MySQL执行SQL的核心流程:
- 连接器:建立连接、验证身份、获取权限
- 查询缓存(MySQL 8.0已移除):命中则直接返回
- 解析器:词法分析 + 语法分析,生成语法树
- 优化器:选择最优执行计划(索引选择、JOIN顺序)
- 执行器:调用存储引擎接口执行SQL
写操作(INSERT/UPDATE/DELETE)额外流程:
- 先写undo log(用于回滚)
- 修改Buffer Pool中的数据页
- 写redo log(WAL机制,保证持久性)
- 写binlog(用于主从复制)
- 两阶段提交保证redo log和binlog一致性
一、MySQL整体架构
MySQL采用分层架构,主要分为Server层和存储引擎层:
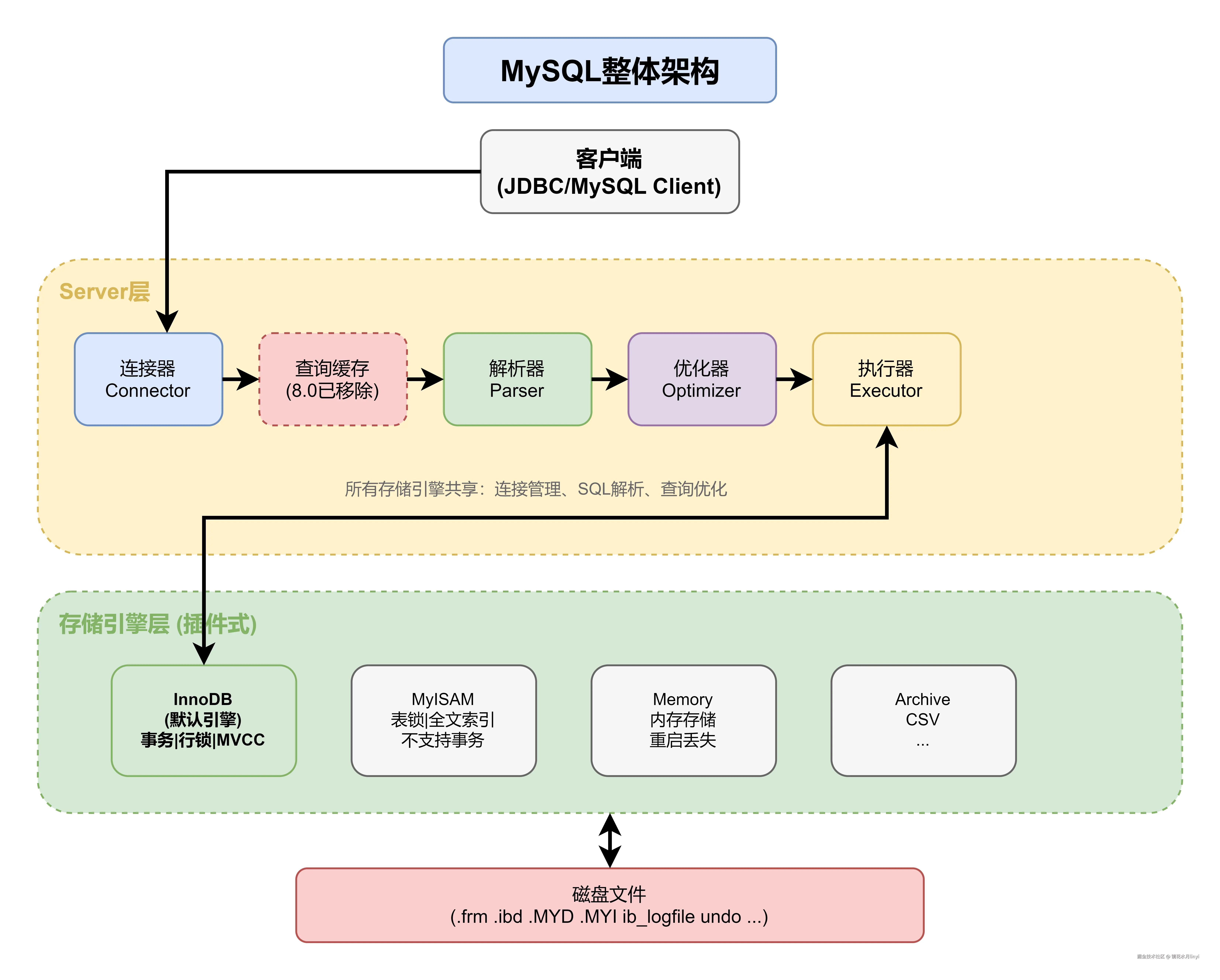
1.1 Server层
Server层涵盖MySQL大多数核心功能:
| 组件 | 功能 |
|---|---|
| 连接器 | 管理连接、身份验证、权限校验 |
| 查询缓存 | 缓存SELECT结果(8.0已移除) |
| 解析器 | 词法分析、语法分析 |
| 预处理器 | 语义校验、权限验证 |
| 优化器 | 生成执行计划、选择索引 |
| 执行器 | 调用存储引擎、返回结果 |
1.2 存储引擎层
存储引擎负责数据的存储和读取,MySQL支持插件式存储引擎:
| 存储引擎 | 特点 |
|---|---|
| InnoDB | 支持事务、行锁、外键,默认引擎 |
| MyISAM | 不支持事务,表锁,查询快 |
| Memory | 数据存内存,重启丢失 |
| Archive | 高压缩比,适合归档数据 |
二、SELECT查询执行全流程
以执行 SELECT * FROM user WHERE id = 1 为例:
