四年前,当我写下那篇MTE(Memory Tagging Extension)的介绍文章时,仿佛它的光明前景就在眼前。
然而现实总是骨感的。这些年,MTE在CPU架构层面经历了数次迭代,它所牵动的模块数量也超过常人想象:从CPU到Bootloader,从Kernel到Bionic,从LLVM到NDK......每一层都需要为它调整。不断迭代的架构、众多牵扯的模块,使得MTE的落地速度比预期更为缓慢。
如今,MTE正逐渐浮出水面,在越来越多的工程实践中显露身影,因此是时候重新审视它了。只不过这一次,我们不再局限于"使用者"的视角,而是试着把它背后的每一处改动、每一次演进都给弄懂,构建一种更深刻、更宽广的认识。
历史演进
时间拉回到7年前。2018年,Google的一篇论文《Memory Tagging and how it improves C/C++ memory safety》横空出世,预示着MTE在理论上的正式发表。同年,Armv8.5架构正式发表,其中赫然标注着FEAT_MTE和FEAT_MTE2的feature,预示着MTE在CPU架构层面的出现。事实上早在2017年,Google和ARM就已经开始合作,探索这种硬件+软件的安全方案的可能性。2019年,ARM正式发表了MTE的白皮书,系统性地介绍了MTE在Arm架构中的支持。同年,Google也正式宣布将在Android中采用MTE。之后的时间,MTE在CPU架构层经历了两轮迭代,分别是Armv8.7推出的FEAT_MTE3和Armv8.9推出的FEAT_MTE4。AOSP、LLVM和Linux Kernel等开源社区,也在紧锣密鼓地推进着MTE在各自领域的支持。最终在2023年末,Google Pixel 8正式发布,成为第一台支持MTE的手机。
Google和ARM刮起的这股内存安全之风同样席卷了位于硅谷的苹果。作为一家追求极致的企业,早期的MTE并没有入得了苹果的法眼,他们总觉得那时的MTE还是个半成品,因此积极和ARM合作,推动了FEAT_MTE4------也即Enhanced MTE的诞生。直到2025年9月,经过5年多的打磨,苹果才终于将这个安全特性推入了iPhone 17,并公开发表了一篇介绍文章。为了表示自身的差异化,苹果换了一个名字,叫作"MIE(Memory Integrity Enforcement)",并深情发表了这样一句话:
We believe Memory Integrity Enforcement represents the most significant upgrade to memory safety in the history of consumer operating systems.
颇有些"苹果的一小步,人类的一大步"的感觉。
在CPU系统架构层面,MTE目前共有4个版本。
| MTE Version | Architecture Version | Year |
|---|---|---|
| FEAT_MTE | Armv8.5 | 2018 |
| FEAT_MTE2 | Armv8.5 | 2018 |
| FEAT_MTE3 | Armv8.7 | 2020 |
| FEAT_MTE4 | Armv8.9 | 2022 |
FEAT_MTE:确立了接口规范。它引入了IRG、STG等MTE相关的指令,确保了软件生态的兼容性。
FEAT_MTE2:赋予了硬件灵魂。这是MTE的完全体,打通了Tag的生成、物理存储和硬件检测,并定义了Synchronous(同步)和Asynchronous(异步)两种基础检测模式。
FEAT_MTE3:引入了Asymmetric(非对称)检测模式,巧妙地在性能和安全性之间找到一种平衡,在和异步检测性能开销相近的情况下,可以针对读操作进行同步检测。
