编者按: 你是否曾经在配置 CUDA 环境时被"driver version mismatch"或"no kernel image for device"这类错误困扰,却难以厘清"CUDA 版本"、"驱动版本"、"计算能力"之间的复杂关系?为何 nvidia-smi、nvcc 和 PyTorch 报告的"CUDA 版本"常常不一致?
我们今天为大家带来的文章,作者的观点是:CUDA 生态系统的混乱根源在于术语与组件的多重含义,只有通过一套严谨的本体论(ontology)厘清各组件的定义、层级关系与版本语义,才能从根本上理解并解决兼容性问题。
本文从术语辨析入手,逐一澄清"CUDA"、"driver"、"kernel"等关键概念的多重含义,进而剖析 CUDA 软件栈的分层架构 ------ 从应用层的 Runtime API(libcudart),到底层的 Driver API(libcuda)与内核驱动(nvidia.ko),最终抵达 GPU 硬件。文章重点阐述了版本语义的多维性(计算能力、驱动版本、Toolkit 版本、Runtime/Driver API 版本)及其兼容性约束,并通过编译模型、执行模型与典型故障场景,揭示版本不匹配的根本成因。文中还提供了实用的诊断工具指南与面向开发者、用户、PyTorch 及容器使用者的实践建议。
作者 | James Akl
编译 | 岳 扬
CUDA 的术语存在严重的多重含义问题:"CUDA" 一词本身至少指代五种不同的概念,"driver" 在不同上下文中含义也不同,而各种工具报告的版本号衡量的也是不同的子系统。本文提供了一套关于 CUDA 组件的严谨本体论(译者注:ontology,指的是一种对某个领域内所有存在事物、其本质属性及相互关系的正式、系统的描述和分类体系。):一种对 CUDA 生态系统中存在哪些内容、各组件间如何相互关联、它们的版本语义、兼容性规则以及故障模式的系统性描述。为了消除歧义,每个术语都经过精确定义。只有先厘清了"CUDA"、"driver"、"kernel"这些术语的确切所指以及各组件之间的关系,我们才能有效地解决版本冲突和理解系统运作的逻辑。这是进行后续所有 CUDA 问题排查和系统管理的基础。
01 CUDA 术语与歧义消除
1.1 术语"CUDA"
"CUDA" 一词至少承载五种不同的含义:
1)CUDA 作为计算架构:由 NVIDIA 设计的并行计算平台和编程模型。
2)CUDA 作为指令集:NVIDIA 硬件支持的 GPU 指令集架构(ISA),按计算能力划分版本(compute_8.0、compute_9.0 等)。
3)CUDA 作为源语言:用于编写 GPU 代码的 C/C++ 语言扩展(如 global、device 等)。
4)CUDA Toolkit:包含 nvcc、库文件、头文件和开发工具的开发套件。
5)CUDA Runtime:应用程序所链接的运行时库(libcudart)。
当有人提到"CUDA 版本"时,可能指的是 Toolkit 版本、Runtime 版本、Driver API 版本或计算能力。要表达精确,必须明确限定具体所指。
1.2 术语"kernel"
在 GPU 计算的语境中,kernel 有两种完全不同的含义:
1)操作系统内核:运行在特权内核空间中的操作系统内核。例如:Linux kernel(如版本 6.6.87)、Windows NT kernel、macOS XNU kernel。
2)CUDA kernel:带有 global 修饰的 C++ 函数,在 GPU 上执行。当从主机代码调用时,CUDA kernel 会以线程块网格的形式启动。
在本文中,OS kernel 始终指操作系统内核(Linux、Windows 等),CUDA kernel 始终指 GPU 函数。
1.3 术语"driver"
在计算领域,"driver" 是使操作系统能够与硬件设备通信的软件。在 CUDA 语境中,"driver" 包含以下两种含义:
1)NVIDIA GPU Driver(也称 "NVIDIA Display Driver"):运行在(OS)kernel 空间的驱动程序(Linux 上为(OS)kernel 模块,Windows 上为(OS)kernel 驱动),用于管理 GPU 硬件。尽管历史上被称为"显示驱动",但这个统一的驱动实际上处理了所有 GPU 操作:图形渲染、计算任务、内存管理与调度。该名称反映了 NVIDIA 从专注于图形的 GPU 向通用计算加速器的演进过程。
- 以(OS)kernel 模块形式安装:nvidia.ko、nvidia-modeset.ko、nvidia-uvm.ko(Linux),或作为 Windows(OS)kernel 驱动。
- 使用独立的版本号划分:535.104.05、550.54.15 等。
2)CUDA Driver API:一个底层的 C 语言 API(Linux 上为 libcuda.so,Windows 上为 nvcuda.dll),提供对 GPU 功能的直接访问。这是由 NVIDIA GPU 驱动包提供的用户态库。