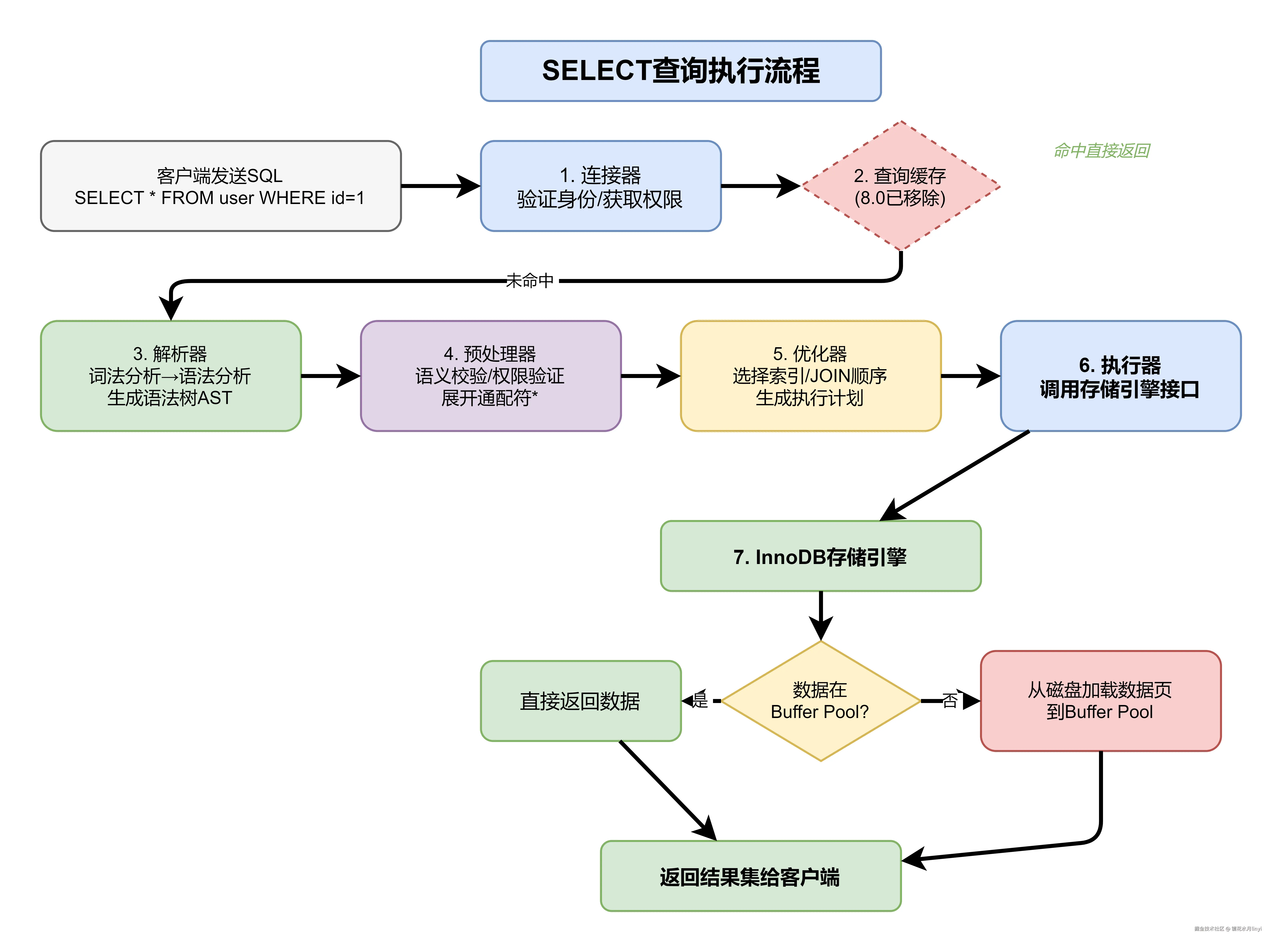
2.1 连接器
sql
mysql -h127.0.0.1 -P3306 -uroot -p连接器工作流程:
- TCP三次握手建立连接
- 身份验证:校验用户名密码
- 权限获取:从mysql.user表读取权限信息
- 建立会话:分配线程处理后续请求
关键参数:
sql
-- 查看连接超时时间(默认8小时)
SHOW VARIABLES LIKE 'wait_timeout';
-- 查看当前连接数
SHOW PROCESSLIST;
-- 查看最大连接数
SHOW VARIABLES LIKE 'max_connections';长连接问题:
- 长连接会累积内存,可能导致OOM
- 解决方案:定期执行
mysql_reset_connection重置连接状态
2.2 查询缓存(MySQL 8.0已移除)
sql
-- MySQL 5.7查看查询缓存状态
SHOW VARIABLES LIKE 'query_cache_type';为什么8.0移除查询缓存?
- 只要表有更新,该表所有缓存都会失效
- 对于更新频繁的表,缓存命中率极低
- 维护缓存本身也有开销
2.3 解析器
词法分析: 将SQL字符串拆分成Token
ini
SELECT * FROM user WHERE id = 1
↓
[SELECT] [*] [FROM] [user] [WHERE] [id] [=] [1]语法分析: 根据语法规则生成语法树(AST)
sql
SELECT_STMT
/ | \
SELECT FROM WHERE
| | |
* user id = 1常见语法错误:
sql
-- 错误示例