FEAT_MTE4:通过Canonical Check等特性,修补了未标记内存的访问漏洞。在安全性和功能性上做了一些增强。
可是道高一尺,魔高一丈。随着MTE逐渐成为内存安全的标配,它也成为了顶级安全研究员的靶子。2024年,首尔大学和三星的研究人员联合发表了一篇文章,旨在揭示通过操纵分支预测(Branch Prediction)和推测执行(Speculative Execution),观察Cache的状态变化(读取某个变量,通过读取时间判断是否Cache命中),在不触发MTE异常的情况下"偷看"到正确的Tag。这无疑给MTE的架构师们提出了新的考验,如何从架构设计和SoC实现的层面封堵这些新的攻击方式,成为接下来的主要目标。
性能开销
自打有手机以来,性能就是一个备受关注的话题。而MTE之所以能够在众多内存检测的工具中脱颖而出,靠的也是它极低的性能开销。Arm的博客和用户手册中明确表达过:Async模式在已测试的workloads/benchmarks上,性能开销大概在1~2%这个区间。Google在MTE的官方介绍也提到,Asymm和Async开销基本一致。至于Sync的开销,目前没有官方论述,但在各种三方论文里能找到蛛丝马迹。只不过它的范围浮动太大,从3%到30%都有人说(取决于实际的benchmark),因此这里不列举具体数值了。
从设计哲学来看,同步模式代表了安全优先的终极形态。MTE的初衷是遏制攻击,而最理想的防御,就是在异常发生时彻底熔断,确保CPU停留在访问异常的那条指令上,而没有任何一条后续的指令被执行,从而切断攻击链。相比之下,异步模式更像是现实主义的妥协(苹果在MIE的文章里表达过对异步的"鄙视")。同步模式的性能开销过大,导致它在生产环节中无法使用。因此异步选择了一种"先执行,后追责"的策略:让流水线全速奔跑,转而将Tag检测作为一种旁路机制,且只在进入内核时才结算。这种设计牺牲了报错的精确性,但却换取了流水线的高速运转,可以适用于生产环节。
不过以上只是宏观的描述,如果具体拆解,我们会得到如下结论:
- 同步的读操作(
ldr)相较于异步的读操作性能开销基本没有增加,因为Async和Asymm的核心差异在于读操作由异步换成了同步,但二者性能基本相当。 - 同步的写操作(
str)相较于异步的写操作性能开销增加很多,甚至可以说是Sync模式性能开销的主力军,因为Asymm和Sync的核心差异在于写操作由异步换成了同步,但二者性能差异很大。
基于这个拆解,我们尝试从CPU执行的角度来看看性能到底开销在哪里。
首先是Async模式的开销。
主要来自这几个地方:
- Tag存储在物理内存中,但同样也需要被加载到Cache中,因此发生Cache Miss时,既需要搬运数据,也需要搬运Tag,所以需要额外的总线传输时间。
- Tag会占用Cache的空间,因此在Cache总大小不变的前提下,Cache Miss率会上升。
- 为了让MTE可以工作,必须插入额外的指令来生成和管理Tag,譬如
IRG、STG等指令,这些指令本身也是种开销。
接着是ldr在异步和同步模式下的区别。
上图展示了一条ldr x0, [x1, #0x8]指令在CPU执行层面的区别。
在深入理解MTE之前,我们先来对现代高性能CPU(如ARM的Cortex-X系列)的执行有些基本了解,它的核心是乱序执行(Out-of-Order Execution)。虽说执行是乱序的,但是指令的提交/退休(Commit/Retire,在这里是同一个概念)必须是顺序(In-Order Commit)的,也就是执行结果必须按照原来的顺序写回寄存器或内存。否则,推测执行产生的错误结果可能会永久生效,导致程序逻辑的彻底崩坏。为了保证In-Order Commit,指令在发送之初就会同步送往一个叫作ROB(Reorder Buffer)的环形缓冲区,它强制所有指令按照最初的代码顺序来退休,如果前面的指令没做完,后面的指令就算做完了,也得在ROB里等着,不能生效。
