Python MySQL监控与日志配置实战:从"盲人摸象"到"明察秋毫"
文章目录
-
- [Python MySQL监控与日志配置实战:从"盲人摸象"到"明察秋毫"](#Python MySQL监控与日志配置实战:从“盲人摸象”到“明察秋毫”)
-
- [一、 为什么我们需要监控与日志?------从一次"血泪"教训说起](#一、 为什么我们需要监控与日志?——从一次“血泪”教训说起)
- [二、 环境准备:搭建你的实验战场](#二、 环境准备:搭建你的实验战场)
-
- [2.1 检查与安装MySQL(以Ubuntu为例)](#2.1 检查与安装MySQL(以Ubuntu为例))
- [2.2 安装Python MySQL驱动](#2.2 安装Python MySQL驱动)
- [2.3 创建测试数据库和数据](#2.3 创建测试数据库和数据)
- [三、 核心概念:MySQL监控的"三驾马车"](#三、 核心概念:MySQL监控的“三驾马车”)
- [四、 实战演练:配置你的第一套监控系统](#四、 实战演练:配置你的第一套监控系统)
-
- [4.1 配置慢查询日志------找到拖慢系统的"罪魁祸首"](#4.1 配置慢查询日志——找到拖慢系统的"罪魁祸首")
- [4.2 使用Performance Schema------数据库的实时"仪表盘"](#4.2 使用Performance Schema——数据库的实时"仪表盘")
- [4.3 Python端的连接健康检查与日志集成](#4.3 Python端的连接健康检查与日志集成)
- [五、 监控指标汇总:你需要关注哪些关键数据?](#五、 监控指标汇总:你需要关注哪些关键数据?)
- [六、 生产环境部署建议](#六、 生产环境部署建议)
- [七、 学习总结与进阶方向](#七、 学习总结与进阶方向)
-
- [7.1 核心要点总结](#7.1 核心要点总结)
- [7.2 我当年踩过的坑](#7.2 我当年踩过的坑)
- [7.3 进阶学习方向](#7.3 进阶学习方向)
- [八、 学习交流与资源推荐](#八、 学习交流与资源推荐)
刚开始用Python操作MySQL时,你是不是也这样:程序突然变慢,数据库连接莫名断开,线上出了Bug却找不到原因,只能对着日志文件"盲人摸象"?我当年接手第一个Python Web项目时,就因为没配监控,半夜被报警电话叫醒,花了3小时才定位到一个简单的慢查询。今天,我就带你用30分钟,从零搭建一套生产级的MySQL监控与日志体系,让你对数据库状态"明察秋毫"。
一、 为什么我们需要监控与日志?------从一次"血泪"教训说起
去年我负责一个用户中心的Python项目,用的是Flask + MySQL架构。上线初期一切正常,直到某个周末,用户反馈页面加载要十几秒。我们查了应用日志、服务器负载,都没问题。最后,还是一个有经验的DBA提醒:"看看MySQL的慢查询日志吧。"
结果一查,发现一条原本0.1秒的查询,因为缺少索引,在数据量增长后变成了15秒的"巨兽"。没有监控,我们就像在黑暗中开车,直到撞墙才知道路有问题。
对于Python开发者来说,MySQL监控与日志配置能帮你解决三大痛点:
- 性能瓶颈定位:快速找到拖慢系统的SQL语句
- 故障预警与排查:连接异常、死锁发生时能及时知道原因
- 容量规划与优化:了解数据库负载趋势,为扩容提供数据支撑
接下来,我会手把手带你配置三个核心部分:慢查询日志 、性能监控(Performance Schema)和Python端的连接健康检查。
二、 环境准备:搭建你的实验战场
在开始实战前,我们需要准备好"战场"。这里我假设你已经有了Python和MySQL的基础环境。
2.1 检查与安装MySQL(以Ubuntu为例)
bash
# 检查MySQL是否安装
mysql --version
# 如果未安装,使用apt安装(其他系统请参考官方文档)
sudo apt update
sudo apt install mysql-server mysql-client
# 启动MySQL服务
sudo systemctl start mysql
sudo systemctl enable mysql
# 安全初始化(设置root密码等)
sudo mysql_secure_installation2.2 安装Python MySQL驱动
我们将使用最流行的pymysql驱动,它纯Python实现,兼容性好。
bash
# 创建虚拟环境(推荐)
python -m venv mysql-monitor-env
source mysql-monitor-env/bin/activate # Linux/Mac
# 或 mysql-monitor-env\Scripts\activate # Windows
# 安装pymysql
pip install pymysql
# 安装额外的工具库,用于后续的监控数据可视化
pip install matplotlib pandas2.3 创建测试数据库和数据
让我们创建一个真实的业务场景------电商用户订单系统。
python
# create_test_data.py
import pymysql
import random
from datetime import datetime, timedelta
def create_test_database():
"""创建测试数据库和表,并插入模拟数据"""
# 连接MySQL(请替换为你的实际密码)
connection = pymysql.connect(
host='localhost',
user='root',
password='your_password', # 改成你的MySQL root密码
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor
)
try:
with connection.cursor() as cursor:
# 创建数据库
cursor.execute("CREATE DATABASE IF NOT EXISTS ecommerce_monitor")
cursor.execute("USE ecommerce_monitor")
# 创建用户表
cursor.execute("""
CREATE TABLE IF NOT EXISTS users (
id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(50) NOT NULL UNIQUE,
email VARCHAR(100) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
INDEX idx_username (username),
INDEX idx_created_at (created_at)
)
""")
# 创建订单表(故意不加索引,用于演示慢查询)
cursor.execute("""
CREATE TABLE IF NOT EXISTS orders (
id INT AUTO_INCREMENT PRIMARY KEY,
user_id INT NOT NULL,
amount DECIMAL(10, 2) NOT NULL,
status ENUM('pending', 'paid', 'shipped', 'delivered') DEFAULT 'pending',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (user_id) REFERENCES users(id)
# 注意:这里故意不在user_id和created_at上加索引!
)
""")
# 插入测试用户数据
print("插入用户数据...")
users = []
for i in range(1, 1001): # 1000个用户
users.append((f'user{i}', f'user{i}@example.com'))
cursor.executemany(
"INSERT INTO users (username, email) VALUES (%s, %s)",
users
)
# 插入测试订单数据(更多数据,用于模拟真实场景)
print("插入订单数据...")
orders = []
start_date = datetime.now() - timedelta(days=365)
for i in range(1, 50001): # 5万条订单
user_id = random.randint(1, 1000)
amount = round(random.uniform(10.0, 1000.0), 2)
days_ago = random.randint(0, 365)
order_date = start_date + timedelta(days=days_ago)
# 随机状态
status = random.choice(['pending', 'paid', 'shipped', 'delivered'])
orders.append((
user_id,
amount,
status,
order_date.strftime('%Y-%m-%d %H:%M:%S')
))
# 分批插入,避免单次SQL太大
batch_size = 1000
for i in range(0, len(orders), batch_size):
batch = orders[i:i+batch_size]
cursor.executemany(
"""INSERT INTO orders (user_id, amount, status, created_at)
VALUES (%s, %s, %s, %s)""",
batch
)
connection.commit()
print(f"已插入 {min(i+batch_size, len(orders))}/{len(orders)} 条订单")
print("测试数据创建完成!")
finally:
connection.close()
if __name__ == "__main__":
create_test_database()运行这个脚本前,记得把password='your_password'改成你的MySQL root密码。这个脚本会创建5万条订单数据,足够我们演示监控效果了。
三、 核心概念:MySQL监控的"三驾马车"
在深入配置前,我们先理解三个核心概念,这就像医生看病需要了解体温、血压、心率一样。
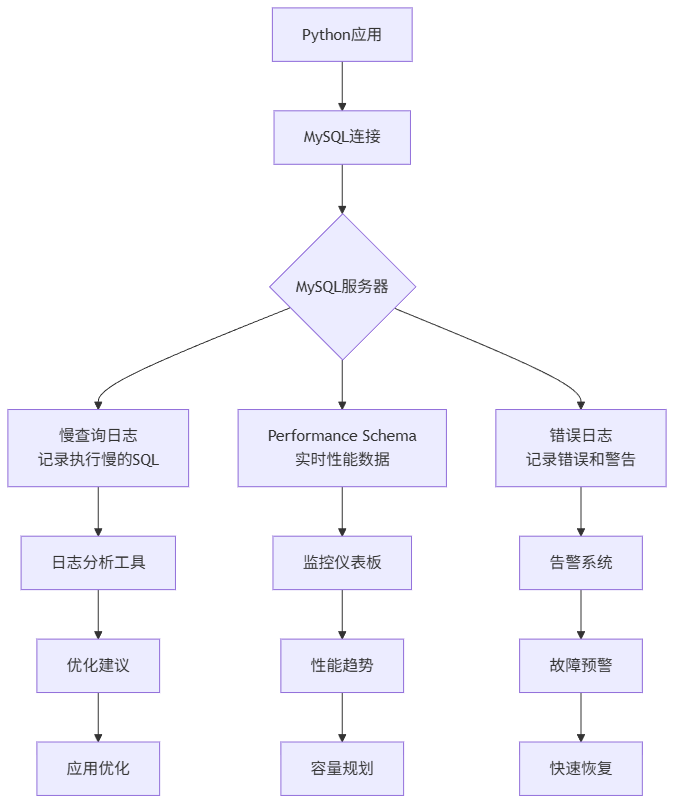
1. 慢查询日志(Slow Query Log)
- 是什么:记录执行时间超过指定阈值的SQL语句
- 为什么重要:80%的性能问题由20%的慢查询引起。找到它们,就找到了优化关键点
- 怎么用:通过MySQL配置开启,设置时间阈值(如2秒)
2. Performance Schema
- 是什么:MySQL 5.5+引入的性能监控框架,像数据库的"仪表盘"
- 为什么重要:提供实时、低开销的性能数据,包括连接数、锁等待、SQL执行统计等
- 怎么用:默认启用,通过SQL查询各种性能表
3. 错误日志(Error Log)
- 是什么:记录MySQL启动、运行、停止过程中的错误和警告信息
- 为什么重要:故障排查的第一现场,连接失败、崩溃原因都在这里
- 怎么用:MySQL自动记录,只需知道查看位置
四、 实战演练:配置你的第一套监控系统
4.1 配置慢查询日志------找到拖慢系统的"罪魁祸首"
慢查询日志是优化数据库的第一步。让我们配置并分析它。
步骤1:修改MySQL配置
bash