SELEC * FROM user; -- 提示 "You have an error in your SQL syntax"2.4 预处理器
- 语义校验:检查表和列是否存在
- 权限验证:检查用户是否有访问权限
- 通配符展开 :将
*展开为具体列名
2.5 优化器
优化器决定SQL的执行计划,主要工作:
1. 索引选择
sql
-- 表有多个索引时,优化器选择最优索引
SELECT * FROM user WHERE name = 'Tom' AND age = 25;
-- 可能选择 idx_name 或 idx_age 或 idx_name_age2. JOIN顺序
sql
-- 优化器决定表的连接顺序
SELECT * FROM t1 JOIN t2 ON t1.id = t2.id JOIN t3 ON t2.id = t3.id;
-- 可能是 t1->t2->t3 或 t2->t1->t3 等3. 查看执行计划
sql
EXPLAIN SELECT * FROM user WHERE id = 1;| 字段 | 说明 |
|---|---|
| type | 访问类型(const > eq_ref > ref > range > index > ALL) |
| key | 实际使用的索引 |
| rows | 预估扫描行数 |
| Extra | 额外信息(Using index表示覆盖索引) |
2.6 执行器
执行器根据执行计划,调用存储引擎接口获取数据:
执行流程(以InnoDB为例):
- 调用存储引擎接口,获取第一行
- 判断是否满足WHERE条件
- 满足则加入结果集,不满足则跳过
- 继续获取下一行,重复步骤2-3
- 遍历完成,返回结果集
存储引擎接口:
c
// InnoDB存储引擎提供的接口
ha_innobase::index_read() // 通过索引读取