当指令进入CPU后,会被拆解为两个动作并行处理,一个是在ROB中占住坑位,标记为Speculative状态。另一个发送到IQ,等待x0和x1的数据就绪。一旦就绪,AGU立即计算出最终的存储地址,然后送入LQ准备和Cache进行交互。
L1的Cache Line分为Data和Tag两部分,因此读回数据的同时也会读回Tag。而同步和异步的核心区别,在于读回Tag后的处理方式。对异步而言,只要数据读回就可以往x0里写,它不用去等待Tag的处理,二者是并行的。但对同步而言,写往x0之前必须等待Tag检测通过。因此,Tag检测成了同步流水线中的一个负担,但好在它只是一个简单的比较逻辑,速度非常快。放在ldr整体的执行时间中来看(主体时间消耗在和Cache的交互上),几乎可以忽略不记。因此,对ldr操作而言,同步和异步在性能上几乎没有差异。
最后是str在异步和同步模式下的区别。
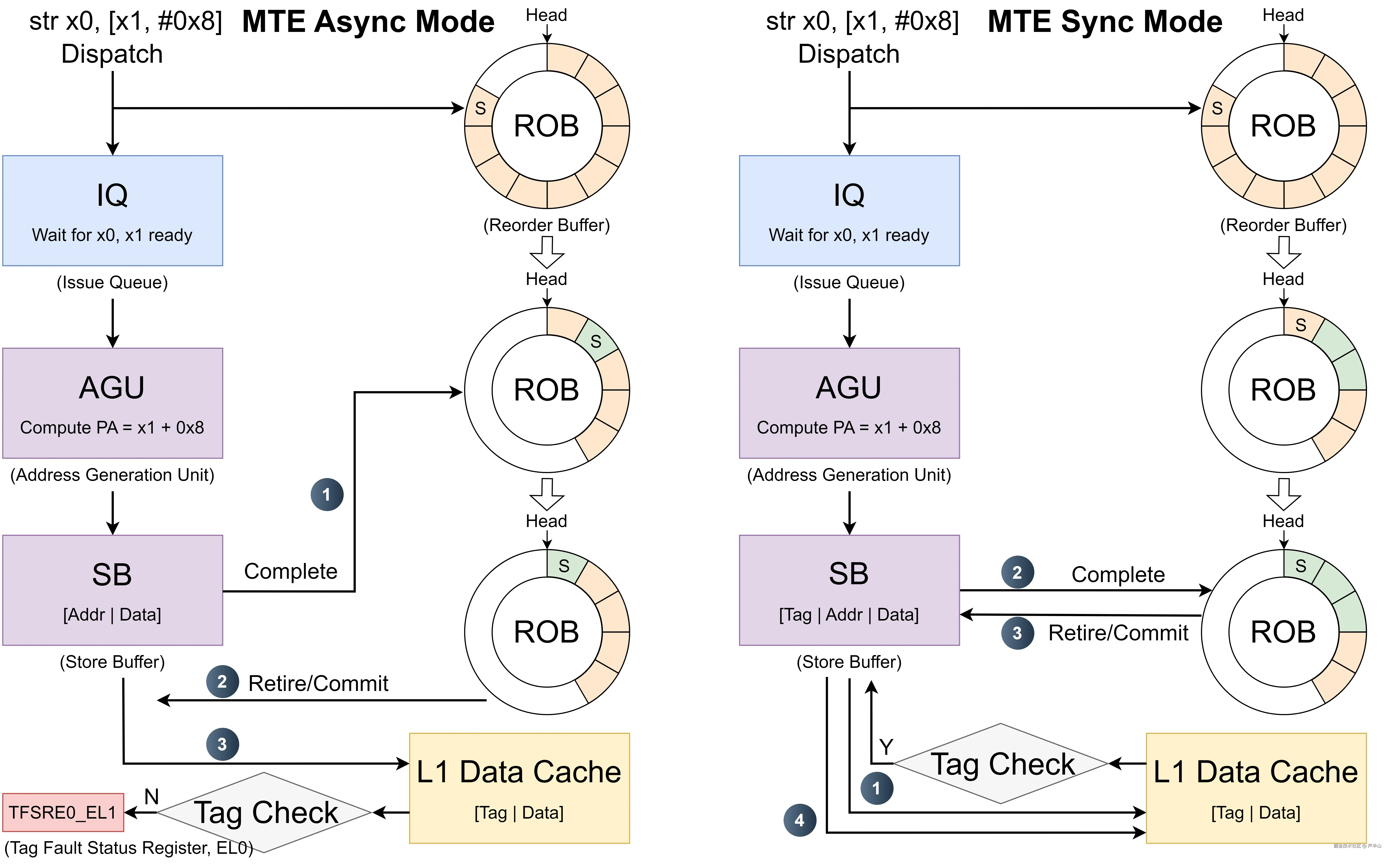
上图展示了一条str x0, [x1, #0x8]指令在CPU执行层面的区别。
Async的图中可以看到,只要数据和地址成功进入SB,ROB便认为该指令已经逻辑完成。一旦它到达ROB头部,就会立即退休,释放流水线资源。而数据真正写入Cache以及伴随的Tag读取和检查,其实都发生在指令退休之后。有人可能会问:指令退休,而数据又没写入Cache的空档期,如果后续指令急用到这块内存,不是会出问题吗?实际上CPU早考虑到了,这些指令可以通过Store-to-Load Forwarding技术直接从SB中"偷看"数据,完全绕过Cache。因此,从流水线吞吐率的角度来看,MTE的Tag读取和检测被完美地推迟到指令退休之后,实现了真正的无感。
但在Sync模式下,为了保证异常的精确性,Tag的检测被强制要求在指令退休之前完成。这是一笔巨大的性能开销。本来瞬间完成退休的str指令,现在必须停下来等待高延迟的Tag读取。这使得它在ROB长时间驻留,一旦这条未完成的指令到达ROB头部,它就会成为整个CPU的瓶颈,导致后续那些早已执行完毕的指令无法退休。这种阻塞效应会迅速填满ROB(因为ROB一直有指令进来),进而影响前端的指令发送,最终迫使整个流水线陷入停顿。
除了上述的指令流水线开销外,Sync模式还有一个常被忽视的隐性成本------即在malloc/free时进行的调用栈回溯。严格来说,这部分开销并非服务于安全性,而是可调试性。它可以让开发者获取完整的上下文,从而定位根因,修复问题。
内存开销
现有的硬件实现中,Tag Storage通常是由DDR Memory Controller线性隐式寻址的:
Tag_PA = Base + (Data_PA >> 5)
这种线性关系是定死的,因此如果你有32G的内存,那么其中必须有1G(1/32)的物理空间是留给Tag的。即使你只为一小部分内存开启了MTE检测,剩下的空间也无法被操作系统当作普通数据内存使用,因为它在Bootloader那一层就已经被Carve-out出去了,相当于操作系统根本感知不到它的存在。
2023年8月,ARM的工程师Alexandru Elisei提交了一笔包含37个patch的改动:Add support for arm64 MTE dynamic tag storage reuse,尝试在Kernel层面对这个问题进行解决。它的核心思路是把这块"预留但经常闲置"的物理内存拿回来给系统当普通内存用,等某页开启MTE时,再将对应的Tag内存迁移释放出来。
但这笔改动确实牵扯的东西太多,因此23年11月发表了v2版本,24年1月又发表了v3版本,都对设计做了大的调整。不过社区最终还是没有采纳,核心的原因正如core-mm的maintainer David Hildenbrand说的那样:最好别为了一个架构特性去动太多的core-mm,此外别引入一些新的zone/migratetype,除非你能说服大家"最多回收3%的RAM"也值得这么折腾。