# 编辑MySQL配置文件
sudo nano /etc/mysql/mysql.conf.d/mysqld.cnf # Ubuntu路径,其他系统可能不同
# 在[mysqld]部分添加或修改以下配置:
"""
[mysqld]
# 开启慢查询日志
slow_query_log = 1
# 指定慢查询日志文件路径
slow_query_log_file = /var/log/mysql/mysql-slow.log
# 设置慢查询阈值(单位:秒),这里设为1秒,生产环境通常设2-3秒
long_query_time = 1
# 记录未使用索引的查询(即使执行时间没超过阈值)
log_queries_not_using_indexes = 1
# 每分钟最多记录多少条慢查询,避免日志爆炸
log_throttle_queries_not_using_indexes = 10
"""
# 保存后重启MySQL
sudo systemctl restart mysql步骤2:验证配置并生成慢查询
python
# generate_slow_queries.py
import pymysql
import time
def generate_slow_queries():
"""执行一些会触发慢查询的SQL"""
connection = pymysql.connect(
host='localhost',
user='root',
password='your_password',
database='ecommerce_monitor',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor
)
try:
with connection.cursor() as cursor:
print("执行可能较慢的查询...")
# 查询1:全表扫描(orders表没有user_id索引)
start = time.time()
cursor.execute("""
SELECT * FROM orders
WHERE user_id = 500
AND created_at > '2023-01-01'
ORDER BY created_at DESC
""")
result1 = cursor.fetchall()
elapsed1 = time.time() - start
print(f"查询1(无索引条件查询)耗时: {elapsed1:.3f}秒,返回 {len(result1)} 条记录")
# 查询2:复杂联表查询
start = time.time()
cursor.execute("""
SELECT u.username, COUNT(o.id) as order_count, SUM(o.amount) as total_amount
FROM users u
LEFT JOIN orders o ON u.id = o.user_id
WHERE o.created_at > '2023-06-01'
GROUP BY u.id
HAVING order_count > 5
ORDER BY total_amount DESC
LIMIT 20
""")
result2 = cursor.fetchall()
elapsed2 = time.time() - start
print(f"查询2(复杂联表分组)耗时: {elapsed2:.3f}秒")
# 查询3:使用索引的快速查询(作为对比)
start = time.time()
cursor.execute("SELECT * FROM users WHERE username = 'user500'")
result3 = cursor.fetchall()
elapsed3 = time.time() - start
print(f"查询3(使用索引查询)耗时: {elapsed3:.3f}秒")
finally:
connection.close()
if __name__ == "__main__":
generate_slow_queries()运行这个脚本,你会看到前两个查询明显较慢(特别是第一个,因为orders表的user_id和created_at字段没有索引)。
步骤3:分析慢查询日志
bash
# 查看慢查询日志(需要sudo权限)
sudo tail -100 /var/log/mysql/mysql-slow.log
# 使用mysqldumpslow工具分析(MySQL自带)
sudo mysqldumpslow /var/log/mysql/mysql-slow.log -t 10 -s at
# 输出示例:
"""
Count: 3 Time=1.23s (3s) Lock=0.00s (0s) Rows=152.7 (458), root[root]@localhost
SELECT * FROM orders WHERE user_id = N AND created_at > 'S' ORDER BY created_at DESC
"""这个输出告诉我们:同一种模式的查询执行了3次,平均耗时1.23秒,每次返回约153行数据。问题很明显:需要在orders.user_id和orders.created_at上建立索引。
步骤4:根据分析结果优化
python
# add_indexes.py
import pymysql
def add_necessary_indexes():
"""根据慢查询分析添加缺失的索引"""
connection = pymysql.connect(
host='localhost',
user='root',
password='your_password',
database='ecommerce_monitor',
charset='utf8mb4'
)
try:
with connection.cursor() as cursor:
print("添加缺失的索引...")
