TL;DR
- 场景:Logstash 过滤后需要稳定输出到控制台、文件、Elasticsearch,并支持多路复用与条件路由
- 结论:Output 阶段决定吞吐、可靠性与可观测性;参数(批量/重试/缓冲)比"能跑"更关键
- 产出:3 类输出最小可用配置 + 生产组合范式 + 性能与故障速查卡

版本矩阵
| 组件/能力 | 已验证说明 |
|---|---|
| Logstash版本 | 7.3.0 |
| 示例目录结构 | /opt/servers/logstash-7.3.0 |
| stdout输出 | 使用rubydebug codec进行stdin联调与字段验收(最快闭环方式) |
| file输出 | 配置为codec => line格式,动态路径模板%{+YYYY-MM-dd}-%{host}.txt |
| Elasticsearch输出 | 基础写入配置已给出(未标注ES版本,注意7/8版本差异会影响type/参数) |
| 条件路由 | 支持(概念验证) |
| 多输出并行 | 支持(需配合生产环境的队列/重试策略定型) |
Output插件
Logstash Output 插件是 Logstash 管道中的最后一个阶段,负责将处理后的数据输出到各种目标系统或存储设备。每一个输出插件都能将 Logstash 接收到并解析的数据发送到不同的外部服务,如数据库、消息队列、搜索引擎、文件系统等。
工作原理
Logstash 的输出插件(Output Plugins)是数据处理流程的关键环节,负责将经过过滤处理的事件数据高效可靠地推送到各类外部系统。作为 Logstash 管道的最终阶段,输出插件支持多种数据目的地和传输协议,能够满足不同场景下的数据存储和分析需求。
常见的输出插件类型包括:
-
存储系统输出:
- Elasticsearch 输出插件(最常用):将数据索引到 Elasticsearch 集群,支持批量提交和自动重试