ha_innobase::rnd_next() // 全表扫描读取下一行
ha_innobase::index_next() // 索引扫描读取下一行三、INSERT执行流程
以执行 INSERT INTO user(name, age) VALUES('Tom', 25) 为例:
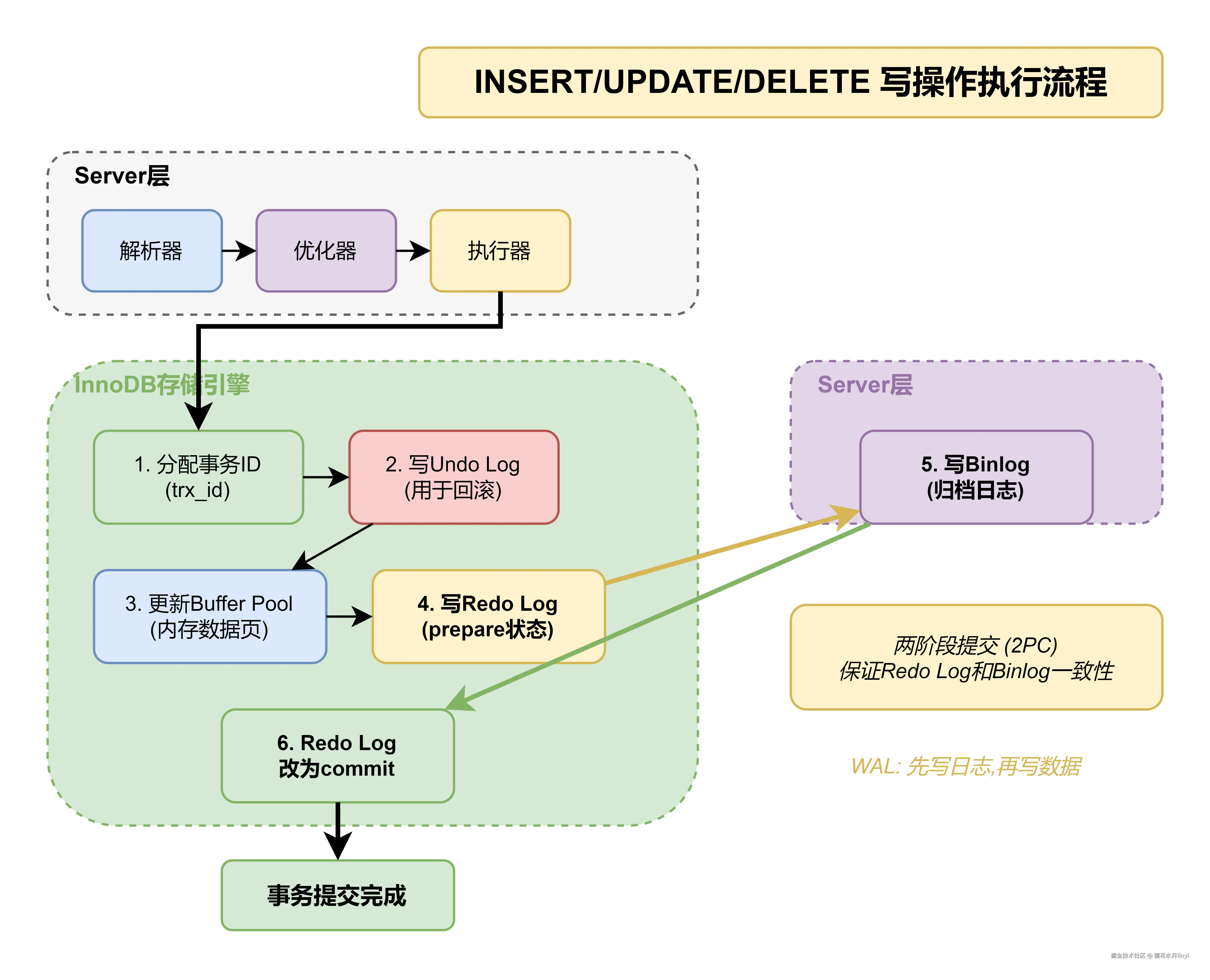
3.1 Server层处理
- 解析器:解析SQL,生成语法树
- 预处理器:校验表和列是否存在
- 优化器:INSERT相对简单,主要确定插入哪个分区(如果有)
- 执行器:调用存储引擎的写入接口
3.2 InnoDB存储引擎处理
核心步骤:
- 分配事务ID(trx_id)
- 写undo log(用于回滚)
- 在Buffer Pool中修改数据页
- 写redo log(prepare状态)
- 写binlog
- 提交事务,redo log改为commit状态
3.3 关键组件详解
Buffer Pool(缓冲池)
sql
-- 查看Buffer Pool大小(建议设置为物理内存的50%-80%)
SHOW VARIABLES LIKE 'innodb_buffer_pool_size';Buffer Pool结构:
| 区域 | 作用 |
|---|---|
| 数据页 | 缓存从磁盘读取的数据页 |
| 索引页 | 缓存索引数据 |
| undo页 | 缓存undo log |
| 插入缓冲 | 优化二级索引的插入 |
| 自适应哈希 | 热点页的哈希索引 |
| 锁信息 | 行锁、表锁信息 |
Undo Log(回滚日志)
作用:
- 事务回滚:ROLLBACK时通过undo log恢复数据
- MVCC:实现多版本并发控制,提供一致性读
undo log类型:
| 类型 | 触发操作 | 内容 |
|---|---|---|
| insert_undo | INSERT | 记录主键,回滚时删除 |
| update_undo | UPDATE/DELETE | 记录旧版本数据 |
Redo Log(重做日志)
作用: 保证事务持久性,实现crash-safe
WAL(Write-Ahead Logging)机制:
- 先写日志,再写数据
- 日志顺序写,性能高
- 崩溃恢复时通过redo log重做
sql
-- 查看redo log配置
SHOW VARIABLES LIKE 'innodb_log_file_size'; -- 单个文件大小
SHOW VARIABLES LIKE 'innodb_log_files_in_group'; -- 文件数量Redo Log Buffer刷盘策略(innodb_flush_log_at_trx_commit):
| 值 | 行为 | 性能 | 安全性 |
|---|---|---|---|
| 0 | 每秒刷盘 | 最高 | 可能丢1秒数据 |
| 1 | 每次提交刷盘 | 较低 | 最安全 |
| 2 | 每次提交写os cache | 中等 | OS崩溃可能丢数据 |
Binlog(归档日志)
作用:
- 主从复制:从库通过binlog同步数据
- 数据恢复:通过binlog恢复到指定时间点
Binlog格式:
| 格式 | 特点 |
|---|---|
| STATEMENT | 记录SQL语句,可能不一致 |
| ROW | 记录行数据变更,数据量大 |
| MIXED | 混合模式,自动选择 |
sql
-- 查看binlog格式
SHOW VARIABLES LIKE 'binlog_format';3.4 两阶段提交(2PC)
为什么需要两阶段提交?