# 为orders表的user_id添加索引
cursor.execute("""
ALTER TABLE orders
ADD INDEX idx_user_id (user_id),
ADD INDEX idx_created_at (created_at),
ADD INDEX idx_user_created (user_id, created_at)
""")
print("索引添加完成!")
# 验证优化效果
print("\n验证优化效果:")
cursor.execute("EXPLAIN SELECT * FROM orders WHERE user_id = 500 AND created_at > '2023-01-01'")
explain_result = cursor.fetchone()
print(f"查询执行计划:")
print(f"- 使用的索引: {explain_result.get('key', '无')}")
print(f"- 扫描行数: {explain_result.get('rows', '未知')}")
print(f"- 查询类型: {explain_result.get('type', '未知')}")
finally:
connection.close()
if __name__ == "__main__":
add_necessary_indexes()运行后再执行之前的慢查询脚本,你会发现第一个查询从秒级变成了毫秒级!这就是监控的价值:数据驱动优化。
4.2 使用Performance Schema------数据库的实时"仪表盘"
Performance Schema(性能模式)是MySQL内置的性能监控工具,开销极小,适合生产环境。
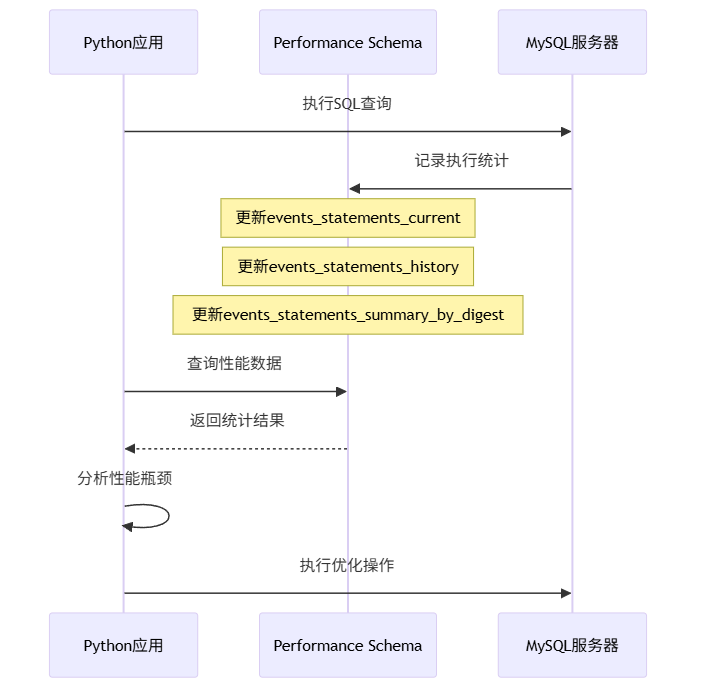
实战:用Python监控实时性能
python
# performance_monitor.py
import pymysql
import time
import pandas as pd
from datetime import datetime
class MySQLPerformanceMonitor:
"""MySQL性能监控器"""
def __init__(self, host='localhost', user='root', password='', database=''):
self.connection = pymysql.connect(
host=host,
user=user,
password=password,
database=database,
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor
)
def get_slow_queries_summary(self):
"""获取慢查询摘要统计"""
with self.connection.cursor() as cursor:
cursor.execute("""
SELECT
DIGEST_TEXT as query_pattern,
COUNT_STAR as exec_count,
AVG_TIMER_WAIT/1000000000000 as avg_time_sec,
MAX_TIMER_WAIT/1000000000000 as max_time_sec,
SUM_ROWS_EXAMINED as rows_examined_total,
SUM_ROWS_SENT as rows_sent_total
FROM performance_schema.events_statements_summary_by_digest
WHERE DIGEST_TEXT IS NOT NULL
AND AVG_TIMER_WAIT > 1000000000 # 大于1毫秒
ORDER BY avg_time_sec DESC
LIMIT 10
""")
return cursor.fetchall()
def get_connection_stats(self):
"""获取连接统计"""
with self.connection.cursor() as cursor:
cursor.execute("""
SELECT
USER as user,
HOST as host,
COUNT(*) as connection_count,
GROUP_CONCAT(COMMAND) as commands
FROM information_schema.PROCESSLIST
WHERE COMMAND != 'Sleep'
GROUP BY USER, HOST
""")
return cursor.fetchall()
def get_table_access_stats(self, hours=24):
"""获取表访问统计"""
with self.connection.cursor() as cursor:
# 注意:这个查询需要开启某些consumer,默认可能没有数据
cursor.execute("""
SELECT
OBJECT_SCHEMA as db_name,
OBJECT_NAME as table_name,
COUNT_READ as read_count,
COUNT_WRITE as write_count,
COUNT_FETCH as fetch_count
FROM performance_schema.table_io_waits_summary_by_table
WHERE COUNT_STAR > 0
ORDER BY COUNT_STAR DESC
LIMIT 10
""")
return cursor.fetchall()
def monitor_loop(self, interval=60, duration=300):
"""监控循环,定期收集性能数据"""
print(f"开始性能监控,每{interval}秒采样一次,持续{duration}秒...")
data_points = []
start_time = time.time()
while time.time() - start_time < duration:
timestamp = datetime.now()
# 收集各种性能指标
slow_queries = self.get_slow_queries_summary()
connections = self.get_connection_stats()
# 记录数据点
data_point = {
'timestamp': timestamp,
'slow_query_count': len(slow_queries),
'active_connections': sum(c['connection_count'] for c in connections),
'top_slow_query_time': slow_queries[0]['avg_time_sec'] if slow_queries else 0
}
data_points.append(data_point)
print(f"[{timestamp}] 慢查询数: {data_point['slow_query_count']}, "
f"活跃连接: {data_point['active_connections']}")
time.sleep(interval)
# 转换为DataFrame便于分析
df = pd.DataFrame(data_points)
return df
def close(self):
self.connection.close()
# 使用示例
if __name__ == "__main__":
monitor = MySQLPerformanceMonitor(
host='localhost',
user='root',
password='your_password',
database='ecommerce_monitor'
)
try:
# 获取一次性的性能快照
print("=== 当前慢查询TOP 10 ===")
slow_queries = monitor.get_slow_queries_summary()
for i, query in enumerate(slow_queries[:5], 1):
print(f"{i}. {query['query_pattern'][:80]}...")