- 文件输出插件:将事件写入本地文件系统,支持文件轮转和压缩
- 数据库输出插件:支持 MySQL、PostgreSQL 等关系型数据库
-
消息队列输出:
- Kafka 输出插件:将数据发布到 Kafka 主题
- RabbitMQ 输出插件:通过 AMQP 协议发送消息
-
云服务输出:
- Amazon S3 输出插件:将日志存档到 S3 存储桶
- Google Cloud Storage 输出插件
-
监控系统输出:
- Prometheus 输出插件
- Nagios 输出插件
输出插件通常提供以下关键特性:
- 批量处理能力(bulk processing)
- 自动重试机制(retry on failure)
- 负载均衡支持(multiple endpoints)
- 数据格式转换(如 JSON、CSV 等)
配置示例(输出到 Elasticsearch):
ruby
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "applogs-%{+YYYY.MM.dd}"
document_type => "_doc"
retry_on_failure => 3
}
}在实际生产环境中,通常会采用多输出插件组合的方式,比如同时输出到 Elasticsearch 进行实时分析和文件系统进行长期归档。输出插件的性能调优(如批量大小、工作线程数等参数)对整体数据处理效率有重要影响。
主要功能
- 多种输出目标:支持广泛的输出目标,如 Elasticsearch、Kafka、RabbitMQ、Amazon S3、文件、HTTP、数据库等。
- 批处理:在某些情况下,输出插件可以批量发送数据,而非逐条处理,从而提高性能。例如,Elasticsearch 插件可以配置批量请求,以优化写入性能。
