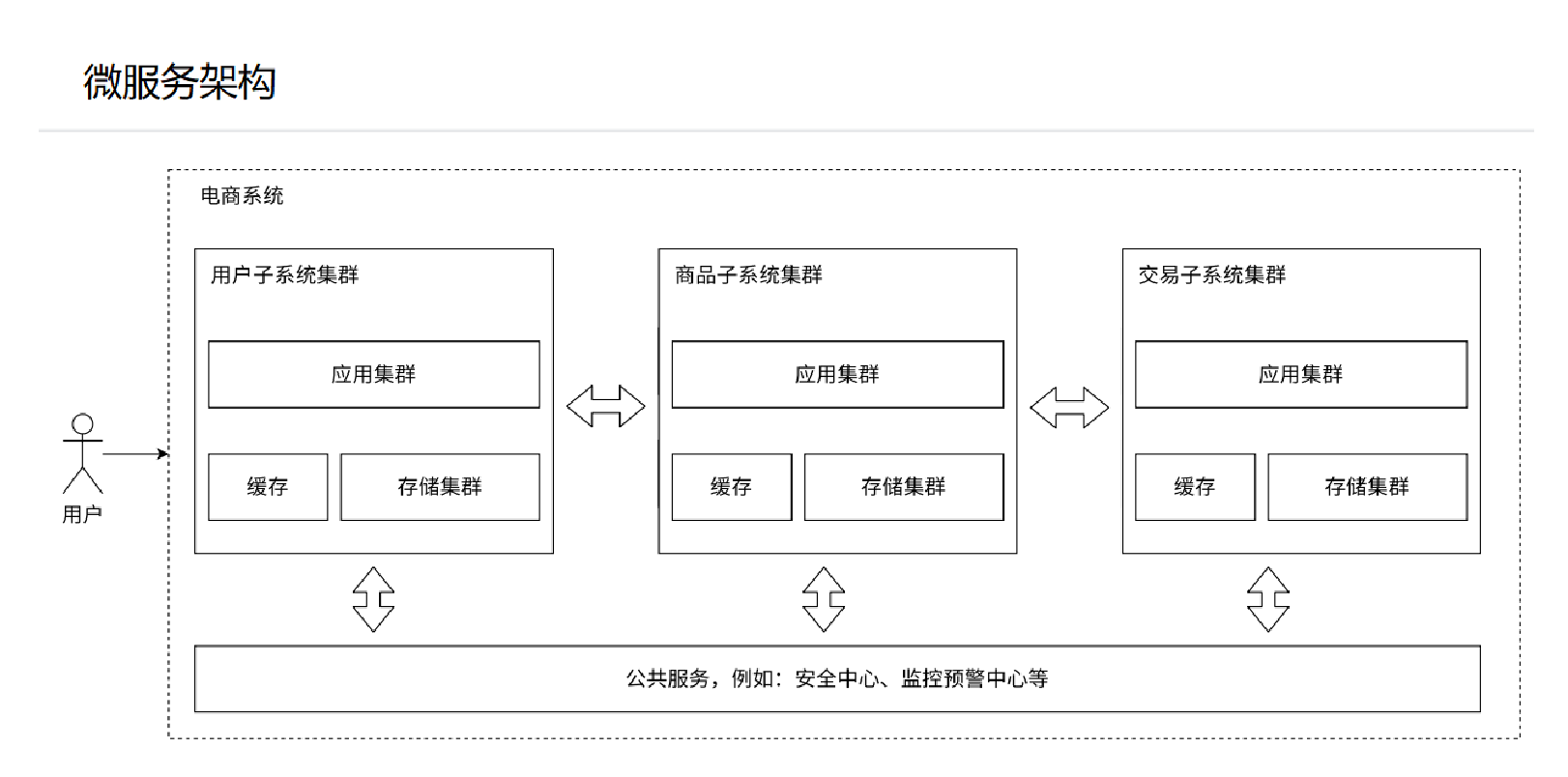
2.7 微服务架构(为了方便人的产出量化和分工)
相比于之前的业务全放在服务器们里面跑,**微服务架构是将业务进行更加细致地拆分,每个业务划分成不同的系统集群,**也抽取出一些公共的服务;
服务器的种类和数量增加了;本质在解决人的问题,划分了业务代码,便于人的管理。
微服务的代价:
**1)系统性能的下降;**各系统集群间是通过网络进行访问的,网络通信速度通常是比硬盘还要慢的;充钱可以解决,万兆网卡;
**2)系统复杂程度提高,可用性受到影响;**服务器变多了,出现问题的概率就更大了;
优势:
1)解决了人的问题
2)便于功能复用
3)按需部署
3.概念补充
1)应用(Application)/系统(System):一个应用,就是一个/一组服务器程序。
2)模块(Module)/组件(Component):一个应用,有很多功能;每个独立的功能就是一个模块/组件。
3)分布式(Distributed): 引入多个主机/服务器,协同配合完成一系列任务**(物理上)**
4)集群(Cluster) :引入多个主机/服务器,协同配合完成一系列任务**(逻辑上)**
5)主(Master)/从(Slave):服务器一主多从,从节点需要从主节点同步数据;
6)**中间件(Middleware):**与具体业务无关,通用的服务(缓存、数据库、消息队列)
7)**可用性(Availability):**系统整体可用时间/总的时间
8)响应时长(Response Time RT):衡量服务器的性能
9)吞吐(Throughput)vs并发(Concurrent):衡量服务器处理请求的能力
4.总结
1.单机架构(应用服务+存储服务)
2.应用和存储分离
3.引入负载均衡,应用服务器集群
4.存储服务器读写分离
5.引入缓存
6.数据库分库分表
7.微服务