print(f" 平均耗时: {query['avg_time_sec']:.3f}s, 执行次数: {query['exec_count']}")
print("\n=== 当前连接统计 ===")
connections = monitor.get_connection_stats()
for conn in connections:
print(f"用户: {conn['user']}, 连接数: {conn['connection_count']}")
# 运行监控循环(生产环境可以改为后台任务)
# df = monitor.monitor_loop(interval=10, duration=60)
# print(f"\n监控数据摘要:\n{df.describe()}")
finally:
monitor.close()这个监控器展示了如何从Performance Schema获取关键指标。在生产环境中,你可以将这些数据发送到Prometheus、Grafana等监控系统。
4.3 Python端的连接健康检查与日志集成
除了监控MySQL服务器,我们还需要在Python应用层做好健康检查和日志记录。
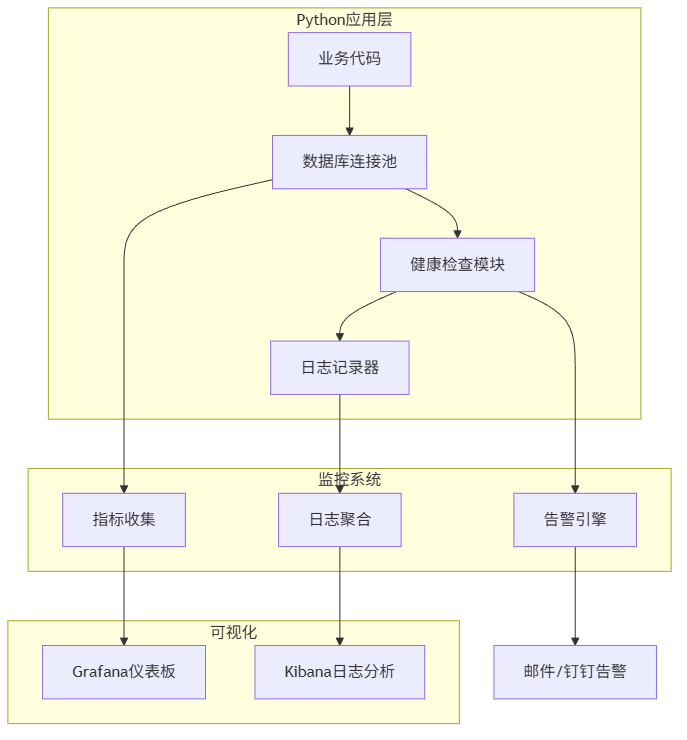
实战:带健康检查和日志的连接池
python
# db_connection_pool.py
import pymysql
import logging
import time
from threading import Lock
from contextlib import contextmanager
from datetime import datetime, timedelta
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('mysql_operations.log'),
logging.StreamHandler()
]
)
logger = logging.getLogger('MySQLMonitor')
class HealthyConnectionPool:
"""带健康检查的MySQL连接池"""
def __init__(self, max_connections=10, **kwargs):
self.max_connections = max_connections
self.connection_args = kwargs
self.pool = []
self.in_use = set()
self.lock = Lock()
self.last_health_check = datetime.min
# 初始化连接池
self._initialize_pool()
logger.info(f"连接池初始化完成,最大连接数: {max_connections}")
def _initialize_pool(self):
"""初始化连接池"""
for _ in range(min(3, self.max_connections)):
conn = self._create_connection()
if conn:
self.pool.append(conn)
def _create_connection(self):
"""创建新连接"""
try:
conn = pymysql.connect(**self.connection_args)
# 设置连接属性,便于追踪
with conn.cursor() as cursor:
cursor.execute("SET @python_client_id = %s",
(f"pool_conn_{len(self.pool)}",))
logger.debug(f"创建新数据库连接: {conn.server_version}")
return conn
except Exception as e:
logger.error(f"创建数据库连接失败: {e}")
return None
def _health_check(self):
"""定期健康检查"""
now = datetime.now()
if now - self.last_health_check < timedelta(minutes=5):
return
with self.lock:
healthy_connections = []
for conn in self.pool:
try:
with conn.cursor() as cursor:
cursor.execute("SELECT 1")
cursor.fetchone()
healthy_connections.append(conn)
except Exception as e:
logger.warning(f"连接健康检查失败,关闭异常连接: {e}")
try:
conn.close()
except:
pass
# 补充连接
while len(healthy_connections) < self.max_connections:
new_conn = self._create_connection()
if new_conn:
healthy_connections.append(new_conn)
else:
break
self.pool = healthy_connections
self.last_health_check = now
logger.info(f"健康检查完成,活跃连接数: {len(self.pool)}")
@contextmanager
def get_connection(self):
"""获取连接(上下文管理器方式)"""
self._health_check()
conn = None
start_time = time.time()
with self.lock:
if self.pool:
conn = self.pool.pop()
elif len(self.in_use) < self.max_connections:
conn = self._create_connection()
if conn:
self.in_use.add(id(conn))
if not conn:
wait_time = time.time() - start_time
logger.error(f"获取数据库连接超时,等待{wait_time:.2f}秒后仍无可用连接")
raise Exception("数据库连接池耗尽")