- 数据格式化:插件能够根据需要以特定格式(如 JSON、CSV、Plaintext)输出数据。
- 重试机制:某些输出插件具有自动重试功能,确保在网络故障或系统不稳定时数据不会丢失。
- 动态路由:可以根据事件的内容动态决定数据输出到哪个目标系统。通过条件语句,可以对不同类型的数据使用不同的输出路径。
- 插件配置灵活性:每个插件都有丰富的配置选项,可以定制行为,比如指定目标主机、端口、身份验证机制、缓冲设置、批处理参数等。
高级功能
-
输出负载均衡:Logstash 提供了强大的负载均衡功能,可以配置多个输出目标(如多个 Elasticsearch 节点或多个 Kafka 代理)。Logstash 会自动将数据轮询分发到这些目标,避免单点故障并提高数据传输的吞吐量。例如,在生产环境中可以配置 3 个 Elasticsearch 节点作为输出目标,Logstash 会均匀地将日志事件分发到这些节点,既提高了系统的可用性,又实现了读写负载的均衡分配。
-
事件条件判断:Logstash 支持使用条件语句(如 if/else)对事件进行过滤和路由。可以根据事件字段值动态决定输出目标,实现精细化的日志分发策略。典型应用场景包括:
- 将 ERROR 级别的日志发送到专门的告警系统
- 将不同业务线的日志路由到不同的 Elasticsearch 索引
- 示例配置:
ruby
output {
if [log_level] == "ERROR" {
elasticsearch { ... } # 错误日志专用管道
} else {
kafka { ... } # 普通日志管道
}
}- 插件组合输出 :Logstash 支持在单个管道中并行使用多个输出插件,实现数据的多路复用。常见组合方式包括:
- 存储+转发组合:同时写入 Elasticsearch 和 Kafka