- 位置示例:/usr/lib/x86_64-linux-gnu/libcuda.so(Linux)。
- 其 API 版本不同于 GPU 驱动版本,但二者打包在同一驱动程序安装包中。
NVIDIA GPU 驱动包同时包含(OS)kernel 组件((OS)kernel 模块/驱动)和 libcuda 用户态库。
02 组件架构
CUDA 生态系统由多个层级构成,每个层级都有其明确的职责。理解这种分层结构,是推理版本兼容性与系统行为的基础。
2.1 系统层级
CUDA 软件栈横跨(OS)kernel 空间和用户空间:
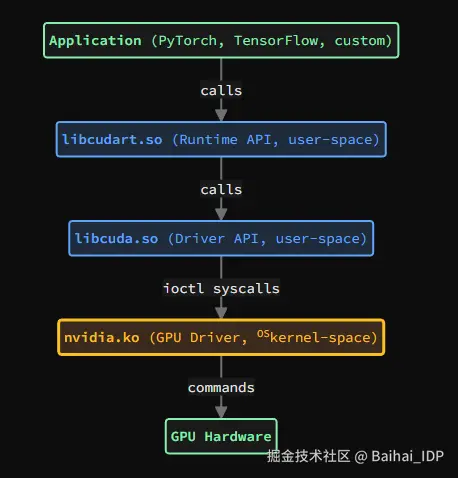
2.2 组件定义
libcuda.so / nvcuda.dll (Driver API,后端) :
- 由 NVIDIA GPU 驱动程序包提供。
- 操作系统内的安装位置:
- Linux: /usr/lib/x86_64-linux-gnu/libcuda.so (或 /usr/lib64/libcuda.so)
- Windows: C:\Windows\System32\nvcuda.dll
- 提供底层原语:cuInit、cuMemAlloc、cuLaunchKernel 等。
- 通过系统调用与(OS)kernel 驱动通信:
- Linux: ioctl 系统调用 (用于与(OS)kernel 设备通信的 I/O 控制系统调用)
- Windows: 向(OS)kernel 驱动发起 DeviceIoControl 调用
- 其版本与 GPU 驱动程序版本绑定(例如,driver 535.x 提供支持 CUDA Driver API 12.2 的 libcuda.so/nvcuda.dll)。
libcudart.so / cudart64_*.dll (Runtime API,前端) :
- 由 CUDA Toolkit 提供(或随 PyTorch 等应用程序打包)。
- 文件位置:
- Linux: libcudart.so (动态库), libcudart_static.a (静态库)
- Windows: cudart64_.dll (动态库), cudart_static.lib (静态库)
- 提供封装后的高层 API:cudaMalloc、cudaMemcpy、cudaLaunchKernel 等。
- 其内部调用 libcuda.so/nvcuda.dll (Driver API) 来执行相关操作。
- 可静态链接,也可动态链接。
- 应用程序代码通常直接使用 Runtime API,而非使用 Driver API。
CUDA Toolkit:
- 开发套件,包含:
- nvcc: 用于编译 (CUDA)kernel 代码的编译器。
- libcudart/cudart64_*.dll: 运行时库(Runtime library)。
- 头文件 (cuda.h, cuda_runtime.h)。
- 数学库:cuBLAS、cuDNN、cuFFT 等。
- 性能分析和调试工具:nvprof、nsight、cuda-gdb。
- 版本独立于 GPU 驱动:例如 toolkit 12.1、12.4 等。
- 在编译 (CUDA)kernel 代码时需要此工具包。
- 运行时需要运行时库(libcudart),但不需要 nvcc 和头文件。
- 安装路径:
- Linux: /usr/local/cuda/ (默认)
- Windows: C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.x\
NVIDIA GPU 驱动程序:
- 操作系统层级的驱动程序,用于管理 GPU 硬件。
- 提供(OS)kernel 模块 (Linux 上的 nvidia.ko,Windows 上的(OS)kernel 驱动) 和用户空间库 (Linux/macOS 上的 libcuda.so,Windows 上的 nvcuda.dll)。
- 必须在所有运行 CUDA 应用程序的机器上安装。
- 通过向前兼容支持多个 CUDA Runtime API 版本(较新的驱动支持较旧的运行时版本)。
- 注意:自 CUDA 10.2 (2019) 起,NVIDIA 已弃用对 macOS 的 CUDA 支持。现代 CUDA 开发主要面向 Linux 和 Windows。
2.3 分层架构模型(Layered architecture model)
CUDA 软件栈将应用层和系统层之间的职责分离:
- 前端(应用层) :libcudart.so + 应用程序代码。提供高层 Runtime API(如 cudaMalloc、cudaMemcpy 等)。由应用程序打包或链接使用。
- 后端(系统层) :libcuda.so + GPU 驱动(nvidia.ko)。提供底层 Driver API 和硬件管理功能。系统级安装,在执行时必须存在。