随着这笔patch的搁置,大家慢慢意识到:只要Tag和物理地址绑定,那么软件层面的修复方案只能是戴着镣铐跳舞。因此,ARM在对未来的架构展望上提出了一个新的feature,叫作vMTE(Virtual Memory Tagging Extension)。它将Tag的存储关系,由物理层面的映射转换成了页表层面的映射,从而可以做到按需分配。这种从静态预留到动态映射的转变,将极大地降低MTE的内存开销。
仔细想想,有时在软件层面累死累活的工作,放到架构层面可能会轻松很多。
繁杂的配置
初入MTE会给人一种眼花缭乱的感觉,心想,配置项怎么这么多呢。这也难怪,谁让它横跨了那么多层级,又有那么多模式呢。从CPU到Kernel到用户空间,这是一个维度;从sync到async到asymm的检测模式,这是另一个维度;从heap到stack到global的检测范围,这还是一个维度。总之,纷繁复杂。
今天,我想要做的就是把这些繁杂的配置项给统一起来,理解每一项配置的传导逻辑,以及最底层的调控逻辑。于是有了下面这张图。
让我们从最底层的硬件逻辑开始,看看CPU是如何执行MTE检测的。
MTE的所有上层调控,最终都会汇聚成CPU的行为。这种影响主要通过两条路径实现:一条是控制CPU的执行单元,另一条是控制内存系统。
当CPU在用户空间执行一条读写指令(如LDR或STR)时,它会按顺序进行两次判定:
- 是否持有"免检金牌"?CPU首先检查
PSTATE.TCO寄存器。如果这个位被置上(TCO=1),意味着当前线程处于免检状态,直接跳过所有的Tag检查。如果没有置上,则继续下面的判定。 - 访问地址是否需要检测?CPU接着检查访问地址在TLB中的MTE属性位。只有当这块内存页被明确标记为开启MTE保护时,CPU才会启动硬件比较器进行Tag比对;否则,默认放行。
如果Tag比对失败,那么CPU该怎么办?这就轮到SCTRL_EL1中的TCF0字段来指挥了:
- 0b00(None),装作没看见,继续执行。
- 0b01(Sync),立即报警,产生同步异常,内核捕获后会给上层发送
SIGSEGV(MTESERR)信号。 - 0b10(Async),记录下来,但不打断当前执行,等到下一次进入内核(如系统调用)时再结算,上层会收到
SIGSEGV(MTEAERR)信号。 - 0b11(Asymm),看人下菜碟。如果是读操作,采用Sync模式;如果是写操作,采用Async模式。
此外,还有一个特殊的寄存器GCR_EL1,它就像是Tag生成器的黑名单。例如在Android上,系统配置它排除掉了Tag 0,只允许生成1~15的Tag。因为Tag 0被单独留给了Scudo内存块的头部(Chunk Header),这样任何溢出踩踏到头部的行为都会因为Tag不匹配而被当场抓获。
至于CPU到底支不支持MTE功能,则由ID_AA64PFR1_EL1中的MTE位来告知操作系统。
理解了硬件逻辑,我们将视线稍微上移,来到Kernel层。
操作系统是如何管理这些硬件寄存器的呢?我们依然分执行控制和内存控制两个方面来阐述。
- 执行控制:
SCTRL_EL1和GCR_EL1并不是全局不变的,它们的值来源于每个线程结构体中的mte_ctrl。这意味着,MTE的这些策略是线程级的。当线程切换时,内核会负责切换这些寄存器,所以这些MTE的策略本质上是线程绑定,而非CPU绑定的。不过每个CPU都有一个自己的mte_tcf_preferred变量,它相当于一次升舱机会。譬如mte_ctrl原本的模式为Async,但由于当前CPU的mte_tcf_preferred是Asymm,所以最终写入SCTRL_EL1的模式将会升舱为Asymm。 - 内存控制:TLB里的MTE属性并不是凭空产生的,它源自页表项(PTE)。PTE记录了虚拟地址与物理地址的映射关系及属性。当我们在用户空间调用