保证redo log和binlog的一致性,避免主从数据不一致。
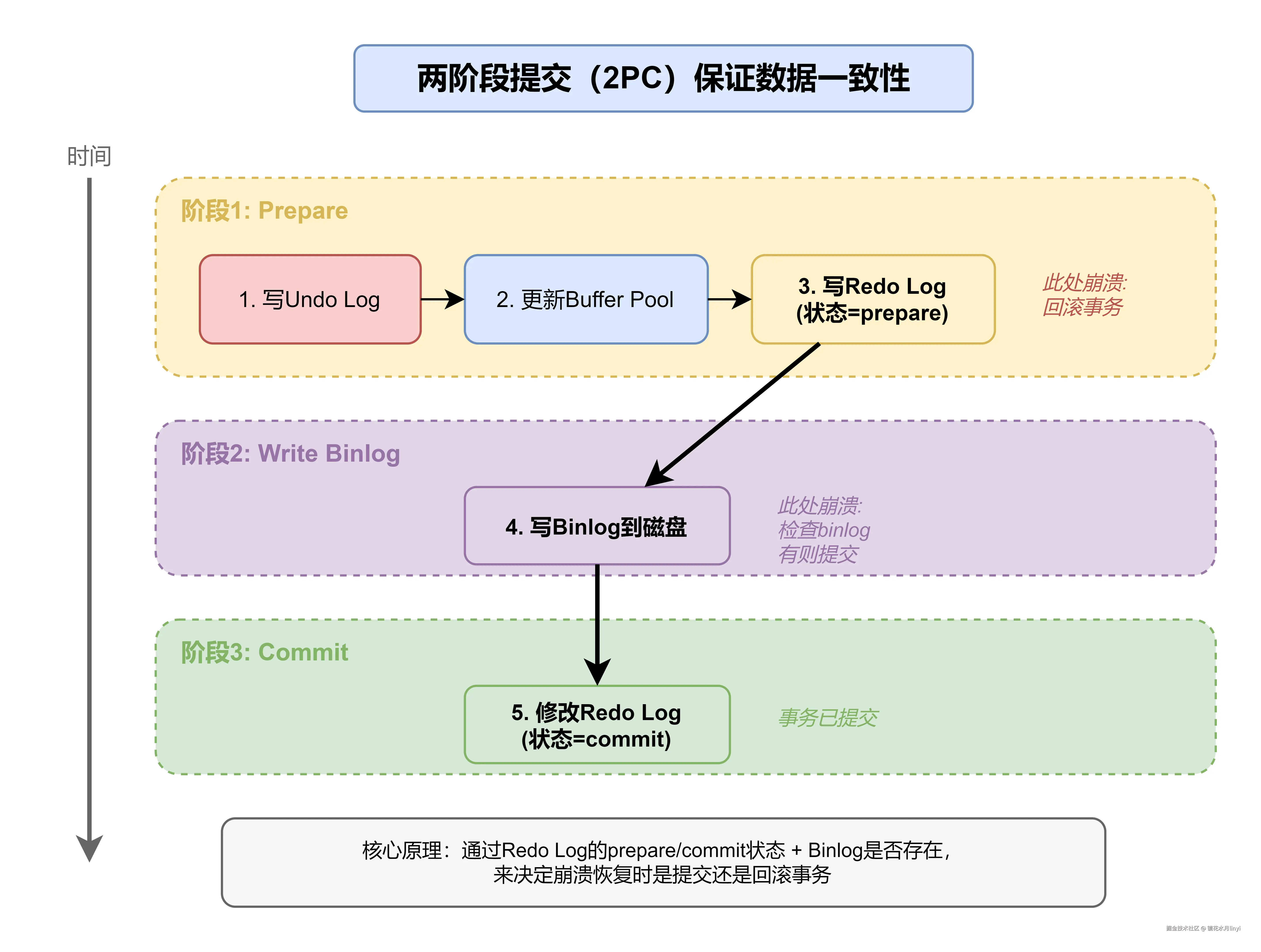
流程:
- 写入redo log,状态为prepare
- 写入binlog
- 提交事务,redo log状态改为commit
崩溃恢复逻辑:
| 崩溃时刻 | redo log状态 | binlog状态 | 恢复策略 |
|---|---|---|---|
| 阶段1后 | prepare | 无 | 回滚事务 |
| 阶段2后 | prepare | 有 | 提交事务 |
| 阶段3后 | commit | 有 | 已提交 |
四、UPDATE执行流程
以执行 UPDATE user SET age = 26 WHERE id = 1 为例:
4.1 执行流程
- 执行器调用存储引擎,通过索引找到id=1的记录
- 若数据页不在Buffer Pool,从磁盘加载
- 返回行数据给执行器
- 执行器修改age为26,调用存储引擎写入
- 存储引擎: a. 写undo log(记录旧值age=25) b. 更新Buffer Pool中的数据页(脏页) c. 写redo log(prepare)
- 执行器写binlog
- 执行器调用存储引擎提交事务
- 存储引擎:redo log改为commit
4.2 Change Buffer(写缓冲)
适用场景: 二级索引的写操作
原理:
- 更新仅非唯一二级索引时,若数据页不在Buffer Pool
- 先将修改记录在Change Buffer
- 后续读取该页或后台线程merge时,再应用修改
优势: 减少随机磁盘I/O
sql
-- 查看Change Buffer配置