- 主备方案:主要输出到 Elasticsearch,备用输出到文件系统
- 监控方案:在业务输出的同时,将统计指标发送到 Prometheus
- 典型配置示例:
ruby
output {
elasticsearch { ... } # 主要存储
kafka {
topic_id => "log_backup" # 消息队列备份
}
file {
path => "/var/log/logstash/archive.log" # 本地归档
}
}常见问题
-
网络问题:由于输出插件大多与外部系统交互,网络问题可能导致输出失败。常见的网络问题包括:
- 连接超时(如默认 30 秒未建立连接)
- 带宽限制导致数据传输缓慢
- 防火墙或安全组策略阻止访问
- DNS 解析失败 应对方案:
- 重试机制(如指数退避重试,初始间隔 1 秒,最大重试 5 次)
- 内存/磁盘缓冲(如设置 500MB 内存缓冲区,溢出时写入临时文件)
- 心跳检测(每 60 秒发送 ping 包检测连接状态)
-
性能瓶颈:某些输出插件(例如 Elasticsearch、Kafka)在高并发场景下需要调整批处理和缓冲参数:
- Elasticsearch 场景:
- 建议批量大小设置为 500-1000 条/批次
- 并发 worker 数建议为 CPU 核数的 1.5 倍
- 启用压缩传输(设置 gzip 压缩级别为 6)
- Kafka 场景:
- 调整 linger.ms 参数(建议 50-100ms)
- 设置 batch.size 为 16384-32768 字节
- 配置 acks=1 平衡可靠性与性能
- Elasticsearch 场景:
-
数据格式问题:输出的数据格式需要与目标系统兼容,典型场景包括:
- 数据库写入:
- 字段类型映射(如将日志中的字符串 "123" 转换为 INTEGER 类型)
- 时间格式转换(UTC 时间转本地时区)