这种职责分离使应用程序能使用统一的高层 API,而后端负责处理与硬件相关的具体细节。libcudart 将 Runtime API 调用转换为 Driver API 调用,再由 libcuda 通过(OS)kernel 驱动执行。
2.4 编译期组件 vs. 执行期组件
术语说明:"执行期"(execution-time)指应用程序运行时(即 runtime),这与"Runtime API"(libcudart)这一特定 CUDA 库不同 ------ 后者是执行期所必需的一个具体库。
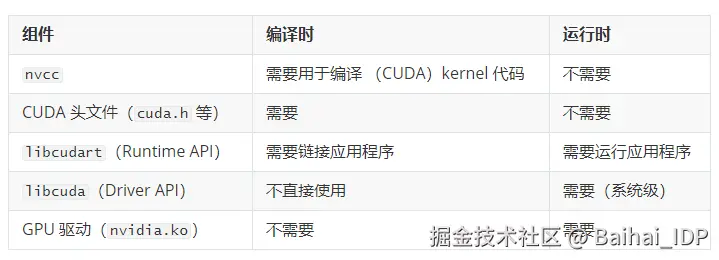
示例:
PyTorch 的编译过程:
- PyTorch 使用 CUDA Toolkit 12.1 进行编译(即构建过程中链接并使用了 toolkit 12.1 的头文件和库文件)。
- 编译期:使用 toolkit 12.1 中的 nvcc、头文件和 libcudart。
- 执行期:PyTorch 会打包或依赖 libcudart.so(通常静态链接或随包分发),并调用系统 GPU 驱动提供的 libcuda.so。
- 系统必须安装支持 CUDA Driver API 版本 ≥ PyTorch 所需版本的 GPU 驱动(本例中 ≥ 12.1)。
03 版本语义
CUDA 生态系统拥有多套独立的版本编号体系。每个版本号衡量的是系统的不同方面。混淆这些版本是造成误解的主要根源。
3.1 计算能力(Compute capability)
计算能力(CC)定义了 GPU 的指令集和硬件特性。这是 GPU 硬件本身的属性,而非软件属性:
- 格式:X.Y,其中 X 为主版本号,Y 为次版本号(例如 8.0、9.0)。
- 由 GPU 硬件决定:RTX 4090 的 CC 为 8.9,H100 的 CC 为 9.0。
- 可通过 nvidia-smi 或 cudaGetDeviceProperties() 查询计算能力(Compute capability )。
GPU 代码可编译为两种形式:
- SASS(Shader Assembly):针对特定计算能力(CC)编译的 GPU 专属机器码。可直接在匹配该 CC 的硬件上运行,但无法在不同计算能力(CC)的硬件间移植。
- PTX(Parallel Thread Execution):NVIDIA 的虚拟指令集架构(ISA)和中间表示。是一种与平台无关的字节码,可在执行时由驱动程序即时编译(JIT-compiled)为适用于任何支持 GPU 架构的原生 SASS。
二进制兼容性规则:
SASS(编译后的机器码)具有严格的兼容性限制:
- 不同计算能力之间无法保证二进制兼容。例如,为 CC 8.0 编译的 SASS 通常无法在 CC 8.6 硬件上运行,即使两者主版本同为 8.x ------ 不同 CC 可能采用不同的指令编码方式。
- SASS 无法在更旧的硬件上运行:CC 8.0 的 SASS 不能在 CC 7.5 上运行(旧硬件缺少所需指令)。
- SASS 无法跨主版本运行:CC 8.0 的 SASS 不能在 CC 9.0 硬件上运行(主版本不同,ISA 也不同)。
PTX(中间表示)提供前向兼容性:
- PTX 具备跨计算能力(compute capabilities)的可移植性:为 CC 8.0 编译生成的 PTX 代码,在程序运行时(execution time)可以被 NVIDIA 驱动程序即时编译(JIT-compiled)成适用于任何它所支持的 GPU 架构的原生 SASS 机器码,比如 CC 8.6、8.9、9.0 等。
- 要求:二进制文件必须包含 PTX,且驱动程序必须支持目标 GPU 架构。
- 性能考量:JIT 编译会在首次(CUDA)kernel 启动时带来一次性的开销;预编译的 SASS 可避免此开销。
- 建议:同时包含针对已知目标架构的 SASS 代码和用于未来 GPU 向前兼容的 PTX 代码。
3.2 GPU 驱动程序版本
格式(Linux):R.M.P(例如 535.104.05、550.54.15)
- R:主发布版本(对应所支持的 CUDA Driver API 主版本)
- M:次发布版本
- P:补丁版本
格式(Windows):显示驱动使用不同的版本编号(例如 31.0.15.3623),但 CUDA 组件报告的版本仍采用类似的 R.M 编号方式。
每个驱动版本都有一个所支持的 CUDA Driver API 最高版本。例如:
- 驱动 535.x 版本支持 CUDA Driver API 12.2
- 驱动 550.x 版本支持 CUDA Driver API 12.4
关键点:驱动版本决定了所能支持的 CUDA Driver API 最高版本,该版本必须 ≥ 应用程序所使用的 Runtime API 版本。
可通过 nvidia-smi 查询驱动版本及其支持的最高 CUDA Driver API 版本。
3.3 CUDA Toolkit 版本
格式:X.Y.Z(例如 12.1.0、12.4.1)
- 对应开发阶段安装的 toolkit 版本。
- 决定了 nvcc 版本、libcudart 版本以及可用的 API 功能。