try:
# 记录连接获取
logger.debug(f"获取数据库连接,当前使用中: {len(self.in_use)}")
# 执行查询前的准备
with conn.cursor() as cursor:
cursor.execute("SET @query_start_time = NOW(6)")
yield conn
except pymysql.Error as e:
# 记录数据库错误
error_code, error_msg = e.args
logger.error(f"数据库操作错误 [{error_code}]: {error_msg}")
# 根据错误类型决定是否关闭连接
if error_code in (2006, 2013): # 连接相关错误
logger.warning("连接异常,将关闭并创建新连接")
try:
conn.close()
except:
pass
conn = self._create_connection()
raise
finally:
# 记录查询执行时间
try:
with conn.cursor() as cursor:
cursor.execute("SELECT TIMESTAMPDIFF(MICROSECOND, @query_start_time, NOW(6)) / 1000000 as exec_time")
result = cursor.fetchone()
exec_time = result['exec_time'] if result else 0
if exec_time > 1.0: # 超过1秒的记录为慢查询
logger.warning(f"慢查询检测: 执行时间 {exec_time:.3f}秒")
except:
exec_time = 0
# 归还连接
with self.lock:
if conn and conn.open:
self.pool.append(conn)
if id(conn) in self.in_use:
self.in_use.remove(id(conn))
logger.debug(f"归还数据库连接,执行时间: {exec_time:.3f}秒")
def close_all(self):
"""关闭所有连接"""
with self.lock:
for conn in self.pool:
try:
conn.close()
except:
pass
self.pool.clear()
self.in_use.clear()
logger.info("连接池已关闭所有连接")
# 使用示例
def example_usage():
"""使用带监控的连接池示例"""
# 创建连接池
pool = HealthyConnectionPool(
max_connections=5,
host='localhost',
user='root',
password='your_password',
database='ecommerce_monitor',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor
)
try:
# 示例1:正常查询
with pool.get_connection() as conn:
with conn.cursor() as cursor:
cursor.execute("SELECT COUNT(*) as count FROM orders")
result = cursor.fetchone()
print(f"订单总数: {result['count']}")
# 示例2:事务操作
with pool.get_connection() as conn:
try:
with conn.cursor() as cursor:
# 开始事务
cursor.execute("START TRANSACTION")
# 插入新订单
cursor.execute(
"INSERT INTO orders (user_id, amount, status) VALUES (%s, %s, %s)",
(1, 99.99, 'pending')
)
# 更新用户统计(模拟业务逻辑)
cursor.execute(
"UPDATE users SET email = %s WHERE id = %s",
('updated@example.com', 1)
)
# 提交事务
conn.commit()
logger.info("事务提交成功")
except Exception as e:
conn.rollback()
logger.error(f"事务回滚: {e}")
raise
# 示例3:批量查询(模拟业务高峰)
import concurrent.futures
def query_user_orders(user_id):
"""查询用户订单"""
with pool.get_connection() as conn:
with conn.cursor() as cursor:
cursor.execute(
"SELECT * FROM orders WHERE user_id = %s LIMIT 10",
(user_id,)
)
return cursor.fetchall()
# 模拟并发查询
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor:
user_ids = list(range(1, 10))
futures = [executor.submit(query_user_orders, uid) for uid in user_ids]
for future in concurrent.futures.as_completed(futures):
try:
orders = future.result()
print(f"查询到 {len(orders)} 条订单")
except Exception as e:
logger.error(f"并发查询失败: {e}")
finally:
pool.close_all()
if __name__ == "__main__":
example_usage()这个连接池实现包含了几个关键特性:
- 连接健康检查:定期验证连接是否可用
- 慢查询日志:自动记录执行时间超过1秒的查询
- 错误处理:根据错误类型智能处理连接
- 连接追踪:记录连接使用情况,便于排查问题
五、 监控指标汇总:你需要关注哪些关键数据?