- 处理字段缺失(设置默认值或跳过空字段)
- API 对接:
- 遵循 OpenAPI 规范定义数据结构
- 处理嵌套 JSON(展平或保留层级结构)
- 添加必要的请求头(如 Content-Type: application/json)
- 特殊字符处理:
- 转义单引号(' → ')
- 处理换行符(\n → \n)
- 编码非 ASCII 字符(使用 UTF-8 编码)
- 数据库写入:
标准输出到控制台
将收集到的数据直接打印到控制台:
shell
cd /opt/servers/logstash-7.3.0
bin/logstash -e 'input{stdin{}}output{stdout{codec=>rubydebug}}'运行之后,对应的结果如下所示: 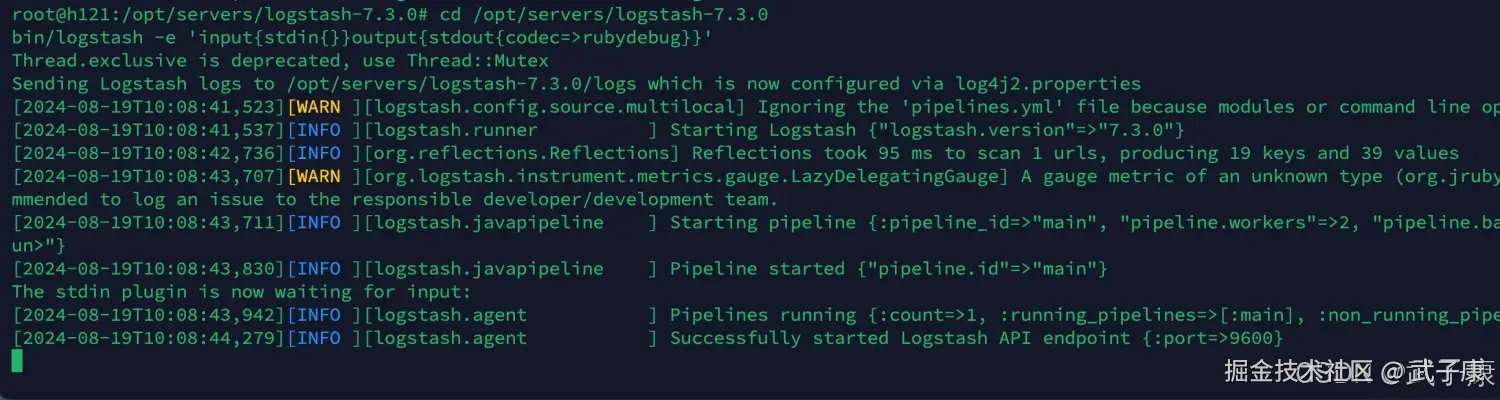
采集的数据保存到文件中
需求描述
Logstash也可以将收集到的数据写入到文件当中去保存,接下来我们看看Logstash如何配置以实现将数据写入到文件当中。
编写配置
shell
cd /opt/servers/logstash-7.3.0/config
vim output_file.conf写入的内容如下:
shell
input {stdin{}}
output {
file {
path => "/opt/servers/es/%{+YYYY-MM-dd}-%{host}.txt"
codec => line {
format => "%{message}"
}
flush_interval => 0
}
}写入的内容截图如下所示: 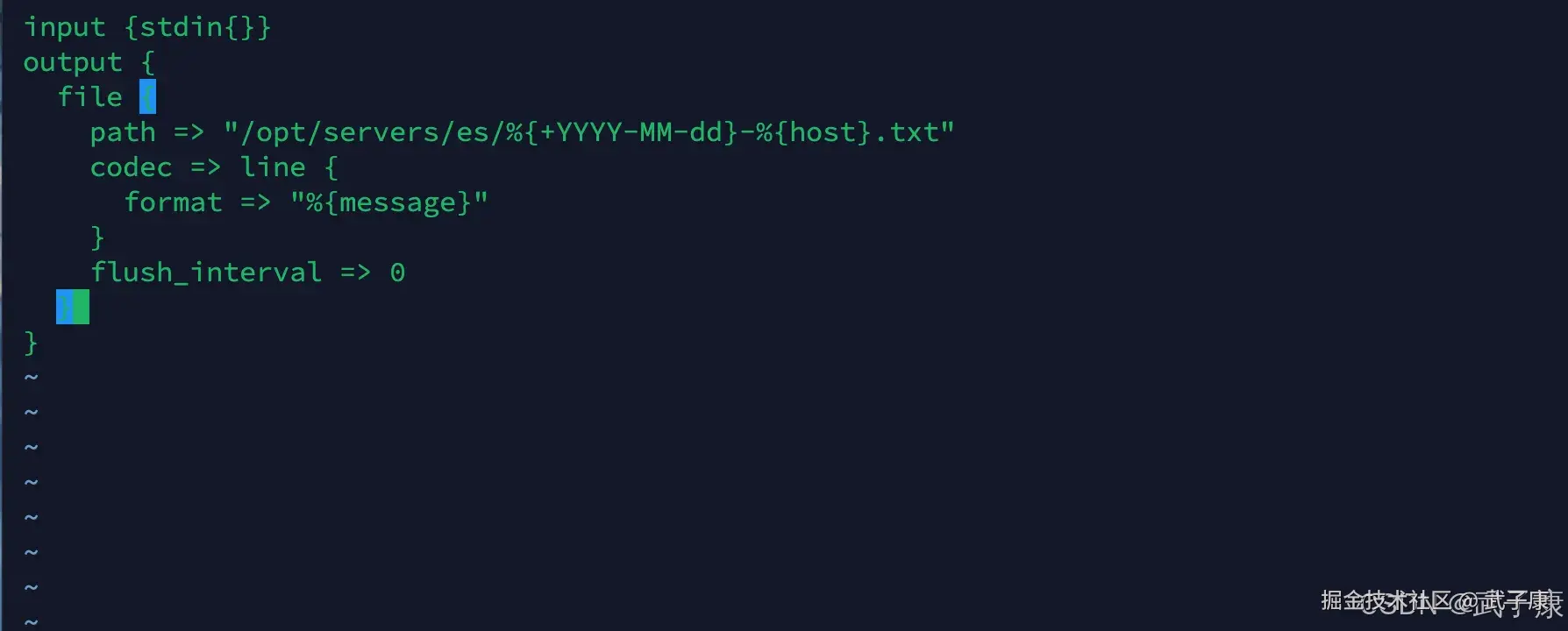
检查配置
shell
cd /opt/servers/logstash-7.3.0