- 可通过 nvcc --version 查询 Toolkit 版本(需已安装 Toolkit)。
3.4 CUDA Runtime API 版本
- 由 libcudart 所支持的 API 版本。
- 通常与 Toolkit 版本一致(Toolkit 12.1 提供的 libcudart 对应 Runtime API 12.1)。
- 应用程序可能会捆绑特定版本的 libcudart。
- 可在应用程序代码中通过 cudaRuntimeGetVersion() 查询 Runtime API 版本。
3.5 CUDA Driver API 版本
- 由 libcuda.so 提供的 API 版本。
- 由 GPU 驱动版本决定。
- 必须 ≥ 应用程序所使用的 Runtime API 版本。
- 可在应用程序代码中通过 cudaDriverGetVersion() 查询,或通过 nvidia-smi 查看(显示为 "CUDA Version")。
3.6 PyTorch 的 CUDA 版本
当 PyTorch 报告 CUDA 版本时,指的是:
- 编译期 Toolkit 版本:PyTorch 编译时所链接的 CUDA Toolkit 版本。可通过 torch.version.cuda 查询(例如 "12.1")。
- 运行期驱动版本:系统在运行时可用的 CUDA Driver API 版本。可通过 torch.cuda.is_available() 及驱动检查确认。
PyTorch 可能使用 Toolkit 12.1 编译(构建时链接该版本),但运行在支持 CUDA Driver API 12.4 的系统驱动上。只要 Driver API 版本 ≥ Toolkit 的 CUDA 版本(12.4 ≥ 12.1),这种配置就是有效的。
04 版本兼容性
CUDA 中的版本兼容性遵循一些特定规则。理解这些规则对于确保应用程序在不同系统上都能够正确运行非常重要。
术语说明:兼容性是从后端(驱动 + GPU 硬件)的角度描述的。 "前向兼容"(Forward compatible) 指后端能够与基于较旧 Toolkit 版本构建的前端协同工作(例如:driver version 12.4 可运行使用 Toolkit 12.1 的 libcudart 构建的应用程序)。 "后向兼容"(Backward compatible) 指后端能够与基于较新 Toolkit 版本构建的前端协同工作(例如:driver version 12.1 可运行使用 Toolkit 12.4 的 libcudart 构建的应用程序)。CUDA 驱动支持前向兼容(可运行旧版前端),但不支持后向兼容(无法运行新版前端)。
4.1 前向兼容:旧前端 + 新后端
CUDA 在以下维度上保持前向兼容:
Driver API 与 Runtime API 的前向兼容
- 支持 CUDA Driver API 12.4 的驱动,可运行使用 Runtime API 12.1、12.2、12.3 或 12.4 构建的应用程序。
- 新驱动支持旧版 Runtime。
- 应用程序无需重新编译,即可在安装了新驱动的系统上运行。
PTX 提供跨计算能力(compute capabilities)的前向兼容
- 为 CC 8.0 编译的 PTX 代码,可以被驱动程序进行 JIT 编译,从而兼容运行在 CC 8.6、8.9 甚至 9.0 的硬件上(甚至可以跨越主版本的界限)。
- 要求:二进制文件必须包含 PTX,且驱动必须支持目标 GPU 架构。
- 应用程序无需重新编译即可在新 GPU 上运行,代价是一次性的 JIT 编译开销。
4.2 后向兼容:新前端 + 旧后端
CUDA 不支持后向兼容:
Driver API 无法支持较新的 Runtime API
- 仅支持 CUDA Driver API 12.1 的驱动,无法运行需要 Runtime API 12.4 的应用程序。
- 旧驱动不支持新版 Runtime。
- 解决方法:升级 GPU 驱动以支持所需的 Driver API 版本。
SASS 无法在更旧的硬件上运行
- 为 CC 8.0 编译的 SASS 无法在 CC 7.5 硬件上运行(较旧的 GPU 缺少必要的指令)。
- 解决方法:针对较旧的计算能力重新编译,或在二进制文件中包含 PTX 以便进行 JIT 编译。
SASS 在不同计算能力之间不具备可移植性
- 为 CC 8.0 编译的 SASS 通常无法在 CC 8.6 或 9.0 硬件上运行。
- 解决方法:在二进制文件中包含 PTX 以实现前向兼容,或为所有目标架构分别编译 SASS。
4.3 兼容性要求
要使 CUDA 应用程序成功执行,必须同时满足以下两个独立条件:
条件 1:API 版本兼容
Driver API 版本 ≥ Runtime API 版本
即:由 libcuda.so 提供的 Driver API 版本(由 GPU 驱动决定)必须 ≥ 应用程序所使用的 libcudart 提供的 Runtime API 版本(由应用捆绑或链接)。