SHOW VARIABLES LIKE 'innodb_change_buffer_max_size';五、DELETE执行流程
以执行 DELETE FROM user WHERE id = 1 为例:
5.1 执行流程
DELETE在InnoDB中并非真正删除,而是标记删除:
- 找到id=1的记录
- 写undo log(记录完整行数据)
- 将记录的delete_mark标记为1
- 写redo log
- 写binlog
- 提交事务
5.2 真正删除时机
- Purge线程:后台线程定期清理标记删除的记录
- 清理条件:没有任何事务需要访问该版本(MVCC)
六、InnoDB存储引擎核心架构
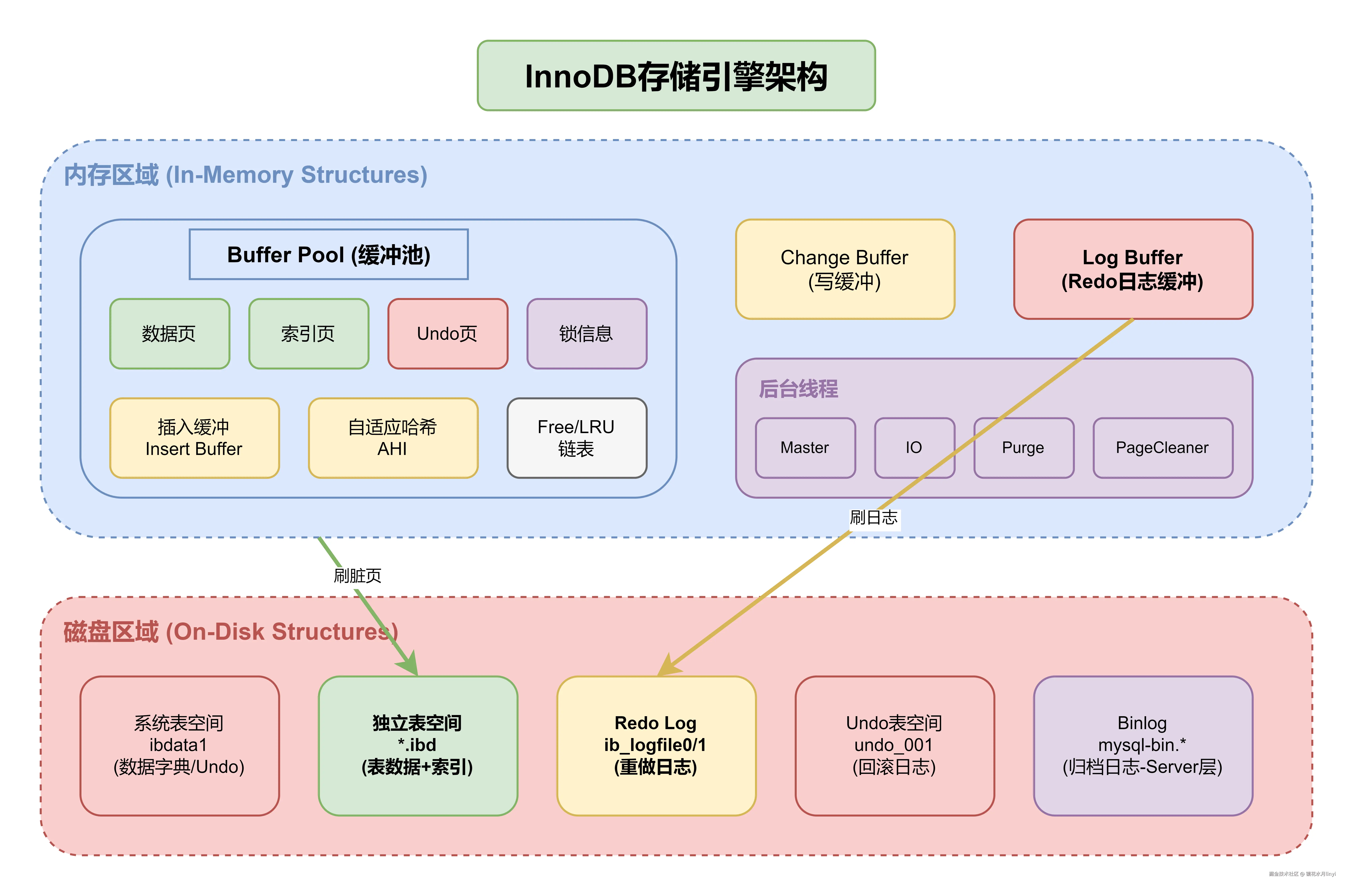
6.1 内存结构
| 组件 | 作用 |
|---|---|
| Buffer Pool | 缓存数据页、索引页 |
| Change Buffer | 缓存二级索引的写操作 |
| Log Buffer | 缓存redo log |
| Adaptive Hash Index | 自适应哈希索引 |
6.2 磁盘结构
| 组件 | 文件 | 作用 |
|---|---|---|
| 系统表空间 | ibdata1 | 存储数据字典、undo log等 |
| 独立表空间 | *.ibd | 每个表的数据和索引 |
| Redo Log | ib_logfile0/1 | 重做日志 |
| Undo Tablespace | undo_001等 | undo日志(8.0+) |
6.3 后台线程
| 线程 | 作用 |
|---|---|
| Master Thread | 刷新脏页、合并Change Buffer |