bin/logstash -f /opt/servers/logstash-7.3.0/config/output_file.conf -t 检查结果如下图所示: 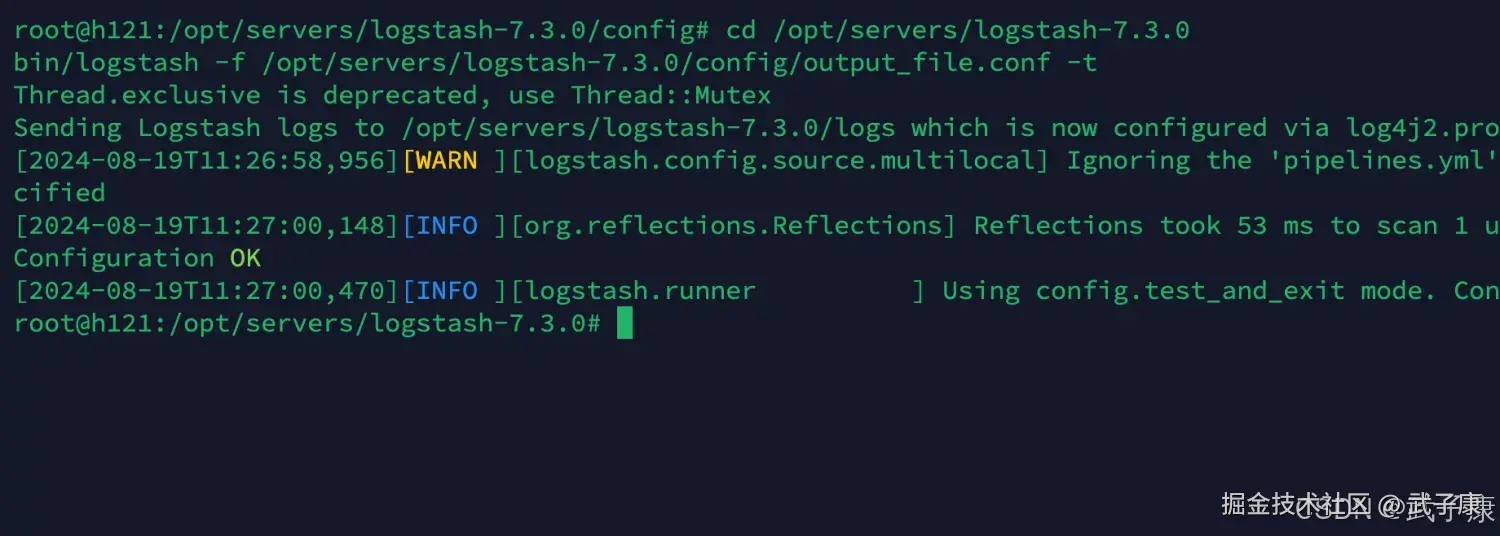
启动配置
shell
cd /opt/servers/logstash-7.3.0
bin/logstash -f /opt/servers/logstash-7.3.0/config/output_file.conf启动的结果如下图所示: 
测试数据
我们在控制台中输入一些测试的内容,然后查看输出的文件的内容:
shell
hello wzk icu!查看的结果如下图所示: 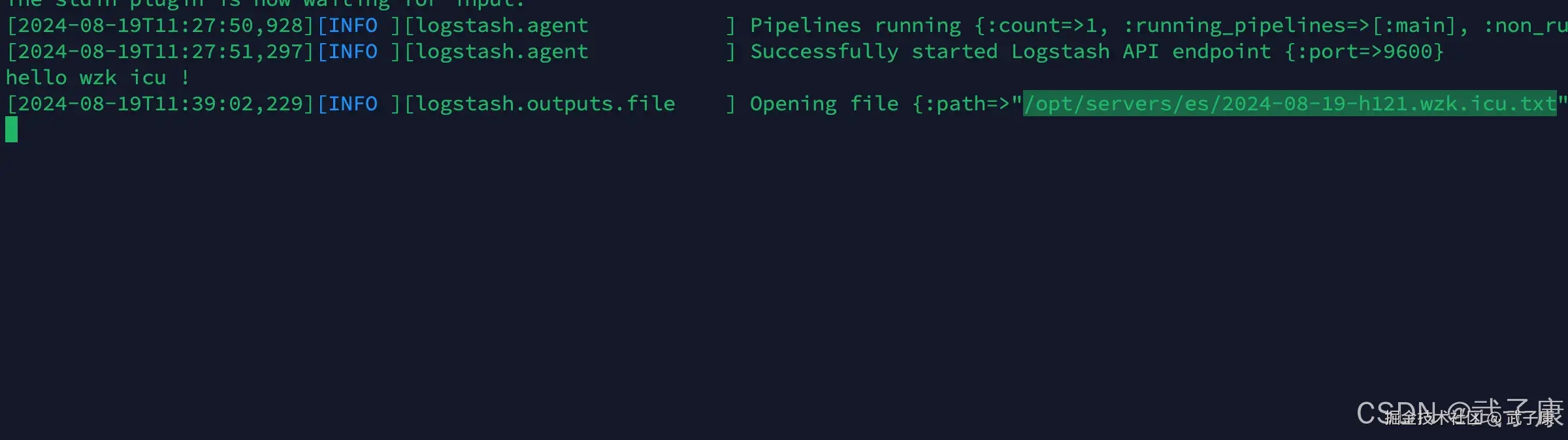
查看内容:
shell
cat /opt/servers/es/2024-08-19-h121.wzk.icu.txt结果如下图所示: 
采集数据保存到Elasticsearch
需求描述
不过多描述,主要就是把收集到的数据写入到Elasticsearch中。
编写配置
shell
cd /opt/servers/logstash-7.3.0/config
vim output_es.conf写入的内容如下:
shell
input {stdin{}}
output {
elasticsearch {
hosts => ["h121.wzk.icu:9200"]
index => "logstash-%{+YYYY.MM.dd}"
}
}对应的截图如下所示: 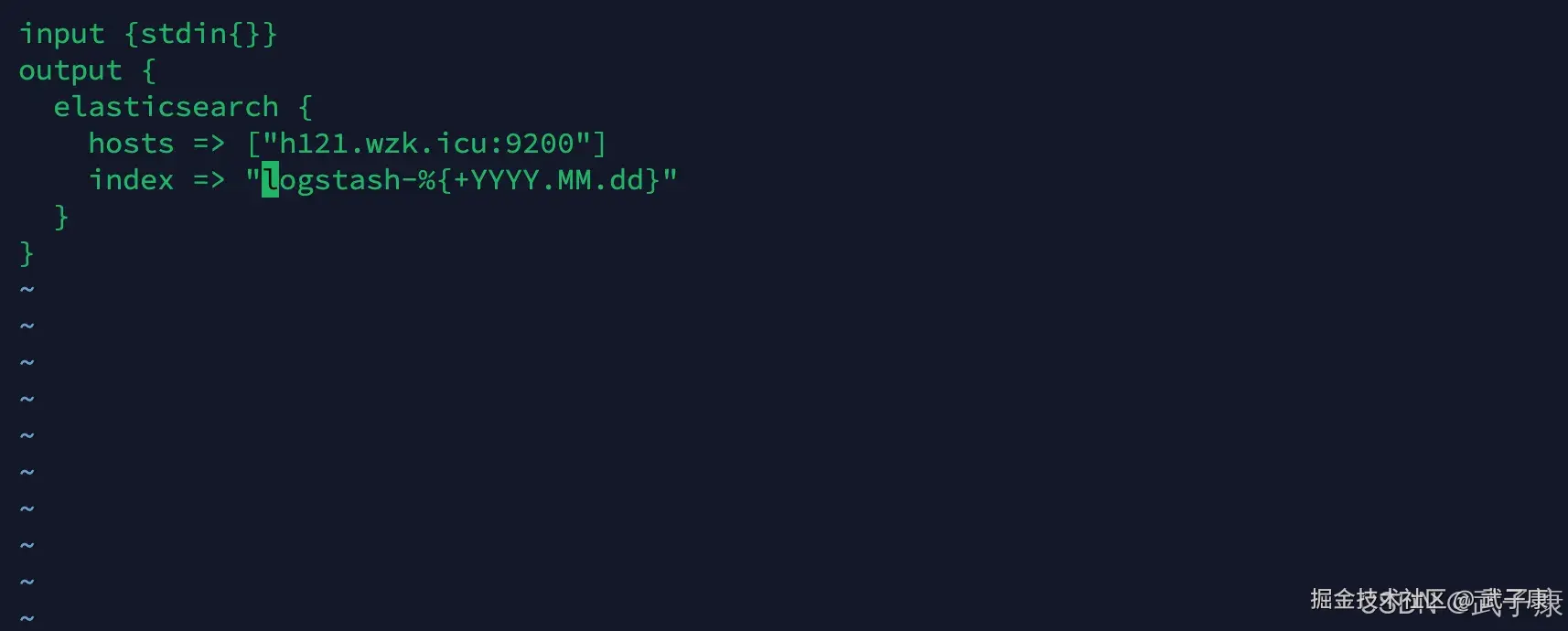
注意:这个index是保存到Elasticsearch的索引名称,如何命名是非常重要的,因为我们后续可能有某些需求做查询,所以最好带上时间。
检查配置
shell
cd /opt/servers/logstash-7.3.0