在实际项目中,你需要关注以下关键指标。我整理了一个表格,方便你快速参考:
| 监控类别 | 具体指标 | 正常范围 | 告警阈值 | 检查频率 | Python获取方式 |
|---|---|---|---|---|---|
| 连接状态 | 当前连接数 | < 最大连接数80% | > 最大连接数90% | 每分钟 | SHOW STATUS LIKE 'Threads_connected' |
| 连接错误数 | 接近0 | 每小时>10 | 每小时 | SHOW STATUS LIKE 'Connection_errors%' |
|
| 查询性能 | 慢查询数量 | 接近0 | 每分钟>5 | 实时 | 慢查询日志 |
| 平均查询时间 | < 100ms | > 500ms | 每分钟 | Performance Schema | |
| QPS(每秒查询) | 根据业务定 | 突增100% | 每分钟 | SHOW STATUS LIKE 'Queries' |
|
| 资源使用 | InnoDB缓冲池命中率 | > 95% | < 90% | 每分钟 | SHOW STATUS LIKE 'Innodb_buffer_pool%' |
| 临时表磁盘使用 | 接近0 | > 100MB | 每小时 | SHOW STATUS LIKE 'Created_tmp%' |
|
| 复制状态 | 主从延迟 | < 1秒 | > 5秒 | 每分钟 | SHOW SLAVE STATUS |
六、 生产环境部署建议
当你掌握了基本监控配置后,在生产环境中我建议:
-
分层监控:
- 基础设施层:服务器CPU、内存、磁盘
- MySQL层:连接数、慢查询、锁等待
- 应用层:Python连接池状态、查询耗时
-
告警策略:
- 紧急告警(电话/短信):数据库宕机、连接池耗尽
- 重要告警(邮件/钉钉):慢查询突增、主从延迟
- 提醒通知(邮件):磁盘空间不足、备份完成
-
日志管理:
python# 生产环境日志配置示例 import logging from logging.handlers import RotatingFileHandler, TimedRotatingFileHandler # 按大小轮转的日志文件 size_handler = RotatingFileHandler( 'mysql_operations.log', maxBytes=100*1024*1024, # 100MB backupCount=10 ) # 按时间轮转的日志文件 time_handler = TimedRotatingFileHandler( 'mysql_slow_queries.log', when='midnight', # 每天轮转 backupCount=30 ) # 发送到监控系统(如ELK) # 可以使用logstash handler或直接API发送
七、 学习总结与进阶方向
恭喜你!现在你已经掌握了Python MySQL监控与日志配置的核心技能。让我们回顾一下今天的收获:
7.1 核心要点总结
- 慢查询日志是性能优化的起点,配置简单但效果显著
- Performance Schema提供实时、低开销的性能数据
- Python端的健康检查能提前发现连接问题
- 分层监控 和合理告警是生产环境的必备
7.2 我当年踩过的坑
- 坑1 :开启了慢查询日志但没定期清理,磁盘被撑满
- 解决方案 :配置日志轮转,或使用
pt-query-digest分析后清理
- 解决方案 :配置日志轮转,或使用
- 坑2 :监控指标太多,反而找不到重点
- 解决方案:先关注连接数、慢查询、缓冲池命中率这三个核心指标
- 坑3 :Python连接泄露,导致连接数缓慢增长
- 解决方案 :使用上下文管理器(
with语句),确保连接总是被正确归还
- 解决方案 :使用上下文管理器(
7.3 进阶学习方向
如果你想深入MySQL监控,我建议按这个路径学习:
- 监控工具:学习使用Percona Monitoring and Management (PMM) 或 VividCortex
- SQL优化:深入理解EXPLAIN执行计划,学习索引优化技巧
- 架构设计:了解读写分离、分库分表下的监控策略
- 自动化:使用Ansible/Terraform自动化监控部署
八、 学习交流与资源推荐
互动时间
欢迎在评论区分享你的经验或问题:
- 你在Python项目中遇到过哪些MySQL监控难题?
- 今天的示例代码运行成功了吗?遇到了什么报错?
- 对于慢查询优化,你有哪些独门技巧?
我会挑选典型问题详细解答。记住,监控配置不是一次性的工作,而是需要持续优化的过程。
学习资源推荐
-
官方文档(最权威):
-
实战书籍:
- 《高性能MySQL》(第4版) - 监控与优化必读
- 《MySQL技术内幕:InnoDB存储引擎》 - 深入理解原理
-
在线工具:
- Percona Toolkit - MySQL管理瑞士军刀
- phpMyAdmin - 简单的Web监控界面
-
我的GitHub仓库:
- 本文完整代码示例:python-mysql-monitoring-demo(示例链接,请替换为你的)
下篇预告
下一篇将分享《Python MySQL连接池深度优化:从基础配置到生产级实践》,我会带你:
- 深入分析不同连接池的实现原理
- 配置适合高并发场景的连接参数
- 实现智能连接管理和故障转移
- 分享我在千万级用户项目中的实战经验
最后的小建议:监控配置就像给数据库装上"眼睛"和"耳朵"。不要等到出问题了才临时抱佛脚,从现在开始,为你每个Python MySQL项目都配上基础监控。刚开始可能觉得麻烦,但当你半夜不再被报警电话吵醒时,你会感谢现在的自己。
动手时间:打开你的Python项目,花30分钟配置一下慢查询日志和基础监控。遇到问题?随时回来交流!