mmap或mprotect并指定PROT_MTE标志时,内核就会在PTE中打上标记,最终被加载进TLB生效。
接着来到用户空间。
对于上层开发者而言,Kernel暴露了一些标准的接口:
prctl:用于修改当前线程的mte_ctrl,从而控制CPU的检测模式和Tag范围。getauxval:通过读取辅助向量(Auxiliary Vector),查询硬件是否支持MTE。msr指令:这是一个特例。用户空间可以直接执行msr tco, #1来修改PSTATE.TCO。这通常用于内存分配器内部,在初始化内存等特殊时刻,临时开启"免检金牌"来跳过检查。
有了Kernel提供的基本接口,那么谁负责来调用它们呢?这主要是libc和内存分配器Scudo的职责。
在Android的Bionic Libc中,全局静态变量heap_target_level是连接上层策略与底层实现的总闸门,它可以通过mallopt(M_BIONIC_SET_HEAP_TAGGING_LEVEL)来动态调控,也可以在进程启动初期通过SetDefaultHeapTaggingLevel来设定。那么它具体会控制哪些东西呢?
- 通过
prctl的接口来控制检测模式和Tag范围。 - 控制Scudo内存分配器MTE功能的开关,进而影响到三件事:一是Scudo分配的内存页是否标记上
PROT_MTE;二是内存分配时,是否生成随机Tag,并利用STG指令将Tag写入内存;三是是否开启malloc/free调用栈的记录功能。
Libc只是个执行的中转层,那么具体是谁,来决定一个进程该以什么模式运行呢?这就回到进程启动的起点,在Android中分为两条不同的路径。
路径一:原生程序的exec之路(由Dynamic Loader主导,蓝色背景)
当你运行一个Native可执行文件时,内核会加载Dynamic Loader(Linker)。Linker在加载依赖库之前,必须先决定MTE的策略。为了考虑到更加广泛的适用性,Linker设计了一套复杂的调控逻辑,其优先级如下:
-
开发者在启动时设置的环境变量
MEMTAG_OPTIONS,具有最高优先级。MEMTAG_OPTIONS = (off|sync|async)
-
系统属性
arm64.memtag.process.{basename},根据basename来决定所影响的进程。arm64.memtag.process.{basename} = (off|sync|async)
-
常驻(重启依然有效)的系统属性
persist.arm64.memtag.default。persist.arm64.memtag.default = (off|sync|async)
-
可以云端调控的常驻的系统属性
persist.device_config.memory_safety_native.mode_override.process.{basename}。persist.device_config.memory_safety_native.mode_override.process.{basename} = (off|sync|async)
-
通过读取ELF文件中Dynamic Section里的
DT_AARCH64_MEMTAG_MODE得到的配置信息。具有最低优先级。
这套逻辑虽说复杂,但也给了开发者足够的自由度,可以定制属于自己的MTE使用方式。
上述配置中的第5项,属于ELF文件中自带的信息,它其实就是连接编译和运行最为关键的中间人。
让我们把视角再移到编译世界。
现如今,不论是Android的用户空间还是Linux内核,编译的核心角色都已经换成了LLVM的Clang。但我们在现实场景中碰到更多的似乎是Soong、CMake这样的名词,它们之间有啥关系呢?