bin/logstash -f /opt/servers/logstash-7.3.0/config/output_es.conf -t运行的结果如下图所示: 
启动配置
shell
cd /opt/servers/logstash-7.3.0
bin/logstash -f /opt/servers/logstash-7.3.0/config/output_es.conf启动结果如下图所示: 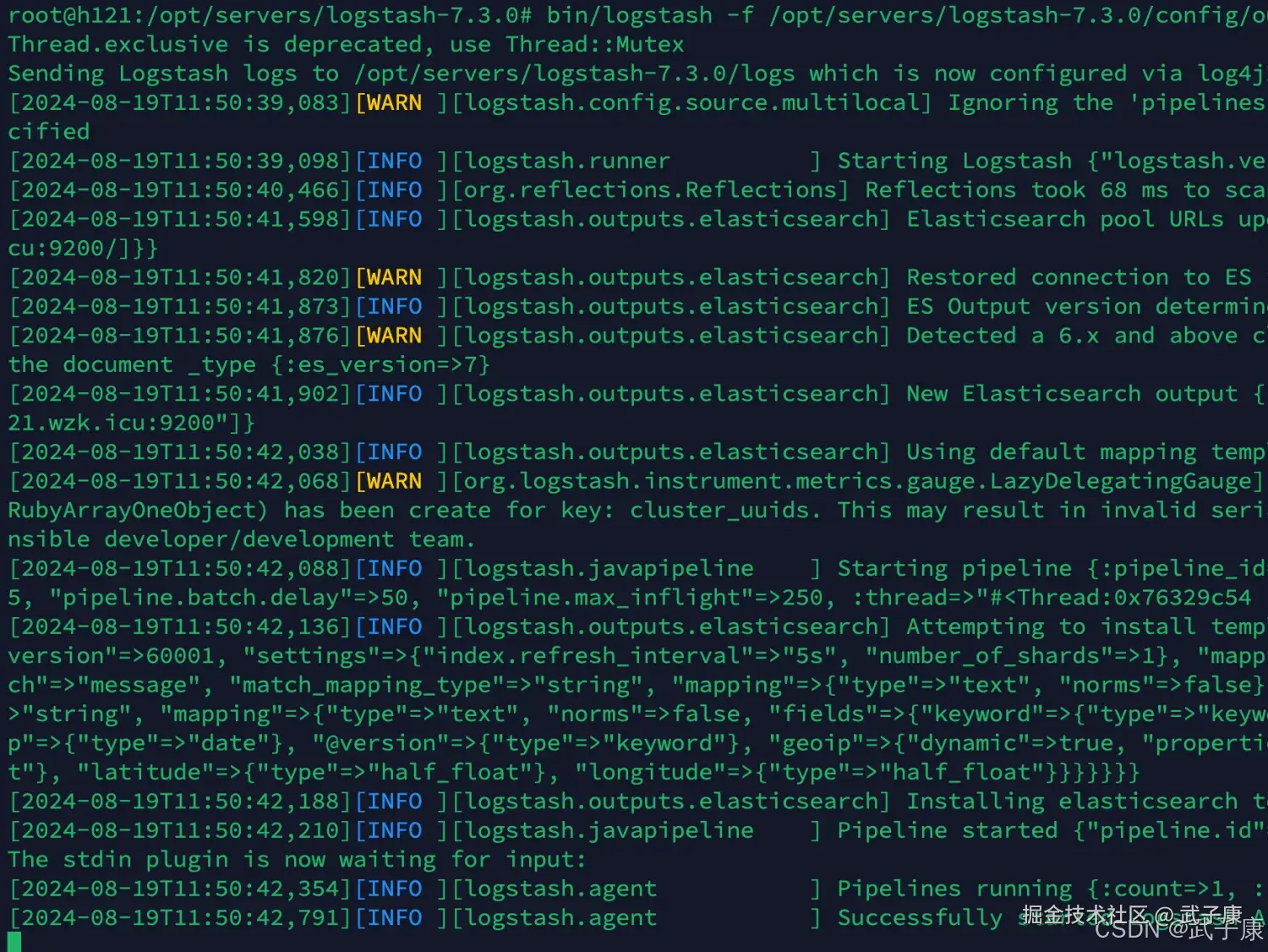
测试数据
向控制台写入 hello wzk icu ! 查看ES集群中的数据如下图所示: 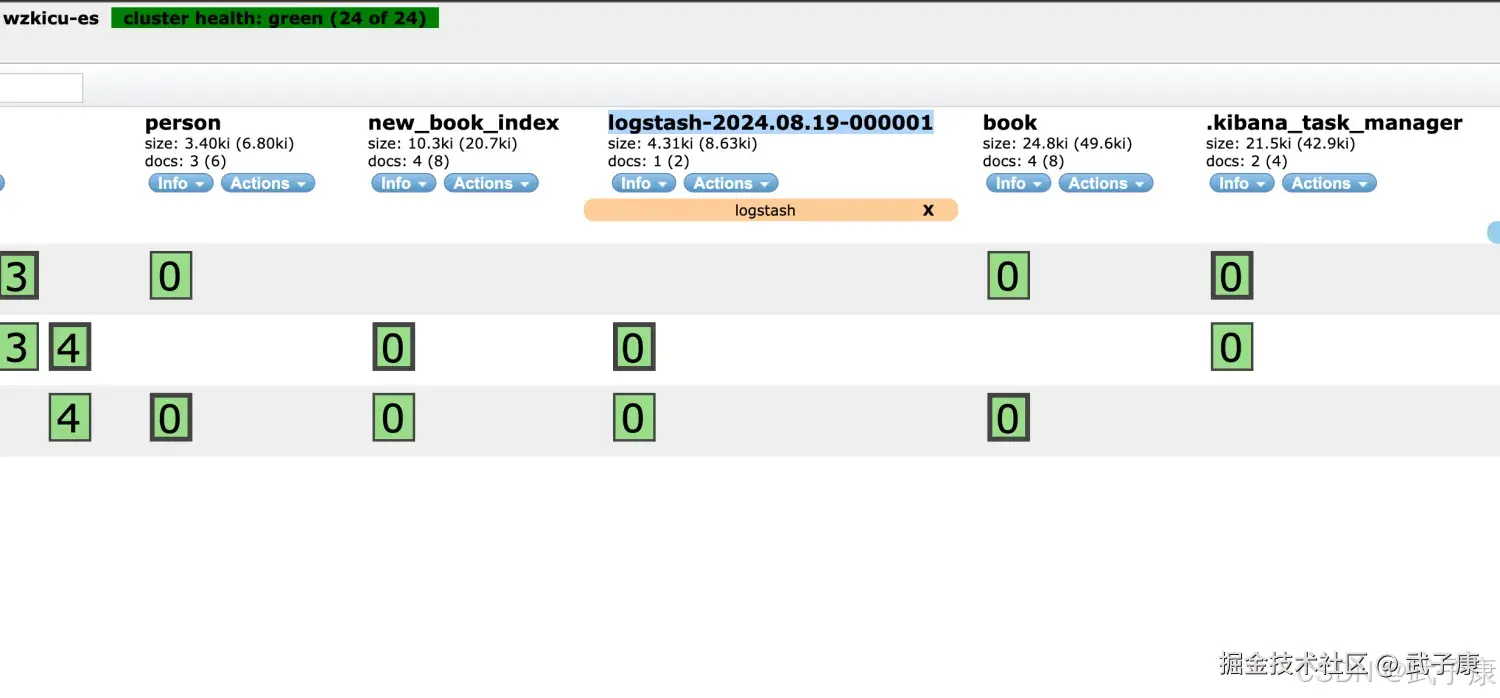
错误速查
| 症状 | 根因定位 | 修复 |
|---|---|---|
| 启动成功但 stdout 没输出 | stdin 无输入/管道未加载目标 conf/多管道覆盖 | bin/logstash -t;启动日志里确认 pipeline 与 conf 路径指定 -f 到正确 conf;用 stdin{} 直接输入验证 |
| file 输出无文件/文件为空 | 目录不存在/权限不足/字段缺失导致路径渲染异常 | 看 Logstash 日志报错;确认目标目录与用户权限预创建目录并授权;路径字段改为稳定值(或给 host 默认值) |
| ES 连接超时/拒绝连接 | hosts 不通、端口/防火墙、协议/域名解析问题 | curl -sS http://host:9200;Logstash 日志里 connection error hosts 写全协议与端口;放通网络;修正 DNS/安全组 |
| ES 返回 401/403 | 开了安全认证但未配 user/pass 或证书 | ES 响应码与响应体;Logstash 输出插件报 auth 配置 user/password 或 API Key;TLS 配置证书 |
| 写入失败:mapper_parsing_exception | 字段类型漂移(string↔number/date)、动态映射冲突 | ES 返回的 bulk item error;查看 index template/mapping 固定 mapping(模板/组件模板);在 filter 阶段做类型转换与字段清洗 |
| 写入失败:bulk 413/请求过大 | 单批次过大/事件体积过大/网关限制 | ES/代理返回 413;Logstash 重试但持续失败 降低批量大小;启用压缩;拆分大字段或截断 |
| 吞吐低、CPU 高、延迟抖动 | flush 过频、批量太小、并发不匹配、下游慢 | 观察 pipeline throughput;看 JVM/GC/队列积压 调大批量与并发;合理 flush;必要时启用持久队列/背压策略 |
| 重试后仍丢数据/重复数据 | 无持久化队列、下游短暂故障、幂等策略缺失 | 看 Logstash persistent queue 是否开启;ES 是否幂等写入 开启 PQ;用稳定 document_id 做幂等;为失败事件加旁路输出 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
💻 Java篇持续更新中(长期更新)
Java-196 消息队列选型:RabbitMQ vs RocketMQ vs Kafka MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS已完结,GuavaCache已完结,EVCache已完结,RabbitMQ正在更新... 深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解