条件 2:GPU 代码可用
以下至少一项必须成立:
二进制文件包含与 GPU 计算能力匹配的 SASS
或
二进制文件包含 PTX 且驱动支持对该 GPU 架构进行 JIT 编译
应用程序二进制文件必须包含可执行的 GPU 代码,形式可以是:
- 与 GPU 计算能力匹配的预编译 SASS(执行最快,无 JIT 开销)
- PTX 中间表示,驱动程序可将其 JIT 编译为 SASS 代码(支持向前兼容,产生一次性 JIT 开销)
常见故障模式:
- cudaErrorInsufficientDriver:违反条件 1(Driver API 版本 < Runtime API 版本)
- cudaErrorNoKernelImageForDevice:违反条件 2(既无匹配的 SASS,也无可用的 PTX)
05 诊断工具与版本信息查询
不同的工具会报告不同的版本号。清楚每个工具检测的是什么,对于排查兼容性问题至关重要。
5.1 nvidia-smi
nvidia-smi(NVIDIA System Management Interface)用于查询 GPU 驱动程序,并报告与驱动相关的信息。
报告内容包括:
- GPU 驱动版本(例如 535.104.05)
- 支持的最高 CUDA Driver API 版本(例如 12.2)
- GPU 型号(例如 "NVIDIA GeForce RTX 4090")
- 计算能力(可通过 nvidia-smi --query-gpu=compute_cap --format=csv 查询)
不报告以下内容:
- CUDA Toolkit 版本(系统可能未安装 Toolkit)
- 应用程序使用的 Runtime API 版本
- nvcc 编译器版本
示例输出:
Driver Version: 535.104.05 CUDA Version: 12.2- 535.104.05:系统上安装的 GPU 驱动版本
- 12.2:该驱动所支持的最高 CUDA Driver API 版本(版本 ≤ 12.2 的应用程序才可以正常运行)
5.2 nvcc --version
报告内容包括:
- 已安装的 CUDA Toolkit 版本(例如 12.1.0)
- nvcc 编译器版本(与 Toolkit 版本一致)
不报告以下内容:
- GPU 驱动版本
- 当前使用的 Runtime API 版本
- 当前使用的 Driver API 版本
可能无法使用的情况:
- 系统仅安装了驱动,未安装 CUDA Toolkit
- 应用程序仅捆绑了 libcudart,未包含完整的 Toolkit
- 在容器中运行,且容器镜像仅包含运行时(runtime-only),不含 Toolkit
5.3 torch.version.cuda
报告内容:
- PyTorch 编译时所链接的 CUDA Toolkit 版本(例如 "12.1")
不报告以下内容:
- 驱动版本
- 系统当前可用的 Runtime Driver API 版本
5.4 torch.cuda.is_available()
报告内容:
- PyTorch 是否能访问支持 CUDA 的 GPU
- 要求驱动与运行时版本兼容
返回布尔值,指示 CUDA 是否可用。若返回 False,通常表明存在版本不匹配或缺少 GPU 驱动。
5.5 cudaRuntimeGetVersion() 和 cudaDriverGetVersion()
可在应用程序代码中以编程方式查询:
- cudaRuntimeGetVersion():Runtime API 版本(来自 libcudart)
- cudaDriverGetVersion():Driver API 版本(来自 libcuda)
示例:
scss
int runtimeVersion, driverVersion;
cudaRuntimeGetVersion(&runtimeVersion); // 例如 12010(对应 12.1)
cudaDriverGetVersion(&driverVersion); // 例如 12040(对应 12.4)06 编译模型与执行模型
6.1 编译流水线
编译 CUDA 代码时:
1)源代码(.cu 文件):包含(CUDA)kernel 定义(global 函数)和主机端代码。
2)nvcc 编译过程:
- 将设备端代码(GPU)与主机端代码(CPU)分离。
- 设备端代码被编译为指定计算能力(compute capabilities)的 PTX(中间表示)和/或 SASS(GPU 机器码)。
- 主机端代码由主机编译器编译(例如 Linux 上的 g++,Windows 上的 cl.exe)。
3)链接阶段:
- 目标文件与 libcudart(Runtime API)链接。
- 生成的二进制文件包含主机代码和内嵌的 GPU 代码(PTX/SASS)。
为目标计算能力进行编译配置,nvcc 使用 -arch 和 -code 编译选项:
- -arch=compute_XY:设置虚拟架构(PTX 功能级别),决定编译时可使用的 CUDA 特性。