在Android的编译体系中,实际上有三层架构:
- 元构建层:Soong、CMake、Make
- 执行层:Ninja
- 工具链层:Clang、LLD
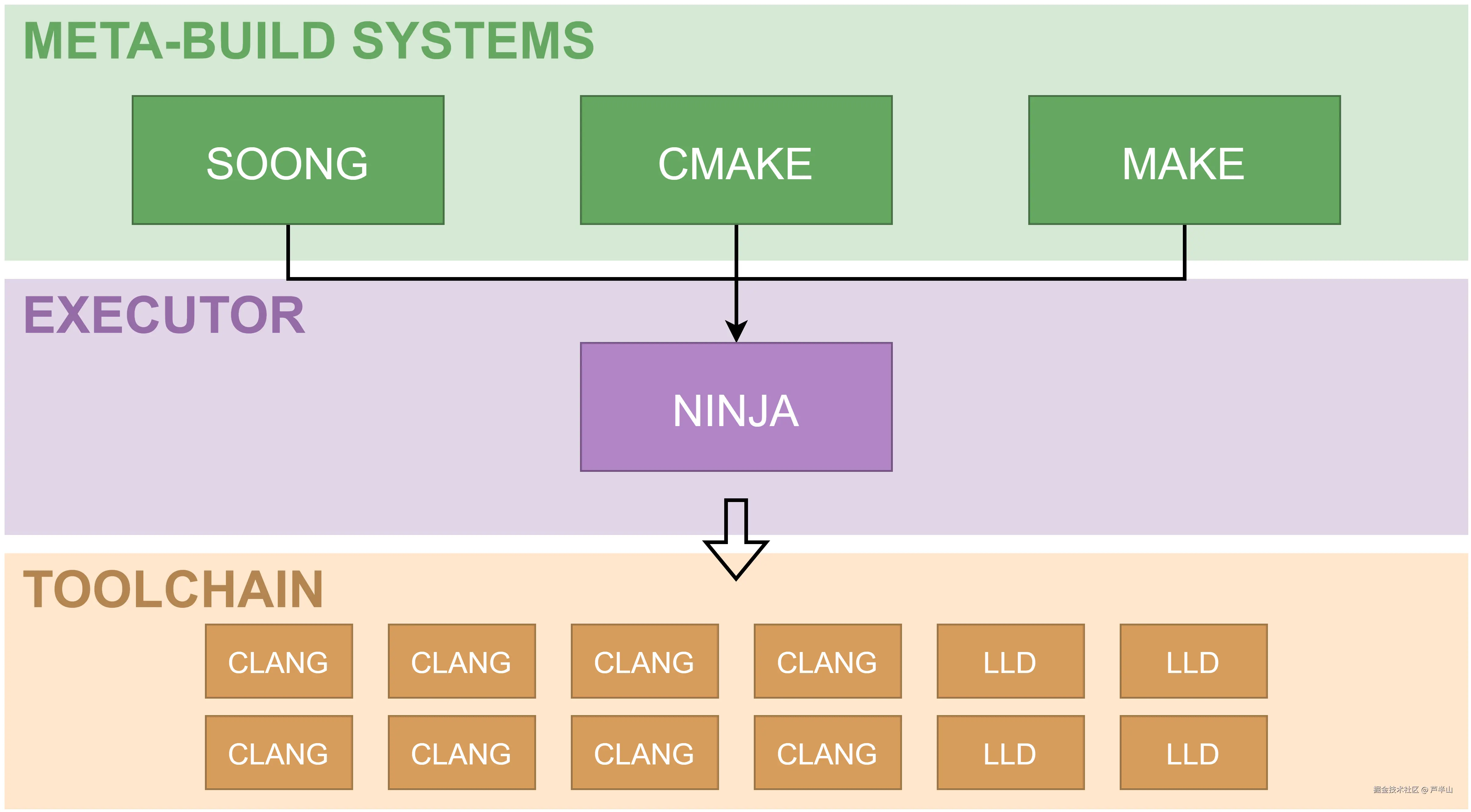
元构建层负责将那些人类可读、有复杂逻辑关系的文件(譬如Android.bp、CMakeLists.txt)转译成一份巨大的、有扁平依赖关系网的文件(build.ninja),之后执行层会根据这个文件来并发地启动进程快速执行任务,而每个任务的内部则需要调用Clang或lld来负责具体的编译和链接。
了解了整个编译体系,我们便可以知道:所有构建系统中的配置项,其实决定的就是传给Clang的参数。
而这个参数只有两种:
- CFLAGS:
-fsanitize=memtag-xxx,它决定编译器的行为,最终影响生成的机器码。拆开来说,MTE的检测可以分为三个区域:堆上的对象、栈上的局部变量,还有全局变量。堆上对象的Tag生成、存储、擦除等动作都集成到了malloc和free的具体实现中,因此和编译环节无关。全局变量的Tag生成、存储等动作是在运行时由Dynamic Loader完成的,因此基本上也和编译环节无关。只有栈上的对象,需要在函数的Prologue和Epilogue中对局部变量进行Tag的相关操作,因此需要大量的代码插桩,和编译环节高度相关。 - LDFLAGS:
-fsanitize=memtag-xxx, -fsanitize-memtag-mode=sync,它决定的是链接器的行为,最终影响生成的ELF文件的Dynamic Section,相当于把这些信息放入文件,最终在运行时让Dynamic Loader读取到。
路径二:Java进程的fork之路(由zygote主导,绿色背景)
所有的Java进程都fork自zygote进程。对zygote自身而言,Dynamic Loader在它的启动过程中承担了重要作用;但对Java进程而言,这个过程其实被跳过了,因此MTE的配置需要另择良机。
启动过程中,AMS会按照一个复杂的优先级来获知此次启动的MTE策略,然后在Zygote Specialize的时候将策略写入mallopt,进而修改fork出子进程的heap_tagging_level。这个具体的策略如下:
-
常驻的系统属性
persist.arm64.memtag.app.{PackageName},具有最高优先级。persist.arm64.memtag.app.{PackageName} = (off|sync|async)
-
Manifest里process标签下的memtagMode配置。
<process
...