| IO Thread | 异步IO处理 |
| Purge Thread | 清理undo log和标记删除的记录 |
| Page Cleaner Thread | 刷新脏页到磁盘 |
七、常见问题
Buffer Pool和查询缓存有什么区别?
| 对比项 | Buffer Pool | 查询缓存 |
|---|---|---|
| 所属层 | 存储引擎层 | Server层 |
| 缓存内容 | 数据页、索引页 | SQL结果集 |
| 失效条件 | LRU淘汰 | 表有任何更新 |
| 状态 | 一直存在 | 8.0已移除 |
redo log和binlog有什么区别?
| 对比项 | redo log | binlog |
|---|---|---|
| 所属层 | InnoDB存储引擎 | Server层 |
| 内容 | 物理日志(数据页修改) | 逻辑日志(SQL或行变更) |
| 写入方式 | 循环写,空间固定 | 追加写,切换新文件 |
| 作用 | crash-safe | 主从复制、数据恢复 |
为什么需要undo log?
- 事务回滚:ROLLBACK时恢复数据
- MVCC实现:提供数据的历史版本,实现一致性读
什么是脏页?什么时候刷盘?
脏页: Buffer Pool中被修改但未刷到磁盘的页
刷盘时机:
- redo log空间不足
- Buffer Pool空间不足
- 系统空闲时后台线程刷新
- MySQL正常关闭
八、总结
又是没有大厂约面日子😣😣😣,小编还在找实习的路上,这篇文章是我的笔记汇总整理。
参考资料
- MySQL官方文档:dev.mysql.com/doc/
- 《MySQL技术内幕:InnoDB存储引擎》
- 《高性能MySQL》