- -code=sm_XY:为特定 GPU 架构(CC X.Y)生成 SASS(原生机器码)。
- -code=compute_XY:在二进制文件中嵌入 CC X.Y 的 PTX,用于前向兼容。
- 可通过逗号分隔指定多个 -code 目标。
默认行为:如果仅指定 -arch=compute_XY 而未指定 -code,nvcc 会隐式为该架构同时生成 sm_XY SASS 和 compute_XY PTX。
最佳实践:始终同时指定 -arch(虚拟架构)和 -code(真实架构)。虽然可以单独使用 -code 而不指定 -arch,但 nvcc 会推断 PTX 级别,这可能不符合预期。
示例:
ini
nvcc -arch=compute_80 -code=sm_80,sm_86,sm_89,compute_80 kernel.cu -o app此命令会生成四种输出:
- SASS(分别对应 CC 8.0(A100)、8.6(RTX 3090/3080)、8.9(RTX 4090/4080))
- CC 8.0 的 PTX,用于未来 GPU 的前向兼容
在执行时:
- 在 A100(CC 8.0)上:直接加载 sm_80 SASS
- 在 RTX 3090(CC 8.6)上:直接加载 sm_86 SASS
- 在 RTX 4090(CC 8.9)上:直接加载 sm_89 SASS
- 在 H100(CC 9.0)上:没有匹配的 SASS,因此驱动程序将 CC 8.0 的 PTX JIT 编译为适用于 CC 9.0 的 SASS
6.2 执行模型
当应用程序运行时:
1)应用程序调用 cudaMalloc、cudaMemcpy、cudaLaunchKernel 等(Runtime API)。
2)libcudart 将这些调用转换为 Driver API 调用(如 cuMemAlloc、cuMemcpyHtoD、cuLaunchKernel)。
3)libcuda.so 通过 ioctl 系统调用与(OS)kernel 驱动程序通信。
4)驱动程序在 GPU 硬件上调度(CUDA)kernel 执行。
5)GPU 执行(CUDA)kernel(SASS 指令),处理数据并返回结果。
传输内容说明:当(CUDA)kernel 被"启动"时,主机不会将 C++ 源代码发送到 GPU。而是:
- 预编译的 GPU 机器码(SASS)或 PTX 已在编译时由 nvcc 嵌入应用程序二进制文件中。
- 应用程序启动时,驱动将合适的代码加载到 GPU 内存:
- 若存在与 GPU 计算能力匹配的 SASS,则直接加载 SASS。
- 若仅有 PTX,则驱动将 PTX JIT 编译为该 GPU 架构的 SASS,再加载执行。
- (CUDA)kernel 启动时,主机指定:
- 网格/块维度(线程块的数量,每个线程块中的线程数量)
- (CUDA)kernel 参数(传递给(CUDA)kernel 的函数参数)
- 共享内存大小
- GPU 的硬件调度器在多个线程块上并行执行 SASS 代码。
该执行模型并非网络层面上的 RPC(远程过程调用),但在概念上有相似之处:
- 命令提交:主机将命令(如(CUDA)kernel 启动、内存传输)放入命令缓冲区。
- 驱动解析:驱动程序将命令翻译为 GPU 特定的操作。
- 异步执行:GPU 独立执行;主机可继续执行其他任务,或通过 cudaDeviceSynchronize() 进行同步。
该编程模型类似于远程执行:主机代码在一个独立的处理器(GPU)上调用操作,该处理器拥有自己的内存空间和指令集。
07 版本不匹配场景
场景 1:Runtime 版本 > Driver 版本
环境配置:
- GPU 驱动支持 CUDA Driver API 12.1。
- 应用程序使用 Runtime API 12.4 构建。
结果:
- 应用程序调用 libcudart(Runtime API 版本 12.4)。
- libcudart 调用 libcuda.so(由 GPU 驱动提供,Driver API 版本 12.1)。
- libcuda.so 不支持 Runtime API 12.4 所需的新 Driver API 功能。
故障:应用程序崩溃或返回 cudaErrorInsufficientDriver。
解决思路:升级 GPU 驱动至支持 CUDA Driver API ≥ 12.4 的版本。
场景 2:编译的计算能力 > GPU 计算能力
环境配置:
- 代码为 CC 8.0 编译(例如 A100)。
- 在 CC 7.5 硬件上运行(例如 RTX 2080 Ti)。
结果:
- 驱动尝试加载 CC 8.0 的(CUDA)kernel 代码。
- GPU 不支持 CC 8.0 指令。
故障:cudaErrorNoKernelImageForDevice 或类似错误。
解决思路:
- 为支持 CC 7.5 而重新编译代码(-arch=compute_75)。