android.memtagMode=off|sync|async>
-
Manifest里application标签下的memtagMode配置。
<application
...
android.memtagMode=off|sync|async>
-
开发者选项里的App兼容性配置,可以手机界面操作,也支持am指令来修改。
adb shell am compat enable NATIVE_MEMTAG_ASYNC my.app.name
-
常驻的系统属性
persist.arm64.memtag.app_default。persist.arm64.memtag.app_default = (off|sync|async)
-
当上述指定的模式为Async时,如果手机是USERDEBUG或者ENG版本,且
persist.arm64.memtag.default为Sync的话,则自动将Async升舱为Sync。
细心的朋友可能发现了,android.memtagMode里有个default选项我在2、3里没有提及,这是因为default最终会由第5项配置决定。
单向开关
在上述的动态调控策略中,有很多都可以双向开关,比如由开到关,过一会再由关到开,很自由,譬如prctl和PSTATE.tco的调控。但也有些调控只能单向,开完就不能关了,比如PROT_MTE,或者关完就不能再开了,比如heap_target_level。
先来说说PROT_MTE,Kernel文档中明确提到,它无法被mprotect清除。这背后基于两点考虑,一个是生态,一个是语义。
虽然现在Kernel支持了PROT_MTE的flag,但是历史上很多代码根本不会考虑到它。比如,JIT的内存区域经常需要通过mprotect来切换权限(r-x ↔ rw-),如果允许PROT_MTE被清除,那么它在这种场景下将很容易被"误"清除。
再者,如果PROT_MTE允许被清除,那么清除之后进程里依然存在大量指向该区域且带有Tag的指针。即便在PROT_MTE被清除的这段时间检测被关闭,没有问题出现,但是如果再次开启PROT_MTE,那么内存的Tag将被清零,这时再拿着带有Tag的指针访问,将会引发大面积的错误。
接着说说heap_target_level,Android文档中明确提到,从M_HEAP_TAGGING_LEVEL_NONE切换到任何模式都是不允许的。
因为一旦允许从关→开,那么就等于允许"开→关→开"等多次切换。而关闭的这段时间,由于Scudo不会再管Tag的事情,释放的内存一旦被复用,就会出现Pointer Tag(未设置,为0)和Memory Tag(未清除,依然存在)的不匹配。只不过关闭期间不检测,所以不会产生问题。可是如果再开启的话,这种不匹配就会导致进程的崩溃。
从设计的本源出发,很多东西都是自由的,之所以有限制,其背后一定有深刻的权衡和考量。
栈检测
很多时候,我们讨论MTE有个隐含的假设,即只针对堆上的数据进行检测。但实际上MTE同样可以针对栈上的数据和全局变量进行检测。
Android宣称从Android 14 QPR3版本就开始支持MTE的Stack Tagging,但实际上直到2024年下半年,Google的工程师还一直在增加对Stack MTE的代码支持,所以严格来说,Android 16才算对Stack检测有了比较完整的支持。
与堆的检测不同,栈对象的生命周期由编译器管理。因此,Stack MTE的核心逻辑发生在LLVM生成汇编代码的阶段。
当你使用-fsanitize=memtag-stack编译代码时,LLVM会在函数的入口(Prologue)处对当前SP使用IRG指令,生成一个带有随机Tag的基地址,接着为每个局部变量通过递增方式生成一个独特的Tag。函数返回(Epilogue)前,再将Tag擦除或重置。如此一来,只有在函数的生命周期内,局部变量的访问才是合法的。当然,越界的错误由于Tag不同也可以被检测出来。
然而,仅有编译器的插桩是不够的,还需要Android在bionic、dynamic loader以及debuggerd层面给予支持。需要注意的是,Stack MTE和ELF文件本身高度捆绑,这个ELF文件可以是进程启动时的可执行文件,也可以是进程运行到一半时加载的共享库。因此,Stack MTE的启用路径就要分为两种情况:
- 启动时启用:主程序或任一依赖库是
memtag-stack编译的,就在进程启动阶段启用。 - 运行中启用:如果后续dlopen进来一个
memtag-stack库,需要把已有线程的检测也给补齐。
所谓的启用其实包含三件事:
- 把线程栈remap/mprotect成
PROT_MTE。 - 通过
prctl(PR_SET_TAGGED_ADDR_CTRL, ...)的接口来设置具体的检测模式。 - 分配stack history buffer,它是每个线程一个的ring buffer,挂在TLS上。
当栈上对象触发错误时,debuggerd会将stack history写入tombstone,但我们还无法看出最终的问题归因,还需要借助development/scripts下的stack脚本以及symbols文件。Android源码目录里的stack脚本会把stack history里的信息映射到本地的符号文件,再从DWARF调试信息里恢复该栈帧里局部变量的布局,从而根据fault地址和Tag值判断问题是overflow/underflow还是use-after-return。
总体来说,Stack MTE的流程是割裂的,横跨编译/运行/离线分析多个维度,对使用者来说并不友好。
全局变量检测
全局变量,主要指的是ELF文件里.data、.bss段里那些具有静态存储期的对象。Android对它的检测支持同样发生在24年底,因此Android 16上才算有这个功能。
当你使用-fsanitize=memtag-globals编译代码时,实际上汇编指令层面并不会有任何插桩,但是LLD会把Memtag ABI相关的动态条目写入ELF(DT_AARCH64_MEMTAG_GLOBALS和DT_AARCH64_MEMTAG_GLOBALSSZ)。
真正干活的其实是Dynamic Loader(Android linker),它会解析ELF文件的dynamic section,一旦发现DT_AARCH64_MEMTAG_GLOBALS和DT_AARCH64_MEMTAG_GLOBALSSZ,就会进入Globals MTE的加载路径。
首先,它会让相应的地址范围开启PROT_MTE。不过根据内核文档,PROT_MTE只支持MAP_ANONYMOUS和RAM-based file mappings(如tmpfs/memfd),而共享库的.data往往来自file-backed的私有映射,因此PROT_MTE时会失败。所以Dynamic Loader会把所有可写的SHF_ALLOC段转换成匿名映射,并拷贝初始内容,从而确保全局变量所属内存可以开启MTE检测。
其次,它会读取DT_AARCH64_MEMTAG_GLOBALS指向的description stream,是一个ULEB128编码的信息流,描述的是全局变量的布局。根据这个信息,Loader可以为每个全局变量都打上合适的Tag。
不过光有内存的Tag还不够,还需要为使用这些内存的指针打上Tag。由于全局对象的地址通常会在加载时被填入GOT或其他重定位目标位置,因此Dynamic Loader需要为它们也打上Tag。
当检测到错误时,tombstone无法很好的归因,这部分需要开发者自己补齐。一般的流程如下:
- 定位fault address在哪个so的哪个段(.data/.bss)。
- 再用symbols/DWARF把地址范围映射到具体的全局变量。
- 结合tombstone的tag表,寻找指针tag到底归属于哪个全局变量,从而判断越界的来源。
和堆上的检测相比,栈和全局变量的用户友好性不高,当然,它们用到的机会也不多。
后记
目前Android内部的配置和支持还稍显杂乱,比如heap_tagging_level,它不光控制heap,其实也控制stack和globals,这属于命名的不规范;还有tombstone的一些归因,在Asymm模式下会产生误导性的信息,等等,这些未来估计都会有调整。总的来说,MTE仍然处在快速的演进过程中,还未完全定型。但它的光明前景,依然是可以期待的。
这篇文章可能是我有史以来耗时最久的一篇,前后持续了几周,翻阅了各种资料、论文、手册,只为了把MTE的各个细节都理解透彻。我心里明白,这样的文章受众不会很多。就像哲学在很多人眼中是无用的,但王德峰说的:这么大的国家,总得有几个人来研究黑格尔,研究康德,研究下孔孟和老庄吧?同理,这么多研究Android的人里,总得有几个人来深入地研究下MTE吧?