- 或者在二进制文件中包含用于 JIT 编译的 PTX(例如使用 -arch=compute_75 且不指定仅 sm_ 的 -code)。
场景 3:缺少用于前向兼容的 PTX
环境配置:
- 代码使用 -code=sm_80 编译(仅包含 CC 8.0 的 SASS,未嵌入 PTX)。
- 在 CC 9.0 的新 GPU 上运行(例如 H100)。
结果:
- 二进制文件仅包含用于 CC 8.0 的 SASS。
- 没有可用于 JIT 编译的 PTX。
- CC 8.0 的 SASS 与 CC 9.0 不兼容(主版本不同,ISA 不同)。
故障:cudaErrorNoKernelImageForDevice ------ 二进制文件中找不到兼容的(CUDA)kernel 镜像。
解决思路:
- 重新编译并包含 PTX:-arch=compute_80 -code=sm_80,compute_80。
- 在 -code 参数中使用 compute_80 确保 PTX 代码被嵌入二进制文件。
- 在 CC 9.0 硬件上执行时,驱动会将 PTX 代码 JIT 编译为适用于 CC 9.0 的 SASS。
场景 4:PyTorch Toolkit 版本 vs. 驱动版本
环境配置:
- PyTorch 使用 CUDA Toolkit 12.1 编译。
- 系统驱动支持 CUDA 12.4。
结果:
- PyTorch 捆绑或链接 libcudart(版本 12.1)。
- 驱动提供 libcuda.so(版本 12.4)。
- 12.4 ≥ 12.1:成功,无问题。
环境配置(反向):
- PyTorch 使用 CUDA Toolkit 12.4 编译。
- 系统 GPU 驱动仅支持 CUDA Driver API 12.1。
结果:
- PyTorch 运行时所执行的调用,需要使用 Driver API 12.4 版本才提供的功能。
- libcuda.so(Driver API 12.1)不支持这些功能。
故障:cudaErrorInsufficientDriver 或运行时错误。
解决思路:升级 GPU 驱动至支持 CUDA Driver API ≥ 12.4 的版本。
场景 5:系统安装了多个 CUDA Toolkit
环境配置:
- 系统在 /usr/local/cuda-12.1 安装了 Toolkit 12.1。
- 系统在 /usr/local/cuda-12.4 安装了 Toolkit 12.4。
- PATH 指向 /usr/local/cuda-12.1/bin。
- 应用程序使用 Toolkit 12.4 编译。
结果:
- nvcc --version 报告版本号为 12.1(来自 PATH)。
- 应用程序实际使用 Toolkit 12.4 的 libcudart。
- nvcc --version 报告的版本与应用程序运行时(runtime)版本不一致。
注意:nvcc --version 报告的是 PATH 中的 Toolkit,而非应用程序实际链接的版本。应用程序可能捆绑或链接了不同版本的 Toolkit。
解决思路:通过 ldd ./app 检查应用程序实际链接的库,以确定真实的 libcudart 版本。
场景 6:Docker 容器仅有 CUDA 运行时(runtime),无 Toolkit
环境配置:
- 容器镜像基于 nvidia/cuda:12.1-runtime。
- 应用程序需要在运行时(runtime)使用 nvcc 编译(CUDA)kernel 代码。
结果:
- 运行时镜像包含 libcudart,但不包含 nvcc 或头文件。
- nvcc 未找到。
故障:nvcc not found。
解决思路:
- 使用 nvidia/cuda:12.1-devel 镜像,其中包含完整 Toolkit。
- 或在运行时镜像中单独安装 Toolkit。
注意:运行时镜像 vs. 开发镜像:
- 运行时镜像(-runtime):包含运行 CUDA 应用所需的 libcudart 和库,不含 nvcc 或头文件。
- 开发镜像(-devel):包含完整 Toolkit(nvcc、头文件、库),用于编译 CUDA 代码。
场景 7:libcudart 的静态链接 vs. 动态链接
环境配置:
- 应用程序静态链接 libcudart_static.a(Toolkit 12.1)。
- 系统驱动支持 CUDA 12.4。
结果:
- 应用程序内嵌了 libcudart 代码(版本 12.1)。
- libcudart 调用 libcuda.so(版本 12.4)。
- 12.4 ≥ 12.1:成功。
环境配置(反向):
- 应用程序静态链接 libcudart_static.a(Toolkit 12.4)。
- 系统驱动支持 CUDA 12.1。
结果:
- 内嵌的 libcudart(版本 12.4)调用 libcuda.so(版本 12.1)。
- 12.1 < 12.4:失败。
注意:静态链接会将 libcudart 打包进应用程序二进制文件,其版本在编译时确定,无法在运行时更改。动态链接允许在程序运行时,通过库搜索路径(Linux 上为 LD_LIBRARY_PATH,Windows 上为 PATH)或系统库,来选择使用哪个版本。
08 组件关系总结
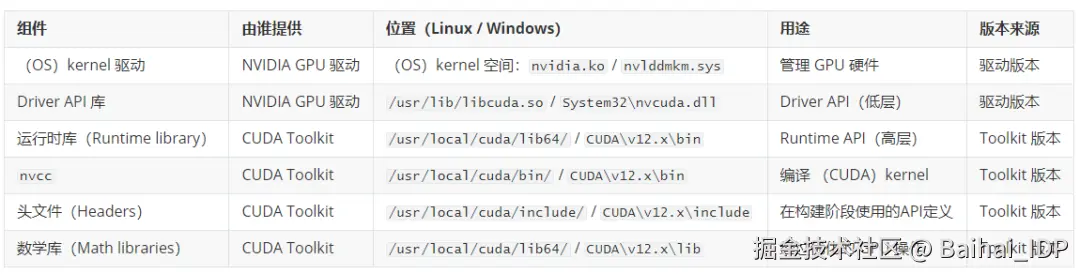
09 实用指南
9.1 面向应用程序开发者
- 明确最低驱动版本:在文档中注明所需的 CUDA Driver API 版本。
- 捆绑或指定运行时版本:若静态链接 libcudart,需确保与系统驱动兼容;若动态链接,应注明所需的 libcudart 版本。
- 为多种计算能力(compute capabilities)编译:使用 -arch 和 -code 标志来支持多种 GPU,并嵌入 PTX 以实现前向兼容。
- 在运行时(runtime)检查版本:通过 cudaDriverGetVersion() 和 cudaRuntimeGetVersion() 验证兼容性。
9.2 面向终端用户
- 安装合适的 GPU 驱动:确保驱动支持的 CUDA Driver API 版本 ≥ 应用程序所需的 Runtime 版本。
- 运行时通常无需安装完整 Toolkit:大多数应用程序不需要 nvcc 等开发工具,仅需 libcudart 和 GPU 驱动即可。
- 检查兼容性:运行 nvidia-smi 以确认 GPU 驱动版本及其支持的 CUDA Driver API 版本。
9.3 面向 PyTorch 用户
- 编译时 Toolkit 版本(torch.version.cuda):指 PyTorch 编译时(build time)所链接的 CUDA Toolkit 版本,无需与系统中安装的 Toolkit 一致。
- 运行时驱动程序版本要求:系统 GPU 驱动必须支持 CUDA Driver API 版本 ≥ PyTorch 的编译 Toolkit 版本。
- 示例:
- 若 PyTorch 使用 CUDA Toolkit 12.1 编译,则系统 GPU 驱动必须支持 CUDA Driver API ≥ 12.1。
- 若系统 GPU 驱动支持 CUDA Driver API 12.4,则可运行使用 CUDA Toolkit 12.1、12.2、12.3 或 12.4 编译的 PyTorch。
注意:TensorFlow 采用相同的兼容性模型,请查阅其发布说明以确认其编译所用的 Toolkit 版本。
9.4 面向 Docker / 容器用户
- 仅运行时镜像(-runtime):包含 libcudart 及运行库,适用于运行预编译的 CUDA 应用程序,不含 nvcc。
- 开发镜像(-devel):包含完整的 CUDA Toolkit(nvcc、头文件、库文件),编译 CUDA 代码时必需。
- NVIDIA Container Toolkit:确保容器能访问主机的 GPU 和 GPU 驱动。容器内可用的 CUDA Driver API 最高版本由主机上的 GPU 驱动版本决定。
10 结论
CUDA 的架构是一个分层系统,各组件在编译时和运行时承担不同职责。要准确理解它,需做到以下几点:
1)术语辨析(Disambiguation) :
"CUDA" 可指计算架构、指令集(ISA)、语言扩展、Toolkit 或 Runtime。
"Driver" 可指 (OS)kernel 空间的驱动(如 nvidia.ko)或用户空间的 Driver API 库(如 libcuda.so)。
"Kernel" 可指操作系统内核(OS kernel)或 GPU 函数(CUDA kernel)。
2)分层结构(Layering) :
libcudart(前端,Runtime API,面向应用)调用 libcuda(后端,Driver API,面向系统);
libcuda 进而调用(OS)kernel 驱动(nvidia.ko);
(OS)kernel 驱动最终管理 GPU 硬件。
3)版本规则(Versioning) :
Driver API 版本必须 ≥ Runtime API 版本。
GPU 要么需有与其计算能力匹配的 SASS,要么二进制文件中必须包含 PTX,以便驱动能 JIT 编译为对应架构的 SASS。
4)编译时 vs. 运行时(Build vs. execution) :
编译时需要 CUDA Toolkit(含 nvcc);
运行时仅需 libcudart(可捆绑或动态链接)和系统 GPU 驱动。
版本不匹配会产生特定的故障模式:驱动程序版本不足、找不到(CUDA)kernel 映像或不支持 API 调用。通过这种系统化的理解,我们可以清楚为什么 nvidia-smi、nvcc --version 和 torch.version.cuda 会报告不同的版本号,每个版本号的含义是什么,以及如何诊断版本不兼容问题。
END
本期互动内容 🍻
❓除了本文提到的术语,你还遇到过哪些容易混淆的CUDA相关概念?(例如:stream、context、graph...)
本文经原作者授权,由 Baihai IDP 编译。如需转载译文,请联系获取授权。
原文链接: